이 문서에서는 개발 팀이 메트릭을 사용하여 병목 상태를 찾고 분산 시스템의 성능을 개선하는 방법을 설명합니다. 이 문서는 샘플 애플리케이션에 대해 수행한 실제 부하 테스트를 기반으로 합니다. 애플리케이션은 마이크로 서비스용 AKS(Azure Kubernetes Service) 기준에서 가져온 것입니다.
이 문서는 시리즈의 일부입니다. 여기에서 첫 번째 부분을 읽어보세요.
시나리오: 클라이언트 애플리케이션이 여러 단계를 포함하는 비즈니스 트랜잭션을 시작합니다.
이 시나리오에는 AKS에서 실행되는 드론 배달 애플리케이션이 포함됩니다. 고객은 웹앱을 사용하여 드론으로 배달을 예약합니다. 각 트랜잭션에는 백 엔드에서 별도의 마이크로 서비스가 수행하는 여러 단계가 필요합니다.
- 배달 서비스는 배달을 관리합니다.
- Drone Scheduler 서비스는 픽업을 위해 드론을 예약합니다.
- 패키지 서비스는 패키지를 관리합니다.
두 가지 다른 서비스가 있습니다. 클라이언트 요청을 수락하고 처리를 위해 큐에 넣는 수집 서비스와 워크플로의 단계를 조정하는 워크플로 서비스입니다.
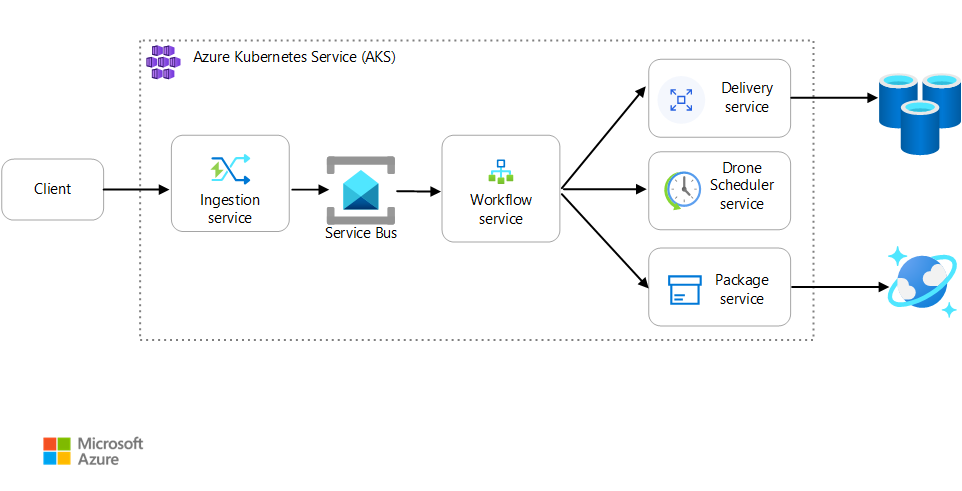
이 시나리오에 대한 자세한 내용은 마이크로 서비스 아키텍처 설계를 참조하세요.
테스트 1: 기준
첫 번째 부하 테스트를 위해 팀은 6노드 AKS 클러스터를 만들고 각 마이크로 서비스의 복제본 3개를 배포했습니다. 부하 테스트는 두 명의 시뮬레이션된 사용자에서 시작하여 최대 40명의 시뮬레이션된 사용자로 증가하는 단계 부하 테스트였습니다.
| 설정 | 값 |
|---|---|
| 클러스터 노드 | 6 |
| Pod | 서비스당 3개 |
다음 그래프는 Visual Studio에 표시된 부하 테스트 결과를 보여 줍니다. 보라색 선은 사용자 부하를 표시하고 주황색 선은 총 요청을 표시합니다.
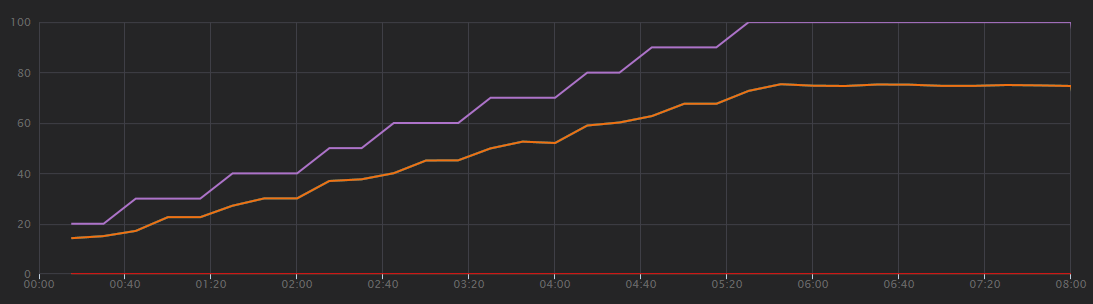
이 시나리오에 대해 가장 먼저 깨달아야 할 점은 초당 클라이언트 요청이 유용한 성능 메트릭이 아니라는 점입니다. 애플리케이션이 요청을 비동기적으로 처리하여 클라이언트가 즉시 응답을 받기 때문입니다. 응답 코드는 항상 HTTP 202(수락됨)이며 이는 요청이 수락되었지만 처리가 완료되지 않았음을 의미합니다.
우리가 정말로 알고 싶은 것은 백 엔드가 요청 속도를 따라가고 있는지 여부입니다. Service Bus 큐는 급증을 흡수할 수 있지만 백 엔드가 지속적인 부하를 처리할 수 없는 경우 처리가 점점 더 뒤처집니다.
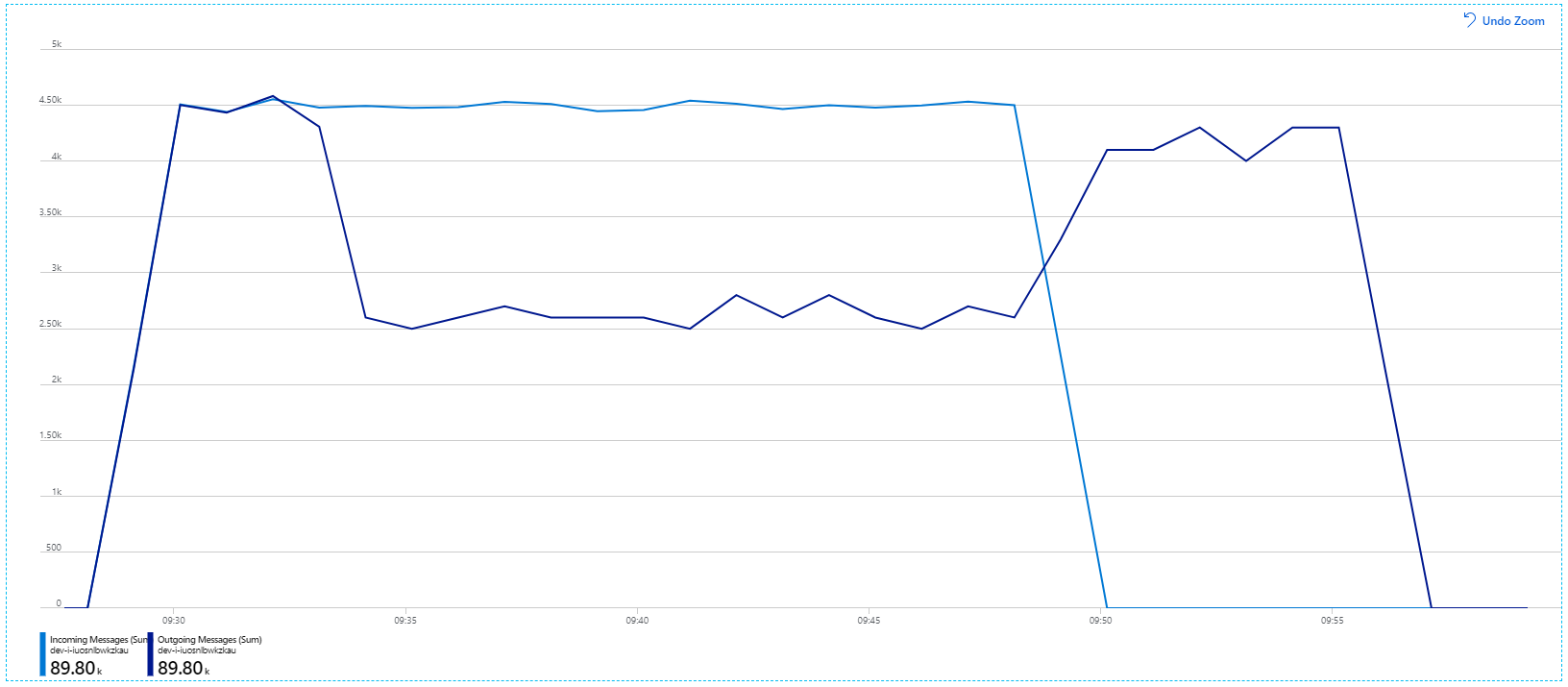
다음은 보다 유용한 그래프입니다. Service Bus 큐에 들어오는 메시지와 보내는 메시지 수를 표시합니다. 들어오는 메시지는 연한 파란색으로 표시되고 보내는 메시지는 진한 파란색으로 표시됩니다.

이 차트는 들어오는 메시지의 속도가 증가하여 최고에 도달한 다음 부하 테스트가 끝나면 다시 0으로 떨어지는 것을 보여 줍니다. 그러나 보내는 메시지의 수는 테스트 초반에 최고조에 달한 다음 실제로 떨어집니다. 이는 요청을 처리하는 Workflow 서비스가 따라가지 못하고 있음을 의미합니다. 부하 테스트가 종료된 후에도(그래프에서 약 9:22) Workflow 서비스가 큐를 계속 드레이닝함에 따라 메시지는 여전히 처리되고 있습니다.
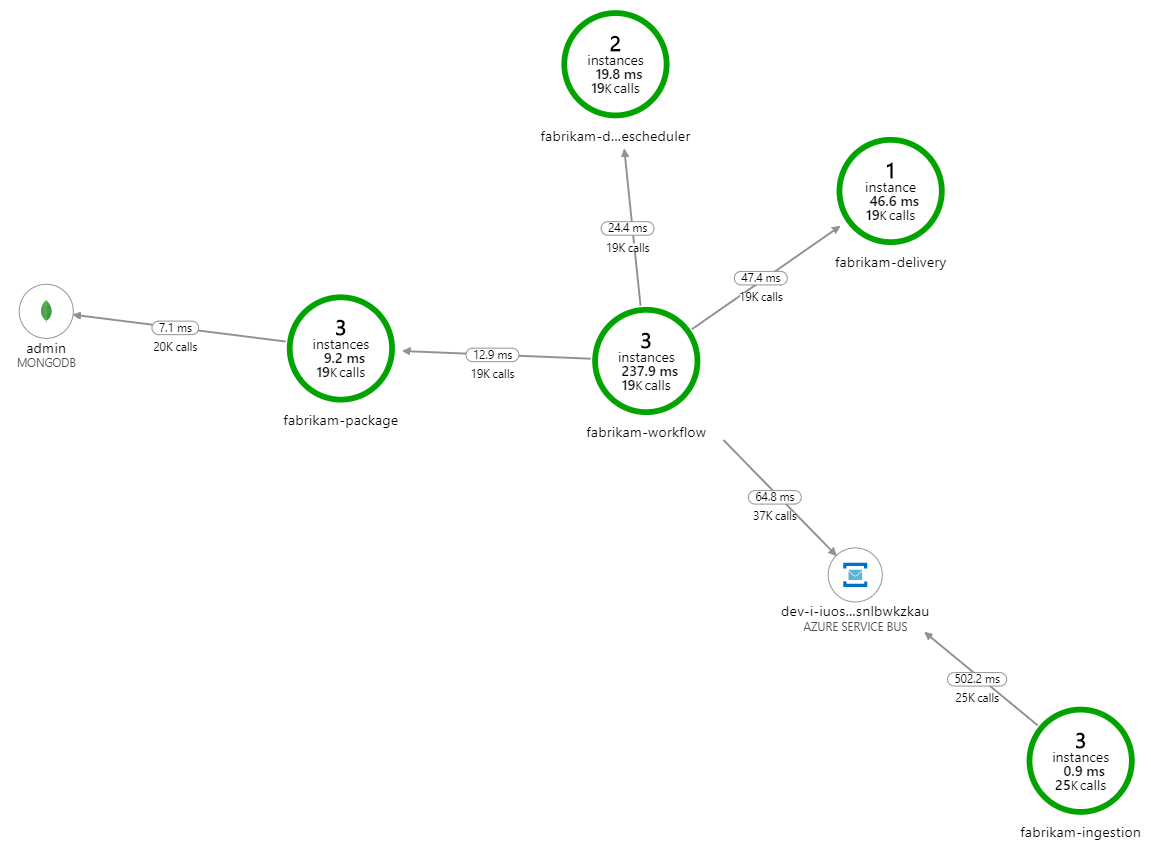
처리 속도가 느려지는 이유는 무엇인가요? 가장 먼저 찾아야 할 것은 체계적인 문제를 나타낼 수 있는 오류 또는 예외입니다. Azure Monitor의 애플리케이션 맵은 구성 요소 간의 호출 그래프를 보여 주며 문제를 빠르게 발견한 다음 클릭하여 자세한 내용을 볼 수 있는 방법입니다.
물론 애플리케이션 맵은 Workflow 서비스가 배달 서비스에서 오류를 받고 있음을 보여 줍니다.
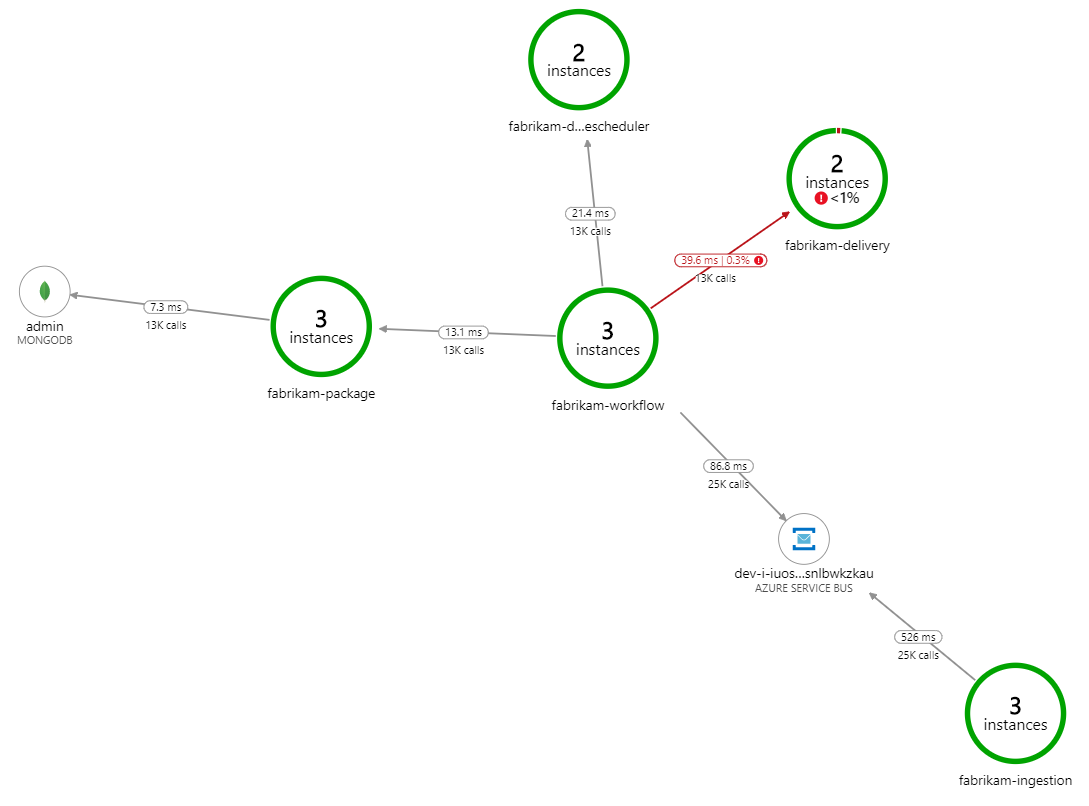
자세한 내용을 보려면 그래프에서 노드를 선택하고 엔드투엔드 트랜잭션 보기를 클릭하면 됩니다. 이 경우 배달 서비스가 HTTP 500 오류를 반환하고 있음을 보여 줍니다. 오류 메시지는 Azure Cache for Redis 메모리 제한으로 인해 예외가 throw되고 있음을 나타냅니다.
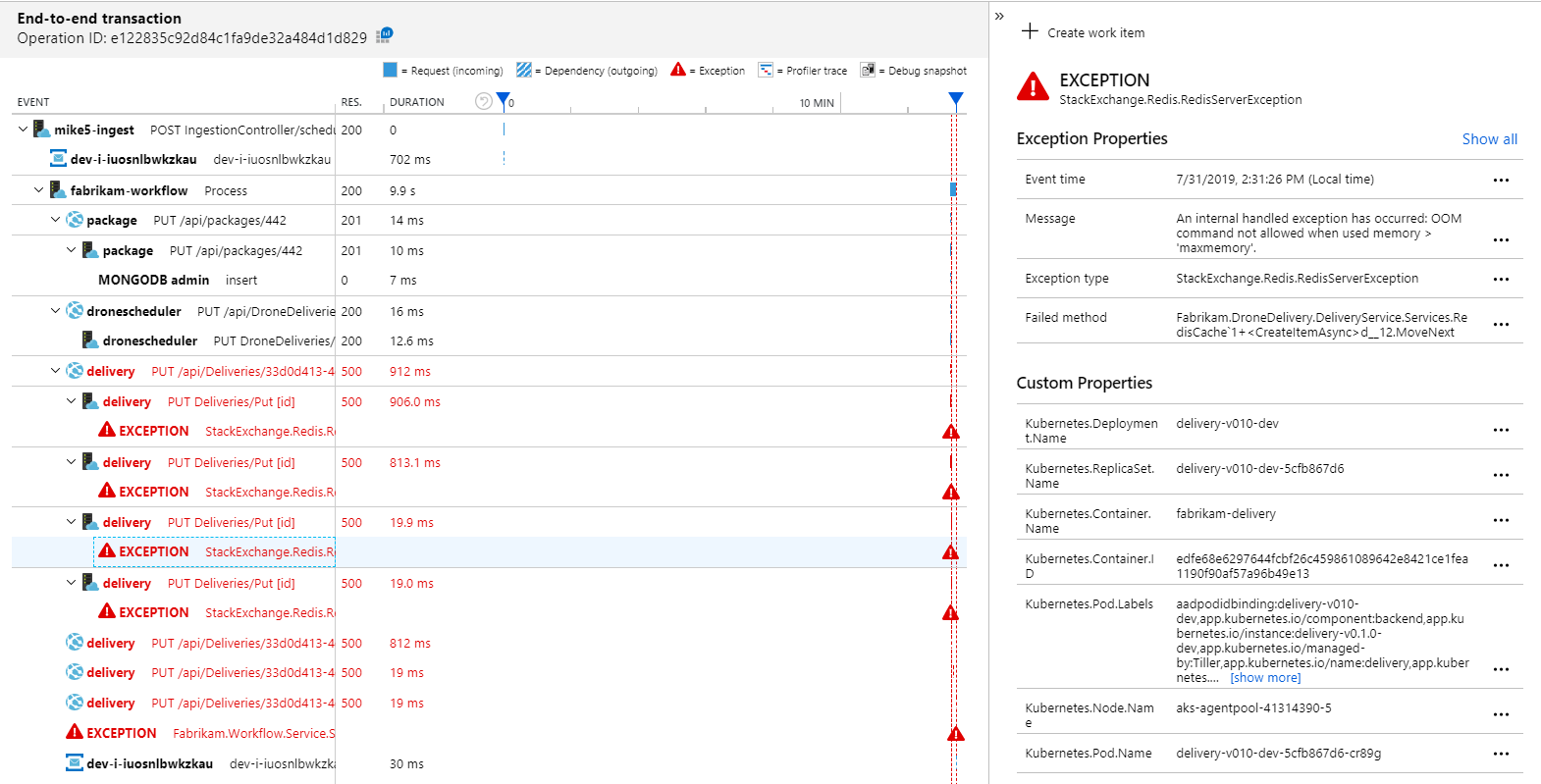
Redis에 대한 이러한 호출은 애플리케이션 맵에 표시되지 않습니다. Application Insights용 .NET 라이브러리에는 Redis를 종속성으로 추적하기 위한 기본 제공 지원이 없기 때문입니다. (기본적으로 지원되는 항목 목록은 종속성 자동 수집을 참조하세요.) 대안으로 TrackDependency API를 사용하여 모든 종속성을 추적할 수 있습니다. 부하 테스트는 종종 원격 분석에서 이러한 종류의 격차를 표시하며 이는 수정할 수 있습니다.
테스트 2: 캐시 크기 증가
두 번째 부하 테스트를 위해 개발 팀은 Azure Cache for Redis의 캐시 크기를 늘렸습니다. (Azure Cache for Redis를 스케일링하는 방법을 참조하세요.) 이 변경으로 메모리 부족 예외가 해결되었으며 이제 애플리케이션 맵에 오류가 표시되지 않습니다.
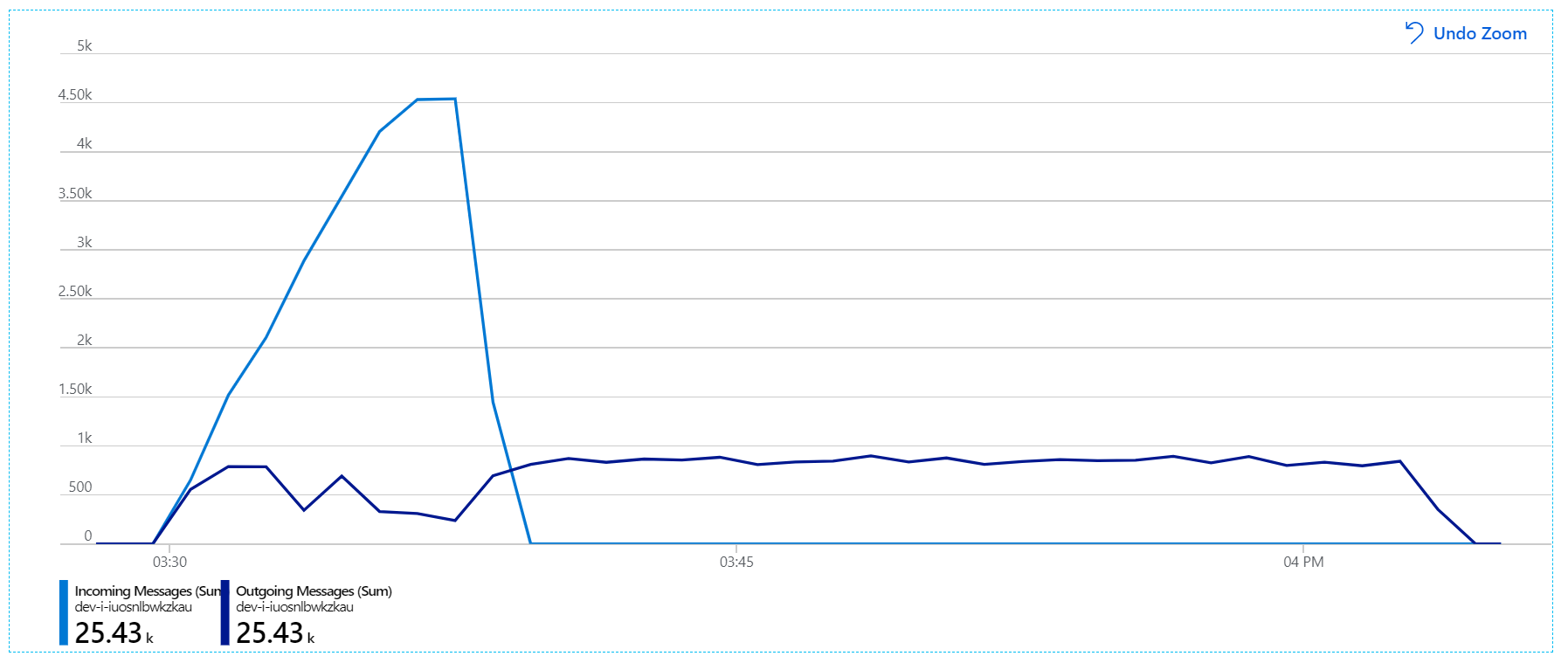
그러나 메시지 처리에는 여전히 상당한 지연이 있습니다. 부하 테스트가 최고조에 도달하면 들어오는 메시지 속도는 보내는 메시지 속도의 5배를 초과합니다.
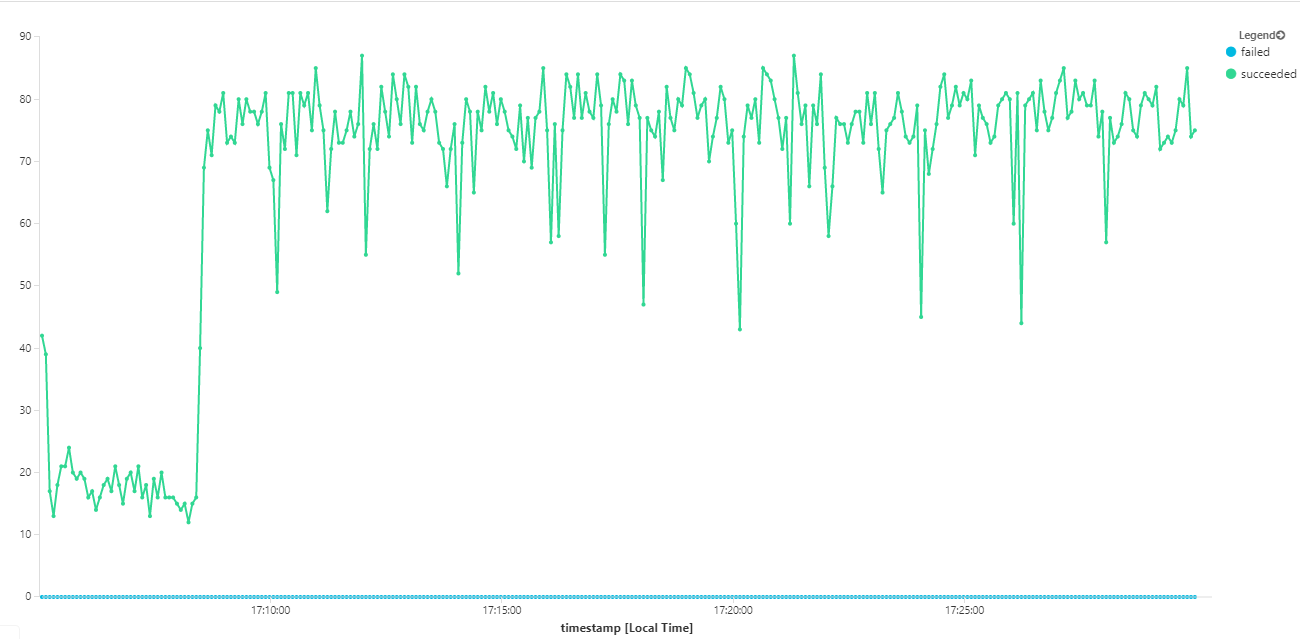
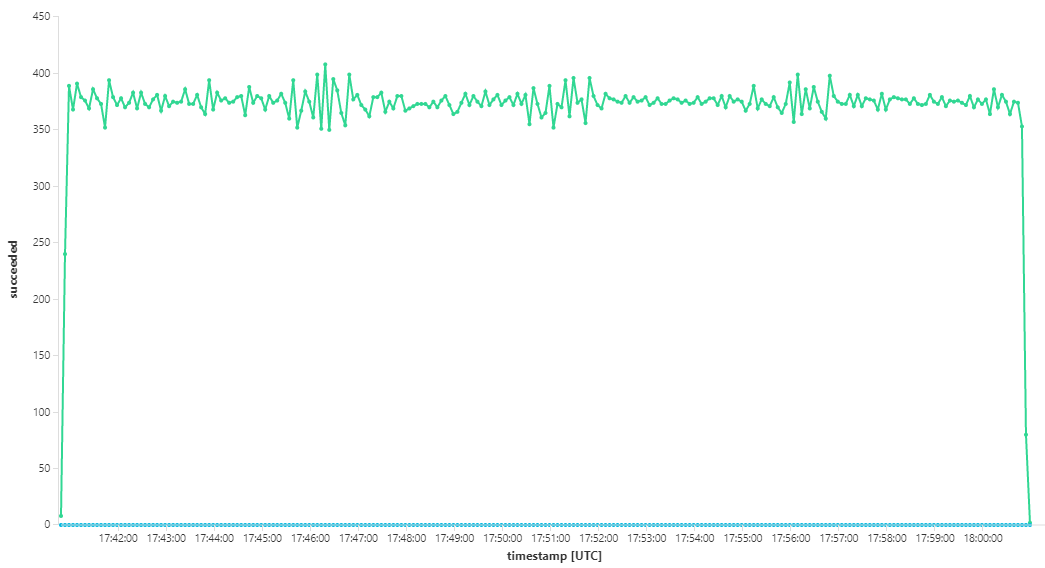
다음 그래프는 메시지 완료 측면에서 처리량을 측정합니다. 즉, Workflow 서비스가 Service Bus 메시지를 완료된 것으로 표시하는 속도입니다. 그래프의 각 지점은 최대 처리량이 16/초인 5초의 데이터를 나타냅니다.
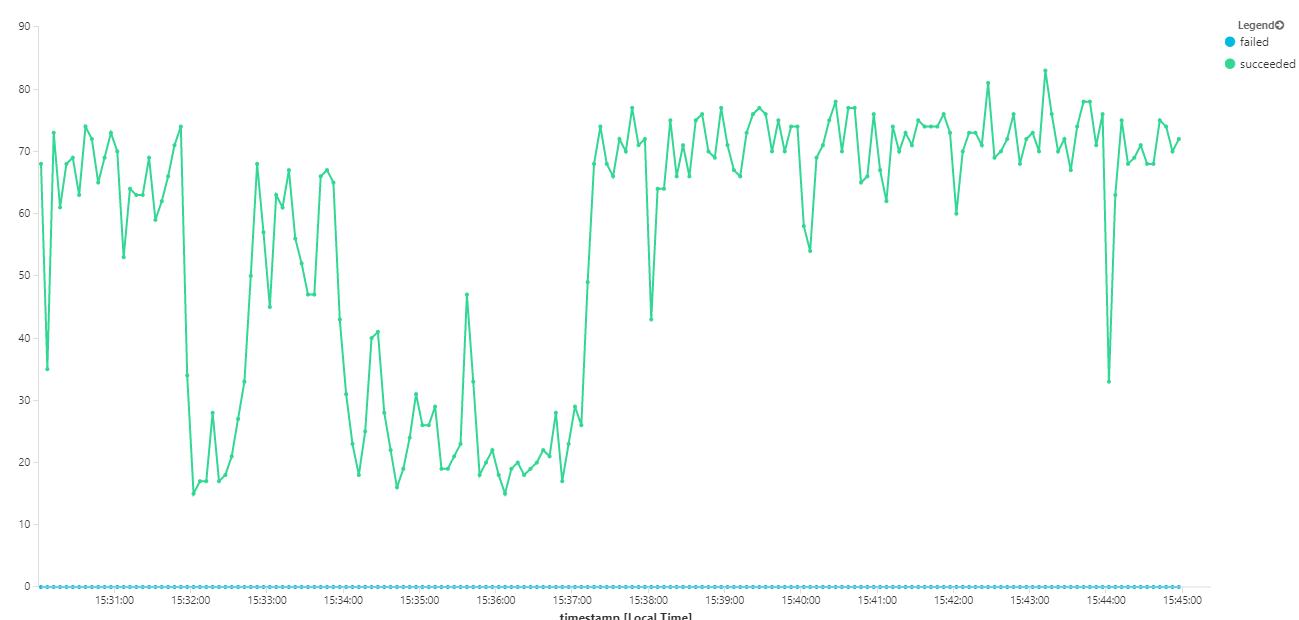
이 그래프는 Kusto 쿼리 언어를 사용하여 Log Analytics 작업 영역에서 쿼리를 실행하여 생성되었습니다.
let start=datetime("2020-07-31T22:30:00.000Z");
let end=datetime("2020-07-31T22:45:00.000Z");
dependencies
| where cloud_RoleName == 'fabrikam-workflow'
| where timestamp > start and timestamp < end
| where type == 'Azure Service Bus'
| where target has 'https://dev-i-iuosnlbwkzkau.servicebus.windows.net'
| where client_Type == "PC"
| where name == "Complete"
| summarize succeeded=sumif(itemCount, success == true), failed=sumif(itemCount, success == false) by bin(timestamp, 5s)
| render timechart
테스트 3: 백 엔드 서비스 스케일 아웃
백 엔드가 병목 상태인 것 같습니다. 간편한 다음 단계는 비즈니스 서비스(Package, Delivery, Drone Scheduler)를 스케일 아웃하고 처리량이 개선되는지 확인하는 것입니다. 다음 부하 테스트를 위해 팀은 이러한 서비스를 복제본 3개에서 복제본 6개로 스케일 아웃했습니다.
| 설정 | 값 |
|---|---|
| 클러스터 노드 | 6 |
| 수집 서비스 | 복제본 3개 |
| Workflow 서비스 | 복제본 3개 |
| 패키지, 배달, Drone Scheduler 서비스 | 각 복제본 6개 |
아쉽게도 이 부하 테스트는 약간만 개선되었음을 보여 줍니다. 보내는 메시지는 여전히 들어오는 메시지를 따라잡지 못하고 있습니다.
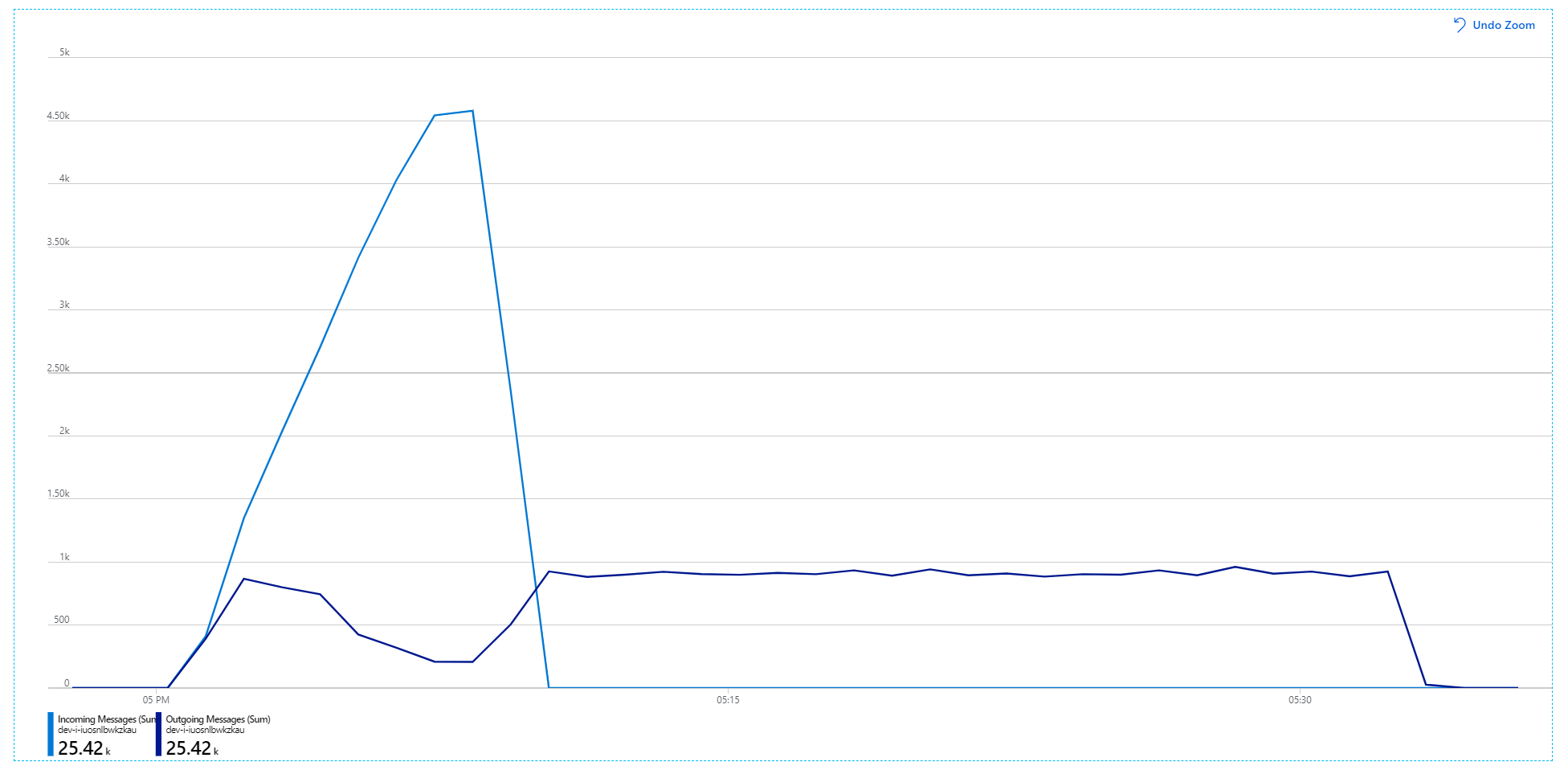
처리량은 더 일관되지만 달성된 최댓값은 이전 테스트와 거의 동일합니다.
또한 Azure Monitor 컨테이너 인사이트를 살펴보면 문제가 클러스터 내 리소스 소모로 인해 발생하지 않은 것으로 보입니다. 첫째, 노드 수준 메트릭은 CPU 사용률이 95번째 백분위수에서도 40% 미만으로 유지되고 메모리 사용률은 약 20%임을 보여 줍니다.
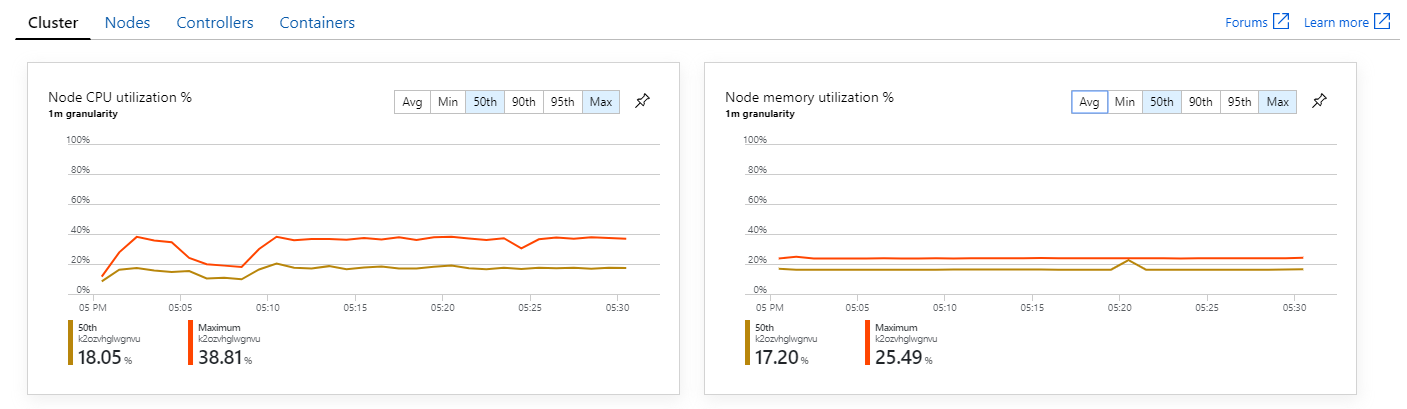
Kubernetes 환경에서는 노드의 리소스가 제한되지 않는 경우에도 개별 Pod의 리소스가 제한될 수 있습니다. 그러나 Pod 수준 보기는 모든 Pod가 정상임을 보여 줍니다.

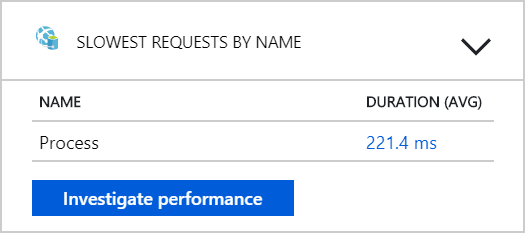
이 테스트에서 백 엔드에 더 많은 Pod를 추가하는 것만으로는 도움이 되지 않는 것으로 보입니다. 다음 단계는 Workflow 서비스가 메시지를 처리할 때 발생하는 상황을 이해하기 위해 Workflow 서비스를 더 자세히 살펴보는 것입니다. Application Insights는 Workflow 서비스의 Process 작업 평균 기간이 246ms임을 보여 줍니다.
쿼리를 실행하여 각 트랜잭션 내의 개별 작업에 대한 메트릭을 가져올 수도 있습니다.
| 대상 | percentile_duration_50 | percentile_duration_95 |
|---|---|---|
https://dev-i-iuosnlbwkzkau.servicebus.windows.net/ | dev-i-iuosnlbwkzkau |
86.66950203 | 283.4255578 |
| 배달 | 37 | 57 |
| 패키지 | 12 | 17 |
| dronescheduler | 21 | 41 |
이 테이블의 첫 번째 행은 Service Bus 큐를 나타냅니다. 다른 행은 백 엔드 서비스에 대한 호출입니다. 참고로 이 테이블에 대한 Log Analytics 쿼리는 다음과 같습니다.
let start=datetime("2020-07-31T22:30:00.000Z");
let end=datetime("2020-07-31T22:45:00.000Z");
let dataset=dependencies
| where timestamp > start and timestamp < end
| where (cloud_RoleName == 'fabrikam-workflow')
| where name == 'Complete' or target in ('package', 'delivery', 'dronescheduler');
dataset
| summarize percentiles(duration, 50, 95) by target
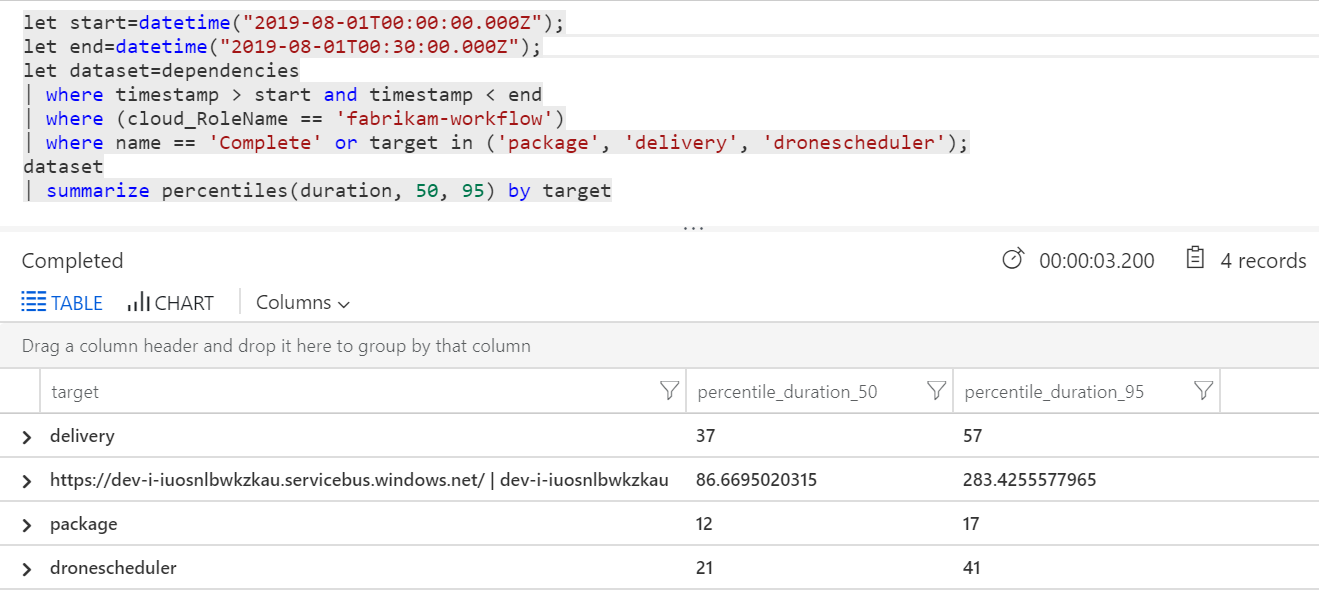
이러한 대기 시간은 합리적으로 보입니다. 그러나 핵심 인사이트는 다음과 같습니다. 총 작업 시간이 최대 250ms이면 메시지를 직렬로 처리할 수 있는 속도에 엄격한 상한이 적용됩니다. 따라서 처리량 개선의 핵심은 더 큰 병렬 처리입니다.
이 시나리오에서는 다음 두 가지 이유로 가능해야 합니다.
- 네트워크 호출이므로 대부분의 시간은 I/O 완료를 기다리는 데 소요됩니다.
- 메시지는 독립적이며 순서대로 처리할 필요가 없습니다.
테스트 4: 병렬 처리 증가
팀은 이 테스트에서 병렬 처리를 늘리는 데 집중했습니다. 이를 위해 Workflow 서비스에서 사용하는 Service Bus 클라이언트에서 두 가지 설정을 조정했습니다.
| 설정 | 설명 | 기본값 | 새 값 |
|---|---|---|---|
MaxConcurrentCalls |
동시에 처리할 최대 메시지 수. | 1 | 20 |
PrefetchCount |
클라이언트가 사전에 로컬 캐시로 가져올 메시지 수. | 0 | 3000 |
이러한 설정에 대한 자세한 내용은 Service Bus 메시징을 사용한 성능 향상의 모범 사례를 참조하세요. 이러한 설정을 사용하여 테스트를 실행하면 다음 그래프가 생성됩니다.
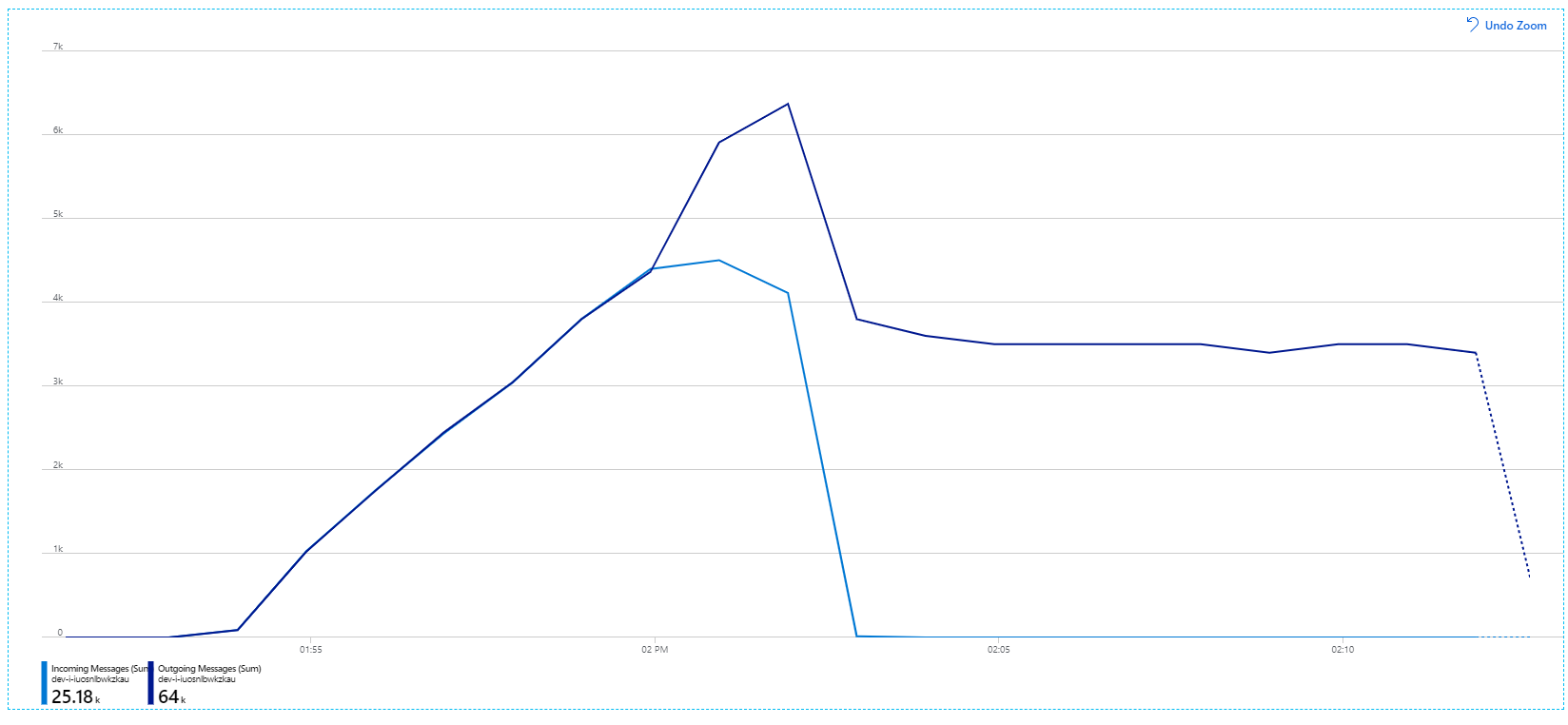
들어오는 메시지는 연한 파란색으로 표시되고 보내는 메시지는 진한 파란색으로 표시된다는 점을 기억하세요.
언뜻 보기에 이것은 매우 이상한 그래프입니다. 잠시 동안 보내는 메시지 속도는 들어오는 속도를 정확하게 추적합니다. 그러나 약 2:03 지점에서 들어오는 메시지의 속도는 줄어들고 보내는 메시지의 수는 계속 증가하여 실제로 들어오는 메시지의 총 수를 초과합니다. 그것은 불가능한 것 같습니다.
이 미스터리에 대한 단서는 Application Insights의 종속성 보기에서 찾을 수 있습니다. 이 차트에는 Workflow 서비스가 Service Bus에 대해 수행한 모든 호출이 요약되어 있습니다.

DeadLetter에 대한 항목에 유의하세요. 이 호출은 메시지가 Service Bus 배달 못 한 편지 큐로 이동하고 있음을 나타냅니다.
무슨 일이 일어나고 있는지 이해하려면 Service Bus의 보기 잠금 의미 체계를 이해해야 합니다. 클라이언트가 보기 잠금을 사용하는 경우 Service Bus는 메시지를 자동으로 검색하고 잠급니다. 잠금이 유지되는 동안 메시지는 다른 수신기에 전달되지 않습니다. 잠금이 만료되면 다른 수신기가 메시지를 사용할 수 있게 됩니다. 최대 배달 시도 횟수(구성 가능) 후에 Service Bus는 나중에 검사할 수 있는 배달 못 한 편지 큐에 메시지를 넣습니다.
Workflow 서비스는 한 번에 3000개의 메시지와 같이 대량의 메시지 일괄 처리를 프리페치하고 있음을 기억하세요. 즉, 각 메시지를 처리하는 데 걸리는 총 시간이 길어져 메시지가 시간 초과되어 큐로 돌아가고 결국 배달 못 한 편지 큐로 이동하게 됩니다.
많은 MessageLostLockException 예외가 기록된 예외에서도 이 동작을 볼 수 있습니다.
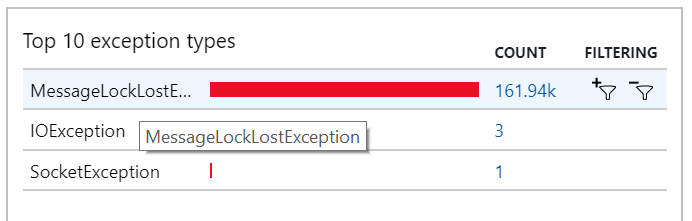
테스트 5: 잠금 기간 늘리기
이 부하 테스트에서는 잠금 시간 제한을 방지하기 위해 메시지 잠금 기간을 5분으로 설정했습니다. 들어오는 메시지와 보내는 메시지의 그래프는 이제 시스템이 들어오는 메시지의 속도를 따라가고 있음을 보여 줍니다.
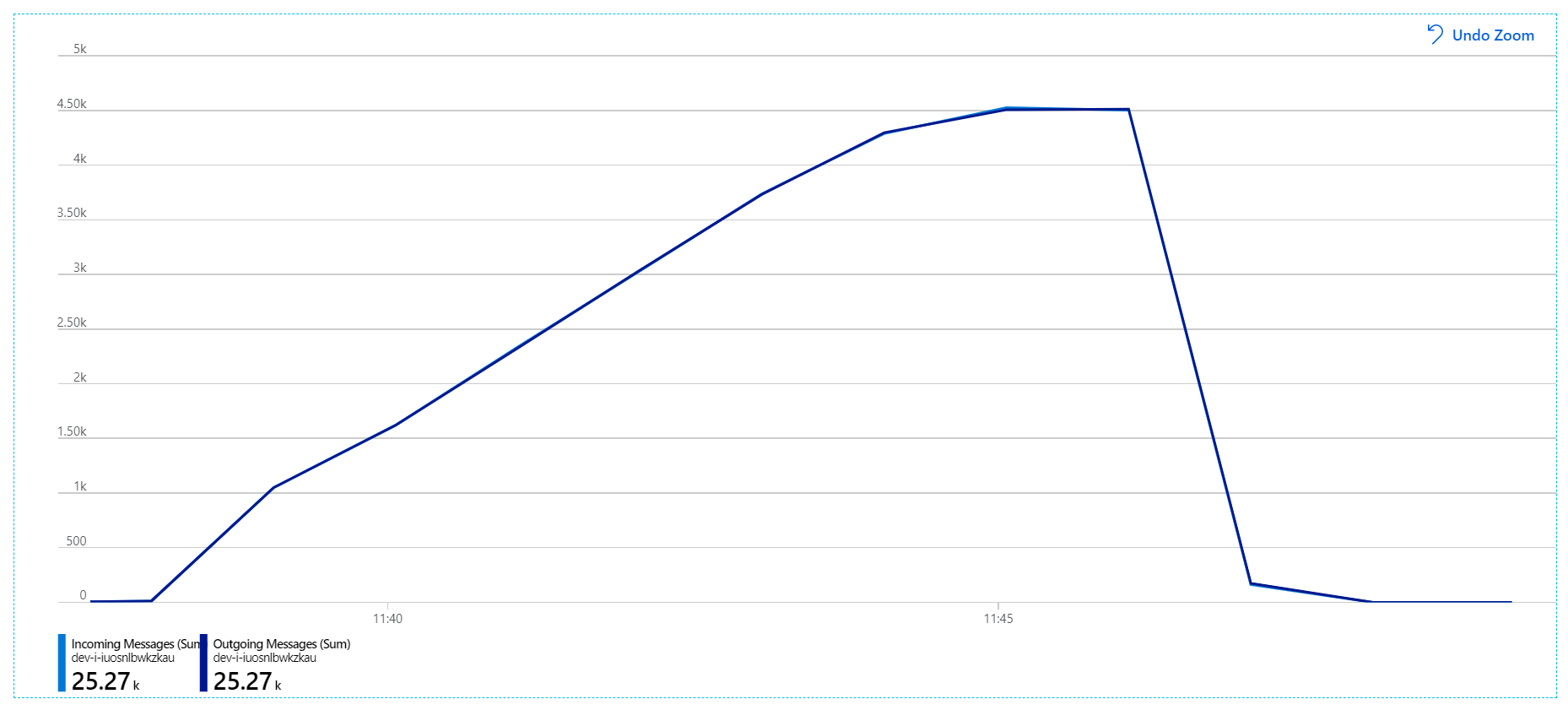
8분 부하 테스트의 총 기간 동안 애플리케이션은 25,000개의 작업을 완료했으며 최대 처리량은 초당 72개 작업으로 최대 처리량이 400% 증가했습니다.
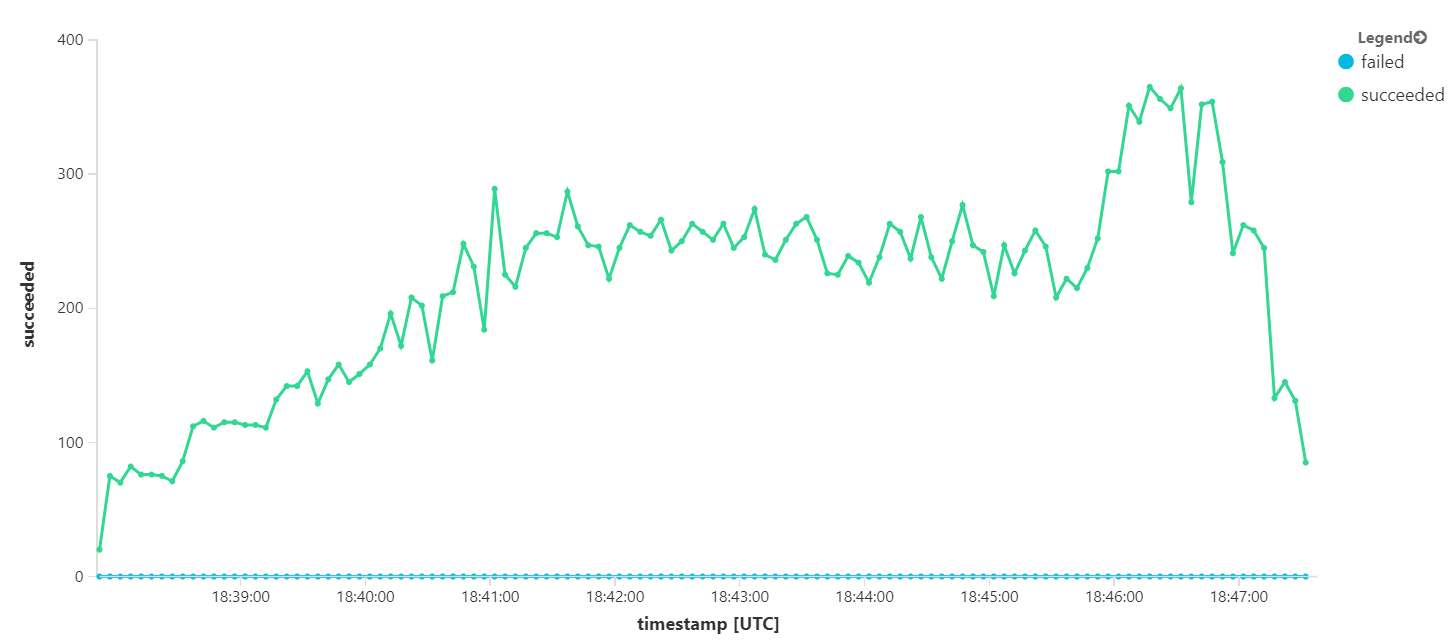
그러나 동일한 테스트를 더 긴 기간 동안 실행하면 애플리케이션이 이 속도를 유지할 수 없는 것으로 나타났습니다.
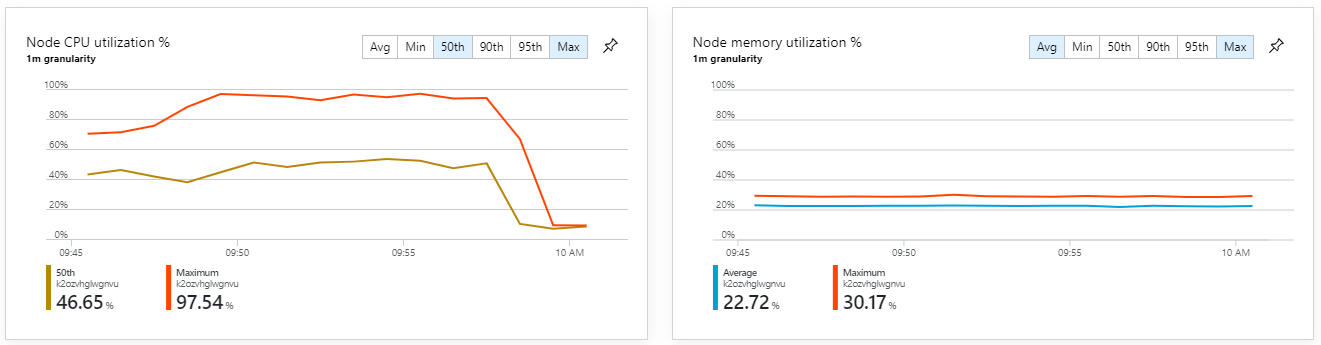
컨테이너 메트릭은 최대 CPU 사용률이 100%에 근접했음을 보여 줍니다. 이 시점에서 애플리케이션은 CPU에 바인딩된 것으로 보입니다. 이제 클러스터를 스케일링하면 이전의 스케일 아웃 시도와 달리 성능이 향상될 수 있습니다.
테스트 6: 백 엔드 서비스 스케일 아웃(다시)
시리즈의 최종 부하 테스트를 위해 팀은 다음과 같이 Kubernetes 클러스터와 Pod를 스케일 아웃했습니다.
| 설정 | 값 |
|---|---|
| 클러스터 노드 | 12 |
| 수집 서비스 | 복제본 3개 |
| Workflow 서비스 | 복제본 6개 |
| 패키지, 배달, Drone Scheduler 서비스 | 각 복제본 9개 |
이 테스트 결과 메시지 처리 시 상당한 지연 없이 더 높은 지속적인 처리량이 나타났습니다. 또한 노드 CPU 사용률은 80% 미만으로 유지되었습니다.
요약
이 시나리오에서는 다음과 같은 병목 상태가 확인되었습니다.
- Azure Cache for Redis의 메모리 부족 예외.
- 메시지 처리의 병렬 처리 부족.
- 메시지 잠금 기간이 부족하여 잠금 시간 제한 및 메시지가 배달 못 한 편지 큐에 배치.
- CPU 소모.
이러한 문제를 진단하기 위해 개발 팀은 다음 메트릭을 사용했습니다.
- 들어오고 보내는 Service Bus 메시지의 속도.
- Application Insights의 애플리케이션 맵.
- 오류 및 예외.
- 사용자 지정 Log Analytics 쿼리.
- Azure Monitor 컨테이너 인사이트의 CPU와 메모리 사용률.
다음 단계
이 시나리오의 설계에 대한 자세한 내용은 마이크로 서비스 아키텍처 설계를 참조하세요.