캐싱 없음 안티패턴
안티패턴은 스트레스 상황에서 소프트웨어 또는 애플리케이션을 중단시킬 수 있는 일반적인 설계 결함이며 간과해서는 안 됩니다. 여러 동시 요청을 처리하는 클라우드 애플리케이션에서 동일한 데이터를 반복적으로 가져오면 캐싱 없음 안티패턴이 발생합니다. 이 경우 성능과 확장성이 저하될 수 있습니다.
데이터가 캐시되지 않으면 다음을 비롯한 여러 가지 바람직하지 않은 동작이 발생할 수 있습니다.
- I/O 오버헤드 또는 대기 시간 측면에서 액세스 비용이 높은 리소스에서 동일한 정보를 반복적으로 가져옵니다.
- 여러 요청에 대해 동일한 개체 또는 데이터 구조를 반복적으로 생성합니다.
- 서비스 할당량이 있는 원격 서비스에 대한 과도한 호출을 수행하고 클라이언트가 특정 한도를 초과하도록 제한합니다.
따라서 이러한 문제로 인해 응답 시간이 저하되고, 데이터 저장소의 경합이 증가하고, 확장성이 저하될 수 있습니다.
캐싱 안티패턴 없음의 예
다음 예제에서는 Entity Framework를 사용하여 데이터베이스에 연결합니다. 여러 요청이 정확히 동일한 데이터를 가져오는 경우에도 모든 클라이언트 요청은 데이터베이스에 대한 호출을 발생합니다. 반복되는 요청의 비용은 I/O 오버헤드 및 데이터 액세스 비용 측면에서, 신속하게 누적 될 수 있습니다.
public class PersonRepository : IPersonRepository
{
public async Task<Person> GetAsync(int id)
{
using (var context = new AdventureWorksContext())
{
return await context.People
.Where(p => p.Id == id)
.FirstOrDefaultAsync()
.ConfigureAwait(false);
}
}
}
전체 샘플은 여기에서 찾을 수 있습니다.
이런 안티패턴이 발생하는 일반적인 이유는 다음과 같습니다.
- 캐시를 사용하지 않는 것이 구현이 더 간단하며 부하가 낮은 상태에서는 잘 작동합니다. 캐싱을 사용하면 코드가 더 복잡해집니다.
- 캐시 사용의 장단점을 명확하게 이해하기 힘듭니다.
- 캐시된 데이터의 정확성과 최신 상태를 유지하는 오버헤드에 대한 우려가 있습니다.
- 애플리케이션은 네트워크 대기 시간이 문제가 되지 않는 온-프레미스 시스템에서 마이그레이션되었으며, 시스템이 고가의 고성능 하드웨어에서 실행되었으므로 원래 디자인에서는 캐싱이 고려되지 않았습니다.
- 개발자는 지정된 시나리오에서 캐싱이 가능할 수 있다는 것을 인식하지 못합니다. 예를 들어 개발자는 웹 API를 구현할 때 ETag를 사용하지 않을 수 있습니다.
캐싱 없음 안티패턴을 해결하는 방법
가장 많이 사용되는 캐싱 전략은 주문형 또는 캐시 배재 전략입니다.
- 읽기 시 애플리케이션은 캐시에서 데이터를 읽으려고 시도합니다. 데이터가 캐시에 없으면 애플리케이션은 데이터 원본에서 데이터를 검색하여 캐시에 추가합니다.
- 쓰기의 경우, 애플리케이션은 변경 사항을 데이터 원본에 직접 쓰고 캐시에서 이전 값을 제거합니다. 다음에 필요할 때 검색되어 캐시에 추가됩니다.
이 방식은 자주 변경되는 데이터에 적합합니다. 다음은 캐시 배제 패턴을 사용하도록 업데이트된 이전 예제입니다.
public class CachedPersonRepository : IPersonRepository
{
private readonly PersonRepository _innerRepository;
public CachedPersonRepository(PersonRepository innerRepository)
{
_innerRepository = innerRepository;
}
public async Task<Person> GetAsync(int id)
{
return await CacheService.GetAsync<Person>("p:" + id, () => _innerRepository.GetAsync(id)).ConfigureAwait(false);
}
}
public class CacheService
{
private static ConnectionMultiplexer _connection;
public static async Task<T> GetAsync<T>(string key, Func<Task<T>> loadCache, double expirationTimeInMinutes)
{
IDatabase cache = Connection.GetDatabase();
T value = await GetAsync<T>(cache, key).ConfigureAwait(false);
if (value == null)
{
// Value was not found in the cache. Call the lambda to get the value from the database.
value = await loadCache().ConfigureAwait(false);
if (value != null)
{
// Add the value to the cache.
await SetAsync(cache, key, value, expirationTimeInMinutes).ConfigureAwait(false);
}
}
return value;
}
}
이제 메서드가 GetAsync 데이터베이스를 CacheService 직접 호출하지 않고 클래스를 호출합니다. 클래스는 CacheService 먼저 Azure Cache for Redis에서 항목을 가져오려고 시도합니다. 캐시 CacheService 에 값이 없으면 호출자가 전달한 람다 함수를 호출합니다. 람다 함수는 데이터베이스에서 데이터를 가져오는 역할을 담당합니다. 이 구현은 특정 캐싱 솔루션에서 리포지토리를 분리하고 데이터베이스에서 분리합니다 CacheService .
캐싱 전략에 대한 고려 사항
일시적 오류로 인해 캐시를 사용할 수 없는 경우 클라이언트에 오류를 반환하지 마세요. 대신 원래 데이터 원본에서 데이터를 가져옵니다. 그러나 캐시가 복구되는 동안 원래 데이터 저장소는 요청으로 인해 시간이 초과되고 연결이 실패할 수 있습니다. (결국, 이것은 처음에 캐시를 사용하는 동기 중 하나입니다.) 회로 차단기 패턴과 같은 기술을 사용하여 데이터 원본을 압도하지 않도록 합니다.
동적 데이터를 캐시하는 애플리케이션은 최종 일관성을 지원하도록 설계되어야 합니다.
웹 API의 경우, 요청 및 응답 메시지에 Cache-Control 헤더를 포함시키고 ETag를 사용하여 개체 버전을 식별하면 클라이언트 쪽 캐싱을 지원할 수 있습니다. 자세한 내용은 API 구현을 참조하세요.
전체 엔터티를 캐시할 필요는 없습니다. 대부분의 엔터티가 정적이지만 작은 부분만 자주 변경되는 경우 정적 요소를 캐시하고 데이터 원본에서 동적 요소를 검색합니다. 이 방식은 데이터 원본에 대해 수행되는 I/O 볼륨을 줄이는 데 유용합니다.
경우에 따라 일시적 데이터가 수명이 짧은 경우 캐시하는 것이 유용할 수 있습니다. 예를 들어 상태 업데이트를 지속적으로 보내는 디바이스를 고려해 보세요. 정보가 도착하면 캐시하고 영구 저장소에 전혀 쓰지 않는 것이 좋습니다.
데이터가 부실해지는 것을 방지하기 위해 많은 캐싱 솔루션이 구성 가능한 만료 기간을 지원합니다. 따라서 지정된 간격이 지나면 데이터가 캐시에서 자동으로 제거됩니다. 시나리오의 만료 시간을 조정해야 할 수 있습니다. 매우 정적인 데이터는 휘발성 데이터(신속하게 부실한 상태가 되는 )보다 캐시에 오래 남아있을 수 있습니다.
캐싱 솔루션이 기본 제공 만료를 제공하지 않는 경우 캐시가 제한 없이 증가하지 않도록 캐시를 스윕하는 백그라운드 프로세스를 구현해야 할 수 있습니다.
외부 데이터 원본에서 데이터를 캐싱하는 것 외에도 캐싱을 사용하여 복잡한 계산 결과를 저장할 수 있습니다. 그러나 이렇게 하기 전에 애플리케이션을 계측하여 애플리케이션이 실제로 CPU 바인딩되어 있는지 확인합니다.
애플리케이션이 시작될 때 캐시를 프라임하는 것이 유용할 수 있습니다. 캐시를 사용할 가능성이 가장 높은 데이터로 채웁다.
항상 캐시 적수 및 캐시 누락을 감지하는 계측을 포함합니다. 이 정보를 사용하여 캐시할 데이터 및 만료되기 전에 캐시에 데이터를 보관할 기간과 같은 캐싱 정책을 튜닝합니다.
캐싱이 부족하여 병목 상태가 되는 경우, 캐싱을 추가하면 요청 수가 너무 많아져서 웹 프런트 엔드에 과부하가 걸릴 수 있습니다. 클라이언트는 HTTP 503(서비스를 사용할 수 없음) 오류를 수신하기 시작할 수 있습니다. 프런트 엔드를 확장해야 한다는 표시입니다.
캐싱 방지 방지를 감지하는 방법
다음 단계를 수행하여 캐싱 부족이 성능 문제를 일으키는지 여부를 식별할 수 있습니다.
애플리케이션 디자인을 검토합니다. 애플리케이션에서 사용하는 모든 데이터 저장소의 인벤토리를 가져옵니다. 각각에 대해 애플리케이션이 캐시를 사용하는지 여부를 확인합니다. 가능하면 데이터 변경 빈도를 결정합니다. 캐싱에 적합한 초기 후보는 느리게 변경되는 데이터와 자주 읽는 정적 참조 데이터를 포함합니다.
애플리케이션을 계측하고 실시간 시스템을 모니터링하여 애플리케이션이 데이터를 검색하거나 정보를 계산하는 빈도를 확인합니다.
테스트 환경에서 애플리케이션을 프로파일레이션하여 데이터 액세스 작업 또는 기타 자주 수행되는 계산과 관련된 오버헤드에 대한 하위 수준 메트릭을 캡처합니다.
테스트 환경에서 부하 테스트를 수행하여 시스템이 일반 워크로드 및 부하가 많은 상태에서 응답하는 방법을 식별합니다. 부하 테스트는 실제 워크로드를 사용하여 프로덕션 환경에서 관찰된 데이터 액세스 패턴을 시뮬레이션해야 합니다.
기본 데이터 저장소에 대한 데이터 액세스 통계를 검사하고 동일한 데이터 요청이 반복되는 빈도를 검토합니다.
예제 진단
다음 섹션에서는 이러한 단계를 앞에서 설명한 애플리케이션 예제에 적용합니다.
애플리케이션 계측 및 라이브 시스템 모니터링
애플리케이션을 계측하고 모니터링하여 애플리케이션이 프로덕션 상태일 때 사용자가 수행하는 특정 요청에 대한 정보를 가져옵니다.
다음 이미지는 부하 테스트 중 New Relic으로 캡처한 모니터링 데이터를 보여줍니다. 이 경우 수행된 유일한 HTTP GET 작업은 .입니다 Person/GetAsync. 그러나 실제 프로덕션 환경에서 각 요청이 수행되는 상대적 빈도를 알면 어떤 리소스를 캐시해야 하는지 파악할 수 있습니다.
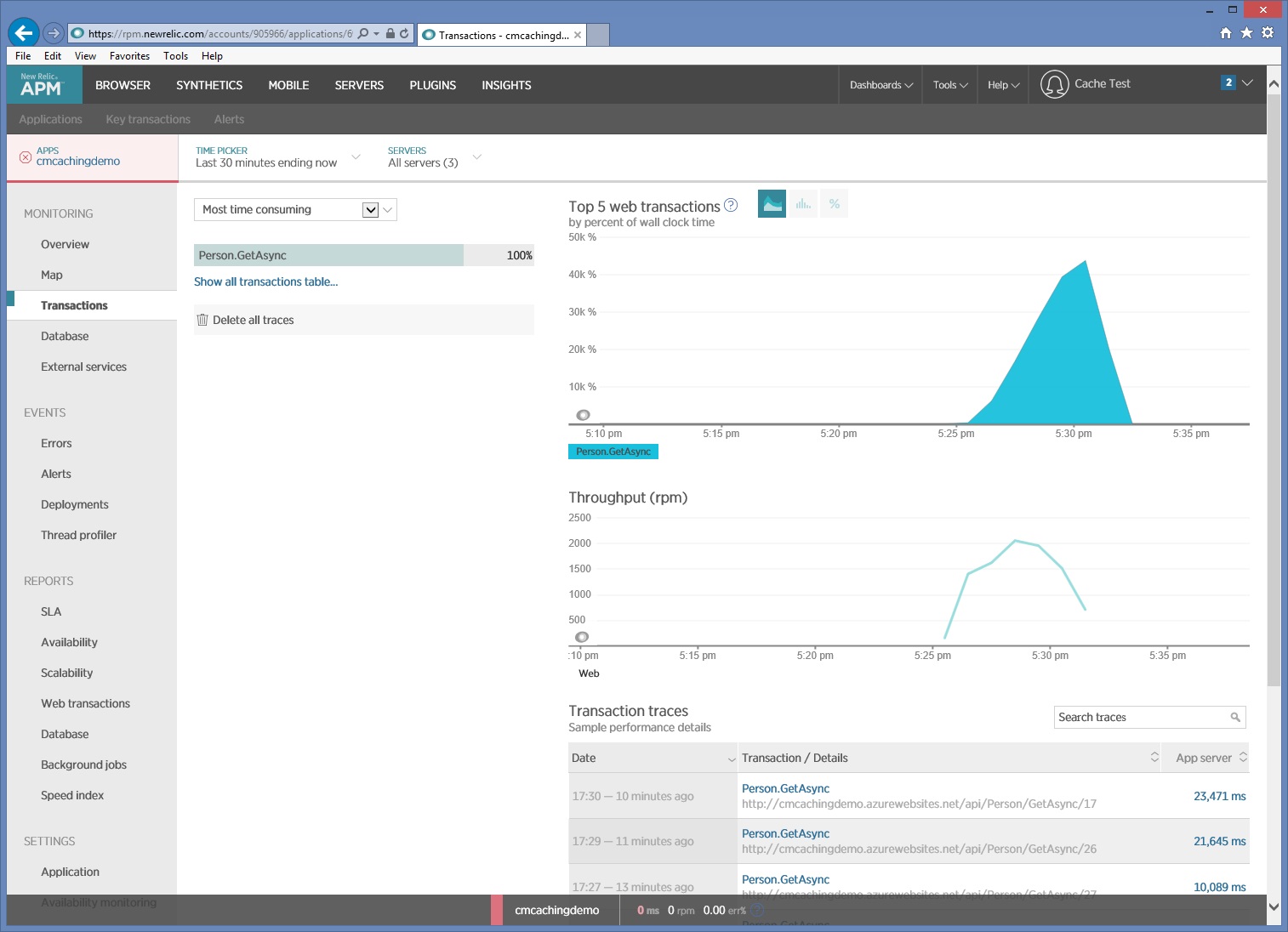
심층 분석이 필요한 경우 프로파일러를 사용하여 프로덕션 시스템이 아닌 테스트 환경에서 낮은 수준의 성능 데이터를 캡처할 수 있습니다. I/O 요청 속도, 메모리 사용량 및 CPU 사용률과 같은 메트릭을 살펴봅니다. 이러한 메트릭은 데이터 저장소 또는 서비스에 대한 많은 요청 또는 동일한 계산을 수행하는 반복된 처리를 표시할 수 있습니다.
애플리케이션 부하 테스트
다음 그래프는 샘플 애플리케이션의 부하 테스트 결과를 보여줍니다. 부하 테스트는 일반적인 일련의 작업을 수행하는 최대 800명의 사용자의 단계 로드를 시뮬레이션합니다.

매 초마다 수행된 성공적인 테스트 수가 고원에 도달하고 추가 요청이 결과적으로 느려집니다. 워크로드에 따라 평균 테스트 시간이 꾸준히 증가합니다. 사용자 로드가 최고조에 도달하면 응답 시간 수준이 해제됩니다.
데이터 액세스 통계 검사
데이터 액세스 통계 및 데이터 저장소에서 제공하는 기타 정보는 가장 자주 반복되는 쿼리와 같은 유용한 정보를 제공할 수 있습니다. 예를 들어 Microsoft SQL Server sys.dm_exec_query_stats 에서 관리 뷰에는 최근에 실행된 쿼리에 대한 통계 정보가 있습니다. 각 쿼리의 텍스트를 보기에서 sys.dm_exec-query_plan 사용할 수 있습니다. SQL Server Management Studio와 같은 도구를 사용하여 다음 SQL 쿼리를 실행하고 쿼리가 수행되는 빈도를 결정할 수 있습니다.
SELECT UseCounts, Text, Query_Plan
FROM sys.dm_exec_cached_plans
CROSS APPLY sys.dm_exec_sql_text(plan_handle)
CROSS APPLY sys.dm_exec_query_plan(plan_handle)
결과의 UseCount 열은 각 쿼리가 실행되는 빈도를 나타냅니다. 다음 이미지는 세 번째 쿼리가 다른 쿼리보다 훨씬 많은 250,000회 이상 실행되었음을 보여줍니다.
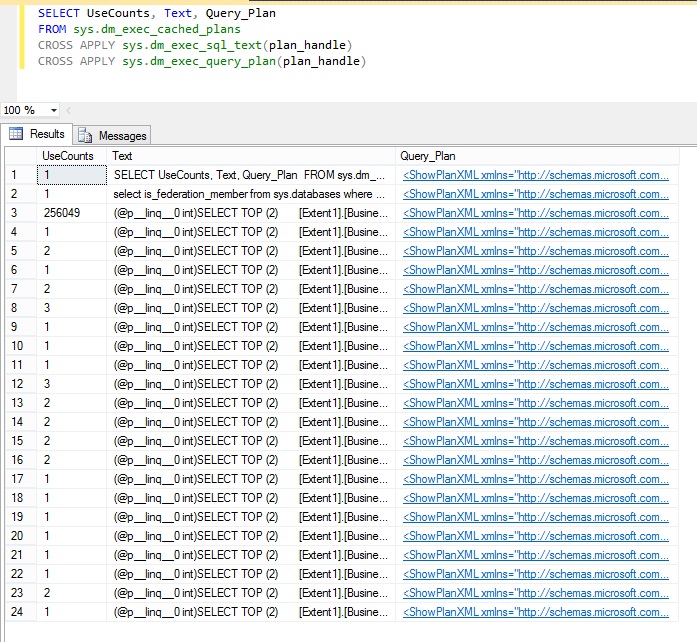
데이터베이스 요청이 너무 많은 SQL 쿼리는 다음과 같습니다.
(@p__linq__0 int)SELECT TOP (2)
[Extent1].[BusinessEntityId] AS [BusinessEntityId],
[Extent1].[FirstName] AS [FirstName],
[Extent1].[LastName] AS [LastName]
FROM [Person].[Person] AS [Extent1]
WHERE [Extent1].[BusinessEntityId] = @p__linq__0
앞에서 본 Entity Framework에서 GetByIdAsync 메서드로 생성한 쿼리입니다.
캐시 전략 솔루션 구현 및 결과 확인
캐시를 통합한 후 부하 테스트를 반복하고 결과를 캐시 없이 이전 부하 테스트와 비교합니다. 다음은 애플리케이션 예제에 캐시를 추가한 후 부하 테스트 결과입니다.
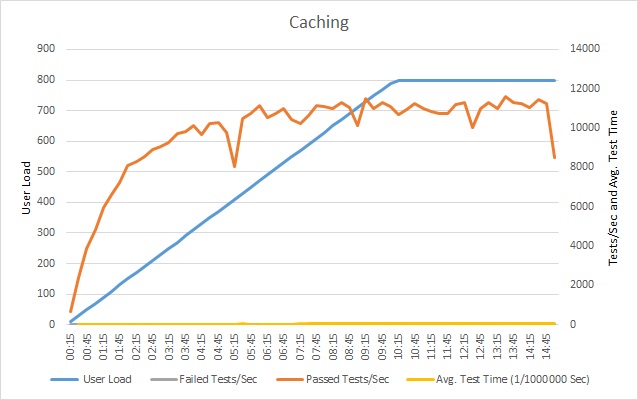
성공적인 테스트 볼륨은 여전히 고원에 도달하지만 사용자 부하가 더 높습니다. 이 로드에서 요청 속도는 이전보다 훨씬 높습니다. 평균 테스트 시간은 부하에 따라 여전히 증가하지만 최대 응답 시간은 이전 1ms 대비 0.05ms로 20배가 향상되었습니다.
관련 참고 자료
피드백
출시 예정: 2024년 내내 콘텐츠에 대한 피드백 메커니즘으로 GitHub 문제를 단계적으로 폐지하고 이를 새로운 피드백 시스템으로 바꿀 예정입니다. 자세한 내용은 다음을 참조하세요. https://aka.ms/ContentUserFeedback
다음에 대한 사용자 의견 제출 및 보기