이 참조 아키텍처에서는 데이터 스트림을 수집하고, 데이터를 처리하고, 결과를 백 엔드 데이터베이스에 기록하는 서버리스 이벤트 구동 아키텍처를 보여줍니다.
아키텍처
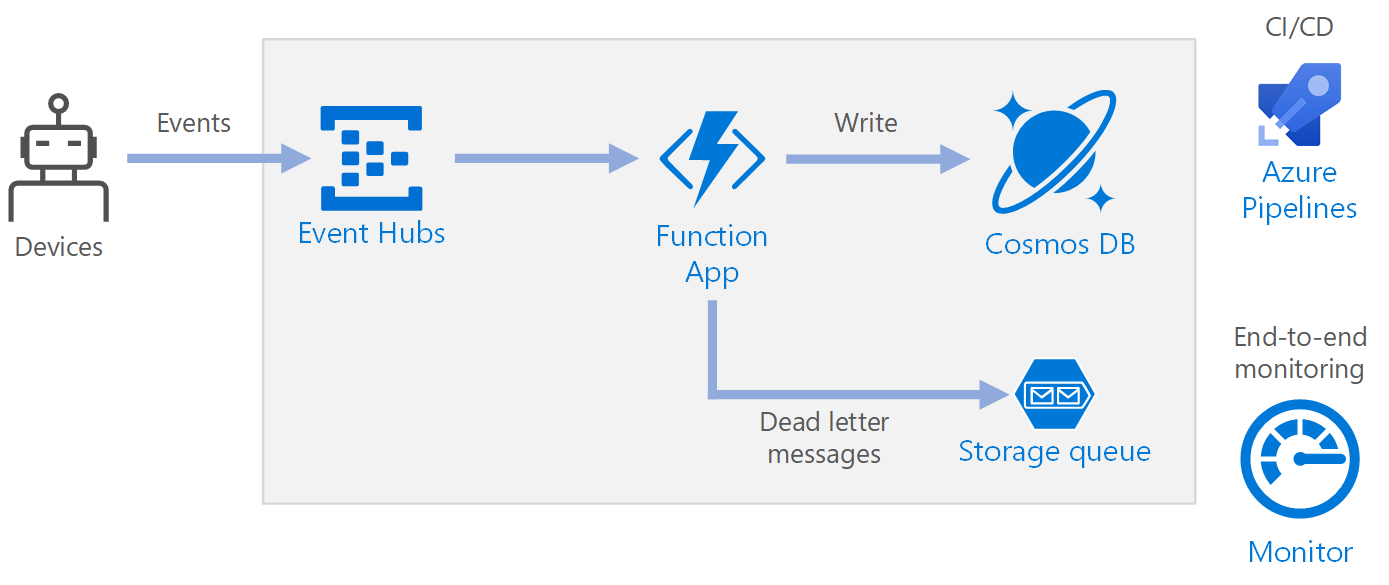
워크플로
- 이벤트는 Azure Event Hubs에 도착합니다.
- 함수 앱은 이벤트를 처리하도록 트리거됩니다.
- 이벤트가 Azure Cosmos DB 데이터베이스에 저장됩니다.
- 함수 앱이 이벤트를 성공적으로 저장하지 못하면 나중에 처리할 Storage 큐에 이벤트가 저장됩니다.
구성 요소
Event Hubs에서 데이터 스트림을 수집합니다. Event Hubs는 높은 처리량 데이터 스트리밍 시나리오를 위해 설계되었습니다.
참고
IoT(사물 인터넷) 시나리오의 경우 Azure IoT Hub를 권장합니다. IoT Hub에는 Azure Event Hubs API와 호환되는 기본 제공 엔드포인트가 있으므로 이 아키텍처에서는 백 엔드 처리를 크게 변경하지 않고도 두 가지 서비스 중 하나를 사용할 수 있습니다. 자세한 내용은 IoT 디바이스를 Azure에 연결: IoT Hub 및 Event Hubs를 참조하세요.
함수 앱. Azure Functions는 서버리스 컴퓨팅 옵션입니다. 트리거를 통해 코드(함수)가 호출되는 이벤트 구동 모델을 사용합니다. 이 아키텍처에서는 이벤트가 Event Hubs에 도착하면 이벤트를 처리하고 결과를 스토리지에 쓰는 함수를 트리거합니다.
함수 앱은 Event Hubs에서 개별 레코드를 처리하는 데 적합합니다. 더 복잡한 스트림 처리 시나리오의 경우 Azure Databricks를 사용하는 Apache Spark 또는 Azure Stream Analytics를 고려해 보세요.
Azure Cosmos DB. Azure Cosmos DB는 서버리스 소비 기반 모드에서 사용할 수 있는 다중 모델 데이터베이스 서비스입니다. 이 시나리오의 경우 이벤트 처리 함수가 Azure Cosmos DB for NoSQL을 사용하여 JSON 레코드를 저장합니다.
Queue storage. Queue storage는 배달 못한 편지 메시지에 사용됩니다. 이벤트를 처리하는 중에 오류가 발생하면 나중에 처리하기 위해 함수에서 이벤트 데이터를 배달 못한 편지 큐에 저장합니다. 자세한 내용은 나중에 이 문서의 복원력 섹션을 참조하세요.
Azure Monitor Monitor는 솔루션에 배포된 Azure 서비스에 대한 성능 메트릭을 수집합니다. 이러한 메트릭을 대시보드에서 시각화하여 솔루션의 상태를 볼 수 있습니다.
Azure Pipelines. Pipelines는 애플리케이션을 빌드, 테스트 및 배포하는 CI(지속적인 통합) 및 CD(지속적인 업데이트) 서비스입니다.
고려 사항
이러한 고려 사항은 워크로드의 품질을 향상시키는 데 사용할 수 있는 일단의 지침 원칙인 Azure Well-Architected Framework의 핵심 요소를 구현합니다. 자세한 내용은 Microsoft Azure Well-Architected Framework를 참조하세요.
가용성
여기에 표시된 배포는 단일 Azure 지역에 있습니다. 재해 복구에 더 탄력적인 방법을 적용하려면 다양한 서비스의 지리적 배포 기능을 활용합니다.
- Event Hubs. 두 개의 Event Hubs 네임스페이스, 즉 기본(활성) 네임스페이스 및 보조(수동) 네임스페이스를 만듭니다. 메시지는 보조 네임스페이스로 장애 조치하지 않는 한 자동으로 활성 네임스페이스로 라우팅됩니다. 자세한 내용은 Azure Event Hubs 지역 재해 복구를 참조하세요.
- 함수 앱. 보조 Event Hubs 네임스페이스에서 읽기를 기다리는 두 번째 함수 앱을 배포합니다. 이 함수는 배달 못한 편지 큐에 대한 보조 스토리지 계정에 씁니다.
- Azure Cosmos DB Azure Cosmos DB는 다중 마스터 지역을 지원하므로 Azure Cosmos DB 계정에 추가하는 모든 지역에 쓸 수 있습니다. 다중 쓰기를 사용하도록 설정하지 않은 경우에도 주 쓰기 지역을 장애 조치(failover)할 수 있습니다. Azure Cosmos DB 클라이언트 SDK 및 Azure Function 바인딩은 장애 조치(failover)를 자동으로 처리하므로 애플리케이션 구성 설정을 업데이트할 필요가 없습니다.
- Azure Storage. 배달 못한 편지 큐에 대해 RA-GRS 스토리지를 사용합니다. 이렇게 하면 읽기 전용 복제본이 다른 지역에 만들어집니다. 주 지역을 사용할 수 없게 되면 현재 큐에 있는 항목을 읽을 수 있습니다. 또한 장애 조치 후에 함수에서 쓸 수 있는 다른 스토리지 계정을 보조 지역에 프로비전합니다.
확장성
Event Hubs
Event Hubs의 처리량 용량은 처리량 단위로 제어됩니다. 자동 팽창을 사용하도록 설정하여 이벤트 허브를 자동 크기 조정할 수 있습니다. 그러면 트래픽에 따라 처리량 단위를 구성된 최댓값까지 자동으로 크기 조정합니다.
함수 앱의 Event Hubs 트리거는 이벤트 허브의 파티션 수에 따라 크기 조정됩니다. 각 파티션에는 한 번에 하나의 함수 인스턴스가 할당됩니다. 처리량을 최대화하려면 한 번에 하나씩이 아니라 일괄 처리 방식으로 이벤트를 받습니다.
Azure Cosmos DB
Azure Cosmos DB는 두 가지 용량 모드로 사용할 수 있습니다.
워크로드의 확장성을 보장하려면 Azure Cosmos DB 컨테이너를 만들 때 적절한 파티션 키를 선택하는 것이 중요합니다. 적절한 파티션 키에 대한 몇 가지 특징은 다음과 같습니다.
- 키 값 공간이 큽니다.
- 바로 가기 키를 사용하지 않고도 값당 읽기/쓰기 수가 균등하게 분산됩니다.
- 단일 키 값에 저장되는 최대 데이터 크기는 최대 실제 파티션 크기(20GB)를 초과하지 않습니다.
- 문서에 대한 파티션 키는 변경되지 않습니다. 기존 문서의 파티션 키는 업데이트할 수 없습니다.
이 참조 아키텍처에 대한 시나리오에서 함수는 정확히 데이터를 보내는 디바이스당 하나의 문서를 저장합니다. 함수에서 지속적으로 upsert 작업을 사용하여 문서를 최신 디바이스 상태로 업데이트합니다. 쓰기가 키 전체에 균등하게 분산되므로 디바이스 ID가 이 시나리오에 적합한 파티션 키이며, 각 키 값에 대해 하나의 문서가 있으므로 각 파티션의 크기가 엄격하게 제한됩니다. 파티션 키에 대한 자세한 내용은 Azure Cosmos DB의 파티션 및 확장을 참조하세요.
복원력
Functions에서 Event Hubs 트리거를 사용하는 경우 처리 루프 내에서 예외를 catch합니다. 처리되지 않은 예외가 발생하면 Functions 런타임에서 메시지를 다시 시도하지 않습니다. 메시지를 처리할 수 없는 경우 배달 못한 편지 큐에 메시지를 넣습니다. 대역 외 프로세스를 사용하여 메시지를 검토하고 수정 작업을 결정합니다.
다음 코드에서는 수집 함수에서 예외를 catch하고, 처리되지 않은 메시지를 배달 못한 편지 큐에 넣는 방법을 보여 줍니다.
[Function(nameof(RawTelemetryFunction))]
public async Task RunAsync([EventHubTrigger("%EventHubName%", Connection = "EventHubConnection")] EventData[] messages,
FunctionContext context)
{
_telemetryClient.GetMetric("EventHubMessageBatchSize").TrackValue(messages.Length);
DeviceState? deviceState = null;
// Create a new CosmosClient
var cosmosClient = new CosmosClient(Environment.GetEnvironmentVariable("COSMOSDB_CONNECTION_STRING"));
// Get a reference to the database and the container
var database = cosmosClient.GetDatabase(Environment.GetEnvironmentVariable("COSMOSDB_DATABASE_NAME"));
var container = database.GetContainer(Environment.GetEnvironmentVariable("COSMOSDB_DATABASE_COL"));
// Create a new QueueClient
var queueClient = new QueueClient(Environment.GetEnvironmentVariable("DeadLetterStorage"), "deadletterqueue");
await queueClient.CreateIfNotExistsAsync();
foreach (var message in messages)
{
try
{
deviceState = _telemetryProcessor.Deserialize(message.Body.ToArray(), _logger);
try
{
// Add the device state to Cosmos DB
await container.UpsertItemAsync(deviceState, new PartitionKey(deviceState.DeviceId));
}
catch (Exception ex)
{
_logger.LogError(ex, "Error saving on database", message.PartitionKey, message.SequenceNumber);
var deadLetterMessage = new DeadLetterMessage { Issue = ex.Message, MessageBody = message.Body.ToArray(), DeviceState = deviceState };
// Convert the dead letter message to a string
var deadLetterMessageString = JsonConvert.SerializeObject(deadLetterMessage);
// Send the message to the queue
await queueClient.SendMessageAsync(deadLetterMessageString);
}
}
catch (Exception ex)
{
_logger.LogError(ex, "Error deserializing message", message.PartitionKey, message.SequenceNumber);
var deadLetterMessage = new DeadLetterMessage { Issue = ex.Message, MessageBody = message.Body.ToArray(), DeviceState = deviceState };
// Convert the dead letter message to a string
var deadLetterMessageString = JsonConvert.SerializeObject(deadLetterMessage);
// Send the message to the queue
await queueClient.SendMessageAsync(deadLetterMessageString);
}
}
}
표시된 코드는 또한 예외를 Application Insights에 기록합니다. 파티션 키와 시퀀스 번호를 사용하여 배달 못한 편지 메시지와 로그의 예외 사이의 상관 관계를 지정할 수 있습니다.
배달 못한 편지 큐의 메시지에는 오류 컨텍스트를 이해할 수 있도록 충분한 정보가 있어야 합니다. 이 예제 DeadLetterMessage 에서 클래스에는 예외 메시지, 원래 이벤트 본문 데이터 및 역직렬화된 이벤트 메시지(사용 가능한 경우)가 포함됩니다.
public class DeadLetterMessage
{
public string? Issue { get; set; }
public byte[]? MessageBody { get; set; }
public DeviceState? DeviceState { get; set; }
}
Azure Monitor를 사용하여 이벤트 허브를 모니터링합니다. 입력은 있지만 출력이 없는 경우 메시지가 처리되고 있지 않음을 의미합니다. 이 경우 Log Analytics로 이동하여 예외 또는 다른 오류를 찾습니다.
DevOps
가능하면 IaC(Infrastructure as Code)를 사용합니다. IaC는 Azure Resource Manager와 같은 선언적 접근 방식으로 인프라, 애플리케이션 및 스토리지 리소스를 관리합니다. 이는 DevOps를 CI/CD(연속 통합 및 지속적인 업데이트) 솔루션으로 사용하여 배포를 자동화하는 데 도움이 됩니다. 템플릿은 버전이 지정되고 릴리스 파이프라인의 일부로 포함되어야 합니다.
템플릿을 만들 때 워크로드별로 구성하고 격리하는 방법으로 리소스를 그룹화합니다. 워크로드를 생각하는 일반적인 방법은 단일 서버리스 애플리케이션 또는 가상 네트워크입니다. 워크로드 격리의 목적은 DevOps 팀이 해당 리소스의 모든 측면을 독립적으로 관리하고 CI/CD를 수행할 수 있도록 리소스를 팀과 연결하는 데 있습니다.
서비스를 배포할 때 서비스를 모니터링해야 합니다. Application Insights를 사용하여 개발자가 성능을 모니터링하고 문제를 검색할 수 있도록 하는 것이 좋습니다.
자세한 내용은 DevOps 검사 목록을 참조하세요.
재해 복구
여기에 표시된 배포는 단일 Azure 지역에 있습니다. 재해 복구에 더 탄력적인 방법을 적용하려면 다양한 서비스의 지리적 배포 기능을 활용합니다.
Event Hubs. 두 개의 Event Hubs 네임스페이스, 즉 기본(활성) 네임스페이스 및 보조(수동) 네임스페이스를 만듭니다. 메시지는 보조 네임스페이스로 장애 조치하지 않는 한 자동으로 활성 네임스페이스로 라우팅됩니다. 자세한 내용은 Azure Event Hubs 지역 재해 복구를 참조하세요.
함수 앱. 보조 Event Hubs 네임스페이스에서 읽기를 기다리는 두 번째 함수 앱을 배포합니다. 이 함수는 배달 못한 편지 큐에 대한 보조 스토리지 계정에 씁니다.
Azure Cosmos DB. Azure Cosmos DB는 다중 마스터 지역을 지원하므로 Azure Cosmos DB 계정에 추가하는 모든 지역에 쓸 수 있습니다. 다중 쓰기를 사용하도록 설정하지 않은 경우에도 주 쓰기 지역을 장애 조치(failover)할 수 있습니다. Azure Cosmos DB 클라이언트 SDK 및 Azure Function 바인딩은 장애 조치(failover)를 자동으로 처리하므로 애플리케이션 구성 설정을 업데이트할 필요가 없습니다.
Azure Storage. 배달 못한 편지 큐에 대해 RA-GRS 스토리지를 사용합니다. 이렇게 하면 읽기 전용 복제본이 다른 지역에 만들어집니다. 주 지역을 사용할 수 없게 되면 현재 큐에 있는 항목을 읽을 수 있습니다. 또한 장애 조치 후에 함수에서 쓸 수 있는 다른 스토리지 계정을 보조 지역에 프로비전합니다.
비용 최적화
비용 최적화는 불필요한 비용을 줄이고 운영 효율성을 높이는 방법을 찾는 것입니다. 자세한 내용은 비용 최적화 핵심 요소 개요를 참조하세요.
Azure 가격 계산기를 사용하여 비용을 예측합니다. 다음은 Azure Functions 및 Azure Cosmos DB에 대한 몇 가지 다른 고려 사항입니다.
Azure Functions
Azure Functions는 두 가지 호스팅 모델을 지원합니다.
- 사용 플랜. 코드가 실행되면 컴퓨팅 성능이 자동으로 할당됩니다.
- App Service 계획 VM(가상 머신) 세트가 코드에 할당됩니다. App Service 계획은 VM의 수와 크기를 정의합니다.
이 아키텍처에서 Event Hubs에 도착하는 각 이벤트는 해당 이벤트를 처리하는 함수를 트리거합니다. 비용 측면에서 사용하는 컴퓨팅 리소스에 대해서만 비용을 지불하므로 사용 플랜을 사용하는 것이 좋습니다.
Azure Cosmos DB
Azure Cosmos DB를 사용하면 데이터베이스를 대상으로 수행한 작업과 데이터에서 사용하는 스토리지에 대한 비용만 지불하게 됩니다.
- 데이터베이스 작업 데이터베이스 작업에 대해 청구되는 방식은 사용 중인 Azure Cosmos DB 계정 유형에 따라 다릅니다.
- 스토리지. 주어진 시간 동안 데이터 및 인덱스에서 소비한 총 스토리지 양(GB)에 대해 고정 요금이 청구됩니다.
이 참조 아키텍처에서 함수는 정확히 데이터를 보내는 디바이스당 하나의 문서를 저장합니다. 이 함수는 소비된 스토리지 측면에서 비용 효율적인 upsert 작업을 사용하여 최신 디바이스 상태로 문서를 지속적으로 업데이트합니다. 자세한 내용은 Azure Cosmos DB 가격 책정 모델을 참조하세요.
Azure Cosmos DB 용량 계산기를 사용하여 워크로드 비용을 빠르게 예측할 수 있습니다.
시나리오 배포
 이 아키텍처에 대한 참조 구현은 GitHub에서 사용할 수 있습니다.
이 아키텍처에 대한 참조 구현은 GitHub에서 사용할 수 있습니다.