ビジネス継続性とデータベースの復旧 - SQL Server
適用対象:![]() SQL Server 2016 (13.x) 以降のバージョン
SQL Server 2016 (13.x) 以降のバージョン
この記事では、Windows と Linux 上の SQL Server での高可用性とディザスター リカバリーのためのビジネス継続性ソリューションの概要を説明します。
SQL Server を展開するすべての人が行う必要がある 1 つの共通タスクは、すべてのミッション クリティカルな SQL Server インスタンスとそれらに含まれるデータベースを、ビジネスおよびエンド ユーザーが必要とするときに (9 時から 5 時であろうと、24 時間であろうと) 使えるようにすることです。 目標は、最小限の中断または中断なく、ビジネスを継続させることです。 この概念は、"ビジネス継続性" とも呼ばれます。
SQL Server 2017 (14.x) では、多くの新機能の導入と、既存機能への強化が行われ、そのいくつかは可用性に対するものでした。 SQL Server 2017 (14.x) の最大の補強は、Linux ディストリビューションでの SQL Server のサポートでした。 SQL Server でのすべての新機能の一覧については、次の記事をご覧ください。
- SQL Server 2017 の新機能
- SQL Server 2017 on Linux の新機能
- SQL Server 2019 の新機能
- SQL Server 2019 on Linux の新機能
- SQL Server 2022 の新機能
この記事では、SQL Server 2017 (14.x) 以降のバージョンでの可用性シナリオと、新規および強化された可用性機能について重点的に取り上げます。 シナリオには、Windows Server と Linux の両方にまたがって SQL Server を展開できるハイブリッドなものと、データベースの読み取り可能なコピーの数を増やすことができるものが含まれます。
この記事では、SQL Server 以外の可用性オプション (仮想化によって提供されるものなど) については扱いませんが、ここで説明している内容はすべて、パブリック クラウド内であれ、オンプレミスのハイパーバイザー サーバーでホストされる場合であれ、ゲスト仮想マシン内での SQL Server のインストールに適用されます。
可用性機能を使用した SQL Server のシナリオ
Always On 可用性グループ、Always On フェールオーバー クラスター インスタンス、ログ配布は、さまざまな方法で使用でき、必ずしも可用性を高めることだけが目的ではありません。 可用性機能を使用できる 4 つの主な方法があります。
- 高可用性
- 障害復旧
- 移行とアップグレード
- 1 つ以上のデータベースの読み取り可能なコピーのスケール アウト
以下のセクションでは、その特定のシナリオに使用できる関連機能について説明します。 SQL Server レプリケーションの機能については、取り上げません。 これは Always On の傘下の可用性機能としては正式に指定されていませんが、特定のシナリオでデータに冗長性を持たせるために SQL Server のレプリケーションがよく使用されます。 SQL Server on Linux では、マージ レプリケーションはサポートされていません。 詳細については、「Linux 上の SQL Server レプリケーション」を参照してください。
重要
SQL Server の可用性機能は、可用性ソリューションの最も基本的なビルディング ブロックである、堅牢で十分にテストされたバックアップと復元方法を持つという要件に取って代わるものではありません。
高可用性
データ センターで局所的に、またはクラウド内の 1 つのリージョンで問題が発生した場合に、SQL Server インスタンスまたはデータベースを使用できることを保証することが重要です。 このセクションでは、SQL Server の可用性機能がそのタスクでどのように役立つかを説明します。 記載されているすべての機能は、Windows Server と Linux の両方で使用できます。
可用性グループ
SQL Server 2012 (11.x) で導入された可用性グループ (AG) は、データベースの各トランザクションを、そのデータベースの特別な状態のコピーが含まれる別のインスタンス ("レプリカ") に送信することによって、データベース レベルの保護を提供します。 AG は、Standard または Enterprise エディションに展開できます。 AG に参加しているインスタンスは、スタンドアロンまたはフェールオーバー クラスター インスタンス (FCI、次のセクションで説明) のいずれかにすることができます。 トランザクションは、発生したときにレプリカに送信されるため、目標復旧時点と目標復旧時間の要件がより低い AG が推奨されます。 レプリカ間のデータ移動は、同期または非同期で行うことができ、Enterprise エディションでは最大 3 つのレプリカ (プライマリを含む) の同期が許可されます。 AG には、プライマリ レプリカにあるデータベースの完全な読み取り/書き込みコピーが 1 つありますが、すべてのセカンダリ レプリカはエンド ユーザーやアプリケーションから直接トランザクションを受け取れません。
注意
Always On は SQL Server での可用性機能の総称で、AG と FCI の両方が含まれます。 Always On は、AG 機能の名前ではありません。
SQL Server 2022 (16.x) より前の AG では、データベース レベルのみが提供され、インスタンス レベルの保護は提供されません。 トランザクション ログにキャプチャされていないものや、データベースに構成されていないものはすべて、セカンダリ レプリカごとに手動で同期する必要があります。 手動で同期する必要があるオブジェクトの例としては、インスタンス レベル、リンク サーバー、および SQL Server エージェント ジョブでのログインがあります。
SQL Server 2022 (16.x) 以降では、ユーザーは、インスタンス レベルに加えて、AG レベルでユーザー、ログイン、アクセス許可、SQL Server エージェント ジョブなどのメタデータ オブジェクトを管理できます。 詳しくは、包含可用性グループに関する記事をご覧ください。
AG には、"リスナー" と呼ばれる別のコンポーネントもあります。これにより、アプリケーションとエンド ユーザーは、プライマリ レプリカをホストしている SQL Server インスタンスがわからなくても接続できます。 各 AG には、独自のリスナーがあります。 リスナーの実装は、Windows Server と Linux ではわずかに異なりますが、提供される機能とその使用方法は同じです。 次の図は、Windows Server フェールオーバー クラスター (WSFC) を使っている Windows Server ベースの AG を示したものです。 OS レイヤーでの基になるクラスターは、Linux または Windows Server 上にあるかどうかに関係なく、可用性に必要です。 この例では、基になるクラスターが WSFC である 2 つのサーバー ("ノード") の単純な構成を示します。
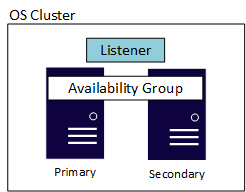
レプリカ数に関しては、Standard と Enterprise エディションで最大数が異なります。 Standard エディションの AG (基本的な可用性グループ) は、AG 内で 2 つのレプリカ (プライマリとセカンダリ) と 1 つのデータベースのみをサポートします。 Enterprise エディションは、1 つの AG に複数のデータベースを構成できるだけでなく、最大 9 つのレプリカ (1 つのプライマリ、8 つのセカンダリ) を持つこともできます。 Enterprise Edition では、読み取り可能なセカンダリ レプリカ、セカンダリ レプリカからバックアップを作成するなど、その他の利点ももたらされます。
Note
SQL Server 2012 (11.x) で非推奨とされたデータベース ミラーリングは、Linux バージョンの SQL Server では使用できず、追加される予定もありません。 まだデータベース ミラーリングを使っているお客様は、データベース ミラーリングの後継である AG への移行を計画する必要があります。
可用性に関しては、AG は自動または手動のフェールオーバーを提供できます。 自動フェールオーバーは、同期データ移動が構成されていて、プライマリとセカンダリのレプリカ上のデータベースが同期状態にある場合に発生する可能性があります。 リスナーが使われていて、アプリケーションが新しいバージョンの .NET Framework (更新プログラムが提供された 3.5、または 4.0 以降) を使っている限り、フェールオーバーは、リスナーが利用される場合はエンド ユーザーに対する影響が最小限になるか、ないように処理されるはずです。 セカンダリ レプリカを新しいプライマリ レプリカにするフェールオーバーは、自動または手動に構成でき、通常は数秒で測定されます。
次の一覧は、Windows Server と Linux での AG に関するいくつかの違いを示したものです。
- Linux と Windows Server での基になるクラスターの動作の違いにより、AG のすべてのフェールオーバー (手動または自動) は、Linux 上のクラスターを介して行われます。 Windows Server ベースの AG の展開では、手動フェールオーバーは SQL Server 経由で行う必要があります。 自動フェールオーバーは、Windows Server でも Linux でも基になるクラスターによって処理されます。
- SQL Server on Linux の場合は、少なくとも 3 つのレプリカで AG を構成することをお勧めします。 これは、基になるクラスタリングの動作方法に起因します。
- Linux では、各リスナーで使用される共通名は、Windows Server のようにクラスターではなく、DNS で定義されます。
SQL Server 2017 (14.x) 以降の AG には、いくつかの新機能と機能強化があります。
- クラスターの種類
- REQUIRED_SECONDARIES_TO_COMMIT
- Windows Server ベースの構成に対する Microsoft 分散トランザクション コーディネーター (DTC) サポートの強化
- 読み取り専用データベースに対するスケール アウト シナリオの追加 (この記事内で後ほど説明)
可用性グループのクラスターの種類
Windows Server でのクラスタリングの組み込みの可用性フォームは、フェールオーバー クラスタリングと呼ばれる機能を通じて有効化されます。 これにより、AG または FCI で使用される WSFC を構築できます。 AG と FCI 用の統合は、SQL Server に付属するクラスター対応のリソース DLL で提供されます。
SQL Server on Linux では、複数のクラスタリング テクノロジがサポートされています。 Microsoft は SQL Server コンポーネントをサポートし、パートナーは関連するクラスタリング テクノロジをサポートしています。 たとえば、SQL Server on Linux では、Pacemaker と共に、HPE Serviceguard と DH2i DxEnterprise がクラスター ソリューションとしてサポートされています。
Windows ベースのフェールオーバー クラスターと Linux クラスター ソリューションは、相違点より類似点の方が多くあります。 どちらも個別のサーバーを使用してそれらを構成で結合し、可用性を提供する方法を提供し、リソース、制約 (異なる方法で実装されている場合でも)、フェールオーバーなどの概念を持っています。
たとえば、自動フェールオーバーなど、AG と FCI の両方の構成で Pacemaker をサポートするために Microsoft が提供している Pacemaker 用の mssql-server-ha パッケージは、WSFC でのリソース DLL に似ていますが、まったく同じではありません。 WSFC と Pacemaker の違いの 1 つは、Pacemaker にはネットワーク名リソースがないことです。これは、WSFC でリスナーの名前 (または FCI の名前) を抽象化するのに役立つコンポーネントです。 DNS は、その名前解決を Linux 上で提供しています。
クラスター スタックの違いにより、SQL Server は WSFC によってネイティブに処理されるメタデータの一部を処理する必要があるため、AG に対していくつかの変更を行う必要があります。 そのような重要な変更の 1 つは、可用性グループに対する "クラスターの種類" の導入です。 これは、sys.availability_groups の cluster_type 列と cluster_type_desc 列に格納されます。 次の 3 つのクラスターの種類があります。
- WSFC
- 外部
- なし
高可用性を必要とするすべての AG で、基になるクラスターを使う必要があり、SQL Server 2017 (14.x) 以降のバージョンでは、これは WSFC または Linux クラスタリング エージェントを意味します。 基になる WSFC を使う Windows Server ベースの AG の場合は、既定のクラスターの種類が WSFC なので、設定する必要はありません。 Linux ベースの AG の場合は、AG を作成するときに、クラスターの種類を External に設定する必要があります。 Linux での外部クラスター ソリューションとの統合は、AG の作成後に構成されますが、WSFC では作成時に行われます。
None のクラスターの種類は、Windows Server と Linux 両方の AG で使用できます。 クラスターの種類を None に設定することは、AG で基になるクラスターが必要ないことを意味します。 つまり、SQL Server 2017 (14.x) は、クラスターなしで AG をサポートする最初の SQL Server のバージョンですが、そのトレードオフとして、この構成は高可用性ソリューションとしてサポートされません。
重要
SQL Server 2017 (14.x) 以降では、作成後に AG のクラスターの種類を変更することはできません。 つまり、AG を None から External または WSFC (またはその逆) に切り替えることはできません。
データベースの読み取り専用コピーをさらに追加することだけを検討しているユーザー、または移行やアップグレードを提供している AG は欲しいが、基になるクラスターやレプリケーションにより複雑さが増すことを好まないユーザーにとっては、クラスターの種類が None の AG が、最適なソリューションです。 詳しくは、「移行とアップグレード」と「読み取りスケール」のセクションをご覧ください。
次のスクリーンショットは、SQL Server Management Studio (SSMS) での異なるクラスターの種類のサポートを示しています。 17.1 以降のバージョンを実行する必要があります。 次のスクリーンショットはバージョン 17.2 のものです。

REQUIRED_SYNCHRONIZED_SECONDARIES_TO_COMMIT
SQL Server 2016 (13.x) では、Enterprise エディションでのサポートされる同期レプリカの数が 2 つから 3 つに増えました。 しかし、1 つのセカンダリ レプリカを同期したものの、他のレプリカで問題が発生した場合、動作を制御する方法がなく、プライマリ レプリカに誤動作しているレプリカを待機するか、先に進むかを指示できませんでした。 つまり、セカンダリ レプリカが同期されていない状態 (セカンダリ レプリカ上でデータの損失が発生している) でも、ある時点でプライマリ レプリカが書き込みトラフィックを受信し続けることになります。
SQL Server 2017 (14.x) 以降では、REQUIRED_SYNCHRONIZED_SECONDARIES_TO_COMMIT を使用して同期レプリカがある場合の動作を制御できます。 このオプションの動作は次のとおりです。
- 指定可能な 3 つの値は、
0、1、2です - 値は同期する必要があるセカンダリ レプリカの数で、データの損失、AG の可用性、およびフェールオーバーに影響します
- WSFC およびクラスターの種類 None の場合、既定値は
0で、手動で1または2に設定できます - クラスターの種類が External の場合、既定では、クラスター メカニズムによってこの値が設定され、手動でオーバーライドできます。 同期レプリカが 3 つの場合は、既定値は
1になります。
Linux では、REQUIRED_SYNCHRONIZED_SECONDARIES_TO_COMMIT の値はクラスター内の AG リソースで構成されます。 Windows では、Transact-SQL を使って設定します。
0 より大きい値は、より高いデータ保護を提供します。これは、必要な数のセカンダリ レプリカを使用できない場合は、それが解決されるまでプライマリを使用できないためです。 必要な数のセカンダリ レプリカが適切な状態でない場合、自動フェールオーバーが行われないため、REQUIRED_SYNCHRONIZED_SECONDARIES_TO_COMMIT はフェールオーバーの動作にも影響します。 Linux では、値 0 は自動フェールオーバーを許可しないため、Linux では、自動フェールオーバーで同期を使用する場合は、自動フェールオーバーを実現するため 0 より大きい値を設定する必要があります。 Windows Server での 0 は、SQL Server 2016 (13.x) 以前での動作です。
Microsoft 分散トランザクション コーディネーターのサポートの強化
SQL Server 2016 (13.x) より前では、表面下の DTC を使用する分散トランザクションを必要とするアプリケーションの SQL Server での可用性を取得する唯一の方法は、FCI を展開することでした。 分散トランザクションは、次の 2 つのいずれかの方法で実行できます。
- 同じ SQL Server インスタンスで複数のデータベースにまたがるトランザクション
- 複数の SQL Server インスタンスにまたがる、または場合によっては SQL Server 以外のデータ ソースが関与するトランザクション
SQL Server 2016 (13.x) では、後者のシナリオをカバーする AG で DTC の部分的なサポートが導入されました。 SQL Server 2017 (14.x) により、DTC を使用した両方のシナリオがサポートされるようになりました。
SQL Server 2017 (14.x) 以降のバージョンでは、AG を作成した後でも DTC サポートを追加できます。 SQL Server 2016 (13.x) では、AG で DTC のサポートを有効にできるのは、AG の作成時のみです。
フェールオーバー クラスター インスタンス
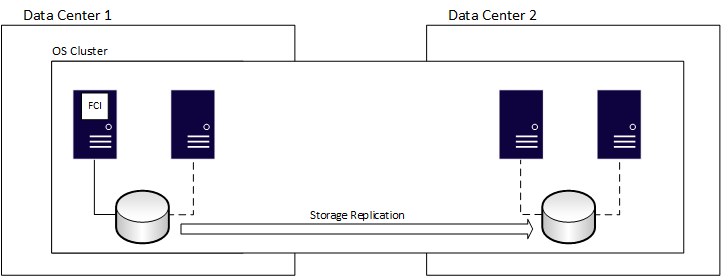
クラスター化されたインストールは、SQL Server バージョン 6.5 以降の機能です。 FCI は、インスタンスと呼ばれる SQL Server のインストール全体の可用性を実現する実証済みの方法です。 つまり、基になるサーバーに問題が生じると、データベース、SQL Server エージェント ジョブ、リンク サーバーなど、インスタンス内のすべてのものが別のサーバーに移動します。 すべての FCI には、何らかの共有ストレージが必要です。ネットワーク経由で提供されるものでもかまいません。 FCI のリソースを実行および所有できるのは、一度に 1 つのノードのみです。 次の図は、FCI を所有するクラスターの最初のノードを示しています。これは、それに関連付けられた共有ストレージ リソースを所有 (ストレージへの実線で示されています) していることも意味します。
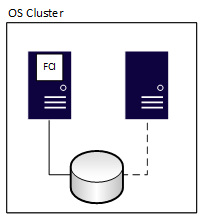
フェールオーバー後は、所有権は次の図にように変更されます。

FCI ではデータ損失は発生しませんが、データのコピーが 1 つ存在するため、基になる共有ストレージが単一障害点になります。 FCI は多くの場合、データベースの冗長コピーを持つために、AG やログ配布などの別の可用性メソッドと組み合わされます。 展開される追加の方法では、FCI と物理的に分離したストレージを使用してください。 FCI が別のノードにフェールオーバーすると、1 つのノードで停止してから別のノードで開始します。これはサーバーの電源をオフにしてからオンにするのと似ています。 FCI は、通常の復旧プロセスを行います。つまり、ロール フォワードする必要があるすべてのトランザクションと、完了していないすべてのトランザクションがロールバックされます。 したがって、データベースは、データ ポイントから障害または手動フェールオーバーの時点まで整合性があるため、データ損失が生じません。 データベースは、復旧が完了しないと利用できないため、復旧時間はさまざまな要因によって異なり、通常は AG のフェールオーバーより長くなります。 トレードオフとして、AG をフェールオーバーするときに、SQL Server エージェント ジョブを有効にするなど、データベースを使用できるようにするために追加タスクが必要になる場合があります。
AG と同様に、FCI は基になるクラスターのどのノードによってホストされているかを抽象化します。 FCI は常に同じ名前を保持します。 アプリケーションとエンド ユーザーはノードに接続せず、FCI に割り当てられている一意の名前が使用されます。 FCI は、プライマリまたはセカンダリのいずれかのレプリカをホストしているインスタンスの 1 つとして、AG に参加できます。
次のリストは、Windows Server と Linux 上の FCI でのいくつかの違いを示しています。
- Windows Server では、FCI はインストール プロセスの一部です。 Linux では、FCI は SQL Server のインストール後に構成されます。
- Linux は、ホストあたり 1 つの SQL Server のインストールしかサポートしないため、すべての FCI が既定のインスタンスになります。 Windows Server は、WSFC あたり最大 25 の FCI をサポートします。
- Linux で FCI によって使用される共通名は DNS で定義され、FCI 用に作成されたリソースと同じ名前である必要があります。
ログ配布
復旧ポイントの目標と復旧時間の目標により柔軟性がある場合、またはデータベースが非常にミッション クリティカルであると見なされていない場合は、ログ配布が SQL Server におけるもう 1 つの実証済みの可用性機能となります。 SQL Server のネイティブ バックアップに基づき、ログ配布のプロセスによってトランザクション ログ バックアップが自動的に生成され、ウォーム スタンバイ状態であることが判明している 1 つ以上のインスタンスにコピーされ、そのスタンバイにトランザクション ログ バックアップが自動的に適用されます。 ログ配布は、SQL Server エージェント ジョブを使用して、バックアップ、コピー、およびトランザクション ログ バックアップの適用のプロセスを自動化します。
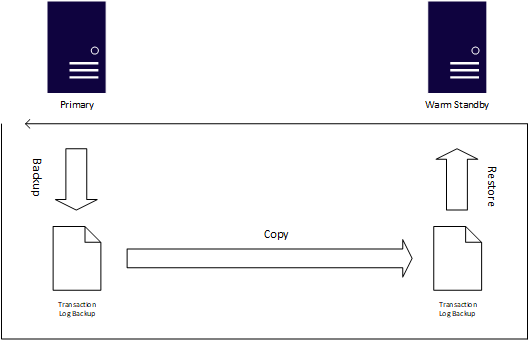
ほぼ間違いなく、一部の容量でログ配布を使用する最大の利点は、ヒューマン エラーに対処することです。 トランザクション ログの適用が遅れる場合があります。 そのため、他のユーザーが WHERE 句なしで UPDATE のようなものを発行すると、スタンバイに変更されずに、プライマリ システムの修復中にスタンバイに切り替えることができます。 ログ配布は構成が容易ですが、プライマリからウォーム スタンバイ状態に切り替える (ロール切り替えと呼ばれます) のは常に手動です。 ロール切り替えは Transact-SQL によって開始され、AG と同様に、トランザクション ログにキャプチャされないすべてのオブジェクトを手動で同期する必要があります。 1 つの AG には複数のデータベースを含めることができるのに対し、ログ配布はデータベースごとに構成する必要があります。
AG や FCI とは異なり、ログ配布にはロール切り替えの抽象化がなく、アプリケーションで処理できる必要があります。 DNS エイリアス (CNAME) などの手法も使用できますが、切り替え後に DNS の更新に時間がかかるなど、良い点と悪い点があります。
障害復旧
プライマリ可用性の場所で地震や洪水などの重大な事態が発生した場合、企業は自社のシステムを別の場所で稼働させるために準備する必要があります。 このセクションでは、SQL Server の可用性機能がビジネス継続性にどのように役立つことができるかを説明します。
可用性グループ
AG の利点の 1 つは、高可用性とディザスター リカバリーの両方を 1 つの機能を使用して構成できることです。 共有ストレージも高可用性にする必要はなく、高可用性のためのローカルのレプリカを 1 つのデータ センターに置き、ディザスター リカバリーのためのリモート レプリカをそれぞれ個別のストレージを使って他のデータ センターに置く方がはるかに簡単です。 データベースの追加のコピーを持つことは、冗長性を確保するためのトレードオフです。 複数のデータ センターにまたがる AG の例を次に示します。 1 つのプライマリ レプリカがすべてのセカンダリ レプリカの同期を維持する役割を担っています。

クラスターの種類が None の AG 以外では、AG は、すべてのレプリカが同じ基になるクラスターの一部である必要があります。WSFC または外部クラスター ソリューションであるかどうかは関係ありません。 これは、上の図では、WSFC が 2 つの異なるデータ センターで機能するために拡張され、複雑さが増すことを意味します。 プラットフォーム (Windows Server または Linux) は関係ありません。 離れた距離でクラスターを拡張することで、複雑さが増します。
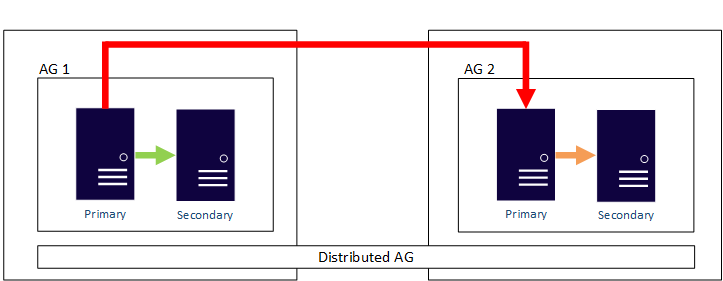
SQL Server 2016 (13.x) で導入された分散可用性グループにより、AG は異なるクラスター上に構成されている AG にまたがることができます。 分散 AG により、すべてのノードを同じクラスターに参加させるという要件から解放され、ディザスター リカバリーの構成がはるかに容易になります。 分散 AG について詳しくは、「分散型可用性グループ」をご覧ください。
フェールオーバー クラスター インスタンス
FCI はディザスター リカバリーに使用できます。 通常の AG と同様に、基になるクラスター メカニズムをすべての場所に拡張する必要もあり、複雑さが増します。 FCI には、共有ストレージという別の考慮事項があります。 プライマリとセカンダリのサイトで同じディスクを使用できる必要があります。 FCI によって使われるディスクを別の場所に置くには、ハードウェア レイヤーでストレージ ベンダーによって提供される機能などの外部の方法や、Windows Server でストレージ レプリカを使用する必要があります。
ログ配布
ログ配布は、SQL Server データベースにディザスター リカバリーを提供するための最も古い方法の 1 つです。 ログ配布は、他のオプションが環境、管理者のスキル、または予算のために困難な場合に、コスト効果の高い、よりシンプルなディザスター リカバリーを提供するために、AG や FCI と共に使われることがよくあります。 ログ配布用の高可用性のシナリオと同様に、ヒューマン エラーに対処するため、多くの環境でトランザクション ログの読み込みに遅延が生じます。
移行とアップグレード
新しいインスタンスを展開する場合、または古いものをアップグレードする場合に、ビジネスでは長時間の停止は許されません。 このセクションでは、SQL Server の機能を使用することで、計画的なアーキテクチャの変更、サーバーの切り替え、プラットフォームの変更 (Windows Server から Linux、またはその逆など)、または修正プログラムの適用時のダウンタイムをいかに最小限に抑えられるかについて説明します。
Note
移行とアップグレードでは、バックアップして他の場所でそれらを復元するなどの他の方法も使用できますが、 この記事では説明しません。
可用性グループ
1 つまたは複数の AG を含む既存のインスタンスは、新しいバージョンの SQL Server にインプレース アップグレードできます。 これにはある程度のダウンタイムが必要になりますが、適切に計画することで最小限に抑えることができます。
目標が構成変更 (オペレーティング システムまたは SQL Server のバージョンを含む) ではなく、新しいサーバーへの移行の場合、これらのサーバーをノードとして既存の基になるクラスターに追加して、AG に追加できます。 レプリカが正しい状態になったら、新しいサーバーに手動フェールオーバーしてから、古いサーバーを AG から削除し、最終的には使用停止にできます。
分散型可用性グループは、新しい構成に移行または SQL Server をアップグレードするもう 1 つの方法でもあります。 分散 AG は、異なるアーキテクチャ上でさまざまな基になる AG をサポートするため、たとえば、Windows Server 2012 R2 上で実行されている SQL Server 2016 (13.x) から Windows Server 2016 上で実行されている SQL Server 2017 (14.x) に変更できます。
最後に、クラスターの種類が None の AG は、移行またはアップグレードにも使用できます。 一般的な AG の構成では、クラスターの種類を混在させることができないため、すべてのレプリカの種類を None にする必要があります。 異なるクラスターの種類で構成された AG にまたがるには、分散 AG を使用できます。 この方法は異なる OS プラットフォームでもサポートされます。
移行とアップグレードに関する AG のすべてのバリエーションでは、最も時間のかかる作業の部分 (データの同期化) を徐々に実行できます。 新しい構成への切り替えを開始する場合、カットオーバーが短時間の停止であるのに対し、データの同期を含め、すべての作業が完了する必要がある場合は長時間のダウンタイムが発生します。
AG は、パッチの適用が完了するまで、プライマリ レプリカからセカンダリ レプリカに手動でフェールオーバーすることで、基になる OS のパッチ適用中のダウンタイムを最小限にできます。 オペレーティング システムの分析観点からは、元になる OS のサービスで (常にではありませんが) しばしば再起動が必要になることがあるため、Windows サーバーではこれを行うのがより一般的です。 Linux のファイルの部分置換の適用には再起動が必要ですが、滅多に発生しません。
可用性グループに参加している SQL Server インスタンスにパッチを適用しても、AG のアーキテクチャの複雑度によっては、ダウンタイムを最小限に抑えることができます。 AG に参加しているサーバーにパッチを適用するには、最初にセカンダリ レプリカにパッチを適用します。 正しい数のレプリカに修正プログラムが適用されたら、プライマリ レプリカを別のノードに手動でフェールオーバーしてアップグレードを行います。 この時点で残りのすべてのセカンダリ レプリカもアップグレードできます。
フェールオーバー クラスター インスタンス
FCI 単独では従来の移行またはアップグレードを支援できません。AG またはログ配布を、FCI 内のデータベースと、考慮する他のすべてのオブジェクト用に、構成する必要があります。 ただし、基になる Windows Server に修正プログラムを適用する必要がある場合は、Windows Server の FCI がまだ一般的なオプションです。 手動フェールオーバーを開始できます。これは、Windows Server にパッチが適用される間ずっとインスタンスを使用できなくする代わりに、短時間停止することを意味します。 FCI は、新しいバージョンの SQL Server にインプレース アップグレードできます。 詳細については、「SQL Server フェールオーバー クラスター インスタンスのアップグレード」を参照してください。
ログ配布
ログ配布は、データベースの移行とアップグレードの両方でいまだに一般的なオプションです。 AG と似ていますが、ここではトランザクション ログを同期方法として使います。データの伝達は、サーバーを切り替える前に十分な余裕をもって開始できます。 切り替え時に、ソースですべてのトラフィックが停止したら、最後のトランザクション ログを取得し、コピーし、新しい構成に適用する必要があります。 その時点で、データベースをオンラインにすることができます。 ログ配布は遅いネットワークに対する許容度が高いことが多く、AG や分散 AG を使って行う切り替えより、切り替えに若干時間がかかる場合がありますが、通常は数分で、数時間、数日、数週間かかることはありません。
AG と同様に、ログ配布はパッチの適用時に別のサーバーに切り替える方法を提供できます。
その他の SQL Server の展開方法と可用性
SQL Server on Linux では、他に 2 つの展開方法があります。コンテナーと Azure (または別のパブリック クラウド プロバイダー) を使用することです。 このペーパーで示したように、SQL Server の展開方法に関係なく、可用性に対する一般的な必要性が存在します。 SQL Server を高可用性にするという点では、これら 2 つの方法にはいくつか特に注意が必要な点があります。
SQL Server コンテナーと HA/DR のオプション
SQL Server コンテナーの展開は、SQL Server on Linux を配置する新しい方法です。 コンテナーとは、実行する準備ができている SQL Server の完全なイメージです。
使用するコンテナー プラットフォームに応じて、たとえば Kubernetes などのコンテナー オーケストレーターを使用すると、コンテナーが失われた場合に、コンテナーをもう一度展開し、使われていた共有ストレージにアタッチできます。 これにより、ある程度の回復性が提供されますが、データベースの復旧に伴うある程度のダウンタイムが発生し、可用性グループまたは FCI を使用している場合ほどの真の高可用性は得られません。
Kubernetes または Kubernetes 以外のプラットフォームに展開された SQL Server コンテナー用に高可用性を構成する必要がある場合は、クラスタリング ソリューションの 1 つとして DH2i DxEnterprise を使用でき、その上に高可用性モードで AG を構成できます。 このオプションでは、高可用性ソリューションから期待される復旧ポイントの目標 (RPO) と復旧時刻の目標 (RTO) が提供されます。
Linux ベースの IaaS の展開
Linux の IaaS 仮想マシンは、Azure を使用してインストールされた SQL Server で展開できます。 オンプレミス ベースのインストールと同じく、サポートされているインストールでは、クラスター エージェント自体の外部にある STONITH (Shoot the Other Node in the Head) を使う必要があります。 STONITH は、フェンス可用性エージェントを介して提供されます。 ディストリビューションによってはプラットフォームの一部として付属していますが、そうでない場合は外部のハードウェアとソフトウェアのベンダーに依存します。 サポートされているソリューションをパブリック クラウドに展開できるように、好みの Linux ディストリビューションでどのような STONITH が提供されているかを確認してください。
SQL Server on Linux のインストールに関するガイドは、次のディストリビューションで利用できます。
- クイック スタート:Red Hat に SQL Server をインストールし、データベースを作成する
- クイック スタート:Ubuntu に SQL Server をインストールし、データベースを作成する
- クイック スタート:SUSE Linux Enterprise Server で SQL Server をインストールし、データベースを作成する
読み取りスケール
SQL Server 2012 (11.x) で導入されて以来、セカンダリ レプリカは読み取り専用クエリに使用できます。 AG で実現できる 2 つの方法があります。セカンダリへの直接アクセスを許可することと、リスナーを使用する必要がある読み取り専用のルーティングを構成することです。 SQL Server 2016 (13.x) で導入された、ラウンド ロビン アルゴリズムを使うリスナーを通じて読み取り専用の接続を負荷分散する機能により、読み取り専用の要求をすべての読み取り可能なレプリカに分散できます。
注意
読み取り可能なセカンダリ レプリカは Enterprise エディションのみの機能で、読み取り可能なレプリカをホストする各インスタンスに SQL Server ライセンスが必要です。
AG によるデータベースの読み取り可能なコピーのスケーリングは、SQL Server 2016 (13.x) の分散 AG で初めて導入されました。 これにより企業は、最小限の構成でデータベースの読み取り専用のコピーをローカルだけでなく、地域およびグローバルで持つことができ、クエリがローカルで実行されることでネットワーク トラフィックと遅延を削減することができます。 AG の各プライマリ レプリカは、完全に読み書き可能なコピーでなくても、他の 2 つの AG をシードできるため、各分散 AG は読み取り可能なデータのコピーを最大 27 個までサポートできます。

SQL Server 2017 (14.x) 以降では、None のクラスターの種類で構成されている AG を使用して、準リアルタイムの読み取り専用ソリューションを作成できます。 AG の使用目的が、読み取り可能なセカンダリ レプリカであり、可用性ではない場合は、これを行うことにより、Linux で WSFC または外部クラスター ソリューションを使うことの複雑さが解消され、より簡単な展開方法で AG の読み取り可能の利点が得られます。
主な注意点は、クラスターの種類が None の基になるクラスターがないため、読み取り専用ルーティングの構成が少し異なることだけです。 SQL Server の観点からは、クラスターが存在しない場合でも、要求をルーティングするために引き続きリスナーが必要です。 従来のリスナーを構成する代わりに、IP アドレスまたはプライマリ レプリカの名前が使用されます。 プライマリ レプリカは、読み取り専用の要求をルーティングするために使用されます。
ログ配布のウォーム スタンバイは、データベース WITH STANDBY を復元することで読み取り可能な使用量に対して技術的に構成できます。 ただし、トランザクション ログは復元するためのデータベースを排他的に使用する必要があるため、その間はユーザーがデータベースにアクセスできないことを意味します。 これにより、ログ配布が理想的とは言えないソリューションになります。ほぼリアルタイムのデータが必要な場合には特にそうなります。
AG を使うすべての読み取りスケールのシナリオで注意すべきことは、すべてのデータがライブであるトランザクション レプリケーションを使う場合とは異なり、各セカンダリ レプリカは、一意のインデックスを適用できる状態になく、そのレプリカはプライマリの完全なコピーであることです。 レポートに任意のインデックスが必要な場合や、データを操作する必要がある場合は、プライマリ レプリカ上のデータベースで作成する必要があります。 その柔軟性が必要な場合は、レプリケーションが読み取り可能なデータにより適したソリューションです。
クロスプラットフォームおよび Linux ディストリビューションの相互運用性
SQL Server は、Windows Server と Linux の両方でサポートされるようになりました。このセクションでは、他の目的だけでなく、可用性のためにこれらを連携させる方法のシナリオと、複数の Linux ディストリビューションを取り入れるソリューションのシナリオについて説明します。
注意
WSFC ベースの FCI または AG が Linux ベースの FCI または AG と直接連動するシナリオはありません。 WSFC は Pacemaker ノードでは拡張できず、その逆も同様です。
分散型可用性グループ
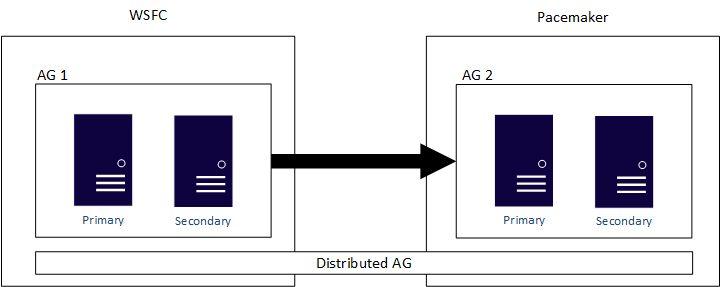
分散 AG は複数の AG 構成にまたがるように設計されており、AG の下のこれらの 2 つの基になるクラスターが 2 つの異なる WSFC、Linux ディストリビューション、または WSFC とその他の Linux 上のものかどうかは関係ありません。 分散 AG は、クロスプラットフォーム ソリューションの主要な手段になります。 分散 AG は、Windows Server ベースの SQL Server インフラストラクチャから Linux ベースへの変換など、移行のための主要なソリューションでもあります (それを会社が望む場合)。 前述のように、AG、特に分散 AG は、アプリケーションを使用できない時間を最小限に抑えます。 WSFC と Pacemaker にまたがる分散 AG の例を次に示します。
AG が None のクラスターの種類で構成されている場合は、Windows Server と Linux だけでなく、複数の Linux ディストリビューションにまたがることができます。 これは、真の高可用性構成ではないため、ミッション クリティカルな展開には使用すべきではありませんが、読み取りスケールまたは移行やアップグレードのシナリオには使用できます。
ログ配布
ログ配布はバックアップと復元に基づいているため、Windows Server の SQL Server と SQL Server on Linux では、データベース、ファイル構造などに違いはありません。 つまり、ログ配布は、Windows Server ベースの SQL Server のインストール間で構成でき、Linux ベースでも Linux のディストリビューション間でも構成できます。 それ以外はすべて同じです。 注意が必要な点は、AG と同じように、ソースの SQL Server のメジャー バージョンが、ターゲットのバージョンより新しい場合は、ログ配布が機能しないことだけです。
まとめ
SQL Server 2017 (14.x) 以降のバージョンのインスタンスとデータベースは、同じ機能を使って Windows Server と Linux の両方で高可用性にすることができます。 ローカルの高可用性とディザスター リカバリーの標準的な可用性シナリオの他に、SQL Server の可用性機能を使用することで、アップグレードと移行に伴うダウンタイムを最小限に抑えることができます。 AG では、同じアーキテクチャの一部としてデータベースの追加コピーを提供し、読み取り可能なコピーをスケールアウトすることもできます。 新しいソリューションを展開する場合でも、またはアップグレードを検討している場合でも、SQL Server は必要な可用性と信頼性を備えてます。
次のステップ
フィードバック
以下は間もなく提供いたします。2024 年を通じて、コンテンツのフィードバック メカニズムとして GitHub の issue を段階的に廃止し、新しいフィードバック システムに置き換えます。 詳細については、「https://aka.ms/ContentUserFeedback」を参照してください。
フィードバックの送信と表示