이 문서에서는 개발 팀이 메트릭을 사용하여 병목 현상을 찾고 분산 시스템의 성능을 개선하는 방법을 설명합니다. 이 문서는 샘플 애플리케이션에 대해 수행된 실제 부하 테스트를 기반으로 합니다. 애플리케이션은 결과를 생성하는 데 사용되는 Visual Studio 부하 테스트 프로젝트와 함께 마이크로 서비스용 AKS(Azure Kubernetes Service) Baseline에서 가져온 것입니다.
이 문서는 시리즈의 일부입니다. 여기에서 첫 번째 부분을 참조하세요.
시나리오: 여러 백 엔드 서비스를 호출하여 정보를 검색한 다음 결과를 집계합니다.
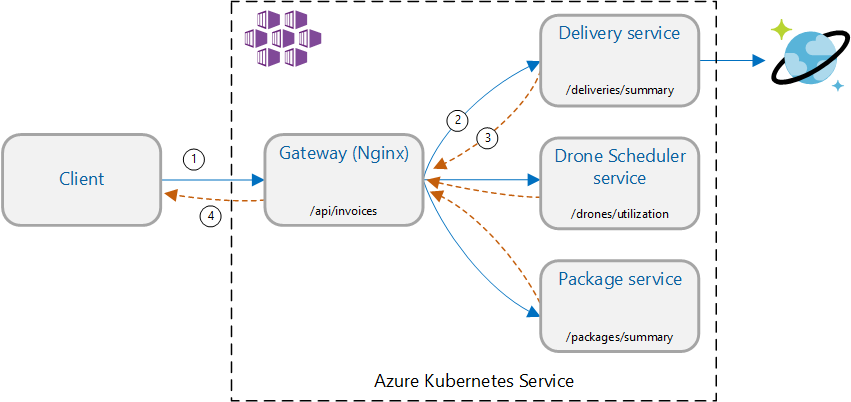
이 시나리오에는 드론 배달 애플리케이션이 포함됩니다. 클라이언트는 REST API를 쿼리하여 최신 청구서 정보를 가져올 수 있습니다. 청구서에는 고객의 배달, 패키지 및 총 드론 활용에 대한 요약이 포함됩니다. 이 애플리케이션은 AKS에서 실행되는 마이크로 서비스 아키텍처를 사용하며 청구서에 필요한 정보는 여러 마이크로 서비스에 분산되어 있습니다.
클라이언트가 각 서비스를 직접 호출하는 대신 애플리케이션이 게이트웨이 집계 패턴을 구현합니다. 이 패턴을 사용하여 클라이언트는 게이트웨이 서비스에 단일 요청을 수행합니다. 그러면 게이트웨이가 백 엔드 서비스를 병렬로 호출한 다음 결과를 단일 응답 페이로드로 집계합니다.
테스트 1: 기본 성능
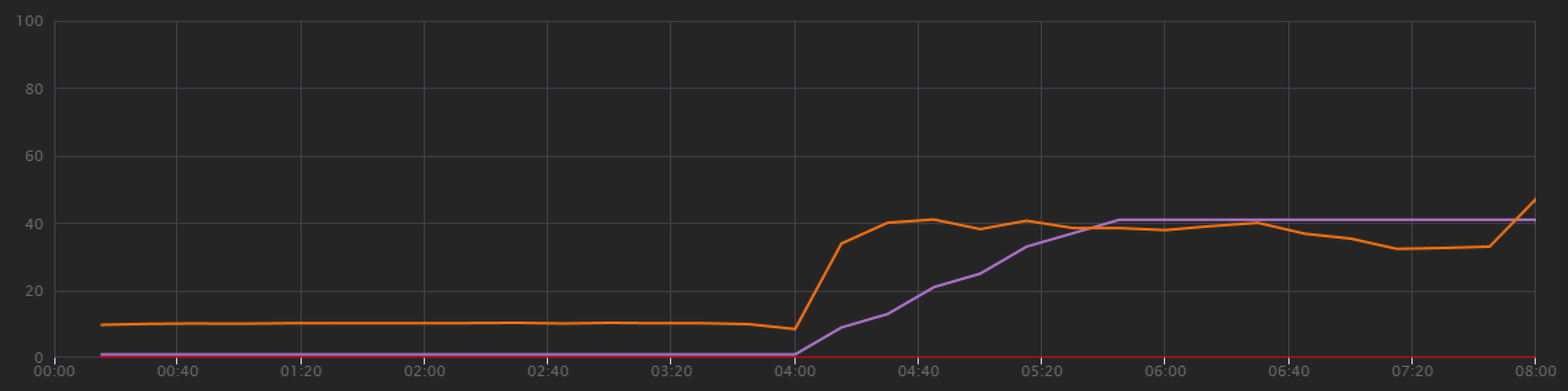
기준을 설정하기 위해 개발 팀은 총 8분 동안 한 명의 시뮬레이트된 사용자에서 최대 40명의 사용자까지 로드를 램핑하는 단계별 부하 테스트로 시작했습니다. Visual Studio에서 가져온 다음 차트는 결과를 보여 줍니다. 자주색 선은 사용자 부하를 나타내고 주황색 선은 처리량(초당 평균 요청 수)을 나타냅니다.
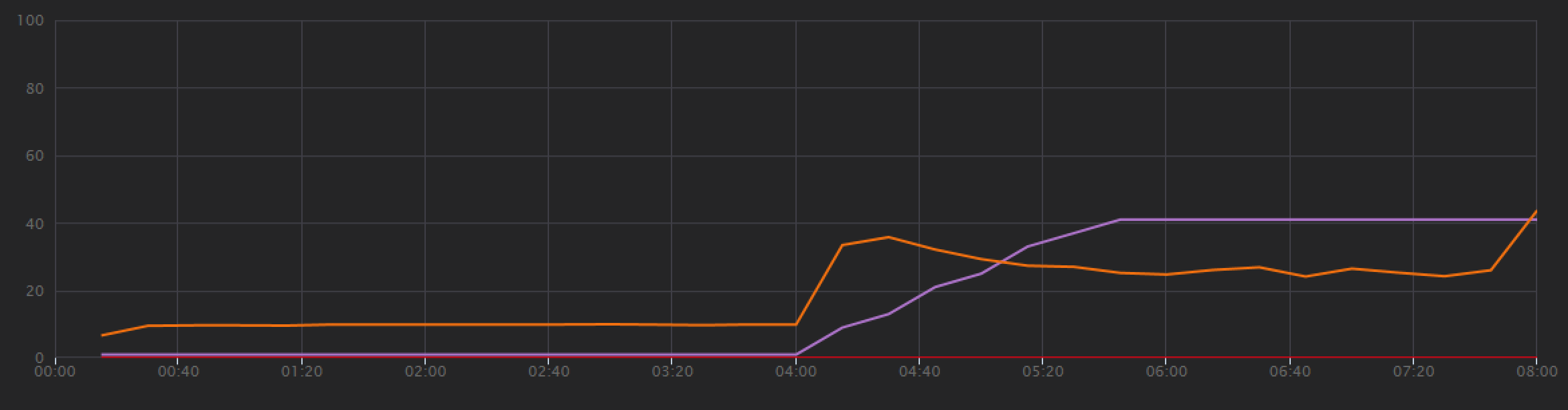
차트 하단의 빨간색 선은 클라이언트에 반환된 오류가 없음을 보여 주며, 이는 권장하는 결과입니다. 그러나 평균 처리량은 테스트 중간쯤에 최고조에 달한 다음 로드가 계속 증가하는 동안에도 나머지 부분에서 떨어집니다. 이는 백 엔드가 따라갈 수 없음을 나타냅니다. 여기에서 볼 수 있는 패턴은 시스템이 리소스 제한에 도달하기 시작할 때 일반적입니다. 즉, 최댓값에 도달한 후 실제로 처리량이 크게 떨어집니다. 리소스 경합, 일시적인 오류 또는 예외 비율의 증가는 모두 이 패턴에 기여할 수 있습니다.
시스템 내부에서 무슨 일이 일어나고 있는지 알아보기 위해 모니터링 데이터를 자세히 살펴보겠습니다. 다음 차트는 Application Insights에서 가져온 것입니다. 게이트웨이에서 백 엔드 서비스로의 HTTP 호출의 평균 지속 시간을 보여 줍니다.
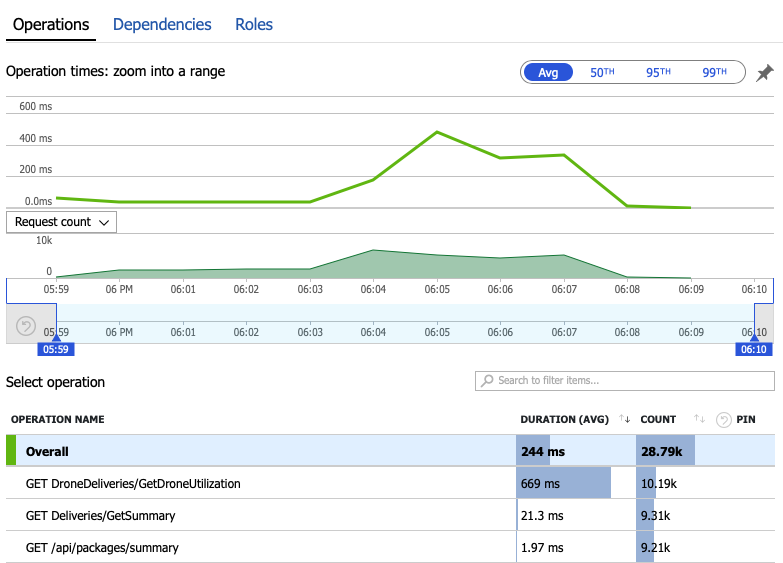
이 차트는 특히 GetDroneUtilization 작업이 평균적으로 훨씬 더 오래 걸린다는 것을 보여 줍니다. 게이트웨이는 이러한 호출을 병렬로 수행하므로 가장 느린 작업에 따라 전체 요청을 완료하는 데 걸리는 시간이 결정됩니다.
분명히 다음 단계는 GetDroneUtilization 작업을 자세히 살펴보고 병목 현상을 찾는 것입니다. 한 가지 가능성은 리소스 소진입니다. 아마도 이 특정 백 엔드 서비스는 CPU나 메모리가 부족할 것입니다. AKS 클러스터의 경우 이 정보는 Azure Monitor 컨테이너 인사이트 기능을 통해 Azure Portal에서 사용할 수 있습니다. 다음 그래프는 클러스터 수준의 리소스 사용률을 보여 줍니다.
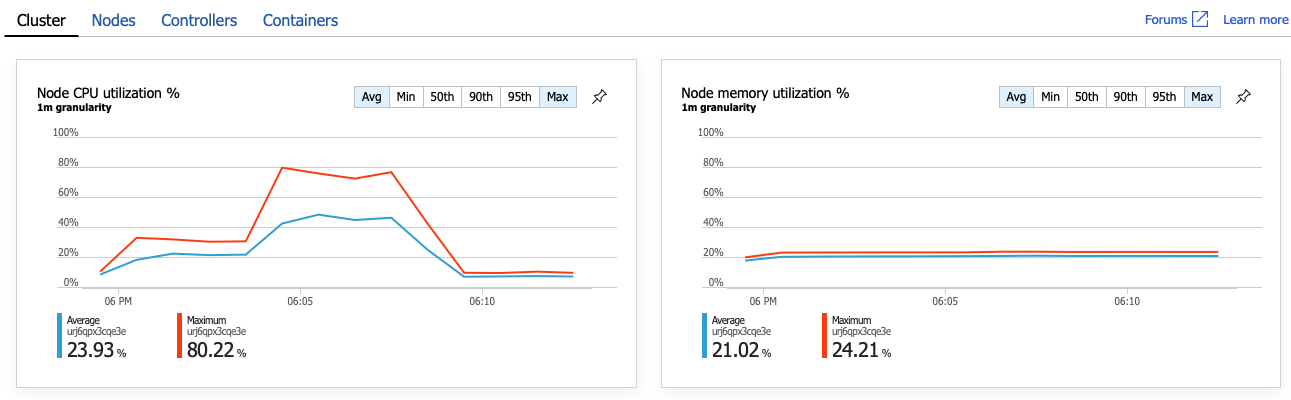
이 스크린샷에는 평균값과 최댓값이 모두 표시됩니다. 평균은 데이터의 급증을 숨길 수 있기 때문에 평균 이상을 살펴보는 것이 중요합니다. 여기에서 평균 CPU 사용률은 50% 미만으로 유지되지만 80%까지 몇 차례 급증했습니다. 이는 용량에 가깝지만 여전히 허용 오차 내에 있습니다. 병목 현상을 일으키는 다른 원인이 있습니다.
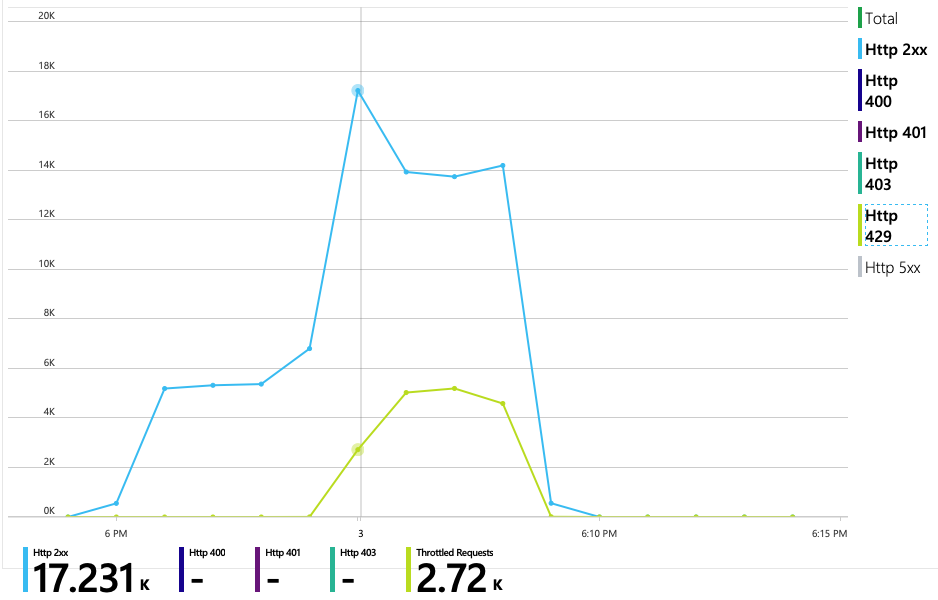
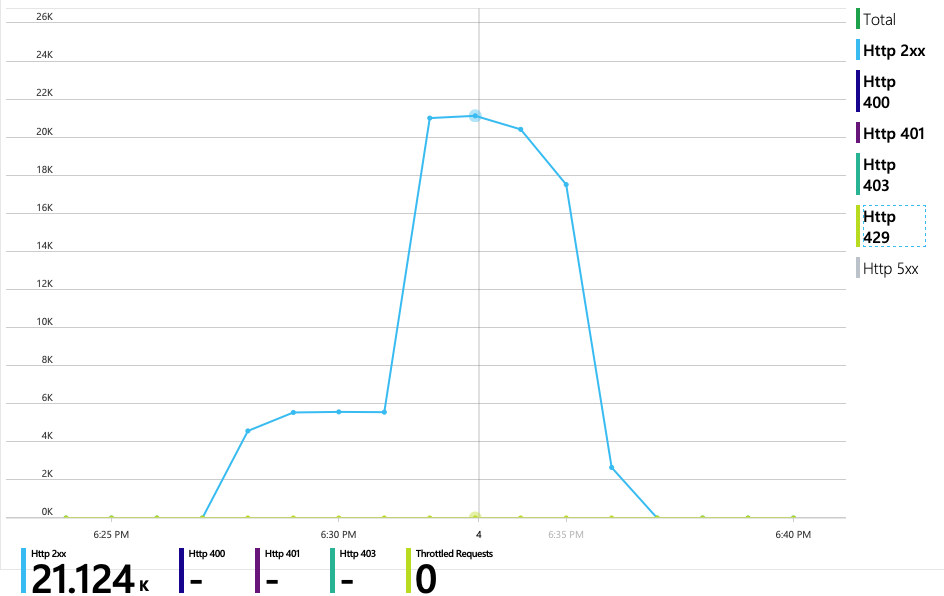
다음 차트는 진정한 문제를 보여 줍니다. 이 차트는 배달 서비스의 백 엔드 데이터베이스(이 경우 Azure Cosmos DB)의 HTTP 응답 코드를 보여 줍니다. 파란색 선은 성공 코드(HTTP 2xx)를 나타내고 녹색 선은 HTTP 429 오류를 나타냅니다. HTTP 429 반환 코드는 호출자가 프로비전된 것보다 더 많은 RU(리소스 단위)를 소비하기 때문에 Azure Cosmos DB가 일시적으로 요청을 제한하고 있음을 의미합니다.
추가 정보를 가져오기 위해 개발 팀은 Application Insights를 사용하여 대표적인 요청 샘플에 대한 엔드투엔드 원격 분석을 확인했습니다. 다음은 한 가지 예입니다.
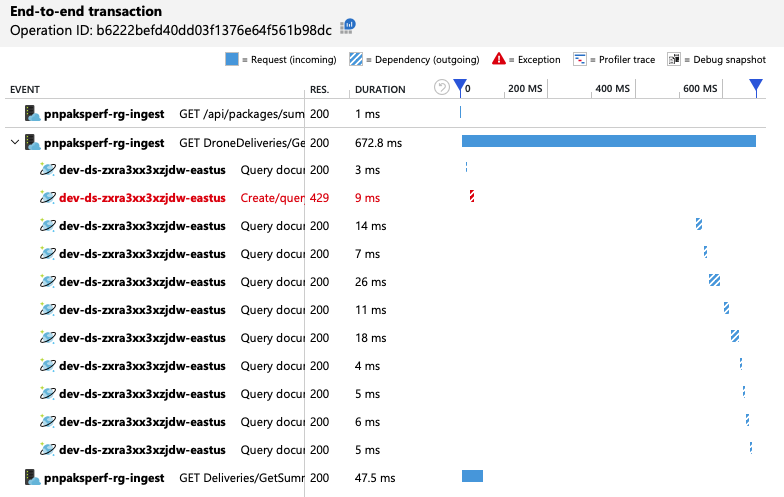
이 보기는 타이밍 정보 및 응답 코드와 함께 단일 클라이언트 요청과 관련된 호출을 표시합니다. 최상위 호출은 게이트웨이에서 백 엔드 서비스로의 호출입니다. GetDroneUtilization에 대한 호출은 외부 종속성에 대한 호출(이 경우 Azure Cosmos DB에 대한 호출)을 표시하도록 확장됩니다. 빨간색 호출은 HTTP 429 오류를 반환했습니다.
HTTP 429 오류와 다음 호출 사이의 큰 간격에 유의합니다. Azure Cosmos DB 클라이언트 라이브러리가 HTTP 429 오류를 수신하면 자동으로 백오프하고 작업을 다시 시도할 때까지 기다립니다. 이 보기에서 보여 주는 것은 이 작업에 소요된 672ms 동안 대부분의 시간이 Azure Cosmos DB를 다시 시도하기 위해 대기하는 데 사용되었다는 것입니다.
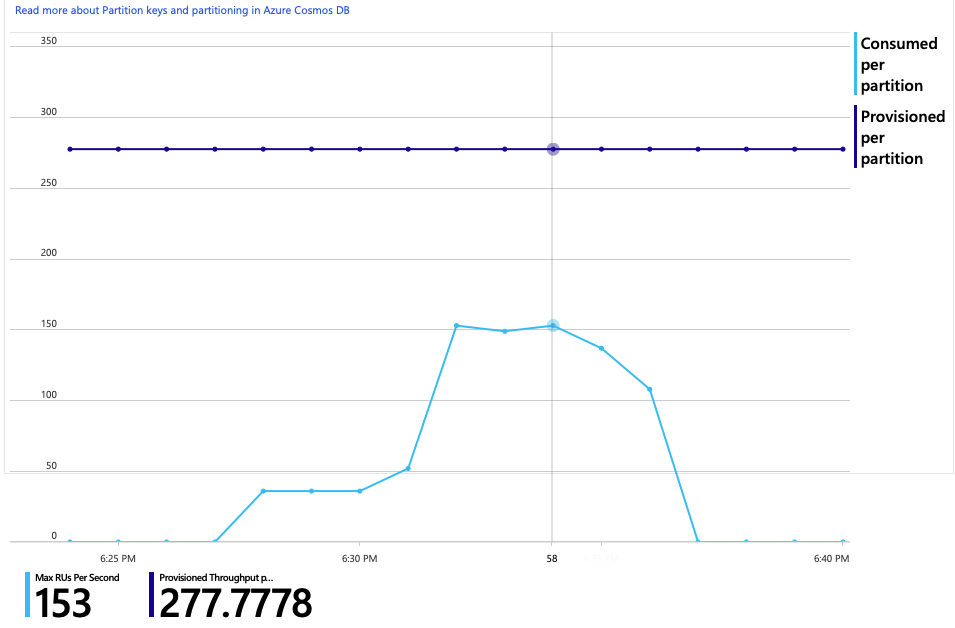
이 분석에 대한 또 다른 흥미로운 그래프가 있습니다. 실제 파티션당 RU 사용량 대 실제 파티션당 프로비전된 RU를 보여 줍니다.
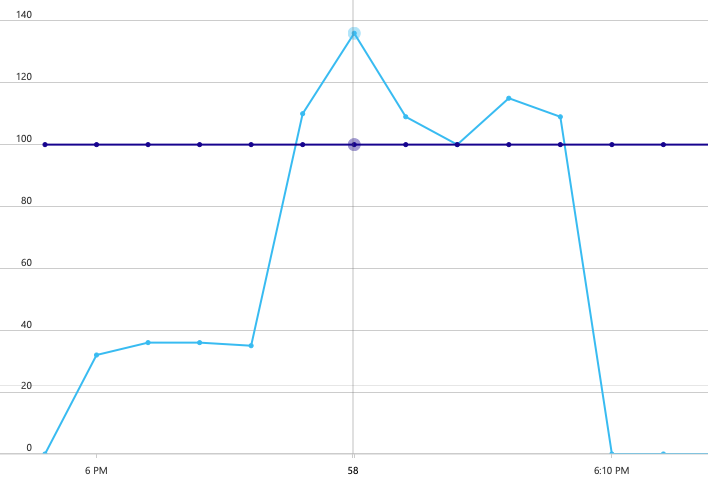
이 그래프를 이해하려면 Azure Cosmos DB가 파티션을 관리하는 방법을 이해해야 합니다. Azure Cosmos DB의 컬렉션에는 파티션 키가 있을 수 있습니다. 가능한 각 키 값은 컬렉션 내 데이터의 논리적 파티션을 정의합니다. Azure Cosmos DB는 이러한 논리적 파티션을 하나 이상의 실제 파티션에 분산합니다. 실제 파티션 관리는 Azure Cosmos DB에서 자동으로 처리됩니다. 더 많은 데이터를 저장함에 따라 Azure Cosmos DB는 실제 파티션 간에 로드를 분산하기 위해 논리 파티션을 새 실제 파티션으로 이동할 수 있습니다.
이 부하 테스트를 위해 Azure Cosmos DB 컬렉션은 900RU로 프로비전되었습니다. 차트에는 실제 파티션당 100RU가 표시되며 이는 총 9개의 실제 파티션을 의미합니다. Azure Cosmos DB는 실제 파티션의 분할을 자동으로 처리하지만 파티션 수를 알면 성능에 대한 인사이트를 얻을 수 있습니다. 개발 팀은 나중에 최적화를 계속하면서 이 정보를 사용할 것입니다. 파란색 선이 자주색 가로선을 교차하는 위치에서 RU 사용량이 프로비전된 RU를 초과했습니다. 여기가 Azure Cosmos DB가 호출을 제한하기 시작하는 지점입니다.
테스트 2: 리소스 단위 증가
두 번째 부하 테스트를 위해 팀은 Azure Cosmos DB 컬렉션을 900RU에서 2500RU로 크기 조정했습니다. 처리량은 초당 19개 요청에서 초당 23개 요청으로 증가했고 평균 대기 시간은 669ms에서 569ms로 떨어졌습니다.
| 메트릭 | 테스트 1 | 테스트 2 |
|---|---|---|
| 처리량(요청/초) | 19 | 23 |
| 평균 대기 시간(밀리초) | 669 | 569 |
| 성공한 요청 | 9.8K | 11K |
이는 큰 이득은 아니지만 시간이 지남에 따라 그래프를 보면 더 완전한 그림을 볼 수 있습니다.
이전 테스트에서는 초기 급상승 후 급격하게 감소하는 것으로 나타났지만 이 테스트에서는 보다 일관된 처리량을 보여 줍니다. 그러나 최대 처리량은 크게 높지 않습니다.
Azure Cosmos DB에 대한 모든 요청이 2xx 상태를 반환했고 HTTP 429 오류가 사라졌습니다.
RU 사용량과 프로비전된 RU의 그래프는 충분한 헤드룸이 있음을 보여 줍니다. 실제 파티션당 약 275RU가 있으며 부하 테스트는 초당 약 100RU를 소비했습니다.
또 다른 흥미로운 메트릭은 성공적인 작업당 Azure Cosmos DB에 대한 호출 수입니다.
| 메트릭 | 테스트 1 | 테스트 2 |
|---|---|---|
| 작업당 호출 | 11 | 9 |
오류가 없다고 가정하면 호출 수는 실제 쿼리 계획과 일치해야 합니다. 이 경우 작업에는 9개의 실제 파티션 모두에 도달하는 파티션 간 쿼리가 포함됩니다. 첫 번째 부하 테스트에서 더 높은 값은 429 오류를 반환한 호출 수를 반영합니다.
이 메트릭은 사용자 지정 Log Analytics 쿼리를 실행하여 계산되었습니다.
let start=datetime("2020-06-18T20:59:00.000Z");
let end=datetime("2020-07-24T21:10:00.000Z");
let operationNameToEval="GET DroneDeliveries/GetDroneUtilization";
let dependencyType="Azure DocumentDB";
let dataset=requests
| where timestamp > start and timestamp < end
| where success == true
| where name == operationNameToEval;
dataset
| project reqOk=itemCount
| summarize
SuccessRequests=sum(reqOk),
TotalNumberOfDepCalls=(toscalar(dependencies
| where timestamp > start and timestamp < end
| where type == dependencyType
| summarize sum(itemCount)))
| project
OperationName=operationNameToEval,
DependencyName=dependencyType,
SuccessRequests,
AverageNumberOfDepCallsPerOperation=(TotalNumberOfDepCalls/SuccessRequests)
요약하면 두 번째 부하 테스트에서 개선이 나타납니다. 그러나 GetDroneUtilization 작업은 여전히 다음으로 가장 느린 작업보다 훨씬 더 오래 걸립니다. 엔드투엔드 트랜잭션을 보면 그 이유를 설명하는 데 도움이 됩니다.
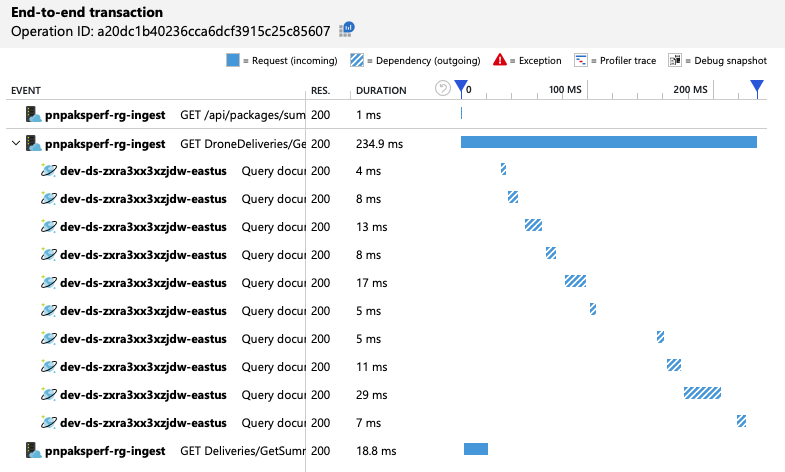
앞서 언급했듯이 GetDroneUtilization 작업에는 Azure Cosmos DB에 대한 파티션 간 쿼리가 포함됩니다. 즉, Azure Cosmos DB 클라이언트는 각 실제 파티션에 대한 쿼리를 팬아웃하고 결과를 수집해야 합니다. 엔드투엔드 트랜잭션 보기에서 볼 수 있듯이 이러한 쿼리는 순차적으로 수행됩니다. 이 작업은 모든 쿼리의 합계만큼 오래 걸리며, 이 문제는 데이터 크기가 커지고 실제 파티션이 더 추가될수록 악화됩니다.
테스트 3: 병렬 쿼리
이전 결과를 기반으로 대기 시간을 줄이는 확실한 방법은 쿼리를 병렬로 실행하는 것입니다. Azure Cosmos DB 클라이언트 SDK에는 최대 병렬 처리 수준을 제어하는 설정이 있습니다.
| 값 | 설명 |
|---|---|
| 0 | 병렬 처리 없음(기본값) |
| > 0 | 최대 병렬 호출 수 |
| -1 | 클라이언트 SDK는 최적의 병렬 처리 수준을 선택합니다. |
세 번째 부하 테스트의 경우 이 설정이 0에서 -1로 변경되었습니다. 다음 표에서는 이 결과를 요약합니다.
| 메트릭 | 테스트 1 | 테스트 2 | 테스트 3 |
|---|---|---|---|
| 처리량(요청/초) | 19 | 23 | 42 |
| 평균 대기 시간(밀리초) | 669 | 569 | 215 |
| 성공한 요청 | 9.8K | 11K | 20K |
| 제한된 요청 | 2.72K | 0 | 0 |
부하 테스트 그래프에서 전체 처리량이 훨씬 더 높을 뿐만 아니라(주황색 선) 처리량도 부하와 보조를 맞추었습니다(자주색 선).
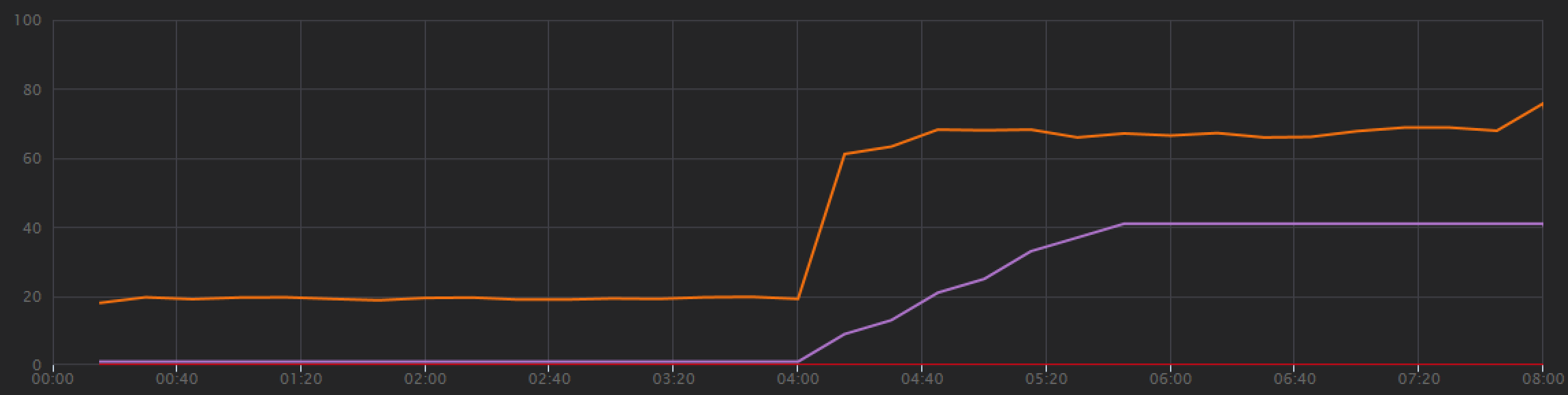
엔드투엔드 트랜잭션 보기를 확인하여 Azure Cosmos DB 클라이언트가 병렬로 쿼리를 만들고 있는지 확인할 수 있습니다.
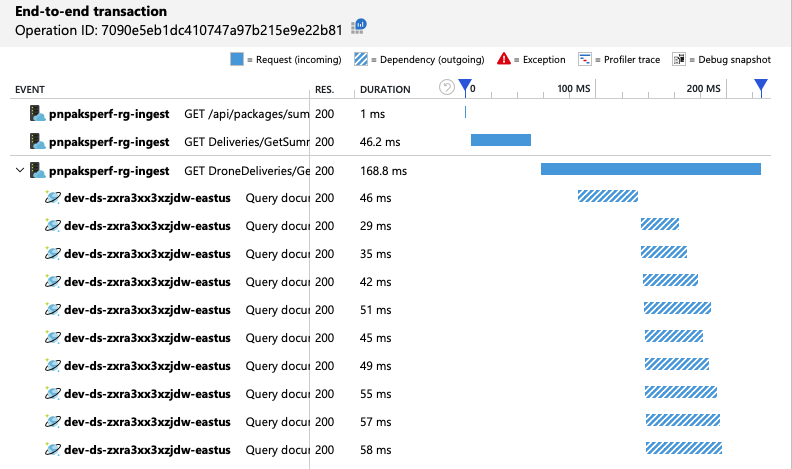
흥미롭게도 처리량 증가의 부작용은 초당 소비되는 RU 수도 증가한다는 것입니다. Azure Cosmos DB는 이 테스트 중에 요청을 제한하지 않았지만 사용량은 프로비전된 RU 제한에 가깝습니다.
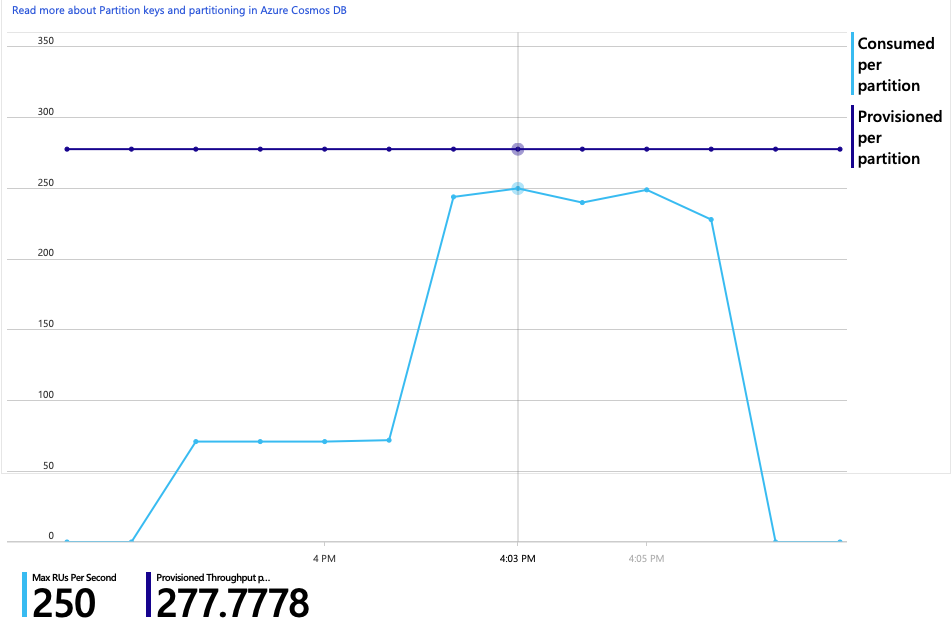
이 그래프는 데이터베이스를 더 스케일 아웃하라는 신호일 수 있습니다. 그러나 대신 쿼리를 최적화할 수 있음이 밝혀졌습니다.
4단계: 쿼리 최적화
이전 부하 테스트는 대기 시간 및 처리량 측면에서 더 나은 성능을 보여 주었습니다. 평균 요청 대기 시간은 68% 감소했고 처리량은 220% 증가했습니다. 그러나 파티션 간 쿼리가 문제입니다.
파티션 간 쿼리의 문제점은 모든 파티션에서 RU 비용을 지불한다는 것입니다. 쿼리가 가끔씩만 실행되는 경우(예: 한 시간에 한 번) 문제가 되지 않을 수 있습니다. 그러나 파티션 간 쿼리와 관련된 읽기 작업이 많은 워크로드를 볼 때마다 파티션 키를 포함하여 쿼리를 최적화할 수 있는지 여부를 확인해야 합니다. (다른 파티션 키를 사용하려면 컬렉션을 다시 설계해야 할 수도 있습니다.)
이 특정 시나리오에 대한 쿼리는 다음과 같습니다.
SELECT * FROM c
WHERE c.ownerId = <ownerIdValue> and
c.year = <yearValue> and
c.month = <monthValue>
이 쿼리는 특정 소유자 ID 및 월/연도와 일치하는 레코드를 선택합니다. 원래 디자인에서는 이러한 속성 중 어느 것도 파티션 키가 아닙니다. 이를 위해서는 클라이언트가 쿼리를 각 실제 파티션으로 팬아웃하고 결과를 수집해야 합니다. 쿼리 성능을 개선시키기 위해 개발 팀은 소유자 ID가 컬렉션의 파티션 키가 되도록 디자인을 변경했습니다. 이렇게 하면 쿼리가 특정 실제 파티션을 대상으로 할 수 있습니다. (Azure Cosmos DB는 이를 자동으로 처리하므로 파티션 키 값과 실제 파티션 간의 매핑을 관리할 필요가 없습니다.)
컬렉션을 새 파티션 키로 전환한 후 RU 사용량이 크게 개선되어 비용 절감으로 직결됩니다.
| 메트릭 | 테스트 1 | 테스트 2 | 테스트 3 | 테스트 4 |
|---|---|---|---|---|
| 작업당 RU | 29 | 29 | 29 | 3.4 |
| 작업당 호출 | 11 | 9 | 10 | 1 |
엔드투엔드 트랜잭션 보기는 예상대로 쿼리가 하나의 실제 파티션만 읽는 것을 보여 줍니다.
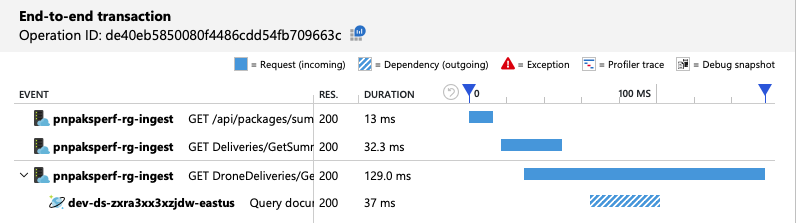
부하 테스트는 개선된 처리량과 대기 시간을 보여 줍니다.
| 메트릭 | 테스트 1 | 테스트 2 | 테스트 3 | 테스트 4 |
|---|---|---|---|---|
| 처리량(요청/초) | 19 | 23 | 42 | 59 |
| 평균 대기 시간(밀리초) | 669 | 569 | 215 | 176 |
| 성공한 요청 | 9.8K | 11K | 20K | 29K |
| 제한된 요청 | 2.72K | 0 | 0 | 0 |
개선된 성능의 결과로 노드 CPU 사용률이 매우 높아집니다.
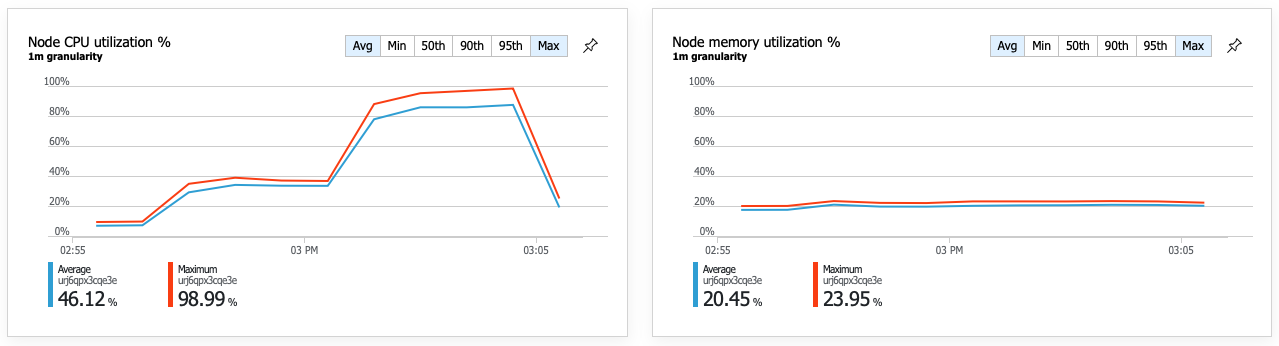
부하 테스트가 끝날 무렵 평균 CPU는 약 90%에 도달했고 최대 CPU는 100%에 도달했습니다. 이 메트릭은 CPU가 시스템의 다음 병목 지점임을 나타냅니다. 더 높은 처리량이 필요한 경우 다음 단계는 배달 서비스를 더 많은 인스턴스로 확장하는 것일 수 있습니다.
요약
이 시나리오에서는 다음과 같은 병목 현상이 확인되었습니다.
- 프로비전된 RU 부족으로 인한 Azure Cosmos DB 제한 요청.
- 여러 데이터베이스 파티션을 직렬로 쿼리하여 대기 시간이 길어졌습니다.
- 쿼리에 파티션 키가 포함되지 않았기 때문에 파티션 간 쿼리는 비효율적입니다.
또한 CPU 사용률은 더 높은 규모에서 잠재적인 병목 현상으로 식별되었습니다. 이러한 문제를 진단하기 위해 개발 팀은 다음을 살펴보았습니다.
- 부하 테스트의 대기 시간 및 처리량.
- Azure Cosmos DB 오류 및 RU 사용량.
- Application Insight의 엔드투엔드 트랜잭션 보기.
- Azure Monitor 컨테이너 인사이트의 CPU 및 메모리 사용률.
다음 단계
성능 안티패턴 검토