Power Query クエリの参照
この記事は、Power BI Desktop を操作するデータ モデラーを対象としています。 他のクエリを参照する Power Query クエリを定義する際のガイダンスを示します。
次の文が何を意味してるかを十分に理解しましょう。"あるクエリで 2 つ目のクエリが参照されるとき、2 つ目のクエリの手順は最初のクエリと結合されているかのように扱われ、最初のクエリの手順が実行される前に実行されます。 "
いくつかのクエリを検討します。Query1 のデータ ソースは Web サービスであり、その読み込みは無効にななっています。 Query2、Query3、Query4 は、すべて Query1 を参照しており、それらの出力がデータ モデルに読み込まれます。
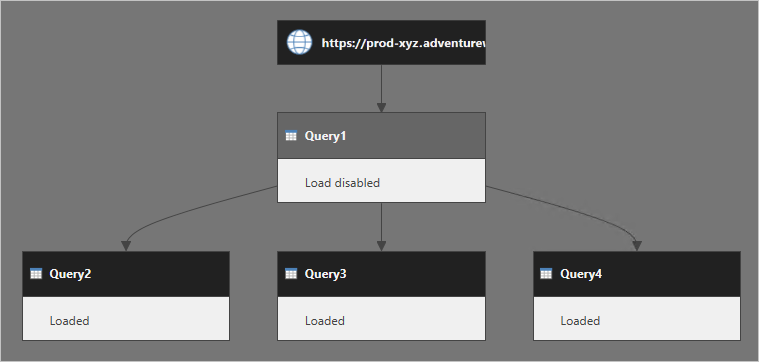
このデータ モデルが更新されるとき、Power Query によって Query1 の結果が取得され、それを参照しているクエリで再利用されるものと思うことがよくあります。 この考え方は正しくありません。 実際には、Power Query では、Query2、Query3、および Query4 は個別に実行されます。
Query2 には、Query1 の手順が埋め込まれていると考えることができます。 同じことが、Query3 と Query4 にも当てはまります。 次の図は、クエリがどのように実行されるかをより明確に示しています。
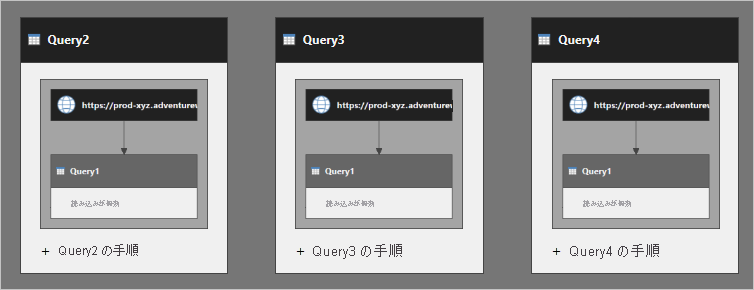
Query1 は 3 回実行されます。 複数回実行されるためデータ更新が低速になり、データ ソースに悪影響を及ぼす可能性があります。
Query1 で Table.Buffer 関数を使用しても、追加のデータ取得が排除されることはありません。 この関数はテーブルをメモリにバッファー処理しますが、このバッファー処理されたテーブルは同じクエリ実行内でのみ使用できます。 したがって、この例では、Query2 の実行時に Query1 がバッファー処理された場合でも、Query3 と Query4 の実行時にバッファー処理されたデータを使用することはできません。 それぞれでバッファー処理が実行されるため、データはさらに 2 回バッファー処理されます。 (テーブルが参照元のクエリによって個別にバッファー処理されるため、パフォーマンスへの悪影響が増加する可能性があります)。
注意
Power Query のキャッシュ アーキテクチャは複雑であり、それはこの記事の焦点ではありません。 Power Query では、データ ソースから取得したデータをキャッシュできます。 ただし、クエリの実行時に、データ ソースからデータを複数回取得する場合があります。
推奨事項
通常は、クエリ間でのロジックの重複を回避するようにクエリを参照することが推奨されています。 ただし、この記事で説明したように、この設計方法では、データ更新の速度が低下し、データ ソースに過度の負荷がかかる可能性があります。
代わりに、データフローを作成することをお勧めします。 データフローを使用すると、データ更新時間が短縮され、データ ソースへの影響が軽減されます。
ソース データと変換をカプセル化するようにデータフローを設計できます。 データフローは Power BI サービス内に保持されるデータ ストアであるため、データは高速で取得されます。 そのため、クエリの参照でデータフローに対する要求が複数回発生した場合でも、データ更新時間を短縮することができます。
この例では、Query1 をデータフロー エンティティとして再設計すれば、Query2、Query3、および Query4 でそれをデータ ソースとして使用できます。 この設計では、Query1 をソースとするエンティティの評価は、1 回だけ実行されます。
関連するコンテンツ
この記事に関する詳細については、次のリソースを参照してください。
- Power BI でのセルフサービスのデータ準備
- Power BI でのデータフローの作成と使用
- わからないことがある場合は、 Power BI コミュニティで質問してみてください。
- Power BI チームへのご提案は、 Power BI を改善するためのアイデアをお寄せください
フィードバック
以下は間もなく提供いたします。2024 年を通じて、コンテンツのフィードバック メカニズムとして GitHub の issue を段階的に廃止し、新しいフィードバック システムに置き換えます。 詳細については、「https://aka.ms/ContentUserFeedback」を参照してください。
フィードバックの送信と表示