ディザスター リカバリー訓練の実行
このユニットでは、Site Recovery のディザスター訓練について学習します。考慮が必要な事項と、テストを実行して構成が正しいかどうかを確認する方法について学習します。
ディザスター リカバリー (DR) 訓練を使用して、運用サービスに影響を与えることなく、機能停止から復旧する組織の能力をテストします。
前の演習で Azure Site Recovery の設定が完了したので、次にインフラストラクチャのレプリケーションをテストする必要があります。 DR 訓練を実行して構成をテストします。 Azure Site Recovery を使用すると、運用環境に影響を与えないよう、安全にこれらの訓練を行うことができます。 DR ソリューションが機能していることを確認するために、構成上で品質保証テストも実行します。
ディザスター リカバリー訓練とは
DR 訓練とは、ソリューションを正しく構成したかどうかを確認する方法です。 訓練により、皆さん、また会社は、災害が発生した場合でもデータとサービスを確実に利用できるという自信が得られます。 通常、組織は、インフラストラクチャの復旧にかかる時間を示す目標復旧時間 (RTO) を設定します。 また、時間の関数として許容されるデータ損失の量を定義する、目標復旧時点 (RPO) も定義する必要があります。 たとえば、会社の RPO が 1 日である場合は、毎日 1 回はすべてのデータのバックアップを作成する必要があります。 また、このバックアップの復元にかかる時間が必ず 1 日未満になるようにする必要もあります。
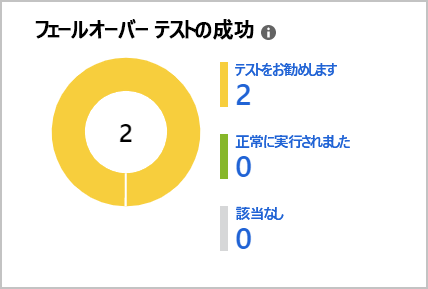
DR テストを確実に実行するために、Site Recovery では、Site Recovery ダッシュボード上でテストの実行が促されます。
DR 訓練の実行が必要な理由
DR 訓練は、実装されているソリューションが事業継続とディザスター リカバリー (BCDR) の要件を満たしていることを確認し、レプリケーションが適切に機能することを確認するために不可欠です。 RTO と RPO を組み合わせて、レプリケーション、フェールオーバー、復旧が必要な時間枠内に行われるように DR 訓練を十分にテストする必要があります。
たとえば、RTO が 1 時間、RPO が 6 時間であるとします。 システムは 1 時間ごとにバックアップされ、このデータ損失の 1 時間に、システムを復旧するための時間が追加されます。
実際の復旧時間が 5 時間であると仮定します。 システムの古さはもう少しで 6 時間を上回ります。これは、BCDR RPO 目標に違反することを意味します。 障害からの復旧にかかる実際の時間をテストすることで、システムが BCDR プランに従っているという自信が得られます。
個々のマシンのテスト フェールオーバー
フェールオーバー テストを使って、障害をシミュレートし、その影響を確認することができます。 フェールオーバー テストは、Site Recovery ダッシュボードから開始するか、特定の VM のディザスター リカバリー メニューから直接起動できます。 最初に、復旧ポイントを選択します。 最後に処理されたポイント、最新のアプリ整合性ポイント、カスタム復旧ポイントのいずれかから選択できます。
フェールオーバー テストを作成する
ここでは、運用インフラストラクチャが影響を受けないように、分離した仮想ネットワークを作成します。 これを行うには、次の手順に従います。
patient-records という名前のターゲット VM を開きます。 これを見つける簡単な方法は、すべてのリソースをフィルター処理して、種類 == 仮想マシンのみを表示する方法です。 結果リストから patient-records を選択します。
リソース メニューの [操作] までスクロールし、[ディザスター リカバリー] を選択します。
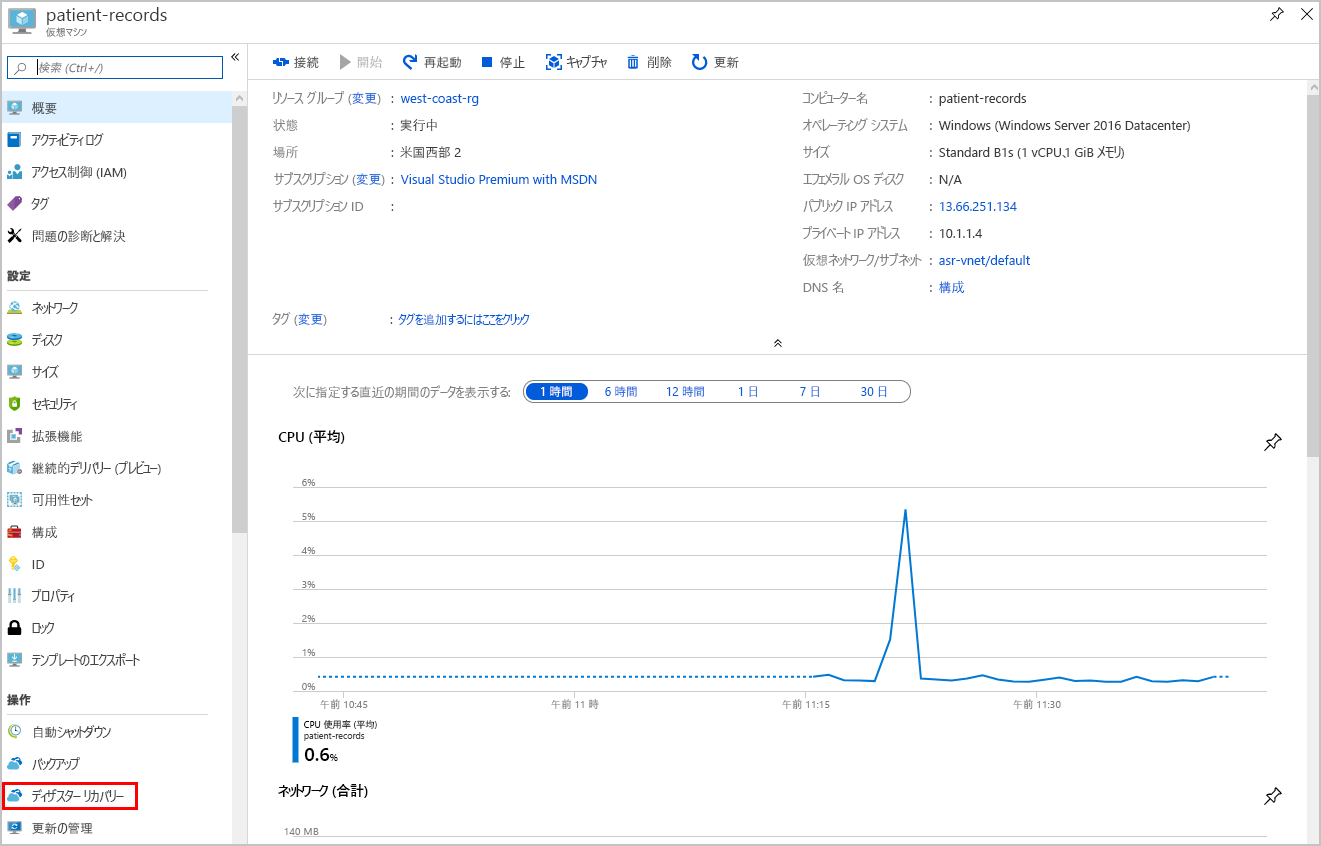
新しい [レプリケートされたアイテム] ウィンドウが開きます。 [状態] フィールドに [保護済み] が表示されるまで、[最新の情報に更新] を選択します。 その後、上部のメニュー バーで [テスト フェールオーバー] を選択します。

検証が成功したら、[Azure 仮想ネットワーク] ドロップダウンで仮想ネットワークを選び、[テスト フェールオーバー] ボタンを選びます。 このオプションを選ぶと、VM のテスト フェールオーバーが実行されます。また、[通知] アイコンを選び、[Starting the task to perform test failover of virtual machine] (仮想マシンのテスト フェールオーバーを実行するタスクの開始) リンクを選ぶことで、Site Recovery ジョブ ページでその進行状況を追跡できます。
完了すると、フェールオーバーされた VM が、ポータルの Virtual Machines の下の復旧リージョンに表示されます。 そこで、VM が実行中で、サイズと接続が正しく、ソース VM をミラーリングしているが、別の Azure リージョンにあることを確認できます。
すべてが想定どおりに動作していることを検証したら、[ディザスター リカバリー] ペインから [テスト フェールオーバーのクリーンアップ] を選んで、レプリケートされた VM を削除できます。 この時点で、テスト結果に関するメモを追加することをお勧めします。 [テストが完了しました] の横のチェック ボックスをオンにしてテスト フェールオーバー仮想マシンを削除してから、[OK] を選びます。


複数のマシンの柔軟なフェールオーバー
Site Recovery により、すべての VM に対して完全な DR テスト シナリオを実行する柔軟性が得られます。 1 台以上の VM を含めた復旧計画を作成できます。 フェールオーバーは何回でも実行でき、柔軟なポリシーでインフラストラクチャのさまざまな組み合わせをテストできます。

単一の VM をテストするのと同様に、復旧計画に含まれるすべてに対して同じテスト クリーンアップを使用できます。

訓練と運用フェールオーバーの違い
Site Recovery での運用フェールオーバーの実行は、テスト訓練の実行に似ています。 いくつか例外があります。第 1 は、[テスト フェールオーバー] ではなく、[フェールオーバー] が選択されていることです。 切り替え中にデータが失われないように、フェールオーバーを開始する前にソース VM のシャットダウンを選択できます。 フェールオーバーが完了すると、Site Recovery ではソース環境をクリーンアップしません。
フェールオーバーが完了したら、VM が想定どおりに動作していることを確認します。 Site Recovery では、この段階で復旧ポイントを変更できます。 フェールオーバーが正常に行われたら、フェールオーバーをコミットします。 Site Recovery によって、ソース VM のすべての復旧ポイントが削除され、フェールオーバーが完了します。 レプリケートされたインフラストラクチャとデータがセカンダリ リージョンにあり、セカンダリ リージョンの新しい VM も保護が必要であることに注意する必要があります。