Azure Arc 지원 SQL Managed Instance를 통한 고가용성
Azure Arc 지원 SQL Managed Instance는 Kubernetes에 컨테이너화된 애플리케이션으로 배포됩니다. 상태 저장 집합 및 영구 스토리지와 같은 Kubernetes 구성을 사용하여 다음과 같은 기본 제공 기능을 제공합니다.
- 상태 모니터링
- 실패 감지
- 서비스 상태를 유지하기 위한 자동 장애 조치.
안정성 향상을 위해 Azure Arc SQL 지원 Managed Instance를 구성하여 고가용성 구성에서 추가 복제본을 배포할 수도 있습니다. Arc 데이터 서비스 데이터 컨트롤러는 다음을 관리합니다.
- 모니터링
- 실패 감지
- 자동 장애 조치(Failover)
Arc 지원 데이터 서비스는 사용자 개입 없이 이 서비스를 제공합니다. 서비스는 다음을 수행합니다.
- 가용성 그룹을 설정합니다.
- 데이터베이스 미러링 엔드포인트를 구성합니다.
- 가용성 그룹에 데이터베이스를 추가합니다.
- 장애 조치 및 업그레이드를 조정합니다.
이 문서에서는 두 가지 유형의 고가용성을 모두 살펴봅니다.
Azure Arc 지원 SQL Managed Instance는 SQL Managed Instance가 범용 서비스 계층으로 배포되었는지 아니면 중요 비즈니스용 서비스 계층으로 배포되었는지에 따라 다양한 수준의 고가용성을 제공합니다.
범용 서비스 계층의 고가용성
범용 서비스 계층에는 사용 가능한 복제본이 하나만 있으며 Kubernetes 오케스트레이션을 통해 고가용성을 달성합니다. 예를 들어 관리되는 인스턴스 컨테이너 이미지가 포함된 Pod 또는 노드가 충돌하는 경우 Kubernetes는 다른 Pod 또는 노드를 세우고 동일한 영구 스토리지에 연결하려고 시도합니다. 이 시간 동안 SQL 관리되는 인스턴스는 애플리케이션에서 사용할 수 없습니다. 애플리케이션은 새 Pod가 작동할 때 다시 연결하고 트랜잭션을 다시 시도해야 합니다. load balancer이 사용된 서비스 형식인 경우 애플리케이션은 동일한 기본 엔드포인트에 다시 연결할 수 있으며 Kubernetes는 연결을 새 기본 엔드포인트로 리디렉션합니다. 서비스 형식이 nodeport인 경우 애플리케이션은 새 IP 주소에 다시 연결해야 합니다.
기본 제공 고가용성 확인
Kubernetes에서 제공하는 기본 제공 고가용성을 확인하려면 다음을 수행할 수 있습니다.
- 기존 관리되는 인스턴스의 Pod 삭제
- Kubernetes가 이 작업에서 복구되는지 확인
복구하는 동안 Kubernetes는 다른 Pod를 부트스트랩하고 영구 스토리지를 연결합니다.
필수 조건
- Kubernetes 클러스터에는 공유 원격 스토리지가 있어야 합니다.
- 하나의 복제본으로 배포된 Azure Arc 지원 SQL Managed Instance(기본값)
Pod 보기
kubectl get pods -n <namespace of data controller>관리되는 인스턴스 Pod를 삭제합니다.
kubectl delete pod <name of managed instance>-0 -n <namespace of data controller>예를 들면 다음과 같습니다.
user@pc:/# kubectl delete pod sql1-0 -n arc pod "sql1-0" deletedPod를 보고 관리되는 인스턴스가 복구 중인지 확인합니다.
kubectl get pods -n <namespace of data controller>예시:
user@pc:/# kubectl get pods -n arc NAME READY STATUS RESTARTS AGE sql1-0 2/3 Running 0 22s
Pod 내의 모든 컨테이너가 복구된 후 관리되는 인스턴스에 연결할 수 있습니다.
중요 비즈니스용 서비스 계층의 고가용성
중요 비즈니스용 서비스 계층에서 Kubernetes 오케스트레이션이 기본적으로 제공하는 것 외에도 Azure Arc용 SQL Managed Instance는 포함된 가용성 그룹을 제공합니다. 포함된 가용성 그룹은 SQL Server Always On 기술을 기반으로 합니다. 더 높은 수준의 가용성을 제공합니다. 중요 비즈니스용 서비스 계층과 함께 배포된 Azure Arc 지원 SQL Managed Instance는 2개 또는 3개의 복제본으로 배포할 수 있습니다. 이러한 복제본은 항상 서로 동기화된 상태로 유지됩니다.
포함된 가용성 그룹을 사용하면 Pod 크래시 또는 노드 오류가 애플리케이션에 투명하게 표시됩니다. 포함된 가용성 그룹은 주 Pod의 모든 데이터를 포함하고 연결을 수행할 준비가 된 하나 이상의 다른 Pod를 제공합니다.
포함된 가용성 그룹
가용성 그룹은 장애 조치(failover)가 있을 때 전체 데이터베이스 그룹이 단일 단위로 보조 복제본으로 장애 조치(failover)되도록 하나 이상의 사용자 데이터베이스를 논리 그룹에 바인딩합니다. 가용성 그룹은 사용자 데이터베이스의 데이터만 복제하지만 로그인, 권한 또는 에이전트 작업과 같은 시스템 데이터베이스의 데이터는 복제하지 않습니다. 포함된 가용성 그룹에는 msdb 및 master 데이터베이스와 같은 시스템 데이터베이스의 메타데이터가 포함됩니다. 로그인이 주 복제본에서 만들어지거나 수정되면 보조 복제본에서도 자동으로 만들어집니다. 마찬가지로 주 복제본에서 에이전트 작업이 만들어지거나 수정되면 보조 복제본도 이러한 변경 내용을 수신합니다.
Azure Arc 지원 SQL Managed Instance는 포함된 가용성 그룹의 이러한 개념을 취하고 Kubernetes 연산자를 추가하여 대규모로 배포 및 관리할 수 있습니다.
가용성 그룹이 포함된 기능은 다음을 가능하게 합니다.
여러 복제본과 함께 배포되면 Arc 지원 SQL Managed Instance와 이름이 같은 단일 가용성 그룹이 만들어집니다. 기본적으로 포함된 AG에는 기본을 포함하여 3개의 복제본이 있습니다. 가용성 그룹 만들기 또는 만들어진 가용성 그룹에 복제본 조인을 포함하여 가용성 그룹에 대한 모든 CRUD 작업은 내부적으로 관리됩니다. 인스턴스에서 더 많은 가용성 그룹을 만들 수 없습니다.
모든 사용자 및 시스템 데이터베이스(예:
master및msdb)를 포함하여 모든 데이터베이스가 가용성 그룹에 자동으로 추가됩니다. 이 기능은 가용성 그룹 복제본 전체에서 단일 시스템 보기를 제공합니다. 인스턴스에 직접 연결하는 경우containedag_master및containedag_msdb데이터베이스를 모두 확인합니다.containedag_*데이터베이스는 가용성 그룹 내의master및msdb를 나타냅니다.외부 엔드포인트는 가용성 그룹 내의 데이터베이스에 연결하기 위해 자동으로 프로비저닝됩니다. 이
<managed_instance_name>-external-svc엔드포인트는 가용성 그룹 수신기의 역할을 수행합니다.
Azure Portal을 사용하여 여러 복제본이 있는 Azure Arc 지원 SQL Managed Instance 배포
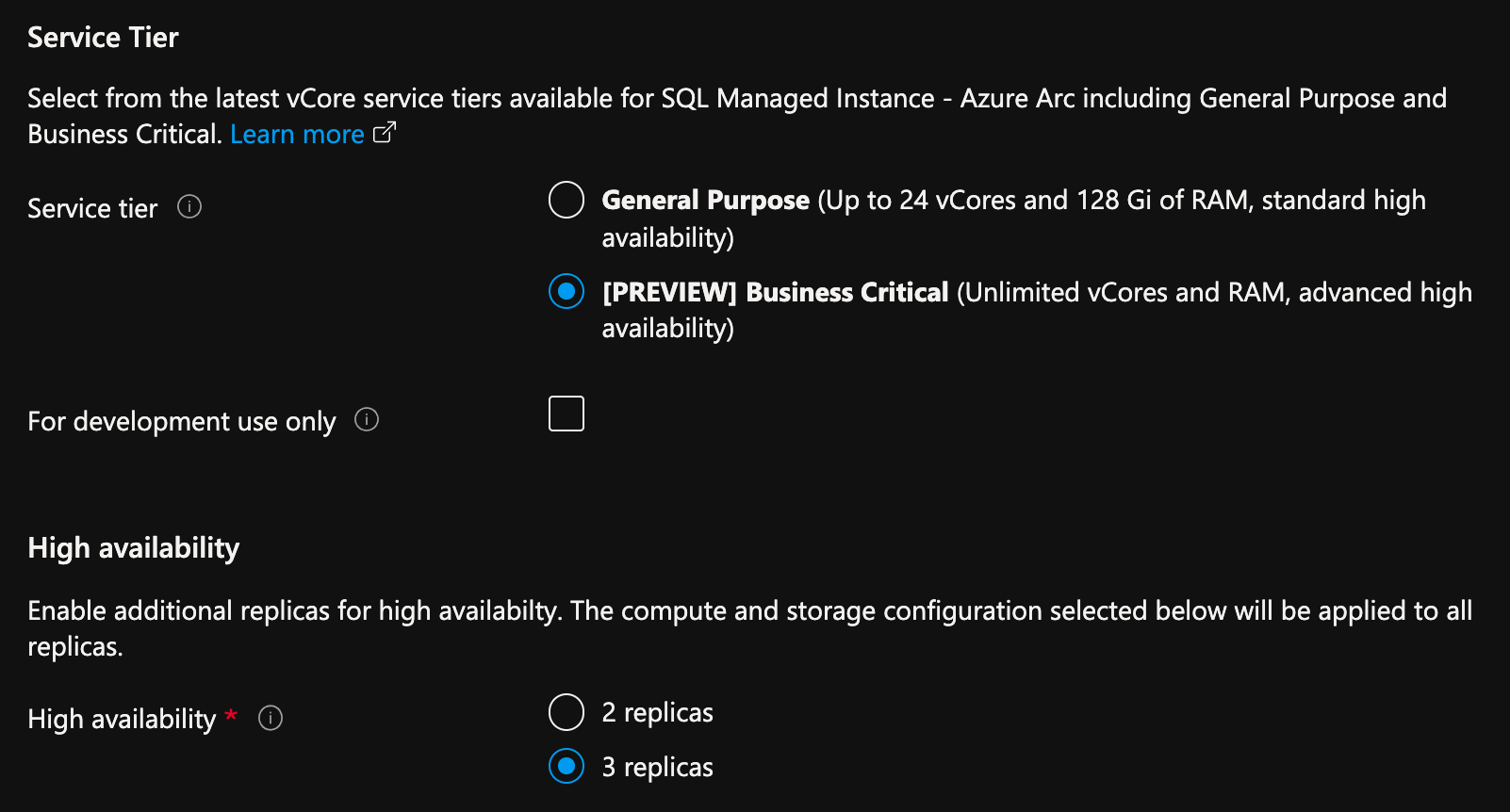
Azure Portal의 Azure Arc 지원 SQL Managed Instance 만들기 페이지에서 다음을 수행합니다.
- 컴퓨팅 + 스토리지에서 컴퓨팅 + 스토리지 구성을 선택합니다. 포털에 고급 설정이 표시됩니다.
- 서비스 계층에서 중요 비즈니스용을 선택합니다.
- 개발 목적으로 사용하는 경우 "개발 전용"에 체크합니다.
- 고가용성에서 복제본 2개 또는 복제본 3개를 선택합니다.
Azure CLI를 사용하여 여러 복제본으로 배포
Azure Arc 지원 SQL Managed Instance가 중요 비즈니스용 서비스 계층에 배포되면 여러 복제본이 만들어집니다. 이러한 인스턴스 간에 포함된 가용성 그룹의 설정 및 구성은 프로비저닝 중에 자동으로 수행됩니다.
예를 들어 다음 명령은 3개의 복제본이 있는 관리되는 인스턴스를 만듭니다.
간접적으로 연결된 모드:
az sql mi-arc create -n <instanceName> --k8s-namespace <namespace> --use-k8s --tier <tier> --replicas <number of replicas>
예시:
az sql mi-arc create -n sqldemo --k8s-namespace my-namespace --use-k8s --tier BusinessCritical --replicas 3
직접 연결 모드:
az sql mi-arc create --name <name> --resource-group <group> --location <Azure location> –subscription <subscription> --custom-location <custom-location> --tier <tier> --replicas <number of replicas>
예시:
az sql mi-arc create --name sqldemo --resource-group rg --location uswest2 –subscription xxxxxxx-xxxx-xxxx-xxxx-xxxxxxxxxxxx --custom-location private-location --tier BusinessCritical --replcias 3
기본적으로 모든 복제본은 동기 모드로 구성됩니다. 즉, 기본 인스턴스의 모든 업데이트가 각 보조 인스턴스에 동기식으로 복제됩니다.
고가용성 상태 보기 및 모니터링
배포가 완료되면 SQL Server Management Studio에서 기본 엔드포인트에 연결합니다.
주 복제본의 엔드포인트를 확인 및 검색하고 SQL Server Management Studio에서 연결합니다.
예를 들어, SQL 인스턴스가 service-type=loadbalancer를 사용하여 배포된 경우 아래 명령을 실행하여 연결할 엔드포인트를 검색합니다.
az sql mi-arc list --k8s-namespace my-namespace --use-k8s
또는
kubectl get sqlmi -A
기본 및 보조 엔드포인트 및 AG 상태 가져오기
kubectl describe sqlmi 또는 az sql mi-arc show 명령을 사용하여 기본 및 보조 엔드포인트와 고가용성 상태를 봅니다.
예시:
kubectl describe sqlmi sqldemo -n my-namespace
또는
az sql mi-arc show --name sqldemo --k8s-namespace my-namespace --use-k8s
예제 출력:
"status": {
"endpoints": {
"logSearchDashboard": "https://10.120.230.404:5601/app/kibana#/discover?_a=(query:(language:kuery,query:'custom_resource_name:sqldemo'))",
"metricsDashboard": "https://10.120.230.46:3000/d/40q72HnGk/sql-managed-instance-metrics?var-hostname=sqldemo-0",
"mirroring": "10.15.100.150:5022",
"primary": "10.15.100.150,1433",
"secondary": "10.15.100.156,1433"
},
"highAvailability": {
"healthState": "OK",
"mirroringCertificate": "-----BEGIN CERTIFICATE-----\n...\n-----END CERTIFICATE-----"
},
"observedGeneration": 1,
"readyReplicas": "2/2",
"state": "Ready"
}
SQL Server Management Studio를 사용하여 위의 기본 엔드포인트에 연결하고 다음과 같이 DMV를 확인할 수 있습니다.
SELECT * FROM sys.dm_hadr_availability_replica_states
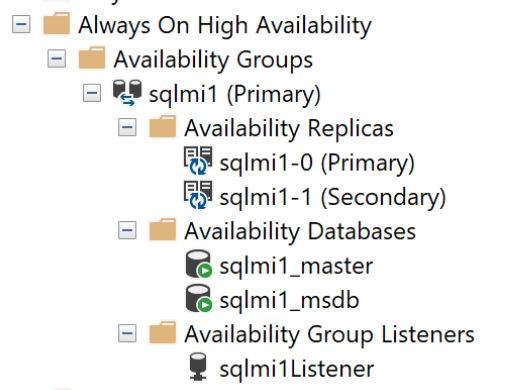
포함된 가용성 대시보드:
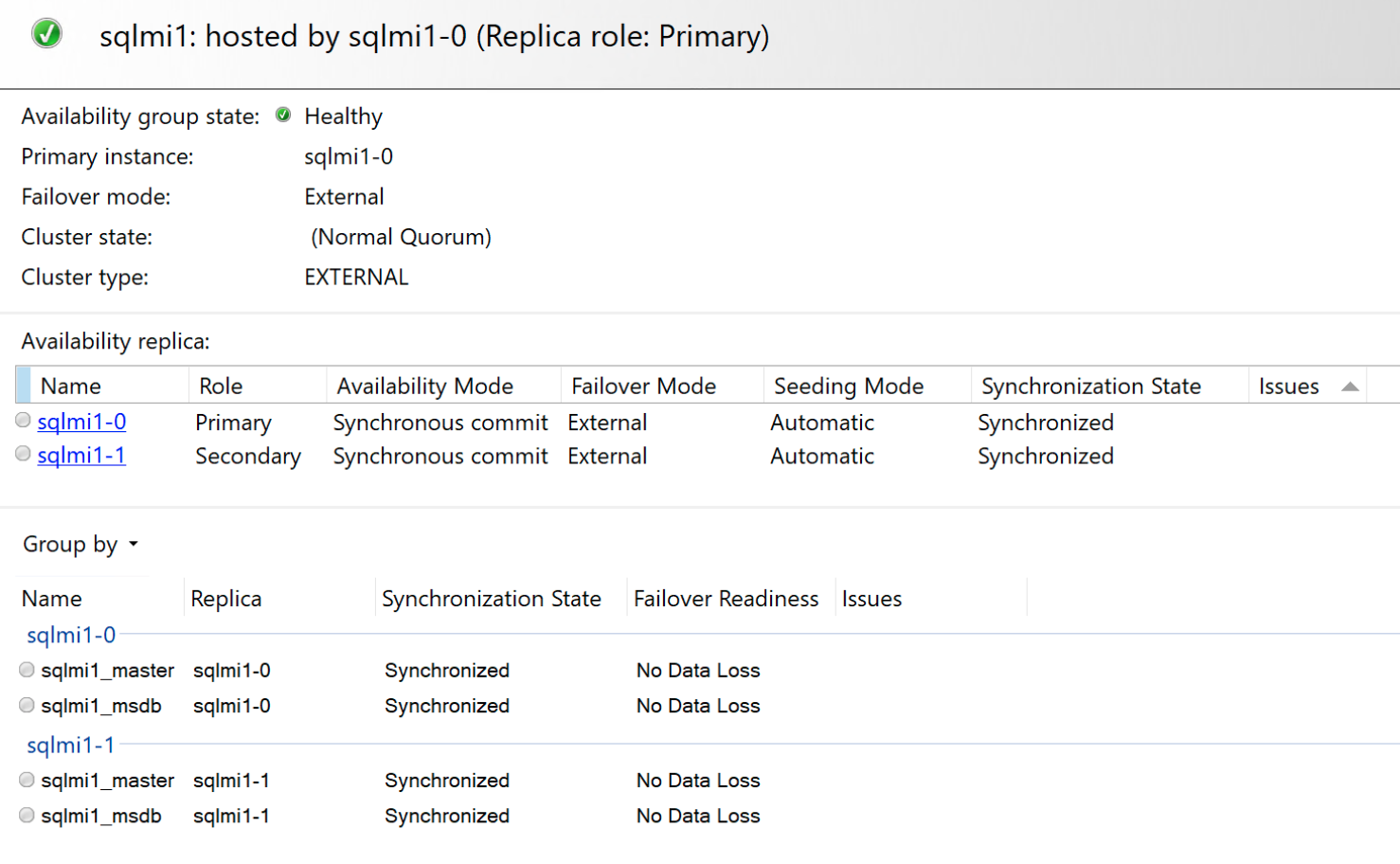
장애 조치(failover) 시나리오
SQL Server Always On 가용성 그룹과 달리 포함된 가용성 그룹은 관리되는 고가용성 솔루션입니다. 따라서 장애 조치(failover) 모드는 SQL Server Always On 가용성 그룹에서 사용할 수 있는 일반적인 모드에 비해 제한됩니다.
2개의 복제본 구성 또는 3개의 복제본 구성으로 중요 비즈니스용 서비스 계층 SQL Managed Instance를 배포합니다. 장애의 영향과 후속 복구 가능성은 구성마다 다릅니다. 3개의 복제본 인스턴스는 2개의 복제본 인스턴스보다 높은 수준의 가용성 및 복구를 제공합니다.
두 개의 복제본 구성에서 두 노드 상태가 모두 SYNCHRONIZED일 때 주 복제본을 사용할 수 없게 되면 보조 복제본이 주 복제본으로 자동 승격됩니다. 실패한 복제본을 사용할 수 있게 되면 보류 중인 모든 변경 내용으로 업데이트됩니다. 복제본 간에 연결 문제가 있는 경우 주 복제본에서 성공을 다시 반환하기 전에 모든 트랜잭션이 두 복제본에서 모두 커밋되어야 하므로 주 복제본은 트랜잭션을 커밋하지 않을 수 있습니다.
3개의 복제본 구성에서 트랜잭션은 애플리케이션에 성공 메시지를 다시 반환하기 전에 3개의 복제본 중 최소 2개에서 커밋해야 합니다. 장애가 발생하면 Kubernetes가 실패한 복제본을 복구하려고 시도하는 동안 보조 중 하나가 자동으로 주 복제본으로 승격됩니다. 복제본을 사용할 수 있게 되면 포함된 가용성 그룹과 자동으로 다시 조인되고 보류 중인 변경 내용이 동기화됩니다. 복제본 간에 연결 문제가 있고 2개 이상의 복제본이 동기화되지 않은 경우 주 복제본은 트랜잭션을 커밋하지 않습니다.
참고 항목
거의 0에 가까운 데이터 손실을 달성하려면 2개의 복제본 구성보다 3개의 복제본 구성으로 중요 비즈니스용 SQL Managed Instance를 배포하는 것이 좋습니다.
계획된 이벤트에 대해 주 복제본에서 보조 복제본 중 하나로 장애 조치(failover)하려면 다음 명령을 실행합니다.
주 복제본에 연결하는 경우 다음 T-SQL을 사용하여 SQL 인스턴스를 보조 복제본 중 하나로 장애 조치(failover)할 수 있습니다.
ALTER AVAILABILITY GROUP current SET (ROLE = SECONDARY);
보조 복제본에 연결하면 다음 T-SQL을 사용하여 원하는 보조 복제본을 주 복제본으로 승격할 수 있습니다.
ALTER AVAILABILITY GROUP current SET (ROLE = PRIMARY);
기본 설정 주 복제본
다음과 같이 AZ CLI를 사용하여 특정 복제본을 주 복제본으로 설정할 수도 있습니다.
az sql mi-arc update --name <sqlinstance name> --k8s-namespace <namespace> --use-k8s --preferred-primary-replica <replica>
예제:
az sql mi-arc update --name sqldemo --k8s-namespace my-namespace --use-k8s --preferred-primary-replica sqldemo-3
참고 항목
Kubernetes는 기본 복제본을 설정하려고 시도하지만 보장되지는 않습니다.
여러 복제본 인스턴스에 데이터베이스 복원
데이터베이스를 가용성 그룹으로 복원하려면 추가 단계가 필요합니다. 다음 단계에서는 데이터베이스를 관리되는 인스턴스로 복원하고 이를 가용성 그룹에 추가하는 방법을 보여 줍니다.
새 Kubernetes 서비스를 만들어 주 인스턴스 외부 엔드포인트를 노출합니다.
주 복제본을 호스팅하는 Pod를 결정합니다. 관리되는 인스턴스에 연결하고 다음을 실행합니다.
SELECT @@SERVERNAME쿼리는 주 복제본을 호스팅하는 Pod를 반환합니다.
Kubernetes 클러스터에서
NodePort서비스를 사용하는 경우 다음 명령을 실행하여 주 인스턴스에 대한 Kubernetes 서비스를 만듭니다.<podName>을 이전 단계에서 반환된 서버의 이름으로 바꾸고,<serviceName>을 만든 Kubernetes 서비스의 기본 설정 이름으로 바꿉니다.kubectl -n <namespaceName> expose pod <podName> --port=1533 --name=<serviceName> --type=NodePortLoadBalancer 서비스의 경우 생성된 서비스 유형이
LoadBalancer인 것을 제외하고 동일한 명령을 실행합니다. 예시:kubectl -n <namespaceName> expose pod <podName> --port=1533 --name=<serviceName> --type=LoadBalancer다음은 기본을 호스팅하는 Pod가
sql2-0인 Azure Kubernetes Service에 대해 실행되는 이 명령의 예입니다.kubectl -n arc-cluster expose pod sql2-0 --port=1533 --name=sql2-0-p --type=LoadBalancer생성한 Kubernetes 서비스의 IP를 가져옵니다.
kubectl get services -n <namespaceName>데이터베이스를 주 인스턴스 엔드포인트로 복원합니다.
주 인스턴스 컨테이너에 데이터베이스 백업 파일을 추가합니다.
kubectl cp <source file location> <pod name>:var/opt/mssql/data/<file name> -c <serviceName> -n <namespaceName>예시
kubectl cp /home/WideWorldImporters-Full.bak sql2-1:var/opt/mssql/data/WideWorldImporters-Full.bak -c arc-sqlmi -n arc아래 명령을 실행하여 데이터베이스 백업 파일을 복원합니다.
RESTORE DATABASE test FROM DISK = '/var/opt/mssql/data/<file name>.bak' WITH MOVE '<database name>' to '/var/opt/mssql/data/<file name>.mdf' ,MOVE '<database name>' to '/var/opt/mssql/data/<file name>_log.ldf' ,RECOVERY, REPLACE, STATS = 5; GO예시
RESTORE Database WideWorldImporters FROM DISK = '/var/opt/mssql/data/WideWorldImporters-Full.BAK' WITH MOVE 'WWI_Primary' TO '/var/opt/mssql/data/WideWorldImporters.mdf', MOVE 'WWI_UserData' TO '/var/opt/mssql/data/WideWorldImporters_UserData.ndf', MOVE 'WWI_Log' TO '/var/opt/mssql/data/WideWorldImporters.ldf', MOVE 'WWI_InMemory_Data_1' TO '/var/opt/mssql/data/WideWorldImporters_InMemory_Data_1', RECOVERY, REPLACE, STATS = 5; GO데이터베이스를 가용성 그룹에 추가합니다.
AG에 데이터베이스를 추가하려면 전체 복구 모드에서 실행해야 하고 로그 백업을 수행해야 합니다. 아래 TSQL 문을 실행하여 복원된 데이터베이스를 가용성 그룹에 추가합니다.
ALTER DATABASE <databaseName> SET RECOVERY FULL; BACKUP DATABASE <databaseName> TO DISK='<filePath>' ALTER AVAILABILITY GROUP containedag ADD DATABASE <databaseName>다음 예제에서는 인스턴스에 복원된
WideWorldImporters라는 데이터베이스를 추가합니다.ALTER DATABASE WideWorldImporters SET RECOVERY FULL; BACKUP DATABASE WideWorldImporters TO DISK='/var/opt/mssql/data/WideWorldImporters.bak' ALTER AVAILABILITY GROUP containedag ADD DATABASE WideWorldImporters
Important
모범 사례로 다음 명령을 실행하여 위에서 만든 Kubernetes Service를 삭제해야 합니다.
kubectl delete svc sql2-0-p -n arc
제한 사항
Azure Arc 지원 SQL Managed Instance 가용성 그룹에는 빅 데이터 클러스터 가용성 그룹과 동일한 제한 사항이 있습니다. 자세한 내용은 고가용성을 사용하여 SQL Server 빅 데이터 클러스터 배포를 참조하세요.
관련 콘텐츠
Azure Arc 지원 SQL Managed Instance의 특징 및 기능에 대해 자세히 알아보기