Always On 可用性グループのパフォーマンスを監視する
適用対象:![]() SQL Server
SQL Server
Always On 可用性グループのパフォーマンス面は、ミッション クリティカルなデータベースに対するサービス レベル アグリーメント (SLA) を維持する上で重要です。 可用性グループがセカンダリ レプリカにログを配布する方法を理解することで、可用性実装の回復時刻の目標 (RTO) および回復ポイントの目標 (RPO) の推定、ならびにパフォーマンスに問題がある可用性グループまたはレプリカにおけるボトルネックの特定が容易になります。 この記事では、同期プロセスについて説明し、主要なメトリックの計算方法を示すと共に、一般的なパフォーマンス トラブルシューティング シナリオへのリンクをいくつか紹介します。
データ同期プロセス
完全に同期するまでの時間を推定し、ボトルネックを特定するには、同期プロセスを理解する必要があります。 パフォーマンスのボトルネックはプロセス内の任意の箇所で発生する可能性があります。ボトルネックの場所を特定することで、基になっている問題をさらに詳しく調べることができます。 次の図と表に、データの同期プロセスを示します。

| シークエンス | ステップの説明 | 説明 | 有用なメトリック |
|---|---|---|---|
| 1 | ログの生成 | ログ データがディスクにフラッシュされます。 このログはセカンダリ レプリカにレプリケートする必要があります。 ログ レコードによって送信キューが入力されます。 | SQL Server: データベース > Log bytes flushed/sec |
| 2 | キャプチャ | 各データベースに関するログがキャプチャされ、対応するパートナー キュー (データベース レプリカ ペアごとに 1 つ) に送信されます。 このキャプチャ プロセスは、可用性レプリカが接続されていて何らかの理由でデータ移動が中断されていない限り、継続されます。データベース レプリカのペアは同期中または同期済みのいずれかであると表示されます。 キャプチャ プロセスによるメッセージのスキャンおよびエンキューに時間がかかる場合は、ログ送信キューがビルドされます。 | SQL Server: 可用性レプリカ > Bytes Sent to Replica/sec。可用性レプリカのキューに配置されたすべてのデータベース メッセージの合計を集計したものです。 プライマリ レプリカの log_send_queue_size (KB) とlog_bytes_send_rate (KB/秒)。 |
| 3 | Send | 各データベース レプリカ キュー内のメッセージがデキューされ、それぞれのセカンダリ レプリカにネットワーク経由で送信されます。 | SQL Server: 可用性レプリカ > Bytes sent to transport\sec |
| 4 | 受信とキャッシュ | 各セカンダリ レプリカがメッセージを受信しキャッシュします。 | パフォーマンス カウンター SQL Server: 可用性レプリカ > Log Bytes Received/sec |
| 5 | 書き込み | 書き込みのためログがセカンダリ レプリカにフラッシュされます。 ログのフラッシュ後、プライマリ レプリカに確認応答が返送されます。 ログが書き込まれると、データ損失は回避されます。 |
パフォーマンス カウンター SQL Server: データベース > Log Bytes Flushed/sec 待機の種類 HADR_LOGCAPTURE_SYNC |
| 6 | やり直し | セカンダリ レプリカでページのフラッシュを再実行します。 再実行されるのを待機する間、ページは再実行キューに保持されます。 | SQL Server: データベース レプリカ > Redone Bytes/sec redo_queue_size (KB) と redo_rate。 待機の種類 REDO_SYNC |
フロー制御ゲート
プライマリ レプリカではフロー制御ゲートを使用して可用性グループが設計されています。このため、すべての可用性レプリカ上でネットワークやメモリ リソースなどのリソースが過剰消費されるのを回避することができます。 このようなフロー制御ゲートは、可用性レプリカの同期の正常性状態に影響を及ぼしませんが、可用性データベースの全体的なパフォーマンス (RPO を含む) には影響する可能性があります。
ログはプライマリ レプリカ上でキャプチャされると、フロー制御の 2 つのレベルの影響を受けるようになります。 いずれかのゲートのメッセージしきい値に達すると、ログ メッセージは特定のレプリカ、または特定のデータベースに送信されなくなります。 送信するメッセージに対して確認応答メッセージが受信され、結果として送信メッセージの数がしきい値を下回ると、メッセージを送信できるようになります。
フロー制御ゲートに加えて、ログ メッセージの送信を回避することができる要素がもう 1 つあります。 レプリカを同期すると、メッセージは確実にログ シーケンス番号 (LSN) の順序で送信および適用されます。 ログ メッセージが送信される前に、その LSN は最小の確認応答 LSN 番号と突き合わせてチェックされ、いずれかのしきい値を下回っているかどうかが確認されます (メッセージの種類に応じて)。 2 つの LSN 番号間の差がしきい値よりも大きい場合、メッセージは送信されません。 番号間の差が再びしきい値を下回ると、メッセージは送信されます。
SQL Server 2022 では、各ゲートで許可されるメッセージ数の制限が引き上げられます。 トレース フラグ 12310 を使うと、引き上げられた制限を、次のバージョンの SQL Server 以降でも使用できます: SQL Server 2019 CU9、SQL Server 2017 CU18、SQL Server 2016 SP1 CU16。
次の表では、メッセージの制限を比較しています。
SQL Server 2022 と、トレース フラグ 12310 が有効なサポート対象バージョンの SQL Server (SQL Server 2019 CU9、SQL Server 2017 CU18、SQL Server 2016 SP1 CU16 以降) については、次の制限を参照してください。
| Level | ゲート数 | メッセージ数 | 有用なメトリック |
|---|---|---|---|
| トランスポート | 可用性レプリカごとに 1 つ | 16384 | 拡張イベント database_transport_flow_control_action |
| データベース | 可用性データベースごとに 1 つ | 7168 | DBMIRROR_SEND 拡張イベント hadron_database_flow_control_action |
2 つの有用なパフォーマンス カウンターである SQL Server: 可用性レプリカ > Flow control/sec と SQL Server: 可用性レプリカ > Flow Control Time (ms/sec) では、最後の 1 秒以内に、フロー制御がアクティブになった回数とフロー制御を待機していた時間を示します。 フロー制御の待機時間が長いと、RPO が大きくなります。 フロー制御の待機時間を長くする可能性のある問題の種類の詳細については、Troubleshoot: Availability group exceeded RPO (トラブルシューティング: 可用性グループが RPO を超過した) を参照してください。
フェールオーバー時間 (RTO) の推定
SLA での RTO は、特定の時点での Always On 実装のフェールオーバー時間に依存し、次の数式で表すことができます。

重要
可用性グループに複数の可用性データベースが含まれている場合、Tfailover が最も高い可用性データベースは RTO 準拠の制限値になります。
障害検出時間 Tdetection は、システムが障害を検出するのにかかる時間です。 この時間は、個々の可用性レプリカではなく、クラスター レベルの設定に依存します。 構成されている自動フェールオーバーの条件に応じて、SQL Server での重大な内部エラー (孤立したスピンロックなど) への瞬時の応答として、フェールオーバーをトリガーすることができます。 この場合、sp_server_diagnostics (Transact-SQL) エラー レポートが WSFC クラスターに送信されるのと同じ速さで検出が行われます (既定の間隔は正常性チェックのタイムアウトの 1/3 です)。 クラスターの正常性チェックのタイムアウトの時間 (既定では 30 秒) が経過したり、リソース DLL と SQL Server インスタンス間のリースの有効期限 (既定では 20 秒) が切れたりなど、タイムアウトが原因でフェールオーバーがトリガーされることもあります。 この場合、検出時間はタイムアウト間隔と同じ長さとなります。 詳細については、「可用性グループの自動フェールオーバーのための柔軟なフェールオーバー ポリシー (SQL Server)」を参照してください。
フェールオーバーの準備を整えるためにセカンダリ レプリカで実行する必要があることは、再実行でログの末尾をキャッチアップすることだけです。 再実行時間 Tredo は次の式を使用して計算します。

ここで、redo_queue は redo_queue_size 内の値であり、redo_rate は redo_rate 内の値です。
フェールオーバーのオーバーヘッド時間 Toverhead には、WSFC クラスターをフェールオーバーしてデータベースをオンラインにするのにかかる時間が含まれます。 この時間は通常は短く一定です。
データ損失の可能性 (RPO) の推定
SLA での RPO は、特定の時点での Always On 実装のデータ損失の可能性に依存します。 このデータ損失の可能性は次の式で表すことができます。

ここで、log_send_queue は、log_send_queue_size の値であり、"ログ生成速度" は、SQL Server: データベース > Log Bytes Flushed/sec の値です。
警告
可用性グループに 1 つ以上の可用性データベースが含まれている場合、最高 Tdata_loss で可用性データベースの RPO 対応制限値になります。
ログ送信キューは、重大なエラーによって失われる可能性のあるすべてのデータを表します。 一見して、ログ送信速度 (log_send_rate を参照) ではなく、ログ生成速度が使用されているのは興味深いことです。 なお、RPO ではデータを同期する速度ではなく、データを生成する速度に基づいてデータ損失が測定されるにも関わらず、ログ送信速度を使用した場合は同期のための時間しか得られません。
Tdata_loss を推定するには、last_commit_time を使用する方法が簡単です。 プライマリ レプリカ上の DMV は、この値をすべてのレプリカにレポートします。 プライマリ レプリカの値とセカンダリ レプリカの値との差を計算することで、セカンダリ レプリカ上のログがプライマリ レプリカに追いつく速さを推定することができます。 前述のように、この計算からは、ログが生成される速度に基づいたデータ損失の可能性は得られませんが、近似値を指定する必要があります。
SSMS ダッシュボードを使用して RTO と RPO を推定する
Always On 可用性グループで、セカンダリ レプリカでホストされているデータベースに対する RTO と RPO が計算され、表示されます。 プライマリ レプリカのダッシュボードで、RTO と RPO がセカンダリ レプリカごとにグループ化されます。
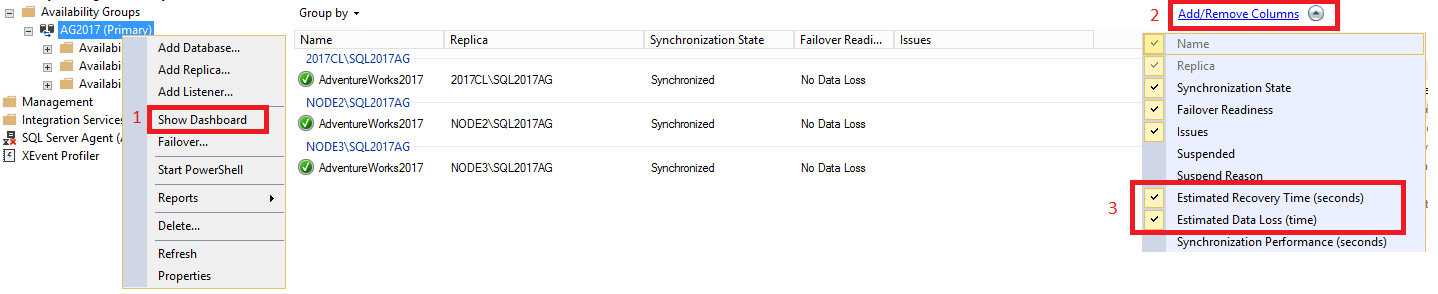
ダッシュボード内に RTO と RPO を表示するには、次の操作を行います。
SQL Server Management Studio で、 [Always On 可用性グループ] ノードを展開し、可用性グループの名前を右クリックして [ダッシュボードの表示] を選択します。
[グループ化] タブで、 [列の追加と削除] を選択します。 [推定復旧時間 (秒)] (RTO) と [推定データ損失 (時間)] (RPO) の両方のチェック ボックスをオンにします。
セカンダリ データベースの RTO の計算
フェールオーバーが発生した後、セカンダリ データベース の復旧に必要な時間は、復旧時間の計算で決まります。 フェールオーバー時間は通常は短く一定です。 この検出時間は、個々の可用性レプリカではなく、クラスター レベルの設定に依存します。
セカンダリ データベース (DB_sec) の場合、その RTO の計算と表示は redo_queue_size と redo_rate に基づきます。

まれなケースを除き、セカンダリ データベースの RTO を計算する数式は次のようになります。
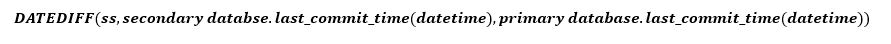
セカンダリ データベースの RPO の計算
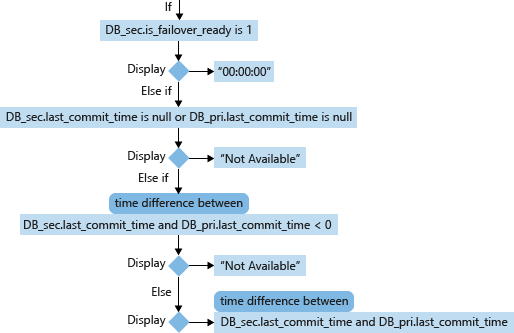
セカンダリ データベース (DB_sec) の場合、その RPO の計算と表示は、is_failover_ready、last_commit_time、および関連付けられているプライマリ データベース (DB_pri) の last_commit_time に基づきます。 セカンダリ データベースの is_failover_ready が 1 の場合、データは同期され、フェールオーバー時にデータの損失は発生しません。 しかし、この値が 0 の場合、プライマリ データベースの last_commit_time とセカンダリ データベースの last_commit_time には差が生じます。
プライマリ データベースの場合、last_commit_time は最後のトランザクションがコミットされた時間となります。 セカンダリ データベースの場合、last_commit_time は、同様にセカンダリ データベースに正常に書き込まれた、プライマリ データベースでのトランザクションに対する最後のコミット時間となります。 この数値は、プライマリ データベースとセカンダリ データベースで同じである必要があります。 これら 2 つの値の間の差は、保留中のトランザクションがセカンダリ データベースに書き込まれず、フェールオーバーの発生時に失われる期間です。
RTO と RPO の数式で使用されるパフォーマンス カウンター
- redo_queue_size (KB) (RTO で使用): 再実行キューのサイズは、last_received_lsn と last_redone_lsn の間のトランザクション ログのサイズです。 last_received_lsn は、このセカンダリ データベースをホストするセカンダリ レプリカによって受信されたすべてのログ ブロックの最後のポイントを示すログ ブロック ID です。 Last_redone_lsn は、セカンダリ データベースで再実行された最後のログ レコードのログ シーケンス番号です。 これら 2 つの値に基づき、開始ログ ブロック (last_received_lsn) と終了ログ ブロック (last_redone_lsn) の ID を見つけることができます。 これら 2 つのログ ブロックの間のスペースで、まだ再実行されていないトランザクション ログ ブロックの数を表すことができます。 これはキロバイト (KB) で測定されます。
- redo_rate (KB/秒) (RTO で使用): 一定の経過時間において、セカンダリ データベースでトランザクション ログ (KB) がどれくらい再実行されたかをキロバイト (KB)/秒で表す累積値。
- last_commit_time (日時) (RPO で使用): プライマリ データベースの場合、last_commit_time は最後のトランザクションがコミットされた時間となります。 セカンダリ データベースの場合、last_commit_time は、同様にセカンダリ データベースに正常に書き込まれた、プライマリ データベースでのトランザクションに対する最後のコミット時間となります。 セカンダリのこの値はプライマリの同じ値と同期する必要があるため、これら 2 つの値の間の差はデータ損失の推定値 (RPO) となります。
DMV を使用して RTO と RPO を推定する
DMV の sys.dm_hadr_database_replica_states と sys.dm_hadr_database_replica_cluster_states をクエリして、データベースの RPO と RTO を推定することができます。 以下のクエリでは、両方に実行するストアド プロシージャが作成されます。
注意
必ず、最初に RTO を推定するためのストアド プロシージャを作成して実行してください。生成される値は、RPO を推定するためのストアド プロシージャを実行するために必要になります。
RTO を推定するためのストアド プロシージャを作成する
- ターゲット セカンダリ レプリカで、ストアド プロシージャ proc_calculate_RTO を作成します。 このストアド プロシージャが既に存在する場合は、まず、削除してから再作成します。
if object_id(N'proc_calculate_RTO', 'p') is not null
drop procedure proc_calculate_RTO
go
raiserror('creating procedure proc_calculate_RTO', 0,1) with nowait
go
--
-- name: proc_calculate_RTO
--
-- description: Calculate RTO of a secondary database.
--
-- parameters: @secondary_database_name nvarchar(max): name of the secondary database.
--
-- security: this is a public interface object.
--
create procedure proc_calculate_RTO
(
@secondary_database_name nvarchar(max)
)
as
begin
declare @db sysname
declare @is_primary_replica bit
declare @is_failover_ready bit
declare @redo_queue_size bigint
declare @redo_rate bigint
declare @replica_id uniqueidentifier
declare @group_database_id uniqueidentifier
declare @group_id uniqueidentifier
declare @RTO float
select
@is_primary_replica = dbr.is_primary_replica,
@is_failover_ready = dbcs.is_failover_ready,
@redo_queue_size = dbr.redo_queue_size,
@redo_rate = dbr.redo_rate,
@replica_id = dbr.replica_id,
@group_database_id = dbr.group_database_id,
@group_id = dbr.group_id
from sys.dm_hadr_database_replica_states dbr join sys.dm_hadr_database_replica_cluster_states dbcs on dbr.replica_id = dbcs.replica_id and
dbr.group_database_id = dbcs.group_database_id where dbcs.database_name = @secondary_database_name
if @is_primary_replica is null or @is_failover_ready is null or @redo_queue_size is null or @replica_id is null or @group_database_id is null or @group_id is null
begin
print 'RTO of Database '+ @secondary_database_name +' is not available'
return
end
else if @is_primary_replica = 1
begin
print 'You are visiting wrong replica';
return
end
if @redo_queue_size = 0
set @RTO = 0
else if @redo_rate is null or @redo_rate = 0
begin
print 'RTO of Database '+ @secondary_database_name +' is not available'
return
end
else
set @RTO = CAST(@redo_queue_size AS float) / @redo_rate
print 'RTO of Database '+ @secondary_database_name +' is ' + convert(varchar, ceiling(@RTO))
print 'group_id of Database '+ @secondary_database_name +' is ' + convert(nvarchar(50), @group_id)
print 'replica_id of Database '+ @secondary_database_name +' is ' + convert(nvarchar(50), @replica_id)
print 'group_database_id of Database '+ @secondary_database_name +' is ' + convert(nvarchar(50), @group_database_id)
end
- ターゲット セカンダリ データベース名を指定して proc_calculate_RTO を実行します。
exec proc_calculate_RTO @secondary_database_name = N'DB_sec'
出力には、ターゲット セカンダリ レプリカ データベースの RTO の値が表示されます。 RPO 推定ストアド プロシージャで使用する group_id、replica_id、group_database_id を保存します。
サンプル出力:
データベース DB_sec の RTO は 0 です
データベース DB4 の group_id は F176DD65-C3EE-4240-BA23-EA615F965C9B です
データベース DB4 の replica_id は 405554F6-3FDC-4593-A650-2067F5FABFFD です
データベース DB4 の group_database_id は 39F7942F-7B5E-42C5-977D-02E7FFA6C392 です
RPO を推定するためのストアド プロシージャを作成する
- プライマリ レプリカで、ストアド プロシージャ proc_calculate_RPO を作成します。 既に存在する場合は、まず、ドロップしてから再作成します。
if object_id(N'proc_calculate_RPO', 'p') is not null
drop procedure proc_calculate_RPO
go
raiserror('creating procedure proc_calculate_RPO', 0,1) with nowait
go
--
-- name: proc_calculate_RPO
--
-- description: Calculate RPO of a secondary database.
--
-- parameters: @group_id uniqueidentifier: group_id of the secondary database.
-- @replica_id uniqueidentifier: replica_id of the secondary database.
-- @group_database_id uniqueidentifier: group_database_id of the secondary database.
--
-- security: this is a public interface object.
--
create procedure proc_calculate_RPO
(
@group_id uniqueidentifier,
@replica_id uniqueidentifier,
@group_database_id uniqueidentifier
)
as
begin
declare @db_name sysname
declare @is_primary_replica bit
declare @is_failover_ready bit
declare @is_local bit
declare @last_commit_time_sec datetime
declare @last_commit_time_pri datetime
declare @RPO nvarchar(max)
-- secondary database's last_commit_time
select
@db_name = dbcs.database_name,
@is_failover_ready = dbcs.is_failover_ready,
@last_commit_time_sec = dbr.last_commit_time
from sys.dm_hadr_database_replica_states dbr join sys.dm_hadr_database_replica_cluster_states dbcs on dbr.replica_id = dbcs.replica_id and
dbr.group_database_id = dbcs.group_database_id where dbr.group_id = @group_id and dbr.replica_id = @replica_id and dbr.group_database_id = @group_database_id
-- correlated primary database's last_commit_time
select
@last_commit_time_pri = dbr.last_commit_time,
@is_local = dbr.is_local
from sys.dm_hadr_database_replica_states dbr join sys.dm_hadr_database_replica_cluster_states dbcs on dbr.replica_id = dbcs.replica_id and
dbr.group_database_id = dbcs.group_database_id where dbr.group_id = @group_id and dbr.is_primary_replica = 1 and dbr.group_database_id = @group_database_id
if @is_local is null or @is_failover_ready is null
begin
print 'RPO of database '+ @db_name +' is not available'
return
end
if @is_local = 0
begin
print 'You are visiting wrong replica'
return
end
if @is_failover_ready = 1
set @RPO = '00:00:00'
else if @last_commit_time_sec is null or @last_commit_time_pri is null
begin
print 'RPO of database '+ @db_name +' is not available'
return
end
else
begin
if DATEDIFF(ss, @last_commit_time_sec, @last_commit_time_pri) < 0
begin
print 'RPO of database '+ @db_name +' is not available'
return
end
else
set @RPO = CONVERT(varchar, DATEADD(ms, datediff(ss ,@last_commit_time_sec, @last_commit_time_pri) * 1000, 0), 114)
end
print 'RPO of database '+ @db_name +' is ' + @RPO
end
- ターゲット セカンダリ データベースの group_id、replica_id、group_database_id を指定して、proc_calculate_RPO を実行します。
exec proc_calculate_RPO @group_id= 'F176DD65-C3EE-4240-BA23-EA615F965C9B',
@replica_id = '405554F6-3FDC-4593-A650-2067F5FABFFD',
@group_database_id = '39F7942F-7B5E-42C5-977D-02E7FFA6C392'
- 出力には、ターゲット セカンダリ レプリカ データベースの RPO の値が表示されます。
RTO と RPO の監視
このセクションでは、可用性グループの RTO および RPO メトリックを監視する方法を実演します。 この実演の内容は、「The Always On health model, part 2: Extending the health model」 (Always On 正常性モデル、パート 2: 正常性モデルの拡張) で提供している GUI のチュートリアルに類似しています。
フェールオーバー時間 (RTO) の推定 およびデータ損失の可能性 (RPO) の推定 におけるフェールオーバー時間の計算およびデータ損失の可能性の計算の要素は、ポリシー管理ファセット "データベース レプリカ状態" の中でパフォーマンス メトリックとして便利に提供されています (「SQL Server オブジェクトのポリシー ベースの管理ファセットの表示」を参照)。 この 2 つのメトリックはスケジュールに従って監視することができます。メトリックが指定の RTO および RPO を超えた場合はそれぞれアラートが返されます。
デモ スクリプトでは、以下の特性を備え、それぞれのスケジュールに従って実行される 2 つのシステム ポリシーが作成されます。
RTO ポリシーは 5 分ごとに評価され、推定フェールオーバー時間が 10 分を超えると失敗します。
RPO ポリシーは 30 分ごとに評価され、推定データ損失が 1 時間を超えると失敗します。
2 つのポリシーの構成は、すべての可用性レプリカ上で同じです。
ポリシーはすべてのサーバー上で評価されますが、可用性グループ上ではローカルの可用性レプリカがプライマリ レプリカである場合にのみ評価されます。 ローカルの可用性レプリカがプライマリ レプリカでない場合、ポリシーは評価されません。
プライマリ レプリカ上で Always On ダッシュボードを表示すると、ポリシー エラーを容易に確認できます。
ポリシーを作成するには、可用性グループに参加しているすべてのサーバー インスタンス上で次の手順を実行します。
まだ開始していない場合は、SQL Server エージェント サービスを開始します。
SQL Server Management Studio で、 [ツール] メニューの [オプション] をクリックします。
[SQL Server Always On] タブで [ユーザー定義の Always On ポリシーを有効にする] を選択し、 [OK] をクリックします。
この設定により、適切に構成されたカスタム ポリシーを Always On ダッシュボードに表示できるようになります。
次の仕様に基づいてポリシー ベースの管理条件を作成します。
名前:
RTOファセット: データベース レプリカ状態
フィールド:
Add(@EstimatedRecoveryTime, 60)演算子: <=
値:
600
この条件は、潜在的なフェールオーバー時間が 10 分 (エラー検出とフェールオーバーの両方ための 60 秒のオーバーヘッドも含まれる) を超えると失敗します。
次の仕様に基づいて 2 番目のポリシー ベースの管理条件を作成します。
名前:
RPOファセット: データベース レプリカ状態
フィールド:
@EstimatedDataLoss演算子: <=
値:
3600
この条件は、データ損失の可能性が 1 時間を超えると失敗します。
次の仕様に基づいて 3 番目のポリシー ベースの管理条件を作成します。
名前:
IsPrimaryReplicaファセット: 可用性グループ
フィールド:
@LocalReplicaRole演算子: =
値:
Primary
この条件では、特定の可用性グループのローカルの可用性レプリカがプライマリ レプリカであるかどうかがチェックされます。
次の仕様に基づいてポリシー ベースの管理ポリシーを作成します。
[全般] ページ:
名前:
CustomSecondaryDatabaseRTO条件の確認:
RTO対象: IsPrimaryReplica AvailabilityGroup のすべての DatabaseReplicaState
この設定により、ポリシーは必ず、ローカルの可用性レプリカがプライマリ レプリカである可用性グループのみで評価されます。
[評価モード] :スケジュールで実行
[スケジュール] :CollectorSchedule_Every_5min
有効: 選択
[説明] ページ:
カテゴリ:可用性データベースの警告
この設定により、Always On ダッシュボードにポリシーの評価結果を表示できるようになります。
説明:検出とフェールオーバーのオーバーヘッドが 1 分であると仮定すると、現在のレプリカの RTO は 10 分を超えています。すぐに、それぞれのサーバー インスタンスでのパフォーマンスの問題を調査する必要があります。
表示するテキスト:RTO を超過しました!
次の仕様に基づいて 2 番目のポリシー ベースの管理ポリシーを作成します。
[全般] ページ:
名前:
CustomAvailabilityDatabaseRPO条件の確認:
RPO対象: IsPrimaryReplica AvailabilityGroup のすべての DatabaseReplicaState
[評価モード] :スケジュールで実行
[スケジュール] :CollectorSchedule_Every_30min
有効: 選択
[説明] ページ:
カテゴリ:可用性データベースの警告
説明:可用性データベースは、1 時間の RPO を超過しています。すぐに、可用性レプリカでのパフォーマンスの問題を調査する必要があります。
表示するテキスト:RPO を超過しました!
完了すると、2 つの新しい SQL Server エージェント ジョブが作成されます (各ポリシー評価スケジュールに対して 1 つ)。 これらのジョブの名前は、syspolicy_check_schedule で始める必要があります。
評価結果を検査するために、ジョブの履歴を表示することができます。 評価エラーは、イベント ID 34052 で Windows アプリケーション ログ (イベント ビューアー内) にも記録されます。 また、ポリシー エラー発生時にアラートを送信するように SQL Server エージェントを構成することもできます。 詳細については、「ポリシー管理者にポリシー エラーを通知する警告の構成」を参照してください。
パフォーマンスのトラブルシューティング シナリオ
次の表に、一般的なパフォーマンスに関連するトラブルシューティング シナリオを示します。
| シナリオ | 説明 |
|---|---|
| トラブルシューティング:可用性グループ接続の超過 RTO | データ損失のない自動フェールオーバーまたは計画的な手動フェールオーバーの後で、フェールオーバー時間が RTO を超過します。 または、同期コミット セカンダリ レプリカのフェールオーバー時間を推定したとき (自動フェールオーバー パートナーなど)、RTO を超過していることが判明します。 |
| トラブルシューティング:可用性グループ接続の超過 RPO | 強制的な手動フェールオーバーを実行した後で、データ損失が RPO より大きくなります。 または、非同期コミット セカンダリ レプリカのデータ損失の可能性を計算したとき、計算結果が RPO を超過していることが判明します。 |
| トラブルシューティング:プライマリ上の変更がセカンダリ レプリカに反映されない | クライアント アプリケーションは、プライマリ レプリカの更新を正常に完了しますが、セカンダリ レプリカのクエリを実行すると、変更が反映されていないことが示されます。 |
有用な拡張イベント
同期中の状態にあるレプリカのトラブルシューティングを行う場合は、次の拡張イベントは便利です。
| イベント名 | カテゴリ | チャネル | 可用性レプリカ |
|---|---|---|---|
| redo_caught_up | トランザクション | デバッグ | セカンダリ |
| redo_worker_entry | トランザクション | デバッグ | セカンダリ |
| hadr_transport_dump_message | alwayson |
デバッグ | プライマリ |
| hadr_worker_pool_task | alwayson |
デバッグ | プライマリ |
| hadr_dump_primary_progress | alwayson |
デバッグ | プライマリ |
| hadr_dump_log_progress | alwayson |
デバッグ | プライマリ |
| hadr_undo_of_redo_log_scan | alwayson |
分析 | セカンダリ |
フィードバック
以下は間もなく提供いたします。2024 年を通じて、コンテンツのフィードバック メカニズムとして GitHub の issue を段階的に廃止し、新しいフィードバック システムに置き換えます。 詳細については、「https://aka.ms/ContentUserFeedback」を参照してください。
フィードバックの送信と表示