Azure SQL Database를 사용하여 Kubernetes 애플리케이션 개발
적용 대상:![]() Azure SQL Database
Azure SQL Database
이 자습서에서는 Python, Docker 컨테이너, Kubernetes 및 Azure SQL Database를 사용하여 최신 애플리케이션을 개발하는 방법을 알아봅니다.
최신 애플리케이션 개발에는 몇 가지 문제가 있습니다. 경쟁하고 있는 여러 표준에서 데이터 스토리지 및 처리를 통해 프런트 엔드의 "스택"을 선택하는 것부터 최고 수준의 보안 및 성능을 보장하는 것까지, 개발자는 애플리케이션이 확장되고, 잘 작동하고, 여러 플랫폼을 지원하게 만들어야 합니다. 이 마지막 요구 사항의 경우 애플리케이션을 Docker와 같은 컨테이너 기술로 묶고 Kubernetes 플랫폼에 여러 컨테이너를 배포하는 것은 이제 애플리케이션 개발에서 필수입니다.
이 예제에서는 Microsoft Azure 플랫폼에서 실행하는 Python, Docker 컨테이너 및 Kubernetes를 사용하는 방법을 살펴봅니다. Kubernetes를 사용하면 애플리케이션의 원활하고 일관된 배포를 위해 로컬 환경 또는 다른 클라우드를 유연하게 사용할 수 있으며 더 높은 복원력을 위해 다중 클라우드 배포가 가능합니다. 또한 데이터 스토리지 및 처리를 위해 Microsoft Azure SQL Database를 서비스를 기반으로 한 확장성 있고 복원력이 뛰어나며 안전한 환경에 사용합니다. 실제로 대부분의 경우 다른 애플리케이션은 이미 Microsoft Azure SQL Database를 사용하고 있으며 이 샘플 애플리케이션을 사용하여 해당 데이터를 추가로 사용하고 보강할 수 있습니다.
이 예제에서는 범위가 꽤 포괄적이지만 가장 간단한 애플리케이션, 데이터베이스 및 배포를 사용하여 프로세스를 보여줍니다. 반환된 데이터에 최신 기술을 사용하는 것을 포함하여 이 샘플을 훨씬 더 강력하게 조정할 수 있습니다. 이는 다른 애플리케이션을 위한 패턴을 만드는 유용한 학습 도구입니다.
실제 예제에서 Python, Docker 컨테이너, Kubernetes 및 AdventureWorksLT 샘플 데이터베이스 사용
AdventureWorks(가상) 회사는 영업 및 마케팅, 제품, 고객 및 제조에 대한 데이터를 저장하는 데이터베이스를 사용합니다. 제품 이름, 범주, 가격 및 간략한 설명과 같은 제품에 대한 정보를 조인하는 보기 및 저장 프로시저도 포함합니다.
AdventureWorks 개발 팀은 AdventureWorksLT 데이터베이스의 뷰에서 데이터를 반환하는 PoC(개념 증명)를 만들고 이를 REST API로 제공하려고 합니다. 개발 팀은 이 PoC를 사용하여 영업 팀을 위한 더 확장성 있으며 다중 클라우드에 준비된 애플리케이션을 만듭니다. 배포의 모든 측면에 Microsoft Azure 플랫폼을 선택했습니다. PoC는 다음 요소를 사용합니다.
- 헤드리스 웹 배포를 위해 Flask 패키지를 사용하는 Python 애플리케이션.
- 코드 및 환경 격리를 위한 Docker 컨테이너(회사 전체가 향후 프로젝트에서 애플리케이션 컨테이너를 다시 사용할 수 있도록 프라이빗 레지스트리에 저장하여 시간과 비용 절약).
- 배포 및 크기 조정의 용이성을 위한 Kubernetes(플랫폼 종속 방지).
- 가장 높은 보안 수준에서 관계형 데이터 스토리지 및 처리 외에도 크기, 성능, 크기 조정, 자동 관리 및 백업을 선택하기 위한 Microsoft Azure SQL Database.
이 문서에서는 전체 개념 증명 프로젝트를 만드는 프로세스를 설명합니다. 애플리케이션을 만드는 일반적인 단계는 다음과 같습니다.
- 전제 조건 설정
- 애플리케이션 만들기
- 애플리케이션을 배포하고 테스트하기 위해 Docker 컨테이너 만들기
- ACS(Azure Container Service) 레지스트리를 만들고 컨테이너를 ACS 레지스트리에 로드
- AKS(Azure Kubernetes Service) 환경 만들기
- ACS 레지스트리에서 AKS로 애플리케이션 컨테이너 배포
- 애플리케이션 테스트
- 정리
필수 조건
이 문서 전체에서 몇 가지 값을 바꾸어야 합니다. 각 단계에 대해 이러한 값을 일관되게 바꾸어야 합니다. 개념 증명 프로젝트를 통해 작업할 때 텍스트 편집기를 열고 이러한 값을 삭제하여 올바른 값을 설정할 수 있습니다.
ReplaceWith_AzureSubscriptionName: 이 값을 보유하고 있는 Azure 구독 이름으로 바꿉니다.ReplaceWith_PoCResourceGroupName: 이 값을 만들고자 하는 리소스 그룹의 이름으로 바꿉니다.ReplaceWith_AzureSQLDBServerName: 이 값을 Azure Portal을 사용하여 만든 Azure SQL Database 논리 서버의 이름으로 바꿉니다.ReplaceWith_AzureSQLDBSQLServerLoginName: 이 값을 Azure Portal에서 만든 SQL Server 사용자 이름의 값으로 바꿉니다.ReplaceWith_AzureSQLDBSQLServerLoginPassword: 이 값을 Azure Portal에서 만든 SQL Server 사용자 암호 값으로 바꿉니다.ReplaceWith_AzureSQLDBDatabaseName: 이 값을 Azure Portal을 사용하여 만든 Azure SQL Database의 이름으로 바꿉니다.ReplaceWith_AzureContainerRegistryName: 이 값을 만들고자 하는 Azure Container Registry의 이름으로 바꿉니다.ReplaceWith_AzureKubernetesServiceName: 이 값을 만들고자 하는 Azure Kubernetes Service의 이름으로 바꿉니다.
AdventureWorks를 사용하는 개발자는 개발을 위해 Windows, Linux 및 Apple 시스템을 혼합하여 사용하므로 Visual Studio Code를 소스 제어를 위한 환경 및 git로 사용하고 있으며, 모두 크로스 플랫폼을 실행합니다.
PoC의 경우 팀에는 다음과 같은 필수 구성 요소가 필요합니다.
Python, pip 및 패키지 - 개발 팀은 Python 프로그래밍 언어를 이 웹 기반 애플리케이션의 표준으로 선택합니다. 현재 버전 3.9를 사용하고 있지만 PoC 필수 패키지를 지원하는 모든 버전을 허용합니다.
- python.org에서 Python 버전 3.9를 다운로드할 수 있습니다.
팀은 데이터베이스 액세스를 위해
pyodbc패키지를 사용하고 있습니다.- pip 명령을 사용하여 pyodbc 패키지를 설치할 수 있습니다.
- Microsoft ODBC 드라이버 소프트웨어를 아직 설치하지 않은 경우 이것이 필요할 수 있습니다.
팀은 구성 변수를 제어하고 설정하기 위해
ConfigParser패키지를 사용하고 있습니다.- pip 명령을 사용하여 configparser 패키지를 설치할 수 있습니다.
팀은 애플리케이션을 위한 웹 인터페이스에 Flask 패키지를 사용하고 있습니다.
- Flask 라이브러리의 Python 버전을 설치할 수 있습니다.
다음으로
az팀은 구문으로 쉽게 식별할 수 있는 Azure CLI 도구를 설치했습니다. 이 크로스 플랫폼 도구를 사용하면 PoC에 대한 명령줄 및 스크립팅된 접근 방식을 허용하므로 변경 및 개선 작업을 수행할 때 단계를 반복할 수 있습니다.- Azure CLI 도구를 다운로드 및 설치할 수 있습니다.
Azure CLI를 설정하면 팀은 Azure 구독에 로그인하고 PoC에 사용한 구독 이름을 설정합니다. 그런 다음 Azure SQL Database 서버 및 데이터베이스가 구독에 액세스할 수 있는지 확인했습니다.
az login az account set --name "ReplaceWith_AzureSubscriptionName" az sql server list az sql db list ReplaceWith_AzureSQLDBDatabaseNameMicrosoft Azure 리소스 그룹은 Azure 솔루션을 위해 관련 리소스를 보관하는 논리 컨테이너입니다. 일반적으로 쉽게 배포하고, 업데이트하고, 그룹으로 삭제할 수 있도록 동일한 리소스 그룹에 동일한 수명 주기를 공유하는 리소스를 추가합니다. 리소스 그룹은 리소스에 대한 메타데이터를 저장하고 리소스 그룹의 위치를 지정할 수 있습니다.
리소스 그룹은 Azure Portal 또는 Azure CLI를 사용하여 만들고 관리할 수 있습니다. 리소스 그룹은 애플리케이션을 위해 관련 리소스를 그룹화하고 프로덕션 및 비프로덕션 또는 사용자가 원하는 다른 조직 구조를 위한 그룹으로 나누는 데 사용할 수도 있습니다.
다음 코드 조각에서는 리소스 그룹을 만드는 데 사용하는
az명령을 볼 수 있습니다. 샘플에서는 Azure의 eastus지역을 사용합니다.az group create --name ReplaceWith_PoCResourceGroupName --location eastus개발 팀은 SQL 인증 로그인을 사용하여
AdventureWorksLT샘플 데이터베이스를 설치한 Azure SQL Database를 만듭니다.AdventureWorks는 Microsoft SQL Server 관계형 데이터베이스 관리 시스템 플랫폼에서 표준화했으며 개발 팀은 로컬로 설치하는 대신 데이터베이스에 관리형 서비스를 사용하려고 합니다. Azure SQL Database를 사용하면 온-프레미스, 컨테이너, Linux 또는 Windows 또는 IoT(사물 인터넷) 환경에서 SQL Server 엔진을 실행하는 모든 위치에서 이 관리형 서비스의 코드를 완전히 호환할 수 있습니다.
만드는 동안 Azure 관리 포털을 사용하여 애플리케이션에 대한 방화벽을 로컬 개발 컴퓨터로 설정하고, 여기에 보이는 기본값을 변경하여 모든 Azure 서비스 허용을 사용하도록 설정하고, 연결 자격 증명을 검색하기도 했습니다.
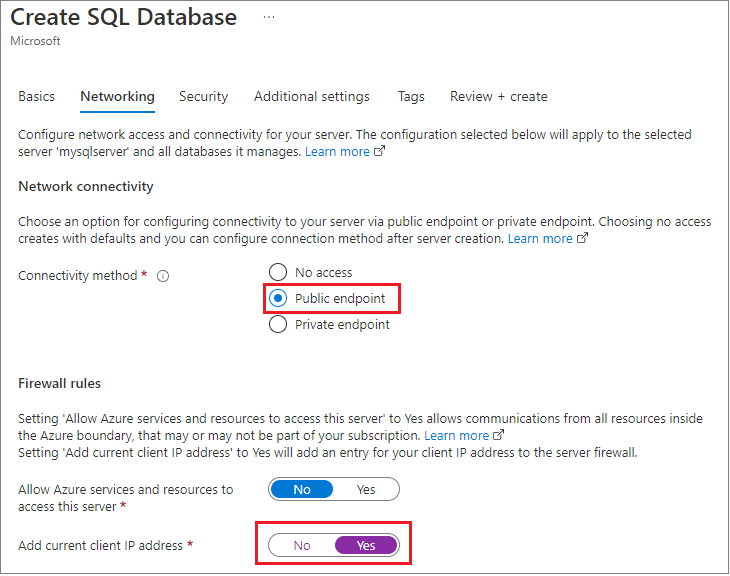
이 접근 방식을 사용하면 다른 지역이나 다른 구독에서도 데이터베이스에 액세스할 수 있습니다.
팀은 테스트를 위해 SQL 인증 로그인을 설정했지만 보안 검토에서 이 결정을 다시 검토합니다.
팀은 동일한 PoC 리소스 그룹을 사용하여 PoC에 샘플
AdventureWorksLT데이터베이스를 사용했습니다. 걱정하지 마세요. 이 자습서가 끝나면 이 새 PoC 리소스 그룹의 모든 리소스를 삭제합니다.Azure Portal을 사용하여 Azure SQL Database를 배포할 수 있습니다. Azure SQL Database를 만들 때 추가 설정 탭에서 기존 데이터 사용 옵션에 대해 샘플을 선택합니다.

마지막으로 새 Azure SQL Database의 태그 탭에서 개발 팀은 Owner 또는 ServiceClass 또는 WorkloadName과 같은 이 Azure 리소스를 위한 태그 메타데이터를 제공했습니다.

애플리케이션 만들기
다음으로 개발 팀은 Azure SQL Database에 대한 연결을 열고 제품 목록을 반환하는 간단한 Python 애플리케이션을 만들었습니다. 이 코드는 더 복잡한 함수로 대체하며, 애플리케이션 솔루션에 대한 강력한 매니페스트 기반 접근 방식을 위해 프로덕션에 있는 Kubernetes Pod에 배포한 애플리케이션을 둘 이상 포함할 수도 있습니다.
팀은 서버 연결 및 기타 정보에 대한 변수를 보관하기 위해
.env라는 간단한 텍스트 파일을 만들었습니다.python-dotenv라이브러리를 사용하여 Python 코드에서 변수를 분리할 수 있습니다. 이는 코드 자체에서 비밀 및 기타 정보를 유지하는 일반적인 접근 방식입니다.SQL_SERVER_ENDPOINT = ReplaceWith_AzureSQLDBServerName SQL_SERVER_USERNAME = ReplaceWith_AzureSQLDBSQLServerLoginName SQL_SERVER_PASSWORD = ReplaceWith_AzureSQLDBSQLServerLoginPassword SQL_SERVER_DATABASE = ReplaceWith_AzureSQLDBDatabaseName주의
명확성과 단순성을 위해 이 애플리케이션은 Python에서 읽은 구성 파일을 사용합니다. 코드를 컨테이너와 함께 배포하므로 연결 정보가 콘텐츠에서 파생될 수 있습니다. 보안, 연결 및 비밀을 사용하는 다양한 방법을 신중하게 고려하고 애플리케이션에 사용해야 하는 최상의 수준과 메커니즘을 결정해야 합니다. 항상 가장 높은 수준의 보안과 여러 수준을 선택하여 애플리케이션의 보안을 보장합니다. 연결 문자열과 같은 비밀 정보를 사용하는 여러 옵션이 있으며 다음 목록에는 이러한 옵션 중 몇 가지가 나와 있습니다.
자세한 내용은 Azure SQL Database 보안을 참조하세요.
- Python에서 비밀을 사용하는 또 다른 방법은 python-secrets 라이브러리를 사용하는 것입니다.
- Docker 보안 및 비밀을 검토하세요.
- Kubernetes 비밀을 검토하세요.
- Microsoft Entra(구 Azure Active Directory) 인증에 대해 자세히 알아볼 수도 있습니다.
팀은 다음으로 PoC 애플리케이션을 작성하고 이름을
app.py로 설정했습니다.다음 스크립트는 다음 단계를 완료합니다.
- 구성 및 기본 웹 인터페이스의 라이브러리를 설정합니다.
.env파일에서 변수를 로드합니다.- Flask-RESTful 애플리케이션을 만듭니다.
config.ini파일 값을 사용하여 Azure SQL Database 연결 정보를 가져옵니다.config.ini파일 값을 사용하여 Azure SQL Database에 연결합니다.pyodbc패키지를 사용하여 Azure SQL Database에 연결합니다.- 데이터베이스에 대해 실행할 SQL 쿼리를 실행합니다.
- API에서 데이터를 반환하는 데 사용할 클래스를 만듭니다.
- API 엔드포인트를
Products클래스로 설정합니다. - 마지막으로 기본 Flask 포트 5000에서 앱을 시작합니다.
# Set up the libraries for the configuration and base web interfaces from dotenv import load_dotenv from flask import Flask from flask_restful import Resource, Api import pyodbc # Load the variables from the .env file load_dotenv() # Create the Flask-RESTful Application app = Flask(__name__) api = Api(app) # Get to Azure SQL Database connection information using the config.ini file values server_name = os.getenv('SQL_SERVER_ENDPOINT') database_name = os.getenv('SQL_SERVER_DATABASE') user_name = os.getenv('SQL_SERVER_USERNAME') password = os.getenv('SQL_SERVER_PASSWORD') # Create connection to Azure SQL Database using the config.ini file values ServerName = config.get('Connection', 'SQL_SERVER_ENDPOINT') DatabaseName = config.get('Connection', 'SQL_SERVER_DATABASE') UserName = config.get('Connection', 'SQL_SERVER_USERNAME') PasswordValue = config.get('Connection', 'SQL_SERVER_PASSWORD') # Connect to Azure SQL Database using the pyodbc package # Note: You may need to install the ODBC driver if it is not already there. You can find that at: # https://learn.microsoft.com/sql/connect/odbc/download-odbc-driver-for-sql-server connection = pyodbc.connect(f'Driver=ODBC Driver 17 for SQL Server;Server={ServerName};Database={DatabaseName};uid={UserName};pwd={PasswordValue}') # Create the SQL query to run against the database def query_db(): cursor = connection.cursor() cursor.execute("SELECT TOP (10) [ProductID], [Name], [Description] FROM [SalesLT].[vProductAndDescription] WHERE Culture = 'EN' FOR JSON AUTO;") result = cursor.fetchone() cursor.close() return result # Create the class that will be used to return the data from the API class Products(Resource): def get(self): result = query_db() json_result = {} if (result == None) else json.loads(result[0]) return json_result, 200 # Set the API endpoint to the Products class api.add_resource(Products, '/products') # Start App on default Flask port 5000 if __name__ == "__main__": app.run(debug=True)이 애플리케이션이 로컬에서 실행되고
http://localhost:5000/products에 페이지를 반환하는지 확인했습니다.
Important
프로덕션 애플리케이션을 빌드할 때는 관리자 계정을 사용하여 데이터베이스에 액세스하지 마세요. 자세한 내용은 애플리케이션에 계정을 설정하는 방법을 참조하세요. 이 문서의 코드는 Azure에서 Python 및 Kubernetes를 사용하여 애플리케이션을 빠르게 시작할 수 있도록 간소화되었습니다.
더 현실적으로는 읽기 전용 권한이 있는 포함된 데이터베이스 사용자 또는 읽기 전용 권한이 있는 사용자가 할당 관리 ID에 연결된 로그인 또는 포함된 데이터베이스 사용자를 사용할 수 있습니다.
자세한 내용은 Python 및 Azure SQL Database를 사용하여 API를 만드는 방법에 대한 완전한 예제를 검토하세요.

Docker 컨테이너에 애플리케이션 배포
컨테이너는 격리 및 캡슐화를 제공하는 컴퓨팅 시스템의 지정 및 보호 공간입니다. 컨테이너를 만들려면 포함하고자 하는 이진 파일 및 코드를 설명하는 텍스트 파일인 매니페스트 파일을 사용합니다. 컨테이너 런타임(예: Docker)을 사용하여 실행하고 참조하고자 하는 모든 파일이 있는 이진 이미지를 만들 수 있습니다. 여기에서 이진 이미지를 "실행"할 수 있으며, 이를 컨테이너라고 합니다. 컨테이너는 전체 컴퓨팅 시스템인 것처럼 참조할 수 있습니다. 전체 가상 컴퓨터를 사용하는 것보다 애플리케이션 런타임 및 환경을 추상화할 수 있는 더 작고 간단한 방법입니다. 자세한 내용은 컨테이너 및 Docker를 참조하세요.
팀은 팀에서 사용하고자 하는 요소를 계층화한 DockerFile(매니페스트)로 시작했습니다. pyodbc 라이브러리를 이미 설치한 기본 Python 이미지로 시작한 다음, 이전 단계에서 프로그램 및 구성 파일을 포함하는 데 필요한 모든 명령을 실행합니다.
다음 Dockerfile에는 다음 단계가 있습니다.
- Python 및
pyodbc를 이미 설치한 컨테이너 이진 파일로 시작합니다. - 애플리케이션의 작업 디렉터리를 만듭니다.
- 현재 디렉터리의 모든 코드를
WORKDIR에 복사합니다. - 필요한 라이브러리를 설치합니다.
- 컨테이너를 시작한 후 애플리케이션을 실행하고 모든 TCP/IP 포트를 엽니다.
# syntax=docker/dockerfile:1
# Start with a Container binary that already has Python and pyodbc installed
FROM laudio/pyodbc
# Create a Working directory for the application
WORKDIR /flask2sql
# Copy all of the code from the current directory into the WORKDIR
COPY . .
# Install the libraries that are required
RUN pip install -r ./requirements.txt
# Once the container starts, run the application, and open all TCP/IP ports
CMD ["python3", "-m" , "flask", "run", "--host=0.0.0.0"]
해당 파일을 사용하는 상태에서 팀은 코딩 디렉터리의 명령 프롬프트로 이동하고 다음 코드를 실행하여 매니페스트에서 이진 이미지를 만든 다음 컨테이너를 시작하는 다른 명령을 실행했습니다.
docker build -t flask2sql .
docker run -d -p 5000:5000 -t flask2sql
다시 한 번 팀은 http://localhost:5000/products 링크를 테스트하여 컨테이너가 데이터베이스에 액세스할 수 있는지 확인하고 다음 반환을 확인합니다.

Docker 레지스트리에 이미지 배포
이제 컨테이너는 작동하지만 개발자 컴퓨터에서만 사용할 수 있습니다. 개발 팀은 이 애플리케이션 이미지를 회사의 나머지 부서에 제공한 다음, 프로덕션 배포를 위해 Kubernetes에 제공하고자 합니다.
컨테이너 이미지의 스토리지 영역은 리포지토리라고 하며 컨테이너 이미지를 위한 공용 리포지토리 및 프라이빗 리포지토리가 모두 있을 수 있습니다. 실제로 AdvenureWorks는 Dockerfile에서 Python 환경을 위해 공용 이미지를 사용했습니다.
팀은 이미지에 대한 액세스를 제어하고 웹에 배치하는 대신 자체적으로 호스팅하기로 결정하지만 보안 및 액세스를 완전히 제어할 수 있는 Microsoft Azure에서 호스팅하고자 합니다. Microsoft Azure Container Registry에 대한 자세한 내용은 여기를 참조하세요.
명령줄로 돌아가서 개발 팀은 컨테이너 레지스트리 서비스를 추가하고, 관리 계정을 사용하도록 설정하고, 테스트 단계에서 익명 "끌어오기"로 설정하고, 레지스트리에 로그인 컨텍스트를 설정하는 데 az CLI를 사용합니다.
az acr create --resource-group ReplaceWith_PoCResourceGroupName --name ReplaceWith_AzureContainerRegistryName --sku Standard
az acr update -n ReplaceWith_AzureContainerRegistryName --admin-enabled true
az acr update --name ReplaceWith_AzureContainerRegistryName --anonymous-pull-enabled
az acr login --name ReplaceWith_AzureContainerRegistryName
이 컨텍스트는 후속 단계에서 사용합니다.
로컬 Docker 이미지에 태그를 지정하여 업로드 준비
다음 단계는 클라우드에서 사용할 수 있도록 로컬 애플리케이션 컨테이너 이미지를 ACR(Azure Container Registry) 서비스로 보내는 것입니다.
- 다음 샘플 스크립트에서 팀은 Docker 명령을 사용하여 컴퓨터의 이미지를 나열합니다.
az CLI유틸리티를 사용하여 ACR 서비스의 이미지를 나열합니다.- Docker 명령을 사용하여 이전 단계에서 만든 ACR의 대상 이름으로 이미지에 "태그"를 지정하고 적절한 DevOps에 버전 번호를 설정합니다.
- 마지막으로 태그를 올바르게 적용했는지 확인하기 위해 로컬 이미지 정보를 다시 나열합니다.
docker images
az acr list --resource-group ReplaceWith_PoCResourceGroupName --query "[].{acrLoginServer:loginServer}" --output table
docker tag flask2sql ReplaceWith_AzureContainerRegistryName.azurecr.io/azure-flask2sql:v1
docker images
코드 작성 및 테스트, Dockerfile, 이미지 및 컨테이너 실행 및 테스트, ACR 서비스 설정 및 적용한 모든 태그를 사용하여 팀은 ACR 서비스에 이미지를 업로드할 수 있습니다.
Docker "push" 명령을 사용하여 파일을 보낸 다음, az CLI 유틸리티를 사용하여 이미지를 로드했는지 확인합니다.
docker push ReplaceWith_AzureContainerRegistryName.azurecr.io/azure-flask2sql:v1
az acr repository list --name ReplaceWith_AzureContainerRegistryName --output table
Kubernetes에 배포
팀은 단순히 컨테이너를 실행하고 온-프레미스 및 클라우드 내 환경에 애플리케이션을 배포할 수 있습니다. 그러나 크기 조정 및 가용성을 위해 애플리케이션의 여러 복사본을 추가하고, 다른 작업을 수행하는 다른 컨테이너를 추가하고, 모니터링 및 계측을 전체 솔루션에 추가하고자 합니다.
컨테이너를 완전한 솔루션으로 그룹화하기 위해 팀은 Kubernetes를 사용하기로 했습니다. Kubernetes는 온-프레미스 및 모든 주요 클라우드 플랫폼에서 실행할 수 있습니다. Microsoft Azure에는 AKS(Azure Kubernetes Service)라고 하는 Kubernetes를 위한 완전한 관리형 환경이 있습니다. Azure에서의 Kubernetes 소개 학습 경로를 사용하여 AKS에 대해 자세히 알아보세요.
az CLI 유틸리티를 사용하여 팀은 앞서 만든 동일한 리소스 그룹에 AKS를 추가합니다. 개발 팀은 단일 az 명령을 사용하여 다음 단계를 수행합니다.
- 테스트 단계에서 복원력을 위해 2개의 "노드" 또는 컴퓨팅 환경 추가
- 환경에 액세스하기 위해 SSH 키 자동 생성
- AKS 클러스터가 배포에 사용하고자 하는 이미지를 찾을 수 있도록 이전 단계에서 만든 ACR 서비스 연결
az aks create --resource-group ReplaceWith_PoCResourceGroupName --name ReplaceWith_AzureKubernetesServiceName --node-count 2 --generate-ssh-keys --attach-acr ReplaceWith_AzureContainerRegistryName
Kubernetes는 명령줄 도구를 사용하여 kubectl이라는 클러스터에 액세스하고 제어합니다. 팀은 az CLI 유틸리티를 사용하여 kubectl 도구를 다운로드하고 설치합니다.
az aks install-cli
현재 AKS에 연결되어 있으므로 kubectl 유틸리티를 실행할 때 사용할 연결을 위해 SSH 키를 전송하도록 요청할 수 있습니다.
az aks get-credentials --resource-group ReplaceWith_PoCResourceGroupName --name ReplaceWith_AzureKubernetesServiceName
이러한 키는 사용자의 디렉터리에 있는 .config라는 파일에 저장합니다. 이 보안 컨텍스트 집합을 사용하여 팀은 kubectl get nodes를 사용하여 클러스터에 노드를 표시합니다.
kubectl get nodes
이제 팀은 az CLI 도구를 사용하여 ACR 서비스의 이미지를 나열합니다.
az acr list --resource-group ReplaceWith_PoCResourceGroupName --query "[].{acrLoginServer:loginServer}" --output table
이제 Kubernetes가 배포를 제어하는 데 사용하는 매니페스트를 빌드할 수 있습니다. 이는 yaml 형식으로 저장한 텍스트 파일입니다. flask2sql.yaml 파일에서 주석을 단 텍스트는 다음과 같습니다.
apiVersion: apps/v1
# The type of commands that will be sent, along with the name of the deployment
kind: Deployment
metadata:
name: flask2sql
# This section sets the general specifications for the application
spec:
replicas: 1
selector:
matchLabels:
app: flask2sql
strategy:
rollingUpdate:
maxSurge: 1
maxUnavailable: 1
minReadySeconds: 5
template:
metadata:
labels:
app: flask2sql
spec:
nodeSelector:
"kubernetes.io/os": linux
# This section sets the location of the Image(s) in the deployment, and where to find them
containers:
- name: flask2sql
image: bwoodyflask2sqlacr.azurecr.io/azure-flask2sql:v1
# Recall that the Flask application uses (by default) TCIP/IP port 5000 for access. This line tells Kubernetes that this "pod" uses that address.
ports:
- containerPort: 5000
---
apiVersion: v1
# This is the front-end of the application access, called a "Load Balancer"
kind: Service
metadata:
name: flask2sql
spec:
type: LoadBalancer
# this final step then sets the outside exposed port of the service to TCP/IP port 80, but maps it internally to the app's port of 5000
ports:
- protocol: TCP
port: 80
targetPort: 5000
selector:
app: flask2sql
flask2sql.yaml 파일을 정의하면 팀은 애플리케이션을 실행 중인 AKS 클러스터에 배포할 수 있습니다. 이 작업은 클러스터에 대한 보안 컨텍스트가 여전히 존재하는 kubectl apply 명령으로 수행합니다. 그런 다음 클러스터가 빌드되는 것을 감시하기 위해 kubectl get service 명령을 전송합니다.
kubectl apply -f flask2sql.yaml
kubectl get service flask2sql --watch
잠시 후 "watch" 명령은 외부 IP 주소를 반환합니다. 이때 팀은 Ctrl-C를 눌러 watch 명령을 중단하고 부하 분산 장치의 외부 IP 주소를 기록합니다.
애플리케이션 테스트
팀은 마지막 단계에서 얻은 IP 주소(엔드포인트)를 사용하여 로컬 애플리케이션 및 Docker 컨테이너와 동일한 출력을 보장하기 위해 확인합니다.
정리
애플리케이션을 만들고, 편집하고, 문서화하고, 테스트하면 팀은 이제 애플리케이션을 "삭제"할 수 있습니다. Microsoft Azure의 단일 리소스 그룹에 모든 항목을 유지하면 az CLI 유틸리티를 사용하여 PoC 리소스 그룹을 삭제하는 일은 간단합니다.
az group delete -n ReplaceWith_PoCResourceGroupName -y
참고 항목
다른 리소스 그룹에서 Azure SQL Database를 만들었지만 더 이상 필요하지 않은 경우 Azure Portal을 사용하여 삭제할 수 있습니다.
PoC 프로젝트를 이끄는 팀 구성원은 Microsoft Windows를 워크스테이션으로 사용하며 Kubernetes에서 비밀 파일을 유지하지만 시스템에서 활성 위치로 제거하고자 합니다. 파일을 config.old 텍스트 파일에 복사한 다음 삭제하기만 하면 됩니다.
copy c:\users\ReplaceWith_YourUserName\.kube\config c:\users\ReplaceWith_YourUserName\.kube\config.old
del c:\users\ReplaceWith_YourUserName\.kube\config
관련 콘텐츠
피드백
출시 예정: 2024년 내내 콘텐츠에 대한 피드백 메커니즘으로 GitHub 문제를 단계적으로 폐지하고 이를 새로운 피드백 시스템으로 바꿀 예정입니다. 자세한 내용은 다음을 참조하세요. https://aka.ms/ContentUserFeedback
다음에 대한 사용자 의견 제출 및 보기