高可用性構成で HDFS 名前ノードと共有 Spark サービスを展開する
適用対象:![]() SQL Server 2019 (15.x)
SQL Server 2019 (15.x)
重要
Microsoft SQL Server 2019 ビッグ データ クラスターのアドオンは廃止されます。 SQL Server 2019 ビッグ データ クラスターのサポートは、2025 年 2 月 28 日に終了します。 ソフトウェア アシュアランス付きの SQL Server 2019 を使用する既存の全ユーザーはプラットフォームで完全にサポートされ、ソフトウェアはその時点まで SQL Server の累積更新プログラムによって引き続きメンテナンスされます。 詳細については、お知らせのブログ記事と「Microsoft SQL Server プラットフォームのビッグ データ オプション」を参照してください。
可用性グループを使用して、高可用性構成で SQL Server マスター インスタンスを展開するだけでなく、他のミッション クリティカルなサービスをビッグ データ クラスターに展開し、確実に信頼性のレベルを高めることができます。 HDFS name node と、sparkhead の下にグループ化された共有 Spark サービスを追加のレプリカで構成できます。 この場合、次のサービス用のクラスター コーディネーターおよびメタデータ ストアとして機能するように、Zookeeper もビッグ データ クラスターに展開されます。
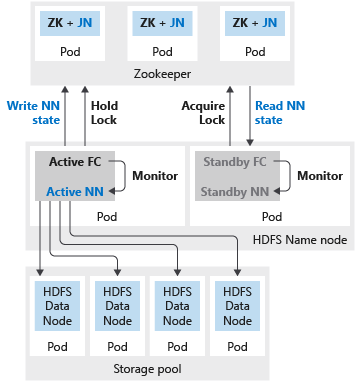
- HDFS 名前ノード
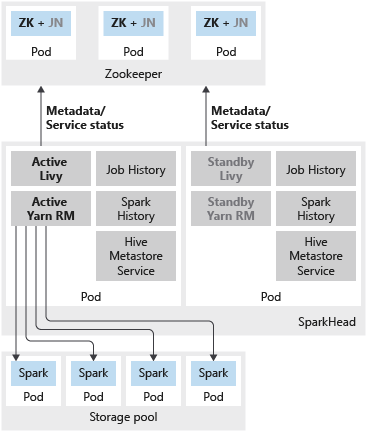
- Livy と Yarn Resource Manager
Spark 履歴、ジョブ履歴、および Hive メタデータ サービスはステートレス サービスです。 Zookeeper は、これらのコンポーネントのサービスの正常性の保証には関与しません。
これらのサービスに対して複数のレプリカを展開すると、使用可能なレプリカ間でのワークロードのスケーラビリティ、信頼性、および負荷分散が向上します。
Note
次のサービスは、sparkhead ポッドにコンテナーとして展開されます。
- Livy
- Yarn Resource Manager
- Spark 履歴
- ジョブ履歴
- Hive メタデータ サービス
次の図は、SQL Server ビッグ データ クラスターでの spark HA の展開を示しています。
次の図は、SQL Server ビッグ データ クラスターでの HDFS HA の展開を示しています。
デプロイ
名前ノードまたは spark ヘッドのいずれかが 2 つのレプリカで構成されている場合は、3 つのレプリカで Zookeeper リソースを構成する必要もあります。 HDFS 名前ノードの高可用性構成では、2 つのポッドで 2 つのレプリカがホストされます。 ポッドは nmnode-0 と nmnode-1 です。 この構成はアクティブ/パッシブです。 名前ノードは一度に 1 つしかアクティブになりません。 もう一方はスタンバイ状態であり、フェールオーバー イベントの結果としてアクティブになります。
aks-dev-test-ha または kubeadm-prod の組み込み構成プロファイルを使用して、ビッグ データ クラスターの展開のカスタマイズを開始できます。 これらのプロファイルには、追加の高可用性を構成できるリソースに必要な設定が含まれます。 たとえば、以下は bdc.json 構成ファイルのセクションです。これは、HDFS 名前ノード、Zookeeper および共有 Spark リソース (sparkhead) を高可用性を使用して展開する場合に関連します。
{
...
"nmnode-0": {
"spec": {
"replicas": 2
}
},
"sparkhead": {
"spec": {
"replicas": 2
}
},
"zookeeper": {
"spec": {
"replicas": 3
}
},
...
}
ベスト プラクティスとして、運用環境での展開では、HDFS ブロック レプリケーションを 3 に構成する必要もあります。 この設定は、aks-dev-test-ha および kubeadm-prod プロファイルで既に指定されています。 bdc.json 構成ファイルの以下のセクションを参照してください。
{
...
"hdfs": {
"resources": [
"nmnode-0",
"zookeeper",
"storage-0",
"sparkhead"
],
"settings": {
"hdfs-site.dfs.replication": "3"
}
},
...
}
既知の制限事項
SQL Server ビッグ データ クラスターで Hadoop サービスの高可用性を構成する際の既知の問題と制限事項には、以下が含まれます。
- ビッグ データ クラスターの展開時に、すべての構成を指定する必要があります。 SQL Server 2019 CU1 リリースでは、展開後に高可用性構成を有効にすることはできません。
次のステップ
- ビッグ データ クラスターの展開での構成ファイルの使用について詳しくは、「Kubernetes に SQL Server ビッグ データ クラスターを展開する方法」を参照してください。
- ビッグ データ クラスターの SQL Server マスターの高可用性オプションについて詳しくは、高可用性を使用する SQL Server マスター インスタンスの展開に関するトピックを参照してください。
フィードバック
以下は間もなく提供いたします。2024 年を通じて、コンテンツのフィードバック メカニズムとして GitHub の issue を段階的に廃止し、新しいフィードバック システムに置き換えます。 詳細については、「https://aka.ms/ContentUserFeedback」を参照してください。
フィードバックの送信と表示