AKS(Azure Kubernetes Service) 개요의 클러스터 자동 크기 조정
AKS(Azure Kubernetes Service)에서 애플리케이션 수요에 맞추려면 워크로드를 실행하는 노드 수를 조정해야 할 수 있습니다. 클러스터 자동 크기 조정기 구성 요소는 리소스 제약 조건으로 인해 예약할 수 없는 클러스터의 Pod를 감시합니다. 클러스터 자동 크기 조정기가 문제를 검색하면 애플리케이션 요구 사항에 맞게 노드 풀의 노드 수의 크기를 조정합니다. 또한 노드에서 실행 중인 Pod가 부족한지 정기적으로 확인하고 필요에 따라 노드 수의 크기를 조정합니다.
이 문서는 AKS에서 클러스터 자동 크기 조정기가 작동하는 방식을 이해하는 데 도움이 됩니다. 또한 AKS 워크로드에 대해 클러스터 자동 크기 조정기를 구성할 때 지침, 모범 사례 및 고려 사항을 제공합니다. AKS 워크로드에 대해 클러스터 자동 크기 조정기를 사용하도록 설정하거나, 사용하지 않도록 설정하거나, 업데이트하려면 AKS에서 클러스터 자동 크기 조정기 사용을 참조하세요.
클러스터 자동 크기 조정기 정보
클러스터에는 근무일, 저녁, 주말 등 변화하는 애플리케이션 요구 사항에 맞게 자동으로 크기 조정할 수 있는 방법이 필요한 경우가 많습니다. AKS 클러스터는 다음과 같은 방식으로 스케일 인할 수 있습니다.
- 클러스터 자동 크기 조정기는 리소스 제약 조건으로 인해 노드에 예약할 수 없는 Pod를 주기적으로 확인합니다. 이에 따라 클러스터가 자동으로 노드 수를 늘립니다. 클러스터 자동 크기 조정기를 사용하면 수동 크기 조정이 사용하지 않도록 설정됩니다. 자세한 내용은 스케일 업은 어떻게 작동하나요?를 참조하세요.
- Horizontal Pod Autoscaler는 Kubernetes 클러스터에서 메트릭 서버를 사용하여 Pod의 리소스 수요를 모니터링합니다. 애플리케이션에 더 많은 리소스가 필요한 경우 수요에 맞게 자동으로 Pod 수가 증가합니다.
- 수직형 Pod 자동 크기 조정기는 과거 사용량을 기준으로 워크로드당 컨테이너에 대한 리소스 요청과 한도를 자동으로 설정하여 필요한 CPU 및 메모리 리소스가 있는 노드에 Pod가 예약되도록 합니다.
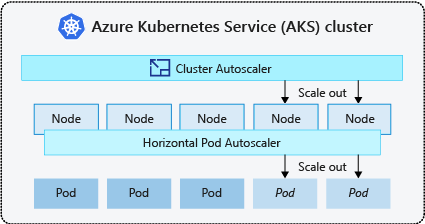
노드에 대해 클러스터 자동 크기 조정기를 사용하도록 설정하고 Pod에 대해 수직형 Pod 자동 크기 조정기 또는 수평형 Pod 자동 크기 조정기를 사용하도록 설정하는 것이 일반적인 방법입니다. 클러스터 자동 크기 조정기를 사용하도록 설정하면 노드 풀 크기가 최솟값보다 작거나 최댓값보다 클 때 지정된 크기 조정 규칙이 적용됩니다. 클러스터 자동 크기 조정기는 노드 풀에 새 노드가 필요할 때까지 또는 현재 노드 풀에서 노드가 안전하게 삭제될 때까지 기다립니다. 자세한 내용은 스케일 다운 작동 방식을 참조하세요.
모범 사례 및 고려 사항
- 클러스터 자동 크기 조정기를 사용하여 가용성 영역을 구현할 때 각 영역에 단일 노드 풀을 사용하는 것이 좋습니다.
--balance-similar-node-groups매개 변수를True로 설정하면 스케일 업 작업 중에 워크로드에 대해 영역 전체에 균형 잡힌 노드 배포를 유지할 수 있습니다. 이 방식이 구현되지 않으면 스케일 다운 작업으로 인해 영역 간 노드 균형이 중단될 수 있습니다. - 노드가 400개가 넘는 클러스터의 경우 Azure CNI 또는 Azure CNI 오버레이를 사용하는 것이 좋습니다.
- 스폿 및 고정 노드 풀 모두에서 동시에 워크로드를 효과적으로 실행하려면 우선 순위 확장기를 사용하는 것이 좋습니다. 이 방식을 사용하면 노드 풀의 우선 순위에 따라 Pod를 예약할 수 있습니다.
- Pod에 CPU/메모리 요청을 할당할 때는 주의해야 합니다. 클러스터 자동 크기 조정기는 노드에 대한 CPU/메모리 압력이 아닌 보류 중인 Pod를 기반으로 크기 조정됩니다.
- 웹앱과 같은 장기 실행 워크로드와 집중적으로 짧게 발생하는 워크로드를 동시에 호스팅하는 클러스터의 경우, 불필요한 노드 드레이닝 또는 스케일 다운 작업을 방지하려면 선호도 규칙/확장기를 사용하거나 PriorityClass를 사용하여 이를 별도의 노드 풀로 분리하는 것이 좋습니다.
- 자동 크기 조정기 사용 노드 풀에서 노드 수를 수동으로 줄이는 대신 워크로드를 제거하여 노드를 축소합니다. 노드 풀이 이미 최대 용량에 있거나 노드에서 실행 중인 활성 워크로드가 있는 경우 클러스터 자동 크기 조정기에서 예기치 않은 동작이 발생할 수 있습니다.
- Pod의 PriorityClass 값이 -10 미만인 경우 노드가 스케일 업되지 않습니다. 우선 순위 -10은 Pod 초과 프로비전용으로 예약되어 있습니다. 자세한 내용은 Pod 우선 순위 및 선점 기능을 갖춘 클러스터 자동 크기 조정기 사용을 참조하세요.
- 클러스터 자동 크기 조정기와 다른 노드 자동 크기 조정 메커니즘(가상 머신 확장 집합 자동 크기 조정기 등)을 결합하지 마세요.
- 클러스터 자동 크기 조정기는 다음 상황에서처럼 Pod를 이동할 수 없는 경우 규모를 스케일 다운하지 못할 수 있습니다.
- 배포 또는 ReplicaSet와 같은 컨트롤러 개체의 지원을 받지 않고 직접 만들어진 Pod입니다.
- 너무 제한적이고 Pod 수가 특정 임계값 아래로 떨어지는 것을 허용하지 않는 PDB(Pod Disruption Budget)입니다.
- Pod는 다른 노드에서 예약된 경우 적용할 수 없는 노드 선택기 또는 선호도 방지를 사용합니다. 자세한 내용은 클러스터 자동 크기 조정기가 노드를 제거하는 것을 방해할 수 있는 Pod 형식은 무엇인가요?를 참조하세요.
Important
자동 크기 조정된 노드 풀 내의 개별 노드를 변경하지 마세요. 동일한 노드 그룹의 모든 노드에는 균일한 용량, 레이블, taint 및 시스템 Pod가 있어야 합니다.
클러스터 자동 크기 조정기 프로필
클러스터 자동 크기 조정기 프로필은 클러스터 자동 크기 조정기의 동작을 제어하는 매개 변수 집합입니다. 클러스터를 만들거나 기존 클러스터를 업데이트할 때 클러스터 자동 크기 조정기 프로필을 구성할 수 있습니다.
클러스터 자동 크기 조정기 프로필 최적화
성능과 비용 간의 장단점을 고려하면서 특정 워크로드 시나리오에 따라 클러스터 자동 크기 조정기 프로필 설정을 미세 조정해야 합니다. 이 섹션에서는 이러한 장단점을 보여 주는 예를 제공합니다.
클러스터 자동 크기 조정기 프로필 설정은 클러스터 전체에 적용되며 자동 크기 조정이 사용하도록 설정된 모든 노드 풀에 적용된다는 점에 유의해야 합니다. 한 노드 풀에서 발생하는 모든 조정 작업은 다른 노드 풀의 자동 크기 조정 동작에 영향을 미칠 수 있으며, 이로 인해 예기치 않은 결과가 발생할 수 있습니다. 원하는 결과를 가져오려면 모든 관련 노드 풀에 일관되고 동기화된 프로필 구성을 적용해야 합니다.
예 1: 성능 최적화
성능에 중점을 두고 집중적으로 상당히 크게 발생하는 워크로드를 처리하는 클러스터의 경우 scan-interval을 늘리고 scale-down-utilization-threshold를 줄이는 것이 좋습니다. 이러한 설정은 여러 조정 작업을 단일 호출로 일괄 처리하여 조정 시간과 컴퓨팅 읽기/쓰기 할당량 사용률을 최적화하는 데 도움이 됩니다. 또한 활용도가 낮은 노드에서 신속한 스케일 다운 작업의 위험을 완화하여 Pod 예약 효율성을 향상시키는 데 도움이 됩니다. 또한 증가 ok-total-unready-count및 max-total-unready-percentage.
DaemonSet Pod가 있는 클러스터의 경우 ignore-daemonset-utilization을 true로 설정하는 것이 좋습니다. 그러면 DaemonSet Pod의 노드 사용률을 효과적으로 무시하고 불필요한 스케일 다운 작업을 최소화할 수 있습니다. 버스트 워크로드에 대한 프로필 참조
예 2: 비용 최적화
비용 최적화 프로필을 원하는 경우 다음 매개 변수 구성을 설정하는 것이 좋습니다.
- 노드가 스케일 다운되기 전에 노드가 필요 없어져야 하는 시간인
scale-down-unneeded-time을 줄입니다. - 노드가 추가된 후 스케일 다운을 고려하기 전에 대기하는 시간인
scale-down-delay-after-add를 줄입니다. - 노드 제거를 위한 사용률 임계값인
scale-down-utilization-threshold를 늘립니다. - 단일 호출에서 삭제할 수 있는 최대 노드 수인
max-empty-bulk-delete를 늘립니다. - false로 설정합니다
skip-nodes-with-local-storage. - 증가
ok-total-unready-count및max-total-unready-percentage
일반적인 문제 및 완화 권장 사항
CLI 또는 포털을 통해 크기 조정 실패 및 확장이 트리거되지 않은 이벤트를 봅니다.
스케일 업 작업을 트리거하지 않음
| 일반적인 원인 | 완화 권장 사항 |
|---|---|
| 여러 가용성 영역이 있는 클러스터 자동 크기 조정기를 사용하거나 Pod 또는 영구 볼륨의 영역이 노드 영역과 다를 때 발생할 수 있는 PertantVolume 노드 선호도 충돌이 발생합니다. | 가용성 영역당 하나의 노드 풀을 사용하고 --balance-similar-node-groups를 사용하도록 설정합니다. 또한 볼륨을 사용하는 Pod가 만들어질 때까지 볼륨이 노드에 바인딩되지 않도록 Pod 사양에서 WaitForFirstConsumer로 volumeBindingMode 필드를 설정할 수도 있습니다. |
| 테인트 및 톨러레이션/노드 선호도 충돌 | 노드에 할당된 테인트를 평가하고 Pod에 정의된 톨러레이션 범위를 검토합니다. 필요한 경우 Pod가 노드에서 효율적으로 예약될 수 있도록 테인트 및 톨러레이션을 조정합니다. |
스케일 업 작업 실패
| 일반적인 원인 | 완화 권장 사항 |
|---|---|
| 서브넷의 IP 주소 소진 | 동일한 가상 네트워크에 다른 서브넷을 추가하고 새 서브넷에 다른 노드 풀을 추가합니다. |
| 코어 할당량 소진 | 승인된 코어 할당량이 소진되었습니다. 할당량 증가를 요청합니다. 클러스터 자동 크기 조정기는 스케일 업 시도가 여러 번 실패하면 특정 노드 그룹 내에서 지수 백오프 상태로 전환됩니다. |
| 노드 풀의 최대 크기 | 노드 풀의 최대 노드 수를 늘리거나 새 노드 풀을 만듭니다. |
| 속도 제한을 초과하는 요청/호출 | 429 요청이 너무 많음 오류를 참조하세요. |
스케일 다운 작업 실패
| 일반적인 원인 | 완화 권장 사항 |
|---|---|
| 노드 드레이닝을 방지하는 Pod/Pod를 제거할 수 없음 | • 스케일 다운을 방지할 수 있는 Pod 형식을 확인합니다. • hostPath 및 emptyDir과 같은 로컬 스토리지를 사용하는 Pod의 경우 클러스터 자동 크기 조정기 프로필 플래그 skip-nodes-with-local-storage를 false로 설정합니다. • Pod 사양에서 cluster-autoscaler.kubernetes.io/safe-to-evict 주석을 true로 설정합니다. • 제한적일 수 있으므로 PDB를 확인합니다. |
| 노드 풀의 최소 크기 | 노드 풀의 최소 크기를 줄입니다. |
| 속도 제한을 초과하는 요청/호출 | 429 요청이 너무 많음 오류를 참조하세요. |
| 쓰기 작업이 잠김 | 완전 관리형 AKS 리소스 그룹을 변경하지 마세요(AKS 지원 정책 참조). 이전에 리소스 그룹에 적용한 모든 리소스 잠금을 제거하거나 다시 설정합니다. |
기타 문제
| 일반적인 원인 | 완화 권장 사항 |
|---|---|
| PriorityConfigMapNotMatchedGroup | 자동 크기 조정이 필요한 모든 노드 그룹을 크기 조정 구성 파일에 추가했는지 확인합니다. |
백오프의 노드 풀
백오프의 노드 풀은 버전 0.6.2에 도입되었으며 장애 후 클러스터 자동 크기 조정기가 노드 풀 크기 조정을 백오프하게 만듭니다.
조정 작업에 오류가 발생한 기간에 따라 다시 시도하기까지 최대 30분이 걸릴 수 있습니다. 자동 크기 조정을 사용하지 않도록 설정했다가 다시 사용하도록 설정하여 노드 풀의 백오프 상태를 다시 설정할 수 있습니다.