데이터 스토리지 옵션(Azure를 사용하여 Real-World Cloud Apps 빌드)
작성자 : Rick Anderson, Tom Dykstra
Azure 전자책 을 사용하여 Real World Cloud Apps 빌드 는 Scott Guthrie가 개발한 프레젠테이션을 기반으로 합니다. 클라우드용 웹앱을 성공적으로 개발하는 데 도움이 될 수 있는 13개의 패턴과 사례를 설명합니다. 전자책에 대한 자세한 내용은 첫 번째 장을 참조하세요.
대부분의 사용자는 관계형 데이터베이스에 사용되며 클라우드 앱을 디자인할 때 다른 데이터 스토리지 옵션을 간과하는 경향이 있습니다. NoSQL(비관계형) 데이터베이스는 관계형 데이터베이스보다 일부 작업을 더 효율적으로 처리할 수 있으므로 그 결과는 최적이 아닌 성능, 높은 비용 또는 더 나빠질 수 있습니다. 고객이 중요한 데이터 스토리지 문제를 해결하는 데 도움을 요청할 때 NoSQL 옵션 중 하나가 더 잘 작동했을 관계형 데이터베이스가 있기 때문입니다. 이러한 상황에서 고객이 앱을 프로덕션에 배포하기 전에 NoSQL 솔루션을 구현했다면 더 좋았을 것입니다.
반면에 NoSQL 데이터베이스가 모든 작업을 잘 또는 충분히 수행할 수 있다고 가정하는 것도 실수입니다. 모든 데이터 스토리지 작업에 가장 적합한 단일 데이터 관리 선택은 없습니다. 다양한 데이터 관리 솔루션은 다양한 작업에 최적화되어 있습니다. 대부분의 실제 클라우드 앱에는 다양한 데이터 스토리지 요구 사항이 있으며 여러 데이터 스토리지 솔루션의 조합으로 가장 잘 제공되는 경우가 많습니다.
이 장에서는 클라우드 앱에서 사용할 수 있는 데이터 스토리지 옵션을 보다 광범위하게 파악하고 시나리오에 맞는 옵션을 선택하는 방법에 대한 몇 가지 기본 지침을 제공합니다. 애플리케이션을 개발하기 전에 사용할 수 있는 옵션을 알고 장점과 약점을 생각하는 것이 가장 좋습니다. 비행기가 비행하는 동안 제트 엔진을 변경해야 하는 것과 같이 프로덕션 앱에서 데이터 스토리지 옵션을 변경하는 것은 매우 어려울 수 있습니다.
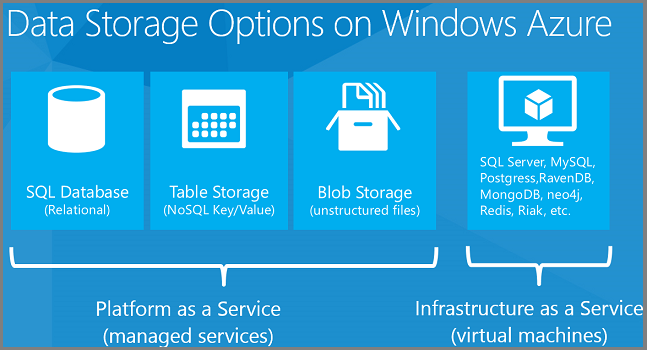
Azure의 데이터 스토리지 옵션
클라우드를 사용하면 다양한 관계형 및 NoSQL 데이터 저장소를 비교적 쉽게 사용할 수 있습니다. 다음은 Azure에서 사용할 수 있는 몇 가지 데이터 스토리지 플랫폼입니다.
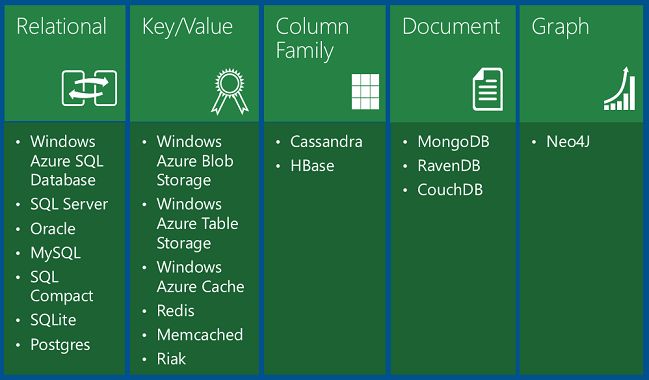
표에는 다음과 같은 네 가지 유형의 NoSQL 데이터베이스가 표시됩니다.
키/값 데이터베이스는 각 키 값에 대해 직렬화된 단일 개체를 저장합니다. 이 데이터베이스는 지정된 키 값에 대해 하나의 항목을 가져오려고 하며 항목의 다른 속성을 기준으로 쿼리할 필요가 없는 경우에 대용량의 데이터를 저장하는 데 좋습니다.
Azure Blob Storage 는 폴더 및 파일 이름에 해당하는 키 값을 사용하여 클라우드의 파일 스토리지와 같은 기능을 하는 키/값 데이터베이스입니다. 파일 내용에서 값을 검색하지 않고 폴더 및 파일 이름으로 파일을 검색합니다.
Azure Table Storage 는 키/값 데이터베이스이기도 합니다. 각 값은 엔터티 (파티션 키 및 행 키로 식별되는 행과 유사)라고 하며 여러 속성을 포함합니다(열과 유사하지만 테이블의 모든 엔터티가 동일한 열을 공유해야 하는 것은 아님). 키가 아닌 열에 대한 쿼리는 매우 비효율적이므로 피해야 합니다. 예를 들어 단일 사용자에 대한 정보를 저장하는 하나의 파티션을 사용하여 사용자 프로필 데이터를 저장할 수 있습니다. 사용자 이름, 암호 해시, 생년월일 등의 데이터를 하나의 엔터티의 별도 속성이나 동일한 파티션의 별도 엔터티에 저장할 수 있습니다. 그러나 지정된 생년월일 범위의 모든 사용자를 쿼리하고 싶지는 않으며 프로필 테이블과 다른 테이블 간에 조인 쿼리를 실행할 수 없습니다. Table Storage는 관계형 데이터베이스보다 확장성이 높고 비용이 적게 들지만 복잡한 쿼리 또는 조인을 사용하도록 설정하지는 않습니다.
Documentdatabases 는 값이 문서인 키/값 데이터베이스입니다. 여기서 "문서"는 Word 또는 Excel 문서의 의미에서 사용되지 않지만 명명된 필드와 값의 컬렉션을 의미하며, 이 컬렉션은 자식 문서일 수 있습니다. 예를 들어 주문 기록 테이블에서 주문 문서에는 주문 번호, 주문 날짜 및 고객 필드가 있을 수 있습니다. 고객 필드에 이름 및 주소 필드가 있을 수 있습니다. 데이터베이스는 XML, YAML, JSON 또는 BSON과 같은 형식으로 필드 데이터를 인코딩합니다. 또는 일반 텍스트를 사용할 수 있습니다. 키/값 데이터베이스와 별도로 문서 데이터베이스를 설정하는 한 가지 기능은 키가 아닌 필드를 쿼리하고 보조 인덱스를 정의하여 쿼리를 보다 효율적으로 만드는 기능입니다. 이 기능을 사용하면 문서 데이터베이스가 문서 키 값보다 조건에 따라 데이터를 검색해야 하는 애플리케이션에 더 적합합니다. 예를 들어 판매 주문 기록 문서 데이터베이스에서 제품 ID, 고객 ID, 고객 이름 등과 같은 다양한 필드를 쿼리할 수 있습니다. MongoDB 는 널리 사용되는 문서 데이터베이스입니다.
열 패밀리 데이터베이스는 데이터 스토리지를 열 패밀리라는 관련 열의 컬렉션으로 구조화할 수 있는 키/값 데이터 저장소입니다. 예를 들어 인구 조사 데이터베이스에는 사람의 이름에 대한 하나의 열 그룹(첫 번째, 중간, 마지막), 해당 사용자의 주소에 대한 하나의 그룹 및 해당 사용자의 프로필 정보(DOB, 성별 등)에 대한 하나의 그룹이 있을 수 있습니다. 그런 다음 데이터베이스는 동일한 키와 관련된 한 사람의 모든 데이터를 유지하면서 각 열 패밀리를 별도의 파티션에 저장할 수 있습니다. 그런 다음 모든 이름 및 주소 정보를 읽지 않고도 모든 프로필 정보를 읽을 수 있습니다. Cassandra 는 인기 있는 열 패밀리 데이터베이스입니다.
그래프 데이터베이스는 정보를 개체 및 관계의 컬렉션으로 저장합니다. 그래프 데이터베이스의 목적은 애플리케이션이 개체 네트워크와 개체 간의 관계를 트래버스하는 쿼리를 효율적으로 수행할 수 있도록 하는 것입니다. 예를 들어 개체는 인적 자원 데이터베이스의 직원일 수 있으며 "Scott에서 직접 또는 간접적으로 일하는 모든 직원 찾기"와 같은 쿼리를 용이하게 할 수 있습니다. Neo4j 는 인기 있는 그래프 데이터베이스입니다.
관계형 데이터베이스에 비해 NoSQL 옵션은 비정형 데이터의 스토리지 및 분석에 훨씬 더 큰 확장성과 비용 효율성을 제공합니다. 단점은 관계형 데이터베이스의 풍부한 쿼리 가능성과 강력한 데이터 무결성 기능을 제공하지 않는다는 것입니다. NoSQL은 조인 쿼리가 필요 없는 대량의 IIS 로그 데이터에 적합합니다. NoSQL은 절대 데이터 무결성이 필요하고 다른 계정 관련 데이터와의 많은 관계를 포함하는 은행 거래에는 잘 작동하지 않습니다.
NoSQL 데이터베이스의 확장성과 관계형 데이터베이스의 쿼리 가능성 및 트랜잭션 무결성을 결합하는 NewSQL 이라는 최신 데이터베이스 플랫폼 범주도 있습니다. NewSQL 데이터베이스는 "OldSQL" 데이터베이스에서 구현하기 어려운 분산 스토리지 및 쿼리 처리를 위해 설계되었습니다. NuoDB 는 Azure에서 사용할 수 있는 NewSQL 데이터베이스의 예입니다.
Hadoop 및 MapReduce
NoSQL 데이터베이스에 저장할 수 있는 대량의 데이터는 적시에 효율적으로 분석하기 어려울 수 있습니다. 이렇게 하려면 MapReduce 기능을 구현하는 Hadoop과 같은 프레임워크를 사용할 수 있습니다. 기본적으로 MapReduce 프로세스에서 수행하는 일은 다음과 같습니다.
- 실제로 분석해야 하는 데이터만 데이터 저장소에서 선택하여 처리해야 하는 데이터의 크기를 제한합니다. 예를 들어 출생 연도별로 사용자 기반의 구성을 알고자 하므로 사용자 프로필 데이터 저장소에서 출생 연도만 선택합니다.
- 데이터를 파트로 분해하고 처리를 위해 다른 컴퓨터로 보냅니다. 컴퓨터 A는 1950-1959 날짜, 컴퓨터 B는 1960-1969 등을 가진 사람들의 수를 계산합니다. 이 컴퓨터 그룹을 Hadoop 클러스터라고 합니다.
- 부품에 대한 처리가 완료된 후 각 파트의 결과를 다시 함께 배치합니다. 이제 각 출생 연도의 사용자 수에 대한 비교적 짧은 목록이 있으며 이 전체 목록에서 백분율을 계산하는 작업은 관리할 수 있습니다.
Azure에서 HDInsight 를 사용하면 Hadoop의 기능을 사용하여 빅 데이터에서 새로운 인사이트를 처리, 분석 및 얻을 수 있습니다. 예를 들어 웹 서버 로그를 분석하는 데 사용할 수 있습니다.
스토리지 계정에 웹 서버 로깅을 사용하도록 설정합니다. 이렇게 하면 애플리케이션에 대한 모든 HTTP 요청에 대한 로그를 Blob Service에 기록하도록 Azure가 설정됩니다. Blob Service는 기본적으로 클라우드 파일 스토리지이며 HDInsight와 원활하게 통합됩니다.
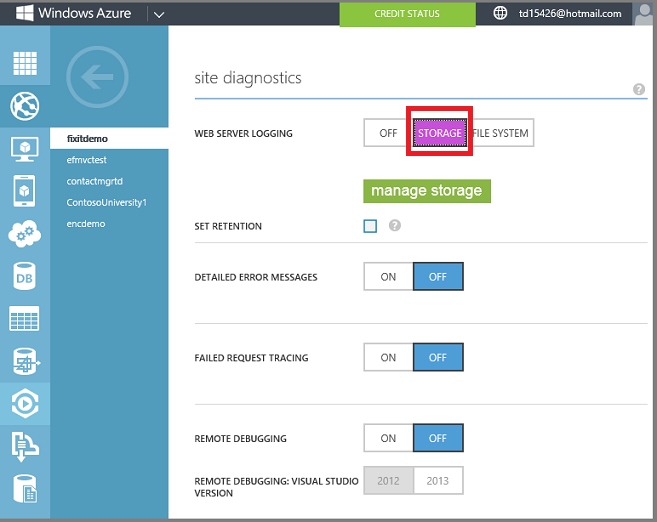
앱이 트래픽을 가져오면 웹 서버 IIS 로그가 Blob Storage에 기록됩니다.
포털에서 새 - Data Services - HDInsight - 빠른 만들기를 클릭하고 HDInsight 클러스터 이름, 클러스터 크기(HDInsight 클러스터 데이터 노드 수) 및 HDInsight 클러스터의 사용자 이름 및 암호를 지정합니다.
이제 MapReduce 작업을 설정하여 로그를 분석하고 다음과 같은 질문에 대한 답변을 얻을 수 있습니다.
- 내 앱이 트래픽을 가장 많이 또는 가장 적게 받는 시간은 하루 중 몇 번인가요?
- 트래픽이 들어오는 국가는 무엇인가요?
- 내 트래픽에서 오는 지역의 평균 이웃 소득은 무엇입니까. (IP 주소별로 이웃 소득을 제공하는 공용 데이터 세트가 있으며 웹 서버 로그의 IP 주소와 일치시킬 수 있습니다.)
- 이웃 소득은 사이트의 특정 페이지 또는 제품과 어떤 관련이 있습니까?
그런 다음 이러한 질문에 대한 답변을 사용하여 고객이 특정 제품에 관심이 있거나 구매할 가능성에 따라 광고를 타겟팅할 수 있습니다.
모든 항목 자동화 챕터에 설명된 대로 포털에서 수행할 수 있는 대부분의 함수를 자동화할 수 있으며, 여기에는 HDInsight 분석 작업 설정 및 실행이 포함됩니다. 일반적인 HDInsight 스크립트에는 다음 단계가 포함될 수 있습니다.
- HDInsight 클러스터를 프로비전하고 Blob Storage 입력을 위해 스토리지 계정에 연결합니다.
- MapReduce 작업 실행 파일(.jar 또는 .exe 파일)을 HDInsight 클러스터에 업로드합니다.
- 출력 데이터를 Blob Storage에 저장하는 MapReduce를 제출합니다.
- 작업이 완료될 때까지 대기합니다.
- HDInsight 클러스터 삭제
- Blob Storage에서 출력에 액세스합니다.
이 모든 작업을 수행하는 스크립트를 실행하면 HDInsight 클러스터가 프로비전되는 시간을 최소화하여 비용을 최소화할 수 있습니다.
PaaS(Platform as a Service) 대 IaaS(Infrastructure as a Service)
앞서 나열된 데이터 스토리지 옵션에는 PaaS(Platform-as-a-Service) 및 IaaS(Infrastructure-as-a-Service) 솔루션이 모두 포함됩니다. PaaS는 하드웨어 및 소프트웨어 인프라를 관리하고 서비스만 사용한다는 것을 의미합니다. SQL Database Azure의 PaaS 기능입니다. 데이터베이스를 요청하고 백그라운드에서 Azure는 VM을 설정 및 구성하고 데이터베이스를 설정합니다. VM에 직접 액세스할 수 없으며 VM을 관리할 필요가 없습니다. IaaS는 데이터 센터 인프라에서 실행되는 VM을 설정, 구성 및 관리하고 원하는 모든 VM을 배치한다는 것을 의미합니다. 일반적인 VM 구성을 위해 미리 구성된 VM 이미지 갤러리를 제공합니다. 예를 들어 Windows Server 2008, Windows Server 2012, BizTalk Server, Oracle WebLogic Server, Oracle Database 등에 대해 미리 구성된 VM 이미지를 설치할 수 있습니다.
Azure에서 제공하는 PaaS 데이터 솔루션은 다음과 같습니다.
- Azure SQL 데이터베이스(이전의 SQL Azure). SQL Server 기반으로 하는 클라우드 관계형 데이터베이스입니다.
- Azure Table Storage 키/값 NoSQL 데이터베이스입니다.
- Azure Blob Storage. 클라우드의 파일 스토리지.
IaaS의 경우 VM에 로드할 수 있는 모든 항목을 실행할 수 있습니다. 예를 들면 다음과 같습니다.
- SQL Server, Oracle, MySQL, SQL Compact, SQLite 또는 Postgres와 같은 관계형 데이터베이스
- Memcached, Redis, Cassandra 및 Riak과 같은 키/값 데이터 저장소입니다.
- HBase와 같은 열 데이터 저장소.
- MongoDB, RavenDB 및 CouchDB와 같은 데이터베이스를 문서화합니다.
- Neo4j와 같은 그래프 데이터베이스.
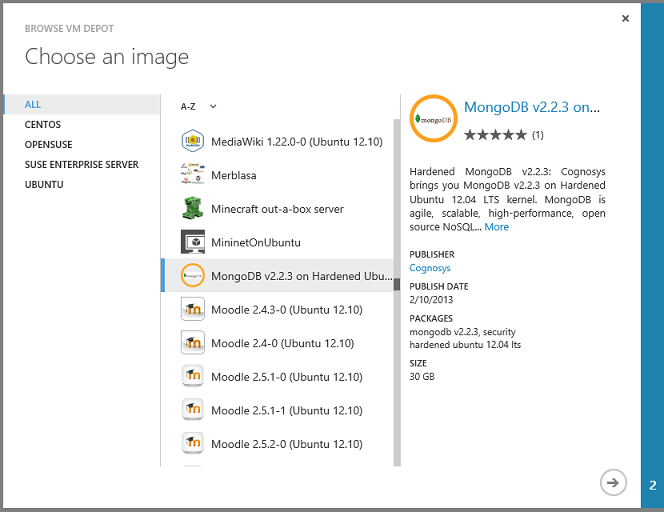
IaaS 옵션은 거의 무제한의 데이터 스토리지 옵션을 제공하며, 미리 구성된 이미지를 사용하여 VM을 만들 수 있으므로 많은 옵션을 사용하기가 특히 쉽습니다. 예를 들어 관리 포털에서 Virtual Machines 이동하여 이미지 탭을 클릭하고 VM 디포 찾아보기를 클릭합니다.

그런 다음 , 미리 구성된 수백 개의 VM 이미지 목록이 표시되고 MongoDB, Neo4J, Redis, Cassandra 또는 CouchDB와 같이 데이터베이스 관리 시스템이 사전 설치된 이미지에서 VM을 만들 수 있습니다.
Azure를 사용하면 IaaS 데이터 스토리지 옵션을 최대한 쉽게 사용할 수 있지만 PaaS 제품에는 많은 시나리오에서 보다 비용 효율적이고 실용적인 많은 이점이 있습니다.
- VM을 만들 필요가 없으며 포털 또는 스크립트를 사용하여 데이터 저장소를 설정하기만 하면 됩니다. 200테라바이트 데이터 저장소를 원하는 경우 단추를 클릭하거나 명령을 실행할 수 있으며 몇 초 안에 사용할 준비가 됩니다.
- 서비스에서 사용하는 VM을 관리하거나 패치할 필요가 없습니다. Microsoft는 자동으로 이를 수행합니다.- 크기 조정 또는 고가용성을 위한 인프라 설정에 대해 걱정할 필요가 없습니다. Microsoft는 모든 작업을 자동으로 처리합니다.
- 라이선스를 구입할 필요가 없습니다. 라이선스 요금은 서비스 요금에 포함됩니다.
- 사용한 양만큼만 요금을 지불합니다.
Azure의 PaaS 데이터 스토리지 옵션에는 타사 공급자의 제품이 포함됩니다.
데이터 스토리지 옵션 선택
모든 시나리오에 적합한 접근 방식은 없습니다. 다른 솔루션이 다양한 항목에 최적화되어 있기 때문에 이 기술이 답이라고 말하는 사람이 있다면 가장 먼저 물어봐야 할 것은 "질문이란?"입니다. 관계형 모델에는 확실한 이점이 있습니다. 그래서 오랫동안 주변을 돌아다녔습니다. 그러나 NoSQL 솔루션으로 해결할 수 있는 SQL에 대한 하위 측면도 있습니다.
단일 솔루션에서 SQL 및 NoSQL을 사용하는 컴퍼지션 접근 방식이 가장 잘 작동하는 경우가 많습니다. 사람들이 NoSQL을 수용하고 있다고 말할 때에도, 그들이 하는 일을 자세히 살펴보면 종종 여러 가지 NoSQL 프레임워크를 사용하고 있다는 것을 알게 됩니다: 그들은 CouchDB를 사용하고, Redis는, 그리고 Riak 은 다른 것들을 위해 사용합니다. NoSQL을 광범위하게 사용하는 Facebook에서도 서비스의 여러 부분에 서로 다른 NoSQL 프레임워크를 사용합니다. 여러 데이터 솔루션을 사용하고 단일 앱에 통합하기 쉽기 때문에 데이터 스토리지 접근 방식을 혼합하고 일치시킬 수 있는 유연성은 클라우드에 좋은 점 중 하나입니다.
다음은 접근 방식을 선택할 때 고려해야 할 몇 가지 질문입니다.
| 데이터 의미 체계 | - 핵심 데이터 스토리지 및 데이터 액세스 의미 체계란 무엇인가요(관계형 또는 비구조적 데이터를 저장하고 있나요). 미디어 파일과 같은 구조화되지 않은 데이터는 Blob Storage에 가장 적합합니다. 제품, 인벤토리, 공급업체, 고객 주문 등과 같은 관련 데이터의 컬렉션은 관계형 데이터베이스에 가장 적합합니다. |
|---|---|
| 쿼리 지원 | - 데이터를 얼마나 쉽게 쿼리할 수 있나요? - 효율적으로 질문할 수 있는 질문 유형은 무엇인가요? 키/값 데이터 저장소는 키 값이 지정된 경우 단일 행을 가져오는 데 매우 능숙하지만 복잡한 쿼리에는 좋지 않습니다. 특정 사용자에 대한 데이터를 항상 가져오는 사용자 프로필 데이터 저장소의 경우 키/값 데이터 저장소가 잘 작동할 수 있습니다. 다양한 제품 특성에 따라 서로 다른 그룹화하려는 제품 카탈로그의 경우 관계형 데이터베이스가 더 잘 작동할 수 있습니다. NoSQL 데이터베이스는 대량의 데이터를 효율적으로 저장할 수 있지만 앱이 데이터를 쿼리하는 방법을 중심으로 데이터베이스를 구성해야 하므로 임시 쿼리를 더 어렵게 만듭니다. 관계형 데이터베이스를 사용하면 거의 모든 종류의 쿼리를 빌드할 수 있습니다. |
| 함수 프로젝션 | - 질문, 집계 등을 서버 쪽에서 실행할 수 있나요? SQL의 테이블에서 SELECT COUNT(*)를 실행하면 서버에서 모든 작업을 매우 효율적으로 수행하고 원하는 번호를 반환합니다. 집계를 지원하지 않는 NoSQL 데이터 저장소에서 동일한 계산을 원하는 경우 이는 비효율적인 "바인딩되지 않은 쿼리"이며 시간이 초과될 수 있습니다. 쿼리가 성공하더라도 서버에서 클라이언트로 모든 데이터를 검색하고 클라이언트의 행 수를 계산해야 합니다. - 사용할 수 있는 식의 언어 또는 형식은 무엇인가요? 관계형 데이터베이스를 사용하면 SQL을 사용할 수 있습니다. Azure Table Storage와 같은 일부 NoSQL 데이터베이스에서는 OData를 사용하고, 기본 키를 필터링하고 프로젝션을 가져오기만 하면 됩니다(사용 가능한 필드의 하위 집합 선택). |
| 확장성 용이성 | - 데이터의 크기를 조정하는 데 필요한 빈도와 크기는 얼마인가요? - 플랫폼이 기본적으로 스케일 아웃을 구현하나요? - 용량(크기 및 처리량)을 얼마나 쉽게 추가/제거할 수 있나요? 관계형 데이터베이스와 테이블은 확장성을 위해 자동으로 분할되지 않으므로 특정 제한을 초과하여 크기를 조정하기가 어렵습니다. Azure Table Storage와 같은 NoSQL 데이터 저장소는 기본적으로 모든 항목을 분할하며 파티션 추가에는 거의 제한이 없습니다. Table Storage를 최대 200테라바이트까지 쉽게 확장할 수 있지만 Azure SQL Database의 최대 데이터베이스 크기는 500기가바이트입니다. 관계형 데이터를 여러 데이터베이스로 분할하여 크기를 조정할 수 있지만 해당 모델을 지원하도록 애플리케이션을 설정하려면 많은 프로그래밍 작업이 필요합니다. |
| 계측 및 관리 효율성 | - 플랫폼은 얼마나 쉽게 계측, 모니터링 및 관리할 수 있나요? 데이터 저장소의 상태 및 성능에 대한 정보를 계속 제공해야 하므로 플랫폼이 무료로 제공하는 메트릭과 직접 개발해야 하는 메트릭을 미리 알아야 합니다. |
| 작업 | - 플랫폼이 Azure에서 얼마나 쉽게 배포하고 실행할 수 있나요? Paas? Iaas? 리눅스? Table Storage 및 SQL Database Azure에서 쉽게 설정할 수 있습니다. 기본 제공 Azure PaaS 솔루션이 아닌 플랫폼에는 더 많은 노력이 필요합니다. |
| API 지원 | - 플랫폼에서 쉽게 작업할 수 있는 API를 사용할 수 있나요? Azure Table Service의 경우 .NET 4.5 비동기 프로그래밍 모델을 지원하는 .NET API가 있는 SDK가 있습니다. .NET 앱을 작성하는 경우 API가 없거나 덜 포괄적인 다른 키/값 열 데이터 저장소 플랫폼에 비해 Azure Table Service에 대한 코드를 작성하고 테스트하는 것이 훨씬 쉽습니다. |
| 트랜잭션 무결성 및 데이터 일관성 | - 데이터 일관성을 보장하기 위해 플랫폼이 트랜잭션을 지원하는 것이 중요합니까? 전송된 대량 전자 메일을 추적하기 위해 데이터 플랫폼의 트랜잭션 또는 참조 무결성에 대한 자동 지원보다 성능 및 낮은 데이터 스토리지 비용이 더 중요할 수 있으므로 Azure Table Service를 선택하는 것이 좋습니다. 은행 계좌 잔액 또는 구매 주문을 추적하는 경우 강력한 트랜잭션 보증을 제공하는 관계형 데이터베이스 플랫폼이 더 나은 선택입니다. |
| 비즈니스 연속성 | - 백업, 복원 및 재해 복구는 얼마나 쉽나요? 조만간 프로덕션 데이터가 손상되고 실행 취소 함수가 필요합니다. 관계형 데이터베이스에는 특정 시점으로 복원하는 기능과 같은 보다 세분화된 복원 기능이 있는 경우가 많습니다. 고려 중인 각 플랫폼에서 사용할 수 있는 복원 기능을 이해하는 것은 고려해야 할 중요한 요소입니다. |
| 비용 | - 둘 이상의 플랫폼이 데이터 워크로드를 지원할 수 있는 경우 비용을 어떻게 비교합니까? 예를 들어 ASP.NET ID를 사용하는 경우 Azure Table Service 또는 Azure SQL Database에 사용자 프로필 데이터를 저장할 수 있습니다. SQL Database 풍부한 쿼리 기능이 필요하지 않은 경우 지정된 양의 스토리지에 대한 비용이 훨씬 적게 들기 때문에 Azure 테이블을 부분적으로 선택할 수 있습니다. |
일반적으로 권장되는 것은 데이터 스토리지 솔루션을 선택하기 전에 이러한 각 범주의 질문에 대한 답변을 아는 것입니다.
또한 워크로드에는 일부 플랫폼이 다른 플랫폼보다 더 잘 지원할 수 있는 특정 요구 사항이 있을 수 있습니다. 예:
- 애플리케이션에 감사 기능이 필요한가요?
- 데이터 수명 요구 사항은 무엇인가요? 자동화된 보관 또는 제거 기능이 필요한가요?
- 특수한 보안 요구 사항이 있나요? 예를 들어 데이터에는 PII(개인 식별 정보)가 포함되지만 PII가 쿼리 결과에서 제외되었는지 확인할 수 있어야 합니다.
- 규정 또는 기술적인 이유로 클라우드에 저장할 수 없는 데이터가 있는 경우 온-프레미스 스토리지와 쉽게 통합할 수 있는 클라우드 데이터 스토리지 플랫폼이 필요할 수 있습니다.
데모 – Azure에서 SQL Database 사용
수정 앱은 관계형 데이터베이스를 사용하여 작업을 저장합니다. 모든 항목 자동화 챕터에 표시된 환경 만들기 Windows PowerShell 스크립트는 두 개의 SQL Database 인스턴스를 만듭니다. SQL Database 탭을 클릭하여 포털에서 이러한 항목을 볼 수 있습니다.
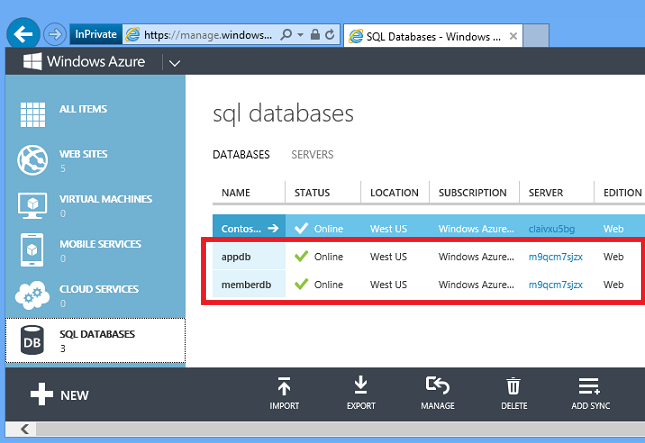
포털을 사용하여 데이터베이스를 쉽게 만들 수도 있습니다.
새로 만들기 -- Data Services -- SQL Database -- Quick 만들기를 클릭하고, 데이터베이스 이름을 입력하고, 계정에 이미 있는 서버를 선택하거나, 새 서버를 만들고, SQL Database 만들기를 클릭합니다.
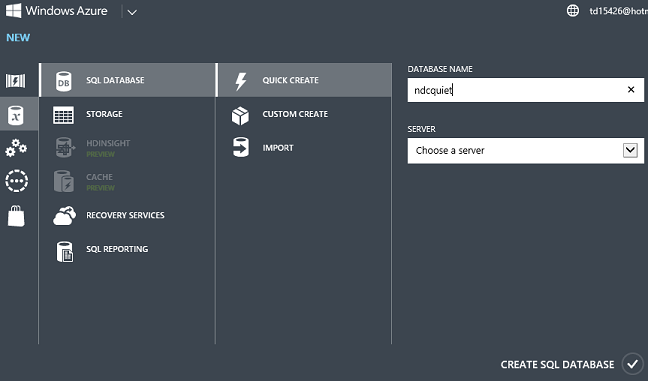
몇 초 정도 기다리면 Azure에 데이터베이스를 사용할 준비가 된 것입니다.
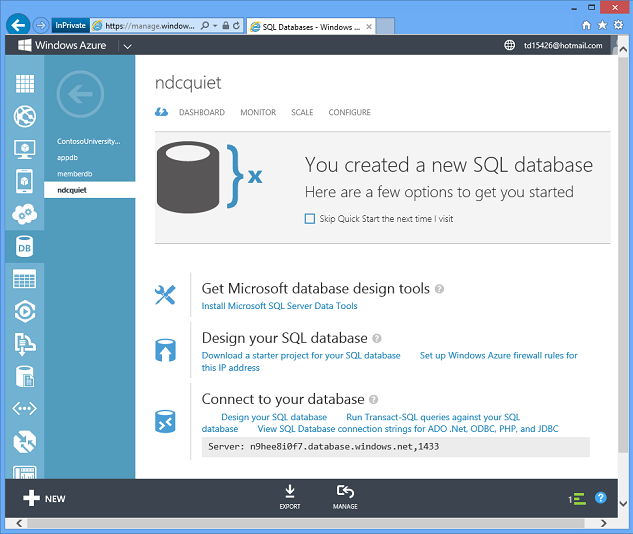
따라서 Azure는 온-프레미스 환경에서 수행하는 데 하루 또는 일주일 이상이 걸릴 수 있는 작업을 몇 초 안에 수행합니다. 또한 스크립트에서 또는 관리 API를 사용하여 자동으로 데이터베이스를 쉽게 만들 수 있으므로 애플리케이션이 프로그래밍된 한 여러 데이터베이스에 데이터를 분산하여 동적으로 확장할 수 있습니다.
이는 서비스로서의 플랫폼 모델의 예입니다. 서버를 관리할 필요가 없습니다. 백업에 대해 걱정할 필요가 없습니다. 고가용성으로 실행됩니다. 데이터베이스의 데이터는 3개의 서버에서 자동으로 복제됩니다. 컴퓨터가 죽으면 자동으로 장애 조치(failover)되며 데이터가 손실되지 않습니다. 서버가 정기적으로 패치되므로 걱정할 필요가 없습니다.
단추를 클릭하면 필요한 정확한 연결 문자열을 얻을 수 있으며 새 데이터베이스 사용을 즉시 시작할 수 있습니다.
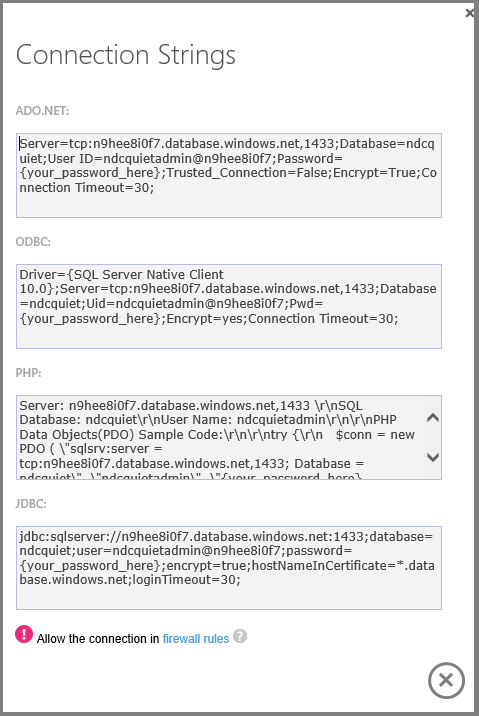
대시보드에는 연결 기록 및 사용된 스토리지 양이 표시됩니다.

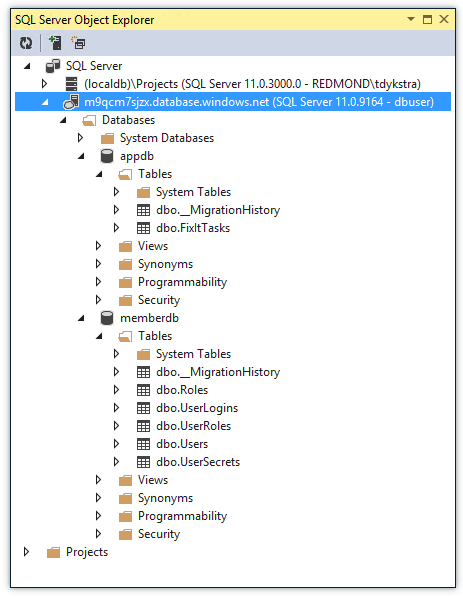
포털에서 또는 SSMS(SQL Server Management Studio) 및 SSOX(Visual Studio 도구 SQL Server 개체 탐색기) 및 서버 Explorer 포함하여 이미 익숙한 SQL Server 도구를 사용하여 데이터베이스를 관리할 수 있습니다.
또 다른 좋은 점은 가격 책정 모델입니다. 무료 20MB 데이터베이스로 개발을 시작할 수 있으며 프로덕션 데이터베이스는 매월 약 $5부터 시작합니다. 최대 용량이 아니라 데이터베이스에 실제로 저장하는 데이터의 양에 대해서만 비용을 지불합니다. 라이선스를 구입할 필요가 없습니다.
SQL Database 크기 조정이 쉽습니다. 수정 앱의 경우 자동화 스크립트에서 만드는 데이터베이스는 1기가로 제한됩니다. 최대 150기가까지 확장하려면 포털로 이동하여 해당 설정을 변경하거나 REST API 명령을 실행하면 됩니다. 몇 초 안에 데이터를 배포할 수 있는 150기가 데이터베이스가 있습니다.
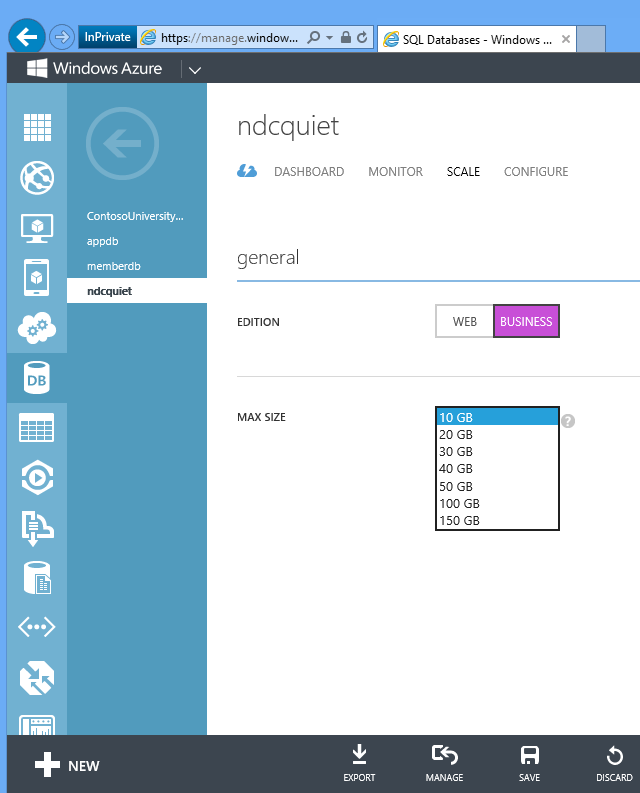
이것이 바로 클라우드가 인프라를 빠르고 쉽게 돋보이게 하고 즉시 사용하기 시작하는 강력한 힘입니다.
Fix It 앱은 멤버 자격(인증 및 권한 부여)과 데이터에 대해 하나씩 두 개의 SQL 데이터베이스를 사용하며, 이를 프로비전하고 크기를 조정하기 위해 수행해야 하는 모든 작업입니다. 이전에 Windows PowerShell 스크립트를 통해 데이터베이스를 프로비전하는 방법을 살펴보았으며, 이제 포털에서 데이터베이스를 얼마나 쉽게 프로비전할 수 있는지도 살펴보았습니다.
Entity Framework와 ADO.NET 사용하여 직접 데이터베이스 액세스
Fix It 앱은 .NET 애플리케이션에 대해 Microsoft에서 권장하는 ORM(개체 관계형 매퍼)인 Entity Framework를 사용하여 이러한 데이터베이스에 액세스합니다. ORM은 개발자 생산성을 용이하게 하는 훌륭한 도구이지만 생산성은 일부 시나리오에서 성능 저하를 희생합니다. 실제 클라우드 앱에서는 EF를 사용하거나 ADO.NET 직접 사용하는 것 중에서 선택할 수 없습니다. 둘 다 사용합니다. 대부분의 경우 데이터베이스에서 작동하는 코드를 작성할 때 최대 성능을 얻는 것은 중요하지 않으며 Entity Framework를 사용하여 얻을 수 있는 간소화된 코딩 및 테스트를 활용할 수 있습니다. EF 오버헤드로 인해 성능이 허용되지 않는 경우 저장 프로시저를 호출하여 ADO.NET 사용하여 고유한 쿼리를 작성하고 실행할 수 있습니다.
데이터베이스에 액세스하는 데 사용하는 방법이 무엇이든 간에 가능한 한 "잡담"을 최소화하려고 합니다. 즉, 수십 개 또는 수백 개의 작은 쿼리 결과 집합이 아닌 하나의 더 큰 쿼리 결과 집합에서 필요한 모든 데이터를 가져올 수 있는 경우 일반적으로 더 좋습니다. 예를 들어 학생과 등록한 과정을 나열해야 하는 경우 일반적으로 학생을 하나의 쿼리로 가져오고 각 학생의 과정에 대해 별도의 쿼리를 실행하는 대신 모든 데이터를 하나의 조인 쿼리로 가져오는 것이 좋습니다.
수정 앱의 SQL 데이터베이스 및 Entity Framework
Fix It 앱 FixItContext 에서 Entity Framework DbContext 클래스에서 파생되는 클래스는 데이터베이스를 식별하고 데이터베이스의 테이블을 지정합니다. 컨텍스트는 작업에 대한 엔터티 집합(테이블)을 지정하고 코드는 연결 문자열 이름을 컨텍스트에 전달합니다. 해당 이름은 Web.config 파일에 정의된 연결 문자열을 나타냅니다.
public class MyFixItContext : DbContext
{
public MyFixItContext()
: base("name=appdb")
{
}
public DbSet<MyFixIt.Persistence.FixItTask> FixItTasks { get; set; }
}
Web.config 파일의 연결 문자열 이름은 appdb입니다(여기서는 로컬 개발 데이터베이스를 가리킵니다.).
<connectionStrings>
<add name="DefaultConnection" connectionString="Data Source=(LocalDb)\v11.0;Initial Catalog=aspnet-MyFixIt-20130604091232_4;Integrated Security=True" providerName="System.Data.SqlClient" />
<add name="appdb" connectionString="Data Source=(localdb)\v11.0; Initial Catalog=MyFixItContext-20130604091609_11;Integrated Security=True; MultipleActiveResultSets=True" providerName="System.Data.SqlClient" />
</connectionStrings>
Entity Framework는 엔터티 클래스에 포함된 FixItTask 속성을 기반으로 FixItTasks 테이블을 만듭니다. 간단한 POCO(Plain Old CLR Object) 클래스입니다. 즉, Entity Framework에서 상속되거나 엔터티 프레임워크에 대한 종속성이 없습니다. 그러나 Entity Framework는 테이블을 기반으로 테이블을 만들고 CRUD(create-read-update-delete) 작업을 실행하는 방법을 알고 있습니다.
public class FixItTask
{
public int FixItTaskId { get; set; }
public string CreatedBy { get; set; }
[Required]
public string Owner { get; set; }
[Required]
public string Title { get; set; }
public string Notes { get; set; }
public string PhotoUrl { get; set; }
public bool IsDone { get; set; }
}
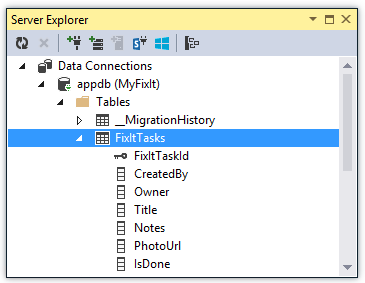
Fix It 앱에는 데이터 저장소로 작업하는 CRUD 작업에 사용하는 리포지토리 인터페이스가 포함되어 있습니다.
public interface IFixItTaskRepository
{
Task<List<FixItTask>> FindOpenTasksByOwnerAsync(string userName);
Task<List<FixItTask>> FindTasksByCreatorAsync(string userName);
Task<MyFixIt.Persistence.FixItTask> FindTaskByIdAsync(int id);
Task CreateAsync(FixItTask taskToAdd);
Task UpdateAsync(FixItTask taskToSave);
Task DeleteAsync(int id);
}
리포지토리 메서드는 모두 비동기이므로 모든 데이터 액세스를 완전히 비동기 방식으로 수행할 수 있습니다.
리포지토리 구현은 Entity Framework 비동기 메서드를 호출하여 LINQ 쿼리를 비롯한 데이터와 삽입, 업데이트 및 삭제 작업을 수행합니다. 다음은 수정 작업을 조회하기 위한 코드의 예입니다.
public async Task<FixItTask> FindTaskByIdAsync(int id)
{
FixItTask fixItTask = null;
Stopwatch timespan = Stopwatch.StartNew();
try
{
fixItTask = await db.FixItTasks.FindAsync(id);
timespan.Stop();
log.TraceApi("SQL Database", "FixItTaskRepository.FindTaskByIdAsync", timespan.Elapsed, "id={0}", id);
}
catch(Exception e)
{
log.Error(e, "Error in FixItTaskRepository.FindTaskByIdAsynx(id={0})", id);
}
return fixItTask;
}
여기에 타이밍 및 오류 로깅 코드도 있습니다. 모니터링 및 원격 분석 챕터의 뒷부분에서 살펴보겠습니다.
Azure의 VM(IaaS)에서 SQL Database(PaaS) 및 SQL Server 선택
SQL Server 및 Azure SQL Database의 좋은 점은 두 가지 모두에 대한 핵심 프로그래밍 모델이 동일하다는 것입니다. 두 환경에서 동일한 기술의 대부분을 사용할 수 있습니다. 개발 시 SQL Server 데이터베이스와 수정 앱이 설정된 방식인 클라우드의 SQL Database instance 사용할 수도 있습니다.
또는 IaaS VM에 설치하여 온-프레미스에서 실행하는 클라우드에서 동일한 SQL Server 실행할 수 있습니다. 일부 레거시 애플리케이션의 경우 VM에서 SQL Server 실행하는 것이 더 나은 솔루션일 수 있습니다. SQL Server 데이터베이스는 전용 VM에서 실행되므로 공유 서버에서 실행되는 SQL Database 데이터베이스보다 더 많은 리소스를 사용할 수 있습니다. 즉, SQL Server 데이터베이스가 더 크고 여전히 잘 수행될 수 있습니다. 일반적으로 데이터베이스 크기와 테이블 크기가 작을수록 SQL Database(PaaS)에 대한 사용 사례가 더 잘 작동합니다.
다음은 두 모델 중에서 선택하는 방법에 대한 몇 가지 지침입니다.
| Azure SQL Database(PaaS) | 가상 머신의 SQL Server(IaaS) |
|---|---|
| 장점 - VM을 만들거나 관리하거나 OS 또는 SQL을 업데이트하거나 패치할 필요가 없습니다. Azure에서 이 작업을 수행합니다. - 데이터베이스 수준 SLA를 사용하는 기본 제공 고가용성. - TCO(총 소유 비용)가 낮습니다. 사용량에 대해서만 비용을 지불하기 때문입니다(라이선스 필요 없음). - 많은 수의 작은 데이터베이스를 처리하는 데 적합합니다(<각각 =500GB). - 확장이 가능하도록 새 데이터베이스를 동적으로 쉽게 만들 수 있습니다. | 장점 - 온-프레미스 SQL Server 기능과 호환됩니다. - VM 수준 SLA를 사용하여 2개 이상의 VM에서 AlwaysOn을 통해 SQL Server 고가용성을 구현할 수 있습니다. - SQL 관리 방법을 완전히 제어할 수 있습니다. - 이미 소유하고 있는 SQL 라이선스를 다시 사용하거나 시간당 비용을 지불할 수 있습니다. - 적은 수의 데이터베이스(1TB 이상)를 처리하는 데 적합합니다. |
| 단점 - 온-프레미스 SQL Server 비해 일부 기능 차이(CLR 통합, TDE, 압축 지원, SQL Server Reporting Services 등 부족) - 데이터베이스 크기 제한은 500GB입니다. | 단점 - 업데이트/패치(OS 및 SQL)는 사용자의 책임입니다. DB 만들기 및 관리는 사용자의 책임입니다. 디스크 IOPS(초당 입력/출력 작업)는 약 8,000개(16개의 데이터 드라이브를 통해)로 제한됩니다. |
VM에서 SQL Server 사용하려는 경우 고유한 SQL Server 라이선스를 사용하거나 1시간 동안 비용을 지불할 수 있습니다. 예를 들어 포털 또는 REST API를 통해 SQL Server 이미지를 사용하여 새 VM을 만들 수 있습니다.
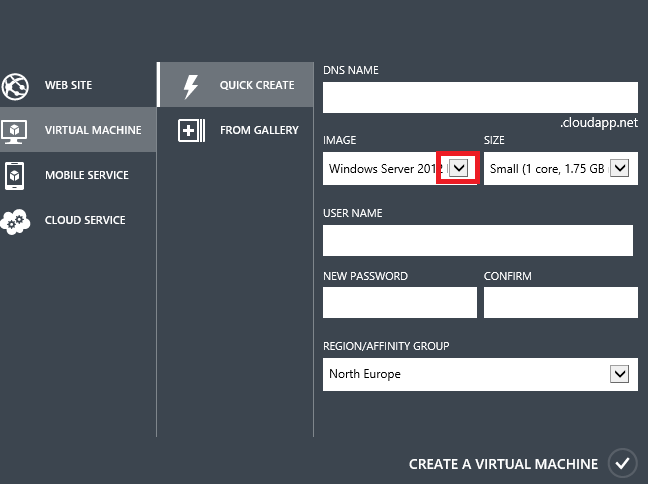
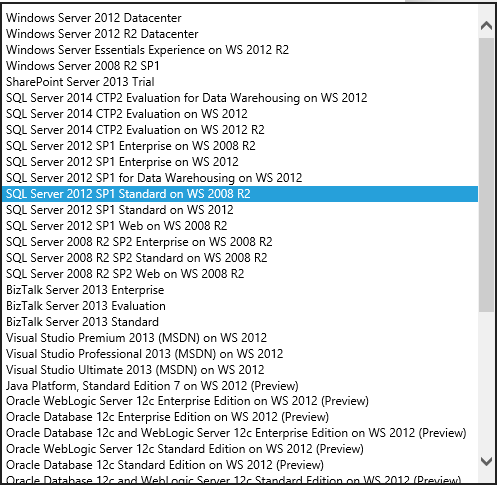
SQL Server 이미지를 사용하여 VM을 만들 때 VM 사용에 따라 시간당 SQL Server 라이선스 비용을 평가합니다. 몇 달 동안만 실행되는 프로젝트가 있는 경우 시간당 지불하는 것이 더 저렴합니다. 프로젝트가 수년 동안 지속될 것이라고 생각되면 일반적으로 하는 방식으로 라이선스를 구입하는 것이 더 저렴합니다.
요약
클라우드 컴퓨팅을 사용하면 애플리케이션의 요구 사항에 가장 잘 맞는 데이터 스토리지 접근 방식을 혼합하고 일치시키는 것이 실용적입니다. 새 애플리케이션을 빌드하는 경우 애플리케이션이 증가할 때 계속 잘 작동하는 방법을 선택하기 위해 여기에 나열된 질문에 대해 신중하게 생각하세요. 다음 챕터에서는 여러 데이터 스토리지 접근 방식을 결합하는 데 사용할 수 있는 몇 가지 분할 전략을 설명합니다.
리소스
자세한 내용은 다음 리소스를 참조하세요.
데이터베이스 플랫폼 선택:
- Highly-Scalable 솔루션에 대한 데이터 액세스: SQL, NoSQL 및 Polyglot 지속성 사용 클라우드 애플리케이션에 사용할 수 있는 다양한 종류의 데이터 저장소에 대해 자세히 설명한 Microsoft 패턴 및 사례별 전자책.
- Microsoft 패턴 및 사례 - Azure 지침. 데이터 일관성 입문서, 데이터 복제 및 동기화 지침, 인덱스 테이블 패턴, 구체화된 뷰 패턴을 참조하세요.
- 베이스: 산성 대안. 데이터 일관성과 확장성 간의 절충에 대한 문서입니다.
- 7주 동안의 7개 데이터베이스: 최신 데이터베이스 및 NoSQL 이동에 대한 가이드입니다. 에릭 레드먼드와 짐 알 윌슨이 예약합니다. 현재 사용 가능한 다양한 데이터 스토리지 플랫폼을 소개하는 것이 좋습니다.
SQL Server 및 SQL Database 중에서 선택:
- SQL Database 지침에 대한 프리미엄 미리 보기입니다. SQL Database Premium에 대한 소개와 SQL Database Web and Business 버전을 통해 선택할 시기에 대한 지침입니다.
- 지침 및 제한 사항(Azure SQL 데이터베이스). SQL Database 지원하지 않는 SQL Server 기능에 중점을 둔 기능을 포함하여 SQL Database 제한 사항에 대한 설명서로 연결되는 포털 페이지입니다.
- Azure Virtual Machines SQL Server. Azure에서 SQL Server 실행에 대한 설명서로 연결되는 포털 페이지입니다.
- Scott Guthrie가 Azure의 SQL Database에 대해 설명합니다. 스콧 거스리에 의해 SQL Database 6 분 비디오 소개.
- Azure Virtual Machines SQL Server 애플리케이션 패턴 및 개발 전략.
ASP.NET 웹앱에서 Entity Framework 및 SQL Database 사용
- MVC 5를 사용하여 EF 6에서 시작. EF를 사용하고 데이터베이스를 Azure 및 SQL Database 배포하는 MVC 앱을 빌드하는 방법을 안내하는 9부로 구성된 자습서 시리즈입니다.
- Visual Studio를 사용하여 웹 배포를 ASP.NET. EF Code First를 사용하여 데이터베이스를 배포하는 방법에 대해 자세히 알아보는 12부로 구성된 자습서 시리즈입니다.
- Membership, OAuth 및 SQL Database 사용하여 보안 ASP.NET MVC 5 앱을 Azure 웹 사이트에 배포합니다. 인증을 사용하고, 멤버 자격 데이터베이스에 애플리케이션 테이블을 저장하고, 데이터베이스 스키마를 수정하고, 앱을 Azure에 배포하는 웹앱을 만드는 방법을 안내하는 단계별 자습서입니다.
- 데이터 액세스 콘텐츠 맵을 ASP.NET. EF 및 SQL Database 사용하기 위한 리소스에 대한 링크입니다.
Azure에서 MongoDB 사용:
- Azure의 MongoDB Atlas. Azure에서 MongoDB Atlas를 실행하는 방법에 대한 설명서에 대한 포털 페이지입니다.
- Azure의 가상 머신에서 실행되는 MongoDB에 연결하는 Azure 웹 사이트를 만듭니다. ASP.NET 웹 애플리케이션에서 MongoDB 데이터베이스를 사용하는 방법을 보여 주는 단계별 자습서입니다.
HDInsight(Azure의 Hadoop):
- HDInsight. Azure 웹 사이트의 HDInsight에 대한 포털 설명서입니다.
- Hadoop 및 HDInsight: Azure의 빅 데이터입니다. 브루노 테르칼리와 리카르도 빌라로보스의 MSDN 매거진 기사로, Azure에서 Hadoop을 소개합니다.
- Microsoft 패턴 및 사례 - Azure 지침. MapReduce 패턴을 참조하세요.
피드백
출시 예정: 2024년 내내 콘텐츠에 대한 피드백 메커니즘으로 GitHub 문제를 단계적으로 폐지하고 이를 새로운 피드백 시스템으로 바꿀 예정입니다. 자세한 내용은 다음을 참조하세요. https://aka.ms/ContentUserFeedback
다음에 대한 사용자 의견 제출 및 보기