Active Directory Domain Services のキャパシティ プランニング
このトピックは元々、Active Directory Domain Services (AD DS) のキャパシティ プランニングに関する推奨事項を提供するために、Microsoft のプログラム マネージャーである Ken Brumfield によって書かれました。
キャパシティ プランニングの目標
キャパシティ プランニングは、パフォーマンス インシデントのトラブルシューティングと同じではありません。 これらは密接に関連していますが、まったく異なっています。 キャパシティ プランニングの目標は次のとおりです。
- 環境を適切に実装して運用する
- パフォーマンスの問題のトラブルシューティングに費やす時間を最小限に抑える
キャパシティ プランニングでは、クライアントのパフォーマンス要件を満たし、データセンター内のハードウェアをアップグレードするために必要な時間を提供するために、組織はピーク時に 40% のプロセッサ使用率というベースライン ターゲットを設定している場合があります。 一方、異常なパフォーマンス インシデントが通知されるように、監視アラートのしきい値を 5 分間隔で 90% に設定している場合があります。
違いは、容量管理のしきい値を継続的に超えている場合 (1 回限りのイベントは問題にはなりません) に、容量を追加する (つまり、より多くのまたはより高速なプロセッサを追加する) ことが解決策になるのか、または複数のサーバー間でサービスの規模拡張することが解決策になるのかということです。 パフォーマンス アラートのしきい値は、クライアント エクスペリエンスが現在問題になっていて、問題に対処するには早急な措置が必要であることを意味します。
容量管理は、自動車事故の防止 (事故を防げる運転、ブレーキが適切に機能していることの確認など) に例えることができます。一方、パフォーマンスのトラブルシューティングは、事故後に警察、消防署、および救急医療の専門家が行うことです。 これは、Active Directory 式の "事故を防げる運転" に関することです。
過去数年間で、スケールアップ システムのキャパシティ プランニングのガイダンスは大幅に変更されています。 システム アーキテクチャにおける次の変更は、サービスの設計とスケーリングに関する基本的な前提に挑戦しています。
- 64 ビット サーバー プラットフォーム
- 仮想化
- 消費電力への関心の高まり
- SSD ストレージ
- クラウド シナリオ
また、このアプローチは、サーバーベースのキャパシティ プランニングの演習から、サービスベースのキャパシティ プランニングの演習に移行しています。 Active Directory Domain Services (AD DS) は、多くの Microsoft およびサードパーティ製品でバックエンドとして使用される成熟した分散サービスであり、他のアプリケーションを実行するために必要な容量を確保するために正しく計画するための最も重要な製品の 1 つになっています。
キャパシティ プランニング ガイダンスのベースライン要件
この記事では、次のベースライン要件が想定されています。
- 読者は、「Windows Server 2012 R2 のパフォーマンス チューニング ガイドライン」を読んで十分に理解していること。
- Windows Server プラットフォームが、x64 ベースのアーキテクチャであること。 ただし、ご使用の Active Directory 環境が Windows Server 2003 x86 (現在はサポート ライフサイクルが終了しています) にインストールされていて、メモリ内に簡単に保持できるサイズが 1.5 GB 未満のディレクトリ情報ツリー (DIT) がある場合でも、この記事のガイドラインは引き続き適用可能です。
- キャパシティ プランニングは継続的なプロセスであり、環境が期待をどの程度満たしているかを定期的に確認する必要があります。
- 最適化は、ハードウェアのコストの変化に応じて、複数のハードウェア ライフサイクルにわたって行われます。 たとえば、メモリが安くなったり、コアあたりのコストが下がったり、さまざまなストレージ オプションの価格が変化します。
- 1 日の全稼働時間のピークに対して計画します。 30 分または 1 時間間隔でこれを確認することをお勧めします。 それより長くすると、実際のピークが隠される可能性があり、短くすると、"一時的なスパイク" によってゆがめられる可能性があります。
- 企業のハードウェア ライフサイクル全体にわたる成長を計画します。 これには、段階的な方法でハードウェアをアップグレードまたは追加する方法や、3 - 5 年ごとに完全な更新を行う方法などがあります。 いずれの場合も、Active Directory の負荷がどれだけ増大するかについての "推測" が必要です。 履歴データが収集されている場合は、この評価に役立ちます。
- フォールト トレランスを計画します。 推定値 N が導き出されたら、N – 1、N – 2、N –x を含むシナリオを計画します。
組織のニーズに応じてサーバーを追加し、単一または複数のサーバーの損失が最大ピーク容量の見積もりを超えないようにします。
また、拡張計画とフォールト トレランス計画を統合する必要があることも考慮してください。 たとえば、負荷をサポートするには 1 つの DC が必要ですが、その負荷が翌年に 2 倍になり、合計 2 つの DC が必要であると推定される場合は、フォールト トレランスをサポートするのに十分な容量がありません。 この解決策は、3 つの DC から開始することになります。 予算が厳しい場合は、3 - 6 か月後に 3 番目の DC を追加することを計画してもよいでしょう。
注意
Active Directory 対応アプリケーションを追加すると、DC の負荷に大きな影響を与える可能性があります。その負荷がアプリケーション サーバーまたはクライアントから発生したかどうかには関係ありません。
キャパシティ プランニング サイクルの 3 段階のプロセス
キャパシティ プランニングでは、まず、必要なサービスの品質を決定します。 たとえば、コア データセンターでは、高いレベルの同時実行性がサポートされており、ユーザーと使用するアプリケーションに対してより一貫性のあるエクスペリエンスが求められます。これには、冗長性にさらに注意を払い、システムとインフラストラクチャのボトルネックを最小限に抑える必要があります。 これに対し、少数のユーザーしかいないサテライトの場所では、同じレベルの同時実行性やフォールト トレランスは必要ありません。 そのため、サテライト オフィスでは、基盤となるハードウェアとインフラストラクチャの最適化にそれほど注意を払う必要がない可能性があり、コスト削減につながる可能性があります。 ここでのすべての推奨事項とガイダンスは、最適なパフォーマンスのためのものであり、要件がそれほど厳しくないシナリオでは、選択的に緩和することができます。
次の質問は、仮想か物理かということです。 キャパシティ プランニングの観点からは、正しい答えも間違った答えもありません。使用する変数のセットが異なるだけです。 仮想化のシナリオは、次の 2 つのオプションのいずれかになります。
- ホストごとに 1 つのゲストがある "直接マッピング" (仮想化はサーバーから物理ハードウェアを抽象化するためだけに存在します)
- "共有ホスト"
テストと運用の各シナリオでは、"直接マッピング" シナリオを物理ホストと同じように扱うことができることが示されています。 ただし、"共有ホスト" では、いくつかの考慮事項が発生します。これについては後で詳しく説明します。 "共有ホスト" のシナリオでは、AD DS もリソースをめぐって競合していることを意味し、そのためのペナルティやチューニングに関する考慮事項があります。
これらの考慮事項を念頭に置くと、キャパシティ プランニング サイクルは、反復的な 3 段階のプロセスです。
- 既存の環境を測定し、システムのボトルネックが現在発生している場所を特定し、必要な容量を計画するために必要な環境の基本を取得します。
- 手順 1 で説明した条件に従って、必要なハードウェアを決定します。
- 実装されたインフラストラクチャが仕様の範囲内で動作していることを監視および検証します。 この手順で収集されるデータの一部は、キャパシティ プランニングの次のサイクルのベースラインになります。
プロセスを適用する
パフォーマンスを最適化するには、これらの主要なコンポーネントが正しく選択されていて、アプリケーションの負荷に合わせてチューニングされていることを確認します。
- メモリ
- ネットワーク
- ストレージ
- プロセッサ
- Net Logon
AD DS の基本的なストレージ要件と、適切に記述されたクライアント ソフトウェアの一般的な動作により、10,000 - 20,000 人のユーザーがいる環境では、物理ハードウェアに関するキャパシティプランニングへの多額の投資を控えることができます。これは、最新のサーバー クラス システムのほとんどがこれらの負荷を処理するからです。 とはいえ、適切なハードウェアを選択するために既存の環境を評価する方法を次の表にまとめました。 AD DS 管理者がベースラインの推奨事項と環境固有のプリンシパルを使用して自身のインフラストラクチャを評価できるように、各コンポーネントは以降のセクションで詳細に分析されます。
一般的には次のとおりです。
- 現在のデータに基づくサイズ設定は、現在の環境に対してのみ正確です。
- どのような見積もりを行う場合でも、ハードウェアのライフサイクル全体で需要が増加すると予想します。
- 今、サイズを大きくしてより大きな環境に拡張するか、ライフサイクル全体で容量を追加するかを決定します。
- 仮想化の場合、すべて同じ容量計画の原則と方法論が適用されます。ただし、仮想化のオーバーヘッドは、ドメインに関連するすべてのものに追加する必要があります。
- キャパシティ プランニングは、予測しようとするものはどれも同じですが、正確な科学ではありません。 100% の精度で完全に計算されることを期待しないでください。 ここでのガイダンスは最も無駄のない推奨事項です。安全性を高めるために容量を追加し、環境がターゲット内に収まっていることを継続的に検証します。
データ コレクションの概要テーブル
新しい環境
| コンポーネント | 見積もり |
|---|---|
| ストレージまたはデータベースのサイズ | ユーザーごとに 40 KB - 60 KB |
| RAM | データベース サイズ 基本オペレーティング システムの推奨事項 サードパーティ アプリケーション |
| ネットワーク | 1 GB |
| CPU | コアごとに 1000 人の同時ユーザー |
高レベルの評価基準
| コンポーネント | 評価基準 | 計画に関する考慮事項 |
|---|---|---|
| ストレージまたはデータベースのサイズ | ストレージの制限の「最適化によって解放されたディスク領域のログをアクティブ化するには」というタイトルのセクション | |
| ストレージまたはデータベースのパフォーマンス |
|
|
| RAM |
|
|
| ネットワーク |
|
|
| CPU |
|
|
| NetLogon |
|
|
計画
長い間、AD DS のサイズ設定に関するコミュニティの推奨事項は、"データベースのサイズに応じて RAM を増設する" ということでした。 その推奨事項の大部分は、ほとんどの環境で考慮する必要があることです。 しかし、AD DS を使用しているエコシステムは、1999 年の導入以来、AD DS 環境自体と同様にはるかに大きくなっています。 コンピューティング能力の向上と、x86 アーキテクチャから x64 アーキテクチャへの切り替えにより、パフォーマンスのサイズ調整の微妙な側面は、物理ハードウェア上で AD DS を実行している多くの顧客とは無関係になりましたが、仮想化の成長により、以前よりも多くの対象ユーザーにチューニングの懸念事項が再び発生しました。
したがって、次のガイダンスは、Active Directory が物理、仮想と物理の組み合わせ、または純粋に仮想化されたシナリオのいずれで展開されているかに関係なく、サービスとしての Active Directory の需要を決定および計画する方法に関するものです。 そのため、評価をストレージ、メモリ、ネットワーク、プロセッサの 4 つの主要なコンポーネントにそれぞれ分割します。 つまり、AD DS のパフォーマンスを最大化するための目標は、プロセッサの限界にできる限り近づけることです。
RAM
簡単に言うと、RAM にキャッシュできるものが多いほど、ディスクに移動する必要が少なくなります。 サーバーのスケーラビリティを最大限に高めるには、RAM の最小容量を、現在のデータベース サイズ、SYSVOL の合計サイズ、オペレーティング システムで推奨されている容量、エージェントに対するベンダーの推奨事項 (ウイルス対策、監視、バックアップなど) の合計にする必要があります。 サーバーの有効期間中の増加に対応するために、容量をさらに追加する必要があります。 これは、環境の変化に基づくデータベースの増加量の見積もりに基づいているため、環境の影響を受けます。
RAM の容量を最大化することがコスト効率に優れていない (サテライトの場所など)、または実現不可能 (DIT が大きすぎる) な環境の場合は、ストレージ セクションを参照して、ストレージが適切に設計されていることを確認してください。
メモリのサイズ変更において一般的な状況で発生する結果は、ページ ファイルのサイズ変更です。 メモリに関連する他のすべてのものと同じ状況の場合、非常に低速なディスクへの移動を最小限に抑えることが目標です。 そのため、質問は "ページ ファイルのサイズをどのように設定するべきか" から始まり、 "ページングを最小化するためにどのくらいの RAM が必要か" へと進みます。 後者の質問に対する回答については、このセクションの残りの部分で説明します。 そのため、ページ ファイルのサイズ設定に関するほとんどの説明は、一般的なオペレーティング システムの推奨事項と、AD DS のパフォーマンスとは関係のないメモリ ダンプ用にシステムを構成する必要性の領域で行います。
評価中
ドメイン コントローラー (DC) で必要な RAM の容量は、次のような理由で実際には複雑な作業になります。
- 既存のシステムを使用して必要な RAM の量を測定しようとすると、エラーが発生する可能性が高くなります。これは、メモリ不足の条件下で LSASS がトリミングを行い、人為的に必要性を低下させるためです。
- 個々の DC は、クライアントにとって "興味深い"ものをキャッシュするだけでよいという主観的な事実。 つまり、Exchange サーバーのみのサイトの DC にキャッシュする必要があるデータは、ユーザーを認証するだけの DC にキャッシュする必要があるデータとは大きく異なります。
- 各 DC の RAM をケースバイケースで評価するための労力は膨大であり、環境の変化に応じて変化します。
- 推奨事項の背後にある基準は、情報に基づいた意思決定を行うのに役立ちます。
- RAM にキャッシュできるものが多いほど、ディスクに移動する必要が少なくなります。
- ストレージは、コンピューターの中で群を抜いて最も遅いコンポーネントです。 スピンドルベースおよび SSD ストレージ メディア上のデータへのアクセスは、RAM 内のデータへのアクセスよりも 100 万倍遅くなります。
したがって、サーバーのスケーラビリティを最大限に高めるため、RAM の最小容量は、現在のデータベース サイズ、SYSVOL の合計サイズ、オペレーティング システムで推奨されている容量、エージェントに対するベンダーの推奨事項 (ウイルス対策、監視、バックアップなど) の合計となります。 サーバーの有効期間中の増加に対応するために、容量をさらに追加します。 これは、データベースの増加の見積もりに基づいて、環境の影響を受けます。 ただし、エンド ユーザーの数が少ないサテライトの場所の場合、これらのサイトでほとんどの要求を処理するためにそれほど多くをキャッシュする必要がないため、これらの要件を緩和できます。
RAM の容量を最大化することがコスト効率に優れていない (サテライトの場所など)、または実現不可能 (DIT が大きすぎる) な環境の場合は、ストレージ セクションを参照して、ストレージのサイズが適切に設定されていることを確認してください。
注意
メモリのサイズを変更すると、結果的にページ ファイルのサイズが変更されます。 この目標は、非常に低速なディスクへの移行を最小限に抑えることを目的としているため、質問は "ページ ファイルのサイズをどのように設定するべきか" から始め、 "ページングを最小化するためにどのくらいの RAM が必要か" へと進みます。 後者の質問に対する回答については、このセクションの残りの部分で説明します。 そのため、ページ ファイルのサイズ設定に関するほとんどの説明は、一般的なオペレーティング システムの推奨事項と、AD DS のパフォーマンスとは関係のないメモリ ダンプ用にシステムを構成する必要性の領域で行います。
RAM の仮想化に関する考慮事項
ホストでメモリを過剰コミットすることは避けてください。 RAM の容量を最適化するための基本的な目標は、ディスクへの移動にかかる時間を最小限に抑えることです。 仮想化のシナリオでは、メモリの過剰コミットの概念は、物理マシン上に存在するよりも多くの RAM がゲストに割り当てられる場合に存在します。 これ自体は問題ではありません。 すべてのゲストによってアクティブに使用されているメモリの合計がホストの RAM 容量を超え、基盤となるホストがページングを開始したときに問題になります。 ドメイン コントローラーが NTDS.dit にアクセスしてデータを取得する場合、またはドメイン コントローラーがページ ファイルにアクセスしてデータを取得する場合、またはホストがディスクにアクセスしてゲストが RAM にあると考えているデータを取得する場合、パフォーマンスはディスクに束縛されます。
計算の概要の例
| コンポーネント | 推定メモリ (例) |
|---|---|
| 基本オペレーティング システムの推奨 RAM (Windows Server 2008) | 2 GB |
| LSASS 内部タスク | 200 MB |
| 監視エージェント | 100 MB |
| ウイルス対策 | 100 MB |
| データベース (グローバル カタログ) | 8.5 GB |
| 管理者が影響を受けずにログオンするための、バックアップを実行するためのクッション | 1 GB |
| 合計 | 12 GB |
推奨: 16 GB
時間の経過とともに、データベースにさらに多くのデータが追加され、サーバーはおそらく 3 - 5 年間運用されると想定されます。 33% の増加の推定に基づくと、16 GB は物理サーバーに配置するのに妥当な RAM 容量です。 仮想マシンでは、設定を簡単に変更でき、RAM を VM に追加できることを考えると、12 GB から開始し、将来の監視とアップグレードの計画を立てることが妥当です。
ネットワーク
評価中
このセクションでは、WAN を通過するトラフィックに重点を置いた レプリケーション トラフィックに関する要求の評価についてではなく (これについては「Active Directory レプリケーション トラフィック」で完全にカバーされています)、クライアント クエリ、グループ ポリシー アプリケーションなどを含む、必要な合計帯域幅とネットワーク容量の評価について説明します。 既存の環境の場合は、これはパフォーマンス カウンター “Network Interface(*)\Bytes Received/sec” と “Network Interface(*)\Bytes Sent/sec” を使用して収集できます。 ネットワーク インターフェイス カウンターのサンプル間隔は、15 分、30 分、60 分のいずれかです。 それより少ないと、一般的に揮発性が高すぎて適切な測定ができません。それより大きいと、毎日のピークが過度に滑らかになります。
注意
一般に、DC でのネットワーク トラフィックの大半は、DC がクライアント クエリに応答するときに送信されます。 これが送信トラフィックに焦点を当てる理由ですが、受信トラフィックについても各環境を評価することをお勧めします。 同じ方法を使用して、受信ネットワーク トラフィックの要件に対処して確認することもできます。 詳細については、サポート技術情報の記事「929851: Windows Vista および Windows Server 2008 では TCP/IP の既定の動的ポート範囲が変更されている」を参照してください。
帯域幅のニーズ
ネットワークのスケーラビリティの計画には、トラフィックの量と、ネットワーク トラフィックからの CPU 負荷という 2 つの異なるカテゴリがあります。 これらの各シナリオは、この記事の他のいくつかのトピックと比較すると簡単です。
サポートする必要のあるトラフィックの量を評価する場合、ネットワーク トラフィックの観点から、AD DS のキャパシティ プランニングには 2 つの固有のカテゴリがあります。 1 つ目は、ドメインコン トローラー間をトラバースするレプリケーション トラフィックです。これについては、リファレンス「Active Directory レプリケーション トラフィック」で詳しく説明されていますが、AD DS の現在のバージョンにも関連しています。 2 つ目は、サイト内のクライアントとサーバー間のトラフィックです。 計画するのが簡単なシナリオの 1 つは、クライアントに返送される大量のデータに比べて、クライアントから受信する要求が圧倒的に少ないサイト内トラフィックです。 通常、サイト内のサーバーあたり最大 5,000 ユーザーの環境では 100 MB で十分です。 5,000 を超えるユーザーには、1 GB のネットワーク アダプターと Receive Side Scaling (RSS) のサポートを使用することをお勧めします。 このシナリオを検証するには、特にサーバー統合のシナリオでは、サイト内のすべての DC で Network Interface(*)\Bytes/sec を調べ、それらを合計し、ドメイン コントローラーのターゲット数で割って、適切な容量を確保します。 これを行う最も簡単な方法は、Windows 信頼性およびパフォーマンス モニター (旧称 Perfmon) の "積み上げ面" ビューを使用して、すべてのカウンターが同じようにスケーリングされるようにすることです。
次の例を考えてみます (これは、一般的な規則が特定の環境に適用可能であることを検証するための非常に複雑な方法としても知られています)。 次のように仮定します。
- 目標は、サーバーの設置面積をできる限り削減することです。 理想的には、1 台のサーバーで負荷を処理し、冗長性を確保するために追加のサーバーを配置します (N + 1 シナリオ)。
- このシナリオでは、現在のネットワーク アダプターはスイッチド環境にあり、100 MB のみをサポートしています。 N シナリオ (DC の損失) では、ターゲット ネットワーク帯域幅の最大使用率は 60% です。
- 各サーバーには、約 10,000 のクライアントが接続されています。
グラフのデータ (Network Interface(*)\Bytes Sent/sec) から得られた知識:
- 営業日は午前 5 時 30 分頃に増加し始め、午後 7 時に減少します。
- ピークの時間帯は午前 8 時から午前 8 時 15 分までで、最もビジーな DC では 25 Bytes sent/sec を超えます。
注意
すべてのパフォーマンス データは履歴です。 そのため、午前 8 時 15 分のピーク データ ポイントは 午前 8 時から午前 8 時 15 分 までの負荷を示しています。
- 最もビジーな DC には、午前 4 時 より前に 20 Bytes sent/sec を超えるスパイクがあります。これは、異なるタイム ゾーンからの負荷、またはバックアップなどのバックグラウンド インフラストラクチャ アクティビティのいずれかを示している可能性があります。 午前 8 時のピークではこのアクティビティを超えているため、これは関係ありません。
- サイトには 5 つのドメイン コントローラーがあります。
- 最大負荷は DC あたり約 5.5 MB/秒です。これは、100 MB 接続の 44% に相当します。 このデータを使用すると、午前 8 時から午前 8 時 15 分の間に必要な合計帯域幅が 28 MB/秒であると見積もることができます。
注意
ネットワーク インターフェイスの送信/受信カウンターはバイト単位であり、ネットワーク帯域幅はビット単位で計測されることに注意してください。 100 MB ÷ 8 = 12.5 MB、1 GB ÷ 8 = 128 MB。
結論:
- この現在の環境は、60% のターゲット使用率で N + 1 レベルのフォールト トレランスを満たしています。 1 つのシステムをオフラインにすると、サーバーあたりの帯域幅が約 5.5 MB/秒 (44%) から約 7 MB/秒 (56%) に移行します。
- 1 台のサーバーに統合するという前述の目標に基づくと、これは最大目標使用率と理論的には 100 MB 接続の可能な使用率の両方を超えています。
- 1 GB の接続では、これは合計容量の 22% に相当します。
- N + 1 シナリオの通常の動作条件下では、クライアントの負荷はサーバーあたり約 14 MB/秒または合計容量の 11% で相対的に均等に分散されます。
- DC が使用できないときに容量が十分であることを保証するために、サーバーごとの通常の運用ターゲットは、30% のネットワーク使用率またはサーバーあたり 38 MB/秒になります。 フェールオーバー ターゲットは、60% のネットワーク使用率またはサーバーあたり 72 MB/秒になります。
つまり、システムの最終的な展開には、1 GB のネットワーク アダプターが必要であり、上記の負荷をサポートするネットワーク インフラストラクチャに接続されている必要があります。 さらに、生成されるネットワーク トラフィックの量を考えると、ネットワーク通信からの CPU 負荷が大きな影響を与える可能性があり、AD DS の最大スケーラビリティが制限される可能性があることに注意してください。 これと同じプロセスを使用して、DC への受信通信の量を見積もることができます。 しかし、受信トラフィックに比べて送信トラフィックの方が優勢であることを考えると、ほとんどの環境では学術的な演習になります。 サーバーあたりのユーザーが 5,000 人を超える環境では、RSS のハードウェア サポートを確保することが重要です。 ネットワーク トラフィックの量が多いシナリオでは、割り込み負荷の分散がボトルネックになることがあります。 これは、Processor(*)% Interrupt Time が CPU 間で不均一に分散していることで検出できます。 RSS 対応 NIC を使用すると、この制限を緩和し、スケーラビリティを向上させることができます。
注意
同様の方法を使用して、データ センターを統合する場合や、サテライトの場所にあるドメイン コントローラーを廃止する場合に必要な追加容量を見積もることができます。 クライアントへの送信トラフィックと受信トラフィックを収集するだけで、WAN リンクに存在するトラフィック量になります。
場合によっては、証明書のチェックが WAN での厳しいタイムアウトに対応できない場合など、トラフィックが遅いために、予想よりも多くのトラフィックが発生する可能性があります。 このため、WAN のサイズ設定と使用率は反復的で継続的なプロセスである必要があります。
ネットワーク帯域幅に関する仮想化に関する考慮事項
物理サーバーの推奨事項を作成するのは簡単です。5,000 人を超えるユーザーをサポートするサーバーの場合は 1 GB です。 複数のゲストが基礎となる仮想スイッチ インフラストラクチャの共有を開始したら、システム上のすべてのゲストをサポートするのに十分なネットワーク帯域幅がホストで確保されるように一層の注意が必要であるため、より厳密さが求められます。 これは、ホスト マシンへのネットワーク インフラストラクチャを確保するための拡張にすぎません。 これは、ネットワークが、仮想スイッチを経由するネットワーク トラフィックを持つホスト上の仮想マシン ゲストとして実行されているドメイン コントローラを包含しているかどうか、または物理スイッチに直接接続されているかどうかには関係ありません。 仮想スイッチは、送信されるデータ量をアップリンクでサポートする必要があるコンポーネントの 1 つにすぎません。 そのため、スイッチにリンクされている物理ホストの物理ネットワーク アダプターは、DC の負荷と、物理ネットワーク アダプターに接続されている仮想スイッチを共有している他のすべてのゲストをサポートできる必要があります。
計算の概要の例
| システム | 最大帯域幅 |
|---|---|
| DC 1 | 6.5 MB/秒 |
| DC 2 | 6.25 MB/秒 |
| DC 3 | 6.25 MB/秒 |
| DC 4 | 5.75 MB/秒 |
| DC 5 | 4.75 MB/秒 |
| 合計 | 28.5 MB/秒 |
推奨:72 MB/秒 (28.5 MB/秒を 40% で除算)
| ターゲット システム数 | 合計帯域幅 (上記から) |
|---|---|
| 2 | 28.5 MB/秒 |
| 結果として得られる通常の動作 | 28.5 ÷ 2 = 14.25 MB/秒 |
いつものように、時間の経過とともにクライアントの負荷が増加すると想定することができ、この増加は可能な限り最善の方法で計画する必要があります。 計画する推奨容量は、50% のネットワーク トラフィックの推定される増加を考慮に入れます。
Storage
ストレージの計画では、2 つのコンポーネントを構成します。
- 容量、またはストレージのサイズ
- パフォーマンス
多大な時間とドキュメントが容量の計画に費やされ、パフォーマンスが完全に見落とされることがよくあります。 現在のハードウェア コストでは、ほとんどの環境はこれらのいずれかが実際に懸念されるほど大きくはないため、"データベースのサイズに応じて RAM を増設する" という推奨事項で通常、残りの部分はカバーされますが、大規模な環境のサテライトの場所に対しては過剰かもしれません。
サイズ変更
ストレージの評価
Active Directory が発表された 13 年前は、4 GB と 9 GB のドライブが最も一般的なドライブ サイズでした。その時代と比較すると、Active Directory のサイズ設定は、最大規模の環境を除くすべての環境で考慮事項でさえありません。 180 GBの範囲で使用可能な最小のハード ドライブ サイズを使用して、オペレーティング システム全体、SYSVOL、NTDS.dit を 1 つのドライブに簡単に収めることができます。 そのため、この領域への多額の投資を廃止することをお勧めします。
考慮すべき唯一の推奨事項は、デフラグを有効にするために、NTDS.dit サイズの 110% が使用可能であることを確認することです。 さらに、ハードウェアの寿命にわたって増加に対応する必要があります。
まず最も重要な考慮事項は、NTDS.dit と SYSVOL の大きさを評価することです。 これらの測定値から、固定ディスクと RAM 割り当ての両方のサイズが導き出されます。 これらのコンポーネントは (比較的) 低コストであるため、計算は厳密で正確である必要はありません。 既存の環境と新しい環境の両方でこれを評価する方法については、「データ ストレージ」の一連の記事を参照してください。 具体的には、次の記事を参照してください。
既存の環境の場合 – 「ストレージの制限」の記事の「最適化によって解放されたディスク領域のログをアクティブ化するには」というタイトルのセクション。
新しい環境の場合 – 「Active Directory ユーザーと組織単位の増加見積もり」というタイトルの記事。
注意
これらの記事は、Windows 2000 の Active Directory のリリース時に行われたデータ サイズの見積もりに基づいています。 ご使用の環境内のオブジェクトの実際のサイズを反映するオブジェクト サイズを使用してください。
複数のドメインを持つ既存の環境を確認する場合、データベースのサイズに違いがある可能性があります。 これが当てはまる場合は、最小のグローバル カタログ (GC) と非 GC のサイズを使用します。
データベースのサイズは、オペレーティング システムのバージョンによって異なります。 Windows Server 2003 などの以前のオペレーティング システムを実行している DC では、特に Active Directory のごみ箱や資格情報の移動などの機能が有効になっている場合に、Windows Server 2008 R2 などのより新しいオペレーティング システムを実行する DC よりもデータベースのサイズが小さくなります。
注意
- 新しい環境の場合、Active Directory ユーザーと組織単位の増加見積もりで、10 万ユーザー (同じドメイン内) が約 450 MB の領域を消費していることが示されていることに注意してください。 値が設定されている属性は、総量に大きな影響を与える可能性があることに注意してください。 属性は、サードパーティ製品と Microsoft 製品 (Microsoft Exchange Server および Lync を含む) の両方によって多数のオブジェクトに設定されます。 環境内の製品のポートフォリオに基づく評価が推奨されますが、最大規模の環境を除き、すべての環境について計算を詳細に説明し、正確な見積もりをテストするという演習は、多大な時間と労力をかける価値は実際にはない場合があります。
- オフラインでのデフラグを可能にするために、NTDS.dit サイズの 110% が空き領域として使用可能であることを確認し、3 - 5 年のハードウェア寿命にわたる拡張を計画します。 ストレージが安価であることを考えると、ストレージ割り当てとして DIT の 300% のサイズでストレージを見積もると、拡張とオフラインでのデフラグの潜在的なニーズに十分に対応できます。
ストレージの仮想化に関する考慮事項
複数の仮想ハード ディスク (VHD) ファイルが 1 つのボリュームに割り当てられているシナリオでは、適切な領域が予約されていることを保証するために、少なくとも DIT のサイズの 210% (DIT の 100% + 110% の空き領域) の固定サイズのディスクを使用します。
計算の概要の例
| 評価フェーズから収集されたデータ | サイズ |
|---|---|
| NTDS.dit のサイズ | 35 GB |
| オフラインでのデフラグを許可する修飾子 | 2.1 GB |
| 必要なストレージの合計 | 73.5 GB |
注意
この必要なストレージは、SYSVOL、オペレーティング システム、ページ ファイル、一時ファイル、ローカルにキャッシュされたデータ (インストーラー ファイルなど)、アプリケーションに必要なストレージに加えて必要な分です。
Storage performance (ストレージのパフォーマンス)
ストレージのパフォーマンスの評価
ストレージはどのコンピューターでも最も低速なコンポーネントであるため、クライアント エクスペリエンスに最も大きい悪影響を及ぼす可能性があります。 RAM のサイズ設定の推奨事項が実行できないほど大規模な環境では、ストレージの計画でパフォーマンスを見落とした場合の結果は壊滅的なものになる可能性があります。 また、ストレージ テクノロジの複雑さと多様性により、"オペレーティング システム、ログ、データベースを別々の物理ディスクに配置する" という長年のベスト プラクティスの適用可能性が有用なシナリオで制限されるため、障害のリスクがさらに高まります。 これは、長年のベスト プラクティスが、"ディスク" が専用のスピンドルであり、これにより I/O を分離できるという前提に基づいているためです。 これが当てはまる仮定は、以下の導入により関係なくなりました。
- RAID
- 新しいストレージの種類と仮想化および共有ストレージのシナリオ
- 記憶域ネットワーク (SAN) 上の共有スピンドル
- SAN またはネットワークに接続されたストレージ上の VHD ファイル
- ソリッド ステート ドライブ
- 階層型記憶域アーキテクチャ (より大きなスピンドル ベースのストレージをキャッシュする SSD ストレージ層)
具体的には、すべての共有ストレージ (RAID、SAN、NAS、JBOD (記憶域スペース)、VHD) には、バックエンド ストレージに配置されている他の作業負荷によって、オーバーサブスクライブまたはオーバーロードされる機能が備わっています。 これらにより、SAN/ネットワーク/ドライバーの問題 (物理ディスクと AD アプリケーションの間のすべてのこと) によって調整や遅延が発生する可能性があるという課題も加わります。 明確にするために、これらは "悪い" 構成ではなく、途中ですべてのコンポーネントが正常に動作するようにする必要があるより複雑な構成です。したがって、パフォーマンスを確実に許容範囲内にするために一層の注意が必要です。 詳細な説明については、このドキュメントで後述する付録 C のサブセクション「SAN の概要」と付録 D を参照してください。 また、ソリッド ステート ドライブには、一度に 1 つの IO しか処理できないという回転ディスク (ハード ドライブ) の制限はありませんが、IO の制限はあり、SSD のオーバーロードまたはオーバーサブスクライブが発生する可能性があります。 つまり、基盤となるストレージ アーキテクチャと設計に関係なく、すべてのストレージ パフォーマンスの取り組みの最終目標は、必要な量の 1 秒あたりの入力/出力操作数 (IOPS) が使用可能であり、それらの IOPS が許容可能な時間枠内 (このドキュメントの別の場所で指定) で発生することを保証することです。 ローカルに接続されたストレージを使用するシナリオの場合は、従来のローカル ストレージのシナリオを設計する方法の基本について、付録 C を参照してください。 これらのプリンシパルは、一般により複雑なストレージ層に適用され、バックエンド ストレージ ソリューションをサポートするベンダーとの対話にも役立ちます。
- 幅広いストレージ オプションを使用できる場合は、特定のソリューションで AD DS のニーズを確実に満たせるように、ハードウェア サポート チームまたはベンダーの専門知識を活用することをお勧めします。 次の数値は、ストレージのスペシャリストに提供される情報です。
データベースが大きすぎて RAM に保持できない環境では、パフォーマンス カウンターを使用して、サポートする必要がある I/O の量を決定します。
- LogicalDisk(*)\Avg Disk sec/Read (たとえば、NTDS.dit が D:/ ドライブに格納されている場合、完全なパスは LogicalDisk(D:)\Avg Disk sec/Read になります)
- LogicalDisk(*)\Avg Disk sec/Write
- LogicalDisk(*)\Avg Disk sec/Transfer
- LogicalDisk(*)\Reads/sec
- LogicalDisk(*)\Writes/sec
- LogicalDisk(*)\Transfers/sec
現在の環境の需要をベンチマークするために、これらを 15/30/60 分間隔でサンプリングする必要があります。
結果を評価する
注意
これは通常、要求が最も厳しいコンポーネントであるため、データベースからの読み取りに重点が置かれています。LogicalDisk(<NTDS Log>)\Avg Disk sec/Write と LogicalDisk(<NTDS Log>)\Writes/sec) を置き換えることで、ログ ファイルへの書き込みに同じロジックを適用できます。
- LogicalDisk(<NTDS>)\Avg Disk sec/Read は、現在のストレージのサイズが適切に設定されているかどうかを示します。 結果がディスクの種類のディスクのアクセス時間とほぼ同じ場合、LogicalDisk(<NTDS>)\Reads/sec が有効な測定値です。 バックエンドのストレージの製造元の仕様を確認します。ただし、LogicalDisk(<NTDS>)\Avg Disk sec/Read の適切な範囲は、おおよそ次のようになります。
- 7200 – 9 から 12.5 ミリ秒 (ms)
- 10,000 – 6 から 10 ms
- 15,000 – 4 から 6 ms
- SSD – 1 から 3 ms
-
注意
ストレージのパフォーマンスが 15 ミリ秒から 20 ミリ秒で低下する (ソースによって異なります) という推奨事項があります。 上記の値と他のガイダンスの違いは、上記の値が通常の動作範囲であることです。 その他の推奨事項は、クライアント エクスペリエンスが大幅に低下し、顕著になるタイミングを特定するためのトラブルシューティング ガイダンスです。 詳細な説明については、付録 C を参照してください。
- LogicalDisk(<NTDS>)\Reads/sec は、実行されている I/O の量です。
- LogicalDisk(<NTDS>)\Avg Disk sec/Read がバックエンド ストレージの最適な範囲内にある場合、LogicalDisk(<NTDS>)\Reads/sec を直接使用してストレージのサイズを設定できます。
- LogicalDisk(<NTDS>)\Avg Disk sec/Read がバックエンド ストレージの最適な範囲内にない場合は、次の式に従って追加の I/O が必要になります。(LogicalDisk(<NTDS>)\Avg Disk sec/Read) ÷ (Physical Media Disk Access Time) × (LogicalDisk(<NTDS>)\Avg Disk sec/Read)
考慮事項:
- サーバーが最適ではない容量の RAM で構成されている場合、これらの値は計画の目的では不正確になることに注意してください。 これらは誤って高めになるため、最悪のシナリオとして使用される場合があります。
- 特に RAM を追加または最適化すると、読み取り I/O (LogicalDisk(<NTDS>)\Reads/Sec の量が減少します。これは、ストレージ ソリューションが最初に計算されたほど堅牢である必要がない可能性があることを意味します。 残念ながら、この概論よりも具体的なことは、環境的にクライアントの負荷に左右されるため、一般的なガイダンスを提供することはできません。 最適なオプションは、RAM を最適化した後でストレージのサイズを調整することです。
パフォーマンスに関する仮想化に関する考慮事項
前述のすべての仮想化の説明と同様に、ここで重要なのは、基盤となる共有インフラストラクチャで、DC の負荷に加えて、基盤となる共有メディアとそれへのすべての経路を使用しているその他のリソースをサポートできるようにすることです。 これは、物理ドメイン コントローラーが SAN、NAS、または iSCSI インフラストラクチャ上で他のサーバーまたはアプリケーションと同じ基盤となるメディアを共有している場合でも、SAN、NAS、または iSCSI インフラストラクチャへのパス スルー アクセスを使用しているのがゲストである場合でも、またはゲストがローカルの共有メディアまたは SAN、NAS、または iSCSI インフラストラクチャに存在する VHD ファイルを使用している場合でも当てはまります。 計画の演習は、基になるメディアがすべてのコンシューマーの総負荷をサポートできることを確認することです。
また、ゲストの観点からは、トラバースする必要がある追加のコード パスがあるため、任意のストレージにアクセスするためにホストを経由する必要がある場合は、パフォーマンスに影響します。 当然のことながら、ストレージ パフォーマンス テストでは、仮想化がホスト システムのプロセッサ使用率に左右されるスループットに影響を与えることが示されます (「付録 A: CPU のサイズ設定の条件」を参照)。これは、ゲストが要求するホストのリソースによる影響を明らかに受けています。 これは、仮想化のシナリオでの処理のニーズに関する仮想化の考慮事項に関係します (「処理のための仮想化に関する考慮事項」を参照)。
これをさらに複雑にすると、パフォーマンスにさまざまな影響を与えるバラエティに富んだストレージ オプションを利用できるようにあなります。 物理から仮想に移行する場合の安全な見積もりとして、1.10 の乗数を使用して、パススルー ストレージ、SCSI アダプター、IDE などの Hyper-V 上の仮想化ゲストのためにさまざまなストレージ オプションを調整します。 異なるストレージ シナリオ間で転送するときに行う必要がある調整は、ストレージがローカル、SAN、NAS、iSCSI のいずれであっても関係ありません。
計算の概要の例
通常の動作状態で正常なシステムに必要な I/O の量を決定する場合:
- ピーク時の 15 分間の LogicalDisk(<NTDS Database Drive>)\Transfers/sec
- 基盤となるストレージの容量を超えるストレージに必要な I/O の量を決定する場合:
Needed IOPS = (LogicalDisk(<NTDS Database Drive>)\Avg Disk sec/Read ÷ <Target Avg Disk sec/Read>) × LogicalDisk(<NTDS Database Drive>)\Read/sec
| カウンタ | 値 |
|---|---|
| 実際の LogicalDisk(<NTDS Database Drive>)\Avg Disk sec/Transfer | .02 秒 (20 ミリ秒) |
| ターゲットの LogicalDisk(<NTDS Database Drive>)\Avg Disk sec/Transfer | .01 秒 |
| 使用可能な IO の変更の乗数 | 0.02 ÷ 0.01 = 2 |
| 値の名前 | 値 |
|---|---|
| LogicalDisk(<NTDS Database Drive>)\Transfers/sec | 400 |
| 使用可能な IO の変更の乗数 | 2 |
| ピーク時に必要な合計 IOPS | 800 |
キャッシュをウォームアップする速度を決定するには:
- キャッシュのウォームアップに許容可能な最大時間を決定します。 これは、ディスクからデータベース全体を読み込むために必要な時間か、またはデータベース全体を RAM に読み込むことができないシナリオでは、これは RAM をいっぱいにするための最大時間になります。
- 空白を除く、データベースのサイズを決定します。 詳細については、「ストレージの評価」を参照してください。
- データベース サイズを 8 KB で割ります。これは、データベースの読み込みに必要な合計 IO になります。
- 合計 IO を、定義された時間枠の秒数で割ります。
計算されたレートは正確ですが、ESE が固定キャッシュ サイズを持つように構成されていない場合は、以前に読み込まれたページが削除され、AD DS では可変キャッシュ サイズが既定で使用されるため、正確でなくなることに注意してください。
| 収集するデータ ポイント | 値 |
|---|---|
| ウォームアップの最大許容時間 | 10 分 (600 秒) |
| データベース サイズ | 2 GB |
| 計算ステップ | Formula | 結果 |
|---|---|---|
| ページ内のデータベースのサイズを計算する | (2 GB × 1024 × 1024) = データベースのサイズ (KB 単位) | 2,097,152 KB |
| データベース内のページ数を計算する | 2,097,152 KB ÷ 8 KB = ページ数 | 262,144 ページ |
| キャッシュを完全にウォームアップするために必要な IOPS を計算する | 262,144 ページ ÷ 600 秒 = 必要な IOPS | 437 IOPS |
処理中
Active Directory のプロセッサ使用率の評価
ほとんどの環境では、計画のセクションで説明したように、ストレージ、RAM、ネットワークを適切に調整したら、処理容量を管理することが、最も注意が必要なコンポーネントになります。 必要な CPU 容量の評価には、2 つの課題があります。
環境内のアプリケーションが、共有サービス インフラストラクチャで適切に動作しているかどうか (これについては、「より効率的な Microsoft Active Directory 対応アプリケーションの作成」の記事の「高コストで非効率的な検索の追跡」というタイトルのセクションで説明されています)、またはダウンレベルの SAM 呼び出しから LDAP 呼び出しに移行しているかどうか。
大規模な環境で、このことが重要な理由は、適切にコード化されていないアプリケーションによって CPU 負荷の変動が起こり、他のアプリケーションから過度の CPU 時間を "奪い"、容量のニーズを人為的に押し上げ、DC に対して負荷を不均一に分散させる可能性があるためです。
AD DS は、多種多様の潜在的なクライアントが存在する分散環境であるため、"単一のクライアント" のコストを見積もることは、AD DS を利用するアプリケーションの使用パターンと種類または量により、環境の影響を受けます。 つまり、ネットワークのセクションと同様に、幅広い適用性のために、環境で必要とされる合計容量を評価するという観点から、これに取り組むことをお勧めします。
既存の環境については、ストレージのサイズ設定について既に説明したように、ストレージのサイズが適切に設定されているため、プロセッサの負荷に関するデータが有効であると想定されています。 繰り返しになりますが、システムのボトルネックがストレージのパフォーマンスではないことを確認することが重要です。 ボトルネックが存在し、プロセッサが待機している場合、ボトルネックが解消されると、アイドル状態が解消されます。 プロセッサの待機状態が解消されると、データを待機する必要がなくなるため、定義上、CPU 使用率は増加します。 このため、パフォーマンス カウンター “Logical Disk(<NTDS Database Drive>)\Avg Disk sec/Read” と “Process(lsass)\% Processor Time” を収集します。 “Logical Disk(<NTDS Database Drive>)\Avg Disk sec/Read” が 10 - 15 ミリ秒を超える場合、“Process(lsass)\% Processor Time” のデータは人為的に低くなります。これは、Microsoft サポートがストレージ関連のパフォーマンスの問題のトラブルシューティングに使用する一般的なしきい値です。 前と同様に、サンプリング間隔は15 分、30 分、または 60 分のいずれかにすることをお勧めします。 それより少ないと、一般的に揮発性が高すぎて適切な測定ができません。それより大きいと、毎日のピークが過度に滑らかになります。
はじめに
ドメイン コントローラーのキャパシティ プランニングを計画するたには、処理能力に最も注意を払って理解する必要があります。 パフォーマンスを最大にするためにシステムのサイズを変更する場合、ボトルネックとなるコンポーネントが常に存在し、適切にサイズ設定されたのドメイン コントローラーではこれがプロセッサになります。
環境の需要がサイトごとに見直されるネットワーク セクションと同様に、要求されるコンピューティング容量についても同じことを行う必要があります。 利用可能なネットワーク テクノロジが通常の需要をはるかに超えるネットワーク セクションとは異なり、CPU 容量のサイズ設定にさらに注意を払ってください。 中規模の環境でも同様です。同時ユーザーが数千人を超えると、CPU に大きな負荷をかける可能性があります。
残念ながら、AD を利用するクライアント アプリケーションには大きなばらつきがあるため、CPU あたりのユーザーの一般的な見積もりを、すべての環境に適用することは到底できません。 具体的には、コンピューティング需要は、ユーザーの行動とアプリケーション プロファイルの影響を受けます。 そのため、環境ごとに個別にサイズを設定する必要があります。
ターゲット サイトの動作プロファイル
既に説明したように、サイト全体の容量を計画する場合、目標は、ピーク時に 1 つのシステムに障害が発生した場合に、妥当なレベルの品質でサービスを継続できるように、N + 1 で容量設計を行うことです。 つまり、"N" シナリオでは、すべてのボックスに対する負荷は、ピーク時に 100% 未満 (できれば 80% 未満) である必要があります。
さらに、サイト内のアプリケーションとクライアントがドメイン コントローラーを特定するためのベスト プラクティスを使用している (つまり、DsGetDcName 関数を使用している) 場合、クライアントは、さまざまな要因による一時的な小さいスパイクで比較的均等に分散される必要があります。
次の例では、以下の仮定が行われています。
- サイト内の 5 つの DC には、それぞれ 4 つの CPU が搭載されています。
- 営業時間内の合計ターゲット CPU 使用率は、通常の動作条件 ("n + 1") では 40%、それ以外の場合 ("N") は 60% です。 営業時間外のターゲット CPU 使用率は 80% です。これは、バックアップ ソフトウェアやその他のメンテナンスで使用可能なすべてのリソースが消費されると予想されるためです。
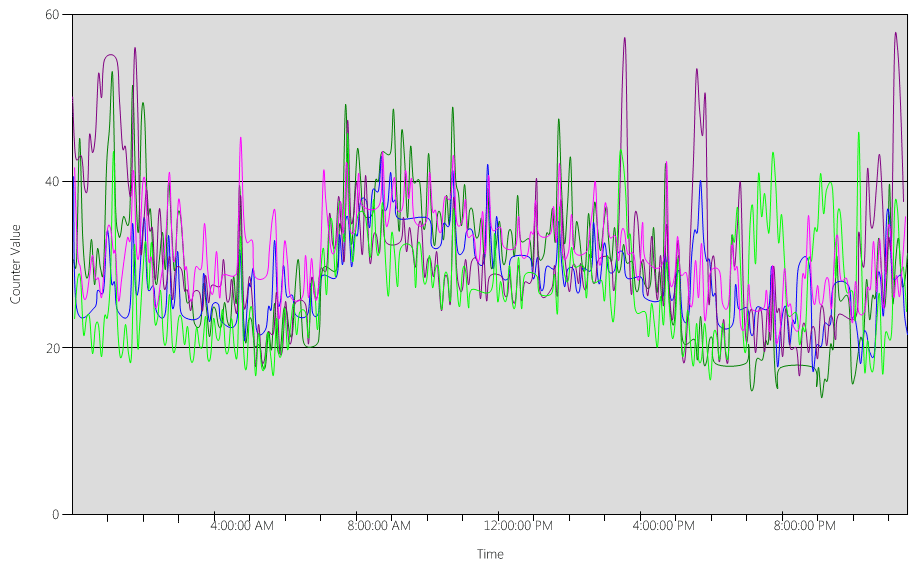
各 DC のグラフ (Processor Information(_Total)\% Processor Utility) 内のデータを分析します。
大部分で負荷は比較的均等に分散されています。これは、クライアントが DC ロケーターを使用し、検索が適切に記述されている場合に予想されることです。
10% の 5 分間のスパイクがいくつかあり、20% にもなるものもあります。 一般に、容量計画の目標を超えない限り、これらを調査する価値はありません。
すべてのシステムのピーク期間は、およそ午前 8 時から午前 9 時 15 分の間です。 午前 5 時頃から午後 5 時頃までスムーズに移行しています。これは一般的にビジネス サイクルを示しています。 午後 5 時から午前 4 時までのボックスごとのシナリオでの CPU 使用率のよりランダムなスパイクは、キャパシティ プランニングの懸念の範囲外になります。
注意
適切に管理されたシステムでは、上記のスパイクは、実行中のバックアップ ソフトウェア、システム全体のウイルス対策スキャン、ハードウェアまたはソフトウェアのインベントリ、ソフトウェアまたはパッチの展開などである可能性があります。 これらはユーザーのビジネス サイクルのピークの範囲外であるため、ターゲットを超えることはありません。
各システムは約 40% で、すべてのシステムに同じ数の CPU があるため、1 つのシステムに障害が発生したりオフラインになったりした場合、残りのシステムは推定 53% で実行されます (システム D の 40% の負荷は均等に分割され、システム A とシステム C の既存の 40% の負荷に追加されます)。 いくつかの理由から、この線形の想定は完全に正確ではありませんが、測定するのに十分な精度を提供します。
代替シナリオ – 2 つのドメイン コントローラーが 40% で実行されていて、1 つのドメイン コントローラーに障害が発生した場合、残りの 1 つの CPU は推定 80% になります。 これは、容量計画について上記で概説したしきい値をはるかに超えており、上記の負荷プロファイルで見られる 10% から 20% のヘッドルームの量も厳しく制限され始めます。これは、"N" のシナリオでは、スパイクによって DC が 90% から 100% になり、応答性が確実に低下することを意味します。
CPU 要求の計算
“Process\% Processor Time” パフォーマンス オブジェクト カウンターは、アプリケーションのすべてのスレッドが CPU に費やした総時間を合計し、経過したシステム時間の合計で除算します。 これにより、マルチ CPU システム上のマルチスレッド アプリケーションが 100% の CPU 時間を超える可能性があり、“Processor Information\% Processor Utility” とはまったく異なる解釈がされます。 実際には、“Process(lsass)\% Processor Time” は、プロセスの要求をサポートするために必要な 100% で実行されている CPU の数と見なすことができます。 200% の値は、AD DS の全負荷をサポートするために、それぞれ 100% の 2 つの CPU が必要であることを意味します。 100% の容量で実行される CPU は、CPU に費やされるコストと電力およびエネルギー消費の観点から最もコスト効率に優れていますが、付録 A で詳しく説明されているいくつかの理由により、システムが 100% で実行されていない場合に、マルチスレッド システムでの応答性が向上します。
クライアント負荷の一時的なスパイクに対応するには、ピーク時の CPU をシステム容量の 40% から 60% をターゲットにすることをお勧めします。 上記の例を使用すると、AD DS (lsass プロセス) の負荷に対して 3.33 (60% ターゲット) から 5 (40% ターゲット) 個の CPU が必要になることを意味します。 基本オペレーティング システムと必要なその他のエージェント (ウイルス対策、バックアップ、監視など) の要求に応じて、容量を追加する必要があります。 エージェントの影響は環境ごとに評価する必要がありますが、1 つの CPU の 5% から 10% で見積もることができます。 現在の例では、これは、ピーク時に 3.43 (60% ターゲット) から 5.1 (40% ターゲット) 個の CPU が必要であることを示しています。
これを行う最も簡単な方法は、Windows 信頼性およびパフォーマンス モニター (Perfmon) の "積み上げ面" ビューを使用して、すべてのカウンターが同じようにスケーリングされるようにすることです。
想定:
- 目標は、サーバーの設置面積をできる限り削減することです。 理想的には、1 台のサーバーで負荷を処理し、冗長性を確保するためにもう 1 台サーバーを追加します (N + 1 シナリオ)。
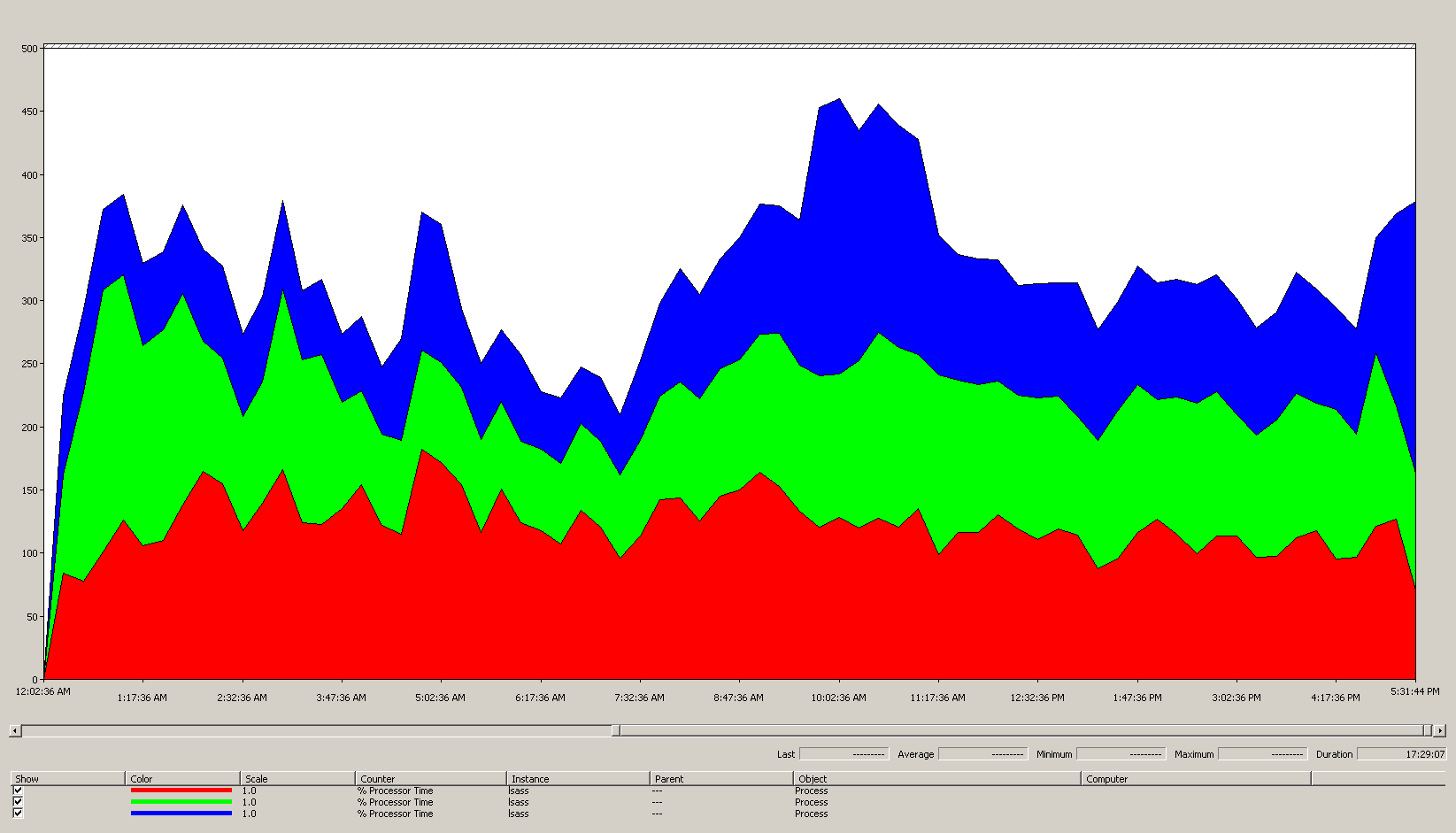
グラフのデータ (Process(lsass)\% Processor Time) から得られた知識:
- 営業日は午前 7 時頃に増加し始め、午後 5 時に減少します。
- 最もビジーなピーク期間は、午前 9 時 30 分から 午前 11 時です。
注意
すべてのパフォーマンス データは履歴です。 午前 9 時 15 分のピーク データ ポイントは、午前 9 時 から午前 9 時 15 分までの負荷を示しています。
- 午前 7 時より前にスパイクがあります。これは、異なるタイム ゾーンからの負荷、またはバックアップなどのバックグラウンド インフラストラクチャ アクティビティのいずれかを示している可能性があります。 午前 9 時 30 分のピークではこのアクティビティを超えているため、これは関係ありません。
- サイトには 3 つのドメイン コントローラーがあります。
最大負荷では、lsass によって、1 つの CPU の約 485%、または100% で実行されている 4.85 個の CPU が消費されます。 前述の計算によると、これは、サイトでは AD DS 用に約 12.25 個の CPU が必要であることを意味します。 バックグラウンド プロセス用に上記の提案の 5% から10% を追加します。これは、現在のサーバーを置き換えるには、同じ負荷をサポートするために約 12.30 から 12.35 個の CPU が必要になることを意味します。 この時点で、拡張のための環境の見積もりを考慮する必要があります。
LDAP の重みをチューニングするタイミング
LdapSrvWeight のチューニングを検討する必要があるシナリオがいくつかあります。 キャパシティ プランニングにおいては、アプリケーションまたはユーザーの負荷が均等に分散されていない場合や、基盤となるシステムが機能面で均等に分散されていない場合に、これを行います。 キャパシティ プランニング以外でそれを行う理由は、この記事の範囲外です。
LDAP の重みをチューニングする一般的な理由は 2 つあります。
- PDC エミュレーターは、ユーザーまたはアプリケーションの読み込み動作が均等に分散されていないすべての環境に影響を与える例です。 特定のツールとアクションは、グループ ポリシー管理ツールなどの PDC エミュレーターをターゲットとしているため、認証エラーや信頼の確立などの場合の 2 回目の試行では、PDC エミュレーターの CPU リソースが、サイトの他の場所よりも高い頻度で要求されることがあります。
- PDC エミュレーターの負荷を軽減し、他のドメイン コントローラーの負荷を増やして、負荷をより均等に分散できるようにするために、CPU 使用率に顕著な違いがある場合にのみ、これをチューニングすると便利です。
- この場合、PDC エミュレーターの LDAPSrvWeight を 50 から 75 に設定します。
- サイト内の CPU 数 (および速度) が異なるサーバー。 たとえば、2 台の 8 コア サーバーと 1 台の 4 コア サーバーがあるとします。 最後のサーバーには、他の 2 台のサーバーの半分のプロセッサが搭載されています。 これは、クライアントの負荷が適切に分散されると、4 コア ボックスの平均 CPU 負荷が 8 コア ボックスの約 2 倍に増加することを意味します。
- たとえば、2 つの 8 コア ボックスは 40% で実行されると、4 コア ボックスは 80% で実行されます。
- また、このシナリオで 1 つの 8 コア ボックスが失われた場合の影響、具体的には 4 コア ボックスが過負荷になるという事実を考慮します。
例 1 - PDC
| システム | 既定値での使用率 | 新しい LdapSrvWeight | 推定される新規使用率 |
|---|---|---|---|
| DC 1 (PDC エミュレーター) | 53% | 57 | 40% |
| DC 2 | 33% | 100 | 40% |
| DC 3 | 33% | 100 | 40% |
ここでの問題点は、PDC エミュレーターのロールが、特にサイト内の別のドメイン コントローラーに移動または奪われた場合、新しい PDC エミュレーターが劇的に増加することです。
「ターゲット サイトの動作プロファイル」セクションの例を使用して、サイト内の 3 つのドメイン コントローラーすべてに 4 個の CPU があると想定しました。 ドメイン コントローラーの 1 つに 8 個の CPU が搭載されている場合、通常の状況ではどうなるでしょうか。 使用率が 40% のドメイン コントローラーが 2 つ、使用率が 20% のドメイン コントローラーが 1 つあることになります。 これは悪くはありませんが、負荷をもう少しよく分散することができます。 これを実現するには、LDAP の重みを活用します。 シナリオ例を次に示します。
例 2 - 異なる CPU 数
| システム | Processor Information\ % Processor Utility(_Total) 既定値での使用率 |
新しい LdapSrvWeight | 推定される新規使用率 |
|---|---|---|---|
| 4-CPU DC 1 | 40 | 100 | 30% |
| 4-CPU DC 2 | 40 | 100 | 30% |
| 8-CPU DC 3 | 20 | 200 | 30% |
ただし、これらのシナリオには十分に注意してください。 上記に見られるように、紙の上での計算はとても素晴らしくてきれいに見えます。 しかし、この記事全体を通して最も重要なことは、"N + 1" シナリオの計画です。 1 つの DC がオフラインになることによる影響は、シナリオごとに計算する必要があります。 負荷の分散が均等である直前のシナリオでは、"N" シナリオで 60% の負荷を確保するために、すべてのサーバーで負荷を均等に分散して、比率が一定に保たれるため、分散は正常に行われます。 PDC エミュレーターのチューニング シナリオと、一般にユーザーまたはアプリケーションの負荷が不均衡なシナリオを見ると、効果は大きく異なります。
| システム | 調整された使用率 | 新しい LdapSrvWeight | 推定される新規使用率 |
|---|---|---|---|
| DC 1 (PDC エミュレーター) | 40% | 85 | 47% |
| DC 2 | 40% | 100 | 53% |
| DC 3 | 40% | 100 | 53% |
処理のための仮想化に関する考慮事項
仮想化環境で行う必要があるキャパシティ プランニングには 2 つの層があります。 ホスト レベルでは、前にドメイン コントローラーの処理に関して概説したビジネス サイクルの特定と同様に、ピーク期間中のしきい値を特定する必要があります。 基盤となるプリンシパルは、CPU 上のゲスト スレッドをスケジュールするホスト マシンでも、物理マシンの CPU で AD DS スレッドを取得する場合と同じであるため、基盤となるホストで 40% から 60% の同じ目標を設定することをお勧めします。 次の層であるゲスト層では、スレッド スケジューリングのプリンシパルが変更されていないため、ゲスト内の目標は 40% から 60% の範囲のままです。
ホストあたり 1 つのゲストが直接マップされたシナリオでは、これまでに行われたすべてのキャパシティ プランニングを、基盤となるホスト オペレーティング システムの要件 (RAM、ディスク、ネットワーク) に追加する必要があります。 共有ホストのシナリオでは、基盤となるプロセッサの効率に 10% の影響があることがテストによって示されています。 つまり、サイトで 40% のターゲットで 10 個の CPU が必要な場合、すべての "N" ゲストに割り当てる仮想 CPU の推奨数は 11 となります。 物理サーバーと仮想サーバーが混在しているサイトでは、修飾子は VM にのみ適用されます。 たとえば、サイトに "N + 1" シナリオがある場合、10 個の CPU が搭載された 1 台の物理または直接マップされたサーバーは、ホスト上に 11 個の CPU が搭載され、ドメイン コントローラー用に 11 個の CPU が予約されている 1 つのゲストとほぼ同等です。
AD DS 負荷をサポートするために必要な CPU の数の分析と計算を通じて、物理ハードウェアの観点から購入できるものにマップされる CPU の数は、必ずしもきれいにマップされるとは限りません。 仮想化により、切り上げが不要になります。 仮想化により、CPU を VM に簡単に追加できるので、コンピューティング容量をサイトに追加するために必要な労力が軽減されます。 追加の CPU をゲストに追加する必要がある場合に、基盤となるハードウェアを使用できるように、必要なコンピューティング能力を正確に評価する必要がなくなるわけではありません。 常に、需要の増加を計画し、監視してください。
計算の概要の例
| システム | ピーク CPU |
|---|---|
| DC 1 | 120% |
| DC 2 | 147% |
| DC 3 | 218% |
| 使用されている CPU の合計 | 485% |
| ターゲット システム数 | 合計帯域幅 (上記から) |
|---|---|
| 40% のターゲットで必要な CPU | 4.85 ÷ .4 = 12.25 |
この点は重要なため繰り返しますが、"増加を計画することを忘れないでください"。 今後 3 年間で 50% の増加を想定すると、この環境では 3 年間で18.375 個の CPU (12.25 × 1.5) が必要になります。 代案として、1 年目の後にレビューして、必要に応じて容量を追加する方法があります。
NTLM の相互信頼クライアント認証の負荷
NTLM の相互信頼クライアント認証の負荷を評価する
多くの環境では、1 つ以上のドメインが信頼によって接続されている場合があります。 Kerberos 認証を使用しない別のドメインの ID に対する認証要求は、ドメイン コントローラーのセキュリティで保護されたチャネルを使用して、宛先ドメインまたは宛先ドメインへのパスの次のドメインにある別のドメイン コントローラーへの信頼をトラバースする必要があります。 ドメイン コントローラーが信頼されたドメイン内のドメイン コントローラーに対して実行できるセキュリティで保護されたチャネルを使用した同時呼び出しの数は、MaxConcurrentAPI と呼ばれる設定によって制御されます。 ドメイン コントローラーの場合、セキュリティで保護されたチャネルが負荷量を確実に処理できるように、MaxConcurrentAPI をチューニングするか、フォレスト内でショートカットの信頼を作成するという 2 つの方法のいずれかを使用します。 個別の信頼間のトラフィック量を測定するには、「MaxConcurrentApi の設定を使用して NTLM 認証のパフォーマンスを調整する方法」を参照してください。
データは、他のすべてのシナリオと同様に、データを有用なものにするために、1 日のピーク時に収集する必要があります。
注意
フォレスト内およびフォレスト間のシナリオでは、認証が複数の信頼をトラバースする可能性があり、各ステージをチューニングする必要があります。
計画
NTLM 認証を既定で使用する、または特定の構成シナリオで使用するアプリケーションはいくつかあります。 アプリケーション サーバーの容量が増加し、サービスを提供するアクティブなクライアントの数も増えます。 また、クライアントが限られた時間だけセッションを開いたままにし、定期的に再接続する傾向もあります (メール プル同期など)。 NTLM 負荷が高いもう 1 つの一般的な例は、インターネット アクセスの認証を必要とする Web プロキシ サーバーです。
これらのアプリケーションは、NTLM 認証に大きな負荷をかける可能性があります。特にユーザーとリソースが異なるドメインにある場合に、DC に大きな負荷を与える可能性があります。
相互信頼の負荷を管理するには複数の方法があり、実際には、 1 つだけまたはいずれかのシナリオではなく、組み合わせて使用されます。 オプションは次のとおりです。
- ユーザーが常駐しているのと同じドメイン内でユーザーが使用するサービスを見つけることで、相互信頼クライアント認証を減らします。
- 使用可能なセキュリティで保護されたチャネルの数を増やします。 これはフォレスト内およびフォレスト間のトラフィックに関連し、ショートカット信頼と呼ばれます。
- MaxConcurrentAPI の既定の設定をチューニングします。
既存のサーバーで MaxConcurrentAPI をチューニングする場合、式は次のようになります。
New_MaxConcurrentApi_setting ≥ (semaphore_acquires + semaphore_time-outs) × average_semaphore_hold_time ÷ time_collection_length
詳細については、「サポート技術情報の記事 2688798: MaxConcurrentApi の設定を使用して NTLM 認証のパフォーマンスを調整する方法」を参照してください。
仮想化に関する考慮事項
ありません。これはオペレーティング システムのチューニング設定です。
計算の概要の例
| データ型 | 値 |
|---|---|
| セマフォ取得 (最小) | 6,161 |
| セマフォ取得 (最大) | 6,762 |
| セマフォ タイムアウト | 0 |
| セマフォの平均保持時間 | 0.012 |
| 収集期間 (秒) | 1:11 分 (71 秒) |
| 式 (KB 2688798 から) | ((6762 – 6161) + 0) × 0.012 / |
| MaxConcurrentAPI の最小値 | ((6762 – 6161) + 0) × 0.012 ÷ 71 = .101 |
この期間、このシステムでは既定値が許容されます。
キャパシティ プランニング目標の準拠を監視する
この記事全体を通して、使用率のターゲットに向けた計画とスケーリングについて説明してきました。 システムが適切な容量のしきい値内で動作していることを確認するために監視する必要がある推奨しきい値の概要グラフを次に示します。 これらはパフォーマンスのしきい値ではなく、キャパシティ プランニングのしきい値であることに注意してください。 これらのしきい値を超えて動作しているサーバーは、機能しますが、すべてのアプリケーションが正常に動作していることの検証を開始する時です。 上記のアプリケーションが正常に動作している場合は、ハードウェアのアップグレードまたはその他の構成変更の評価を開始します。
| カテゴリ | パフォーマンス カウンター | 間隔/サンプリング | 移行先 | 警告 |
|---|---|---|---|---|
| プロセッサ | Processor Information(_Total)\% Processor Utility | 60 分 | 40% | 60% |
| RAM (Windows Server 2008 R2 以前) | Memory\Available MB | < 100 MB | 該当なし | < 100 MB |
| RAM (Windows Server 2012) | Memory\Long-Term Average Standby Cache Lifetime(s) | 30 分 | テストが必要 | テストが必要 |
| ネットワーク | Network Interface(*)\Bytes Sent/sec Network Interface(*)\Bytes Received/sec |
30 分 | 40% | 60% |
| Storage | LogicalDisk(<NTDS Database Drive>)\Avg Disk sec/Read LogicalDisk(<NTDS Database Drive>)\Avg Disk sec/Write |
60 分 | 10 ms | 15 ms |
| AD サービス | Netlogon(*)\Average Semaphore Hold Time | 60 分 | 0 | 1 秒 |
付録 A: CPU のサイズ設定の条件
定義
プロセッサ (マイクロプロセッサ) – プログラムの命令を読み取って実行するコンポーネント
CPU – 中央処理装置
マルチコア プロセッサ – 同じ統合回線上の複数の CPU
マルチ CPU - 同じ統合回線上にない複数の CPU
論理プロセッサ – オペレーティング システムの観点から見た 1 つの論理コンピューティング エンジン
これには、ハイパースレッド、マルチコア プロセッサ上の 1 つのコア、または 1 つのコア プロセッサが含まれます。
現在のサーバー システムには複数のプロセッサ、複数のマルチコア プロセッサ、ハイパースレッドが搭載されているため、この情報は両方のシナリオに対応するために一般化されています。 そのため、論理プロセッサという用語は、使用可能なコンピューティング エンジンのオペレーティング システムとアプリケーションの観点を表すために使用されます。
スレッドレベルの並列処理
各スレッドには独自のスタックと命令があるため、各スレッドは独立したタスクです。 AD DS はマルチスレッドであり、使用可能なスレッドの数は、Ntdsutil.exe を使用して Active Directory で LDAP ポリシーを表示および設定する方法を使用してチューニングできるため、複数の論理プロセッサ間で適切にスケーリングされます。
データレベルの並列処理
これには、1 つのプロセス内の複数のスレッド間 (AD DS プロセスのみの場合)、および複数のプロセス内の複数のスレッド間 (一般に) でのデータの共有が含まれます。 ケースを過度に単純化する懸念から、これは、データへのすべての変更が、共有メモリの更新だけでなく、上記のスレッドを実行しているすべてのコアのさまざまなレベルのキャッシュ (L1、L2、L3) のすべての実行中のスレッドに反映されることを意味します。 命令処理を続行する前に、さまざまなメモリ位置がすべて一貫している間は、書き込み操作中のパフォーマンスが低下する可能性があります。
CPU 速度とマルチコアに関する考慮事項
一般的な目安として、論理プロセッサが高速になるほど、一連の命令の処理にかかる時間が短縮されますが、論理プロセッサが多くなるほど、同時に実行できるタスクが増えます。 これらの目安は、共有メモリからのデータのフェッチ、データレベルの並列処理の待機、複数のスレッド管理のオーバーヘッドを考慮して、シナリオが本質的に複雑になるにつれて、行き詰ります。 これが、マルチコア システムのスケーラビリティが線形ではない理由でもあります。
これらの考慮事項では、次の例えを考慮してください。幹線道路を考えてみてください。各スレッドが個別の車で、各車線が 1 つのコアで、制限速度がクロック速度です。
- 幹線道路に車が 1 台しかいない場合、2 車線でも 12 車線でも関係ありません。 その車は制限速度が許す限りの速度で進みます。
- スレッドが必要とするデータがすぐには使用できないとします。 この例えは、道路の一部が閉鎖されているということになるでしょう。 幹線道路に車が 1 台しかいない場合、車線が再び開かれる (データがメモリからフェッチされる) まで、制限速度は関係ありません。
- 車の数が増えるにつれて、車の数を管理するためのオーバーヘッドが増加します。 道路が実質的に空の時 (深夜など) と交通量が多い時 (たとえば、ラッシュ アワーではない午後 1 時など) の、運転のエクスペリエンスと必要な注意の量を比較します。 また、2 車線の幹線道路 (この場合、ドライバーが何をしているかを気にする車線は他に 1 つしかありません) と、6 車線の幹線道路 (この場合、他の多くのドライバーが何をしているのかを気にする必要があります) を運転する場合に必要な注意の量も考慮します。
注意
ラッシュ アワーのシナリオに関する例えは、次のセクション「応答時間/システムのビジー状態がパフォーマンスに与える影響」でも取り上げます。
その結果、より多くのプロセッサまたはより高速なプロセッサについての詳細は、アプリケーションの動作に非常に影響されるようになります。AD DS の場合、これは環境固有のものであり、環境内のサーバーごとに異なることもあります。 これが、この記事の前出の参照で過度に正確であることにあまりこだわらずに、安全域が計算に含まれている理由です。 予算に基づいて購入を決定するときは、より高速なプロセッサの購入を検討する前に、まずプロセッサの使用率を 40% (または環境に適した数) で最適化することをお勧めします。 同期するプロセッサの数が増えると、プロセッサを増やすことによる線形進行の真のメリットが低下します (プロセッサの数が 2 倍になると、利用可能な追加のコンピューティング能力は 2 倍よりも少なくなります)。
注意
この概念には、アムダールの法則とグスタフソンの法則が関連しています。
応答時間/システムのビジー状態がパフォーマンスに与える影響
待ち行列理論は、待ち行列 (キュー) の数理的研究です。 待ち行列理論では、Utilization Law は次の式で表されます。
U k = B ÷ T
ここで、U kは使用率、B はビジー時間、T はシステムが監視された合計時間です。 Windows のコンテキストに変換すると、これは、実行状態にある 100 ナノ秒 (ns) 間隔のスレッドの数を、指定された時間間隔で使用可能な 100 ns 間隔の数で割ること意味します。 これは、% Processor Utility (「プロセッサ オブジェクト」と「PERF_100NSEC_TIMER_INV」を参照) を計算するための式です。
待ち行列理論では、使用率に基づいて待機アイテムの数を見積もるために、N = U k ÷ (1 – U の式も提供されています (N はキューの長さです)。 すべての使用率間隔でこれをグラフ化すると、特定の CPU 負荷でキューがプロセッサに到達するまでの時間について次の見積もりが得られます。
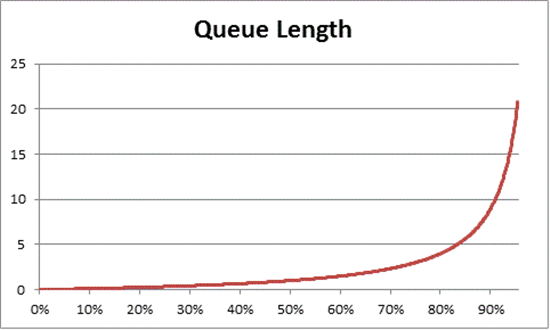
CPU 負荷が 50% になると、平均してキュー内の他の 1 つのアイテムが常に待機し、CPU 使用率が約 70% になると、著しく急速に増加することが確認されます。
このセクションで前に使用した運転の例えに戻ります。
- "午後 3 時頃" のビジー時間は、仮定上、40% から 70% の範囲のどこかに分類されます。 車線を選択する能力が大幅に制限されない程度に十分な交通量があり、他のドライバーが邪魔になる可能性は高いですが、道路上で他の車との安全な間隔を "見つける" ための努力は必要ありません。
- 交通量がラッシュ アワーに近づくと、道路システムの容量が 100% に近づくことに気付くでしょう。 車が非常に接近していて注意を払う必要があるため、車線の変更が非常に困難になる可能性があります。
これが、負荷の異常なスパイクに対するヘッド ルームを可能にするために、容量の長期的な平均を保守的に 40% と見積もる理由です。上記のスパイクは、一時的なもの (数分間実行される適切にコード化されていないなクエリなど) である場合も、一般的な負荷での異常なバースト (長い週末休暇明けの朝) である場合もあります。
上の説明では、% Processor Time の計算が Utilization Law と同じであると見なしていて、一般的な読者にわかりやすくするために少し単純化されています。 数学的に厳密な場合:
- PERF_100NSEC_TIMER_INV を変換する
- B = 論理プロセッサに費やされる "Idle" スレッドの 100 ns 間隔の数。 PERF_100NSEC_TIMER_INV 計算の "X" 変数の変更
- T = 指定された時間範囲内の 100 ns 間隔の総数。 PERF_100NSEC_TIMER_INV 計算の "Y" 変数の変更。
- U k = “Idle Thread” または % Idle Time による論理プロセッサの使用率。
- 数学の計算:
- U k = 1 – %Processor Time
- %Processor Time = 1 – U k
- %Processor Time = 1 – B / T
- %Processor Time = 1 – X1 – X0 / Y1 – Y0
キャパシティ プランニングに概念を適用する
前の数値演算では、システムに必要な論理プロセッサの数が非常に複雑に見える場合があります。 これが、システムのサイズを設定するアプローチが、現在の負荷に基づいて最大目標使用率を決定し、そこに到達するために必要な論理プロセッサの数を計算することに重点を置く理由です。 さらに、論理プロセッサの速度は、パフォーマンスに大きな影響を及ぼしますが、キャッシュの効率性、メモリの一貫性の要件、スレッドのスケジューリングと同期、均等に分散されていないクライアント負荷はすべて、サーバーごとに異なるパフォーマンスに大きな影響を及ぼします。 コンピューティング能力のコストが比較的低いため、必要な CPU の正確な数を分析して決定しようとすると、ビジネス価値を提供するよりも学術的な演習になります。
40% は厳格な要件ではなく、合理的なスタートです。 Active Directory のコンシューマーごとに必要な応答性のレベルは異なります。 プロセッサへのアクセスの待機時間の増加がクライアントのパフォーマンスに目立った影響を与えないため、環境が持続的な平均として 80% または 90% の使用率で実行できるシナリオが考えられます。 重要なので繰り返しますが、システムには、RAM へのアクセス、ディスクへのアクセス、ネットワーク経由での応答の送信など、システムの論理プロセッサよりもはるかに低速な領域が多数あります。 これらすべての項目を組み合わせてチューニングする必要があります。 例 :
- ディスクがバインドされた 90% で実行されているシステムにプロセッサを追加しても、パフォーマンスが大幅に向上することはおそらくありません。 システムをさらに詳しく分析すると、I/O の完了を待機しているために、プロセッサに接続されていないスレッドが多数あることがわかるでしょう。
- ディスク バインドの問題を解決すると、以前は待機状態で多くの時間を費やしていたスレッドが I/O の待機状態にならなくなり、CPU 時間の競合が増える可能性があります。つまり、前の例の 90% の使用率が 100% に上がります (これ以上高くならないため)。 両方のコンポーネントを組み合わせてチューニングする必要があります。
注意
Processor Information(*)\% Processor Utility は、"Turbo" モードがあるシステムでは 100% を超える可能性があります。 この場合に、CPU が短時間、定格プロセッサ速度を超えます。 より詳細な分析情報については、CPU 製造元のドキュメントとカウンターの説明を参照してください。
システム全体の使用率に関する考慮事項について説明する場合、ドメイン コントローラーも仮想化されたゲストとして登場します。 応答時間/システムのビジー状態がパフォーマンスに与える影響は、仮想化のシナリオでは、ホストとゲストの両方に適用されます。 これが、ゲストが 1 人だけのホストでは、ドメイン コントローラー (および通常は任意のシステム) のパフォーマンスが、物理ハードウェアで行うのとほぼ同じになる理由です。 ホストにゲストを追加すると、基盤となるホストの使用率が増加するため、前に説明したように、プロセッサにアクセスするまでの待機時間が長くなります。 つまり、論理プロセッサの使用率は、ホストとゲストの両方のレベルで管理する必要があります。
前の例えを拡大して、幹線道路は物理ハードウェアのままで、ゲスト VM はバス (乗客が望む目的地に直行する急行バス) に例えます。 次の 4 つのシナリオを想像してください。
- ラッシュ アワーをはずれた時間帯で、1 人の乗客がほぼ空のバスに乗り、バスはほぼ空の道路を走ります。 混雑するほどの交通量がないため、乗客は自分で運転するのと同じくらい早く目的地に到着できます。 乗客の移動時間は、制限速度によって制限されます。
- ラッシュ アワーをはずれた時間帯なので、バスは空に近いですが、ほとんどの車線が閉鎖されているため、幹線道路はまだ混雑しています。 乗客は混雑した道路でほとんど空のバスに乗っています。 乗客はバスの中でどこに座るかについての競争はほとんどありませんが、合計の所要期間は依然としてそれ以外の交通量によって決まります。
- ラッシュ アワーなので、幹線道路とバスは混雑しています。 所要時間がかかるだけでなく、バスの中は混雑していて幹線道路も同じく混雑しているため、バスの乗り降りは最悪です。 バスを増発 (論理プロセッサをゲストに追加) しても、スムーズに走行できるわけでも、所要時間が短縮されるわけでもありません。
- 最後のシナリオでは、例えを少し拡大解釈しているかもしれませんが、バスは満員ですが、道路は混雑していません。 乗客はまだバスの乗り降りに問題がありますが、バスが走り出した後の走行は効率的になります。 これは、バスを増発 (論理プロセッサをゲストに追加) することで、ゲストのパフォーマンスが向上する唯一のシナリオです。
そこから、道路の使用率が 0% から100% の間の状態と、バスの乗車率が 0% から 100% の間の状態で、影響の程度が異なるさまざまなシナリオがあることを推定するのは比較的簡単です。
上記の待ち行列の量と同じ理由で、ホストとゲストの妥当なターゲットとして CPU の 40% を超えるプリンシパルを適用することから始めるのが妥当です。
付録 B: さまざまなプロセッサ速度に関する考慮事項と、プロセッサの電源管理がプロセッサ速度に及ぼす影響
プロセッサの選択に関するセクション全体を通して、プロセッサは、データが収集されている間ずっとクロック速度の 100% で実行されており、交換用システムには同じ速度のプロセッサが搭載されていると想定されています。 実際にはどちらの想定も誤りですが、特に、既定の電源プランが Balanced である Windows Server 2008 R2 以降では、この方法論は、保守的なアプローチであるため、今でも有効です。 潜在的なエラー率は増加する可能性がありますが、プロセッサの速度が上がるにつれて安全域はますます増えます。
- たとえば、11.25 CPU が要求されるシナリオでは、データの収集時にプロセッサが半分の速度で実行されていた場合、より正確な見積もりは 5.125 ÷ 2 になる可能性があります。
- クロック速度を 2 倍にしても、特定の期間に発生する処理量が 2 倍になることを保証することはできません。 これは、プロセッサが RAM や他のシステム コンポーネントの待機に費やす時間が同じままである可能性があるためです。 正味の影響は、高速なプロセッサほど、データのフェッチを待機している間のアイドル時間の割合が高くなる可能性があることです。 繰り返しになりますが、分母の最小公倍数を堅持し、保守的になり、プロセッサ速度間の線形比較を想定して、潜在的に誤ったレベルの精度を計算しようとしないでください。
または、交換用ハードウェアのプロセッサ速度が現在のハードウェアよりも遅い場合は、必要なプロセッサの見積もりを比例して増やすのが安全です。 たとえば、サイトの負荷を維持するために 10 個のプロセッサが必要で、現在のプロセッサが 3.3 Ghz で実行されていて、交換用プロセッサが 2.6 Ghzで実行されると、速度が 21% 低下すると計算されます。 この場合、推奨される量は 12 個のプロセッサです。
とはいえ、この変動性によって容量管理プロセッサの使用率のターゲットが変わることはありません。 プロセッサのクロック速度は、必要な負荷に基づいて動的に調整されます。高負荷でシステムを実行すると、CPU がより速いクロック速度の状態でより多くの時間を費やすシナリオが生成され、ピーク時にクロック速度の 100% の状態で 40% の使用率になることが最終的な目標となります。 それより低い場合は、オフピーク シナリオ中に CPU 速度が抑制されるため、電力を節約できます。
注意
必要に応じて、データの収集中にプロセッサの電源管理をオフにする (電源プランを High Performance に設定する) こともできます。 これにより、ターゲット サーバーの CPU 消費量をより正確に表現できます。
さまざまなプロセッサの見積もりを調整するために、上記で概説した他のシステム ボトルネックを除いて、以前はプロセッサ速度を 2 倍にすると、実行できる処理量が 2 倍になると想定しても問題ありませんでした。 現在、プロセッサの内部アーキテクチャはプロセッサ間で大きく異なるため、データの取得元とは異なるプロセッサを使用した場合の影響を測定するより安全な方法は、Standard Performance Evaluation Corporation の SPECint_rate2006 ベンチマークを利用することです。
使用中および使用予定のプロセッサについて、SPECint_rate2006 スコアを確認します。
- Standard Performance Evaluation Corporation の Web サイトで、[Results] (結果) を選択し、[CPU2006] を強調表示して、[Search all SPECint_rate2006 results] (すべての SPECint_rate2006 の結果を検索) を選択します。
- [Simple Request] (簡易リクエスト) で、ターゲット プロセッサの検索条件を入力します。例: Processor Matches E5-2630 (baselinetarget) や Processor Matches E5-2650 (baseline) など。
- 使用するサーバーとプロセッサの構成 (または完全に一致するものがない場合はそれに近いもの) を見つけ、[Result] 列と [# Cores] 列の値をメモします。
修飾子を決定するには、次の式を使用します。
(("ターゲット プラットフォームのコアあたりのスコア値") × ("ベースライン プラットフォームのコアあたりの MHz")) ÷ (("ベースラインのコア ごとのスコア値") × ("ターゲット プラットフォームのコアあたりの MHz"))
上記の例を使用した場合:
(35.83 × 2000) ÷ (33.75 × 2300) = 0.92
プロセッサの推定数に修飾子を乗算します。 上記の場合、E5-2650 プロセッサから E5-2630 プロセッサに移行するには、計算された値を乗算して、11.25 CPU × 0.92 = 10.35 プロセッサが必要です。
付録 C: ストレージと対話するオペレーティング システムに関する基礎
「応答時間/システムのビジー状態がパフォーマンスに与える影響」で概説されている待ち行列理論の概念は、ストレージにも適用できます。 これらの概念を適用するには、オペレーティング システムで I/O がどのように処理されるかについて理解している必要があります。 Microsoft Windows オペレーティング システムでは、物理ディスクごとに I/O 要求を保持するためのキューが作成されます。 ただし、物理ディスクについて明確にする必要があります。 アレイ コントローラーと SAN によって、スピンドルの集合体が単一の物理ディスクとしてオペレーティング システムに提示されます。 さらに、アレイ コントローラーと SAN によって、複数のディスクが 1 つのアレイ セットに集約されてから、このアレイ セットが複数の "パーティション" に分割されます。これらは、オペレーティング システムに複数の物理ディスクとして提示されます (図を参照)。
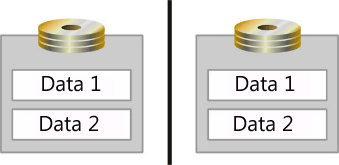
この図では、2 つのスピンドルがミラー化され、データ ストレージ用の論理領域 (データ 1 とデータ 2) に分割されています。 これらの論理領域は、オペレーティング システムによって個別の物理ディスクとして表示されます。
これは非常に紛らわしいかもしれませんが、さまざまなエンティティを識別するために、この付録全体で次の用語が使用されています。
- スピンドル - サーバーに物理的に取り付けられているデバイス。
- アレイ – コントローラーによって集約されたスピンドルのコレクション。
- アレイ パーティション – 集約されたアレイのパーティション分割
- LUN – SANを参照するときに使用されるアレイ
- ディスク – オペレーティング システムで単一の物理ディスクと見なされるもの。
- パーティション – オペレーティング システムで物理ディスクとして認識される論理パーティション分割。
オペレーティング システムのアーキテクチャに関する考慮事項
オペレーティング システムによって、監視対象のディスクごとに先入れ先出し (FIFO) I/O キューが作成されます。このディスクは、スピンドル、配列、または配列パーティションを表している場合があります。 オペレーティング システムの観点からは、I/O の処理に関して、アクティブなキューが多いほど優れています。 FIFO キューはシリアル化されるため、ストレージ サブシステムに発行されるすべての I/O は、要求が到着した順序で処理される必要があります。 オペレーティング システムによって監視される各ディスクをスピンドルまたはアレイと相関させることで、オペレーティング システムによってディスクの一意のセットごとに I/O キューが維持されるようになりました。これにより、不足している I/O リソースのディスク間での競合が排除され、I/O 要求が単一のディスクに分離されます。 例外として、Windows Server 2008 では I/O 優先順位付けという概念が導入されており、"Low" (低) の優先度を使用するように設計されたアプリケーションは、この通常の順序から外れ、後回しにされます。 "Low" (低) の優先度を利用するように特にコード化されていないアプリケーションの既定値は、"Normal" (通常) に設定されます。
シンプルなストレージ サブシステムの概要
シンプルな例 (コンピューター内に 1 つのハード ドライブ) から始めて、コンポーネントごとの分析を提供します。 これを主要なストレージ サブシステム コンポーネントに分割すると、システムの構成は次のようになります。
- 1 – 10,000 RPM Ultra Fast SCSI HD (Ultra Fast SCSI の転送速度は 20 MB/秒)
- 1 – SCSI バス (ケーブル)
- 1 – Ultra Fast SCSI アダプター
- 1 – 32 ビット 33 MHz PCI バス
コンポーネントが特定されると、システムを通過できるデータの量、または処理できる I/O の量を計算できます。 システムを通過できる I/O の量とデータの量は相関していますが、同じではないことに注意してください。 この相関関係は、ディスク I/O がランダムかシーケンシャルか、およびブロック サイズによって異なります (すべてのデータはブロックとしてディスクに書き込まれますが、アプリケーションごとに異なるブロック サイズが使用されています)。コンポーネント単位で次のようになります。
ハード ドライブ – 平均的な 10,000 RPM ハード ドライブのシーク時間は 7 ミリ秒 (ms) で、アクセス時間は 3 ms です。 シーク時間は、読み取り/書き込みヘッドがプラッター上の場所に移動するのにかかる平均時間です。 アクセス時間は、ヘッドが正しい場所に入った後に、ディスクへのデータの読み取りまたは書き込みにかかる平均時間です。 したがって、10,000 RPM の HD で一意のデータ ブロックを読み取る平均時間が、データ ブロックあたり合計約 10 ミリ秒 (.010 秒) のシークとアクセスを構成します。
すべてのディスク アクセスでヘッドをディスク上の新しい場所に移動する必要がある場合、読み取り/書き込み動作は "ランダム" と呼ばれます。 したがって、すべての I/O がランダムな場合、10,000 RPM HD では、1 秒あたり約 100 I/O (IOPS) を処理できます (式は、1 秒あたり 1000 ミリ秒を I/O あたり 10 ミリ秒で割った値、つまり 1000/10=100 IOPS です)。
または、HD 上の隣接するセクターからすべての I/O が発生する場合、これはシーケンシャル I/O と呼ばれます。 シーケンシャル I/O にはシーク時間はありません。これは、最初の I/O が完了すると、読み取り/書き込みヘッドが、次のデータ ブロックが HD に格納される先頭にあるためです。 したがって、10,000 RPM HD は、1 秒あたり約 333 I/O (1 秒あたり 1000 ミリ秒を I/O あたり 3 ミリ秒で割った値) を処理できます。
注意
この例では、通常 1 つのシリンダーのデータが保持されるディスク キャッシュは反映されていません。 この場合、最初の I/O で 10 ミリ秒が必要で、ディスクはシリンダー全体を読み取ります。 その他のシーケンシャル I/O はすべてキャッシュから満たされます。 その結果、ディスク内キャッシュによってシーケンシャル I/O パフォーマンスが向上する可能性があります。
これまでのところ、ハード ドライブの転送速度は関係ありません。 ハード ドライブが 20 MB/秒の Ultra Wide であろうと Ultra3 160 MB/秒であろうと、10,000 RPM HD で処理できる IOPS の実際の量は、最大 100 ランダムまたは最大 300 シーケンシャル I/O です。 ブロック サイズはドライブに書き込むアプリケーションに基づいて変化するため、I/O ごとにプルされるデータの量は異なります。 たとえば、ブロック サイズが 8 KB の場合、100 の I/O 操作がハード ドライブに対して読み取りまたは書き込みを行い、合計 800 KB になります。 しかし、ブロック サイズが 32 KB の場合、100 I/O はハード ドライブに 3,200 KB (3.2 MB) の読み取り/書き込みを行います。 SCSI 転送速度が転送されたデータの総量を超えている限り、転送速度が "より高速な" ドライブを取得しても何も得られません。 比較については、次の表をご覧ください。
説明 7200 RPM 9 ms シーク、4 ms アクセス 10,000 RPM 7 ms シーク、3 ms アクセス 15,000 RPM 4 ms シーク、2 ms アクセス ランダム I/O 80 100 150 シーケンシャル I/O 250 300 500 10,000 RPM ドライブ 8 KB のブロック サイズ (Active Directory Jet) ランダム I/O 800 KB/秒 シーケンシャル I/O 2400 KB/秒 SCSI バックプレーン (バス) – "SCSI バックプレーン (バス)" (このシナリオではリボン ケーブル) がストレージ サブシステムのスループットに与える影響を理解するには、ブロック サイズに関する知識が必要です。 基本的に問題になるのは、I/O が 8 KB ブロックの場合に、バスがどのくらいの I/O を処理できるかということです。 このシナリオでは、SCSI バスは 20 MB/秒 (20480 KB/秒) です。 20480 KB/秒を 8 KB ブロックで割ると、SCSI バスでサポートされる最大約 2,500 IOPS が得られます。
注意
次の表の図は、例を表しています。 ほとんどの接続ストレージ デバイスでは現在、はるかに高いスループットを提供する PCI Express が使用されています。
SCSI バスでサポートされるブロック サイズあたりの I/O 2 KB ブロック サイズ 8 KB ブロック サイズ (AD Jet) (SQL Server 7.0/SQL Server 2000) 20 MB/秒 10,000 2,500 40 MB/秒 20,000 5,000 128 MB/秒 65,536 16,384 320 MB/秒 160,000 40,000 このグラフから判断できるように、提示されたシナリオでは、スピンドルの最大値が100 I/Oで、上記のしきい値のいずれもはるかに下回っているため、用途に関係なく、バスがボトルネックになることはありません。
注意
これは、SCSI バスが 100% の高効率であることを前提としています。
SCSI アダプター – これが処理できる I/O の量を決定するには、製造元の仕様を確認する必要があります。 I/O 要求を適切なデバイスに送信するには、何らかの処理が必要です。そのため、処理できる I/O の量は、SCSI アダプター (またはアレイ コントローラー) プロセッサによって異なります。
この例では、1,000 I/O を処理できると仮定します。
PCI バス – これは見過ごされがちなコンポーネントです。 この例では、これはボトルネックにはなりませんが、システムがスケールアップすると、ボトルネックになる可能性があります。 参考までに、33MHz で動作する 32 ビット PCI バスは、理論上、133 MB/秒のデータを転送できます。 式を次に示します。
32 ビット ÷ バイトあたり 8 ビット× 33 MHz = 133 MB/秒。
これは理論的限界であることに注意してください。実際には、最大値の約 50% しか到達しませんが、特定のバースト シナリオでは、短期間で 75% の効率を得ることができます。
66 MHz 64 ビット PCI バスは、理論上の最大値 (64 ビット ÷バイトあたり 8 ビット × 66 Mhz) = 528 MB/秒をサポートできます。さらに、他のデバイス (ネットワーク アダプター、2 つ目の SCSI コントローラーなど) によって、帯域幅が共有され、デバイスが限られたリソースを奪い合うため、使用可能な帯域幅が減ります。
このストレージ サブシステムのコンポーネントを分析すると、スピンドルが、要求できる I/O の量、つまりシステムを通過できるデータの量を制限する要因であることがわかります。 具体的には、AD DS のシナリオでは、8 KB 単位で 1 秒あたり 100 のランダム I/O であり、Jet データベースにアクセスする場合は、1 秒あたり合計 800 KBになります。 または、ログ ファイルに排他的に割り当てられるスピンドルの最大スループットには、8 KB 単位で 1 秒あたり 300 シーケンシャル I/O、1 秒あたり合計 2400 KB (2.4 MB) という制限があります。
これでシンプルな構成を分析しました。次の表は、ストレージ サブシステムのコンポーネントが変更または追加された場合にボトルネックが発生する場所を示しています。
| メモ | ボトルネック分析 | ディスク | Bus | アダプター | PCI バス |
|---|---|---|---|---|---|
| これは、2 つ目のディスクを追加した後のドメイン コントローラーの構成です。 このディスク構成では、800 KB/秒のボトルネックが示されています。 | ディスクを 1 つ追加 (合計 = 2) I/O はランダム 4 KB ブロック サイズ 10,000 RPM HD |
合計 200 I/O 合計 800 KB/秒。 |
|||
| 7 つのディスクを追加した後も、ディスク構成で 3200 KB/秒のボトルネックが示されています。 | ディスクを 7 つ追加 (合計 = 8) I/O はランダム 4 KB ブロック サイズ 10,000 RPM HD |
合計 800 I/O。 合計 3200 KB/秒 |
|||
| I/O をシーケンシャルに変更すると、ネットワーク アダプターが 1000 IOPS に制限されるため、これがボトルネックになります。 | ディスクを 7 つ追加 (合計 = 8) I/O はシーケンシャル 4 KB ブロック サイズ 10,000 RPM HD |
2400 I/O 秒はディスクに読み取り/書き込み可能、コントローラーは 1000 IOPS に制限 | |||
| ネットワーク アダプターを 10,000 IOPS をサポートする SCSI アダプターに置き換えると、ボトルネックはディスク構成に戻ります。 | ディスクを 7 つ追加 (合計 = 8) I/O はランダム 4 KB ブロック サイズ 10,000 RPM HD SCSI アダプターのアップグレード (10,000 I/O のサポートが可能) |
合計 800 I/O。 合計 3,200 KB/秒 |
|||
| ブロック サイズを 32 KB に増やすと、バスは 20 MB/秒しかサポートしないため、これがボトルネックになります。 | ディスクを 7 つ追加 (合計 = 8) I/O はランダム 32 KB ブロック サイズ 10,000 RPM HD |
合計 800 I/O。 25,600 KB/秒 (25 MB/秒) をディスクに読み取り/書き込みできます。 バスは 20 MB/秒のみをサポート |
|||
| バスをアップグレードし、ディスクを追加した後も、ディスクはボトルネックのままです。 | ディスクを 13 台追加 (合計 = 14) 2 つ目の SCSI アダプターと 14 台のディスクを追加 I/O はランダム 4 KB ブロック サイズ 10,000 RPM HD 320 MB/秒の SCSI バスへのアップグレード |
2800 I/O 11,200 KB/秒 (10.9 MB/秒) |
|||
| I/O をシーケンシャルに変更した後も、ディスクはボトルネックのままです。 | ディスクを 13 台追加 (合計 = 14) 2 つ目の SCSI アダプターと 14 台のディスクを追加 I/O はシーケンシャル 4 KB ブロック サイズ 10,000 RPM HD 320 MB/秒の SCSI バスへのアップグレード |
8,400 I/O 33,600 KB/秒 (32.8 MB/秒) |
|||
| より高速なハード ドライブを追加した後も、ディスクはボトルネックのままです。 | ディスクを 13 台追加 (合計 = 14) 2 つ目の SCSI アダプターと 14 台のディスクを追加 I/O はシーケンシャル 4 KB ブロック サイズ 15,000 RPM HD 320 MB/秒の SCSI バスへのアップグレード |
14,000 I/O 56,000 KB/秒 (54.7 MB/秒) |
|||
| ブロック サイズを 32 KB に増やすと、PCI バスがボトルネックになります。 | ディスクを 13 台追加 (合計 = 14) 2 つ目の SCSI アダプターと 14 台のディスクを追加 I/O はシーケンシャル 32 KB ブロック サイズ 15,000 RPM HD 320 MB/秒の SCSI バスへのアップグレード |
14,000 I/O 448,000 KB/秒 (437 MB/秒) は、スピンドルへの読み取り/書き込みの制限です。 PCI バスでは、理論上、最大 133 MB/秒 (最大 75% の効率) がサポートされています。 |
RAID の概要
アレイ コントローラーを導入しても、ストレージ サブシステムの性質は劇的に変化しません。計算で SCSI アダプターが置き換えられるだけです。 変更点は、さまざまなアレイ レベル (RAID 0、RAID 1、RAID 5 など) を使用する場合のディスクへのデータの読み取りおよび書き込みコストです。
RAID 0 では、データは RAID セット内のすべてのディスクにストライピングされます。 これは、読み取りまたは書き込み操作中に、データの一部が各ディスクからプルまたはプッシュされ、同じ期間にシステムを通過できるデータの量が増加することを意味します。 したがって、各スピンドルで (10,000-RPM ドライブを想定)、1 秒間に 100 回の I/O 操作を実行できます。 サポートできる I/O の総量は、N 個のスピンドルにスピンドルあたり 100 IOPS を掛けた値です (100*N IOPS となります)。

RAID 1 では、冗長性を確保するために、データはスピンドルのペア間でミラー化 (複製) されます。 したがって、読み取り I/O 操作を実行すると、セット内の両方のスピンドルからデータを読み取ることができます。 これにより、読み取り操作中に両方のディスクの I/O 容量を効果的に使用できるようになります。 注意点は、書き込み操作では RAID 1 のパフォーマンス上の利点が得られないことです。 これは、冗長性を確保するために、両方のドライブに同じデータを書き込む必要があるためです。 データの書き込みは両方のスピンドルで同時に行われるので、これには時間がかかりませんが、データの複製に両方のスピンドルが占有されるため、書き込み I/O 操作によって、本質的に 2 つの読み取り操作が行われなくなります。 したがって、書き込み I/O ごとに、2 つの読み取り I/O が犠牲になります。 この情報から数式を作成して、発生している I/O 操作の総数を割り出すことができます。
"読み取り I/O" + 2 ×"書き込み I/O" = "消費された使用可能なディスク I/O の合計"
読み取りと書き込みの比率とスピンドルの数がわかっている場合は、上記の式から次の式を導き出し、そのアレイでサポートできる最大 I/O を割り出します。
"スピンドルあたりの最大 IOPS" × 2 スピンドル × [(%Reads + %Writes) ÷ (%Reads + 2 × %Writes)] = "合計 IOPS"
RAID 1 + 0 は、読み取りと書き込みのコストに関しては、RAID 1 とまったく同じようになります。 ただし、I/O はミラー化されたセットごとにストライピングされるようになりました。 If
"スピンドルあたりの最大 IOPS" × 2 スピンドル × [(%Reads + %Writes) ÷ (%Reads + 2 × %Writes)] = "合計 I/O"
RAID 1 セットで上記の場合、RAID 1 セットの多重度 (N) がストライピングされると、処理できる合計 I/O は、RAID 1 セットあたり N × I/O になります。
N × {"スピンドルあたりの最大 IOPS" × 2 スピンドル × [(%Reads + %Writes) ÷ (%Reads + 2 × %Writes)] } = "合計IOPS"
RAID 5 では、N + 1 RAID と呼ばれることもあり、データは N 個のスピンドルにストライピングされ、パリティ情報は “+ 1” スピンドルに書き込まれます。 ただし、RAID 5 で書き込み I/O を実行すると、RAID 1 または 1 + 0 よりもはるかにコストがかかります。 RAID 5 では、書き込み I/O がアレイに送信されるたびに、次のプロセスが実行されます。
- 古いデータを読み取る
- 古いパリティを読み取る
- 新しいデータを書き込む
- 新しいパリティを書き込む
オペレーティング システムによってアレイ コントローラーに送信されるすべての書き込み I/O 要求は、4 回の I/O 操作を完了する必要があるため、送信される書き込み要求は、単一の読み取り I/O の 4 倍の時間がかかります。 オペレーティング システムの観点から、I/O 要求をスピンドルで発生したものに変換する数式を導き出すには:
"読み取りI/O" + 4 ×"書き込み I/O" = "合計 I/O"
同様に、RAID 1 セットでは、読み取りと書き込みの比率とスピンドルの数がわかっている場合は、上記の式から次の式を導き出し、そのアレイでサポートできる最大 I/O を割り出します (スピンドルの合計数には、パリティに属していない"ドライブ" は含まれていないことに注意してください)。
"スピンドルあたりの IOPS" × ("スピンドル" – 1) × [(%Reads + %Writes) ÷ (%Reads + 4 × %Writes)] = "合計 IOPS"
SAN の概要
ストレージ サブシステムの複雑さが拡大し、SAN を環境に導入する場合、概説されている基本原則は変わりませんが、SAN に接続されているすべてのシステムの I/O 動作を考慮する必要があります。 SAN を使用する主な利点の 1 つは、内部または外部に接続されたストレージに比べてより多くの冗長性が確保できることです。キャパシティ プランニングでは、フォールト トレランスのニーズを考慮する必要があります。 また、評価する必要があるコンポーネントが増えます。 SAN をコンポーネント パーツに分割します。
- SCSI またはファイバー チャネル ハード ドライブ
- ストレージ ユニット チャネル バックプレーン
- ストレージ ユニット
- ストレージ コントローラー モジュール
- SAN スイッチ (複数の場合あり)
- HBA (複数の場合あり)
- PCI バス
冗長性を確保するためにシステムを設計する場合は、障害の可能性に対応するために追加のコンポーネントが含まれます。 キャパシティ プランニングでは、利用可能なリソースから冗長コンポーネントを除外することが非常に重要です。 たとえば、SAN に 2 つのコントローラー モジュールがある場合、1 つのコントローラー モジュールの I/O 容量のすべてを、システムで使用可能な合計 I/O スループットに使用する必要があります。 これは、1 つのコントローラーで障害が発生した場合に、接続されているすべてのシステムで要求される I/O 負荷全体を残りのコントローラーで処理する必要があるためです。 すべてのキャパシティ プランニングはピーク時の使用期間に対して行われるため、冗長コンポーネントを使用可能なリソースに含めるべきではありません。また、計画されたピーク使用率は、システムの飽和が 80% を超えないようにする必要があります (バーストや異常なシステム動作に対応するため)。 同様に、冗長 SAN スイッチ、ストレージ ユニット、スピンドルは、I/O の計算に含めないでください。
SCSI またはファイバー チャネル ハード ドライブの動作を分析する場合、に動作を分析する方法は、前に概説したのと変わりません。 各プロトコルにはいくつかの利点と欠点がありますが、ディスクごとの制限要因は、ハード ドライブの機械的な制限です。
ストレージ ユニットのチャネルを分析することは、SCSI バスで使用可能なリソース、つまり帯域幅 (20 MB/秒など) をブロック サイズ (8 KB など) で割って計算することとまったく同じです。 これが前のシンプルな例と異なっている点は、複数のチャネルの集約です。 たとえば、6 つのチャネルがあり、それぞれが 20 MB/秒の最大転送速度をサポートしている場合、使用可能な I/O およびデータ転送の合計量は 100 MB/秒になります (これが正しく、120 MB/秒ではありません)。 この計算でも、フォールト トレランスが大きな役割を担っており、1 つのチャネル全体が失われた場合、システムには 5 つの機能しているチャネルしか残されません。 したがって、障害が発生した場合でもパフォーマンスの期待に応え続けるには、すべてのストレージ チャネルの合計スループットが 100 MB/秒を超えないようにする必要があります (これは、負荷とフォールト トレランスがすべてのチャネルに均等に分散されることを前提としています)。 これを I/O プロファイルに変換することは、アプリケーションの動作に依存します。 Active Directory Jet I/O の場合、これは 12,500 IOPS (100 MB/秒 ÷ I/Oあたり 8 KB) と相関関係があります。
次に、各モジュールがサポートできるスループットについて理解を深めるために、コントローラー モジュールの製造元の仕様を取得する必要があります。 この例では、SAN にはそれぞれ 7,500 I/O をサポートする 2 つのコントローラー モジュールがあります。 冗長性が不要な場合、システムの合計スループットは 15,000 IOPS になります。 障害が発生した場合の最大スループットの計算では、制限は 1 つのコントローラーのスループット、つまり 7,500 IOPS です。 このしきい値は、すべてのストレージ チャネルでサポートできる最大 12,500 IOPS (4 KB のブロック サイズを想定) よりも低いため、現在、分析ではボトルネックになっています。 それでも計画の目的で、計画される望ましい最大 I/O は 10,400 I/O になります。
データは、コントローラー モジュールを出ると、定格が 1 GB/秒 (1 秒あたり 1 ギガビット) のファイバー チャネル接続を通過します。 これを他のメトリックと相関させるために、1 GB/秒は 128 MB/秒に変換 (1 GB/秒 ÷ 8 ビット/バイト) されます。 これは、ストレージ ユニットのすべてのチャネルの合計帯域幅 (100 MB/秒) を超えているため、システムのボトルネックになることはありません。 さらに、これは 2 つのチャネルのうちの 1 つにすぎないため (冗長性のために追加された 1 GB/秒ファイバー チャネル接続)、一方の接続に障害が発生した場合でも、残りの接続には、要求されたすべてのデータ転送を処理するのに十分な容量が残っています。
サーバーに向かう途中で、データはほとんどの場合、SAN スイッチを通過します。 SAN スイッチは着信 I/O 要求を処理して適切なポートに転送する必要があるため、スイッチには処理可能な I/O の量に制限がありますが、それを決定するには製造元の仕様が必要になります。 たとえば、2 つのスイッチがあり、各スイッチが 10,000 IOPS を処理できる場合、合計スループットは 20,000 IOPS になります。 この場合も、フォールト トレランスが問題になります。1 つのスイッチで障害が発生した場合、システムの合計スループットは 10,000 IOPS になります。 通常の操作では使用率が 80% を超えないことが望ましいため、使用する I/O が 8000 を超えないようにする必要があります。
最後に、サーバーにインストールされている HBA にも、処理できる I/O の量に制限があります。 通常、冗長性を確保するために 2 つ目の HBA を接続しますが、SAN スイッチの場合と同様に、処理できる最大 I/O を計算する場合、N – 1 HBA の合計スループットがシステムの最大スケーラビリティになります。
キャッシュに関する考慮事項
キャッシュは、任意の時点でストレージ システムの全体的なパフォーマンスに大きな影響を与える可能性のあるコンポーネントの 1 つです。 キャッシュ アルゴリズムに関する詳細な分析については、この記事では説明しません。ただし、ディスク サブシステムでのキャッシュに関するいくつかの基本的なステートメントは、明らかにする価値があります。
キャッシュを使用すると、サイズの小さい多くの書き込み操作をより大きな I/O ブロックに格納し、より少ないストレージにデステージできるため、持続的なシーケンシャル書き込み I/O が向上します。 これにより、合計ランダム I/O と合計シーケンシャル I/O が削減されるため、他の I/O に対するリソースの可用性が向上します。
キャッシュを使用しても、ストレージ サブシステムの持続的な書き込み I/O スループットは向上しません。 スピンドルがデータをコミットできるようになるまで、書き込みをバッファーすることのみが可能です。 ストレージ サブシステムで使用可能なすべてのスピンドルの I/O が長期間飽和状態になると、キャッシュが最終的にいっぱいになります。 キャッシュを空にするには、キャッシュをフラッシュをするのに十分な I/O を提供するために、バースト間の十分な時間、または追加のスピンドルを割り当てる必要があります。
キャッシュを大きくすると、より多くのデータをバッファーできます。 これは、より長い飽和期間に対応できることを意味します。
通常動作しているストレージ サブシステムでは、データをキャッシュに書き込むだけでよいため、オペレーティング システムの書き込みパフォーマンスが向上します。 基盤となるメディアが I/O で飽和状態になると、キャッシュがいっぱいになり、書き込みパフォーマンスがディスク速度に戻ります。
読み取り I/O をキャッシュする場合、キャッシュが最も便利なシナリオは、データがディスクに順番に格納され、キャッシュが先読みできる場合です (次のセクターに、次に要求されるデータが含まれていると想定します)。
読み取り I/O がランダムである場合、ドライブ コントローラーでのキャッシュによって、ディスクから読み取ることができるデータの量が拡張される可能性はほとんどありません。 オペレーティング システムまたはアプリケーションベースのキャッシュ サイズがハードウェアベースのキャッシュ サイズよりも大きい場合、拡張は存在しません。
Active Directory の場合、キャッシュは RAM の容量によってのみ制限されます。
SSD に関する考慮事項
SSDは、スピンドルベースのハード ディスクとはまったく異なるものです。 それでも、2 つの重要な基準が残っています。"処理できる IOPS はどれくらいか" と "それらの IOPS の待機時間はどれくらいか" ということです。 スピンドルベースのハード ディスクと比較して、SSD はより多くの I/O を処理でき、待機時間を短縮することができます。 この記事の執筆時点では、一般的に、SSD はギガバイトあたりのコストの比較では依然として高価ですが、I/O あたりのコストの観点からは非常に安価であり、ストレージのパフォーマンスの観点から熟慮する価値があります。
考慮事項:
- IOPS と待機時間はどちらも製造元の設計に大きく左右され、場合によってはスピンドルベースのテクノロジよりもパフォーマンスが低下することが確認されています。 つまり、ドライブごとに製造元の仕様を確認して検証することがより重要であり、一般性を想定しないでください。
- IOPS の型は、読み取りか書き込みかによって、大きく異なる数になる可能性があります。 AD DS サービス (一般に、主に読み取りベース) は、他のいくつかのアプリケーション シナリオよりも影響を受けません。
- "書き込みの耐久性" – これは SSD セルがいずれは摩耗するという概念です。さまざまな製造元がこの課題にさまざまな方法で取り組んでいます。 少なくともデータベース ドライブの場合は、主に読み取り I/O プロファイルであり、データの揮発性が高くないため、この懸念事項を重要視しなくても構いません。
まとめ
ストレージを家庭用の配管に例えて考えてみるのも 1 つの方法です。 データが保存されているメディアの IOPS を家庭のメインの排水管であると想像してください。 これが詰まっている場合 (パイプの根元など) または制限されている場合 (つぶれているか小さすぎる場合)、あまりにも多くの水が使用されると (お客が多すぎる)、家庭内のすべてのシンクで水が逆流します。 これは、1 つ以上のシステムが同じ基盤メディアを備えた SAN/NAS/iSCSI 上の共有ストレージを利用している共有環境と非常に似ています。 さまざまなシナリオを解決するために、さまざまな方法を使用することができます。
- つぶれたまたは小さすぎる排水管は、実際のサイズに合った配管に交換するか、修理する必要があります。 これは、新しいハードウェアを追加したり、インフラストラクチャ全体で共有ストレージを使用してシステムを再配布したりすることと似ています。
- "詰まった" パイプは、通常、1 つ以上の問題を特定し、それらの問題を取り除くことを意味します。 ストレージ シナリオでは、これはストレージまたはシステム レベルのバックアップ、すべてのサーバーにわたる同期されたウイルス対策スキャン、ピーク時に実行される同期された最適化ソフトウェアである可能性があります。
どの配管設計でも、複数の排水管がメインの排水管に流れ込むようになっています。 これらの排水管または接合点のいずれかが詰まると、この接合点の後ろにあるものだけが流れなくなります。 ストレージのシナリオでは、これはスイッチの過負荷 (SAN/NAS/iSCSI シナリオ)、ドライバーの互換性の問題 (ドライバー/HBA ファームウェア/storport.sys の間違った組み合わせ)、またはバックアップ/ウイルス対策/最適化である可能性があります。 ストレージ "パイプ" の大きさが十分であるかどうかを判断するには、IOPS と I/O サイズを測定する必要があります。 各継手で、十分な "パイプの直径" を確保するために、それらをまとめて追加します。
付録 D - ストレージのトラブルシューティングについて - 少なくともデータベース サイズと同じサイズの RAM を提供することが実行可能な選択ではない環境
これらの推奨事項が存在する理由を理解しておくと、ストレージ テクノロジの変更に対応できるようになります。 これらの推奨事項は、次の 2 つの理由で存在します。 1 つ目は、オペレーティング システムのスピンドルのパフォーマンスの問題 (つまり、ページング) がデータベースと I/O プロファイルのパフォーマンスに影響を与えないように IO を分離するためです。 2 つ目は、AD DS (およびほとんどのデータベース) のログ ファイルが本質的にシーケンシャルであり、スピンドルベースのハード ドライブとキャッシュは、シーケンシャル I/O で使用すると、オペレーティング システムのよりランダムな I/O パターンや AD DS データベース ドライブのほぼ純粋にランダムな I/O パターンと比較して、パフォーマンスにおいて大きなメリットがあるためです。 シーケンシャル I/O を別の物理ドライブに分離することにより、スループットを向上させることができます。 現在のストレージ オプションで示されている課題は、これらの推奨事項の背後にある基本的な想定が通用しなくなっていることです。 iSCSI、SAN、NAS、仮想ディスク イメージ ファイルなどの多くの仮想化ストレージ シナリオでは、基盤となるストレージ メディアが複数のホスト間で共有されるため、"IO の分離" と "シーケンシャル I/O の最適化" の両方の側面が完全に否定されます。 実際、このようなシナリオでは、共有メディアにアクセスする他のホストによってドメイン コントローラーへの応答性が低下する可能性があるため、複雑さが増します。
ストレージ パフォーマンスの計画では、コールド キャッシュの状態、ウォームアップされたキャッシュの状態、バックアップ/復元という 3 つのカテゴリを考慮する必要があります。 コールド キャッシュの状態は、ドメイン コントローラーが最初に再起動されたときや Active Directory サービスが再起動されたときに、RAM に Active Directory データがないなどのシナリオで発生します。 ウォームアップされたキャッシュの状態は、ドメイン コントローラーが正常な状態にあり、データベースがキャッシュされている状態です。 これらはかなり異なるパフォーマンス プロファイルを実行し、データベース全体をキャッシュするのに十分な RAM があるため、キャッシュがコールドの場合はパフォーマンスを向上させることができないので注意が必要です。 次の例えを使って、これら 2 つのシナリオのパフォーマンス設計を検討できます。コールド キャッシュのウォームアップを "短距離走" に、ウォーム キャッシュを使用したサーバーの実行を "マラソン" とします。
コールド キャッシュとウォーム キャッシュのどちらのシナリオでも、問題は、ストレージがデータをディスクからメモリにどれだけ速く移動できるかということです。 キャッシュのウォームアップは、時間の経過とともに、データを再利用するクエリが増え、キャッシュ ヒット率が増加し、ディスクに移動する必要がある頻度が減少するにつれて、パフォーマンスが向上するシナリオです。 その結果、ディスクへの移動によるパフォーマンスへの悪影響が軽減されます。 パフォーマンスの低下は、キャッシュがウォームアップしてシステムに依存する最大許容サイズに達するの待機している間の一時的なものに過ぎません。 このスレッドを簡略化して、データをディスクから取得する速度を上げることができます。これは、Active Directory で使用可能な IOPS の簡単な測定値であり、基盤となるストレージから使用可能な IOPS に左右されます。 計画の観点から見ると、キャッシュのウォームアップとバックアップ/復元のシナリオは例外的 (通常は営業時間外) に発生し、DC の負荷に左右されるため、これらのアクティビティをピーク時間外にスケジュールすること以外に、一般的な推奨事項は存在しません。
ほとんどのシナリオでは、AD DS は主に読み取り IO で、通常は90% 読み取り/10% 書き込みの比率です。 読み取り I/O はユーザー エクスペリエンスのボトルネックになる傾向が高く、書き込み IO によって書き込みパフォーマンスが低下します。 NTDS.dit への I/O は圧倒的にランダムであり、キャッシュは読み取り IO に対して最小限のメリットしかもたらさない傾向があるため、読み取り I/O プロファイル用にストレージを正しく構成することがはるかに重要になります。
通常の動作条件では、ストレージの計画目標は、AD DS からの要求がディスクから返されるまでの待機時間を最小限に抑えることです。 これは基本的に、未処理および保留中の I/O の数が、ディスクへの経路の数以下であることを意味します。 これを測定するには、さまざまな方法があります。 パフォーマンス監視シナリオでは、一般的な推奨事項は、LogicalDisk(<NTDS Database Drive>)\Avg Disk sec/Read を 20 ミリ秒未満にすることです。 必要な動作のしきい値は、ストレージの種類に応じて、2 - 6 ミリ秒 (.002 - .006 秒) の範囲で大幅に小さくする必要があります。可能であればストレージの速度にできるだけ近づけます。
例:
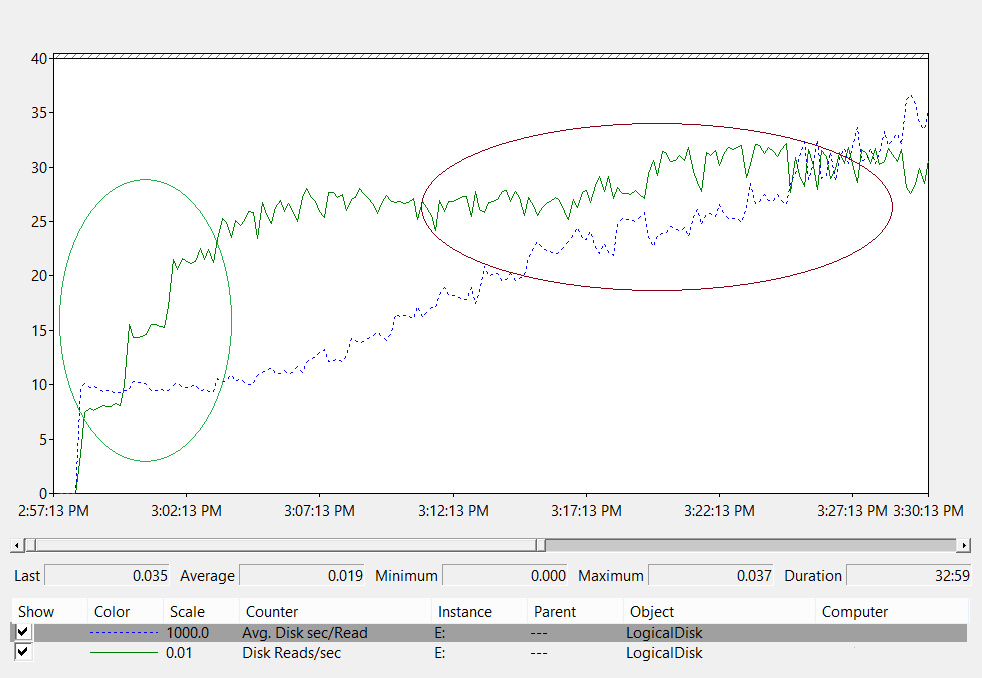
グラフの分析:
- 左側の緑色の楕円 – 待機時間は 10 ミリ秒で一定のままです。 負荷は 800 IOPS から 2400 IOPS に増加しています。 これは、基盤となるストレージで I/O 要求を処理できる速度の絶対的な下限です。 これは、ストレージ ソリューションの仕様の影響を受けます。
- 右側にある赤紫色の楕円 – 待機時間が増加し続けている間、スループットは緑色の円の終了からデータ収集の終わりまでフラットのままです。 これは、要求ボリュームが基盤となるストレージの物理的な制限を超えると、要求がストレージ サブシステムに送信されるのを待つためにキューに留まる時間が長くなることを示しています。
この知識を適用:
- 大規模なグループのメンバーシップを照会するユーザーへの影響 – この場合、ディスクから 1 MB のデータを読み取る必要があると仮定します。I/O の量とその所要時間は次のように評価できます。
- Active Directory データベース ページのサイズは 8 KB です。
- 少なくとも 128 ページをディスクから読み取る必要があります。
- 何もキャッシュされていないと仮定すると、下限 (10ミリ秒) では、データをクライアントに返すためにディスクからデータを読み込むのに最低 1.28 秒かかります。 ストレージのスループットが最大になってから長い時間が経過し、推奨される最大値でもある 20 ミリ秒では、データをエンド ユーザーに返すためにディスクからデータを取得するのに 2.5 秒かかります。
- キャッシュがウォームアップされる速度 - このストレージの例では、クライアントの負荷によってスループットが最大化されると想定すると、キャッシュは 2400 IOPS × IO あたり 8 KB の速度でウォームアップされます。 または、約 20 MB/秒で、53 秒ごとに約 1 GB のデータベースが RAM に読み込まれます。
注意
システムがバックアップされているときや AD DS でガベージ コレクションが実行されているときなど、コンポーネントがディスクに対して積極的に読み取りまたは書き込みを行うときは、短時間、待機時間の上昇が見られるのは通常のことです。 これらの定期的なイベントに対応するために、計算に加えて追加のヘッドルームを用意する必要があります。 目標は、通常の機能に影響を与えることなく、これらのシナリオに対応するのに十分なスループットを提供することです。
ご覧のとおり、ストレージの設計に基づいて、キャッシュをウォームアップできる速度には物理的な制限があります。 キャッシュをウォームアップするのは、基盤となるストレージが提供できる最大速度までの着信クライアント要求です。 ピーク時にキャッシュを "事前にウォームアップ" するスクリプトを実行すると、実際のクライアント要求による読み込みの競合が発生します。 これは、クライアントが最初に必要とするデータの配信に悪影響を及ぼす可能性があります。これは設計上、キャッシュを人為的にウォームアップしようとすると、DC に接続しているクライアントに関係のないデータが読み込まれるため、不足しているディスク リソースをめぐる競合が発生するためです。