모놀리식 지속성 안티패턴
애플리케이션의 모든 데이터를 단일 데이터 저장소에 저장하면 리소스 경합이 발생하기 때문에, 또는 데이터 저장소가 데이터의 일부에 맞지 않기 때문에 성능이 저하될 수 있습니다.
문제 설명
지금까지 애플리케이션은 흔히 애플리케이션이 저장해야 할 수 있는 데이터의 유형과 상관없이 단일 데이터 저장소를 사용해 왔습니다. 일반적으로 이런 관행은 애플리케이션 디자인을 단순화하거나 개발 팀의 기존 기술력에 맞추기 위한 것이었습니다.
최신 클라우드 기반 시스템은 흔히 추가적인 기능 및 비기능 요구 사항을 가지고 있으며 문서, 이미지, 캐시된 데이터, 큐에 저장된 메시지, 애플리케이션 로그 및 원격 분석 데이터 등 형식이 다른 많은 유형을 저장해야 합니다. 기존의 접근법에 따라 이러한 모든 정보를 동일한 데이터 저장소에 저장하면 두 가지 주된 이유 때문에 성능이 저하될 수 있습니다.
- 관련되지 않은 대량의 데이터를 동일한 데이터 저장소에 저장하고 검색하면 경합이 발생하여 응답 시간이 느려지고 연결 장애가 발생할 수 있습니다.
- 어느 데이터 저장소를 선택하든, 서로 다른 모든 유형의 데이터에 맞을 수 없으며 애플리케이션이 수행하는 작업에 대해 최적화되지 않을 수도 있습니다.
다음 예제에서는 데이터베이스에 새 레코드를 추가하고 결과를 로그에 기록하기도 하는 ASP.NET Web API 컨트롤러를 보여 줍니다. 로그는 비즈니스 데이터와 같은 데이터베이스에 저장됩니다. 전체 샘플은 여기에서 찾을 수 있습니다.
public class MonoController : ApiController
{
private static readonly string ProductionDb = ...;
public async Task<IHttpActionResult> PostAsync([FromBody]string value)
{
await DataAccess.InsertPurchaseOrderHeaderAsync(ProductionDb);
await DataAccess.LogAsync(ProductionDb, LogTableName);
return Ok();
}
}
로그 데이터가 생성되는 속도는 아마도 비즈니스 작업의 성능에 영향을 미칠 것입니다. 그리고 애플리케이션 프로세스 모니터 같은 또 다른 구성 요소가 정기적으로 로그 데이터를 읽고 처리하여 비즈니스 작업에 영향을 미칠 수도 있습니다.
문제를 해결하는 방법
용도에 따라 데이터를 분리합니다. 각 데이터 집합에 대해 해당 데이터 집합이 사용되는 방법과 가장 잘 일치하는 데이터 저장소를 선택합니다. 앞의 예제에서는 애플리케이션이 비즈니스 데이터를 저장하는 데이터베이스와 별도의 저장소에 기록해야 합니다.
public class PolyController : ApiController
{
private static readonly string ProductionDb = ...;
private static readonly string LogDb = ...;
public async Task<IHttpActionResult> PostAsync([FromBody]string value)
{
await DataAccess.InsertPurchaseOrderHeaderAsync(ProductionDb);
// Log to a different data store.
await DataAccess.LogAsync(LogDb, LogTableName);
return Ok();
}
}
고려 사항
데이터를 사용 방법 및 액세스 방법에 따라 분리합니다. 예를 들어 로그 정보와 비즈니스 데이터를 같은 데이터 저장소에 저장하지 않습니다. 이러한 유형의 데이터는 요구 사항과 액세스 패턴이 매우 다릅니다. 로그 데이터는 본래 순차적인 반면에, 비즈니스 데이터는 무작위 액세스가 필요할 가능성이 더 높으며 흔히 관계형입니다.
각 데이터 유형에 대한 데이터 액세스 패턴을 고려합니다. 예를 들어 서식 설정된 보고서와 문서를 Azure Cosmos DB와 같은 문서 데이터베이스에 저장하지만 Azure Cache for Redis를 사용하여 임시 데이터를 캐시합니다.
이 지침을 따랐지만 여전히 데이터베이스 한계에 도달한다면 데이터베이스를 규모 확장해야 할 수 있습니다. 또한 수평으로 크기 조정 및 데이터베이스 서버 전체에 걸쳐 부하 분할을 고려합니다. 단, 분할하려면 애플리케이션을 다시 디자인해야 합니다. 자세한 내용은 데이터 분할을 참조하세요.
문제를 감지하는 방법
시스템은 데이터베이스 연결 같은 리소스가 부족하게 되어 속도가 크게 느려지고 결국 장애가 발생할 가능성이 있습니다.
다음 단계를 수행하면 원인을 식별하는 데 도움이 될 수 있습니다.
- 시스템을 계측하여 주요 성능 통계를 기록합니다. 각 작업에 대한 타이밍 정보 및 애플리케이션이 데이터를 읽고 쓰는 지점을 수집합니다.
- 가능하면 프로덕션 환경에서 실행 중인 시스템을 몇 일 동안 모니터링하여 시스템 사용 방법의 실제 모습을 파악합니다. 이렇게 할 수 없는 경우 대표적인 작업 시리즈를 수행하는 가상 사용자의 사실적인 양을 사용하여 스크립트로 작성한 부하 테스트를 실행합니다.
- 원격 분석 데이터를 사용하여 성능이 저하되는 기간을 식별합니다.
- 이러한 기간 동안 액세스되는 데이터 저장소를 식별합니다.
- 충돌이 발생할 수 있는 데이터 스토리지 리소스를 식별합니다.
예제 진단
다음 섹션에서는 이러한 단계를 앞에서 설명한 애플리케이션 예제에 적용합니다.
시스템 계측 및 모니터링
다음 그래프는 앞서 설명한 애플리케이션 예제 부하 테스트의 결과를 보여줍니다. 이 테스트에서는 최대 1000명의 동시 사용자 단계 부하를 사용했습니다.
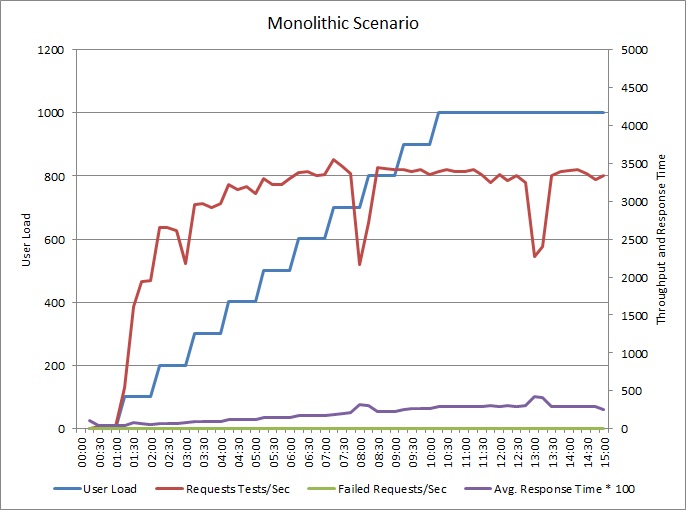
부하가 사용자 700명으로 증가하면 처리량도 그만큼 증가합니다. 그러나 해당 지점에서 처리량 수준이 보통 수준이면 시스템은 최대 용량으로 실행하는 것처럼 보입니다. 평균 응답은 사용자 부하에 따라 서서히 증가하여 시스템이 요구를 수용할 수 없음을 보여 줍니다.
성능 저하 기간 식별
프로덕션 시스템을 모니터링하는 경우 패턴에 확인할 수 있습니다. 예를 들어 응답 시간이 매일 같은 시간에 크게 감소할 수 있습니다. 이러한 현상은 정기적인 워크로드 또는 예약된 일괄 처리 작업 때문에, 또는 단순히 특정 시간에 시스템 사용자가 더 많기 때문에 발생할 수 있습니다. 이러한 이벤트의 경우 원격 분석 데이터에 초점을 맞춰야 합니다.
증가된 응답 시간과 증가된 데이터베이스 작업 또는 공유 리소스에 대한 I/O 간의 상관성을 찾습니다. 상관성이 있다면 그것은 데이터베이스에 병목이 있다는 것을 의미할 수 있습니다.
해당 기간 중에 액세스되는 데이터 저장소 식별
다음 그래프는 부하 테스트 중의 DTU(데이터베이스 처리량 단위) 사용률을 보여 줍니다. (DTU는 사용 가능한 용량의 척도이며 CPU 사용률, 메모리 할당, I/O 속도의 조합입니다.) DTU 사용률은 금세 100%에 도달했습니다. 이 부분은 대략 이전 그래프에서 처리량이 최고점에 도달한 시점입니다. 데이터베이스 사용률은 테스트가 완료될 때까지 매우 높게 유지되었습니다. 제한, 데이터베이스 연결 경합 또는 다른 요인으로 발생할 수 있는 끝부분으로 갈수록 조금씩 저하됩니다.

데이터 저장소에 대한 원격 분석 데이터 검사
데이터 원본을 계측하여 작업의 낮은 수준 세부 정보를 수집합니다. 샘플 애플리케이션에서 데이터 액세스 통계는 PurchaseOrderHeader 테이블 및 MonoLog 테이블에 대해 대량의 삽입 작업이 수행되었음을 보여 줍니다.

리소스 경합 식별
이 시점에서 경합하는 리소스에 애플리케이션이 액세스하는 지점에 초점을 맞춰 소스 코드를 검토할 수 있습니다. 다음과 같은 상황을 찾습니다.
- 동일한 저장소에 쓰는 논리적으로 별개인 데이터. 로그, 보고서 및 큐에 저장된 메시지 같은 데이터는 비즈니스 정보와 동일한 데이터에 저장하지 않아야 합니다.
- 데이터 저장소 선택과 관계 데이터베이스의 큰 Blob 또는 XML 같은 데이터 유형의 불일치.
- 낮은 쓰기/높은 읽기 데이터와 함께 저장된 높은 쓰기/낮은 읽기 데이터와 같이 동일한 저장소를 공유하는 매우 다른 사용량 패턴을 가진 데이터.
솔루션 구현 및 결과 확인
로그를 별도의 데이터 저장소에 쓰기 위해 애플리케이션을 변경했습니다. 부하 테스트 결과는 다음과 같습니다.
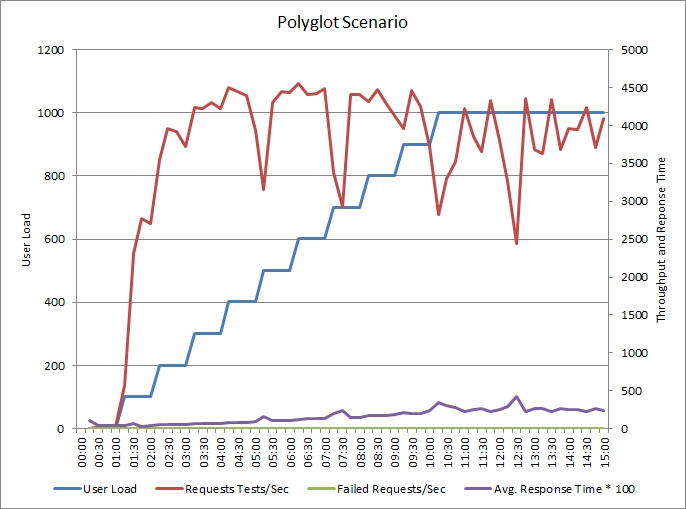
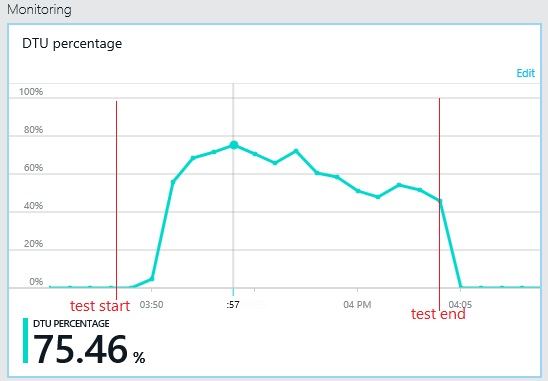
처리량 패턴은 이전 그래프와 유사하지만 성능이 최고점에 도달하는 지점은 초당 요청 수 약 500개 이상입니다. 평균 응답 시간은 조금 낮아졌습니다. 그러나 이러한 통계가 전체 스토리를 말해 주는 것은 아닙니다. 비즈니스 데이터베이스에 대한 원격 분석 데이터는 DTU 사용률이 100%가 아닌 약 75%에서 최고점에 도달한다는 것을 보여 줍니다.
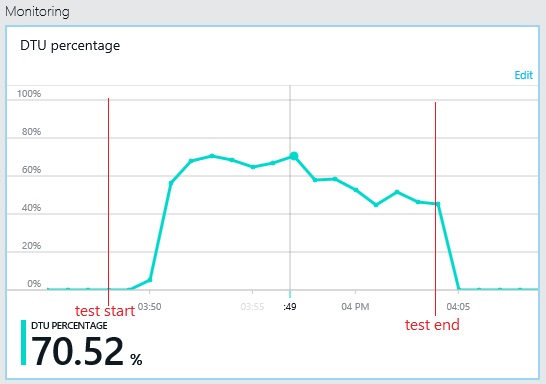
마찬가지로 로그 데이터베이스의 최대 DTU 사용률은 약 70%에만 도달합니다. 데이터베이스는 더 이상 시스템 성능을 제한하는 요소가 아닙니다.
관련 리소스
피드백
출시 예정: 2024년 내내 콘텐츠에 대한 피드백 메커니즘으로 GitHub 문제를 단계적으로 폐지하고 이를 새로운 피드백 시스템으로 바꿀 예정입니다. 자세한 내용은 다음을 참조하세요. https://aka.ms/ContentUserFeedback
다음에 대한 사용자 의견 제출 및 보기