SQL Server ビッグ データ クラスターのデータ プールとは
適用対象:![]() SQL Server 2019 (15.x)
SQL Server 2019 (15.x)
重要
Microsoft SQL Server 2019 ビッグ データ クラスターのアドオンは廃止されます。 SQL Server 2019 ビッグ データ クラスターのサポートは、2025 年 2 月 28 日に終了します。 ソフトウェア アシュアランス付きの SQL Server 2019 を使用する既存の全ユーザーはプラットフォームで完全にサポートされ、ソフトウェアはその時点まで SQL Server の累積更新プログラムによって引き続きメンテナンスされます。 詳細については、お知らせのブログ記事と「Microsoft SQL Server プラットフォームのビッグ データ オプション」を参照してください。
この記事では、SQL Server ビッグ データ クラスターでの "SQL Server データ プール" の役割について説明します。 以下のセクションでは、データ プールのアーキテクチャ、機能、使用シナリオについて説明します。
この 5 分間のビデオでは、データ プールについて説明し、データ プールからデータのクエリを実行する方法について説明します。
データ プールのアーキテクチャ
データ プールは、クラスターに永続的な SQL Server ストレージを提供する 1 つ以上の SQL Server データ プール インスタンスで構成されます。 これにより、外部データ ソースおよび作業のオフロードに対してキャッシュ データをクエリするパフォーマンスを向上させることができます。 データは、T-SQL クエリまたは Spark ジョブのいずれかを使用してデータ プールに取り込まれます。 大きなデータセット全体のパフォーマンスを向上させるために、取り込まれたデータはシャードに分散され、プール内のすべての SQL Server インスタンスに格納されます。 サポートされているディストリビューション方法はラウンド ロビン方式であり、レプリケートされます。 読み取りアクセスの最適化では、各データ プール インスタンスの各テーブルにクラスター化列ストア インデックスが作成されます。 データ プールは、SQL Server ビッグ データ クラスター のスケールアウト データ マートとして機能します。
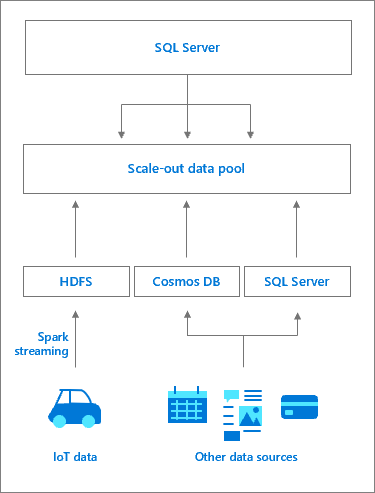
データ プール内の SQL Server インスタンスへのアクセスは、SQL Server マスター インスタンスから管理されます。 データ プールに対する外部データ ソースが、データ キャッシュを格納する PolyBase 外部テーブルと共に作成されます。 バックグラウンドでは、コントローラーによって、外部テーブルに一致するテーブルを含むデータベースがデータ プールに作成されます。 SQL Server マスター インスタンスからは、ワークフローは透過的になります。コントローラーにより、特定の外部テーブル要求が、コンピューティング プールを介してデータ プール内の SQL Server インスタンスにリダイレクトされ、クエリを実行して結果セットが返されます。 データ プール内のデータは、取り込みまたはクエリのみが可能であり、変更することはできません。 そのため、データを更新するには、テーブルを削除してから、テーブルを再作成し、その後データを再設定する必要があります。
データ プールのシナリオ
レポートを作成する目的は、データ プールの一般的なシナリオです。 たとえば、複数の PolyBase データ ソースを結合する複雑なクエリは、週次レポートで使用され、データ プールにオフロードできます。 キャッシュ データにより、ローカルの高速コンピューティングが提供され、元のデータセットに戻る必要がなくなります。 同様に、定期的に更新する必要があるダッシュボード データも、最適化されたレポート作成のためにデータ プールにキャッシュすることができます。 また、Machine Learning の繰り返し探索も、データ プール内のデータセットをキャッシュすることからメリットが得られます。
次のステップ
SQL Server ビッグ データ クラスター の詳細については、次のリソースを参照してください。
フィードバック
以下は間もなく提供いたします。2024 年を通じて、コンテンツのフィードバック メカニズムとして GitHub の issue を段階的に廃止し、新しいフィードバック システムに置き換えます。 詳細については、「https://aka.ms/ContentUserFeedback」を参照してください。
フィードバックの送信と表示