이 문서에서는 Azure에 다중 계층 IaaS(Infrastructure-as-a-Service) 앱을 배포할 때의 의사 결정 트리와 HA(고가용성) 및 DR(재해 복구) 옵션의 예를 제공합니다.
아키텍처
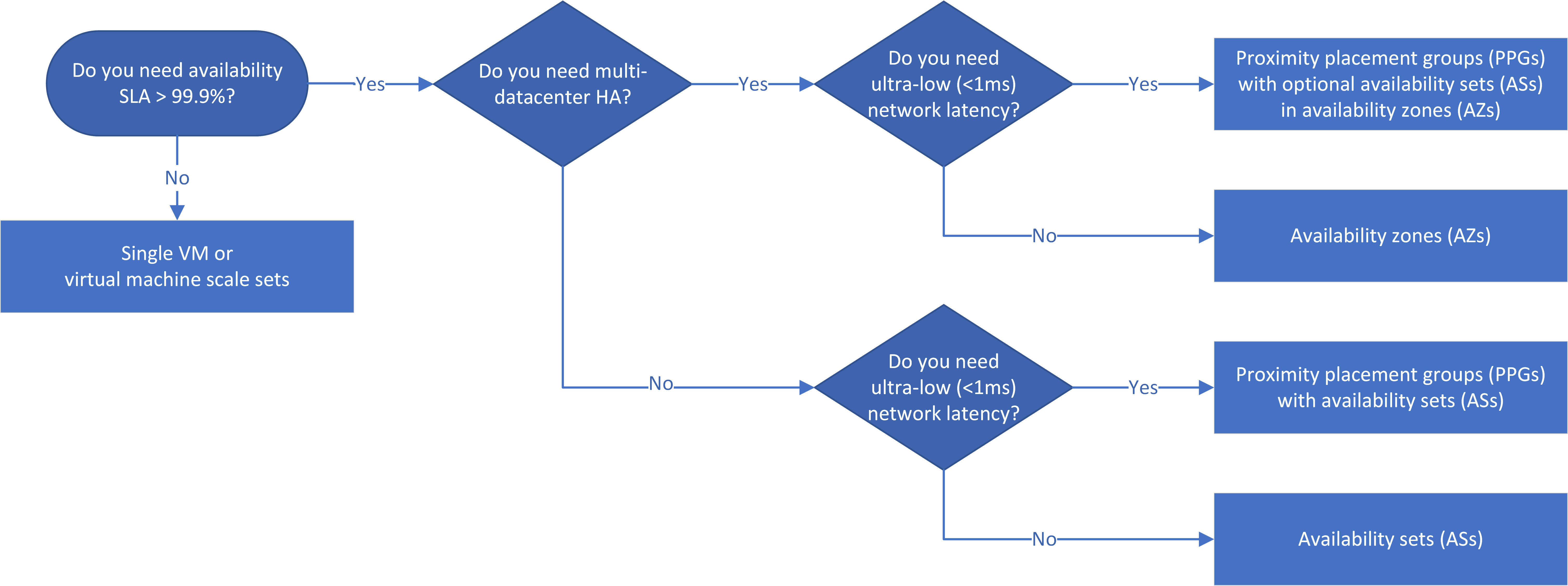
워크플로
AS(가용성 집합)는 여러 개의 격리된 하드웨어 노드에 VM을 배포하여 데이터 센터 내에서 VM 중복성 및 가용성을 제공합니다. VM의 하위 집합은 계획되거나 계획되지 않은 가동 중지 시간 동안 계속 실행되므로 전체 앱을 계속 사용할 수 있고 작동할 수 있습니다.
AZ(가용성 영역)은 Azure 지역 내의 데이터 센터에 걸쳐 있는 고유한 실제 위치입니다. 각 AZ는 독립적인 전원, 냉각 및 네트워킹이 있는 하나 이상의 데이터 센터에 액세스하고 각 AZ 지원 Azure 지역에는 최소 3개의 별도 AZ가 있습니다. 지역 내에서 AZ를 물리적으로 분리하면 배포된 VM이 데이터 센터 오류로부터 보호됩니다.
의사 결정 순서도는 가능한 경우 HA 앱이 AZ를 사용해야 한다는 원칙을 반영합니다. 영역 간, 따라서 데이터 센터 간 HA는 데이터 센터 장애에 대한 복원력으로 인해 > 99.99% SLA를 제공합니다.
다른 앱 계층에 대한 AS 및 AZ는 동일한 데이터 센터 내에 있다고 보장되지 않습니다. 앱 대기 시간이 중요한 경우 AZ 및 AS와 함께 PPG(근접 배치 그룹)을 사용하여 단일 데이터 센터에 서비스를 공동 배치해야 합니다.
구성 요소
대안
Azure Site Recovery를 사용하는 지역 DR의 대안으로 앱이 기본적으로 데이터를 복제할 수 있는 경우 DR 전용 확장 클러스터와 같은 핫/콜드 대기 서버를 사용하여 다중 지역 DR을 구현할 수 있습니다. 이 대안은 예제에 구체적으로 설명되어 있지 않지만 모든 솔루션에 추가할 수 있습니다. 지역 간 복제는 비동기적이며 일부 데이터 손실이 예상됩니다.
또는 자체 데이터 복제 기술이 있는 경우 이를 사용하여 DR을 위한 보조 지역 내 영역을 만들 수 있습니다. 워크로드의 지역에 따라 Azure Site Recovery를 사용하여 항목을 대체 영역으로 복제할 수도 있습니다. 지역별 가용성 및 이 기능에 대한 자세한 내용은 Azure 가상 머신에 대한 영역 간 재해 복구 사용에서 자세히 확인할 수 있습니다.
다중 지역 HA가 가능하지만 Front Door 또는 Traffic Manager와 같은 전역 부하 분산 장치가 필요합니다. 자세한 내용은 여러 Azure 지역에서 N 계층 애플리케이션을 실행하여 고가용성 구현을 참조하세요.
시나리오 정보
다중 계층 또는 n 계층 아키텍처는 기존의 온-프레미스 앱에서 일반적이므로 온-프레미스 앱을 클라우드로 마이그레이션하거나 온-프레미스와 클라우드 모두를 위한 앱을 개발할 때 자연스럽게 선택할 수 있습니다. N 계층 아키텍처는 일반적으로 최상위 웹 또는 프레젠테이션 계층, 중간 비즈니스 계층 및 데이터 계층과 함께 논리적 계층과 물리적 계층으로 나누어진 IaaS 앱으로 구현됩니다.
IaaS n 계층 앱에서 각 계층은 별도의 VM 집합에서 실행됩니다. 웹 및 비즈니스 계층은 상태 비저장입니다. 즉, 계층의 모든 VM이 해당 계층에 대한 모든 요청을 처리할 수 있습니다. 데이터 계층은 복제된 데이터베이스, 개체 스토리지 또는 파일 스토리지입니다. 각 계층의 여러 VM은 하나의 VM이 실패할 경우 복원력을 제공하고 부하 분산 장치는 VM 전체에 요청을 분산합니다.
풀에 VM을 더 추가하여 계층을 스케일 아웃하고 가상 머신 확장 집합을 사용하여 동일한 VM을 자동으로 스케일 아웃할 수 있습니다. 부하 분산 장치를 사용하기 때문에 앱 가동 시간에 영향을 주지 않고 계층을 스케일 아웃할 수 있습니다.
IaaS 앱에 대한 SLA(서비스 수준 계약)에 > 99% 가용성이 필요한 경우 VM을 가용성 집합, 가용성 영역 및 근접 배치 그룹에 배치하여 앱에 대한 고가용성을 구성할 수 있습니다. 선택하는 HA 및 DR 솔루션은 필요한 SLA, 대기 시간 고려 사항 및 지역 DR 요구 사항에 따라 다릅니다.
잠재적인 사용 사례
- 온-프레미스에서 클라우드로 n 계층 앱을 마이그레이션합니다.
- 온-프레미스와 클라우드 모두에 n계층 앱을 배포합니다.
- IaaS 앱에 대한 고가용성 및 재해 복구를 구성합니다.
이 솔루션은 다음 시나리오를 포함하여 모든 업계에서 사용할 수 있습니다.
- 공공 부문 애플리케이션
- 은행(금융 산업)
- 의료
고려 사항
일부 Azure 지역에서는 AZ를 사용할 수 없습니다.
솔루션을 빌드하기 전에 사용할 배포 옵션을 결정합니다. 배포 후 한 옵션에서 다른 옵션으로 이동하는 것은 가능하긴 하지만 쉽지 않습니다. 관련된 프로세스인 기본 관리 디스크에서 VM을 삭제하고 다시 만들어야 합니다.
선택한 솔루션에 대해 애플리케이션을 매핑할 수 있는지 확인합니다. 많은 앱 계층 복원력 패턴 및 디자인이 이 의사 결정 트리의 범위를 벗어납니다.
계획되지 않은 하드웨어 유지 관리, 예기치 않은 가동 중지 및 계획된 유지 관리의 세 가지 시나리오로 인해 Azure VM이 다시 부팅될 수 있습니다. 이러한 이벤트 및 이벤트 영향을 줄이기 위한 HA 모범 사례에 대한 자세한 내용은 VM 다시 부팅, 유지 관리 및 가동 중지 시간 이해를 참조하세요.
단일 VM
앱에 > 99.9% 가용성이 필요하지 않은 경우 HA용으로 구성할 필요가 없으며 단일 VM을 배포할 수 있습니다. 가상 머신 확장 집합을 사용하여 동일한 VM을 자동으로 스케일 아웃할 수 있습니다. 영역을 지정하지 않고 단일 VM을 배포하여 지역 전체에 배포합니다. Azure 프리미엄 SSD 디스크를 사용하는 경우 이러한 앱의 SLA는 99.9%입니다.
단일 VM은 모든 Azure 데이터 센터에 기본 제공되는 기본 서비스 복구 기능을 사용합니다. 예측 가능한 오류의 경우 이 기능은 일반적으로 실시간 마이그레이션을 사용하지만 예측할 수 없는 이벤트가 발생하면 VM이 다시 부팅되거나 사용 불가능하게 될 수 있습니다.
고가용성
앱에 > 99.9%의 SLA가 필요한 경우 HA용으로 앱을 디자인합니다. AZ는 데이터 센터 내결함성을 제공하므로 가능하면 AZ를 사용합니다. AZ 대신 AS를 사용할 수 있지만 AS를 사용하면 데이터 센터 오류를 허용할 수 없기 때문에 가용성이 99.99%에서 99.95%로 줄어듭니다.
AZ는 AlwaysOn SQL 클러스터를 비롯하여 활성-활성, 활성-수동 또는 빠른 장애 조치(failover)를 사용하는 각 계층의 두 HA 수준 조합을 사용하는 여러 클러스터형 앱 시나리오에 적합합니다. 영역 간 네트워크의 대기 시간이 짧기 때문에 모든 DBMS(데이터베이스 관리 시스템) 노드 간에 동기 복제가 가능합니다. 대기 시간이 더 길고 비동기 복제를 지원하는 영역 간에 확장 클러스터 구성을 실행할 수도 있습니다.
VM 기반 클러스터 중재자(예: 파일 공유 감시)를 사용하려는 경우 세 번째 AZ에 배치하여 하나의 영역이 실패하는 경우 쿼럼이 손실되지 않도록 합니다. 또는 다른 지역에서 클라우드 기반 감시를 사용할 수 있습니다.
AZ의 모든 VM은 단일 FD(장애 도메인) 및 UD(업데이트 도메인)에 있으므로 공통 전원 및 네트워크 스위치를 공유하며 동시에 다시 부팅할 수 있습니다. 여러 AZ에 VM을 만드는 경우 VM이 서로 다른 FD 및 UD에 효과적으로 분산되므로 모두 실패하거나 동시에 다시 부팅되지 않습니다. 영역 내 VM과 영역 간 VM이 중복되도록 하려면 PPG의 AS에 영역 내 VM을 배치하여 한 번에 모두 다시 부팅되지 않도록 해야 합니다. 현재 중복되지 않는 단일 인스턴스 VM 워크로드의 경우에도 필요에 따라 PPG에서 AS를 사용하여 향후 성장과 유연성을 허용할 수 있습니다.
AZ 전체에 가상 머신 확장 집합을 배포하려면 FD와 AZ를 결합할 수 있는 오케스트레이션 모드(현재 공개 미리 보기로 제공)를 사용하는 것이 좋습니다.
영역 내 PPG가 있는 AZ는 Azure에서 가장 낮은 네트워크 대기 시간 중 하나와 다중 데이터 센터 복원력으로 인해 최소 99.99%의 SLA를 허용합니다. 가능한 경우 VM에서 가속화된 네트워킹을 사용합니다.
이 솔루션은 한 영역의 VM에서 실행되는 서비스가 다른 영역의 서비스와 상호 작용해야 하는 시나리오를 나타낼 수 있습니다. 예를 들어 영역 간에 활성-활성 웹 계층과 활성-수동 데이터베이스 계층이 있을 수 있습니다. 일부 요청은 영역을 가로질러 대기 시간이 발생합니다. 영역 간 대기 시간은 여전히 매우 낮지만 가능한 가장 낮은 대기 시간을 보장해야 하는 경우 영역 내 앱 계층 간의 모든 네트워크 통신을 유지합니다.
대기 시간 고려 사항
네트워크 대기 시간은 무엇보다도 배포된 VM 간의 실제 거리에 따라 다릅니다. 앱이 계층 간에 매우 짧은 대기 시간을 요구하는 경우 각 계층에 대해 AS가 있는 PPG를 사용하여 단일 데이터 센터에 배포할 수 있습니다. 가능한 경우 VM에서 가속화된 네트워킹을 사용합니다. 이 시나리오에서는 Azure에서 가장 낮은 네트워크 대기 시간 중 하나와 99.95%의 SLA를 허용합니다.
다음 도구를 사용하여 다양한 시나리오의 대기 시간 조건에 대한 더 나은 인사이트를 얻을 수 있습니다.
- VM 간의 대기 시간을 테스트하려면 VM 네트워크 대기 시간 테스트를 참조하세요.
- 영역 간 대기 시간을 테스트하려면 AvZone-Latency-Test를 사용합니다. 이 테스트는 구독에 대한 대기 시간이 가장 짧은 논리 영역을 결정하는 데 도움이 될 수 있습니다.
- Azure 지역 간의 대기 시간을 테스트하려면 http://www.azurespeed.com/을 사용합니다. 정기적으로 업데이트되는 이 도구는 지역 간 비동기 복제를 고려할 때 유용할 수 있습니다.
재해 복구
DR 고려 사항에는 가용성(앱이 정상 상태로 계속 실행되는 기능)과 데이터 내구성(재해 발생 시 데이터 보존)이 포함됩니다.
HA 장애 조치(failover)는 데이터 손실 없이 빠르고 서비스에 미치는 영향이 매우 제한적이어야 합니다. 반면 기존 DR 장애 조치(failover)는 관련 RTO(복구 시간 목표) 및 RPO(복구 지점 목표)가 더 길어질 수 있으며 잠재적인 데이터 손실과 함께 비동기적입니다.
재해 복구 솔루션에 다른 가용성 영역을 사용하여 고가용성 및 재해 복구 모두에 가용성 영역을 활용할 수 있습니다. 가용성 영역은 다른 가용성 영역에 짧은 대기 시간 연결(2ms 미만의 왕복 대기 시간)을 가질 수 있을 만큼 가깝습니다. 그러나 로컬 중단 또는 날씨로 인해 둘 이상의 가용성 영역에 영향을 줄 수 있는 가능성을 줄일 수 있을 만큼 충분히 떨어져 있습니다. 중요 업무용 워크로드의 경우 여러 가용성 영역 외에도 여러 지역을 사용하는 솔루션을 고려해야 합니다.
Azure Site Recovery를 사용하면 지역 재해 복구 및 비즈니스 연속성을 위해 VM을 다른 Azure 지역에 복제할 수 있습니다. Azure Site Recovery를 사용하여 원본 지역 중단 시 앱을 복구하거나 정기적인 재해 복구 훈련을 수행하여 규정 준수 요구 사항을 충족할 수 있습니다.
앱이 Azure Site Recovery를 지원하는 경우 앱의 중요도에 필요하다면 보호 강화를 위해 지역 DR 솔루션을 제공할 수 있습니다. 그러나 앱이 데이터 센터 오류에 완전히 탄력적이라면 가동 중지 시간이나 데이터 손실이 없어야 하므로 영역 간, 데이터 센터 간 HA만으로도 충분한 보호가 될 수 있습니다.
비용 최적화
AZ에 배포된 VM에 대한 추가 비용은 없습니다. AZ 간 VM 간 데이터 전송 요금이 추가로 청구될 수 있습니다. 자세한 내용은 대역폭 가격 책정 페이지를 참조하세요.
참가자
Microsoft에서 이 문서를 유지 관리합니다. 원래 다음 기여자가 작성했습니다.
보안 주체 작성자:
- Shaun Croucher | 선임 컨설턴트