Cutting Edge
Single-page Interface and AJAX Patterns
Dino Esposito
Code download available at:CuttingEdge2008_05.exe(203 KB)
Contents
Impact of the AJAX Paradigm
Single-Page Interface Model
Drawbacks of the Single-Page Interface Model
Accessibile Rich Internet Apps
A Brief Tour of AJAX Patterns
The Unique URL Pattern
The Timeout Pattern
Compared to the development paradigm under which the vast majority of today's Web applications have been built, AJAX represents a paradigm shift for architects of Web solutions. It leans on a few new principles and rules to explain the behavior of a Web-based system and requires some new algorithms to implement them.
The main principle behind AJAX is that you send plain data to the Web server and receive more plain data.
The second AJAX principle is that you orchestrate operations on your own, thus bypassing the host browser and its single page request/response mechanics.
The third AJAX principle is that the client code is fully responsible for updating the user interface using the plain data it receives from the server.
This column will lay out the foundation for developers ready to completely move away from the defensive AJAX implementation represented by partial rendering. Partial rendering is a way to have some AJAX functionality while still staying rooted in a Web Forms architecture. The AJAX paradigm is based on new principles that require new design patterns.
Impact of the AJAX Paradigm
ASP.NET partial rendering is a clever addition that sits on top of the classic Web Forms postback model. In a nutshell, a page using partial rendering has the same postback architecture and page lifecycle as that which occurs in a non-AJAX page (see Figure 1). The difference, then, lies in a client-side interceptor that simply prevents the browser's default action—the form submission—and replaces it with an XMLHttpRequest-led HTTP request (see Figure 2). This trick saves the user a full page refresh while saving developers hours of training on a new architecture and new patterns.
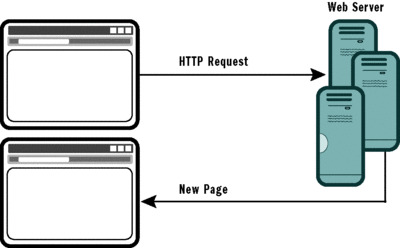
Figure 1** Traditional Full-Page Postback Operation **
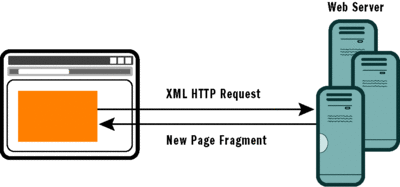
Figure 2** AJAX XMLHttpRequest Partial Rendering **
It goes without saying that partial rendering offers graphical benefits within the context of the current page. If your application is designed around a collection of individual pages, however, a transition from one page to the next still requires a full page load. Partial rendering is excellent at replacing intra-page postbacks, such as paging a grid, adjusting the user interface after a selection change, or editing a record in-place.
Because partial rendering is just a smarter form of a page postback, it has the same architectural limitations of the Web Forms model. For example, you can have just one pending request per browser window. Under the current model for Web apps—submit a form, get a new page—this limitation may not be much of an issue.
However, once you broaden your horizon with AJAX, it starts becoming normal to expect that a user can execute multiple activities at the same time. With partial rendering alone, it's impossible for a user to have two asynchronous operations execute simultaneously and have both complete.
Partial rendering is limited to one request operation at a time in order to preserve the consistency of the view state—which remains an integral part of the model. And this goes against the first A in AJAX: asynchronous. With partial rendering, out-of-band, JavaScript-driven postbacks are possible, but only one at a time. If a second operation is triggered before the previous one has completed, the pending operation is aborted so that the new operation can proceed. This last-win discipline can be altered programmatically to a first-win model where the current operation is kept active and the new one swallowed by the system—but still, the fact remains that only one operation is possible at a time.
Single-Page Interface Model
To take full advantage of AJAX, you need to have all of your features, or at least most of them, in a single page. This is known as the Single-Page Interface (SPI) model. In the SPI model, all browser interactions with a Web application take place within the boundaries of just one page. This approach is revolutionary for the Web, but it is nothing new for Windows® and desktop development. In the end, the SPI model is just like having a Windows application with a main (and unique) window.
In the SPI model, the main page is a combination of visual elements that can be loaded, updated, and replaced independently (see Figure 3). In this way, the entire page doesn't have to be reloaded following a user action. At any time, only visual elements and content that is relevant to the current stage of the application is displayed. Everything else is hidden; it will show up as soon as there's any need for it in the application's flow.
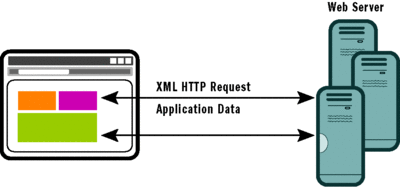
Figure 3** Single-Page Interface Elements within a Page **
The SPI model naturally enables a number of highly interactive features, which include in-place editing, context-sensitive user interface, immediate user feedback prompts, and asynchronous operations. But more than performance or responsiveness, the primary benefit of the SPI model is the significant improvement it offers in the user experience.
Even with these many benefits, though, you should know that designing a new application with the SPI model in mind is challenging, as no established set of patterns and best practices exists. In the end, there's an easy way to employ AJAX that fits a large number of companies and situations. And there's a not-so-easy way to employ AJAX that is taking root, too.
For building pure AJAX apps, you need a good library of user interface widgets to provide effects and special behaviors. You need a rich and customizable document object model (DOM) that uses the standard World Wide Web Consortium (W3C) DOM as its underlying engine but allows you to define your own application-specific model. And finally, you need a server and client framework for developing user interface and codebehind scripts easily and effectively. Ideally, you'll also have tools to debug and test all of this.
Microsoft and other vendors are providing some of these bits and pieces. You have a number of UI widget libraries to choose from and you have vendors that are producing controls that define their own client-side object models. What would really help is an improved AJAX framework specifically designed as an alternative to Web Forms and inspired by the SPI model.
One such alternate programming model is the Model View Controller (MVC) Framework found in the ASP.NET 3.5 Extensions library. In its current form, though, it doesn't have too much to share with AJAX, and while it doesn't prevent the implementation of any AJAX feature, it doesn't seem to have been designed to evolve into an SPI model, either. Time will tell, however.
In the SPI model, the main page points to HTTP endpoints in the same application. It executes remote code but doesn't reload the full page. And it updates the user interface using controls that emit both HTML and script. And these controls could be intelligent enough to generate much of the JavaScript code they require. For example, imagine a form used to book a flight, with two possible parameters for the search: time or cost. If the user is more interested in the cheapest flight, you have no need to display the dropdown list with hours. If the user needs to fly at an exact time, you must bring up the HTML that displays hours.
Clearly, this show/hide trick can be easily accomplished with a bit of JavaScript. Today, though, the page developer is responsible for writing this code. Controls such as the CollapsiblePanel control from the ASP.NET AJAX Control Toolkit (https://www.asp.net/web-forms/tutorials/ajax-control-toolkit/collapsiblepanel/collapsing-and-expanding-a-panel-from-javascript-cs) can also aid in accomplishing this.
Drawbacks of the Single-Page Interface Model
While it yields a more interactive user experience, the SPI model, and the whole AJAX paradigm it embodies, raises a number of issues such as searchability, history management, accessibility, and offline support. For years, Web pages have been tracked using permanent links. Search engines built their business by just mapping a set of keywords to one or more URLs. This model worked based on the assumption that each state in a Web application corresponds to a page and a distinct URL.
With the SPI model in AJAX, this assumption is no longer valid. If everything (or most of it) happens within the same page, there's no URL transition to mark a different state and different site content. Subsequently, there's no easy way to associate content (and keywords) with unique URLs. This aspect of the SPI model affects searchability as well as history management (such as the ability to use Back and Forward buttons).
Browser history may ultimately become an outmoded concept, tightly bound to the classic, static Web model. Nonetheless, you must keep in mind that users are so familiar with these buttons that simply disabling them is not a viable option.
Accessibility is another big issue with AJAX applications. Most popular screen-readers have great difficulty with any content generated via DOM scripting. By design, all forms of AJAX (including partial rendering) are heavily based on DOM scripting. Subsequently, you will need to address accessibility through other avenues.
Section 508 of the paper on the Web Content Accessibility Guidelines (WCAG) recommends that pages provide alternate functional text that can be read by assistive technology whenever they utilize scripting languages to display content or to create visual elements. The <noscript> tag exists to comply with this recommendation. Currently, the majority of AJAX frameworks make their dynamic updates within the page without updating static information contained in <noscript> tags.
Accessibile Rich Internet Apps
The problem seems to be twofold and involves both AJAX applications and the technology behind screen readers. On the one hand, you have screen readers that understand some client events such as onclick, keypress, and readystatechange. Awareness of these events in a screen reader might be sufficient to add at least a first layer of accessibility to a large number of AJAX-based applications.
On the other hand, screen readers don't usually speak any new information if they have proceeded beyond the initial page load event in the DOM. But there are some tricks you can use to let the screen reader know that something has changed. One of the most effective involves setting tabindex to -1 on the root of the updated DOM tree. It's a mere trick, though, and accessibility deserves a broader AJAX solution.
A possible solution is the new standard being developed at W3C, called Accessible Rich Internet Applications (ARIA), that mainly consists of reader-specific extensions to HTML tags. A few popular client-side AJAX libraries already support some ARIA features. More generally, though, the problem is not just with the availability of an AJAX-compliant standard for accessibility. The problem is also, if not especially, with the contents (both markup and script) that server controls actually emit.
And what about offline applications? Many developers think that offline AJAX applications are not possible because AJAX applications are still strictly Internet-based. In my opinion, this statement is a bit too simplistic, but it's not entirely false. Today nearly all Web applications—AJAX and non-AJAX—are Internet- or intranet-based.
But non-AJAX applications are definitely able to work offline. In the case of history management, for instance, the magic of enabling offline navigation is all in the browser. In a classic Web application, each HTTP request is managed by the browser. When no connection is available (and before firing an HTTP 404 error), the browser looks in its local cache of pages.
An AJAX application differs from a classic Web application in that it uses the XMLHttpRequest object instead of the browser engine to send HTTP requests. For AJAX applications to support offline scenarios, you only need to endow the XMLHttpRequest object with either access to the browser's cache or the ability to create and manage its own cache of visited pages. Some AJAX frameworks are starting to include this capability. It's not trivial, though, because it involves disk access from within JavaScript code.
A Brief Tour of AJAX Patterns
The next evolution of Web-based applications leads straight to AJAX and, more generally, Rich Internet Applications (RIA). Initially leading this next evolution are three main categories of applications: classic HTML-based sites, mashups built to integrate multiple systems in a single Web-based front end, and thick clients.
For the first category, partial user interface loading (partial rendering) represents the easy way to implement AJAX with limited impact on existing code and skills.
The concept of a mashup, on the other hand, does not necessarily lend itself to AJAX and improved user interaction. It is merely a way to collect data from a variety of sources and put that together into a coherent and cohesive user interface. This can also happen in a classic server-to-server scenario. However, AJAX makes it simpler and, frankly, cooler. From an AJAX perspective, a mashup application needs standard data serialization formats (syndication), a lightweight framework for calling remote services via script, an updatable DOM, and maybe a few rich visual controls with a convenient programming model.
Building thick clients with AJAX is the biggest challenge. A thick client can be the front end of a distributed enterprise system or perhaps the presentation layer of a line-of-business application. It can also be a standalone application that the IT department decided to expose as a Web application. These applications, whether published to the Internet or restricted to an intranet, need the richness and speed of a regular desktop UI.
Compared to Windows development, the Web is a step backward in terms of interactivity and responsiveness. With AJAX, you finally have the tools (and environmental conditions) to evolve toward a substantially different model. But there is a significant trade-off. On the one hand, you have millions of users and developers accustomed to the old Web and its paradigm of history, offline navigation, favorites, single operations, page transitions, and permanent links. On the other hand, you have AJAX and its paradigm of simultaneous operations and a single auto-updating user interface. In this case, for user tasks, the AJAX model requires a true undo model as opposed to simply using the browser's history and page navigation features.
To code against the SPI model, a new set of design patterns is necessary. Figure 4 lists some of the most popular AJAX patterns. As you can see, most of them are focused on user interface techniques and arrangements, though you should note that the list doesn't include some popular AJAX patterns and practices that are already implemented in the Microsoft® AJAX Client Library. For example, you don't need an AJAX stub, a cross-browser JavaScript model, or a call-tracking model if you use ASP.NET AJAX—all these features are available out of the box.
Figure 4 Some AJAX Patterns
| Pattern | Goal |
|---|---|
| Browser-Side Templating | The pattern suggests using HTML templates that will be fleshed out dynamically with data retrieved from remote HTTP endpoints. Instead of regenerating the HTML layout for the data on the fly and on a per-request basis, the pattern suggests that you set up your own template layer. This pattern represents an alternative to the HTML Message pattern. |
| Cross-Domain Proxy | The pattern operates a server-to-server connection to a reachable and publicly exposed service and carries data back to the client. From the client browser, an AJAX application is not allowed to connect to any URL outside the domain of the page. However, a local proxy located in the same domain can easily grab data from anywhere and flow it back to the caller. |
| Heartbeat | Because most AJAX applications may be doing a lot of work on the client without ever posting back, there might be the need to inform the server that a given client is still active. The pattern suggests that the client application periodically uploads a "heartbeat" message to indicate the application is still loaded and working in the browser. |
| HTML Message | Remote HTTP endpoints normally return JavaScript Object Notation (JSON) data on the client to be integrated in the existing DOM. This task can only be accomplished via JavaScript. However, if the client code is particularly complex, or for performance reasons, you might want to return HTML (data and layout) from the server rather than plain data. |
| Microlink | AJAX is primarily used for doing a lot of activity within the same page. How would you reference external contents, namely the contents that would go to a different page in a classic Web application? You need a sort of in-page hyperlink, or a microlink. The microlink is a reference to a chunk of markup that gets retrieved via server calls and then inserted in the page. A microlink can be an HTTP endpoint or perhaps a method on a JavaScript command object. |
| On-Demand JavaScript | This is the JavaScript counterpart of the popular lazy loading pattern often used in a data access layer. Downloading all the required JavaScript during page initialization may have a performance impact and slows down the whole process. By loading JavaScript files on a per-request basis, you give your pages a much faster load without affecting functionality. |
| Page Arrangement | Because most of the application's activity takes place in the same page, you need to update the page's content and present new information as the context changes. This pattern simply suggests that you use the DOM to add/remove or show/hide elements to reflect state transitions. |
| Periodic Refresh | The browser periodically schedules a request to gain new and up-to-date information to refresh the user interface. |
| Popup | The pattern represents the Web version of modal/modeless Windows dialog boxes. A popup consists of a some HTML content displayed in front of the existing content for a relatively short period of time or until the user dismisses it. |
| Predictive Fetch | The pattern suggests anticipating the most likely user actions and fetching the required data beforehand. Implementation of this pattern comes at a cost: it's ultimately a guess, and you may be wrong. While effective for increasing perceived performance, this pattern may also result in a loss of performance if poorly implemented or implemented in a less than ideal scenario due to heavy server bandwidth consumption. |
| Progress Indicator | The pattern used to monitor the progress of server operations. The idea is that the server operation writes its own progress to a shared location that a client-side monitoring service can read in the context of a progress refresh. |
| Submission Throttling | One of the potential drawbacks of AJAX is that too many requests can be generated to the server in a unit of time. If this is the case, there's a clear scalability problem. This pattern suggests that you use a timer to periodically upload data to the server and a local cache or queue to accumulate requests. |
| Timeout | In case of heavyweight operations conducted from the client such as streaming or periodic refresh, there's the problem of ensuring that each connected client is really using the application. This pattern suggests that you time out the heavy operation and resume only if the user explicitly requires that. |
| Unique URLs | The pattern lets you assign distinct URLs to different parts of your application that typically reflect different states. This pattern is commonly used to support history in AJAX applications. |
| Virtual Workspace | The server needs to respond to requests as quickly as possible, but it can't necessarily return all of the data available for bandwidth reasons. This pattern suggests that you build a virtual user interface that transmits the idea that all data is available while only a small fraction of it is really on the client. It is the application's responsibility to download data on demand and cache it locally. |
You should also notice that patterns listed in Figure 4, and AJAX patterns in general, are more reference patterns than design patterns. They point out common ways of doing things, but not all of them are design issues.
In Figure 4, I briefly outlined the gist of each pattern. For the rest of this column, I'm going to drill down into a couple of these patters. In future columns, I'll return to other significant patterns to discuss their driving forces and demonstrate some practical implementations. (A great Web site to learn more about AJAX patterns is ajaxpatterns.org.)
The Unique URL Pattern
URLs are the essence of the Web. Users save URL favorites for future reference, follow URLs to new content experiences, and use URLs to move back to a previous state. With AJAX and the SPI model, an application may accomplish a number of tasks from within a single URL. And this threatens to invalidate a central pillar of the Web experience: that a discrete state of an application is identified by a distinct URL.
Browsers build their own caches of URLs as users navigate. But with AJAX, many operations don't go through the browser and aren't cached in the list of visited URLs from which the Back and Forward menus are driven. On the other hand, client browsers don't expose a programming model for JavaScript code to add URLs to the list. The browser object model only supplies methods to navigate back and forward within the existing list.
The Unique URLs pattern assigns a unique and expressive URL to each significant application state. For example, if the user clicks to edit a value in an AJAX page, a new URL should be added to the browser cache, even though the operation occurred via XMLHttpRequest from within the same page.
You change the URL without reloading the page by using the following JavaScript:
window.location.hash = stateInfo;
The effect of this code is adding a #-prefixed fragment to the URL, as shown here:
https://www.contoso.com/shopping.aspx#edit-1234
Using this pattern, the URL actually changes when you start any given AJAX operation and thus enables changes in the application state to be tracked by the browser.
However, there's more to it than just capturing the URL. When a browser is directed to a hash-based URL, it first loads the main URL and then looks up for a page fragment with the hash name. In an AJAX context, the hash name doesn't point to a real page fragment but instead to application-specific information that represents the current state. For example, edit-1234 may indicate that you were editing an item with an ID of 1234. The actual format is entirely up to you.
If it can't find the proper fragment, the browser just ignores the URL hash. As a result, the user has the page loaded but not necessarily in the expected application state. A second trick is required. You should intercept the page's onload event, parse the URL, extract the hash, and run any JavaScript code that is required to put the page into the desired state, like so:
window.onload = function() {
checkAndParseURL();
}
checkAndParseURL() {
var state = window.location.hash;
restorePage(state);
}
A similar approach is implemented in the history support available with ASP.NET 3.5 Extensions. You can learn more about this at quickstarts.asp.net/3-5-extensions/ajax. The solution in ASP.NET 3.5 Extensions is fully integrated in the framework. You'll see it in the form of new properties and events added to the ScriptManager control. But in the end, it is an implementation of the Unique URLs pattern.
In addition, it should be noted that the trick based on the URL's hash does not work in Internet Explorer® because Internet Explorer doesn't recognized hash changes for URLs, except for inline frames. In fact, all browsers have different peculiarities in the way that they handle fragment navigation (see weblogs.asp.net/bleroy/archive/2007/09/07/how-to-build-a-cross-browser-history-management-system.aspx for more on this topic). The solution in ASP.NET 3.5 Extensions takes care of this difference and qualifies it as a true cross-browser trick.
The Timeout Pattern
One of the biggest benefits of AJAX is the possibility of implementing real-time page updates. However, live updates, if misused, can become a serious danger for the application. Imagine a scenario where the user displays a live page that polls the server every few seconds to update some contents. Assume that the user leaves for hours without shutting down the browser. As a result, the page keeps on sending requests, generating a significant—and useless—workload for the server.
How can you determine whether a client session is timed out? On the server, there's session timeout, but in AJAX there's also the client session that matters. To detect the end of a client session, you need to check whether there was user activity such as clicking and tapping for a given amount of time. Monitoring keyboard and mouse activity might be heavy; a simpler and lighter approach based on timers is generally more effective.
To detect the end of a session based on a timer, set up a client timer that expires after a specified number of seconds (or, more likely, minutes), stops the ongoing task, and pops up an alert box. If the user responds to the prompt, processing resumes as usual.
Figure 5 shows a piece of JavaScript that illustrates the essence of the Timeout pattern. The sample page embeds a clock. The clock is obtained using a Label control in an UpdatePanel that is periodically updated by a Timer control, like so:
Figure 5 Implementing a Client Session Timeout
<script type="text/javascript">
var timer = null;
function pageLoad()
{
if (timer === null)
{
timer = new Samples.TaskTimer(5000, stopTask);
timer.start();
}
}
function pageUnload()
{
if (timer != null)
timer.stop();
}
function stopTask()
{
// Stop the clock
var clock = $find("<%= Timer1.ClientID%>");
clock._stopTimer();
AskIfTheUserWantsToContinue();
}
function AskIfTheUserWantsToContinue()
{
// Ask if the user wants to continue
var answer = window.confirm(
"Is it OK to continue with the clock?");
if (answer)
{
// Restart the task
var clock = $find("<%= Timer1.ClientID%>");
clock._startTimer();
// Restart our own timeout engine
if (timer !== null)
timer.start();
return;
}
}
</script>
protected void Timer1_Tick(object sender, EventArgs e)
{
Label1.Text = DateTime.Now.ToLongTimeString();
}
The clock represents a heavy task that could flood the server with requests. The idea is to set up a timer that periodically asks the user if he really wants to continue with the clock. The timeout code first stops the clock and then displays the message box. Based on the user's response, the clock is restarted.
The code utilizes the $find function to locate an ASP.NET AJAX component—in this case, it happens to be the client object model of the ASP.NET Timer server control. Figure 6 shows the page in action with a popup asking the user if it's OK to continue.
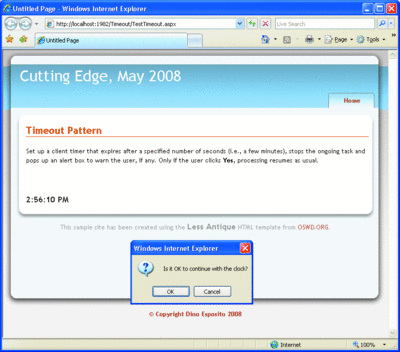
Figure 6** Asking the User Whether to Continue **
Send your questions and comments for Dino to cutting@microsoft.com.
Dino Esposito is the author of Programming ASP.NET 3.5 Core References. Based in Italy, Dino is a frequent speaker at industry events worldwide. You can join his blog at weblogs.asp.net/despos.