音声のアクティブ化
Note
このトピックでは、主に、現在 Windows 10 (バージョン 1909 以前) で提供されているコンシューマー エクスペリエンスについて説明します 詳細については、Windows と Teams での Cortana のサポート終了を参照してください。
パーソナル アシスタント テクノロジである Cortana は、2013 年の Microsoft BUILD Developer Conference で初めてデモンストレーションされました。 Windows 音声認識プラットフォームは、Cortana やディクテーションなど、Windows 10 のすべての音声エクスペリエンスを強化するために使用されます。 音声アクティベーションは、ユーザーが「コルタナさん」という特定のフレーズを言うことによって、さまざまなデバイスの電源状態から音声認識エンジンを呼び出すことができる機能です。 音声アクティブ化テクノロジをサポートするハードウェアを作成するには、このトピックの情報を確認してください。
Note
音声アクティベーションの実装は重要なプロジェクトであり、SoCベンダーが行うタスクです。 OEM は、SoC の音声アクティベーションの実装に関する情報を SoC ベンダーに問い合わせることができます。
Cortana エンド ユーザー エクスペリエンス
Windows で使用できる音声操作エクスペリエンスを理解するには、次のトピックを確認してください。
| トピック | 説明 |
|---|---|
| コルタナとは何ですか? | コルタナの概要と使用方法を提供します |
"コルタナさん"の音声アクティベーションと"自分の声を学ぶ"の概要
"コルタナさん"の音声アクティベーション
"コルタナさん" 音声アクティブ化 (VA) 機能を使用すると、ユーザーは音声を使用して、アクティブなコンテキスト (つまり、現在画面に表示されているもの) の外部で コルタナエクスペリエンスをすばやく操作できます。 ユーザーは、多くの場合、デバイスを物理的に操作したり、タッチしたりすることなく、エクスペリエンスに即座にアクセスできることを望んでいます。 電話ユーザーの場合、これは車を運転し、車両の操作に注意と手を向けていることが原因である可能性があります。 Xboxユーザーの場合、これはコントローラーを見つけて接続したくないことが原因である可能性があります。 PCユーザーの場合、これは、キッチンのコンピューターなど、複数のマウス、タッチ、キーボード操作を実行することなく、エクスペリエンスにすばやくアクセスできることが原因である可能性があります。
音声アクティブ化は、定義済みのキー フレーズまたは "アクティブ化フレーズ" を介して常にリスニング音声入力を提供します。 キー フレーズは、ステージングされたコマンドとして単独で発声される ("コルタナさん" )、または連鎖コマンドである "コルタナさん、次の会議はどこですか?" などの音声操作が続く場合があります。
キーワード検出という用語は、ハードウェアまたはソフトウェアによるキーワードの検出を表します。
キーワードのみのアクティブ化は、コルタナ キーワードのみが発声された場合に発生し、コルタナ が起動して EarCon サウンドを再生し、リスニング モードに入ったことを示します。
連鎖コマンドとは、キーワードの直後にコマンドを発行し (「コルタナさん、ジョンに電話して」など)、Cortana に開始させ (まだ開始していない場合)、コマンドをフォローさせる (John との通話を開始する) 機能を表します。
この図は、連鎖およびキーワードのみのアクティブ化を示しています。
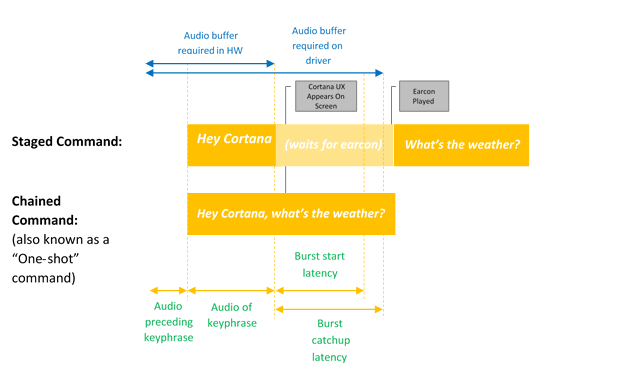
Microsoft は、ハードウェア キーワード検出の品質を保証し、ハードウェア キーワード検出が存在しない、または使用できない場合に Hey Cortana エクスペリエンスを提供するために使用される OS の既定のキーワード スポッター (ソフトウェア キーワード スポッター) を提供しています。
"自分の声を学習"機能
"自分の声を学習"機能を使用すると、ユーザーは コルタナ が自分の固有の声を認識できるようにトレーニングできます。 これは、ユーザーが コルタナ の設定画面で "コルタナ" さんの言い方を確認する を選択することで実現されます。 次に、ユーザーは、ユーザーの音声の一意の属性を識別するのに十分なさまざまな音声パターンを提供する、慎重に選択された 6 つのフレーズを繰り返します。

音声アクティベーションを "自分の声を学ぶ "と組み合わせると、2つのアルゴリズムが連携して、誤ったアクティベーションを減らします。 これは、デバイスでいっぱいの部屋で 1 人のユーザーが "コルタナさん" と言う会議室のシナリオで特に役立ちます。 この機能は、Windows 10 バージョン 1903 以前でのみ使用できます。
音声アクティベーションは、キーフレーズが検出された場合に反応するキーワードスポッター(KWS)によって強化されます。 KWS がデバイスを低電力状態からウェイクアップする場合、このソリューションは Wake on Voice (WoV) と呼ばれます。 詳細については、ウェイクオンボイスを参照してください。
用語集
この用語集は、音声アクティベーションに関連する用語をまとめたものです。
| 用語 | 例/定義 |
|---|---|
| ステージングされたコマンド | 例:コルタナさん、<一時停止して、イヤコンを待って>ください天気は? これは、"2 ショット コマンド" または "キーワードのみ" と呼ばれることもあります |
| 連鎖コマンド | 例:コルタナさん、天気はどうですか? これは “ワンショット コマンド”と呼ばれることもあります |
| 音声のアクティブ化 | 事前定義されたアクティベーションキーフレーズのキーワード検出を提供するシナリオ。 たとえば、"コルタナさん"は Microsoft 音声アクティベーションのシナリオです。 |
| WoV | Wake-on-Voice – 画面がオフの低電力状態からフルパワー状態の画面まで、音声によるアクティベーションを可能にするテクノロジー。 |
| モダン スタンバイからの WoV | モダン スタンバイ (S0ix) 画面オフ状態からフルパワー (S0) 状態への Wake-on-Voice 。 |
| モダン スタンバイ | Windows 低電力アイドル インフラストラクチャ - Windows 10 のコネクト スタンバイ (CS) の後継。 モダン スタンバイの最初の状態は、画面がオフのときです。 最も深いスリープ状態は、DRIPS/回復性にあるときです。 詳細については、「モダン スタンバイ」を参照してください。 |
| KWS | キーワード スポッター – “コルタナさん”の検出を提供するアルゴリズム |
| SW KWS | ソフトウェア キーワード スポッター – ホスト (CPU) 上で実行される KWS の実装。 "コルタナさん" の場合、SW KWS は Windows の一部として含まれています。 |
| HW KWS | ハードウェア オフロード キーワード スポッター – ハードウェア上でオフロードされる KWS の実装。 |
| バーストバッファ | KWS 検出をトリガーしたすべてのオーディオが含まれるように、KWS 検出イベントでバーストできる PCM データを格納するために使用される循環バッファー。 |
| キーワード検出器 OEM アダプター | WoV 対応ハードウェアが Windows および Cortana スタックと通信できるようにするドライバー レベルのシム。 |
| モデル | KWS アルゴリズムで使用される音響モデル データ ファイル。 データファイルは静的です。 モデルはローカライズされ、ロケールごとに 1 つずつ表示されます。 |
ハードウェアキーワードスポッターの統合
ハードウェア キーワード スポッター (HW KWS) を実装するには、SoC ベンダーは次のタスクを完了する必要があります。
- このトピックで後述する SYSVAD サンプルに基づいて、カスタム キーワード検出項目を作成します。 これらのメソッドは、キーワード検出機能 OEM アダプター インターフェイスで説明されている COM DLL に実装します。
- WAVERT の機能強化で説明されている WAVE RT の機能強化を実装します。
- キーワード検出に使用されるカスタム APO を記述する INF ファイル エントリを指定します。
- PKEY_FX_KeywordDetector_StreamEffectClsid
- PKEY_FX_KeywordDetector_ModeEffectClsid
- PKEY_FX_KeywordDetector_EndpointEffectClsid
- PKEY_SFX_KeywordDetector_ProcessingModes_Supported_For_Streaming
- PKEY_MFX_KeywordDetector_ProcessingModes_Supported_For_Streaming
- PKEY_EFX_KeywordDetector_ProcessingModes_Supported_For_Streaming
- オーディオ デバイスの推奨事項でハードウェアの推奨事項とテスト ガイダンスを確認します。 このトピックでは、Microsoft の Speech プラットフォームで使用することを目的としたオーディオ入力デバイスの設計と開発に関するガイダンスと推奨事項について説明します。
- ステージングされたコマンドと連鎖されたコマンドの両方をサポートします。
- サポートされている各コルタナロケールの "コルタナさん" をサポートします。
- APO (オーディオ処理オブジェクト) は、次の効果を提供する必要があります:
- AEC
- AGC
- NS
- 音声処理モードの効果は、MFX APO によって報告される必要があります。
- APO は、MFX として形式変換を実行できます。
- APO は次のフォーマットを出力する必要があります:
- 16kHz、モノラル、フロート。
- 必要に応じて、カスタム APOを設計して、オーディオ キャプチャ プロセスを強化します。 詳細については、Windows オーディオ処理オブジェクトを参照してください。
ハードウェア オフロード キーワード スポッター (HW KWS) WoV の要件
- HW KWS WoV は、S0 動作状態と S0 スリープ状態 (モダン スタンバイとも呼ばれます) でサポートされます。
- HW KWS WoV は S3 からはサポートされていません。
HW KWS の AEC 要件
Windows バージョン 1709 の場合
- S0 スリープ状態 (モダン スタンバイ) の HW KWS WoV をサポートする場合、AEC は必要ありません。
- S0 動作状態の HW KWS WoV は、Windows バージョン 1709 ではサポートされていません。
Windows バージョン 1803 の場合
- S0 動作状態の HW KWS WoV がサポートされています。
- S0 動作状態の HW KWS WoV を有効にするには、APO が AEC をサポートしている必要があります。
サンプルコードの概要
音声アクティブ化を実装するオーディオ ドライバーのサンプル コードは、SYSVAD 仮想オーディオ アダプター サンプルの一部として GitHub にあります。 このコードを出発点として使用することをお勧めします。 コードは、この場所で入手できます。
https://github.com/Microsoft/Windows-driver-samples/tree/main/audio/sysvad/
SYSVAD サンプル オーディオ ドライバーの詳細については、サンプル オーディオ ドライバーを参照してください。
キーワード認識システム情報
音声アクティベーション オーディオ スタックのサポート
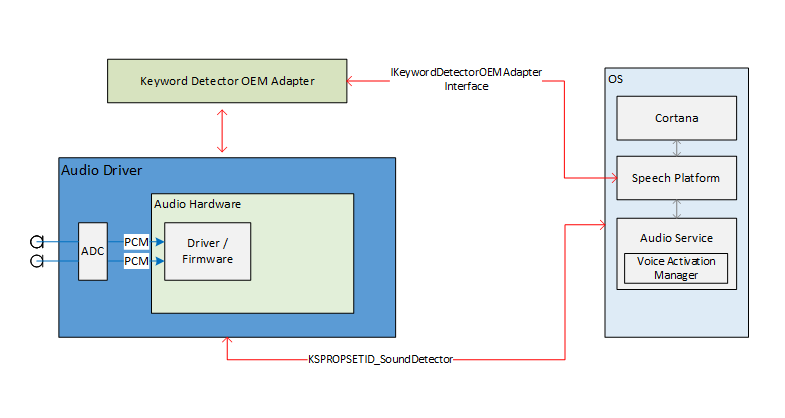
音声アクティブ化を有効にするためのオーディオ スタック外部インターフェイスは、音声プラットフォームとオーディオ ドライバーの通信パイプラインとして機能します。 外部インターフェイスは 3 つの部分に分かれています。
- キーワード検出器デバイス ドライバー インターフェイス (DDI)。 キーワード検出器デバイス ドライバー インターフェイスは、HW キーワード スポッター (KWS) の構成と準備を担当します。 また、ドライバーが検出イベントをシステムに通知するためにも使用されます。
- キーワード検出器 OEM アダプター DLL。 この DLL は、キーワードの検出を支援するために OS で使用するドライバー固有の不透明なデータを適応させる COM インターフェイスを実装します。
- WaveRT ストリーミングの機能強化。 この機能強化により、オーディオ ドライバーは、キーワード検出からバッファーに格納されたオーディオ データをバースト ストリーミングできます。
オーディオ エンドポイントのプロパティ
オーディオ エンドポイント グラフの構築は正常に行われます。 グラフは、リアルタイムキャプチャよりも高速に処理できるように準備されています。 キャプチャされたバッファーのタイムスタンプは真実のままです。 具体的には、タイムスタンプは、過去にキャプチャされてバッファリングされ、現在バーストしているデータを正しく反映します。
Bluetoothバイパスオーディオストリーミングの理論
ドライバーは、通常どおり、キャプチャ デバイスの KS フィルターを公開します。 このフィルターは、検出イベントを構成、有効化、および通知するためのいくつかの KS プロパティと KS イベントをサポートします。 このフィルターには、キーワード スポッター (KWS) ピンとして識別される追加のピン ファクトリも含まれています。 このピンは、キーワード スポッターからオーディオをストリーミングするために使用されます。
次のプロパティです。
- サポートされているキーワードの種類 - KSPROPERTY_SOUNDDETECTOR_PATTERNS。 このプロパティは、検出されるキーワードを構成するためにオペレーティング システムによって設定されます。
- キーワード パターン GUID の一覧 - KSPROPERTY_SOUNDDETECTOR_SUPPORTEDPATTERNS。 このプロパティは、サポートされているパターンの種類を識別する GUID の一覧を取得するために使用されます。
- 武装 - KSPROPERTY_SOUNDDETECTOR_ARMED。 この読み取り/書き込みプロパティは、ディテクターが準備されているかどうかを示す単純なブール状態です。 OS は、キーワード検出機能を有効にするようにこれを設定します。 OS はこれをクリアして解除できます。 ドライバーは、キーワード パターンが設定されたとき、およびキーワードが検出された後に、これを自動的にクリアします。 (OS はリアームする必要があります。
- 試合結果 - KSPROPERTY_SOUNDDETECTOR_MATCHRESULT。 この読み取りプロパティは、検出が発生した後の結果データを保持します。
キーワードが検出されたときに発生するイベントは、KSEVENT_SOUNDDETECTOR_MATCHDETECTED イベントです。
操作のシーケンス
システムの起動
- OS は、サポートされているキーワードの種類を読み取り、その形式のキーワードがあることを確認します。
- OS は、ディテクタのステータス変更イベントに登録します。
- OS によってキーワード パターンが設定されます。
- OS は検出器を作動させます。
KSイベント受信時
- ドライバーは検出器を解除します。
- OS は、キーワード検出機能の状態を読み取り、返されたデータを解析して、検出されたパターンを判断します。
- OS は検出器を再武装します。
内部ドライバとハードウェアの動作
検出器が武装している間、ハードウェアはオーディオデータを連続的にキャプチャし、小さなFIFOバッファにバッファリングすることができます。 (この FIFO バッファーのサイズは、このドキュメント以外の要件によって決まりますが、通常は数百ミリ秒から数秒になる場合があります。)検出アルゴリズムは、このバッファを通過するデータストリーミングに対して動作します。 ドライバとハードウェアの設計は、武装している間は、キーワードが検出されるまで、ドライバとハードウェアの間に相互作用がなく、"アプリケーション" プロセッサへの割り込みも行われないようなものです。 これにより、他のアクティビティがない場合に、システムはより低い電力状態に到達できます。
ハードウェアがキーワードを検出すると、割り込みが生成されます。 ドライバーが割り込みを処理するのを待っている間、ハードウェアはオーディオをバッファーにキャプチャし続け、キーワードが失われた後のデータがバッファリング制限内で行われないようにします。
キーワードのタイムスタンプ
キーワードを検出した後、すべての音声アクティベーション ソリューションは、キーワードの開始の 250ms前を含め、すべての音声キーワードをバッファリングする必要があります。 オーディオ ドライバーは、ストリーム内のキー フレーズの開始と終了を識別するタイムスタンプを提供する必要があります。
キーワードの開始/終了タイムスタンプをサポートするために、DSPソフトウェアはDSPクロックに基づいて内部的にイベントのタイムスタンプを取得する必要があります。 キーワードが検出されると、DSP ソフトウェアはドライバーと対話して KS イベントを準備します。 ドライバーと DSP ソフトウェアは、DSP タイムスタンプを Windows パフォーマンス カウンター値にマップする必要があります。 これを行う方法は、ハードウェア設計に固有です。 考えられる解決策の 1 つは、ドライバーが現在のパフォーマンス カウンターを読み取り、現在の DSP タイムスタンプを照会し、現在のパフォーマンス カウンターを再度読み取り、パフォーマンス カウンターと DSP 時間の相関関係を推定することです。 その後、相関関係が与えられると、ドライバーはキーワード DSP タイムスタンプを Windows パフォーマンス カウンターのタイムスタンプにマップできます。
キーワード ディテクタ OEM アダプタ インターフェイス
OEM は、OS とドライバーの間の仲介役として機能する COM オブジェクトの実装を提供し、KSPROPERTY_SOUNDDETECTOR_PATTERNSとKSPROPERTY_SOUNDDETECTOR_MATCHRESULTを介してオーディオ ドライバーに書き込まれ読み取られる不透明なデータの計算または解析を支援します。
COM オブジェクトの CLSID は、KSPROPERTY_SOUNDDETECTOR_SUPPORTEDPATTERNSによって返されるディテクター パターン タイプの GUID です。 OS は、パターンの種類 GUID を渡して CoCreateInstance を呼び出し、キーワード パターンの種類と互換性のある適切な COM オブジェクトをインスタンス化し、オブジェクトの IKeywordDetectorOemAdapter インターフェイスのメソッドを呼び出します。
COM スレッド モデルの要件
OEM の実装では、任意の COM スレッド モデルを選択できます。
IKeywordDetectorOemAdapter
インターフェイスの設計では、オブジェクトの実装をステートレスに保とうとします。 言い換えれば、実装では、メソッド呼び出し間に状態を格納する必要はありません。 実際、内部 C++ クラスでは、一般的な COM オブジェクトの実装に必要なメンバー変数以外のメンバー変数は必要ない可能性があります。
メソッド
次のメソッドを実装します。
- IKeywordDetectorOemAdapter::BuildArmingPatternData
- IKeywordDetectorOemAdapter::ComputeAndAddUserModelData
- IKeywordDetectorOemAdapter::GetCapabilities
- IKeywordDetectorOemAdapter::ParseDetectionResultData
- IKeywordDetectorOemAdapter::VerifyUserKeyword
KEYWORDID
KEYWORDID 列挙体は、キーワードの語句テキスト/関数を識別し、Windows 生体認証サービス アダプターでも使用されます。 詳細については、生体認証フレームワークの概要 - コア プラットフォーム コンポーネントを参照してください
typedef enum {
KwInvalid = 0,
KwHeyCortana = 1,
KwSelect = 2
} KEYWORDID;
キーワードセレクター
KEYWORDSELECTOR 構造体は、特定のキーワードと言語を一意に選択する ID のセットです。
typedef struct
{
KEYWORDID KeywordId;
LANGID LangId;
} KEYWORDSELECTOR;
モデルデータの処理
静的なユーザーに依存しないモデル - OEM DLL には、通常、DLL に組み込まれている、または DLL に含まれる別のデータ ファイルに、静的なユーザーに依存しないモデル データが含まれます。 GetCapabilities ルーチンによって返される、サポートされているキーワード ID のセットは、このデータによって異なります。 たとえば、GetCapabilities によって返されるサポートされているキーワード ID の一覧に KwHeyCortana が含まれている場合、静的なユーザーに依存しないモデル データには、サポートされているすべての言語の "コルタナさん" (またはその翻訳) のデータが含まれます。
動的ユーザー依存モデル - IStream は、ランダム アクセス ストレージ モデルを提供します。 OS は、 IKeywordDetectorOemAdapter インターフェイスの多くのメソッドに IStream インターフェイス ポインターを渡します。 OS は、最大 1 MB のデータ用の適切なストレージを使用して IStream 実装をバックアップします。
このストレージ内のデータの内容と構造は、OEM によって定義されます。 目的は、OEM DLL によって計算または取得されたユーザー依存モデル データの永続的なストレージです。
OS は、特にユーザーがキーワードをトレーニングしたことがない場合に、空の IStream を使用してインターフェイス メソッドを呼び出すことができます。 OS は、ユーザーごとに個別の IStream ストレージを作成します。 つまり、特定の IStream は、1 人のユーザーのみのモデル データを格納します。
OEM DLL 開発者は、ユーザーに依存しないデータとユーザーに依存するデータの管理方法を決定します。 ただし、ユーザー データは IStream の外部に格納されません。 考えられる OEM DLL 設計の 1 つは、現在のメソッドのパラメーターに応じて、IStream と静的ユーザーに依存しないデータへのアクセスを内部的に切り替えることです。 別の設計では、各メソッド呼び出しの開始時に IStream をチェックし、静的なユーザーに依存しないデータが IStream にまだ存在しない場合は追加し、メソッドの残りの部分がすべてのモデル データの IStream のみにアクセスできるようにすることができます。
トレーニングと操作のオーディオ処理
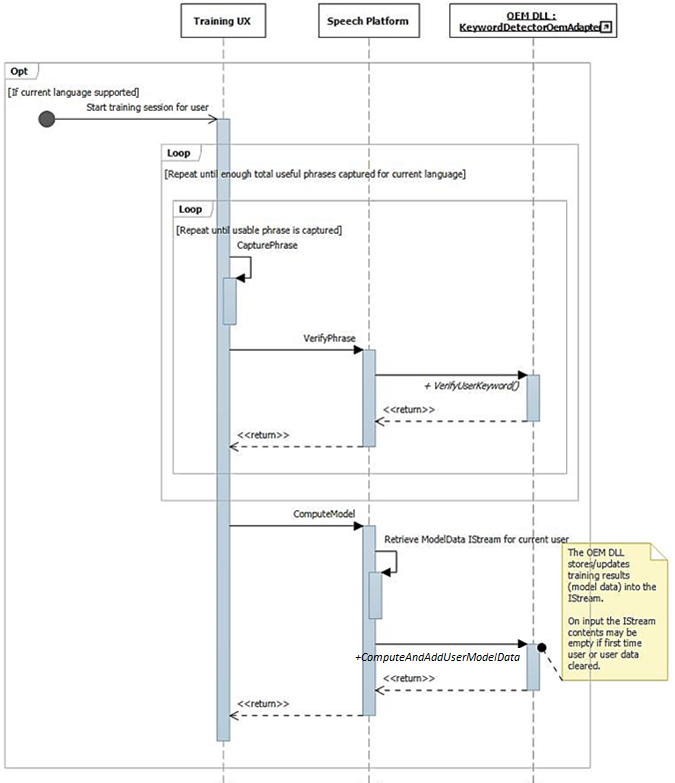
前述したように、トレーニング UI フローでは、音声が豊富な完全な文がオーディオ ストリームで使用できるようになります。 各文は個別に IKeywordDetectorOemAdapter::VerifyUserKeyword に渡され、想定されるキーワードが含まれ、許容できる品質であることを確認します。 すべての文が収集され、UI によって検証された後、それらはすべて IKeywordDetectorOemAdapter::ComputeAndAddUserModelData への 1 回の呼び出しで渡されます。
音声は、音声アクティベーショントレーニング用に独自の方法で処理されます。 次の表は、音声アクティベーション トレーニングと通常の音声認識の使用法の違いをまとめたものです。
|
| 音声トレーニング | 音声認識 | |
| Mode | 直接 | 生または音声 |
| 固定 | 正常 | KWS |
| オーディオフォーマット | 32 ビット浮動小数点 (タイプ = オーディオ、サブタイプ = IEEE_FLOAT、サンプリング レート = 16 kHz、ビット = 32) | OS オーディオ スタックによって管理される |
| マイク | マイク0 | すべてのマイクをアレイまたはモノラルで |
キーワード認識システムの概要
この図は、キーワード認識システムの概要を示しています。
キーワード認識シーケンス図
これらの図では、音声ランタイム モジュールが "音声プラットフォーム" として示されています。 前述のように、Windows 音声プラットフォームは、Cortana やディクテーションなど、Windows 10 のすべての音声エクスペリエンスを強化するために使用されます。
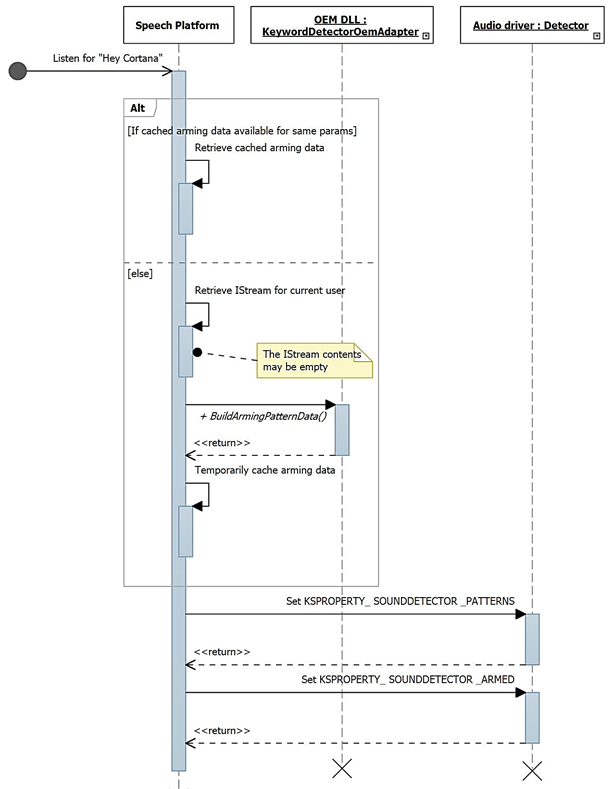
起動時に、IKeywordDetectorOemAdapter::GetCapabilities を使用して機能が収集されます。

その後、ユーザーが「自分の声を学習する」を選択すると、トレーニングフローが呼び出されます。
この図は、キーワード検出のための準備のプロセスを示しています。
WAVERTの機能強化
ミニポート インターフェイスは、WaveRT ミニポート ドライバーによって実装されるように定義されています。 これらのインターフェイスは、オーディオ ドライバーを簡略化したり、OS オーディオ パイプラインのパフォーマンスと信頼性を向上させたり、新しいシナリオをサポートしたりするための方法を提供します。 新しい PnP デバイス インターフェイス プロパティが定義され、ドライバーはバッファー サイズ制約の静的な式を OS に提供できます。
バッファサイズ
ドライバーは、OS、ドライバー、ハードウェア間でオーディオ データを移動するときに、さまざまな制約の下で動作します。 これらの制約は、メモリとハードウェア間でデータを移動する物理的なハードウェア トランスポート、および/またはハードウェアまたは関連する DSP 内の信号処理モジュールが原因である可能性があります。
HW-KWS ソリューションは、少なくとも 100msから最大 200msのオーディオ キャプチャ サイズをサポートする必要があります。
ドライバーは、KS ストリーミング ピンを持つ KS フィルターの KSCATEGORY_AUDIO PnP デバイス インターフェイスで DEVPKEY_KsAudio_PacketSize_Constraints デバイス プロパティを設定することで、バッファー サイズの制約を表します。 このプロパティは、KS フィルター インターフェイスが有効になっている間、有効で安定した状態を維持する必要があります。 OS は、ドライバーへのハンドルを開いてドライバーを呼び出すことなく、いつでもこの値を読み取ることができます。
DEVPKEY_KsAudio_PacketSize_Constraints
DEVPKEY_KsAudio_PacketSize_Constraints プロパティ値には、物理的なハードウェアの制約 (つまり、WaveRT バッファーからオーディオ ハードウェアにデータを転送するメカニズムによる) を記述するKSAUDIO_PACKETSIZE_CONSTRAINTS構造が含まれています。 構造体には、任意の信号処理モードに固有の制約を記述する 0 個以上のKSAUDIO_PACKETSIZE_PROCESSINGMODE_CONSTRAINT構造体の配列が含まれます。 ドライバーは、 PcRegisterSubdevice を呼び出す前に、またはストリーミング ピンの KS フィルター インターフェイスを有効にする前に、このプロパティを設定します。
IMiniportWaveRTInputStream
ドライバーは、ドライバーから OS へのオーディオ データフローをより適切に調整するために、このインターフェイスを実装します。 このインターフェイスがキャプチャ ストリームで使用できる場合、OS はこのインターフェイスのメソッドを使用して WaveRT バッファー内のデータにアクセスします。 詳細については、IMiniportWaveRTInputStream::GetReadPacketを参照してください
IMiniportWaveRTOutputStream
WaveRT ミニポートは、必要に応じてこのインターフェイスを実装して、OS からの書き込みの進行状況を通知し、正確なストリーム位置を返します。 詳細については、IMiniportWaveRTOutputStream::SetWritePacket、IMiniportWaveRTOutputStream::GetOutputStreamPresentationPositionとIMiniportWaveRTOutputStream::GetPacketCountを参照してください。
パフォーマンス カウンターのタイムスタンプ
いくつかのドライバー ルーチンは、サンプルがデバイスによってキャプチャまたは提示された時刻を反映した Windows パフォーマンス カウンターのタイムスタンプを返します。
複雑なDSPパイプラインと信号処理を備えたデバイスでは、正確なタイムスタンプを計算することが困難な場合があるため、慎重に行う必要があります。 タイムスタンプは、サンプルが OS との間で DSP に転送された時刻を単純に反映するべきではありません。
- DSP内では、DSPの内部ウォールクロックを使用してサンプルのタイムスタンプを追跡します。
- ドライバーと DSP の間で、Windows パフォーマンス カウンターと DSP ウォール クロックの間の相関関係を計算します。 この手順は、非常に単純なもの(ただし、精度は低い)から、かなり複雑なものや斬新なもの(ただし、より正確)までさまざまです。
- 信号処理アルゴリズム、パイプライン、またはハードウェアの転送による一定の遅延は、特に考慮されていない限り、考慮に入れます。
バースト読み取り動作
このセクションでは、バースト読み取りの OS とドライバーの相互作用について説明します。 バースト読み取りは、ドライバーが IMiniportWaveRTInputStream::GetReadPacket 関数を含むパケット ベースのストリーミング WaveRT モデルをサポートしている限り、音声アクティブ化シナリオの外部で発生する可能性があります。
バースト読み取りシナリオの 2 つの例について説明します。 1 つのシナリオでは、ミニポートがピン カテゴリ KSNODETYPE_AUDIO_KEYWORDDETECTORを持つピンをサポートしている場合、ドライバーはキーワードが検出されたときにデータのキャプチャと内部バッファリングを開始します。 別のシナリオでは、OS が IMiniportWaveRTInputStream::GetReadPacket を呼び出すことによって十分な速度でデータを読み取っていない場合、ドライバーは必要に応じて WaveRT バッファーの外部にデータを内部的にバッファーできます。
KSSTATE_RUN に移行する前にキャプチャされたデータをバーストするには、ドライバーは、バッファーされたキャプチャ データと共に正確なサンプル タイムスタンプ情報を保持する必要があります。 タイムスタンプは、キャプチャされたサンプルのサンプリング瞬間を識別します。
ストリームが KSSTATE_RUN に切り替わると、ドライバーは既に使用可能なデータがあるため、バッファー通知イベントをすぐに設定します。
このイベントで、OS は GetReadPacket() を呼び出して、使用可能なデータに関する情報を取得します。
a. ドライバーは、有効なキャプチャ データのパケット番号 (KSSTATE_STOP から KSSTATE_RUN への移行後の最初のパケットの場合は 0) を返し、そこから OS は WaveRT バッファー内のパケット位置と、ストリームの開始を基準としたパケット位置を派生させることができます。
b. また、ドライバーは、パケット内の最初のサンプルのサンプリング瞬間に対応するパフォーマンス カウンター値を返します。 このパフォーマンス カウンター値は、ハードウェアまたはドライバー内 (WaveRT バッファーの外部) でバッファーされているキャプチャ データの量に応じて、比較的古い場合があることに注意してください。
c. 使用可能な未読バッファリングデータがさらにある場合、ドライバは次のいずれかを行います。 そのデータを WaveRT バッファーの使用可能な領域 (つまり、GetReadPacket から返されたパケットで使用されていない領域) にすぐに転送し、MoreData に対して 真実 を返し、このルーチンから戻る前にバッファー通知イベントを設定します。 または、ii. 次のパケットを WaveRT バッファーの使用可能な領域にバーストするようにハードウェアをプログラムし、MoreData に対して 間違い を返し、後で転送の完了時にバッファー イベントを設定します。
OS は、GetReadPacket() によって返される情報を使用して、WaveRT バッファーからデータを読み取ります。
OS は、次のバッファー通知イベントを待機します。 ドライバーが手順 (2c) でバッファー通知を設定した場合、待機はすぐに終了する可能性があります。
ドライバーが手順 (2c) でイベントをすぐに設定しなかった場合、ドライバーは、キャプチャされたデータを WaveRT バッファーに転送し、OS が読み取れるようにした後にイベントを設定します
(2)に進みます。 KSNODETYPE_AUDIO_KEYWORDDETECTORキーワード検出器ピンの場合、ドライバーは少なくとも5000msのオーディオデータに十分な内部バーストバッファリングを割り当てる必要があります。 バッファーがオーバーフローする前に OS がピンにストリームを作成できない場合、ドライバーは内部バッファリング アクティビティを終了し、関連付けられているリソースを解放する可能性があります。
ウェイクオンボイス
Wake On Voice (WoV) を使用すると、ユーザーは "コルタナさん" などの特定のキーワードを発声することで、画面オフの低電力状態から画面オンのフルパワー状態まで、音声認識エンジンをアクティブ化して照会できます。
この機能により、画面がオフでデバイスがアイドル状態の場合など、デバイスが低電力状態にある間、デバイスは常にユーザーの音声をリッスンできます。 これは、通常のマイク録音中に見られるはるかに高い電力使用量と比較すると、低電力であるリスニングモードを使用することによって行われます。 低電力の音声認識により、ユーザーは "コルタナさん" などの定義済みのキー フレーズを発声するだけで、その後に "次の予定はいつですか" などの連鎖した音声フレーズを発声して、ハンズフリーで音声を呼び出すことができます。 これは、デバイスが使用中であるか、画面をオフにしてアイドル状態であるかに関係なく機能します。
オーディオ スタックは、ウェイク データ (話者 ID、キーワード トリガー、信頼度) を通信し、キーワードが検出されたことを関心のあるクライアントに通知する役割を担います。
モダン スタンバイ システムでの検証
システムアイドル状態からの WoV は、HLK の AC 電源のモダン スタンバイ ウェイク オン ボイスの基本テストおよび DC 電源のモダン スタンバイ ウェイク オン ボイスの基本テストを使用したモダン スタンバイ システムで検証できます。 これらのテストでは、システムにハードウェア キーワード スポッター (HW-KWS) があり、最も深いランタイム アイドル プラットフォーム状態 (DRIPS) に入ることができ、システム再開待機時間が 1 秒以下の音声コマンドでモダン スタンバイからスリープ解除できることを確認します。
フィードバック
以下は間もなく提供いたします。2024 年を通じて、コンテンツのフィードバック メカニズムとして GitHub の issue を段階的に廃止し、新しいフィードバック システムに置き換えます。 詳細については、「https://aka.ms/ContentUserFeedback」を参照してください。
フィードバックの送信と表示