販売総数が異なる箇所を見つけるために Power BI に分析情報を適用する
適用対象:![]() Power BI Desktop
Power BI Desktop ![]() Power BI サービス
Power BI サービス
視覚化でデータ ポイントを見るとき、異なるカテゴリに対して販売総数が同じになるか気になることがあります。 Power BI の分析情報を利用すれば、数回のクリックでわかります。
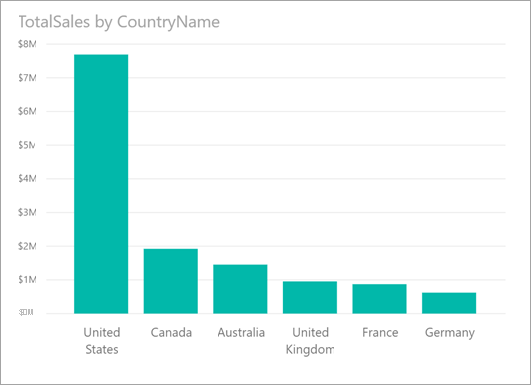
CountryName 別の TotalSales が表示された次の視覚化について考えてみましょう。 売り上げのほとんどは米国からであり、売り上げ全体の 57% を占めています。その他の国/地域からの売り上げは米国より少なくなっています。 このような例では、異なる部分母集団でも販売総数が同じかどうかを調べてみると興味深いことがよくあります。 たとえば、この結果は毎年同じでしょうか。全販売経路で同じでしょうか。製品の全カテゴリで同じでしょうか。 さまざまなフィルターを適用し、結果を視覚的に比べてみることはできますが、その方法では時間がかかり、間違いが起こりやすくなります。
販売総数の異なる箇所を見つけるように Power BI に指示すれば、データを自動分析し、短時間で洞察力のある情報が得られます。 データ ポイントを右クリックし、[分析]>[販売総数が異なる箇所を見つける] の順に選択します。使いやすいウィンドウに分析情報が表示されます。
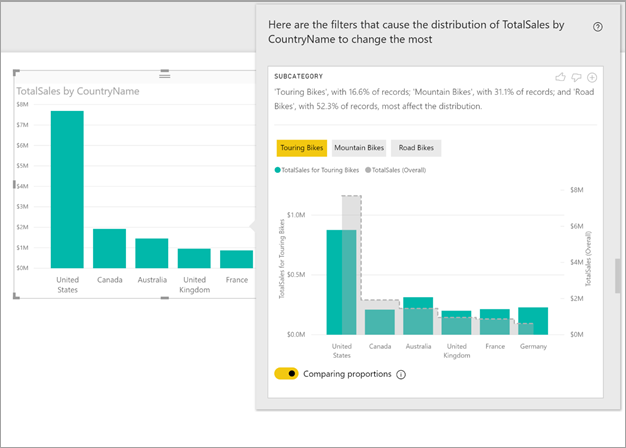
この例の自動分析では、Touring Bikes の売り上げに占める米国とカナダの割合は、その他の国や地域の割合よりも低いことを確認できます。
分析情報を使用する
分析情報を利用してグラフ上の販売総数が異なる箇所を見つけるには、データ ポイントまたは視覚化全体を右クリックします。 次に、[分析]>[販売総数が異なる箇所を見つける] の順に選択します。
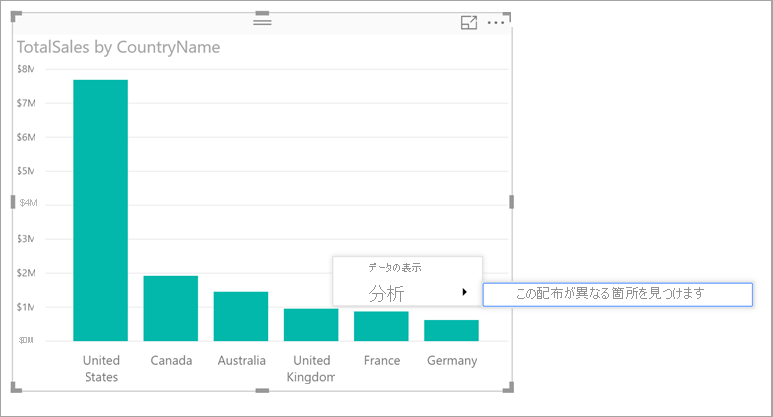
Power BI は、データに対して機械学習アルゴリズムを実行します。 次に、どのカテゴリ (縦棒) とそのカテゴリのどの値が、最も大きく異なる販売総数になっているかを示す視覚化と説明をウィンドウに表示します。 次の画像のように、分析情報は縦棒グラフとして提供されます。

選択したフィルターが適用された値は、既定の色で表示されます。 最初のビジュアルにあった値が端から端までグレーで表示されるので簡単に比較できます。 最大 3 つの異なるフィルターを含めることができます (この例では、Touring Bikes、Mountain Bikes、Road Bikes)。異なるフィルターを選択するには、データ ポイントを選択するか、Ctrl キーを押しながらクリックして複数を選択します。
この例の売上合計のように単純な加法測度の場合、比較は絶対値ではなく相対値に基づきます。 Touring Bikes の売上は全カテゴリの総売上よりも低いですが、視覚化では既定で 2 つの軸が使用されるため、異なる国や地域別で売上に占める割合を比較できます。 ここでは、Touring Bikes と全カテゴリの自転車です。 次の画像に示すように、視覚化の下にあるトグルを切り替えると、同じ軸に 2 つの値が表示され、簡単に絶対値を比較できます。
説明テキストからは、フィルターに一致するレコードの数により重要性の度合いも示されます。この度合いはフィルター値に付けられることがあります。 この例では、Touring Bikes の販売総数は異なっているかもしれませんが、レコードに占める割合は 16.6% に過ぎません。
ページの上部にある "上向き親指" と "下向き親指" のアイコンを使うと、視覚化と機能に関するフィードバックを送ることができます。 ただし、それを行っても、アルゴリズムがトレーニングされて次回この機能を使用したときに返される結果に影響が出るわけではありません。
さらに重要なのがビジュアルの上部にある + ボタンです。これを使用すれば、ビジュアルを手動で作成した場合と同じように、レポートに選択したビジュアルを追加できます。 その後、レポートの他の視覚化と同じように、追加した視覚化を書式設定したり、調整したりすることができます。 選択したインサイト ビジュアルを追加できるのは、Power BI でレポートを編集する場合のみです。
分析情報は、レポートが読み取りモードのときも編集モードのときも使用できます。 これにより、データを分析する場合と、レポートに追加できる視覚化を作成する場合の両方で使用できます。
返される結果の詳細
このアルゴリズムは次のように考えることができます。まず、モデル内の他のすべての縦棒を取り、それらの縦棒のすべての値について、それらをフィルターとして元の視覚化に適用します。 アルゴリズムは次に、それらのフィルター値のうちで、元の視覚化とは最も "異なる" 結果を生み出すものを見つけます。
"異なる" がどのような意味か疑問に思われるかもしれません。 たとえば、米国とカナダでは売上が全体的に次のように分かれるとします。
| 国/リージョン | 売上 ($M) |
|---|---|
| 米国 | 15 |
| Canada | 5 |
これに対し、"Road Bike" という特定の製品カテゴリの売上は次のように分かれます。
| 国/リージョン | 売上 ($M) |
|---|---|
| 米国 | 3 |
| Canada | 1 |
それぞれの表で数字は異なりますが、米国とカナダの間の相対値は同じです。つまり、全体の場合も Road Bikes の場合も、75% と 25% です。 したがって、これらは異なるとは見なされません。 このような単純な加法測度の場合、このアルゴリズムでは "相対" 値の相違が求められます。
対照的に、利益を原価で割り算して求められる "利益率" のような測度について考えてみます。 米国とカナダの全体的な利益率は次のようになるとします。
| 国/リージョン | 利益率 (%) |
|---|---|
| 米国 | 15 |
| Canada | 5 |
これに対し、"Road Bike" という特定の製品カテゴリの売上は次のように分かれます。
| 国/リージョン | 利益率 (%) |
|---|---|
| 米国 | 3 |
| Canada | 1 |
このような測度の性質からすると、興味深いことにこれは "異なっています"。 この利益率の例のような非加法的測度の場合、このアルゴリズムでは絶対値の相違が求められます。
そのため、表示される視覚化の意図は、元の視覚化で見られたような全体的な販売総数と、特定のフィルターが適用された値の間にある相違を示すことです。
前の例にあった Sales のような加法測度の場合、縦棒グラフと折れ線グラフが使用されます。 そこでは、2 つの軸と適切なスケーリングを使用して、相対値を比較できるようにします。 縦棒ではフィルターが適用された値が示され、折れ線では全体値が示されます。 通常、縦棒の軸が左に、折れ線の軸が右に表示されます。 横棒は、破線を使用し、灰色で塗りつぶされた "階段状" のスタイルを使用して表示されます。 前の例では、縦棒軸の最大値が 4 であり、横棒軸の最大値が 20 である場合、フィルター処理された値と全体の値について、米国とカナダの相対値を簡単に比較することができます。
同様に、前の例の利益率のような非加法的測度の場合、縦棒グラフと折れ線グラフが使用され、1 つの軸を使用して絶対値を簡単に比較できます。 グレーで塗られた折れ線は、全体値を示します。 実際の値を比較する場合でも、相対値を比較する場合でも、値の差異を計算するだけでは、2 つの販売総数の違いの程度を判断することはできません。 次に例を示します。
母集団の規模を要因として考慮する場合、母集団全体のより小さい部分に適用すると、違いの統計的な有意性は低くなり、重要度は低くなります。 たとえば、特定の製品について、国や地域によって販売総数が異なるかもしれません。 製品が何千種類とあり、その特定の製品が全体的な売上に占める割合が微々たるものであれば、それは重要ではありません。
元の値が高いかゼロに近いカテゴリの差異には、他のカテゴリより高い重み付けが与えられます。 たとえば、ある国または地域が売上全体の 1% にしか貢献していなくても、特定の種類の製品で 6% 貢献している場合は、貢献度が 50% から 55% に変化した国または地域よりも統計的に有意であり、重要度も高くなります。
さまざまなヒューリスティックスによって (たとえば、データ間のその他の関係を考慮することで)、最も意味のある結果が選択されます。
さまざまな縦棒と各縦棒の値を調べた後、最も大きな違いを生み出す値のセットが選択されます。 理解しやすいように、それらは縦棒別に出力およびグループ化され、最も大きな違いを生み出す値を含む列が一覧の最初に表示されます。 縦棒ごとに最大 3 つの値が表示されますが、効果が大きな値が 3 つより少なければ、あるいはある値のインパクトが他の値よりはるかに高ければ、3 つより少なく表示されることがあります。
限られた時間では、モデル内の縦棒がすべて調べられるとは限りません。そのため、影響が最も大きい縦棒と値が表示される保証はありません。 しかし、さまざまなヒューリスティックスによって、最も可能性の高い縦棒が最初に調べられます。 たとえば、縦棒をすべて調べた後、次の縦棒および値が販売総数において最も影響が大きいと判断されたとします (影響の大きい順)。
Subcategory = Touring Bikes
Channel = Direct
Subcategory = Mountain Bikes
Subcategory = Road Bikes
Subcategory = Kids Bikes
Channel = Store
この場合、縦棒の順序で次のように出力されます。
Subcategory:Touring Bikes, Mountain Bikes, Road Bikes (only three listed, with the text including “...amongst others” to indicate that more than three have a significant impact)
Channel = Direct (影響のレベルが Store よりも大きい場合は、Direct のみが表示されます)
考慮事項と制限事項
インサイトで現在サポートされていないシナリオには、次のようなものがあります。
- 上位 N フィルター
- メジャー フィルター
- 数値以外のメジャー
- "値の表示方法" の使用
- フィルターが適用されたメジャー – フィルターが適用されたメジャーとは、特定のフィルター (たとえば Total Sales for France など) が適用された視覚化レベルの計算結果であり、分析情報機能によって作成された一部の視覚化で使用されます
さらに、次のモデルの種類とデータ ソースは現在、インサイトではサポートされていません。
- DirectQuery
- ライブ接続
- オンプレミスの Reporting Services
- 埋め込み
関連するコンテンツ
詳細については、以下を参照してください: