SQL Server on Linux の可用性グループ
適用対象:![]() SQL Server - Linux
SQL Server - Linux
この記事では、Linux ベースの SQL Server インストールでの、可用性グループ (AG) の特性について説明します。 また、Linux ベースの AG と、Windows Server フェールオーバー クラスター (WSFC) ベースの AG の違いについても説明します。 AG の基本については、Windows ベースのドキュメントを参照してください (WSFC を除き、AG は Windows 上でも Linux 上でも同様に機能します)。
Note
読み取りスケール可用性グループや Linux 上の可用性グループなど、Windows Server フェールオーバー クラスタリング (WSFC) を使用しない可用性グループでは、クラスターに関連する可用性グループ DMV の列に、内部の既定のクラスターに関するデータが表示される場合があります。 これらの列は内部使用のみを目的としており、無視できます。
全体的に見ると、Linux 上の SQL Server の可用性グループは、WSFC ベースの実装で使用する場合と同様に機能します。 つまり、制限事項や機能は基本的に同じですが、いくつかの例外があります。 主な違いは次のとおりです。
- SQL Server 2017 CU16 以降では、Linux で Microsoft 分散トランザクション コーディネーター (DTC) がサポートされています。 ただし、Linux 上の可用性グループでは DTC はまだサポートされていません。 アプリケーションで分散トランザクションを使用する必要があり、AG が必要な場合は、Windows 上で SQL Server をデプロイしてください。
- 高可用性を必要とする Linux ベースのデプロイでは、クラスタリングに WSFC ではなく Pacemaker が使われます。
- Windows 上の AG のほとんどの構成 (ワークグループクラスターのシナリオを除く) とは異なり、Pacemaker では Active Directory Domain Services (AD DS) が必要とされることはありません。
- 1 つのノードから別のノードに AG をフェールオーバーする方法は、Linux と Windows で異なります。
- 特定の設定 (
required_synchronized_secondaries_to_commitなど) は、Linux 上の Pacemaker を使用してのみ変更できます。一方、WSFC ベースのインストールでは Transact-SQL を使用します。
レプリカとクラスター ノードの数
SQL Server Standard エディション内の AG には、2 つのレプリカを含めることができます。1 つはプライマリ、もう 1 つは可用性の目的にのみ使用できます。 他の目的 (読み取り可能なクエリなど) には使用できません。 SQL Server Enterprise エディション内の AG は、最大 9 個のレプリカを持つことができます。1 つのプライマリと最大 8 つのセカンダリで構成し、最大 3 つ (プライマリを含む) を同期できます。 基になるクラスターを使用している場合で、Corosync が使用されている場合には、最大で 16 個のノードを使用できます。 可用性グループでは、SQL Server Enterprise エディションなら 16 ノードのうち最大 9 ノードを使用でき、SQL Server Standard エディションなら 2 ノードまで使用できます。
レプリカ 2 個の構成で、別のレプリカに自動的にフェールオーバーする機能が必要な場合は、構成専用レプリカを使用する必要があります (「構成専用レプリカとクォーラム」で説明されています)。 構成専用レプリカは SQL Server 2017 (14.x) Cumulative Update 1 (CU1) で導入されたので、このバージョンが、この構成用にデプロイできる最低のバージョンになります。
Pacemaker が使用されている場合は、その実行を維持できるように適切に構成する必要があります。 つまり、SQL Server の要件 (構成専用レプリカなど) に加えて、Pacemaker の観点からクォーラムと STONITH を適切に実装する必要があります。
読み取り可能なセカンダ リレプリカは、SQL Server Enterprise エディションでのみサポートされます。
クラスターの種類とフェールオーバー モード
SQL Server 2017 (14.x) では、AG のクラスターの種類が新たに導入されました。 Linux の場合、External と None の 2 つの有効な値があります。 "External" というクラスターの種類は、AG の下で Pacemaker が使用されることを意味します。 クラスターの種類として External を使用するには、フェールオーバー モードも External に設定する必要があります (これも SQL Server 2017 (14.x) の新機能です)。 自動フェールオーバーはサポートされていますが、WSFC とは異なり、Pacemaker が使用されている場合はフェールオーバー モードが (自動ではなく) External に設定されます。 WSFC とは異なり、AG の Pacemaker 部分は AG の構成後に作成されます。
クラスターの種類が None の場合は、Pacemaker に対する要件がない (AG でも使用されない) ことを意味します。 Pacemaker が構成されているサーバー上でも、クラスターの種類を None にして AG が構成されている場合、Pacemaker ではその AG は表示されず、管理もされません。 クラスターの種類が None の場合は、プライマリからセカンダリ レプリカへの手動フェールオーバーのみがサポートされます。 None で作成された AG は、主にアップグレードと読み取りスケールアウトに使用されます。ディザスター リカバリーやローカルの可用性など、自動フェールオーバーを必要としないシナリオでも機能しますが、推奨はされません。 リスナーの取り扱いも、Pacemaker を使わない場合より複雑になります。
クラスターの種類は、SQL Server 動的管理ビュー (DMV) sys.availability_groupsの cluster_type と cluster_type_desc の列に格納されます。
required_synchronized_secondaries_to_commit
SQL Server 2017 (14.x) では、AG によって使用される、required_synchronized_secondaries_to_commit という設定が新たに導入されました。 これは、プライマリと同期する必要があるセカンダリ レプリカの数を AG に伝えるためのものです。 これにより、自動フェールオーバー などの処理が可能になります (クラスターの種類を External にして Pacemaker と統合されている場合のみ)。また、適切な数のセカンダリ レプリカがオンラインまたはオフラインの場合に、プライマリの可用性などに関する動作を制御できるようになります。 このしくみの詳細については、「可用性グループの構成の高可用性とデータの保護」を参照してください。 required_synchronized_secondaries_to_commit の値は既定で設定され、Pacemaker/ SQL Server によって管理されます。 この値は手動でオーバーライドできます。
required_synchronized_secondaries_to_commit と新しいシーケンス番号 (sys.availability_groups に格納されます) の組み合わせにより、たとえば、自動フェールオーバーを実行できることが Pacemaker と SQL Server に通知されます。 その場合、セカンダリ レプリカはプライマリと同じシーケンス番号を持っていることになります。つまり、最新の構成情報がすべて含まれた状態であるということです。
required_synchronized_secondaries_to_commit に設定できる値は、0、1、2 の 3 つです。 これらの値によって、レプリカが使用できなくなったときの動作が制御されます。 これらの数は、プライマリと同期する必要があるセカンダリ レプリカの数に対応しています。 Linux では、動作は次のようになります。
- 0 - セカンダリ レプリカがプライマリと同期された状態である必要はありません。 ただし、セカンダリが同期されていない場合、自動フェールオーバーは行われません。
- 1 - 1 つのセカンダリ レプリカがプライマリと同期された状態である必要があります。自動フェールオーバーが可能です。 プライマリ データベースは、セカンダリの同期レプリカが使用可能になるまで使用できません。
- 2 - 3 ノード以上の AG 構成内にある両方のセカンダリ レプリカが、プライマリと同期されている必要があります。自動フェールオーバーが可能です。
required_synchronized_secondaries_to_commit は、同期レプリカを使用したフェールオーバーの動作だけでなく、データ損失も制御します。 値が 1 または 2 の場合、セカンダリ レプリカは常に同期されていることを要求されるため、常にデータの冗長性が確保されます。 つまり、データ損失は発生しません。
required_synchronized_secondaries_to_commit の値を変更するには、次の構文を使用します。
Note
値を変更すると、リソースが再起動されます。つまり、短時間停止します。 これを回避する唯一の方法は、リソースが一時的にクラスターによって管理されないように設定することです。
Red Hat Enterprise Linux (RHEL) と Ubuntu
sudo pcs resource update <AGResourceName> required_synchronized_secondaries_to_commit=<Value>
SUSE Linux Enterprise Server (SLES)
sudo crm resource param ms-<AGResourceName> set required_synchronized_secondaries_to_commit <value>
ここで、AGResourceName は AG 用に構成されているリソースの名前で、Value は 0、1、または 2 です。 パラメーターを管理する Pacemaker の既定の設定に戻すには、値を指定せずに同じステートメントを実行します。
次の条件が満たされている場合は、AG の自動フェールオーバーが可能です。
- プライマリ レプリカとセカンダリ レプリカが、同期データ移動に設定されている。
- セカンダリが (同期中ではなく) 同期済みの状態である。つまり、2 つが同じデータ ポイントにある。
- クラスターの種類が External に設定されている。 クラスターの種類が None の場合、自動フェールオーバーは実行できません。
- プライマリになるセカンダリ レプリカの
sequence_numberが、最大のシーケンス番号になっている。つまり、セカンダリ レプリカのsequence_numberが、元のプライマリ レプリカの番号と一致している。
これらの条件が満たされている場合、プライマリ レプリカをホストしているサーバーで障害が発生すると、AG は所有者を同期レプリカに変更します。 同期レプリカ (1 つのプライマリ レプリカと 2 つのセカンダリ レプリカで合計 3 つ) の動作は、required_synchronized_secondaries_to_commit によってさらに制御することができます。 これは、Windows と Linux の両方で AG と連携しますが、構成の方法は異なります。 Linux の場合、この値は AG リソース自体のクラスターによって自動的に構成されます。
構成専用レプリカとクォーラム
SQL Server 2017 (14.x) CU1 では、構成専用レプリカも新しく導入されました。 Pacemaker は WSFC とは異なり、特にクォーラムと STONITH の使用に関しては大きく異なるため、2 ノードのみの構成では AG との連携が機能しません。 FCI については、Pacemaker で提供されるクォーラム メカニズムで問題ありません。これは、 FCI のフェールオーバーのアービトレーションがすべてクラスター レイヤーで行われるためです。 AG の場合、Linux でのアービトレーションは、すべてのメタデータが格納されている SQL Server 内で発生します。 そこで必要となるのが、構成専用レプリカです。
3 つ目のノードと、少なくとも 1 つの同期されたレプリカがどうしても必要となります。 構成専用レプリカは、AG 構成内の他のレプリカと同じように、AG 構成を master データベースに格納します。 構成専用レプリカでは、AG に参加しているユーザー データベースは保持されません。 構成データは、プライマリから同期的に送信されます。 この構成データは、自動か手動かにかかわらず、フェールオーバー中に使用されます。
AG でクォーラムを維持し、External のクラスターについて自動フェールオーバーを有効にするには、次のいずれかの条件を満たす必要があります。
- 3 つの同期レプリカがある (SQL Server Enterprise エディションのみ)。または
- 2 つのレプリカ (プライマリとセカンダリ) と、構成専用レプリカがある。
手動フェールオーバーは、AG 構成に使用しているクラスターの種類が External か None かにかかわらず実行できます。 構成専用レプリカは、クラスターの種類が None の AG でも構成できますが、デプロイが複雑になるため推奨されません。 そのように構成する場合は、値が少なくとも 1 になるように required_synchronized_secondaries_to_commit を手動で変更して、同期されたレプリカが少なくとも 1 つ存在するようにしてください。
構成専用レプリカは、SQL Server の任意のエディション (SQL Server Express を含む) でホストできます。 そのため、ライセンス コストを最小限に抑えつつ、SQL Server Standard エディションの AG で動作させることができます。 つまり、3 つ目の必須サーバーでは、SQL Server の最小の仕様を満たすだけで済みます (AG のユーザー トランザクション トラフィックを受信しないため)。
構成専用レプリカを使用する場合、その動作は次のようになります。
- 既定では、
required_synchronized_secondaries_to_commitは 0 に設定されています。 これは、必要に応じて手動で 1 に変更できます。 - プライマリで障害が発生し、
required_synchronized_secondaries_to_commitが 0 の場合は、セカンダリ レプリカが新しいプライマリになり、読み取りと書き込みの両方に使用できるようになります。 値が 1 の場合は、自動フェールオーバーが実行されますが、他のレプリカがオンラインになるまで新しいトランザクションは受け入れられません。 - セカンダリ レプリカで障害が発生し、
required_synchronized_secondaries_to_commitが 0 の場合、プライマリ レプリカは引き続きトランザクションを受け入れますが、その時点でプライマリ レプリカに障害が発生した場合は、セカンダリ レプリカが使用できないため、データ保護もフェールオーバーも (手動と自動のいずれを問わず) 提供されません。 - 構成専用レプリカで障害が発生した場合、AG は正常に機能しますが、自動フェールオーバーは実行できません。
- 同期セカンダリ レプリカと構成専用レプリカの両方で障害が発生した場合、プライマリはトランザクションを受け付けることができず、プライマリからのフェールオーバー先もなくなります。
CU1 では、mssql-server-ha によって生成される corosync.log ファイルのログに既知のバグがあります。 使用可能なレプリカの数が原因でセカンダリ レプリカがプライマリになることができない場合、現在のメッセージは "1 つのシーケンス番号を受け取る必要がありましたが、2 つしか受信されませんでした。 ローカル レプリカを安全に昇格させるための十分なレプリカがオンラインになっていません。" これらの数は逆にする必要があります。正しいメッセージは次のとおりです: "2 つのシーケンス番号を受け取る必要がありましたが、1 つしか受信されませんでした。 ローカル レプリカを安全に昇格させるための十分なレプリカがオンラインになっていません。"
複数の可用性グループ
AG は、Pacemaker クラスターまたは一連のサーバーごとに複数作成できます。 唯一の制限は、システム リソースです。 AG の所有権はマスターによって示されます。 複数の AG を異なるノードで所有することもできます。それらがすべて同じノードで実行されている必要はありません。
データベースのドライブとフォルダーの場所
Windows ベースの AG の場合と同様に、AG に参加しているユーザー データベースのドライブとフォルダーの構造は同じである必要があります。 たとえば、ユーザー データベースがサーバー A 上の /var/opt/mssql/userdata にある場合は、それと同じフォルダーがサーバー B にも存在する必要があります。これに関する唯一の例外については、「Windows ベースの可用性グループとレプリカとの相互運用性」に記載されています。
Linux 下のリスナー
リスナーは、AG のオプション機能です。 これは、すべての接続 (プライマリ レプリカへの読み取り/書き込み接続や、セカンダリ レプリカへの読み取り専用接続) に対する単一のエントリ ポイントを提供するものです。これにより、アプリケーションとエンド ユーザーは、どのサーバーがデータをホストしているのかを認識しなくて済むようになります。 WSFC では、これはネットワーク名リソースと IP リソースの組み合わせであり、AD DS (必要な場合) と DNS に登録されます。 この抽象化は、AG リソース自体との組み合わせによって提供されます。 リスナーの詳細については、「リスナー、クライアント接続、およびアプリケーションのフェールオーバー」を参照してください。
Linux ではリスナーの構成方法が異なりますが、その機能は同じです。 Pacemaker にはネットワーク名リソースの概念がなく、AD DS で作成されたオブジェクトもありません。Pacemaker で作成された IP アドレス リソースしかなく、それらを任意のノードで実行できます。 "フレンドリ名" を使用して、DNS 内のリスナーの IP リソースに関連付けられたエントリを作成する必要があります。 リスナーの IP リソースは、その可用性グループのプライマリ レプリカをホストしているサーバー上でのみアクティブになります。
Pacemaker が使用されていて、リスナーに関連付けられた IP アドレス リソースが作成されている場合は、1 つのサーバーで IP アドレスが停止し、もう 1 つのサーバーで起動する際に、システムがしばらく停止します (フェールオーバーが自動か手動かにかかわらず)。 これにより、単一の名前と IP アドレスの組み合わせによる抽象化が提供されますが、システム停止はマスクされません。 アプリケーションでは、この問題を検出して再接続するための何らかの機能を設けて、切断に対応できるようにする必要があります。
ただし、DNS 名と IP アドレスを組み合わせても、WSFC のリスナーで提供されるすべての機能 (セカンダリ レプリカのための読み取り専用ルーティングなど) を提供するのに十分ではありません。 AG を構成する際、やはり SQL Server で "リスナー" を構成する必要があります。 これは、ウィザードと Transact-SQL 構文で確認できます。 これを Windows と同様に機能するように 構成するには、次の 2 つの方法があります。
- クラスターの種類が External の AG の場合、SQL Server で作成された "リスナー" に関連付けられた IP アドレスは、Pacemaker で作成されたリソースの IP アドレスである必要があります。
- クラスターの種類を None にして作成された AG の場合は、プライマリ レプリカに関連付けられた IP アドレスを使用します。
指定された IP アドレスに関連付けられたインスタンスは、アプリケーションからの読み取り専用ルーティング要求などに対するコーディネーターになります。
Windows ベースの可用性グループとレプリカとの相互運用性
クラスターの種類が External または WSFC である AG では、そのレプリカをクロスプラットフォームにすることはできません。 このことは、AG が SQL Server Standard エディションと SQL Server Enterprise エディションのどちらであっても同様です。 つまり、基になるクラスターを持つ従来の AG 構成では、一方のレプリカを WSFC に配置し、もう一方のレプリカを、Pacemaker を使用して Linux 上に配置することはできません。
クラスターの種類が NONE の AG では、OS の境界をまたいでレプリカを配置することができます。そのため、同じ AG 内に Linux ベースと Windows ベースの両方のレプリカを配置することができます。 次に示すのは、プライマリ レプリカが Windows ベースで、セカンダリが Linux ディストリビューション上にある場合の例です。
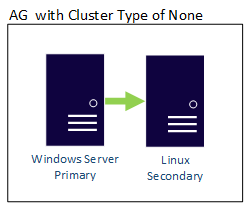
分散型 AG も、OS 境界をまたぐことができます。 基になる AG は、構成方法に関する規則によって制約を受けます (External で構成されたものは Linux のみだが、それが参加している AG は WSFC を使用して構成できるなど)。 次の例を確認してください。
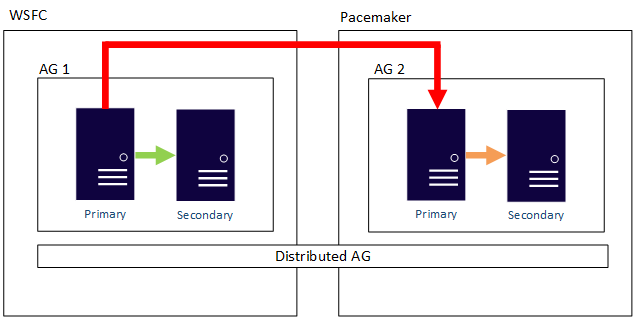
関連するコンテンツ
フィードバック
以下は間もなく提供いたします。2024 年を通じて、コンテンツのフィードバック メカニズムとして GitHub の issue を段階的に廃止し、新しいフィードバック システムに置き換えます。 詳細については、「https://aka.ms/ContentUserFeedback」を参照してください。
フィードバックの送信と表示