CQRS는 데이터 저장소에 대한 읽기 및 업데이트 작업을 구분하는 패턴인 명령과 쿼리의 역할 분리를 의미합니다. 애플리케이션에서 CQRS를 구현하면 성능, 확장성 및 보안을 최대화할 수 있습니다. CQRS로 마이그레이션하면 유연성이 생기므로 시스템이 점점 진화하고 업데이트 명령이 도메인 수준에서 병합 충돌을 일으키지 않도록 할 수 있습니다.
컨텍스트 및 문제점
기존 아키텍처에서 데이터베이스를 쿼리하고 업데이트하는 데 동일한 데이터 모델을 사용합니다. 그러면 간단하고 기본적인 CRUD 작업에 적합합니다. 그러나 더 복잡한 애플리케이션에서는 이 방법을 사용하기 어려울 수 있습니다. 예를 들어 애플리케이션은 읽기 쪽에서 다른 쿼리를 수행할 수 있습니다. 그러면 모양이 다른 DTO(데이터 전송 개체)를 반환합니다. 개체 매핑이 복잡해 질 수 있습니다. 모델은 쓰기 쪽에서 복잡한 유효성 검사 및 비즈니스 논리를 구현할 수 있습니다. 따라서 너무 많은 작업을 수행하는 과도하게 복잡한 모델이 될 수 있습니다.
읽기 및 쓰기 워크로드는 매우 다른 성능 및 확장성 요구 사항을 포함하여 종종 비대칭입니다.
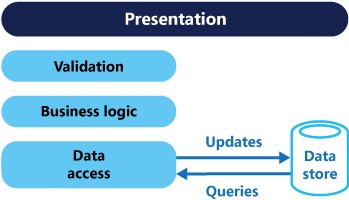
작업의 일부로 필요하지 않더라도 정확하게 업데이트되어야만 하는 추가 열이나 속성과 같이 데이터의 읽기와 쓰기 표현 사이에 불일치가 나타나는 경우가 있습니다.
동일한 데이터 세트에서 작업을 병렬로 수행할 때 데이터 경합이 발생할 수 있습니다.
기존의 접근 방식은 데이터 저장소와 데이터 액세스 계층에 가해지는 부하뿐 아니라 정보를 검색하는 데 필요한 쿼리의 복잡성으로 인해 성능에 좋지 않은 영향을 미칠 수 있습니다.
엔터티 각각이 읽기와 쓰기 작업의 대상으로 잘못된 컨텍스트에 데이터를 노출시킬 수 있기 때문에 보안 및 권한 관리가 더 복잡해질 수 있습니다.
해결 방법
CQRS는 데이터를 업데이트하는 명령 및 데이터를 읽는 쿼리를 사용하여 읽기 및 쓰기를 다른 모델로 구분합니다.
- 명령은 데이터 중심이 아닌 작업을 기반으로 해야 합니다. ("ReservationStatus를 Reserved로 설정"하지 않고 "호텔 객실 예약") 이를 위해서는 사용자 상호 작용 스타일을 약간 변경해야 할 수 있습니다. 그 중 다른 부분은 더 자주 성공하도록 해당 명령을 처리하는 비즈니스 논리를 수정하는 것입니다. 이를 지원하는 한 가지 방법은 명령을 보내기 전에 클라이언트에서 몇 가지 유효성 검사 규칙을 실행하는 것입니다. 단추를 사용하지 않도록 설정하여 UI에서 이유를 설명하는 것입니다("남은 방 없음"). 이러한 방식으로 서버 쪽 명령 오류의 원인은 경합 조건(마지막 방을 예약하려는 두 명의 사용자)으로 좁힐 수 있으며, 경우에 따라 더 많은 데이터와 논리를 사용하여 해결할 수 있습니다(대기자 목록에 게스트 배치).
- 명령은 동기적으로 처리되지 않고 비동기 처리를 위해 큐에 배치될 수 있습니다.
- 쿼리는 데이터베이스를 수정하지 않습니다. 쿼리는 도메인 정보를 캡슐화하지 않는 DTO를 반환합니다.
그런 다음, 이 모델을 아래 다이어그램과 같이 분리할 수 있는데 반드시 분리해야 하는 것은 아닙니다.
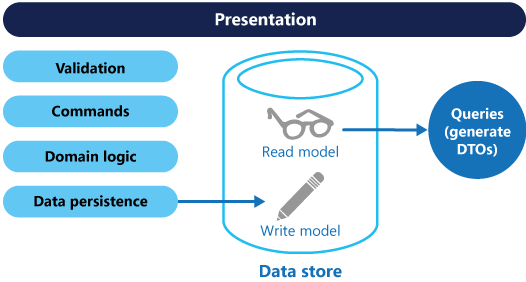
별도의 쿼리 및 업데이트 모델을 사용하면 디자인 및 구현이 간소화됩니다. 그러나 한 가지 단점은 O/RM 도구와 같은 스캐폴딩 메커니즘을 사용하여 데이터베이스 스키마에서 CQRS 코드를 자동으로 생성할 수 없다는 것입니다(그러나 생성된 코드 위에 사용자 지정을 빌드할 수 있습니다).
더 높은 격리 수준을 위해 쓰기 데이터에서 읽기 데이터를 물리적으로 구분할 수 있습니다. 이 경우에 읽기 데이터베이스는 쿼리에 대해 최적화된 고유한 데이터 스키마를 사용할 수 있습니다. 예를 들어 복잡한 조인이나 복잡한 O/RM 매핑을 방지하기 위해 데이터의 구체화된 뷰를 저장할 수 있습니다. 다른 유형의 데이터 저장소도 사용할 수 있습니다. 예를 들어 쓰기 데이터베이스가 관계형일 수 있는 반면 읽기 데이터베이스는 문서 데이터베이스입니다.
별도 읽기 및 쓰기 데이터베이스를 사용하는 경우 동기화를 유지해야 합니다. 일반적으로 데이터베이스를 업데이트할 때마다 쓰기 모델에서 이벤트를 게시함으로써 수행됩니다. 이벤트 사용에 대한 자세한 내용은 이벤트 기반 아키텍처 스타일을 참조하세요. 메시지 브로커 및 데이터베이스는 일반적으로 단일 분산 트랜잭션에 등록할 수 없으므로 데이터베이스를 업데이트하고 이벤트를 게시할 때 일관성을 보장하는 데 문제가 있을 수 있습니다. 자세한 내용은 idempotent 메시지 처리에 대한 지침을 참조하세요.
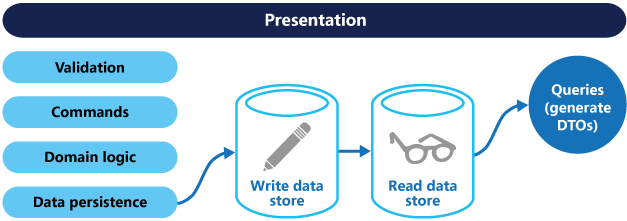
읽기 저장소는 쓰기 저장소의 읽기 전용 복제본이거나 읽기 및 쓰기 저장소가 전혀 다른 구조일 수 있습니다. 읽기 전용 복제본을 여러 개 사용하면 특히 읽기 전용 복제본이 애플리케이션 인스턴스에 가깝게 위치하는 분산 시나리오에서 쿼리 성능을 높일 수 있습니다.
읽기 및 쓰기 저장소를 분리하면 부하를 감안해 각 저장소를 적절하게 확장할 수도 있습니다. 예를 들어 보통 읽기 저장소는 쓰기 저장소보다 부하가 훨씬 더 높습니다.
CQRS의 일부 구현에서는 이벤트 소싱 패턴을 사용합니다. 이러한 패턴에서 애플리케이션 상태는 이벤트의 시퀀스로 저장됩니다. 각 이벤트는 데이터에 대한 변경 집합을 나타냅니다. 현재 상태는 이벤트를 재생함으로써 구축됩니다. CQRS 컨텍스트에서 이벤트 소싱의 이점 중 하나는 다른 구성 요소를 알리는 데 동일한 이벤트를 사용할 수 있다는 점입니다. 특히 읽기 모델에 알립니다. 읽기 모델은 현재 상태의 스냅샷을 만드는 데 이벤트를 사용합니다. 이것이 쿼리에 보다 효과적입니다. 그러나 이벤트 소싱은 디자인에 복잡성을 추가합니다.
CQRS의 이점은 다음과 같습니다.
- 독립적인 크기 조정 CQRS를 통해 읽기 및 쓰기 워크로드를 독립적으로 확장하고 더 적은 수의 잠금 경합이 발생할 수 있습니다.
- 최적화된 데이터 스키마. 읽기 쪽에서는 쿼리에 최적화된 스키마를 사용하는 반면 쓰기 쪽에서는 업데이트에 최적화된 스키마를 사용할 수 있습니다.
- 보안. 올바른 도메인 엔터티만 데이터에서 쓰기를 수행할 수 있는지 쉽게 확인할 수 있습니다.
- 관심사의 분리. 읽기 및 쓰기 쪽을 구분하면 유지 가능하고 유연한 모델을 생성할 수 있습니다. 대부분의 복잡한 비즈니스 논리는 쓰기 모델로 이동합니다. 읽기 모델은 상대적으로 간단할 수 있습니다.
- 단순한 쿼리 읽기 데이터베이스에서 구체화된 뷰를 저장하여 쿼리할 때 애플리케이션은 복잡한 조인을 방지할 수 있습니다.
구현 문제 및 고려 사항
이 패턴을 구현하는 몇 가지 과제는 다음과 같습니다.
복잡성. CQRS의 기본 개념은 간단합니다. 하지만 이벤트 소싱 패턴을 포함하는 경우에 특히 더 복잡한 애플리케이션 디자인을 만들 수 있습니다.
메시징 CQRS에 메시징이 필요하지 않지만 명령을 처리하고 업데이트 이벤트를 게시하는 데 공통적으로 메시징을 사용합니다. 이 경우에 애플리케이션은 메시지 오류 또는 중복 메시지를 처리해야 합니다. 우선 순위가 다른 명령을 처리하기 위한 우선 순위 큐에 대한 참고 자료를 참조하세요.
결과적 일관성 읽기 및 쓰기 데이터베이스를 구분하는 경우 읽기 데이터는 기한이 경과되었을 수 있습니다. 읽기 모델 저장소는 쓰기 모델 저장소의 변경 사항을 반영하도록 업데이트되어야 합니다. 사용자가 오래된 읽기 데이터를 기반으로 요청을 발급하면 변경된 사항을 검색하기 어려울 수 있습니다.
CQRS 패턴을 사용하는 경우
다음 시나리오에 대해 CQRS를 고려하세요.
많은 사용자가 동일한 데이터에 병렬로 액세스하는 협업 도메인 CQRS를 사용하면 도메인 수준에서 병합 충돌 및 충돌이 발생할 때 명령으로 병합할 수 있는 충돌을 최소화할 수 있을 정도로 자세하게 명령을 정의할 수 있습니다.
여러 단계를 거치거나 복잡한 도메인 모델을 사용하는 복잡한 프로세스를 통해 사용자를 안내하는 작업 기반 사용자 인터페이스. 쓰기 모델에는 비즈니스 논리, 입력 유효성 검사 및 비즈니스 유효성 검사가 포함된 전체 명령 처리 스택이 있습니다. 쓰기 모델은 데이터 변경(DDD 용어의 집계)에 대한 단일 단위로 연결된 개체 세트를 처리하고 이러한 개체가 항상 일관된 상태인지 확인할 수 있습니다. 읽기 모델은 비즈니스 논리 또는 유효성 검사 스택을 보유하지 않으며 보기 모델에 사용할 DTO를 반환하기만 합니다. 결과적으로 읽기 모델과 쓰기 모델의 일관성이 유지됩니다.
특히 읽기 수가 쓰기 수보다 훨씬 큰 경우 데이터 읽기의 성능을 데이터 쓰기 성능과 별도로 미세 조정해야 하는 시나리오입니다. 이 시나리오에서는 읽기 모델을 스케일 아웃할 수 있지만 몇 가지 인스턴스에서만 쓰기 모델을 실행할 수 있습니다. 소수의 쓰기 모델 인스턴스는 병합 충돌 발생을 최소화하는 데도 기여합니다.
개발자 중 한 팀은 쓰기 모델에 포함되는 복잡한 도메인 모델에 집중하고 또 한 팀은 읽기 모델과 사용자 인터페이스에 집중할 수 있는 시나리오.
시스템이 시간이 지나면서 진화할 것으로 예상되어 여러 버전의 모델을 포함할 수 있거나 비즈니스 규칙이 정기적으로 변하는 시나리오
특히 이벤트 소싱과 조합해 다른 시스템과 통합하는 경우. 이때 하위 시스템 하나의 일시적인 장애가 다른 시스템의 가용성에 영향을 주지 않아야 합니다.
다음과 같은 경우 이 패턴이 권장되지 않습니다.
도메인 또는 비즈니스 규칙이 간단합니다.
간단한 CRUD 스타일 사용자 인터페이스 및 데이터 액세스 작업이 충분합니다.
가장 가치 있는 시스템의 제한된 구역에 CQRS 적용을 고려해야 합니다.
워크로드 디자인
설계자는 워크로드 디자인에서 CQRS 패턴을 사용하여 Azure Well-Architected Framework 핵심 요소에서 다루는 목표와 원칙을 해결하는 방법을 평가해야 합니다. 예시:
| 핵심 요소 | 이 패턴이 핵심 목표를 지원하는 방법 |
|---|---|
| 성능 효율성은 크기 조정, 데이터, 코드의 최적화를 통해 워크로드가 수요를 효율적으로 충족하는 데 도움이 됩니다. | 높은 읽기-쓰기 워크로드에서 읽기 및 쓰기 작업을 분리하면 각 작업의 특정 목적에 대한 대상 성능 및 크기 조정 최적화가 가능합니다. - PE:05 크기 조정 및 분할 - PE:08 데이터 성능 |
디자인 결정과 마찬가지로 이 패턴으로 도입될 수 있는 다른 핵심 요소의 목표에 대한 절충을 고려합니다.
이벤트 소싱 및 CQRS 패턴
CQRS 패턴은 이벤트 소싱 패턴과 함께 사용되는 경우가 많습니다. CQRS 기반 시스템은 별도의 읽기 및 쓰기 데이터 모델을 사용하며 각각 관련 작업에 맞춤화되고 종종 물리적으로 분리된 저장소에 배치됩니다. 이벤트 소싱 패턴과 함께 사용할 때 이벤트 저장소는 쓰기 모델이며 정보의 공식적인 출처입니다. 보통 CQRS 기반 시스템의 읽기 모델은 고도로 비정규화된 뷰의 형태로 데이터의 구체화된 뷰를 제공합니다. 이러한 뷰는 애플리케이션의 인터페이스 및 디스플레이 요구 사항에 맞춤화되어 디스플레이 및 쿼리 성능을 모두 최대화하는 데 기여합니다.
특정 시점의 실제 데이터 대신 이벤트의 스트림을 쓰기 저장소로 사용하면 단일 집계에서 업데이트 충돌을 방지하고 성능과 확장성을 최대화할 수 있습니다. 읽기 저장소를 채우는 데 사용하는 데이터의 구체화된 뷰를 비동기적으로 생성하는 데 이벤트를 사용할 수 있습니다.
이벤트 저장소는 정보의 공식적인 출처이기 때문에, 시스템이 진화하거나 읽기 모델을 변경해야 할 때 구체화된 뷰를 삭제하고 모든 지난 이벤트를 재생해 현재 상태의 새로운 표현을 생성할 수 있습니다. 사실상 구체화된 뷰는 데이터의 지속형 읽기 전용 캐시입니다.
CQRS를 이벤트 소싱 패턴과 함께 사용할 때는 다음을 고려해야 합니다.
쓰기 및 읽기 저장소가 분리되는 시스템처럼 이 패턴을 기반으로 하는 시스템만이 결과적으로 일관성을 유지할 수 있습니다. 생성되는 이벤트와 업데이트되는 데이터 저장소 사이에는 약간의 지연이 나타나게 됩니다.
이벤트를 시작하고 처리하며 쿼리나 읽기 모델에 필요한 적절한 뷰 또는 개체를 어셈블하거나 업데이트하는 코드를 생성해야 하기 때문에, 이벤트 소싱 패턴은 더 복잡합니다. CQRS 패턴을 이벤트 소싱 패턴과 함께 사용하는 경우 패턴이 복잡하기 때문에 성공적으로 구현하는 것이 더 어려워질 수 있으므로 시스템 디자인에 대한 다른 접근 방식이 필요합니다. 그러나 이벤트 소싱은 도메인을 더 쉽게 모델링할 수 있고 데이터를 변경한 의도가 보존되기 때문에 뷰를 다시 작성하거나 새로 만들기가 더 쉽습니다.
특정 엔터티 또는 엔터티 모음을 위한 이벤트를 재생하고 처리하여 데이터의 읽기 모델 또는 프로젝션에 사용할 구체화된 뷰를 생성하려면 상당한 처리 시간과 리소스 사용이 필요할 수 있습니다. 장기간 값의 합계 또는 분석이 필요한 경우에 특히 그런데 그 이유는 관련된 모든 이벤트를 검사해야 하기 때문입니다. 이 문제는 발생한 특정 동작의 총 개수 또는 엔터티의 현재 상태와 같이 예약된 간격으로 데이터의 스냅샷을 구현해 해결할 수 있습니다.
CQRS 패턴의 예제
다음 코드는 읽기 모델과 쓰기 모델에 다른 정의를 사용하는 CQRS 구현의 예제 중 일부를 보여 줍니다. 모델 인터페이스는 기본 데이터 저장소의 기능을 지정하지 않고 진화할 수 있으며 분리되기 있기 때문에 독립적으로 세밀하게 조정할 수 있습니다.
다음 코드는 읽기 모델 정의를 보여줍니다.
// Query interface
namespace ReadModel
{
public interface ProductsDao
{
ProductDisplay FindById(int productId);
ICollection<ProductDisplay> FindByName(string name);
ICollection<ProductInventory> FindOutOfStockProducts();
ICollection<ProductDisplay> FindRelatedProducts(int productId);
}
public class ProductDisplay
{
public int Id { get; set; }
public string Name { get; set; }
public string Description { get; set; }
public decimal UnitPrice { get; set; }
public bool IsOutOfStock { get; set; }
public double UserRating { get; set; }
}
public class ProductInventory
{
public int Id { get; set; }
public string Name { get; set; }
public int CurrentStock { get; set; }
}
}
시스템에서 사용자가 제품을 평가하는 것을 허용합니다. 애플리케이션 코드는 다음 코드에 제시된 RateProduct 명령을 사용하여 제품을 평가합니다.
public interface ICommand
{
Guid Id { get; }
}
public class RateProduct : ICommand
{
public RateProduct()
{
this.Id = Guid.NewGuid();
}
public Guid Id { get; set; }
public int ProductId { get; set; }
public int Rating { get; set; }
public int UserId {get; set; }
}
시스템이 ProductsCommandHandler 클래스를 사용하여 애플리케이션이 전송한 명령을 처리합니다. 일반적으로 클라이언트는 큐와 같은 메시징 시스템을 통해 명령을 도메인에 보냅니다. 명령 처리기는 이러한 명령을 수락하고 도메인 인터페이스의 메서드를 호출합니다. 요청이 충돌할 가능성이 줄어들도록 세분화된 각 명령이 디자인됩니다. 다음 코드는 ProductsCommandHandler 클래스의 개요를 보여 줍니다.
public class ProductsCommandHandler :
ICommandHandler<AddNewProduct>,
ICommandHandler<RateProduct>,
ICommandHandler<AddToInventory>,
ICommandHandler<ConfirmItemShipped>,
ICommandHandler<UpdateStockFromInventoryRecount>
{
private readonly IRepository<Product> repository;
public ProductsCommandHandler (IRepository<Product> repository)
{
this.repository = repository;
}
void Handle (AddNewProduct command)
{
...
}
void Handle (RateProduct command)
{
var product = repository.Find(command.ProductId);
if (product != null)
{
product.RateProduct(command.UserId, command.Rating);
repository.Save(product);
}
}
void Handle (AddToInventory command)
{
...
}
void Handle (ConfirmItemsShipped command)
{
...
}
void Handle (UpdateStockFromInventoryRecount command)
{
...
}
}
다음 단계
이 패턴을 구현할 때 유용한 패턴 및 지침은 다음과 같습니다.
Data Consistency Primer(데이터 일관성 입문서). CQRS 패턴을 사용할 때 읽기 및 쓰기 데이터 저장소 간의 결과적 일관성 때문에 일반적으로 발생하는 문제와 이러한 문제의 해결 방법을 설명합니다.
수평, 수직 및 기능별 데이터 분할 데이터를 개별적으로 관리 및 액세스할 수 있는 파티션으로 분할하여 확장성을 개선하고 경합을 줄이며 성능을 최적화하는 모범 사례를 설명합니다.
패턴 및 사례는 CQRS 여정을 안내합니다. 특히 명령 쿼리 역할 분리 패턴 소개에서는 패턴 및 유용한 경우를 살펴보며 에필로그: 교훈은 이 패턴을 사용할 때 발생하는 문제 중 일부를 이해하는 데 도움이 됩니다.
Martin Fowler의 블로그 게시물: