可用性グループのレプリカのアップグレード
適用対象:![]() SQL Server
SQL Server
Always On 可用性グループ (AG) をホストする SQL Server インスタンスを新しい SQL Server バージョン、新しい SQL Server サービス パックまたは累積更新プログラムにアップグレードしている場合、または新しい Windows サービス パックまたは累積更新プログラムにインストールしている場合、ローリング アップグレードを実行して、単一の手動フェールオーバー (または、元のプライマリにフェールバックする場合は、2 回の手動フェールオーバー) におけるプライマリ レプリカのダウンタイムを減らすことができます。
アップグレード プロセス中に、セカンダリ レプリカはフェールオーバーや読み取り専用操作を行うことができなくなります。また、アップグレード後は、プライマリ レプリカ ノード上のアクティビティ量に応じて、プライマリ レプリカ ノードを検出するセカンダリ レプリカの時間がかかる場合があります (そのため、高いネットワーク トラフィック量が予想されます)。
また、新しいバージョンの SQL Server を実行しているセカンダリ レプリカに最初にフェールオーバーした後は、その AG のデータベースは、最新バージョンに移動するためにアップグレード プロセス経由で実行されることに注意してください。 この間、これらのいずれのデータベースにも読み取り可能なレプリカはありません。 最初のフェールオーバー後のダウンタイムは、AG に含まれるデータベースの数によって異なります。 元のプライマリへのフェールバックを計画する場合、フェールバックするときに、この手順が繰り返されることはありません。
Note
この記事では、SQL Server 自体のアップグレードについてのみ説明します。 これには、Windows Server フェールオーバー クラスター (WSFC) を含む、オペレーティング システムのアップグレードは含まれません。 フェールオーバー クラスターをホストしている Windows オペレーティング システムのアップグレードは、Windows Server 2012 R2 より前のオペレーティング システムではサポートされません。 Windows Server 2012 R2 で実行されているクラスター ノードのアップグレードについては、「Cluster Operating System Rolling Upgrade」(クラスター オペレーティング システムのローリング アップグレード) を参照してください。
前提条件
作業を開始する前に、次の重要な情報を確認してください。
サポートされるバージョンとエディションのアップグレード: お使いのバージョンの Windows オペレーティング システムと SQL Server から最新のバージョンの SQL Server にアップグレードできることを確認します。 たとえば、SQL Server 2005 インスタンスから直接アップグレードした場合、データベース互換レベルがアップグレードされます。
データベース エンジンのアップグレード方法の選択: 正しい順序でアップグレードするには、サポートされるバージョンとエディションのアップグレードに基づいて、また、自分の環境にインストールされているその他のコンポーネントに基づいて、適切なアップグレードの方法と手順を選択します。
データベース エンジンのアップグレード計画の策定およびテスト:リリース ノート、アップグレードに関する既知の問題、アップグレード前のチェックリストを確認して、アップグレードの計画を作成およびテストします。
SQL Server のインストールに必要なハードウェアおよびソフトウェア:SQL Server のインストールにおけるソフトウェア要件を確認します。 その他のソフトウェアが必要な場合は、ダウンタイムを最小限に抑えるために、アップグレード プロセスを開始する前に、各ノードにソフトウェアをインストールします。
変更データ キャプチャまたはレプリケーションを AG データベースに使用するかどうかの確認: AG のデータベースを変更データ キャプチャ (CDC) に対して有効にする場合は、この手順を完了してください。
Note
同じ AG 内で SQL Server インスタンスのバージョンが混在することは、ローリング アップグレード以外ではサポートされていません。また、アップグレードはすぐに実行されるため、長期間その状態のままにしないでください。 SQL Server 2016 (13.x) 以降のバージョンをアップグレードするには、分散可用性グループを使用する方法もあります。
可用性グループのローリング アップグレードの基本
サーバーのアップグレードまたは更新を行う時に、AG のダウンタイムとデータ損失を最小限に抑えるには、次のガイドラインに従ってください。
ローリング アップグレードを始める前に:
少なくとも 1 つの同期コミット レプリカ インスタンスで試験的に手動フェールオーバーを実行する。
すべての可用性データベースを対象にデータベースの完全バックアップを実行し、データを保護する。
すべての可用性データベースに対して
DBCC CHECKDBコマンドを実行する
常に、最初はリモートのセカンダリ レプリカ ノード、次にローカルのセカンダリ レプリカ インスタンス、最後にプライマリ レプリカ インスタンスという順序でアップグレードしてください。
アップグレード中のデータベースでバックアップを実行することはできません。 セカンダリ レプリカをアップグレードする前に、プライマリ レプリカでのみバックアップを実行するように自動バックアップ設定を構成します。 バージョンのアップグレード中に、レプリカをバックアップ用に読み取ったり、使用したりすることはできません。 バージョン以外のアップグレード時には、プライマリ レプリカをアップグレードする前に、セカンダリ レプリカで実行するように自動化されたバックアップを構成できます。
バージョン アップグレード中、読み取り可能なセカンダリがアップグレードされてから、プライマリ レプリカがアップグレード済みのセカンダリにフェールオーバーされるまで、またはプライマリ レプリカがアップグレードされるまでの間、読み取り可能なセカンダリを読み取ることはできません。
アップグレード プロセスの間に AG が誤ってフェールオーバーされることを防ぐために、作業開始前にすべての同期コミット レプリカから可用性フェールオーバーを削除してください。
最初にセカンダリ レプリカを使用してアップグレードされたインスタンスに AG をフェールオーバーする前に、プライマリ レプリカ インスタンスをアップグレードしないでください。 このベスト プラクティスに従わなかった場合、プライマリ レプリカ インスタンスでのアップグレード時にクライアント アプリケーションで長時間のダウンタイムが発生する可能性があります。
AG は常に同期コミット セカンダリ レプリカ インスタンスにフェールオーバーしてください。 非同期コミット セカンダリ レプリカ インスタンスにフェールオーバーした場合、データベースでデータ損失が発生しやすく、データ移動が自動的に中断されます。データ移動を再開するには、手動で操作する必要があります。
他のセカンダリ レプリカ インスタンスをアップグレードまたは更新する前に、プライマリ レプリカ インスタンスをアップグレードしないでください。 アップグレードされたプライマリ レプリカから、同じバージョンにまだアップグレードされていない SQL Server インスタンスのあるセカンダリ レプリカにログを送信できなくなります。 セカンダリ レプリカへのデータ移動が中断されているときには、そのレプリカに対する自動フェールオーバーは実行されず、可用性データベースでデータ損失が発生する危険性が高まります。 これは、古いプライマリから新しいプライマリに手動でフェールオーバーするローリング アップグレード中にも適用されます。 そのため、古いプライマリをアップグレードした後、同期の再開が必要になる場合があります。
AG をフェールオーバーする前に、フェールオーバー ターゲットの同期状態が
SYNCHRONIZEDであることを確認してください。警告
古いバージョンの SQL Server がインストールされているサーバーに新しいインスタンスまたは新しいバージョンの SQL Server をインストールすると、古いバージョンの SQL Server でホストされている可用性グループが誤って停止する可能性があります。これは、インスタンスまたは SQL Server のバージョンのインストール中に、SQL Server 高可用性モジュール (RHS.EXE) がアップグレードされるためです。 これにより、サーバー上のプライマリ ロール内の既存の可用性グループが一時的に中断します。 そのため、可用性グループが使用されている古いバージョンの SQL Server を既にホストしているシステムに、新しいバージョンの SQL Server をインストールするときは、次のいずれかのようにすることを強くお勧めします。
メンテナンス期間中に、新しいバージョンの SQL Server をインストールします。
可用性グループをセカンダリ レプリカにフェールオーバーして、新しい SQL Server インスタンスのインストールの間はプライマリではないようにします。
ローリング アップグレード プロセス
実際のプロセスは、AG の配置トポロジや各レプリカのコミット モードなどの要因によって変わります。 ただし、最も単純なシナリオにおけるローリング アップグレードは、次の手順で構成される単純な複数段階のプロセスになります。
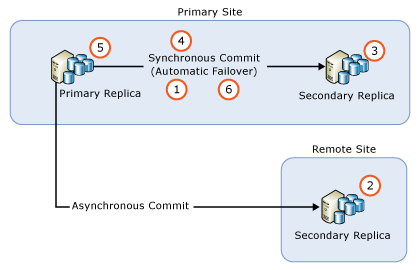
- すべての同期コミット レプリカの自動フェールオーバーを削除する。
- すべての非同期コミット セカンダリ レプリカ インスタンスをアップグレードする。
- すべてのリモート同期コミット セカンダリ レプリカ インスタンスをアップグレードする。
- すべてのローカル同期コミット セカンダリ レプリカ インスタンスをアップグレードする。
- AG を手動で (新規にアップグレードした) ローカルの同期コミット セカンダリ レプリカにフェールオーバーする。
- それまでプライマリ レプリカをホストしていたローカルのレプリカ インスタンスをアップグレードまたは更新する。
- 必要に応じて自動フェールオーバー パートナーを構成する。
必要であれば、さらに手動でフェールオーバーを実行して、AG を元の構成に戻すこともできます。
Note
同期コミット レプリカをアップグレードしてそれをオフラインにしても、プライマリのトランザクションは遅延しません。 セカンダリ レプリカを切断すると、セカンダリ レプリカにログが書き込まれるのを待たずに、トランザクションはプライマリにコミットされます。
REQUIRED_SYNCHRONIZED_SECONDARIES_TO_COMMIT が 1 または 2 に設定されている場合、更新処理中に対応する数の同期セカンダリ レプリカを使用できないときは、プライマリ レプリカを読み書きできない場合があります。
注意
セカンダリ レプリカを新しいバージョンのSQL Serverにインプレース アップグレードすると、可用性グループ内のデータベースは、可用性グループが手動でフェールオーバーされるまで、同期中/復旧中または同期済/復旧中状態のままになり、データベースの復旧とアップグレードが完了します。 アップグレードされたプライマリ レプリカは、下位バージョンのセカンダリ レプリカにログを送信できなくなり、データ移動が停止し、そのレプリカに対して自動フェールオーバーが発生しなくなるため、可用性データベースはデータ損失に対して脆弱になります。 古いプライマリをアップグレードした後、同期の再開が必要になる場合があります。 新しいバージョンのレプリカにフェールオーバーする前に、すべてのセカンダリ レプリカをアップグレードすることを推奨します。 これにより、データベースを新しい形式にアップグレードした後にフェールオーバーを実行できます。
1 つのリモート セカンダリ レプリカを含む AG
ディザスター リカバリーのみを目的として AG を配置していた場合、AG を非同期コミット セカンダリ レプリカにフェールオーバーする必要がある場合があります。 次の図に、そのような構成の例を示します。
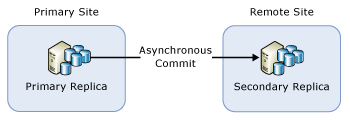
この場合には、ローリング アップグレード時に AG を非同期コミット セカンダリ レプリカにフェールオーバーする必要があります。 データ損失を防ぐために、コミット モードを同期コミットに変更し、セカンダリ レプリカが同期されるまで待ってから、AG をフェールオーバーします。 そのため、ローリング アップグレードのプロセスは次のようになります。
- リモート サイトのセカンダリ レプリカ インスタンスをアップグレードする。
- コミット モードを同期コミットに変更する。
- 同期状態が
SYNCHRONIZEDになるまで待機する - AG をリモート サイトのセカンダリ レプリカにフェールオーバーする
- ローカル (プライマリ サイト) のレプリカ インスタンスをアップグレードまたは更新する。
- AG をプライマリ サイトにフェールオーバーして戻す
- コミット モードを非同期コミットに変更する。
同期コミット モードはリモート サイトとのデータ同期には推奨されない設定であるため、設定の変更後、クライアント アプリケーションでデータベース待機時間が急増する可能性があります。 さらに、フェールオーバーを実行すると未確認のログ メッセージがすべて破棄されます。 2 つのサイト間のネットワーク待機時間が長いと、破棄されるログ メッセージの数が膨大になり、クライアントで大量のトランザクション エラーが発生することがあります。 クライアント アプリケーションへの影響を最小限に抑えるには、次のようにします。
クライアント トラフィックが少ない時間帯にメンテナンス予定を設定する。
プライマリ サイトの SQL Server をアップグレードまたは更新するときに、可用性モードを非同期コミットに戻し、もう一度プライマリ サイトへのフェールオーバーの準備が完了したときに、同期コミットに戻す。
フェールオーバー クラスター インスタンス ノードを含む AG
AG にフェールオーバー クラスター インスタンス (FCI) ノードが含まれている場合、非アクティブなノードをアップグレードした後で、アクティブなノードをアップグレードする必要があります。 次の図では、ローカルでの可用性を高めるために FCI を使用し、リモートのディザスター リカバリーのために FCI 間の非同期コミットを使用する、一般的な AG のシナリオを示します。さらに、アップグレード手順も示しています。
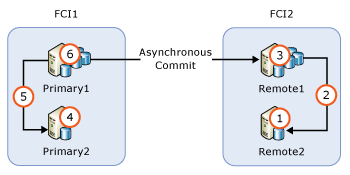
REMOTE2をアップグレードまたは更新する- FCI2 を
REMOTE2にフェールオーバーする REMOTE1をアップグレードまたは更新するPRIMARY2をアップグレードまたは更新する- FCI1 を
PRIMARY2にフェールオーバーする PRIMARY1をアップグレードまたは更新する
複数の AG を含む SQL Server インスタンスをアップグレードまたは更新する
プライマリ レプリカが別々のサーバー ノード (アクティブ/アクティブ構成) に存在する AG が複数実行されている場合、アップグレード時にはプロセスの高可用性を維持するためのフェールオーバー手順を追加で実行する必要があります。 次の表に示すように、3 つのサーバー ノードで 3 つの AG が実行され、すべてのレプリカが同期コミット モードで実行されているとします。
| AG | Node1 | Node2 | Node3 |
|---|---|---|---|
| AG1 | プライマリ | ||
| AG2 | プライマリ | ||
| AG3 | プライマリ |
この状況では、次の順序で負荷分散ローリング アップグレードを実行することが適切であると考えられます。
- AG2 を
Node3にフェールオーバーする (Node2を解放するため) Node2をアップグレードまたは更新する- AG1 を
Node2にフェールオーバーする (Node1を解放するため) Node1をアップグレードまたは更新する- AG2 と AG3 を
Node1にフェールオーバーする (Node3を解放するため) Node3をアップグレードまたは更新する- AG3 を
Node3にフェールオーバーする
この順序でアップグレードを実行した場合、1 つの AG に対して 2 回のフェールオーバーを実行するよりも平均ダウンタイムが短くなります。 実行後の構成は、次の表のようになります。
| AG | Node1 | Node2 | Node3 |
|---|---|---|---|
| AG1 | プライマリ | ||
| AG2 | プライマリ | ||
| AG3 | プライマリ |
実際の実装方法に応じて、アップグレードの手順が変わる可能性があります。また、クライアント アプリケーションで発生するダウンタイムも変わります。
Note
多くの場合は、ローリング アップグレードが完了すると、元のプライマリ レプリカにフェールバックします。
分散型可用性グループのローリング アップグレード
分散型可用性グループのローリング アップグレードを実行するには、まずすべてのセカンダリ レプリカをアップグレードします。 次に、フォワーダーがフェールオーバーされ、セカンダリ可用性グループの最後の残りのインスタンスがアップグレードされます。 その他すべてのレプリカがアップグレードされると、グローバル プライマリがフェールオーバーされ、最初の可用性グループの最後の残りのインスタンスがアップグレードされます。 手順を含む詳細な図を次に示します。
実際の実装方法に応じて、アップグレードの手順が変わる可能性があります。また、クライアント アプリケーションで発生するダウンタイムも変わります。
Note
多くの場合は、ローリング アップグレードが完了すると、元のプライマリ レプリカにフェールバックされます。
分散型可用性グループをアップグレードする一般的な手順
- すべてのデータベース (システム データベースなど) および可用性グループに参加しているデータベースをバックアップします。
- セカンダリ可用性グループ (ダウンストリーム) のセカンダリ レプリカがすべてアップグレードおよび再起動されます。
- 最初の可用性グループ (アップストリーム) のセカンダリ レプリカがすべてアップグレードおよび再起動されます。
- フォワーダー プライマリがセカンダリ可用性グループのアップグレードされたセカンダリ レプリカにフェールオーバーされます。
- データ同期を待ちます。 データベースはすべての同期コミット レプリカ上で同期されたと示され、グローバル プライマリはフォワーダーと同期されます。
- セカンダリ可用性グループの最後の残りのインスタンスがアップグレードして再起動されます。
- グローバル プライマリが最初の可用性グループのアップグレードされたセカンダリにフェールオーバーされます。
- プライマリ可用性グループの最後の残りのインスタンスがアップグレードされます。
- 新しくアップグレードされたサーバーが再起動されます。
- (省略可能) 両方の可用性グループが元のプライマリ レプリカにフェールバックされます。
重要
すべてのステップ間の同期を確認します。 次のステップに進む前に、同期コミット レプリカが可用性グループ内で同期され、グローバル プライマリが分散型 AG 内のフォワーダーと同期されていることを確認します。
推奨事項:同期を確認するたびに、データベース ノードと SQL Server Management Studio 内の分散型 AG ノードの両方を更新してください。 すべてが同期された後に、各レプリカの状態のスクリーンショットを保存します。 これは、現在のステップを追跡したり、次のステップに進む前にすべてが正常に作業されたという証拠を提供したり、問題が発生した場合にトラブルシューティングでサポートを行ったりするのに役立ちます。
分散型可用性グループのローリング アップグレードの例の図
| 可用性グループ | プライマリ レプリカ | セカンダリ レプリカ |
|---|---|---|
| AG1 | NODE1\SQLAG |
NODE2\SQLAG |
| AG2 | NODE3\SQLAG |
NODE4\SQLAG |
| DistributedAG | AG1 (グローバル) | AG2 (フォワーダー) |
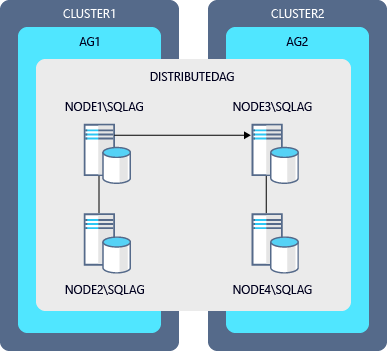
この図のインスタンスをアップグレードするステップ
- すべてのデータベース (システム データベースなど) および可用性グループに参加しているデータベースをバックアップします。
NODE4\SQLAG(AG2 のセカンダリ) をアップグレードして、サーバーを再起動します。NODE2\SQLAG(AG1 のセカンダリ) をアップグレードして、サーバーを再起動します。- AG2 を
NODE3\SQLAGからNODE4\SQLAGにフェールオーバーします。 NODE3\SQLAGをアップグレードして、サーバーを再起動します。- AG1 を
NODE1\SQLAGからNODE2\SQLAGにフェールオーバーします。 NODE1\SQLAGをアップグレードして、サーバーを再起動します。- (省略可能) 元のプライマリ レプリカにフェールバックされます。
- AG2 を
NODE4\SQLAGからNODE3\SQLAGにフェールバックします。 - AG1 を
NODE2\SQLAGからNODE1\SQLAGにフェールバックします。
- AG2 を
各可用性グループに 3 番目のレプリカが存在する場合は、NODE3\SQLAG と NODE1\SQLAG の前にアップグレードします。
重要
すべてのステップ間の同期を確認します。 次のステップに進む前に、同期コミット レプリカが可用性グループ内で同期され、グローバル プライマリが分散型 AG 内のフォワーダーと同期されていることを確認します。
推奨事項: 同期を確認するたびに、データベース ノードと SQL Server Management Studio 内の分散型 AG ノードの両方を更新してください。 すべてが同期された後は、スクリーンショットを取得して保存します。 これは、現在のステップを追跡したり、次のステップに進む前にすべてが正常に作業されたという証拠を提供したり、問題が発生した場合にトラブルシューティングでサポートを行ったりするのに役立ちます。
変更データ キャプチャまたはレプリケーションの特別な手順
更新が適用されているかによって、変更データ キャプチャまたはレプリケーションを有効にしている AG レプリカ データベースに対して追加の手順が必要な場合があります。 次の手順が必要かどうかを確認するには、更新プログラムのリリース ノートを参照してください。
各セカンダリ レプリカをアップグレードします。
すべてのセカンダリ レプリカがアップグレードされてから、AG をアップグレードされたインスタンスにフェール オーバーします。
プライマリ レプリカをホストするインスタンスで、次の Transact-SQL を実行します。
EXECUTE [master].[sys].[sp_vupgrade_replication];Note
このコマンドの実行には数分かかることがあります。 SQL Server 2019 CU1 以降の場合は、この手順をスキップしてください。 詳細については、KB4530283 を参照してください。
元はプライマリ レプリカであったインスタンスをアップグレードします。
背景情報については、最新の CU へのアップグレード後に CDC の機能が動作しない場合に関するページを参照してください。
関連項目
フィードバック
以下は間もなく提供いたします。2024 年を通じて、コンテンツのフィードバック メカニズムとして GitHub の issue を段階的に廃止し、新しいフィードバック システムに置き換えます。 詳細については、「https://aka.ms/ContentUserFeedback」を参照してください。
フィードバックの送信と表示