Synapse SQL에서 외부 테이블 사용
외부 테이블은 Hadoop, Azure Storage Blob 또는 Azure Data Lake Storage에 있는 데이터를 가리킵니다. 외부 테이블을 사용하여 Azure Storage의 파일에서 데이터를 읽거나 쓸 수 있습니다.
Synapse SQL에서는 전용 SQL 풀 또는 서버리스 SQL 풀을 사용하여 외부 테이블로 데이터를 읽고 쓸 수 있습니다.
외부 데이터 원본의 유형에 따라 다음과 같은 두 가지 유형의 외부 테이블을 사용할 수 있습니다.
- CSV, Parquet 및 ORC와 같은 다양한 데이터 형식의 데이터를 읽고 내보낼 수 있는 Hadoop 외부 테이블 Hadoop 외부 테이블은 전용 SQL 풀에서 사용할 수 있지만 서버리스 SQL 풀에서는 사용할 수 없습니다.
- CSV 및 Parquet과 같은 다양한 데이터 형식의 데이터를 읽고 내보낼 수 있는 네이티브 외부 테이블 네이티브 외부 테이블은 서버리스 SQL 풀에서 사용할 수 있으며 전용 SQL 풀에서 공개 미리 보기로 제공됩니다. CETAS 및 네이티브 외부 테이블을 사용하여 데이터를 작성/내보내는 작업은 서버리스 SQL 풀에서만 사용할 수 있지만 전용 SQL 풀에서는 사용할 수 없습니다.
Hadoop과 네이티브 외부 테이블의 주요 차이점:
| 외부 테이블 유형 | Hadoop | 기본 |
|---|---|---|
| 전용 SQL 풀 | 사용 가능 | 공개 미리 보기에서는 Parquet 테이블만 사용할 수 있습니다. |
| 서버리스 SQL 풀 | 사용할 수 없음 | 사용 가능 |
| 지원되는 형식 | 구분 기호로 분리됨/CSV, Parquet, ORC, Hive RC 및 RC | 서버리스 SQL 풀: 구분됨/CSV, Parquet 및 Delta Lake 전용 SQL 풀: Parquet(미리 보기) |
| 폴더 파티션 제거 | 아니요 | 파티션 제거는 Apache Spark 풀에서 동기화되는 Parquet 또는 CSV 형식에서 만든 분할된 테이블에서만 사용할 수 있습니다. Parquet 분할 폴더에 외부 테이블을 만들 수 있지만 파티션 제거가 적용되지 않는 동안 분할 열에 액세스할 수 없으며 무시됩니다. Delta Lake 폴더의 외부 테이블은 지원되지 않으므로 만들지 마세요. 분할된 Delta Lake 데이터를 쿼리해야 하는 경우 델타 분할 뷰를 사용합니다. |
| 파일 제거(조건자 푸시다운) | 아니요 | 서버리스 SQL 풀에만 해당. 문자열 푸시다운의 경우 푸시다운을 활성화하려면 VARCHAR 열에서 Latin1_General_100_BIN2_UTF8 데이터 정렬을 사용해야 합니다. 데이터 정렬에 대한 자세한 내용은 Synapse SQL에 지원되는 데이터 정렬 형식을 참조하세요. |
| 위치의 사용자 지정 형식 | 아니요 | 예, Parquet 또는 CSV 형식에 /year=*/month=*/day=*와 같은 와일드카드를 사용합니다. 사용자 지정 폴더 경로는 Delta Lake에서 사용할 수 없습니다. 서버리스 SQL 풀에서 재귀 와일드카드 /logs/**를 사용하여 참조된 폴더 아래의 하위 폴더에 있는 Parquet 또는 CSV 파일을 참조할 수도 있습니다. |
| 재귀 폴더 검색 | 예 | 예. 서버리스 SQL 풀에서는 위치 경로 끝에 /**을 지정해야 합니다. 전용 풀에서 폴더는 항상 재귀적으로 검사됩니다. |
| 스토리지 인증 | SAK(스토리지 액세스 키), Microsoft Entra 통과, 관리 ID, 사용자 지정 애플리케이션 Microsoft Entra ID | SAS(공유 액세스 서명), Microsoft Entra 통과, 관리 ID, 사용자 지정 애플리케이션 Microsoft Entra ID. |
| 열 매핑 | 서수 - 외부 테이블 정의의 열은 위치별로 기본 Parquet 파일의 열에 매핑됩니다. | 서버리스 풀: 이름별. 외부 테이블 정의의 열은 열 이름 일치를 통해 기본 Parquet 파일의 열에 매핑됩니다. 전용 풀: 서수 일치. 외부 테이블 정의의 열은 위치별로 기본 Parquet 파일의 열에 매핑됩니다. |
| CETAS(내보내기/변환) | 예 | 네이티브 테이블을 대상으로 하는 CETAS는 서버리스 SQL 풀에서만 작동합니다. 전용 SQL 풀을 사용하여 네이티브 테이블을 사용하여 데이터를 내보낼 수 없습니다. |
참고 항목
네이티브 외부 테이블은 일반적으로 사용할 수 있는 풀에서 권장되는 솔루션입니다. 외부 데이터에 액세스해야 하는 경우 항상 서버리스 풀의 네이티브 테이블을 사용합니다. 전용 풀에서는 Parquet 파일이 GA에 있으면 읽을 수 있도록 네이티브 테이블로 전환해야 합니다. 네이티브 외부 테이블(예: ORC, RC)에서 지원되지 않는 일부 형식에 액세스해야 하거나 네이티브 버전을 사용할 수 없는 경우에만 Hadoop 테이블을 사용합니다.
전용 SQL 풀 및 서버리스 SQL 풀의 외부 테이블
외부 테이블을 사용하면 다음 작업을 수행할 수 있습니다.
- Transact-SQL 문을 사용하여 Azure Blob Storage 및 Azure Data Lake Gen2를 쿼리합니다.
- CETAS를 사용하여 쿼리 결과를 Azure Blob Storage 또는 Azure Data Lake Storage의 파일에 저장합니다.
- Azure Blob Storage 및 Azure Data Lake Storage에서 데이터를 가져와서 전용 SQL 풀(전용 풀의 Hadoop 테이블에만)에 저장합니다.
참고 항목
CREATE TABLE AS SELECT 문과 함께 사용할 경우 외부 테이블에서 선택하면 데이터를 전용 SQL 풀 내의 테이블로 가져옵니다.
전용 풀에 있는 Hadoop 외부 테이블의 성능이 성능 목표를 충족하지 않는 경우 COPY 문을 사용하여 외부 데이터를 Datawarehouse 테이블에 로드하는 것이 좋습니다.
로드 자습서는 PolyBase를 사용하여 Azure Blob Storage에서 데이터 로드를 참조하세요.
다음 단계를 통해 Synapse SQL 풀에 외부 테이블을 만들 수 있습니다.
- 외부 데이터 원본 만들기 - 외부 Azure Storage를 참조하고, 스토리지에 액세스할 때 사용해야 하는 자격 증명을 지정합니다.
- 외부 파일 형식 만들기 - CSV 또는 Parquet 파일의 형식을 설명합니다.
- 외부 테이블 만들기 - 데이터 원본에 배치된 파일을 기반으로 동일한 파일 형식을 사용하여 만듭니다.
폴더 파티션 제거
Synapse 풀의 네이티브 외부 테이블은 쿼리와 관련이 없는 폴더에 배치된 파일을 무시할 수 있습니다. 파일이 폴더 계층 구조(예: /year=2020/month=03/day=16)에 저장되고 year, month 및 day 값이 열로 노출되는 경우 year=2020과 같은 필터가 포함된 쿼리는 year=2020 폴더 내에 배치된 하위 폴더에서만 파일을 읽습니다. 다른 폴더(year=2021 또는 year=2022)에 배치된 파일 및 폴더는 이 쿼리에서 무시됩니다. 이 제거를 파티션 제거라고 합니다.
폴더 파티션 제거는 Synapse Spark 풀에서 동기화되는 네이티브 외부 테이블에서 사용할 수 있습니다. 분할된 데이터 세트가 있고 사용자가 만든 외부 테이블로 파티션 제거를 활용하려는 경우 외부 테이블 대신 파티션된 뷰를 사용합니다.
파일 제거
Parquet 및 Delta와 같은 일부 데이터 형식에는 각 열에 대한 파일 통계(예: 각 열의 최소/최댓값)가 포함됩니다. 데이터를 필터링하는 쿼리는 필요한 열 값이 없는 파일을 읽지 않습니다. 쿼리는 먼저 쿼리 조건자에서 사용되는 열의 최소/최댓값을 탐색하여 필수 데이터가 포함되지 않은 파일을 찾습니다. 이러한 파일은 무시되고 쿼리 계획에서 제거됩니다.
이 기술을 필터 조건자 푸시다운이라고도 하며 쿼리의 성능을 향상시킬 수 있습니다. 필터 푸시다운은 Parquet 및 Delta 형식의 서버리스 SQL 풀에서 사용할 수 있습니다. 문자열 형식에 대한 필터 푸시다운을 활용하려면 Latin1_General_100_BIN2_UTF8 데이터 정렬과 함께 VARCHAR 형식을 사용합니다. 데이터 정렬에 대한 자세한 내용은 Synapse SQL에 지원되는 데이터 정렬 형식을 참조하세요.
보안
사용자가 데이터를 읽으려면 외부 테이블에 대해 SELECT 권한이 있어야 합니다.
다음 규칙을 사용하여 데이터 원본에 정의된 데이터베이스 범위의 자격 증명을 사용하는 기본 Azure Storage에 대한 외부 테이블 액세스:
- 자격 증명이 없는 데이터 원본의 경우 외부 테이블이 Azure Storage에서 공개적으로 사용 가능한 파일에 액세스할 수 있습니다.
- 데이터 원본에는 외부 테이블이 SAS 토큰 또는 작업 영역 관리 ID를 사용해서 Azure Storage에 있는 파일만 액세스하도록 설정하는 자격 증명이 포함되어 있습니다. 예를 들어 스토리지 파일 개발 스토리지 액세스 제어 문서를 참조하세요.
CREATE EXTERNAL DATA SOURCE 예제
다음 예제에서는 뉴욕 데이터 세트를 가리키는 Azure Data Lake Gen2에 대한 Hadoop 외부 데이터 원본을 전용 SQL 풀에 만듭니다.
CREATE DATABASE SCOPED CREDENTIAL [ADLS_credential]
WITH IDENTITY='SHARED ACCESS SIGNATURE',
SECRET = 'sv=2018-03-28&ss=bf&srt=sco&sp=rl&st=2019-10-14T12%3A10%3A25Z&se=2061-12-31T12%3A10%3A00Z&sig=KlSU2ullCscyTS0An0nozEpo4tO5JAgGBvw%2FJX2lguw%3D'
GO
CREATE EXTERNAL DATA SOURCE AzureDataLakeStore
WITH
-- Please note the abfss endpoint when your account has secure transfer enabled
( LOCATION = 'abfss://data@newyorktaxidataset.dfs.core.windows.net' ,
CREDENTIAL = ADLS_credential ,
TYPE = HADOOP
) ;
다음 예제에서는 공개적으로 사용할 수 있는 뉴욕 데이터 세트를 가리키는 Azure Data Lake Gen2에 대한 외부 데이터 원본을 만듭니다.
CREATE EXTERNAL DATA SOURCE YellowTaxi
WITH ( LOCATION = 'https://azureopendatastorage.blob.core.windows.net/nyctlc/yellow/',
TYPE = HADOOP)
CREATE EXTERNAL FILE FORMAT 예제
다음 예제에서는 인구 조사 파일에 대한 외부 파일 형식을 만듭니다.
CREATE EXTERNAL FILE FORMAT census_file_format
WITH
(
FORMAT_TYPE = PARQUET,
DATA_COMPRESSION = 'org.apache.hadoop.io.compress.SnappyCodec'
)
CREATE EXTERNAL TABLE 예제
다음 예제에서는 외부 테이블을 만듭니다. 첫 번째 행을 반환합니다.
CREATE EXTERNAL TABLE census_external_table
(
decennialTime varchar(20),
stateName varchar(100),
countyName varchar(100),
population int,
race varchar(50),
sex varchar(10),
minAge int,
maxAge int
)
WITH (
LOCATION = '/parquet/',
DATA_SOURCE = population_ds,
FILE_FORMAT = census_file_format
)
GO
SELECT TOP 1 * FROM census_external_table
Azure Data Lake의 파일에서 외부 테이블 만들기 및 쿼리
이제 Synapse Studio의 Data Lake 검색 기능을 사용하여 마우스 오른쪽 단추로 파일을 간단히 클릭하면 Synapse SQL 풀에서 외부 테이블을 만들고 쿼리할 수 있습니다. ADLS Gen2 스토리지 계정에서 외부 테이블을 만드는 원클릭 제스처는 Parquet 파일에 대해서만 지원됩니다.
필수 조건
ADLS Gen2 계정 또는 ACL(액세스 제어 목록)에서 파일을 쿼리할 수 있는
Storage Blob Data Contributor이상의 액세스 역할을 사용하여 작업 영역에 액세스할 수 있어야 합니다.최소한 Synapse SQL 풀(전용 또는 서버리스)에서 외부 테이블을 쿼리하고 외부 테이블을 만들 수 있는 권한이 있어야 합니다.
[데이터] 패널에서 외부 테이블을 만드는 데 사용할 파일을 선택합니다.
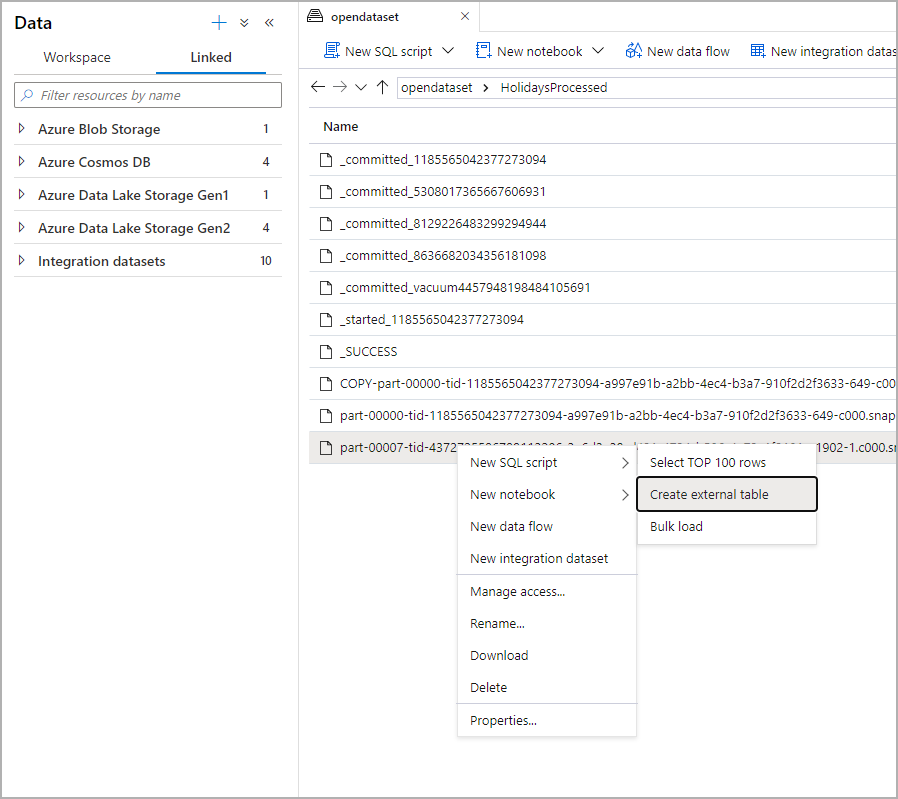
대화 상자 창이 열립니다. 전용 SQL 풀 또는 서버리스 SQL 풀을 선택하고, 테이블에 이름을 지정하고, [스크립트 열기]를 선택합니다.
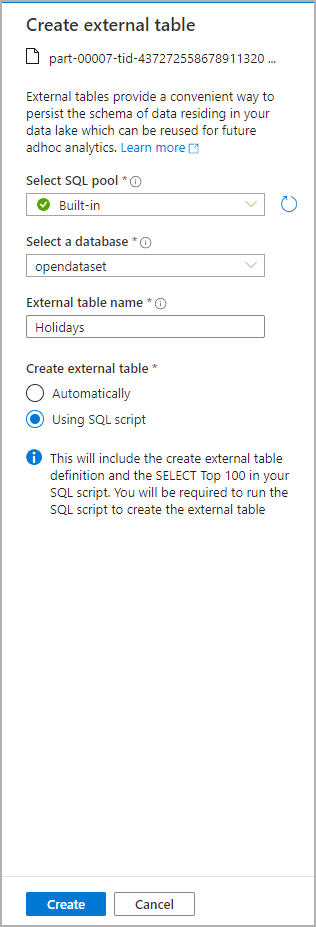
파일에서 스키마를 유추하여 SQL 스크립트가 자동으로 생성됩니다.
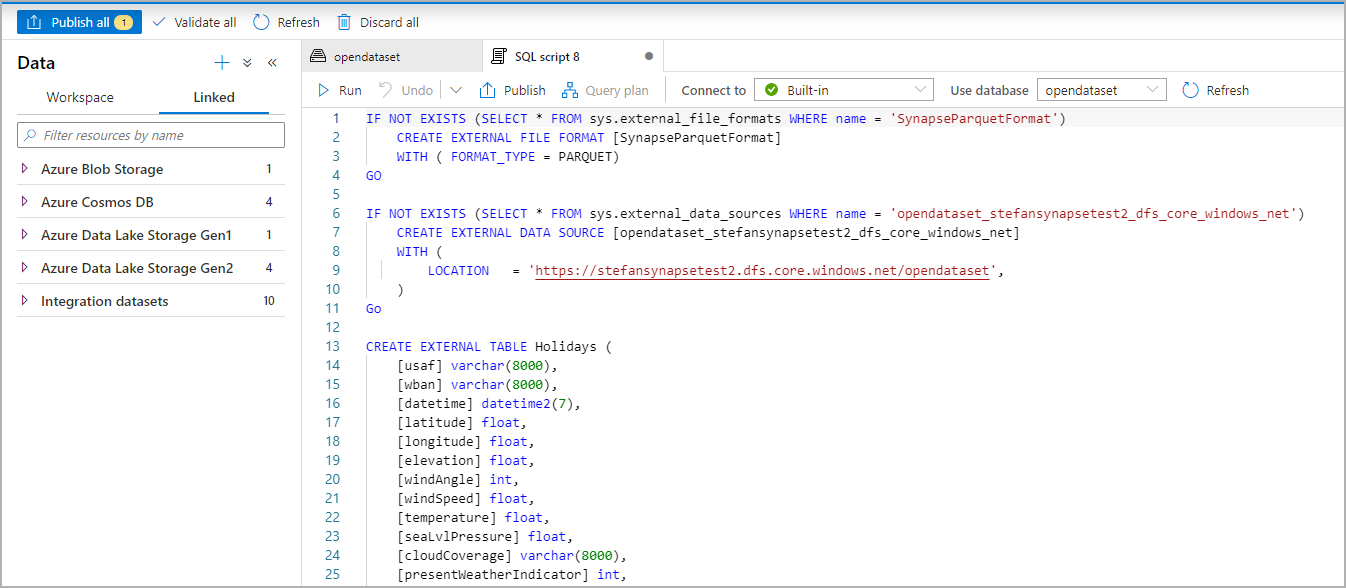
스크립트를 실행합니다. 스크립트에서 Select Top 100 *를 자동으로 실행합니다.
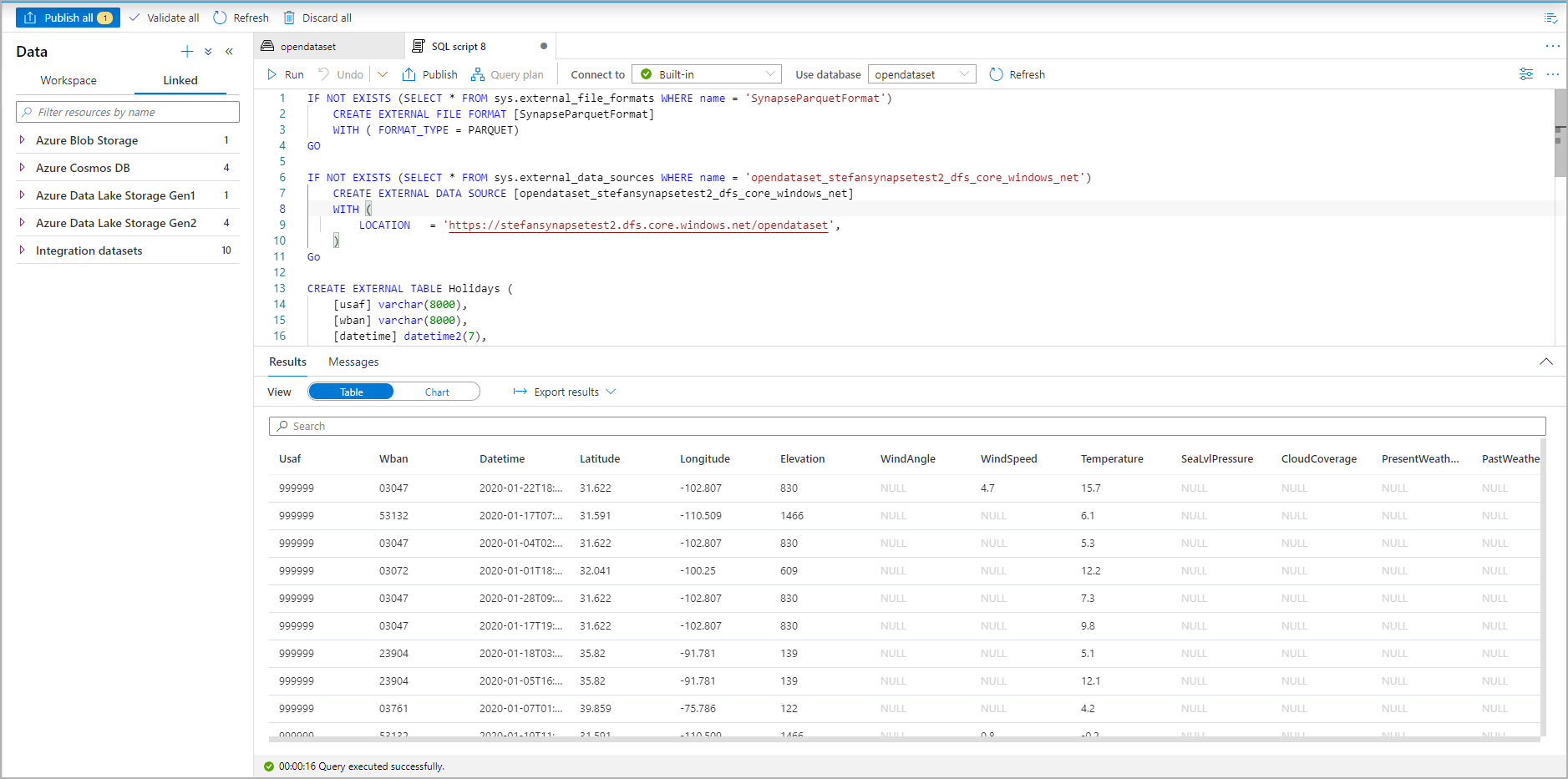
이제 외부 테이블이 만들어집니다. 사용자는 나중에 [데이터] 창에서 직접 쿼리하여 이 외부 테이블의 콘텐츠를 검색할 수 있습니다.

다음 단계
쿼리 결과를 Azure Storage의 외부 테이블에 저장하는 방법은 CETAS 문서를 확인하세요. 또는 Apache Spark for Azure Synapse 외부 테이블 쿼리를 시작할 수 있습니다.