SQL Server ビッグ データ クラスター における記憶域プールとは
適用対象:![]() SQL Server 2019 (15.x)
SQL Server 2019 (15.x)
この記事では、SQL Server ビッグ データ クラスターでの "SQL Server 記憶域プール" の役割について説明します。 以下のセクションでは、記憶域プールのアーキテクチャと機能について説明します。
重要
Microsoft SQL Server 2019 ビッグ データ クラスターのアドオンは廃止されます。 SQL Server 2019 ビッグ データ クラスターのサポートは、2025 年 2 月 28 日に終了します。 ソフトウェア アシュアランス付きの SQL Server 2019 を使用する既存の全ユーザーはプラットフォームで完全にサポートされ、ソフトウェアはその時点まで SQL Server の累積更新プログラムによって引き続きメンテナンスされます。 詳細については、お知らせのブログ記事と「Microsoft SQL Server プラットフォームのビッグ データ オプション」を参照してください。
記憶域プールのアーキテクチャ
記憶域プールは、SQL Server ビッグ データ クラスター内のローカル HDFS (Hadoop) クラスターです。 非構造化および半構造化データ用の永続的ストレージを提供します。 記憶域プールには、Parquet や区切りテキストなどのデータ ファイルを格納できます。 記憶域を永続化するために、プール内の各ポッドには永続ボリュームがアタッチされています。 記憶域プール ファイルには、SQL Server を通して PolyBase 経由でアクセスすることも、Apache Knox ゲートウェイを使用して直接アクセスすることもできます。
クラシック HDFS セットアップは、記憶域が接続されている一連の汎用ハードウェア コンピューターで構成されています。 フォールト トレランスを実現し、並列処理を活用するために、データは複数のノード間にブロック単位で分散されます。 クラスターに含まれるノードの中の 1 つは名前ノードとして機能し、そこにはデータ ノードに配置されているファイルに関するメタデータ情報が格納されます。
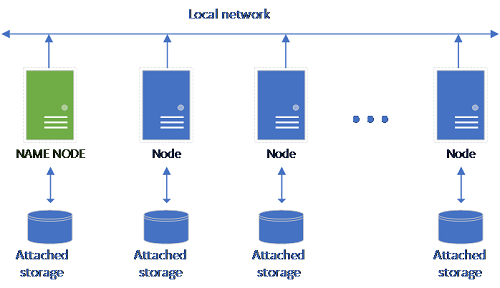
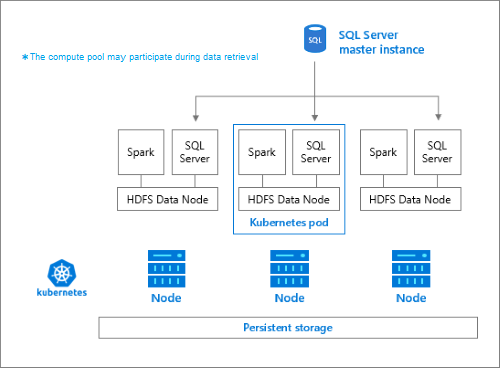
記憶域プールは、HDFS クラスターのメンバーである記憶域ノードで構成されます。 1 つまたは複数の Kubernetes ポッドが実行され、次のコンテナーが各ホストによってホストされます。
- 永続ボリューム (記憶域) にリンクされた Hadoop コンテナー。 この種類のすべてのコンテナーが一緒になって、Hadoop クラスターが形成されます。 Hadoop コンテナー内には、オンデマンドの Apache Spark ワーカー プロセスを作成できる YARN ノード マネージャー プロセスがあります。 この Spark ヘッド ノードによって、Hive メタストア、Spark 履歴、YARN ジョブ履歴の各コンテナーがホストされます。
- OpenRowSet テクノロジを使用して HDFS からデータを読み取る SQL Server インスタンス。
- メトリック データを収集するための
collectd。 - ログ データを収集するための
fluentbit。
役割
記憶域ノードの役割は次のとおりです。
- Apache Spark を通したデータ インジェスト。
- HDFS のデータ ストレージ (Parquet および区切りテキスト形式)。 HDFS では、HDFS データが SQL BDC 内のすべての記憶域ノードに分散されるため、データの永続性も提供されます。
- HDFS と SQL Server エンドポイントを使用したデータ アクセス。
データへのアクセス
記憶域プール内のデータにアクセスするには、主に次の方法があります。
- Spark ジョブ。
- SQL Server 外部テーブルの利用。これにより、PolyBase コンピューティング ノードと HDFS ノード内で実行される SQL Server インスタンスを使用してデータのクエリを実行することができます。
次のものを使用して HDFS とやりとりすることもできます。
- Azure Data Studio。
- Azure Data CLI (
azdata)。 - Hadoop コンテナーにコマンドを発行する kubectl。
- HDFS http ゲートウェイ。
次のステップ
SQL Server ビッグ データ クラスター の詳細については、次のリソースを参照してください。
フィードバック
以下は間もなく提供いたします。2024 年を通じて、コンテンツのフィードバック メカニズムとして GitHub の issue を段階的に廃止し、新しいフィードバック システムに置き換えます。 詳細については、「https://aka.ms/ContentUserFeedback」を参照してください。
フィードバックの送信と表示