Azure Windows 仮想マシンでの CPU 使用率の高い問題のトラブルシューティング
概要
パフォーマンスの問題は、さまざまなオペレーティング システムまたはアプリケーションで発生し、すべての問題のトラブルシューティングには固有のアプローチが必要です。 これらの問題のほとんどは、CPU、メモリ、ネットワーク、入出力 (I/O) を中心に、問題が発生する重要な場所として展開されます。 これらの領域はそれぞれ異なる症状 (場合によっては同時に) を生成し、異なる診断と解決策を必要とします。
この記事では、Windows オペレーティング システムを実行する Azure Virtual Machines (VM) で発生する CPU 使用率の高い問題について説明します。
Azure Windows VM での CPU 使用率の高い問題
I/O とネットワーク待機時間の問題とは別に、CPU とメモリのトラブルシューティングには、オンプレミス サーバーと同じツールと手順が必要です。 Microsoft が通常サポートするツールの 1 つは、PerfInsights (Windows と Linux の両方で使用できます) です。 PerfInsights は、Azure VM のベスト プラクティス診断をユーザーフレンドリ なレポートで提供できます。 PerfInsights は、ツール内で選択されているフラグに応じて、Perfmon、Xperf、Netmon のデータを収集するのに役立つラッパー ツールでもあります。
オンプレミス サーバーに使用される Perfmon や Procmon などの既存のパフォーマンス トラブルシューティング ツールのほとんどは、Azure Windows VM で動作します。 ただし、PerfInsights は、Azure のベスト プラクティス、SQL ベスト プラクティス、高解像度の I/O 待機時間グラフ、CPU タブ、メモリ タブなど、より多くの分析情報を提供するように Azure VM 向けに明示的に設計されています。
User-Mode またはカーネル モードのいずれとして実行される場合でも、アクティブ なプロセスのスレッドでは、作成元のコードを実行するために CPU サイクルが必要です。 多くの問題は、ワークロードに直接関連しています。 サーバー上に存在するワークロードの種類は、CPU を含むリソースの消費を促進します。
一般的な要因
CPU 使用率の高い状況では、次の要因が一般的です。
インターネット インフォメーション サービス (IIS)、Microsoft SharePoint、Microsoft SQL Server、サード パーティ製アプリケーションなどのアプリに主に適用される最近のコードの変更または展開。
OS レベルの更新プログラム、またはアプリケーション レベルの累積的な更新プログラムと修正プログラムに関連している可能性がある最新の更新プログラム。
クエリの変更または古いインデックス。 SQL Serverおよび Oracle データ層アプリケーションには、クエリ プランの最適化も別の要因として用意されています。 データの変更や適切なインデックスの不足により、複数のクエリのコンピューティング負荷が高くなる可能性があります。
Azure VM 固有。 RDAgent などの特定のプロセスと、監視エージェント、MMA エージェント、セキュリティ クライアントなどの拡張機能固有のプロセスがあり、CPU 使用率が高くなる可能性があります。 これらのプロセスは、構成または既知の問題の観点から表示する必要があります。
問題のトラブルシューティング
この記事では、問題のあるプロセスの分離に焦点を当てます。 さらに詳しい分析は、CPU 使用率の高いプロセスに固有です。
たとえば、プロセスがSQL Server (sqlservr.exe) の場合、次の手順は、特定の期間内に最も CPU サイクルを使用していたクエリを分析することです。
問題の範囲を指定する
この問題のトラブルシューティングを行うときに、いくつかの質問を次に示します。
問題のパターンはありますか? たとえば、CPU 使用率の高い問題は、毎日、週、または月の特定の時刻に発生しますか? その場合、この問題をジョブ、レポート、またはユーザー ログインに関連付けることができますか?
最近のコード変更後に CPU 使用率の高い問題が発生しましたか? Windows またはアプリケーションで更新プログラムを適用しましたか?
CPU 使用率の高い問題は、ユーザー数の増加、データの流入の増加、レポートの数の増加など、ワークロードの変更後に発生しましたか?
Azure の場合、CPU 使用率の高い問題は次のいずれかの条件で開始されましたか?
- 最近の再デプロイまたは再起動後
- SKU または VM の種類が変更されたとき
- 新しい拡張機能が追加されたとき
- ロード バランサーの変更が行われた後
Azure の注意事項
ワークロードを理解する。 VM を選択すると、全体的な月間ホスティング コストを見ると、仮想 CPU (vCPU) の数が過小評価される可能性があります。 ワークロードがコンピューティング集中型の場合、1 つまたは 2 つの vCPU を持つ小さな VM SKU を選択すると、ワークロードの問題が発生する可能性があります。 ワークロードのさまざまな構成をテストして、必要な最適なコンピューティング機能を判断します。
品質保証 (QA) とテストに推奨される特定の VM シリーズ (B (バースト モード) シリーズなど) があります。 運用環境でこれらのシリーズを使用すると、CPU クレジットが使い果たされた後のコンピューティング機能が制限されます。
SQL Server、Oracle、RDS (リモート デスクトップ サービス)、Azure Virtual Desktop、IIS、SharePoint などの既知のアプリケーションには、これらのワークロードの最小限の構成に関する推奨事項を含む Azure ベスト プラクティスに関する記事があります。
継続的な CPU 使用率の高い問題
問題が現在発生している場合は、プロセス トレースをキャプチャして問題の原因を特定する最適な機会です。 オンプレミスの Windows サーバーで使用していた既存のツールを使用して、プロセスを見つけることができます。 Azure VM のサポートでは、次のツールが推奨されます。
PerfInsights
PerfInsights は、VM のパフォーマンスの問題にAzure サポートから推奨されるツールです。 CPU、メモリ、高解像度の I/O グラフのベスト プラクティスと専用の分析タブをカバーするように設計されています。 onDemand は、Azure portalを介して、または VM 内から実行できます。 データは、Azure サポート チームと共有できます。
PerfInsights を実行する
PerfInsights は、 Windows OS と Linux OS の両方で使用できます。 Windows の場合、オプションを次に示します。
Azure portalを使用してレポートを実行および分析する
Azure portalを介してインストールされると、VM に拡張機能が実際にインストールされます。 ユーザーは、[VM 内の拡張機能] ブレードに直接移動し、パフォーマンス 診断 オプションを選択することで、PerfInsights を拡張機能としてインストールすることもできます。
Azure portal オプション 1
[VM] ブレードを参照し、[パフォーマンス 診断] オプションを選択します。 選択した VM にオプション (拡張機能を使用) をインストールするように求められます。
![[パフォーマンス 診断] オプションの [パフォーマンス 診断のインストール] ボタンのスクリーンショット。](media/troubleshoot-high-cpu-issues-azure-windows-vm/install-performance-diagnostics.png)
Azure portal オプション 2
[VM] ブレードで [ 問題の診断と解決 ] を参照し、 VM のパフォーマンスの問題を探します。
![[問題の診断と解決] オプションの VM パフォーマンスの問題のスクリーンショット。](media/troubleshoot-high-cpu-issues-azure-windows-vm/troubleshoot-vm-performance-issues.png)
[トラブルシューティング] を選択すると、PerfInsights のインストール画面が読み込まれます。
[インストール] を選択すると、インストールによって異なるコレクション オプションが提供されます。
![[パフォーマンスの診断] オプションの [パフォーマンス分析] 設定のスクリーンショット。](media/troubleshoot-high-cpu-issues-azure-windows-vm/performance-analysis.png)
スクリーンショットの番号付きオプションは、次のコメントに関連しています。
[高 CPU] のオプションで、[パフォーマンス分析] または [詳細設定] を選択します。
ここで症状を追加すると、レポートに追加されます。これは、Azure サポートと情報を共有するのに役立ちます。
データ収集の期間を選択します。 [高 CPU] オプションの場合は、少なくとも 15 分以上を選択します。 Azure portal モードでは、最大 15 分のデータを収集できます。 収集期間が長い場合は、VM 内で実行可能ファイルとしてプログラムを実行する必要があります。
Azure サポートからこのデータの収集を求められた場合は、こちらでチケット番号を追加できます。 このフィールドはオプションです。
エンド ユーザー ライセンス契約 (EULA) に同意するには、このフィールドを選択します。
この場合に役立つ Azure サポート チームがこのレポートを利用できるようにする場合は、このフィールドを選択します。
レポートは、サブスクリプションの下のいずれかのストレージ アカウントに格納されます。 後で表示およびダウンロードできます。
VM 内から PerfInsights を実行する
このメソッドは、PerfInsights を長時間実行する場合に使用できます。 PerfInsights の記事では、PerfInsights を実行可能ファイルとして実行するために必要なさまざまなコマンドとフラグの詳細なチュートリアルを示します。 CPU 使用率が高い目的では、次のいずれかのモードが必要です。
高度なシナリオ
PerfInsights /run advanced xp /d 300 /AcceptDisclaimerAndShareDiagnostics
VM の低速 (パフォーマンス) シナリオ
PerfInsights /run vmslow /d 300 /AcceptDisclaimerAndShareDiagnostics /sa <StorageAccountName> /sk <StorageAccountKey>
コマンド出力は、PerfInsights 実行可能ファイルを保存したのと同じフォルダーにあります。
レポートで探す内容
レポートを実行した後、コンテンツの場所は、Azure portal経由で実行されたか、実行可能ファイルとして実行されたかによって異なります。 どちらのオプションでも、生成されたログ フォルダーにアクセスするか、(Azure portalされている場合は) ローカルにダウンロードして分析します。
Azure portalを実行する
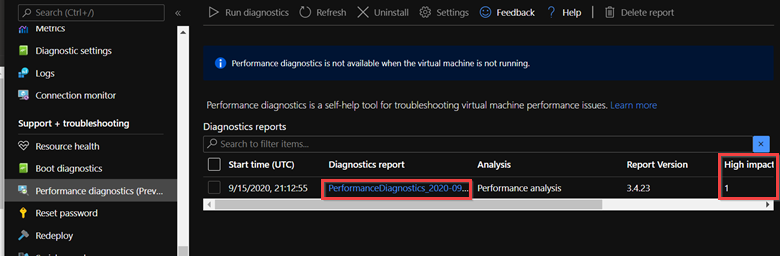
![[パフォーマンス 診断 レポート] ページの [レポートのダウンロード] ボタンのスクリーンショット。](media/troubleshoot-high-cpu-issues-azure-windows-vm/download-report.png)
VM 内から実行する
フォルダー構造は、次の画像のようになります。
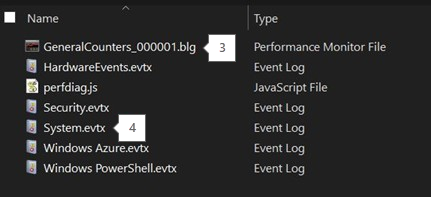
Perfmon、Xperf、Netmon、SMB ログ、イベント ログなどのその他のコレクションは、Output フォルダーにあります。
実際のレポートと分析と推奨事項。
パフォーマンス (VMlow) と Advanced の両方について、レポートは PerfInsights の実行期間中にパー フモン 情報を収集します。
イベント ログには、役に立つシステム レベルまたはプロセス クラッシュの詳細のクイック ビューが表示されます。
どこから始めるか
PerfInsights レポートを開きます。 [ 結果 ] タブには、リソース使用量の観点から外れ値が記録されます。 CPU 使用率が高いインスタンスがある場合は、[ 結果 ] タブで[影響度が高い] または [中程度の影響] として分類されます。
![PerfInsights レポート ページの CPU 部分の [結果] タブのスクリーンショット。この例では、影響レベルは中です。](media/troubleshoot-high-cpu-issues-azure-windows-vm/impact-level-resources.png)
前の例と同様に、PerfInsights は 30 分間実行されました。 その半分の時間、強調表示されたプロセスは、上位側の CPU を使い果たしていました。 コレクション期間中に同じプロセスが実行されていた場合、影響レベルは HIGH に変更されます。
[結果] イベントを展開すると、いくつかの重要な詳細が表示されます。 タブには、 平均 CPU 消費量ごとに、プロセスが降順で一覧表示され、プロセスがシステム、Microsoft 所有のアプリ (SQL、IIS)、またはサード パーティのプロセスに関連していたかどうかを示します。
詳細情報
CPU の下には、詳細なパターン分析、コアごと、またはプロセスごとに使用できる専用のサブタブがあります。
[ 上位 CPU コンシューマー ] タブには、関心のある 2 つのセクションがあり、プロセッサごとの統計情報をここで表示できます。 アプリケーション設計は、多くの場合、1 つのプロセッサに Single-Threaded またはピン自体です。 このシナリオでは、1 つまたは複数のコアが 100% で実行され、他のコアは予想されるレベルで実行されます。 これらのシナリオは、サーバー上の平均 CPU が期待どおりに実行されているように見えますが、使用率が高いコアにピン留めされているプロセスは予想よりも遅くなるため、より複雑になります。
![パフォーマンス診断分析期間と高 CPU 使用率を示す PerfInsights レポート ページの CPU 部分の [上位 CPU コンシューマー] タブのスクリーンショット。](media/troubleshoot-high-cpu-issues-azure-windows-vm/high-cpu-usage.png)
2 番目のセクション (同様に重要) は、 上位の実行時間の長い CPU コンシューマーです。 このセクションでは、プロセスの詳細と CPU 使用率パターンの両方を示します。 一覧は、CPU コンシューマーの平均が高い順に並べ替えられます。
![[上位の実行時間の長い CPU コンシューマー] セクションのスクリーンショット。](media/troubleshoot-high-cpu-issues-azure-windows-vm/top-long-running-cpu-consumers.png)
これら 2 つのタブで、次のトラブルシューティング手順のパスを設定するのに十分です。 CPU 使用率の高い状態を引き上げているプロセスに応じて、先ほど質問された質問に対処する必要があります。 SQL Server (sqlservr.exe) や IIS (w3wp.exe) などのプロセスでは、この条件の原因となっているクエリまたはコードの変更に対する特定のドリルダウンが必要です。 WMI や Lsass.exe などのシステム プロセスの場合は、別のパスに従う必要があります。
RDAgent、OMS、監視拡張機能の実行可能ファイルなどの Azure VM 関連のプロセスでは、Azure サポート チームからサポートを受けることで、新しいビルドまたはバージョンを修正する必要がある場合があります。
Perfmon
Perfmon は、Windows Server 上のリソースの問題をトラブルシューティングするための最も初期のツールの 1 つです。 推奨事項や結果を含む明確なレポートは提供されません。 代わりに、収集されたデータを探索し、さまざまなカウンター カテゴリの下で特定のフィルターを使用する必要があります。
PerfInsights は、VMSlow および高度なシナリオの追加ログとして Perfmon を収集します。 ただし、Perfmon は個別に収集でき、次の追加の利点があります。
リモートで収集できます。
タスクを使用してスケジュールできます。
これは、ロールオーバー機能を使用して、より長い期間、または連続モードで収集できます。
Perfmon がこのデータを表示する方法を確認するには、PerfInsights に示されているのと同じ例を考えてみましょう。 必要なカウンター カテゴリは次のとおりです。
プロセッサ情報 > %Processor Time > _Total
%ProcessorTime > すべてのインスタンスを処理>する
どこから始めるか
Perfmon の出力ファイル名には拡張子があります .blg 。 これらのファイルは、個別に、または PerfInsights を使用して収集できます。 この説明では、PerfInsights データに含まれており、前の例に従って収集された Perfmon .blg を使用します。
Perfmon で使用できる既定のユーザー対応レポートはありません。 グラフの種類を変更するビューは異なりますが、プロセスのフィルター処理 (または原因となるプロセスを特定するために必要な作業) は手動です。
注:
PALツールは、ファイルを使用.blgし、詳細なレポートを生成することができます。
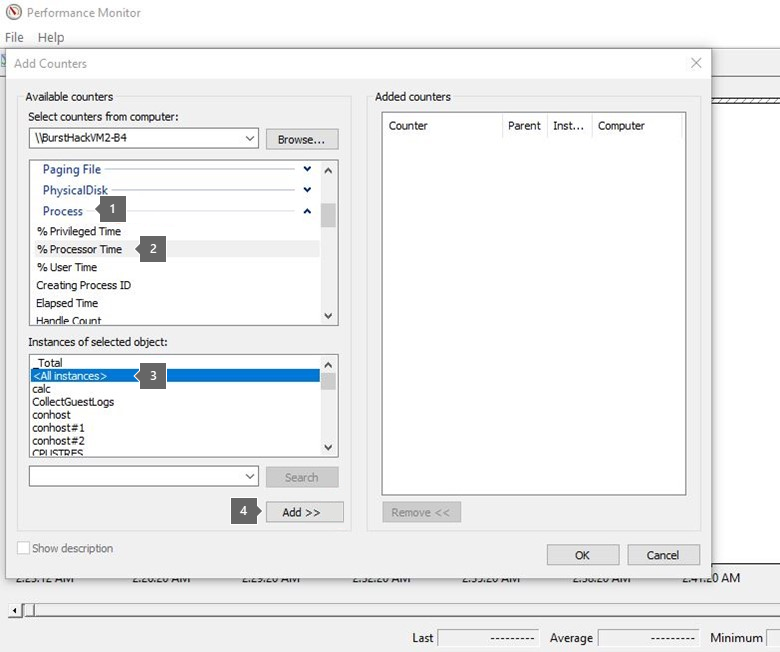
開始するには、[カウンターの 追加] カテゴリを選択します。
[使用可能なカウンター] で、プロセッサ情報カテゴリの %ProcessorTime カウンターを選択します。
[_Total] を選択すると、結合されたすべてのコアの統計情報が表示されます。
[追加] を選択します。 ウィンドウの [追加されたカウンター] に %ProcessorTime が表示されます。
![パフォーマンス モニターの [カウンターの追加] ダイアログのスクリーンショット。](media/troubleshoot-high-cpu-issues-azure-windows-vm/add-processor-time.png)
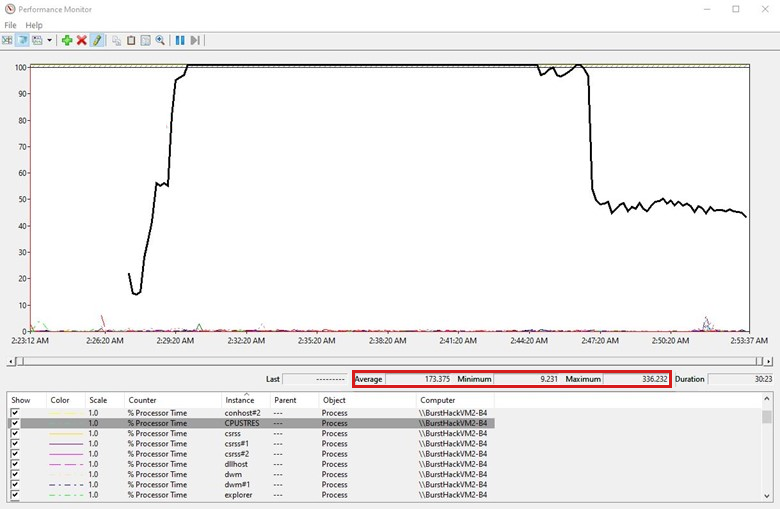
カウンターが読み込まれた後、コレクション時間枠に折れ線の傾向グラフが表示されます。 カウンターを選択またはクリアできます。 ここまでは、カウンターを 1 つだけ追加しました。
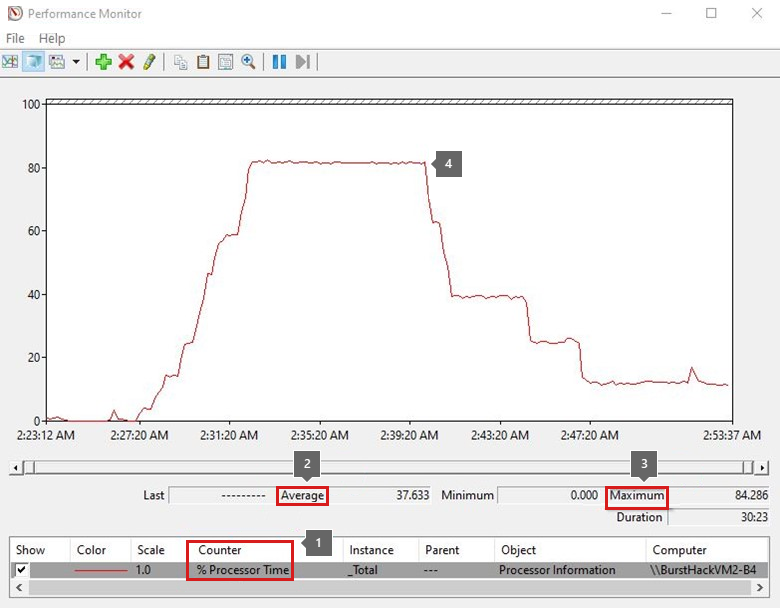
すべてのカウンターには、 Average、 Minimum、 Maximum の各値が含まれます。 平均値はデータ収集の期間によって異なるため、平均値と最大値の両方に焦点を当てます。 全体のコレクションが 40 分であったときに CPU 使用率の高いアクティビティが 10 分間見られた場合、平均値は大幅に低くなります。
前の傾向グラフは、 合計プロセッサ が約 15 分間 80% 近くに及んでいたことを示しています。
プロセスを特定する
サーバーの CPU 消費量が指定された時間だけ高いことが確認されましたが、ドライバーはまだ特定されていません。 PerfInsights の使用とは異なり、この場合は手動で原因プロセスを検索する必要があります。
このタスクでは、以前に追加した %ProcessorTime カウンターをクリアまたは削除してから、新しいカテゴリを追加する必要があります。
- %ProcessorTime > すべてのインスタンスを処理>する
このカテゴリは、その時点で実行されているすべてのプロセスのカウンターを読み込みます。
一般的な運用コンピューターでは、何百ものプロセスを実行できます。 したがって、低い傾向グラフまたはフラット傾向グラフを持っていると思われるすべてのカウンターをクリアするには、しばらく時間がかかる場合があります。
このプロセスを高速化するには、 ヒストグラム ビューを使用し、ビューの種類を [線] から [ヒストグラム] に変更すると、棒グラフが表示されます。 収集時に CPU 使用率が高くなるプロセスを選択する方が簡単です。
Total のバーは常に存在するため、高い排気率を示すバーに注目します。 他のバーを削除してビューをクリーンできます。 次に、 線 ビューに戻ります。
![パフォーマンス モニターの [ヒストグラム ビュー] ボタンと、高い枯渇率を示す 2 つのバーを含むグラフの例のスクリーンショット。](media/troubleshoot-high-cpu-issues-azure-windows-vm/performance-monitor-2.png)
これで、原因となるプロセスを簡単に把握できるようになりました。 既定では、[ 最大] と [ 最小 ] の値は、サーバー上のコア数またはプロセスのスレッド数の倍数です。
使用可能なツールの一覧は、Perfmon の PerfInsights では終わりません。 ProcessMonitor (ProcMon) や Xperf などの他のツールにアクセスできます。 必要に応じて、多くのサード パーティ製ツールを使用できます。
Azure 監視ツール
Azure VM には、CPU、ネットワーク I/O、I/O バイトなどの基本的な情報を含む信頼性の高いメトリックがあります。 Azure Monitor などの高度なメトリックの場合、指定したストレージ アカウントを構成して使用するには、いくつかの選択のみを行う必要があります。
基本 (既定) カウンター
![Azure Monitor の [メトリック] ページのスクリーンショット。この例では、[集計] 設定の [CPU 使用率] オプションが選択されています。](media/troubleshoot-high-cpu-issues-azure-windows-vm/chart-metrics.png)
Azure Monitor の有効化
Azure Monitor メトリックを有効にした後、ソフトウェアは VM に拡張機能をインストールし、Perfmon カウンターを含む詳細なメトリックの収集を開始します。
![[診断設定] ページの [概要] タブの [診断ストレージ アカウント] フィールドのスクリーンショット。](media/troubleshoot-high-cpu-issues-azure-windows-vm/diagnostics-storage-account.png)
Basic カウンター カテゴリは既定として設定されます。 ただし、 カスタム コレクションを設定することもできます。
![[診断設定] ページの [パフォーマンス カウンター] タブにある [基本カテゴリ] オプションのスクリーンショット。](media/troubleshoot-high-cpu-issues-azure-windows-vm/performance-counters.png)
設定が有効になった後、[メトリック] セクションでこれらのゲスト カウンターを表示できます。 メトリックが特定のしきい値 に達した 場合は、アラート (電子メール メッセージを含む) を設定することもできます。
![[メトリック名前空間] フィールドと [メトリック] ページの [新しいアラート ルール] ボタンのスクリーンショット。](media/troubleshoot-high-cpu-issues-azure-windows-vm/metrics-namespace.png)
Azure Monitor を使用して Azure VM を管理する方法の詳細については、「Azure Monitor を使用 した Azure 仮想マシンの監視」を参照してください。
事後対応型のトラブルシューティング
問題が既に発生している場合は、最初に CPU 使用率の高い問題の原因を検出する必要があります。 反応的なスタンスは難しい場合があります。 問題が既に発生しているため、データ収集モードは役に立ちません。
この問題が 1 回限り発生した場合、原因となったアプリを特定するのが困難な場合があります。 OMS またはその他の診断追跡を使用するように Azure VM が構成されている場合でも、問題の原因に関する分析情報を取得できます。
繰り返しパターンを扱う場合は、次に問題が発生する可能性が高い期間中にデータを収集します。
PerfInsights には、 スケジュールされた実行 機能がまだありません。 ただし、Perfmon はコマンド ラインを使用して実行およびスケジュールできます。
Logman コマンド
Logman カウンターの作成コマンドは、コマンド ラインを介して Perfmon コレクションを実行したり、タスク マネージャーを使用してスケジュールしたり、リモートで実行したりするために使用されます。
サンプル (リモート コレクション モードを含む)
Logman create counter LOGNAME -u DOMAIN\USERNAME * -f bincirc -v mmddhhmm -max 300 -c "\\SERVERNAME\LogicalDisk(*)\*" "\\SERVERNAME\Memory\*" "\\SERVERNAME\Network Interface(*)\*" "\\SERVERNAME\Paging File(*)\*" "\\SERVERNAME\PhysicalDisk(*)\*" "\\SERVERNAME\Process(*)\*" "\\SERVERNAME\Redirector\*" "\\SERVERNAME\Server\*" "\\SERVERNAME\System\*" "\\SERVERNAME\Terminal Services\*" "\\SERVERNAME\Processor(*)\*" "\\SERVERNAME\Cache\*" -si 00:01:00
Logman.exe は、同じ VNET 内のピア Azure VM コンピューターから開始することもできます。
これらのパラメーターの詳細については、「 logman create counter」を参照してください。
問題の発生中に Perfmon データが収集された後、データを分析するための残りの手順は、前に説明した手順と同じです。
まとめ
パフォーマンスの問題の場合は、ワークロードを理解することが問題を解決するための鍵となります。 さまざまな VM SKU と異なるディスク ストレージ オプションのオプションは、運用環境のワークロードに焦点を合わせて評価する必要があります。 さまざまな VM でソリューションをテストするプロセスは、最適な意思決定を行うのに役立ちます。
ユーザーの操作とデータ量は異なるため、常に VM のコンピューティング、ネットワーク、I/O 機能にバッファーを保持します。 今では、ワークロードの急激な変化は、あまり大きな影響を与えません。
ワークロードが近いうちに増加する見込みがある場合は、コンピューティング能力の高いより高い SKU に移行します。 ワークロードがコンピューティング集中型になる場合は、VM SKU を賢明に選択します。
お問い合わせはこちらから
質問がある場合やヘルプが必要な場合は、サポート要求を作成するか、Azure コミュニティ サポートにお問い合わせください。 Azure フィードバック コミュニティに製品フィードバックを送信することもできます。
フィードバック
以下は間もなく提供いたします。2024 年を通じて、コンテンツのフィードバック メカニズムとして GitHub の issue を段階的に廃止し、新しいフィードバック システムに置き換えます。 詳細については、「https://aka.ms/ContentUserFeedback」を参照してください。
フィードバックの送信と表示