pyspark ノートブックのトラブルシューティング
重要
Microsoft SQL Server 2019 ビッグ データ クラスターのアドオンは廃止されます。 SQL Server 2019 ビッグ データ クラスターのサポートは、2025 年 2 月 28 日に終了します。 ソフトウェア アシュアランス付きの SQL Server 2019 を使用する既存の全ユーザーはプラットフォームで完全にサポートされ、ソフトウェアはその時点まで SQL Server の累積更新プログラムによって引き続きメンテナンスされます。 詳細については、お知らせのブログ記事と「Microsoft SQL Server プラットフォームのビッグ データ オプション」を参照してください。
この記事では、失敗した pyspark ノートブックのトラブルシューティング方法について説明します。
Azure Data Studio での PySpark ジョブのアーキテクチャ
Azure Data Studio は、SQL Server ビッグ データ クラスター上の livy エンドポイントと通信します。
ビッグ データ クラスター内で、livy エンドポイントによって spark-submit コマンドが発行されます。 各 spark-submit コマンドには、クラスターのリソース マネージャーとして YARN を指定するパラメーターがあります。
PySpark セッションを効率的にトラブルシューティングするには、各レイヤー内のログを収集して確認します (Livy、YARN、Spark)。
このトラブルシューティング手順では、以下が必要です。
- Azure Data CLI (
azdata) がインストールされ、構成がクラスターに正しく設定されていること。 - Linux コマンドの実行に関する知識とログのトラブルシューティング スキル。
トラブルシューティングの手順
pysparkのスタックとエラー メッセージを確認します。ノートブックの最初のセルからアプリケーション ID を取得します。 このアプリケーション ID を使用して、
livy、YARN、および Spark のログを調査します。SparkContextには、この YARN アプリケーション ID が使用されます。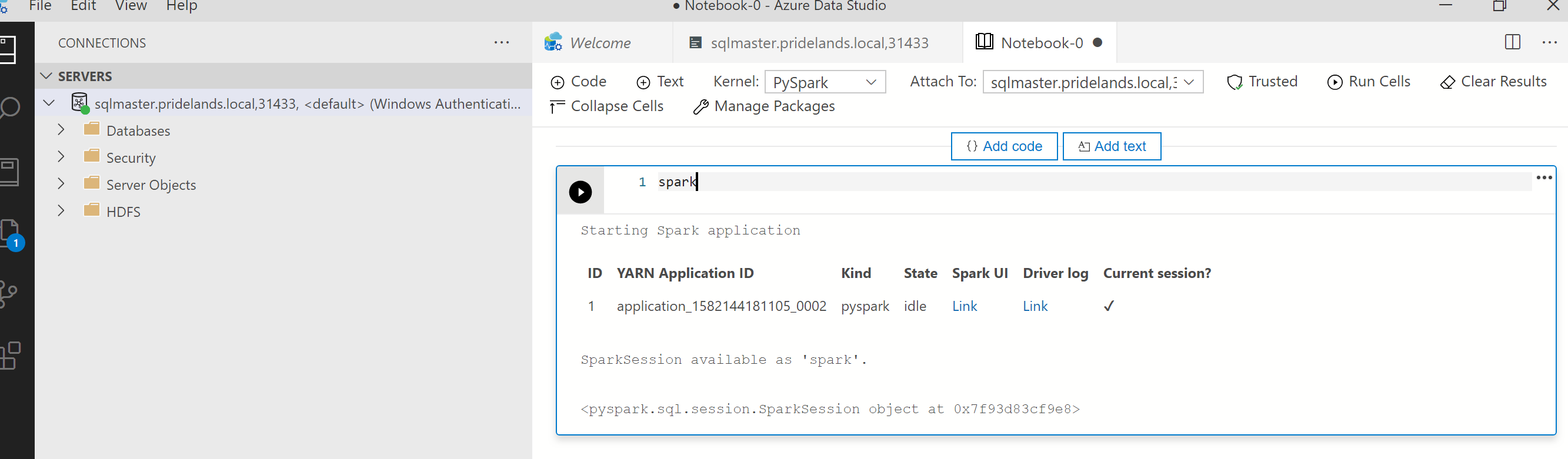
ログを取得します。
azdata bdc debug copy-logsを使用して調査します次の例では、ビッグ データ クラスター エンドポイントを接続してログをコピーします。 実行する前に、例の次の値を更新します。
<ip_address>:ビッグ データ クラスターのエンドポイント<username>:ビッグ データ クラスターのユーザー名<namespace>:クラスターの Kubernetes 名前空間<folder_to_copy_logs>:ログをコピーする先のローカル フォルダーのパス
azdata login --auth basic --username <username> --endpoint https://<ip_address>:30080 azdata bdc debug copy-logs -n <namespace> -d <folder_to_copy_logs>出力例
<user>@<server>:~$ azdata bdc debug copy-logs -n <namespace> -d copy_logs Collecting the logs for cluster '<namespace>'. Collecting logs for containers... Creating an archive from logs-tmp/<namespace>. Log files are archived in /home/<user>/copy_logs/debuglogs-<namespace>-YYYYMMDD-HHMMSS.tar.gz. Creating an archive from logs-tmp/dumps. Log files are archived in /home/<user>/copy_logs/debuglogs-<namespace>-YYYYMMDD-HHMMSS-dumps.tar.gz. Collecting the logs for cluster 'kube-system'. Collecting logs for containers... Creating an archive from logs-tmp/kube-system. Log files are archived in /home/<user>/copy_logs/debuglogs-kube-system-YYYYMMDD-HHMMSS.tar.gz. Creating an archive from logs-tmp/dumps. Log files are archived in /home/<user>/copy_logs/debuglogs-kube-system-YYYYMMDD-HHMMSS-dumps.tar.gz.Livy ログを確認します。 Livy のログは
<namespace>\sparkhead-0\hadoop-livy-sparkhistory\supervisor\logにあります。- pyspark ノートブックの最初のセルから YARN アプリケーション ID を検索します。
ERR状態を検索します。
状態が
YARN ACCEPTEDの Livy ログの例。 Livy から yarn アプリケーションが送信されました。HH:MM:SS INFO utils.LineBufferedStream: YYY-MM-DD HH:MM:SS INFO impl.YarnClientImpl: Submitted application application_<application_id> YY/MM/DD HH:MM:SS INFO utils.LineBufferedStream: YYY-MM-DD HH:MM:SS INFO yarn.Client: Application report for application_<application_id> (state: ACCEPTED) YY/MM/DD HH:MM:SS INFO utils.LineBufferedStream: YYY-MM-DD HH:MM:SS INFO yarn.Client: YY/MM/DD HH:MM:SS INFO utils.LineBufferedStream: client token: N/A YY/MM/DD HH:MM:SS INFO utils.LineBufferedStream: diagnostics: N/A YY/MM/DD HH:MM:SS INFO utils.LineBufferedStream: ApplicationMaster host: N/A YY/MM/DD HH:MM:SS INFO utils.LineBufferedStream: ApplicationMaster RPC port: -1 YY/MM/DD HH:MM:SS INFO utils.LineBufferedStream: queue: default YY/MM/DD HH:MM:SS INFO utils.LineBufferedStream: start time: ############ YY/MM/DD HH:MM:SS INFO utils.LineBufferedStream: final status: UNDEFINED YY/MM/DD HH:MM:SS INFO utils.LineBufferedStream: tracking URL: https://sparkhead-1.fnbm.corp:8090/proxy/application_<application_id>/ YY/MM/DD HH:MM:SS INFO utils.LineBufferedStream: user: <account>YARN UI を確認する
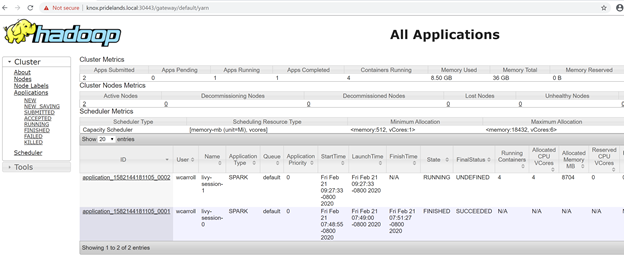
Azure Data Studio ビッグ データ クラスター管理ダッシュボードから YARN エンドポイント URL を取得するか、
azdata bdc endpoint list –o tableを実行します。次に例を示します。
azdata bdc endpoint list -o table戻り値
Description Endpoint Name Protocol ------------------------------------------------------ ---------------------------------------------------------------- -------------------------- ---------- Gateway to access HDFS files, Spark https://knox.<namespace-value>.local:30443 gateway https Spark Jobs Management and Monitoring Dashboard https://knox.<namespace-value>.local:30443/gateway/default/sparkhistory spark-history https Spark Diagnostics and Monitoring Dashboard https://knox.<namespace-value>.local:30443/gateway/default/yarn yarn-ui https Application Proxy https://proxy.<namespace-value>.local:30778 app-proxy https Management Proxy https://bdcmon.<namespace-value>.local:30777 mgmtproxy https Log Search Dashboard https://bdcmon.<namespace-value>.local:30777/kibana logsui https Metrics Dashboard https://bdcmon.<namespace-value>.local:30777/grafana metricsui https Cluster Management Service https://bdcctl.<namespace-value>.local:30080 controller https SQL Server Master Instance Front-End sqlmaster.<namespace-value>.local,31433 sql-server-master tds SQL Server Master Readable Secondary Replicas sqlsecondary.<namespace-value>.local,31436 sql-server-master-readonly tds HDFS File System Proxy https://knox.<namespace-value>.local:30443/gateway/default/webhdfs/v1 webhdfs https Proxy for running Spark statements, jobs, applications https://knox.<namespace-value>.local:30443/gateway/default/livy/v1 livy httpsアプリケーション ID と、個々の application_master とコンテナーのログを確認します。
YARN アプリケーション ログを確認します。
アプリのアプリケーション ログを取得します。
kubectlを使用してsparkhead-0ポッドに接続します。次に例を示します。kubectl exec -it sparkhead-0 -- /bin/bashそして、適切な
application_idを使用して、そのシェル内でこのコマンドを実行します。yarn logs -applicationId application_<application_id>エラーまたはスタックを探します。
hdfs に対するアクセス許可エラーの例。 Java スタックで
Caused by:を探しますYYYY-MM-DD HH:MM:SS,MMM ERROR spark.SparkContext: Error initializing SparkContext. org.apache.hadoop.security.AccessControlException: Permission denied: user=<account>, access=WRITE, inode="/system/spark-events":sph:<bdc-admin>:drwxr-xr-x at org.apache.hadoop.hdfs.server.namenode.FSPermissionChecker.check(FSPermissionChecker.java:399) at org.apache.hadoop.hdfs.server.namenode.FSPermissionChecker.checkPermission(FSPermissionChecker.java:255) at org.apache.hadoop.hdfs.server.namenode.FSPermissionChecker.checkPermission(FSPermissionChecker.java:193) at org.apache.hadoop.hdfs.server.namenode.FSDirectory.checkPermission(FSDirectory.java:1852) at org.apache.hadoop.hdfs.server.namenode.FSDirectory.checkPermission(FSDirectory.java:1836) at org.apache.hadoop.hdfs.server.namenode.FSDirectory.checkAncestorAccess(FSDirectory.java:1795) at org.apache.hadoop.hdfs.server.namenode.FSDirWriteFileOp.resolvePathForStartFile(FSDirWriteFileOp.java:324) at org.apache.hadoop.hdfs.server.namenode.FSNamesystem.startFileInt(FSNamesystem.java:2504) at org.apache.hadoop.hdfs.server.namenode.FSNamesystem.startFileChecked(FSNamesystem.java:2448) Caused by: org.apache.hadoop.ipc.RemoteException(org.apache.hadoop.security.AccessControlException): Permission denied: user=<account>, access=WRITE, inode="/system/spark-events":sph:<bdc-admin>:drwxr-xr-xSPARK UI を確認します。
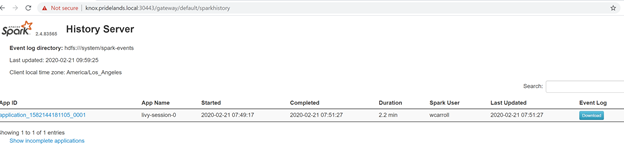
ステージ タスクまでドリルダウンしてエラーを探します。
次のステップ
フィードバック
以下は間もなく提供いたします。2024 年を通じて、コンテンツのフィードバック メカニズムとして GitHub の issue を段階的に廃止し、新しいフィードバック システムに置き換えます。 詳細については、「https://aka.ms/ContentUserFeedback」を参照してください。
フィードバックの送信と表示