이 문서에서는 EDA(탐색적 데이터 분석)라고 하는 데이터 웨어하우스 프로젝트에 대한 대체 접근 방식을 설명합니다. 이 접근 방식은 ETL(추출, 변환, 로드) 작업의 문제를 줄일 수 있습니다. 이 접근 방식에서는 먼저 비즈니스 인사이트를 생성하는 데 중점을 둔 후 모델링 및 ETL 작업을 해결하는 데 중점을 둡니다.
아키텍처

이 아키텍처의 Visio 파일을 다운로드합니다.
EDA의 경우 다이어그램의 오른쪽에만 관심이 있습니다. Azure Synapse SQL 서버리스는 데이터 레이크 파일에 대해 컴퓨팅 엔진으로 사용됩니다.
EDA를 수행하기 위해 다음과 같은 과정이 이루어집니다.
- T-SQL 쿼리가 Azure Synapse SQL 서버리스 또는 Azure Synapse Spark에서 직접 실행됩니다.
- 쿼리가 Power BI 또는 Azure Data Studio와 같은 그래픽 쿼리 도구에서 실행됩니다.
Parquet 또는 델타를 사용하여 모든 레이크하우스 데이터를 유지하는 것이 좋습니다.
원하는 ELT(추출, 로드, 변환) 도구를 사용하여 다이어그램의 왼쪽(데이터 수집)을 구현할 수 있습니다. EDA에는 영향을 주지 않습니다.
구성 요소
Azure Synapse Analytics는 레이크하우스 데이터에 대한 데이터 통합, 엔터프라이즈 데이터 웨어하우징, 빅 데이터 분석을 결합합니다. 이 솔루션의 내용은 다음과 같습니다.
- Azure Synapse 작업 영역은 EDA 작업을 위해 데이터 엔지니어, 데이터 과학자, 데이터 분석가, BI(비즈니스 인텔리전스) 전문가 간의 협업을 촉진합니다.
- Azure Synapse 서버리스 SQL 풀은 표준 T-SQL을 사용하여 Azure Data Lake Storage의 비정형 및 반정형 데이터를 분석합니다.
- Azure Synapse 서버리스 Apache Spark 풀은 Spark SQL, PySpark, Scala 등의 Spark 언어를 사용하여 Data Lake Storage에서 코드 우선 탐색을 수행합니다.
Azure Data Lake Storage는 이후에 Azure Synapse 서버리스 SQL 풀에서 분석되는 데이터의 스토리지를 제공합니다.
Azure Machine Learning은 Azure Synapse Spark에 데이터를 제공합니다.
Power BI는 이 솔루션에서 EDA를 수행하기 위해 데이터를 쿼리하는 데 사용됩니다.
대안
Synapse SQL 서버리스 풀을 Azure Databricks로 바꾸거나 보완할 수 있습니다.
Synapse SQL 서버리스 풀에서 레이크하우스 모델을 사용하는 대신 Azure Synapse 전용 SQL 풀을 사용하여 엔터프라이즈 데이터를 저장할 수 있습니다. 이 문서의 사용 사례 및 고려 사항과 관련 리소스를 검토하여 사용할 기술을 결정합니다.
시나리오 정보
이 솔루션은 데이터 웨어하우스 프로젝트에 대한 EDA 접근 방식의 구현을 보여 줍니다. 이 접근 방식은 ETL 작업의 문제를 줄일 수 있습니다. 이 접근 방식에서는 먼저 비즈니스 인사이트를 생성하는 데 중점을 둔 후 모델링 및 ETL 작업을 해결하는 데 중점을 둡니다.
잠재적인 사용 사례
이 분석 패턴을 활용할 경우 이점을 얻을 수 있는 다른 시나리오:
처방적 분석(Prescriptive analytics). 차선의 작업 또는 다음으로 무엇을 하나?와 같이 데이터에 관해 질문합니다. 데이터를 사용하여 직감에 의존하는 경향을 줄이고 더 데이터 기반의 방식을 마련합니다. 데이터는 다양한 품질의 여러 외부 소스가 출처이고 비정형일 수 있습니다. 데이터를 데이터 웨어하우스에 실제로 로드하지 않고 데이터를 사용하여 가능한 한 빨리 비즈니스 전략을 평가하는 것이 좋습니다. 질문에 답변한 후 데이터를 삭제할 수 있습니다.
셀프 서비스 ETL. 데이터 샌드박싱(EDA) 작업을 수행할 때 ETL/ELT를 수행합니다. 데이터를 변환하고 가치 있게 만듭니다. 그러면 ETL 개발자의 규모를 개선할 수 있습니다.
탐색적 데이터 분석 정보
EDA의 작동 방식을 좀 더 자세히 살펴보기 전에 데이터 웨어하우스 프로젝트에 대한 기존 접근 방식을 요약할 필요가 있습니다. 기존 접근 방식은 다음과 같습니다.
요구 사항 수집. 데이터로 수행할 작업을 문서화합니다.
데이터 모델링. 숫자 및 특성 데이터를 팩트 및 차원 테이블로 모델링하는 방법을 결정합니다. 일반적으로 새 데이터를 가져오기 전에 이 단계를 수행합니다.
ETL. 데이터를 획득하고 데이터 웨어하우스의 데이터 모델에 맞게 조정합니다.
이러한 단계에는 몇 주 또는 몇 개월이 걸릴 수도 있습니다. 해당 단계가 완료된 후에야 데이터를 쿼리하고 비즈니스 문제를 해결할 수 있습니다. 사용자는 보고서가 생성된 후에만 값을 볼 수 있습니다. 솔루션 아키텍처는 일반적으로 다음과 같습니다.
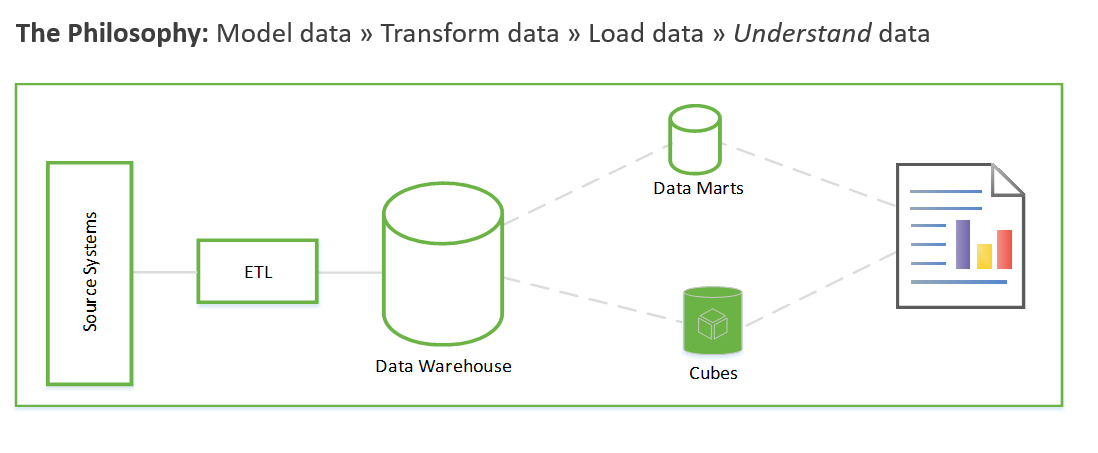
먼저 비즈니스 인사이트를 생성하는 데 중점을 둔 후 모델링 및 ETL 작업을 해결하는 데 중점을 두는 다른 방법으로 이 과정을 수행할 수 있습니다. 이 프로세스는 데이터 과학 프로세스와 비슷합니다. 모양은 다음과 같습니다.
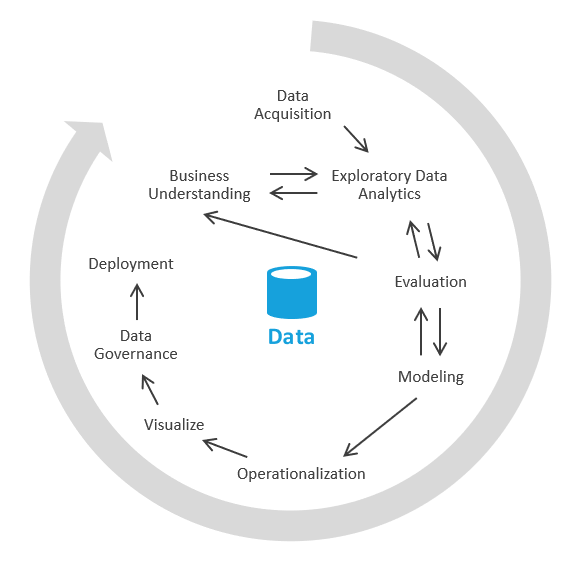
업계에서는 이 프로세스를 EDA 또는 탐색적 데이터 분석이라고 합니다.
수행하는 단계는 다음과 같습니다.
데이터 획득. 먼저 데이터 레이크/샌드박스로 수집해야 할 데이터 원본을 결정해야 합니다. 그런 다음, 해당 데이터를 레이크의 랜딩 영역으로 가져와야 합니다. Azure는 데이터를 빠르게 수집할 수 있는 Azure Data Factory, Azure Logic Apps 등의 도구를 제공합니다.
데이터 샌드박싱. 처음에는 Azure Synapse Analytics 서버리스 또는 기본 SQL을 통해 탐색적 데이터 분석에 능숙한 비즈니스 분석가와 엔지니어가 함께 작업합니다. 이 단계에서는 새 데이터를 사용하여 비즈니스 인사이트를 파악하려고 합니다. EDA는 반복적인 프로세스입니다. 더 많은 데이터를 수집하거나, SME와 대화하거나, 더 많은 질문을 하거나, 시각화를 생성해야 할 수 있습니다.
평가. 비즈니스 인사이트를 찾은 후에는 데이터로 수행할 작업을 평가해야 합니다. 데이터를 데이터 웨어하우스에 유지하려고 할 수 있습니다(따라서 모델링 단계로 이동). 다른 경우에는 데이터를 데이터 레이크/레이크하우스에 유지하고 예측 분석(기계 학습 알고리즘)에 사용하도록 할 수 있습니다. 또 다른 경우에는 새 인사이트를 사용하여 레코드 시스템을 백필하도록 할 수 있습니다. 이러한 결정 사항에 따라 다음에 해야 하는 작업을 더 잘 이해할 수 있습니다. ETL을 수행할 필요가 없을 수도 있습니다.
이러한 방법은 진정한 셀프 서비스 분석의 핵심입니다. 데이터 레이크 및 데이터 레이크 쿼리 패턴을 이해하는 Azure Synapse 서버리스와 같은 쿼리 도구를 사용하여 어느 정도 SQL을 이해하는 비즈니스 사용자에게 데이터 자산을 맡길 수 있습니다. 이 방법을 사용하여 가치 창출 시간을 상당히 줄이고 회사 데이터 이니셔티브와 관련된 위험 중 일부를 제거할 수 있습니다.
고려 사항
이러한 고려 사항은 워크로드의 품질을 향상시키는 데 사용할 수 있는 일단의 지침 원칙인 Azure Well-Architected Framework의 핵심 요소를 구현합니다. 자세한 내용은 Microsoft Azure Well-Architected Framework를 참조하세요.
가용성
Azure Synapse SQL 서버리스 풀은 HA(고가용성) 및 DR(재해 복구) 요구 사항을 충족할 수 있는 PaaS(Platform as a Service) 기능입니다.
서버리스 풀은 주문형으로 사용할 수 있습니다. 스케일 업/다운, 스케일 인/아웃 또는 어떤 종류의 관리도 필요하지 않습니다. 쿼리당 결제 모델을 사용하므로 항상 사용되지 않은 용량이 없습니다. 서버리스 풀은 다음에 적합합니다.
- T-SQL로 임시 데이터 과학 탐색
- 데이터 웨어하우스 엔터티의 초기 프로토타입 생성
- 성능 지연을 허용할 수 있는 시나리오에 대해 소비자가 사용할 수 있는 뷰 정의(예: Power BI에서)
- 탐색적 데이터 분석
작업
Synapse SQL 서버리스에서는 쿼리 및 작업에 표준 T-SQL을 사용합니다. Synapse 작업 영역 UI, Azure Data Studio 또는 SQL Server Management Studio를 T-SQL 도구로 사용할 수 있습니다.
비용 최적화
비용 최적화는 불필요한 비용을 줄이고 운영 효율성을 높이는 방법을 찾는 것입니다. 자세한 내용은 비용 최적화 핵심 요소 개요를 참조하세요.
Data Lake Storage 가격은 저장하는 데이터의 양과 데이터 사용 빈도에 따라 달라집니다. 샘플 가격 책정에는 저장된 데이터 1TB와 추가 트랜잭션 관련 가정이 포함됩니다. 1TB는 원본 레거시 데이터베이스의 크기가 아니라 데이터 레이크의 크기를 나타냅니다.
Azure Synapse Spark 풀은 노드 크기, 인스턴스 수, 가동 시간에 대한 가격 책정을 기반으로 합니다. 이 예제에서는 주당 5시간~월별 40시간의 사용률을 보이는 작은 컴퓨팅 노드 1개를 사용한다고 가정합니다.
Azure Synapse 서버리스 SQL 풀은 처리된 TB 단위의 데이터에 대한 가격 책정을 기반으로 합니다. 이 샘플에서는 월별 50TB가 처리된다고 가정합니다. 이 수치는 원본 레거시 데이터베이스의 크기가 아니라 데이터 레이크의 크기를 나타냅니다.
참가자
이 문서는 Microsoft에서 업데이트 및 유지 관리 중입니다. 원래 다음 기여자가 작성했습니다.
주요 작성자:
- Dave Wentzel | 수석 MTC 기술 설계자
다음 단계
- 데이터 엔지니어 학습 경로
- 자습서: Azure Synapse Analytics 시작
- 단일 데이터베이스 만들기 - Azure SQL Database
- Azure Synapse SQL 아키텍처
- Azure Data Lake Storage용 스토리지 계정 만들기
- Azure Event Hubs 빠른 시작 - Azure Portal을 사용하여 이벤트 허브 만들기
- 빠른 시작 - Azure Portal을 사용하여 Stream Analytics 작업 만들기
- 빠른 시작: Azure Machine Learning 시작