Microsoft SQL Server プラットフォームのビッグ データ オプション
適用対象:![]() SQL Server 2019 (15.x) 以降のバージョン
SQL Server 2019 (15.x) 以降のバージョン
Microsoft SQL Server 2019 ビッグ クラスターは、Kubernetes 上で実行される SQL Server、Spark、HDFS コンテナーのスケーラブルなクラスターをデプロイできる SQL Server プラットフォーム用のアドオンです。 これらのコンポーネントを並行して実行し、Transact-SQL または Spark ライブラリを使ってビッグ データの読み取り、書き込み、処理を行うことができるので、高価値のリレーショナル データと大量の非リレーショナル ビッグ データを簡単に組み合わせて分析できます。 ビッグ データ クラスターでは、PolyBase を使用してデータを仮想化することもできるため、外部テーブルを使って外部の SQL Server、Oracle、Teradata、MongoDB などのデータ ソースからデータを照会することができます。 Microsoft SQL Server 2019 ビッグ クラスター アドオンでは、Always On 可用性グループ テクノロジを使用して、SQL Server マスター インスタンスとすべてのデータベースの高可用性が提供されます。
SQL Server 2019 ビッグ データ クラスター アドオンは、任意の Kubernetes の標準的なデプロイに対して、Kubernetes プラットフォームを使用しているオンプレミスとクラウドで実行されます。 また、SQL Server 2019 ビッグ データ クラスター アドオンは Active Directory と統合され、企業のセキュリティとコンプライアンスのニーズを満たすためのロールベースのアクセス制御が含まれます。
SQL Server 2019 ビッグ データ クラスター アドオンの廃止
2025 年 2 月 28 日に SQL Server 2019 ビッグ データ クラスターは廃止されます。 ソフトウェア アシュアランス付きの SQL Server 2019 を使用する既存の全ユーザーはプラットフォームで完全にサポートされ、ソフトウェアはその時点まで SQL Server の累積更新プログラムによって引き続きメンテナンスされます。 詳細については、お知らせブログ記事をご覧ください。
SQL Server の PolyBase サポートの変更点
SQL Server 2019 ビッグ データ クラスターの廃止に関連するものとして、スケールアウト クエリに関するいくつかの機能があります。
Microsoft SQL Server の PolyBase スケールアウト グループ機能は廃止されました。 SQL Server 2022 (16.x) では、スケールアウト グループ機能が製品から削除されます。 SQL Server 2019、SQL Server 2017、SQL Server 2016 の現在市場にあるバージョンでは、それらの製品のサポートが終了するまで、引き続きこの機能はサポートされます。 PolyBase データ仮想化は、SQL Server のスケールアップ機能として引き続き完全にサポートされます。
Cloudera (CDP) と Hortonworks (HDP) Hadoop の外部データ ソースも、SQL Server の市場にある全バージョンで廃止され、SQL Server 2022 には含まれません。 外部データ ソースのサポートは、各ベンダーによるメインストリーム サポート対象の製品バージョンに限定されます。 SQL Server 2022 (16.x) で利用できる新しいオブジェクト ストレージ統合を使用することをお勧めします。
SQL Server 2022 (16.x) 以降のバージョンでは、ユーザーが外部データ ソースを構成して、Azure Storage に接続するときに新しいコネクタを使うようにする必要があります。 次の表は、その変更をまとめたものです。
| 外部データ ソース | ソース | 終了 |
|---|---|---|
| Azure Blob Storage | wasb[s] |
abs |
| ADLS Gen 2 | abfs[s] |
adls |
注意
Azure Blob Storage (abs) では、データベース スコープの資格情報で SECRET の Shared Access Signature (SAS) を使う必要があります。 SQL Server 2019 以前では、wasb[s] コネクタは、Azure Storage アカウントに対する認証時に、データベース スコープの資格情報と共にストレージ アカウント キーを使っていました。
ビッグ データ クラスター アーキテクチャの置換と移行オプションの概要
ビッグ データ ストレージおよび処理システムの代替ソリューションを作成するには、SQL Server 2019 ビッグ データ クラスターで提供される内容を把握することが重要です。また、そのアーキテクチャが選択に役立つ場合があります。 ビッグ データ クラスターのアーキテクチャは次のようになります。

このアーキテクチャでは、次のような機能のマッピングが提供されます。
| コンポーネント | 特長 |
|---|---|
| Kubernetes | 大規模なコンテナーベースのアプリケーションをデプロイおよび管理するためのオープンソース オーケストレーター。 エラスティック スケールを使用して環境全体の回復性、冗長性、移植性を作成および制御するための、宣言型の方法を提供します。 |
| ビッグ データ クラスター コントローラー | クラスターの管理とセキュリティを提供します。 これには、制御サービス、構成ストア、および Kibana、Grafana、Elasticsearch などのその他のクラスターレベルサービスが含まれています。 |
| コンピューティング プール | クラスターにコンピューティング リソースを提供します。 これには SQL Server on Linux ポッドを実行するノードが含まれます。 コンピューティング プール内のポッドは、特定の処理タスクのために SQL コンピューティング インスタンスに分割されます。 また、このコンポーネントでは PolyBase を使用したデータ仮想化も提供され、データを移動またはコピーせずに外部データ ソースに対してクエリを実行できます。 |
| データ プール | クラスターのデータの永続化を提供します。 データ プールは、SQL Server on Linux を実行している 1 つ以上のポッドで構成されます。 これは、SQL クエリまたは Spark ジョブからデータを取り込むために使用されます。 |
| 記憶域プール | 記憶域プールは、SQL Server on Linux、Spark、および HDFS で構成される記憶域プール ポッドで構成されます。 ビッグ データ クラスター内のすべての記憶域ノードは、HDFS クラスターのメンバーです。 |
| アプリケーション プール | アプリケーションを作成、管理、実行するためのインターフェイスを提供することにより、ビッグ データ クラスターへのアプリケーションの展開を実現します。 |
これらの機能の詳細については、「SQL Server ビッグ データ クラスターの紹介 」を参照してください。
ビッグ データと SQL Server の機能置換オプション
ビッグ データ クラスター内の SQL Server によって促進される "オペレーショナル" データ機能は、ハイブリッド構成のオンプレミス SQL Server によって、または Microsoft Azure プラットフォームを使って置き換えることができます。 Microsoft Azure では、最新のアプリ開発者のニーズに合わせて、フル マネージド リレーショナル、NoSQL、メモリ内の各データベースを、専用、オープンソースのエンジンにわたって選択できます。 インフラストラクチャの管理 (スケーラビリティ、可用性、セキュリティなど) は自動化され、時間とコストを節約できます。また、Azure マネージド データベースによる埋め込みインテリジェンスを使ったパフォーマンス分析情報の表示、制限なしのスケーリング、セキュリティ上の脅威の管理によって業務が簡素化され、アプリケーションの構築に集中できます。 詳細については、Azure データベースに関するページを参照してください。
次の意思決定ポイントは、"分析" 用のコンピューティングとデータ ストレージの場所です。 クラウド デプロイとハイブリッド デプロイという 2 つのアーキテクチャの選択肢があります。 ほとんどの分析ワークロードは、Microsoft Azure プラットフォームに移行できます。 "クラウド内で生まれた" (クラウドベースのアプリケーションで生成された) データがこれらのテクノロジを適用する有力候補であり、データ移動サービスでは大規模なオンプレミスのデータを安全かつ迅速に移行できます。 データ移動オプションの詳細については、データ転送ソリューションに関する記事を参照してください。
Microsoft Azure には、さまざまなツールで安全なデータとデータ処理を可能にするシステムと認定があります。 これらの認定の詳細については、トラスト センターを参照してください。
注意
Microsoft Azure プラットフォームでは、非常に高いレベルのセキュリティ、各種業界に向けた複数の認定が提供され、政府要件のデータ主権が尊重されます。 Microsoft Azure には、政府ワークロード専用のクラウド プラットフォームもあります。 セキュリティのみを、オンプレミスのシステムの主要な意思決定ポイントにすべきではありません。 オンプレミスでビッグ データ ソリューションを保持することを決定する前に、Microsoft Azure によって提供されるセキュリティのレベルを慎重に評価する必要があります。
クラウド内アーキテクチャ オプションでは、すべてのコンポーネントが Microsoft Azure 内に存在します。 お客様の責任は、ワークロードの格納と処理のために作成するデータとコードにあります。 これらのオプションについては、この記事で詳しく説明します。
- このオプションは、データの格納と処理のためのさまざまなコンポーネントや、インフラストラクチャではなくデータと処理の構造に専念したい場合に最適です。
ハイブリッド アーキテクチャ オプションでは、一部のコンポーネントがオンプレミスで保持され、その他のコンポーネントはクラウド プロバイダーに配置されます。 これら 2 つの間の接続は、データに対する処理の最適な配置を目的として設計されています。
- このオプションは、オンプレミスのテクノロジとアーキテクチャに多くの投資をしていても Microsoft Azure のオファリングを使いたい場合や、処理、アプリケーションいずれかのターゲットがオンプレミスにあるか、世界中のユーザーに向けられている場合に最適です。
スケーラブルなアーキテクチャを構築する方法の詳細については、「大規模データ用のスケーラブルなシステムを構築する」を参照してください。
クラウド内
Azure SQL と Synapse
オペレーショナル データに対して 1 つ以上の Azure SQL データベース オプションを使用し、分析ワークロードに対して Microsoft Azure Synapse を使用することで、SQL Server ビッグ データ クラスターの機能を置き換えられます。
Microsoft Azure Synapse は、分散処理とデータの構造を使って、データ ウェアハウスやビッグ データ システム全体にわたって分析情報を取得する時間を早めるエンタープライズ分析サービスです。 Azure Synapse では、エンタープライズ データ ウェアハウスで使用される SQL テクノロジ、ビッグ データに使用される Spark テクノロジ、データ統合と ETL および ELT のためのパイプライン、Power BI、Cosmos DB、Azure Machine Learning などの他の Azure サービスとの緊密な統合が 1 つにまとめられています。
次のことを行う必要がある場合は、SQL Server 2019 ビッグ データ クラスターの代わりとして Microsoft Azure Synapse を使用してください。
- サーバーレスと専用の両方のリソース モデルを使う。 予測可能なパフォーマンスとコストに対しては、専用 SQL プールを作成して、SQL テーブルに格納されているデータの処理能力を確保します。
- 計画外または "バースト" ワークロードを処理し、常に使用可能なサーバーレス SQL エンドポイントにアクセスする。
- 組み込みのストリーミング機能を使用して、クラウド データ ソースから SQL テーブルにデータを取り込む。
- 機械学習モデルを使い、T-SQL PREDICT 関数を使ってデータをスコア付けすることにより、AI を SQL と統合する。
- SparkML アルゴリズムを使った ML モデルと、Linux Foundation Delta Lake でサポートされる Apache Spark 2.4 用の Azure Machine Learning 統合を使う。
- クラスターの管理について心配する必要がなくなる、簡素化されたリソース モデルを使用する。
- Spark の迅速な起動と積極的な自動スケーリングを必要とするデータを処理する。
- .NET for Spark を使ってデータを処理し、C# の専門知識と既存の .NET コードを Spark アプリケーション内で再利用できるようにする。
- データ レイク内のファイルで定義された、Spark または Hive でシームレスに使用できるテーブルを操作する。
- SQL と Spark を使用して、データ レイクに保存されている Parquet、CSV、TSV、JSON ファイルを直接探索して分析する。
- SQL データベースと Spark データベース間の高速かつスケーラブルなデータ読み込みを実現する。
- 90 以上のデータ ソースからデータを取り込む。
- データ フロー アクティビティを使用した "コーディング不要の" ETL を実現する。
- ノートブック、Spark ジョブ、ストアド プロシージャ、SQL スクリプトなどを調整する。
- SQL と Spark 全体のリソース、使用状況、ユーザーを監視する。
- ロールベースのアクセス制御を使用して分析リソースへのアクセスを単純化する。
- SQL または Spark コードを記述し、エンタープライズ CI/CD プロセスと統合する。
Microsoft Azure Synapse のアーキテクチャは次のようになります。

Microsoft Azure Synapse の詳細については、「Azure Synapse Analytics とは」を参照してください。
Azure SQL と Azure Machine Learning
オペレーショナル データに対して 1 つ以上の Azure SQL データベース オプションを使用し、予測ワークロードに対して Microsoft Azure Machine Learning を使用することで、SQL Server ビッグ データ クラスターの機能を置き換えられます。
Azure Machine Learning は、従来の ML からディープ ラーニング、教師あり学習と教師なし学習まで、あらゆる種類の機械学習に使用できるクラウドベースのサービスです。 SDK を使用して Python または R のコードを記述するか、または Studio でのコード不要 (またはローコード) オプションを使用するかにかかわらず、Azure Machine Learning ワークスペースで機械学習およびディープ ラーニング モデルを構築、トレーニング、追跡できます。 Azure Machine Learning を使用すると、ローカル コンピューターでトレーニングを開始してから、クラウドにスケールアウトすることができます。 また、このサービスは、PyTorch、TensorFlow、scikit-learn、Ray RLlib など、ディープ ラーニングや強化のための一般的なオープン ソース ツールと連携します。
次のことが必要な場合は、SQL Server 2019 ビッグ データ クラスターの代わりとして Microsoft Azure Machine Learning を使用してください。
- Machine Learning 用のデザイナーベースの Web 環境: モジュールをドラッグ アンド ドロップして実験を構築し、ローコード環境でパイプラインをデプロイする。
- Jupyter Notebook: サンプル ノートブックを使うか、独自のノートブックを作成して、SDK for Python のサンプルを機械学習に使います。
- R スクリプトまたはノートブックで、SDK for R を使用して独自のコードを記述したり、デザイナーで R モジュールを使用したりする。
- 多数モデル ソリューション アクセラレータは Azure Machine Learning 上に構築されており、数百または数千もの機械学習モデルをトレーニング、操作、管理できます。
- Visual Studio Code 用の Machine Learning 拡張機能 (プレビュー) は、機械学習プロジェクトの構築と管理を目的としたフル機能の開発環境を提供します。
- Machine learning コマンド ライン インターフェイス (CLI)。Azure Machine Learning には、Azure Machine Learning リソースをコマンド ラインから管理するためのコマンドを備えた Azure CLI 拡張機能が含まれています。
- PyTorch、TensorFlow、scikit-learn など、エンド ツー エンドの機械学習プロセスのトレーニング、デプロイ、管理を目的としたさまざまなオープンソース フレームワークとの統合。
- Ray RLlib を使用した強化学習。
- MLflow を使用してメトリックを追跡し、モデルをデプロイしたり Kubeflow を使用したりして、エンドツーエンドのワークフロー パイプラインを構築する。
Microsoft Azure Machine Learning デプロイのアーキテクチャは次のようになります。

Microsoft Azure Machine Learning の詳細については、Azure Machine Learning のしくみに関する記事を参照してください。
Databricks からの Azure SQL
オペレーショナル データに対して 1 つ以上の Azure SQL データベース オプションを使用し、分析ワークロードに対して Microsoft Azure Databricks を使用することで、SQL Server ビッグ データ クラスターの機能を置き換えられます。
Azure Databricks は、Microsoft Azure クラウド サービス プラットフォーム用に最適化された Data Analytics プラットフォームです。 Azure Databricks により、データ集中型アプリケーションを開発するための次の 2 つの環境が提供されます: Azure Databricks SQL Analytics と Azure Databricks ワークスペース。
Azure Databricks SQL Analytics によって、データ レイクで SQL クエリを実行したり、複数の視覚化の種類を作成してさまざまなパースペクティブからクエリ結果を探索したり、ダッシュボードを構築して共有したりするための、使いやすいプラットフォームが提供されます。
Azure Databricks ワークスペースには、データ エンジニア、データ サイエンティスト、機械学習エンジニアの間のコラボレーションを可能にする対話的なワークスペースが用意されています。 ビッグ データ パイプラインに使用されるデータ (生データまたは構造化データ) は、Azure Data Factory を介してバッチで Azure に取り込まれるか、Apache Kafka、Event Hubs、または IoT Hub を使って凖リアルタイムでストリーム配信されます。 このデータは、長期永続保管を目的としたデータ レイク (Azure Blob Storage または Azure Data Lake Storage) に到達します。 分析ワークフローの一環として、Azure Databricks を使用して複数のデータソースからデータを読み取り、それを Spark を使用して画期的な分析情報へと変えることができます。
次のことが必要な場合は、SQL Server 2019 ビッグ データ クラスターの代わりとして Microsoft Azure Databricks を使用してください。
- Spark SQL と DataFrames を使用したフル マネージド Spark クラスター。
- リアルタイム データ処理のためのストリーミングと分析および対話型アプリケーションのための分析、HDFS、Flume、Kafka との統合。
- 分類、回帰、クラスタリング、協調フィルタリング、次元縮小、基になっている最適化プリミティブなど、一般的な学習アルゴリズムとユーティリティで構成された MLlib ライブラリへのアクセス。
- R、Python、Scala、または SQL のノートブックで進行状況を文書化する。
- Matplotlib、ggplot、d3 などの使い慣れたツールを使い、数回の手順でデータを視覚化する。
- 動的なレポートを作成する対話型ダッシュボード。
- 認知分析からデータ探索まで、さまざまなユース ケースを対象とするグラフおよびグラフ計算のための、GraphX。
- 動的自動スケーリング クラスターを使用して数秒でクラスターを作成し、チーム間で共有する。
- REST API を使用したプログラムによるクラスター アクセス。
- リリースごとの最新の Apache Spark 機能にすぐにアクセスする。
- Spark Core API: R、SQL、Python、Scala、Java のサポートを含みます。
- 探索および視覚化のための対話型ワークスペース。
- クラウド内のフル マネージド SQL エンドポイント。
- クエリの待機時間と同時ユーザーの数に応じてサイジングされた、フル マネージド SQL エンドポイントで実行される SQL クエリ。
- Microsoft Entra ID (旧称 Azure Active Directory) との統合。
- ノートブック、クラスター、ジョブ、データに対してきめ細かいユーザー アクセス許可を設定するためのロール ベースのアクセス。
- エンタープライズ グレードの SLA です。
- 分析情報を共有するためのダッシュボード。視覚化とテキストを組み合わせて、クエリから抽出された分析情報を共有します。
- アラートは、クエリによって返されたフィールドがしきい値を満たす場合の監視、統合、および通知に役立ちます。 アラートは、ビジネスを監視するために使用したり、ユーザーのオンボードやサポート チケットなどのワークフローを開始するツールと統合したりします。
- Microsoft Entra ID の統合、ロール ベースの制御、データとビジネスを保護する SLA などを含む、エンタープライズ セキュリティ。
- Synapse Analytics、Cosmos DB、Data Lake Store、BLOB ストレージなどの Azure サービス、Azure データベースおよびストアとの統合。
- Power BI や他の BI ツール (Tableau Software など) との統合。
Microsoft Azure Databricks デプロイのアーキテクチャは次のようになります。
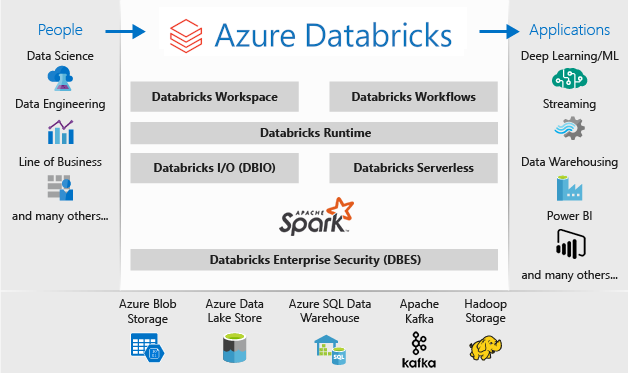
Microsoft Azure Databricks の詳細については、Databricks Data Science & Engineering の概要に関する記事を参照してください。
ハイブリッド
Fabric ミラー化データベース
データ レプリケーション エクスペリエンスとして、Fabric のデータベース ミラーリング (プレビュー) は、さまざまなシステムのデータを単一の分析プラットフォームにまとめる、低コストで低遅延のソリューションです。 Azure SQL データベース、Snowflake、Cosmos DB からのデータを含め、継続的に既存のデータ資産を Fabric の OneLake に直接レプリケートできます。
OneLake でクエリ可能な形式の最新データを使用して、Spark での分析の実行、ノートブックの実行、データ エンジニアリング、Power BI レポートによる視覚化など、Fabric のすべての異なるサービスを使用できるようになりました。
Fabric でのミラーリングを使用すると、分析情報と意思決定の価値実現までの時間を短縮し、コストのかかる抽出、変換、読み込み (ETL) プロセスを開発することなく、テクノロジ ソリューション間のデータ サイロを分割してデータを移動できます。
Fabric のミラーリングを使用すると、複数のベンダーの異なるサービスをまとめる必要はありません。 代わりに、分析ニーズを簡素化し、オープンソースの Delta Lake テーブル形式を読み取ることができるテクノロジ ソリューション間のオープン性とコラボレーションのために構築された、高度に統合された、エンドツーエンドで使いやすい製品を楽しむことができます。
詳細については、以下を参照してください:
- Microsoft Fabric ミラー化データベース (プレビュー)
- Microsoft Fabric ミラー化データベース監視
- Microsoft Fabric を使用してミラー化データベース内のデータを探索する
- Microsoft Fabric とは
- Microsoft Fabric で既定の Power BI セマンティック モデルのデータをモデル化する
- レイクハウスの SQL 分析エンドポイントとは
- Direct Lake
Azure Synapse Link for SQL と共に SQL Server 2022 を使う
SQL Server 2022 (16.x) には、SQL Server テーブルと Microsoft Azure Synapse プラットフォームの間の接続を可能にする、Azure Synapse Link for SQL という新しい機能が含まれています。 SQL Server 2022 (16.x) の Azure Synapse Link では、SQL Server 内の変更をキャプチャして Azure Synapse Analytics に読み込む、自動変更フィードが提供されます。 運用システムへの影響を最小限に抑えた、凖リアルタイムの分析とハイブリッドのトランザクションおよび分析処理が提供されます。 データが Synapse に入った後は、そのサイズ、スケール、または形式に関係なく、さまざまなデータ ソースと組み合わせて、Azure Machine Learning、Spark、または Power BI を使用してデータ全体に対して強力な分析を実行できます。 自動変更フィードによってプッシュされるのは新しいデータか異なるデータのみであり、データ転送がはるかに高速に実行され、凖リアルタイムの分析情報が可能になります。SQL Server 2022 (16.x) のソース データベースのパフォーマンスへの影響は最小限に抑えられます。
運用ワークロード、または分析ワークロードの多くでも、SQL Server では大規模なデータベース サイズを処理できます。SQL Server の最大容量仕様の詳細については、SQL Server のエディション別の計算容量制限に関する記事を参照してください。 個別のマシン上の複数の SQL Server インスタンスと、パーティション分割された T-SQL 要求を使用すると、アプリケーションのスケールアウト環境が可能になります。
PolyBase を使用すると、SQL Server インスタンスにより、クライアント接続ソフトウェアを別途インストールしなくても、SQL Server、Oracle、Teradata、MongoDB、Cosmos DB から T-SQL を使用してデータを直接照会できます。 また、Microsoft Windows ベースのインスタンスで汎用 ODBC コネクタを使い、サードパーティの ODBC ドライバーを使って追加のプロバイダーに接続することもできます。 PolyBase を使用すると、T-SQL クエリで、外部ソースからのデータを SQL Server のインスタンス内のリレーショナル テーブルに結合できるようになります。 これにより、データを元の場所と形式のまま保持することができます。 SQL Server インスタンスを介して外部データを仮想化し、SQL Server 内の他のテーブルと同じようにクエリを行うことができます。 SQL Server 2022 (16.x) では、オブジェクトストア (S3-API を使用) ハードウェアまたはソフトウェア ストレージ オプションを使用したアドホック クエリとバックアップおよび復元も可能です。
2 つの一般的な参照アーキテクチャは、構造化データのクエリ用にスタンドアロン サーバーで SQL Server を使用し、Synapse へのオンプレミスのリンク用にスケールアウト非リレーショナル システム (Apache Hadoop や Apache Spark など) の個別のインストールを使用することです。もう 1 つのオプションは、ソリューションのすべてのコンポーネントを含む Kubernetes クラスター内のコンテナーのセットを使用することです。
Windows 上の Microsoft SQL Server、Apache Spark、オブジェクト ストレージ オンプレミス
Windows または Linux に SQL Server をインストールし、ハードウェア アーキテクチャをスケールアップして、SQL Server 2022 (16.x) のオブジェクト ストレージ クエリ機能と PolyBase 機能を使い、システム内のすべてのデータにわたるクエリを有効にすることができます。
Apache Hadoop や Apache Spark などのスケールアウト プラットフォームをインストールして構成すると、大規模な非リレーショナル データのクエリを実行できます。 S3-API をサポートする集中管理されたオブジェクト ストレージ システムを使用すると、SQL Server 2022 (16.x) と Spark の両方で、すべてのシステムにわたって同じデータ セットにアクセスできます。
SQL Server および Azure SQL 用の Microsoft Apache Spark コネクタを使用すると、Spark ジョブを使用して SQL Server から直接データのクエリを実行できます。 SQL Server と Azure SQL 用の Apache Spark コネクタの詳細については、「Apache Spark コネクタ: SQL Server および Azure SQL」を参照してください。
デプロイに Kubernetes コンテナー オーケストレーション システムを使用することもできます。 これにより、オンプレミス、または Kubernetes または Red Hat OpenShift プラットフォームをサポートする任意のクラウドで実行できる、宣言型アーキテクチャが可能になります。 Kubernetes 環境への SQL Server のデプロイの詳細については、「Azure に SQL Server コンテナー クラスターをデプロイする」を参照するか、「Kubernetes に SQL Server 2019 をデプロイする」をご覧ください。
次のことを行う必要がある場合は、SQL Server 2019 ビッグ データ クラスターの代わりとして、オンプレミスで SQL Server と Hadoop または Spark を使用してください。
- ソリューション全体をオンプレミスに保持する
- ソリューションのすべての部分に専用ハードウェアを使用する
- 同じアーキテクチャからリレーショナル データと非リレーショナル データに両方向でアクセスする
- SQL Server とスケールアウト非リレーショナル システムの間で単一の非リレーショナル データ セットを共有する
移行する
移行の場所 (クラウド内またはハイブリッド) を選んだら、ダウンタイムとコストのベクトルを比較し、新しいシステムを実行して前のシステムから新しいシステムにリアルタイムでデータを移動する (サイドバイサイド移行) か、バックアップと復元か、または既存のデータ ソースからシステムの新しい開始を実行する (インプレース移行) かどうかを判断する必要があります。
次の決定事項は、新しいアーキテクチャの選択を使用してシステム内の現在の機能を書き換えるか、可能な限り多くのコードを新しいシステムに移行するかです。 前の選択肢はより時間がかかりますが、新しいアーキテクチャによって提供される新しい方法、概念、利点を使用できます。 その場合、データ アクセスと機能のマップが焦点を当てるべき主要な計画作業になります。
可能な限り少ないコード変更で現在のシステムを移行する場合は、言語の互換性が計画の主な焦点になります。
コードの移行
次の手順は、現在のシステムで使用されているコードと、新しい環境に対して実行するために必要な変更点を監査することです。
コード移行には、次の 2 つの主要なベクトルを考慮する必要があります。
- ソースとシンク
- 機能の移行
ソースとシンク
コード移行の最初のタスクは、インポートされたデータ、そのパス、およびその最終的な宛先にアクセスするためにコードで使用する、データ ソース接続のメソッド、文字列、または API を特定することです。 これらのソースを文書化し、新しいアーキテクチャの場所へのマップを作成します。
- 現在のソリューションが "パイプライン" システムを使用してシステムを通じてデータを移動している場合は、新しいアーキテクチャのソース、ステップ、シンクをパイプラインのコンポーネントにマップします。
- 新しいソリューションで "パイプライン" アーキテクチャも置き換える場合は、ハードウェアまたはクラウド プラットフォームを代替として再利用する場合でも、計画目的のためにシステムを新しいインストールとして扱います。
機能の移行
移行で必要な最も複雑な作業は、現在のシステムの機能のドキュメントを参照、更新、または作成する作業です。 インプレース アップグレードを計画し、コードの書き換え量を可能な限り減らそうとしている場合は、この手順に最も時間がかかるでしょう。
ただし、以前のテクノロジからの移行は、多くの場合、テクノロジの最新の進歩に合わせて更新を行い、それが提供する構造を活用するために最適な時間です。 多くの場合、現在のシステムを書き換えることによって、セキュリティ、パフォーマンス、機能のより多くの選択肢、さらにコストの最適化を得ることができます。
どちらの場合も、移行には 2 つの主な要因が伴います。つまり、新しいシステムでサポートされるコードと言語、およびデータ移動に関する選択肢です。 通常は、現在のビッグ データ クラスターから SQL Server インスタンスと Spark 環境に接続文字列を変更できるようにする必要があります。 データ接続情報とコード カットオーバーは最小限に抑える必要があります。
現在の機能の書き換えを計画している場合は、新しいライブラリ、パッケージ、DLL を、移行用に選んだアーキテクチャにマップします。 各ソリューションが提供するライブラリ、言語、関数それぞれの一覧については、前のセクションで示したドキュメント リファレンスを参照してください。 疑わしい言語またはサポートされていない言語に関する計画を立て、選択したアーキテクチャへの置き換えを計画します。
データ移行のオプション
大規模な分析システムでのデータ移動には、2 つの一般的なアプローチがあります。 1 つ目は、元のシステムがデータの処理を継続し、そのデータを集計されたレポート データ ソースの小さなセットにロール アップする、"カットオーバー" プロセスを作成することです。 その後、新しいシステムは新しいデータと共に開始され、移行日以降に使用されます。
場合によっては、すべてのデータをレガシ システムから新しいシステムに移動する必要があります。 このケースでは、新しいシステムでサポートされている場合は SQL Server ビッグ データ クラスターから元のファイル ストアをマウントした後、データを新しいシステムに区分的にコピーするか、物理的な移動を作成できます。
現在のデータを SQL Server 2019 ビッグ データ クラスターから別のシステムに移行することは、現在のデータの場所と、移行先がオンプレミスかクラウドか、という 2 つの要因に大きく依存します。
オンプレミスのデータ移行
オンプレミスからオンプレミスへの移行の場合は、バックアップと復元の戦略を使用して SQL Server データを移行するか、一部またはすべてのリレーショナル データを移動するレプリケーションを設定できます。 SQL Server Integration Services を使用して、SQL Server から別の場所にデータをコピーすることもできます。 SSIS を使用してデータを移動する方法の詳細については、「SQL Server Integration Services」を参照してください。
現在の SQL Server ビッグ データ クラスター環境の HDFS データの場合、標準的な方法は、スタンドアロンの Spark クラスターにデータをマウントし、オブジェクト ストレージ プロセスを使用してデータを移動して SQL Server 2022 (16.x) インスタンスがアクセスできるようにするか、そのまま残して Spark ジョブで処理を続行するかです。
クラウド内のデータ移行
クラウド ストレージまたはオンプレミスにあるデータの場合は、Azure Data Factory を使用できます。これには、スケジュール設定、監視、アラート、その他のサービスを含む、転送の完全なパイプライン用の 90 を超えるコネクタがあります。 Azure Data Factory の詳細については、「Azure Data Factory とは何ですか」を参照してください。
大量のデータを安全かつ迅速にローカル データ資産から Microsoft Azure に移動したい場合は、Azure Import/Export サービスを使用できます。 Azure Import/Export サービスを使用すると、Azure データセンターにディスク ドライブを送付することで、Azure Blob Storage と Azure Files に大量のデータを安全にインポートできます。 また、このサービスでは、Azure Blob Storage からディスク ドライブにデータを転送し、オンプレミスのサイトに送付できます。 1 つまたは複数のディスク ドライブからのデータを、Azure Blob Storage または Azure Files にインポートできます。 非常に大量のデータの場合は、このサービスを使用することが最速である場合があります。
Microsoft 提供のディスク ドライブを使用してデータを転送する場合は、Azure Data Box Disk を使用してデータを Azure にインポートできます。 詳細については、「Azure Import/Export サービスとは」を参照してください。
これらの選択肢とそれに付随する決定の詳細については、「Data Lake Storage Gen1 を使用してビッグ データの要件に対応する」を参照してください。
関連するコンテンツ
フィードバック
以下は間もなく提供いたします。2024 年を通じて、コンテンツのフィードバック メカニズムとして GitHub の issue を段階的に廃止し、新しいフィードバック システムに置き換えます。 詳細については、「https://aka.ms/ContentUserFeedback」を参照してください。
フィードバックの送信と表示