ページの読み取り
適用対象:![]() SQL Server
SQL Server
SQL Server データベース エンジンのインスタンスからの I/O には、論理読み取りと物理読み取りがあります。 論理読み取りは、データベース エンジンによりバッファー キャッシュからページが要求されるたびに行われます。 要求したページがバッファー キャッシュに存在しない場合、物理読み取りが行われ、まず、ディスクからキャッシュにページがコピーされます。
データベース エンジンのインスタンスによって生成された読み取り要求はリレーショナル エンジンによって制御され、ストレージ エンジンによって最適化されます。 リレーショナル エンジンは、最も効率的なアクセス方法 (テーブル スキャン、インデックス スキャン、キーによる読み取りなど) を判別します。アクセス方法とストレージ エンジンのバッファー マネージャー コンポーネントによって、実行される読み取りの一般的なパターンが決まり、そのアクセス方法の実装に必要な最適化がその読み取りに対して行われます。 バッチを実行するスレッドが、読み取りのスケジュールを設定します。
先行読み取り
データベース エンジンでは、先行読み取りと呼ばれるパフォーマンス最適化メカニズムがサポートされています。 先行読み取りでは、クエリ実行プランに必要なデータ ページとインデックス ページを予想し、実際にクエリで使用される前に、予想したページをバッファー キャッシュに配置します。 これにより、計算と I/O を同時に行うことができ、CPU とディスクが最大限に活用されます。
データベース エンジンではこの先行読み取りメカニズムにより、1 つのファイルから連続するページを最大 64 ページ (512 KB) まで読み取ることができます。 この読み取りは、バッファー キャッシュ内の (多くの場合連続していない) バッファーを適切な数まで読み取る、単一のスキャッター/ギャザー読み取り処理として実行されます。 この範囲のいずれかのページが既にバッファー キャッシュに存在する場合、読み取りの完了時に、読み取られたページの中から対応するページが破棄されます。 また、バッファー キャッシュのページと対応するページが複数存在する場合、それらのページが先頭または末尾からまとめて "切り捨て" られることもあります。
先行読み取りの対象は、データ ページとインデックス ページの 2 種類です。
データ ページの読み取り
データ ページの読み取りに使用されるテーブル スキャンは、データベース エンジンでは非常に効率的に行われます。 SQL Server データベース内の IAM (Index Allocation Map) ページには、テーブルまたはインデックスで使用されているエクステントの一覧が格納されています。 ストレージ エンジンは IAM を読み取ることで、読み取る必要のあるディスク アドレスが並べ替えられたリストを構築できます。 これによりストレージ エンジンは、ディスク上の位置に基づき、順番に行われる大量の順次読み取りとして、I/O を最適化できます。 IAM ページの詳細については、「 オブジェクトに使用されている領域の管理」をご覧ください。
インデックス ページの読み取り
ストレージ エンジンは、インデックス ページをキー順で直列に読み取ります。 次の図は、キーのセットを格納しているリーフ ページのセットと、リーフ ページをマップしている中間インデックス ノードの例を示しています。 インデックスのページ構造の詳細については、「 クラスタ化インデックスの構造」をご覧ください。
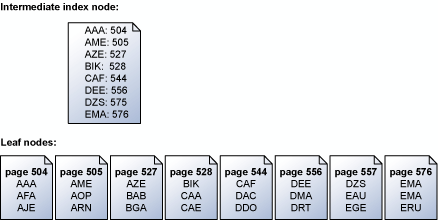
ストレージ エンジンは、リーフ レベルの上にある中間インデックス ページ内の情報を使用して、キーを格納しているページに対して、直列先行読み取りのスケジュールを設定します。 ABC ~ DEF までのすべてのキーに対する要求が行われると、ストレージ エンジンは、まずリーフ ページの上にあるインデックス ページを読み取ります。 ただし、504 ページから 556 ページ (指定された範囲内で最後のキーを持つページ) までを単に順番に読み取るのではありません。 ストレージ エンジンは、中間インデックス ページをスキャンし、読み取りが必要なリーフ ページのリストを構築します。 続けて、すべての読み取りをキー順にスケジュール設定します。 ストレージ エンジンは、ページ 504/505 と 527/528 が連続していることも認識し、単一のスキャッター読み取りを実行して、隣接するページを 1 回の操作で取得します。 直列操作で多くのページを取得する場合、ストレージ エンジンは一度に行う読み取りブロックのスケジュールを設定します。 この読み取りのサブセットが終了すると、ストレージ エンジンは同じ数の新たな読み取りのスケジュールを設定します。これは必要とされるすべての読み取りのスケジュールが設定されるまで続きます。
ストレージ エンジンは、プレフェッチを使用して非クラスター化インデックスからのベース テーブルの参照を高速化します。 非クラスター化インデックスのリーフ行は、それぞれの特定のキー値を格納しているデータ行へのポインターを格納しています。 ストレージ エンジンは、非クラスター化インデックスのリーフ ページを読み取りながら、ポインターが既に取得されているデータ行の非同期読み取りをスケジュールに組み込みます。 これにより、ストレージ エンジンは非クラスター化インデックスのスキャンを完了する前に、基になるテーブルからデータ行を取得できます。 テーブルがクラスター化インデックスを保持しているかどうかに関係なく、プレフェッチが使用されます。 SQL Server Enterprise は、SQL Server の他のエディションよりも多くプレフェッチを使用するため、より多くのページを先行して読み取ることができます。 いずれのエディションでも、プレフェッチのレベルは構成できません。 非クラスター化インデックスの詳細については、「 非クラスタ化インデックスの構造」をご覧ください。
拡張スキャン
SQL Server Enterprise の拡張スキャン機能により、複数のタスクがフル テーブル スキャンを共有できるようになります。 Transact-SQL ステートメントの実行プランがテーブルのデータ ページのスキャンを必要とし、そのテーブルが既に他の実行プラン用にスキャンされていることをデータベース エンジンが検出した場合、データベース エンジンは、2 番目のスキャンの現在位置で 2 番目のスキャンを 1 番目のスキャンに結合します。 データベース エンジンは各ページを 1 回だけ読み取り、各ページの行を両方の実行プランに渡します。 この処理は、テーブルの最後まで行われます。
この時点で、1 番目の実行プランはスキャンの完全な結果を所有していますが、2 番目の実行プランは進行中のスキャンに結合する前に読み取られたデータ ページを取得する必要があります。 2 番目の実行プランのスキャンは、折り返してテーブルの最初のデータ ページに戻り、1 番目のスキャンに結合した位置に達するまでスキャンを実行します。 このようにして、スキャンはいくつでも組み合わせることができます。 データベース エンジンは、すべてのスキャンを完了するまでデータ ページをループし続けます。 このメカニズムは、"メリーゴーラウンド スキャン" とも呼ばれます。また、このメカニズムは、ORDER BY 句が指定されていない SELECT ステートメントから返される結果の順序が保証されない理由を説明しています。
たとえば、500,000 ページを持つテーブルがあるとします。 UserA が、このテーブルのスキャンを要求する Transact-SQL ステートメントを実行します。 このスキャンが 100,000 ページを処理した時点で、UserB が同じテーブルをスキャンする別の Transact-SQL ステートメントを実行します。 データベース エンジンは、100,001 ページ以降のページに対する 1 セットの読み取り要求をスケジュールに組み込み、各ページの行を両方のスキャンに渡します。 スキャンが 200,000 ページ目に達した時点で、UserC が同じテーブルをスキャンする別の Transact-SQL ステートメントを実行します。 データベース エンジンは、200,001 ページから読み取った各ページの行を 3 つのスキャンすべてに渡します。 500,000 行目を読み取った時点で、UserA のスキャンは完了します。UserB と UserC のスキャンは、先頭に戻って 1 ページから読み取りを開始します。 データベース エンジンが 100,000 ページに到達すると、UserB のスキャンが完了します。 UserC のスキャンは 200,000 ページを読み取るまで処理を続けます。 このページ時点ですべてのスキャンが完了したことになります。
拡張スキャンを使用しなければ、ユーザーが互いにバッファー領域の確保を求めて競合することになり、ディスク アームの競合が発生します。 また、一度読み取られたページを複数のユーザーが共有するのではなく、同じページがユーザーごとにその都度読み取られるため、パフォーマンスが低下し、リソースに負荷がかかります。
参照
フィードバック
以下は間もなく提供いたします。2024 年を通じて、コンテンツのフィードバック メカニズムとして GitHub の issue を段階的に廃止し、新しいフィードバック システムに置き換えます。 詳細については、「https://aka.ms/ContentUserFeedback」を参照してください。
フィードバックの送信と表示