Azure SQL 데이터베이스 Elastic 쿼리 개요(미리 보기)
적용 대상:![]() Azure SQL Database
Azure SQL Database
탄력적 쿼리 기능(미리 보기)을 사용하면 Azure SQL 데이터베이스에서 여러 데이터베이스에 걸쳐 있는 Transact-SQL 쿼리를 실행할 수 있습니다. 교차 데이터베이스 쿼리를 수행하여 원격 테이블에 액세스하고, Microsoft 및 타사 도구(Excel, Power BI, Tableau 등)를 연결하여 여러 데이터베이스가 있는 데이터 계층에서 쿼리할 수 있습니다. 이 기능을 사용하여 큰 데이터 계층에 대한 쿼리를 스케일 아웃할 수 있으며 BI(비즈니스 인텔리전스) 보고서의 결과를 시각화할 수 있습니다.
탄력적 쿼리를 사용하는 이유
Azure SQL Database
T-SQL에서 Azure SQL 데이터베이스의 데이터베이스를 완전히 쿼리합니다. 이를 통해 원격 데이터베이스에 대한 읽기 전용 쿼리가 가능하며, 현재 SQL Server 고객이 3~4개의 이름을 사용하는 애플리케이션 또는 연결된 서버를 SQL 데이터베이스로 마이그레이션할 수 있는 옵션을 제공합니다.
모든 서비스 계층에서 사용 가능
탄력적 쿼리는 Azure SQL Database의 모든 서비스 계층에서 지원됩니다. 낮은 서비스 계층에 대한 성능 제한 사항은 아래 미리 보기 제한 사항에 대한 섹션을 참조하세요.
원격 데이터베이스에 매개 변수 푸시
탄력적 쿼리는 이제 실행을 위해 원격 데이터베이스에 SQL 매개 변수를 푸시할 수 있습니다.
저장 프로시저 실행
sp_execute _remote를 사용하여 원격 저장된 프로시저 호출 또는 원격 함수를 실행합니다.
유연성
탄력적 쿼리가 있는 외부 테이블은 다른 스키마 또는 테이블 이름을 가진 원격 테이블을 참조할 수 있습니다.
탄력적 쿼리 시나리오
목표는 여러 데이터베이스가 행을 단일 전체 결과에 기여하는 쿼리 시나리오를 용이하게 하는 것입니다. 쿼리는 사용자 또는 애플리케이션에서 직접 구성하거나 데이터베이스에 연결된 도구를 통해 간접적으로 구성할 수 있습니다. 이는 상용 BI 또는 데이터 통합 도구나 사용하거나 변경할 수 없는 애플리케이션을 만들 때 특히 유용합니다. 탄력적 쿼리를 사용하여 Excel, PowerBI, Tableau 또는 Cognos 같은 도구에서 친숙한 SQL 서버 연결 환경을 사용하여 여러 데이터베이스를 쿼리할 수 있습니다. 탄력적 쿼리는 또한 SQL Server Management Studio 또는 Visual Studio에서 발급하는 쿼리를 통해 전체 데이터베이스 컬렉션에 쉽게 액세스할 수 있으며, Entity Framework 또는 기타 ORM 환경에서 데이터 베이스 간 쿼리를 수월하게 해줍니다. 그림 1은 기존 클라우드 애플리케이션(탄력적 데이터베이스 클라이언트 라이브러리 사용)이 확장된 데이터 계층에 빌드되고 탄력적 쿼리가 데이터베이스 간 보고에 사용되는 시나리오를 보여 줍니다.
그림 1 스케일 아웃 데이터 계층에서 사용하는 탄력적 쿼리

탄력적 쿼리에 대한 고객 시나리오는 다음 토폴로지로 특정됩니다.
- 수직 분할 – 데이터베이스 간 쿼리 (토폴로지 1): 한 데이터 계층의 많은 데이터베이스 간에 데이터를 수직으로 분할합니다. 일반적으로 여러 테이블 집합이 서로 다른 데이터베이스에 상주합니다. 즉 스키마가 데이터베이스마다 서로 다릅니다. 예를 들어 인벤토리의 모든 테이블은 하나의 데이터베이스에 있고 모든 계정 관련 테이블은 두 번째 데이터베이스에 있습니다. 이 토폴로지의 일반적인 사용 사례에서는 여러 데이터베이스의 테이블에서 보고서를 쿼리하거나 컴파일해야 합니다.
- 수평 분할 - 분할 (토폴로지 2): 데이터가 수평으로 분할되어 확장된 데이터 계층에 행을 분산합니다. 이 방법에서는 스키마가 모든 분할 데이터베이스에서 동일합니다. 이 방법을 "분할"이라고도 합니다. 분할은 (1) 탄력적 데이터베이스 도구 라이브러리 또는 (2) 자체 분할을 사용하여 수행하고 관리할 수 있습니다. 탄력적 쿼리는 여러 분할된 데이터베이스에서 보고서를 쿼리하거나 컴파일하는 데 사용됩니다. 분할된 데이터베이스는 일반적으로 탄력적 풀 내의 데이터베이스입니다. 데이터베이스가 공통 스키마를 공유하는 한 탄력적 쿼리를 탄력적 풀의 모든 데이터베이스를 한 번에 쿼리하는 효율적인 방법으로 생각할 수 있습니다.
참고 항목
탄력적 쿼리는 대부분의 처리(필터링, 집계)를 외부 원본 쪽에서 수행할 수 있는 보고 시나리오에 가장 적합합니다. 많은 양의 데이터가 원격 데이터베이스에서 전송되는 ETL 작업에는 적합하지 않습니다. 쿼리가 보다 복잡한 과도한 보고 작업 부하 또는 데이터 웨어하우징 시나리오의 경우, Azure Synapse Analytics사용을 고려합니다.
수직 분할 - 교차 데이터베이스 쿼리
코딩을 시작하려면 교차 데이터베이스 쿼리 시작(수직 분할)을 참조하세요.
탄력적 쿼리를 사용하여 SQL Database의 데이터베이스에 있는 데이터를 다른 SQL Database의 데이터베이스에서 사용하도록 할 수 있습니다. 이렇게 하면 한 데이터베이스의 쿼리가 SQL Database의 다른 원격 데이터베이스에 있는 테이블을 참조할 수 있습니다. 첫 번째 단계는 각 원격 데이터베이스에 대한 외부 데이터 원본을 정의하는 것입니다. 외부 데이터 원본은 원격 데이터베이스에 있는 테이블에 액세스하려는 로컬 데이터베이스에 정의됩니다. 원격 데이터베이스 변경은 필요하지 않습니다. 서로 다른 데이터베이스에 서로 다른 스키마가 있는 일반적인 수직 분할 시나리오의 경우 탄력적 쿼리를 사용하여 참조 데이터에 대한 액세스 및 데이터베이스 간 쿼리와 같은 일반적인 사용 사례를 구현할 수 있습니다.
Important
사용자에게 모든 외부 데이터 원본 ALTER 권한이 있어야 합니다. 이 사용 권한은 ALTER DATABASE 권한에 포함됩니다. 기본 데이터 원본을 참조하기 위해 ALTER ANY EXTERNAL DATA SOURCE 권한이 필요합니다.
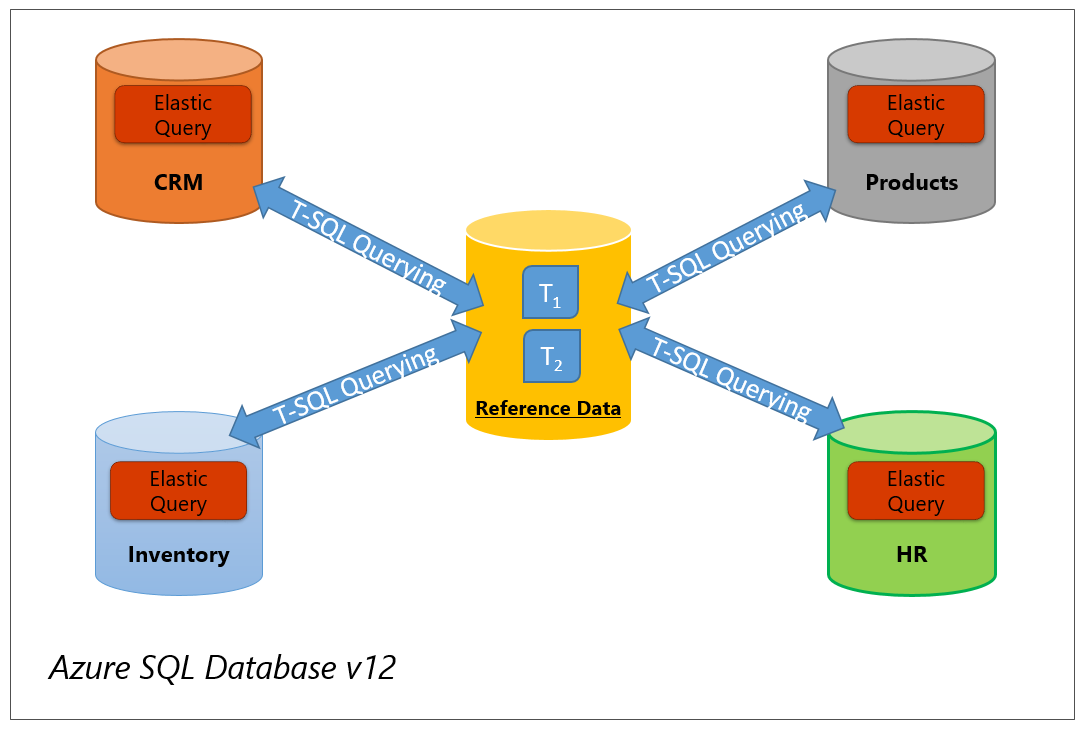
참조 데이터: 토폴로지는 참조 데이터 관리에 사용됩니다. 아래 그림에서는 전용 데이터베이스에 참조 데이터가 있는 두 테이블(T1과 T2)이 유지됩니다. 탄력적 쿼리를 사용하면 그림과 같이 다른 데이터베이스에서 원격으로 T1 및 T2 테이블에 액세스할 수 있습니다. 참조 테이블이 작거나 참조 테이블에 대한 원격 쿼리에 선택적 조건자가 있는 경우 토폴로지 1을 사용합니다.
그림 2 수직 분할 - 탄력적 쿼리를 사용하여 참조 데이터 쿼리
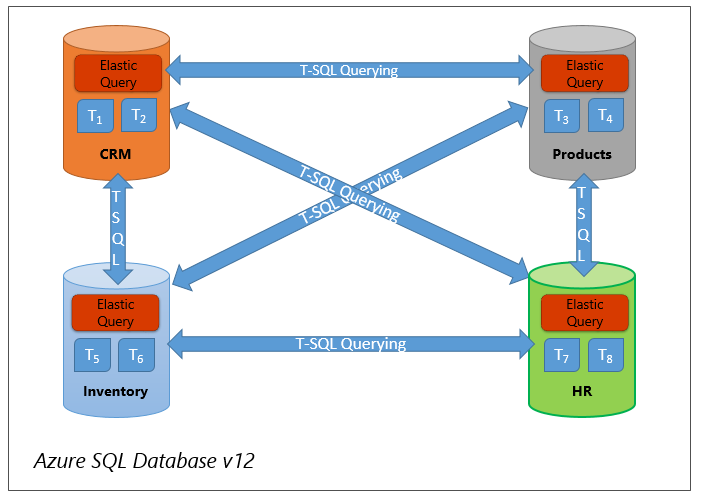
데이터베이스 간 쿼리: 탄력적 쿼리를 사용하면 SQL Database에서 여러 데이터베이스 간 쿼리가 필요한 사용 사례를 구현할 수 있습니다. 그림 3에서는 CRM, 인벤토리, HR 및 제품의 네 가지 데이터베이스를 보여 줍니다. 또한 데이터베이스 중 하나에서 수행되는 쿼리는 하나 또는 모든 다른 데이터베이스에 액세스해야 합니다. 탄력적 쿼리를 사용하여 4개의 데이터베이스 각각에 대해 몇 가지 간단한 DDL 문을 실행하여 이 경우에 데이터베이스를 구성할 수 있습니다. 이 일회성 구성 후에 원격 테이블에 대한 액세스는 T-SQL 쿼리 또는 BI 도구에서 로컬 테이블을 참조하는 것만큼 간단합니다. 원격 쿼리에서 반환되는 결과가 크지 않은 경우에는 이 방법이 권장됩니다.
그림 3 수직 분할 - 탄력적 쿼리를 사용하여 여러 데이터베이스 쿼리
다음 단계에서는 동일한 스키마를 사용하여 SQL Database의 원격 데이터베이스에 있는 테이블에 액세스해야 하는 수직 분할 시나리오에 대한 탄력적 데이터베이스 쿼리를 구성합니다.
- CREATE MASTER KEY mymasterkey
- CREATE DATABASE SCOPED CREDENTIAL mycredential
- CREATE/DROP EXTERNAL DATA SOURCE mydatasource of type RDBMS
- CREATE/DROP EXTERNAL TABLE mytable
DDL 문을 실행한 후 로컬 테이블인 것처럼 원격 테이블 "mytable"에 액세스할 수 있습니다. Azure SQL 데이터베이스는 테이블이 물리적으로 저장된 원격 데이터베이스에 대해 여러 병렬 연결을 자동으로 열고, 원격 데이터베이스에서 요청을 처리하며, 결과를 반환합니다.
행 분할 - 분할
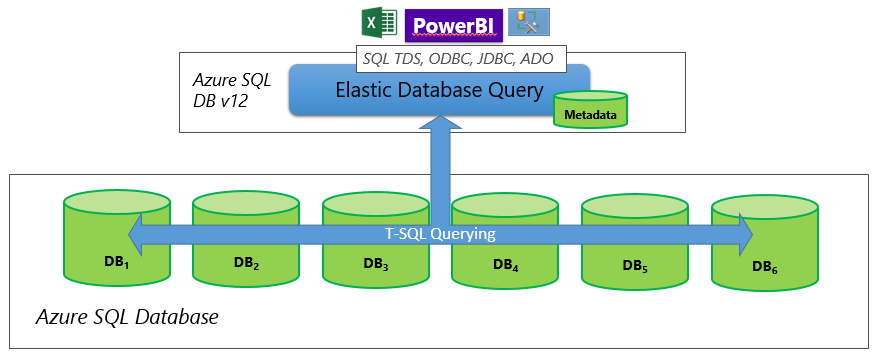
탄력적 쿼리를 사용하여 분할된 데이터베이스를 통해 보고 작업을 수행합니다. 즉, 수평 분할된 데이터 계층에는 데이터 계층의 데이터베이스를 나타내는 탄력적 분할된 데이터베이스 맵이 필요합니다. 일반적으로 이 시나리오에서는 단일 분할된 데이터베이스 맵만 사용되고 탄력적 쿼리 기능(헤드 노드)이 있는 전용 데이터베이스는 쿼리를 보고하기 위한 진입점 역할을 합니다. 이 전용 데이터베이스만 분할된 데이터베이스 맵에 액세스해야 합니다. 그림 4에서는 탄력적 쿼리 데이터베이스 및 분할된 데이터베이스 맵을 사용하여 이 토폴로지 및 해당 구성을 보여 줍니다. 탄력적 데이터베이스 클라이언트 라이브러리 및 분할된 데이터베이스 맵 만들기에 대한 자세한 내용은 분할된 데이터베이스 맵 관리를 참조하세요.
그림 4 행 분할 - 탄력적 쿼리를 사용하여 분할된 데이터 계층에 대해 보고
참고 항목
탄력적 쿼리 데이터베이스(헤드 노드)는 별도 데이터베이스이거나 분할 맵을 호스팅하는 동일한 데이터베이스일 수 있습니다. 어떤 구성을 선택하든 해당 데이터베이스의 서비스 계층 및 컴퓨팅 크기에서 필요한 로그인/쿼리 요청의 양을 처리할 수 있을 만큼 충분한지 확인합니다.
다음 단계에서는 (일반적으로) SQL Database의 여러 원격 데이터베이스에 있는 테이블 집합에 액세스해야 하는 수평 분할 시나리오에 대한 탄력적 데이터베이스 쿼리를 구성합니다.
- CREATE MASTER KEY mymasterkey
- CREATE DATABASE SCOPED CREDENTIAL mycredential
- 탄력적 데이터베이스 클라이언트 라이브러리를 사용하여 분할된 맵을 만듭니다.
- 외부 데이터 소스 생성/삭제 mydatasource 유형 SHARD_MAP_MANAGER
- 외부 테이블 생성/삭제 mytable
이 단계를 수행하고 나면 행 분할 테이블인 "mytable"에 로컬 테이블처럼 액세스할 수 있습니다. Azure SQL Database는 테이블이 물리적으로 저장된 원격 데이터베이스에 대해 여러 병렬 연결을 자동으로 열고, 원격 데이터베이스에서 요청을 처리하며, 결과를 반환합니다. 수평 분할 시나리오에 필요한 단계에 대한 자세한 내용은 수평 분할에 대한 탄력적 쿼리에서 제공합니다.
코딩을 시작하려면 행 분할(분할)을 위한 탄력적 데이터베이스 쿼리 시작하기를 참조하세요.
Important
큰 데이터베이스 세트에 대한 탄력적 쿼리의 실행 성공 여부는 쿼리를 실행하는 동안 각 데이터베이스의 가용성에 크게 좌우됩니다. 데이터베이스 중 하나를 사용할 수 없으면 전체 쿼리가 실패합니다. 수백 또는 수천 개의 데이터베이스를 한 번에 쿼리하려는 경우 클라이언트 애플리케이션에 재시도 논리가 포함되어 있는지 확인하거나 Elastic Database 작업(미리 보기)을 활용하고 더 작은 데이터베이스 하위 집합을 쿼리하여 각 쿼리의 결과를 단일 대상으로 통합하는 것이 좋습니다.
T-SQL 쿼리
외부 데이터 원본과 외부 테이블을 정의한 후에는 일반 SQL Server 연결 문자열을 사용하여 외부 테이블을 정의한 데이터베이스에 연결할 수 있습니다. 이 연결을 통해 외부 테이블에서 T-SQL 문을 실행할 수 있는데, 여기에는 다음과 같은 제한 사항이 있습니다. 수평 분할 및 및 수직 분할에 대한 설명서 항목에서 T-SQL 쿼리의 자세한 내용과 예제를 찾을 수 있습니다.
도구에 대한 연결
일반 SQL Server 연결 문자열을 사용하여 애플리케이션과 BI 또는 데이터 통합 도구를 외부 테이블이 있는 데이터베이스에 연결할 수 있습니다. SQL Server 도구에 대한 데이터 소스로 지원 되는지 확인 합니다. 연결되면, 도구로 연결하는 다른 SQL Server 데이터베이스와 마찬가지로 해당 데이터베이스의 탄력적 쿼리 데이터베이스와 외부 테이블을 참조하세요.
Important
탄력적 쿼리는 SQL Server 인증과 연결할 때만 지원됩니다.
비용
탄력적 쿼리는 Azure SQL 데이터베이스 비용에 포함됩니다. 원격 데이터베이스가 탄력적 쿼리 엔드포인트와 다른 데이터 센터에 있는 토폴로지는 지원되지만 원격 데이터베이스의 데이터 송신에는 정기적으로 Azure 요금이 청구됩니다.
미리 보기 제한 사항
- 더 작은 리소스와 표준 및 범용 서비스 계층에서 첫 번째 탄력적 쿼리를 실행하는 데 최대 몇 분이 걸릴 수 있습니다. 이번에는 탄력적 쿼리 기능을 로드해야 합니다. 로드 성능은 더 높은 서비스 계층 및 컴퓨팅 크기로 향상됩니다.
- SSMS 또는 SSDT에서 외부 데이터 원본 또는 외부 테이블의 스크립팅은 아직 지원되지 않습니다.
- SQL Database용 Import/Export는 외부 데이터 원본 및 외부 테이블을 아직 지원하지 않습니다. 내보내기/가져오기를 사용해야 하는 경우 내보내기 전에 이러한 개체를 삭제한 다음 가져온 후 다시 만듭니다.
- 탄력적 쿼리는 현재 외부 테이블에 대한 읽기 전용 액세스만 지원합니다. 그러나 외부 테이블이 정의된 데이터베이스에서 전체 Transact-SQL 기능을 사용할 수 있습니다. 예를 들어, SELECT <column_list> INTO <local_table>을 사용하여 나온 일시적 결과를 유지하거나 외부 테이블을 참조하는 탄력적 쿼리 데이터베이스의 저장 프로시저를 정의하는 데 이 기능이 유용합니다.
- nvarchar(max)를 제외하고 LOB 형식(공간 형식 포함)은 외부 테이블 정의에서 지원되지 않습니다. 해결 방법으로 LOB 형식을 nvarchar(max)로 캐스팅하고, 기본 테이블 대신 뷰를 통해 외부 테이블을 정의한 다음, 쿼리의 원래 LOB 형식으로 다시 캐스팅하는 원격 데이터베이스에 대한 뷰를 만들 수 있습니다.
- 결과 집합에서 nvarchar(max) 데이터 형식의 열은 탄력적 쿼리 구현에 사용된 고급 일괄 처리 기술을 사용하지 않고, 집계되지 않은 엄청난 양의 데이터가 쿼리 결과로 전송되는 비규범적 사용 사례에서 자릿수, 심지어 두 자릿수에 대한 쿼리 성능에 영향을 줄 수 있습니다.
- 외부 테이블에 대한 열 통계는 현재 지원되지 않습니다. 테이블 통계는 지원되지만 수동으로 만들어야 합니다.
- Azure SQL Database 외부 테이블에는 커서가 지원되지 않습니다.
- 탄력적 쿼리는 Azure SQL 데이터베이스에서만 작동합니다. SQL Server 인스턴스를 쿼리하는 데 사용할 수 없습니다.
- 프라이빗 링크는 현재 외부 데이터 원본의 대상인 데이터베이스에 대한 탄력적 쿼리에서는 지원되지 않습니다.
피드백을 공유해 주세요
아래 MSDN 포럼 또는 Stack Overflow에서 탄력적 쿼리에 대한 경험과 의견을 나눌 수 있습니다. 모든 종류의 서비스에 대한 사용자 의견에 관심이 있습니다.(결함, 조잡함, 기능의 격차)
다음 단계
- 수직 분할 자습서는 데이터베이스 간 쿼리 시작(수직 분할)을 참조하세요.
- 수직 분할된 데이터에 대한 구문 및 예제 쿼리는 수직 분할된 데이터 쿼리하기를 참조하세요.
- 행 분할(분할) 자습서는 행 분할(분할)을 위한 탄력적 데이터베이스 쿼리 시작하기를 참조하세요.
- 행 분할된 데이터에 대한 구문 및 예제 쿼리는 행 분할된 데이터 쿼리하기를 참조하세요.
- 단일 원격 Azure SQL Database 또는 수평 분할 구성표의 분할된 데이터베이스 역할을 하는 데이터베이스 세트에서 Transact-SQL 문을 실행하는 저장 프로시저는 sp_execute _remote를 참조하세요.
피드백
출시 예정: 2024년 내내 콘텐츠에 대한 피드백 메커니즘으로 GitHub 문제를 단계적으로 폐지하고 이를 새로운 피드백 시스템으로 바꿀 예정입니다. 자세한 내용은 다음을 참조하세요. https://aka.ms/ContentUserFeedback
다음에 대한 사용자 의견 제출 및 보기