DTU 기반 모델에서 vCore 기반 모델로 Azure SQL Database 마이그레이션
적용 대상:![]() Azure SQL Database
Azure SQL Database
이 문서에서는 Azure SQL Database의 데이터베이스를 DTU 기반 구매 모델에서 vCore 기반 구매 모델로 마이그레이션하는 방법에 대해 설명합니다.
데이터베이스 마이그레이션
DTU 기반 구매 모델에서 vCore 기반 구매 모델로 데이터베이스를 마이그레이션하는 것은 기본, 표준, 프리미엄 서비스 계층 간의 서비스 목표를 스케일링하는 것과 유사하며, 마이그레이션 프로세스가 끝날 때 비슷한 기간 및 최소 가동 중지 시간이 부여됩니다. vCore 기반 구매 모델로 마이그레이션되는 데이터베이스는 같은 단계를 사용하여 DTU 기반 구매 모델로 다시 마이그레이션할 수 있습니다. 단, Hyperscale 서비스 계층으로 마이그레이션된 데이터베이스는 예외입니다.
Azure Portal, PowerShell, Azure CLI 및 Transact-SQL을 사용하여 데이터베이스를 다른 구매 모델로 마이그레이션할 수 있습니다.
Azure Portal을 사용하여 데이터베이스를 다른 구매 모델로 마이그레이션하려면 다음 단계를 수행합니다.
Azure Portal에서 SQL 데이터베이스로 이동합니다.
설정에서 컴퓨팅 + 저장소를 선택합니다.
서비스 계층 아래의 드롭다운을 사용하여 새 구매 모델과 서비스 계층을 선택합니다.
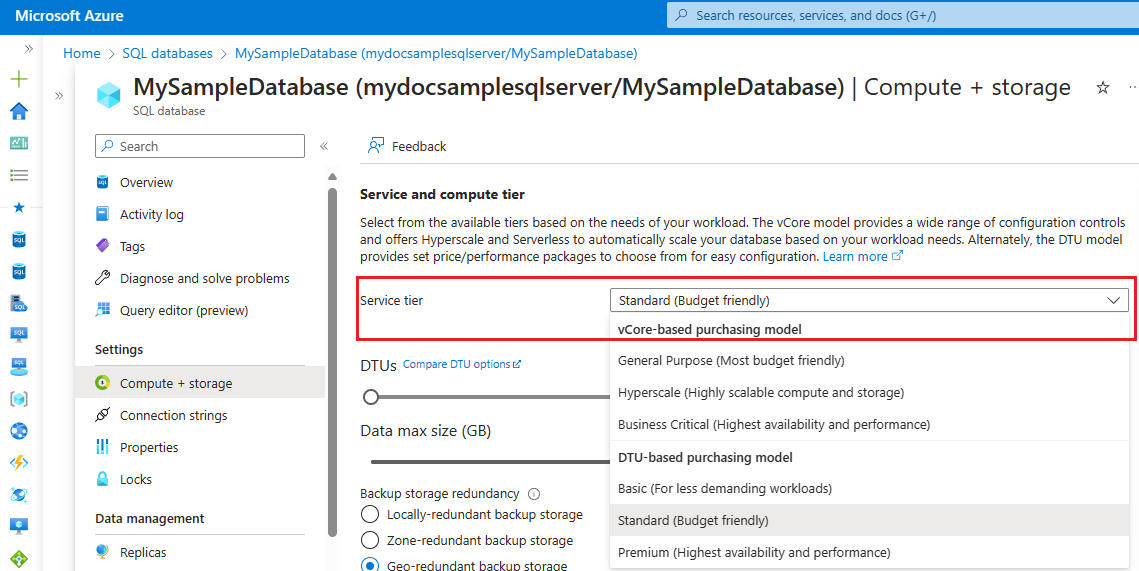

vCore 서비스 계층 및 서비스 목표 선택
대부분의 DTU-vCore 마이그레이션 시나리오에서 기본 및 표준 서비스 계층의 데이터베이스 및 탄력적 풀은 범용 서비스 계층에 매핑됩니다. 프리미엄 서비스 계층의 데이터베이스 및 탄력적 풀은 중요 비즈니스용 서비스 계층에 매핑됩니다. 애플리케이션 시나리오 및 요구 사항에 따라 모든 DTU 서비스 계층의 데이터베이스 및 탄력적 풀에 대한 마이그레이션 대상으로 하이퍼스케일 서비스 계층을 사용할 수 있습니다.
vCore 모델에서 마이그레이션된 데이터베이스에 대한 서비스 목표 또는 컴퓨팅 크기를 선택하기 위해, 간단한 규칙으로 근사값을 계산할 수 있습니다. 해당 규칙은 기본 또는 표준 계층의 모든 100DTU에 대해 하나 이상, 프리미엄 계층의 모든 125DTU에 대해서는 하나 이상의 vCore를 할당하도록 규정합니다.
팁
이 규칙은 DTU 데이터베이스 또는 탄력적 풀에 사용되는 특정 하드웨어 유형을 고려하지 않으므로 대략적인 값입니다.
DTU 모델에서 시스템은 데이터베이스 또는 탄력적 풀에 대해 사용 가능한 모든 하드웨어 구성을 선택할 수 있습니다. 또한 DTU 모델에서 더 높거나 낮은 DTU 또는 eDTU 값을 선택하여 vCore(논리 CPU) 수를 간접적으로 제어할 수 있습니다.
vCore 모델에서 고객은 하드웨어 구성과 vCore(논리 CPU) 수를 모두 명시적으로 선택해야 합니다. DTU 모델에서는 해당 선택 항목을 제공하지 않지만, 모든 데이터베이스 및 탄력적 풀에 사용되는 논리 CPU 수와 하드웨어 유형은 동적 관리 보기를 통해 표시됩니다. 이렇게 하면 일치하는 vCore 서비스 목표를 보다 정확하게 확인할 수 있습니다.
다음에서는 해당 정보를 사용하여 vCore 모델로 마이그레이션한 후 비슷한 수준의 성능을 얻을 수 있도록 비슷한 리소스 할당을 통해 vCore 서비스 목표를 결정합니다.
DTU에서 vCore로 매핑하기
아래의 T-SQL 쿼리는 마이그레이션할 DTU 데이터베이스의 컨텍스트에서 실행할 때 vCore 모델의 각 하드웨어 구성에 일치하는 수의 vCore 수(소수 자릿수일 수 있음)를 반환합니다. 해당 숫자를 vCore 모델의 각 하드웨어 구성에서 데이터베이스 및 탄력적 풀에 사용할 수 있는 가장 가까운 vCore 수로 반올림할 수 있으며, 고객은 DTU 데이터베이스 또는 탄력적 풀에 가장 근접한 vCore 서비스 목표를 선택할 수 있습니다.
해당 방법을 사용하는 샘플 마이그레이션 시나리오는 예제 섹션에서 설명합니다.
master데이터베이스 대신 마이그레이션할 데이터베이스의 컨텍스트에서 해당 쿼리를 실행합니다. 탄력적 풀을 마이그레이션할 때 풀에 있는 모든 데이터베이스의 컨텍스트에서 쿼리를 실행합니다.
WITH dtu_vcore_map AS
(
SELECT rg.slo_name,
CAST(DATABASEPROPERTYEX(DB_NAME(), 'Edition') AS nvarchar(40)) COLLATE DATABASE_DEFAULT AS dtu_service_tier,
CASE WHEN slo.slo_name LIKE '%SQLG4%' THEN 'Gen4' --Gen4 is retired.
WHEN slo.slo_name LIKE '%SQLGZ%' THEN 'Gen4' --Gen4 is retired.
WHEN slo.slo_name LIKE '%SQLG5%' THEN 'standard_series'
WHEN slo.slo_name LIKE '%SQLG6%' THEN 'standard_series'
WHEN slo.slo_name LIKE '%SQLG7%' THEN 'standard_series'
WHEN slo.slo_name LIKE '%GPGEN8%' THEN 'standard_series'
END COLLATE DATABASE_DEFAULT AS dtu_hardware_gen,
s.scheduler_count * CAST(rg.instance_cap_cpu/100. AS decimal(3,2)) AS dtu_logical_cpus,
CAST((jo.process_memory_limit_mb / s.scheduler_count) / 1024. AS decimal(4,2)) AS dtu_memory_per_core_gb
FROM sys.dm_user_db_resource_governance AS rg
CROSS JOIN (SELECT COUNT(1) AS scheduler_count FROM sys.dm_os_schedulers WHERE status COLLATE DATABASE_DEFAULT = 'VISIBLE ONLINE') AS s
CROSS JOIN sys.dm_os_job_object AS jo
CROSS APPLY (
SELECT UPPER(rg.slo_name) COLLATE DATABASE_DEFAULT AS slo_name
) slo
WHERE rg.dtu_limit > 0
AND
DB_NAME() COLLATE DATABASE_DEFAULT <> 'master'
AND
rg.database_id = DB_ID()
)
SELECT dtu_logical_cpus,
dtu_memory_per_core_gb,
dtu_service_tier,
CASE WHEN dtu_service_tier = 'Basic' THEN 'General Purpose'
WHEN dtu_service_tier = 'Standard' THEN 'General Purpose or Hyperscale'
WHEN dtu_service_tier = 'Premium' THEN 'Business Critical or Hyperscale'
END AS vcore_service_tier,
CASE WHEN dtu_hardware_gen = 'Gen4' THEN dtu_logical_cpus * 1.7
WHEN dtu_hardware_gen = 'standard_series' THEN dtu_logical_cpus
END AS standard_series_vcores,
5.05 AS standard_series_memory_per_core_gb,
CASE WHEN dtu_hardware_gen = 'Gen4' THEN dtu_logical_cpus
WHEN dtu_hardware_gen = 'standard_series' THEN dtu_logical_cpus * 0.8
END AS Fsv2_vcores,
1.89 AS Fsv2_memory_per_core_gb,
CASE WHEN dtu_hardware_gen = 'Gen4' THEN dtu_logical_cpus * 1.4
WHEN dtu_hardware_gen = 'standard_series' THEN dtu_logical_cpus * 0.9
END AS M_vcores,
29.4 AS M_memory_per_core_gb
FROM dtu_vcore_map;
추가 요소
vCore(논리 CPU) 수와 하드웨어 유형 외에도 몇 가지 다른 요인이 vCore 서비스 목표의 선택에 영향을 줄 수 있습니다.
- 매핑 Transact-SQL 쿼리는 CPU 용량 측면에서 DTU 및 vCore 서비스 목적과 일치하므로 CPU 바인딩된 작업에 대한 결과는 더욱 정확합니다.
- 동일한 하드웨어 유형과 동일한 수의 vCore에 대해, vCore 데이터베이스의 IOPS 및 트랜잭션 로그 처리량 리소스는 DTU 데이터베이스 보다 더욱 제한됩니다. IO 바인딩 워크로드의 경우 동일한 수준의 성능을 얻기 위해 vCore 모델에서 vCore 수를 줄일 수 있습니다. DTU 및 vCore 데이터베이스에 대한 실제 리소스 제한은 sys.dm_user_db_resource_governance 뷰에 표시됩니다. 마이그레이션할 DTU 데이터베이스 또는 풀과 대략적으로 일치하는 서비스 목표를 사용하는 vCore 데이터베이스 또는 풀의 값을 비교하면 vCore 서비스 목표를 보다 정확하게 선택할 수 있습니다.
- 또한 매핑 쿼리는 마이그레이션할 DTU 데이터베이스 또는 탄력적 풀에 대한 코어 당 메모리 양과 vCore 모델의 각 하드웨어 구성을 반환합니다. 데이터 캐시 또는 쿼리 처리에 큰 메모리가 필요한 작업이나 워크로드가 성능을 충분히 발휘하기 위해서는 vCore로 마이그레이션한 후에도 전체 메모리를 유사하거나 더 높게 유지하는 것이 중요합니다. 해당 워크로드의 경우 실제 성능에 따라 충분한 총 메모리를 얻기 위해 vCore 수를 늘려야 할 수 있습니다.
- vCore 서비스 목표를 선택할 때 DTU 데이터베이스의 과거 리소스 사용률을 고려해야 합니다. 일관되게 CPU 리소스를 적게 활용하는 DTU 데이터베이스는 매핑 쿼리에서 반환된 수보다 적은 vCore가 필요할 수 있습니다. 이와 대조적으로, 일관되게 CPU 리소스를 많이 사용하는 DTU 데이터베이스는 부적절한 워크로드 성능의 원인이 되어 쿼리에서 반환된 수보다 더 많은 vCore가 필요할 수 있습니다.
- 간헐적이거나 예측할 수 없는 사용 패턴의 데이터베이스를 마이그레이션하는 경우 서버리스 컴퓨팅 계층을 사용하는 것이 좋습니다. 최대 서버리스 동시 작업자 수는 구성된 최대 vCore 값과 동일한 수에 대해 75% 한도 내에서 프로비전된 컴퓨팅입니다. 또한 서버리스에서 사용 가능한 최대 메모리는 구성된 최대 vCore 수의 3GB로 프로비저닝된 컴퓨팅의 코어당 메모리보다 낮습니다. 예를 들어, Gen5에서 최대 메모리는 40개의 vCore가 서버리스로 구성된 경우 120GB이고 40개의 vCore 프로비저닝된 컴퓨팅의 경우 204GB입니다.
- vCore 모델에서 지원되는 최대 데이터베이스 크기는 하드웨어에 따라 다를 수 있습니다. 대량 데이터베이스의 경우 단일 데이터베이스 및 탄력적 풀에 대한 vCore 모델에서 지원되는 최대 크기를 확인합니다.
- 탄력적 풀의 경우 DTU 및 vCore 모델은 풀 당 지원되는 최대 데이터베이스 수에 차이가 있습니다. 여러 데이터베이스로 탄력적 풀을 마이그레이션할 때 해당 차이를 고려해야 합니다.
- 일부 하드웨어 구성은 하위 지역에 따라 지원되지 않을 수 있습니다. SQL Database에 대한 하드웨어 구성에서 가용성을 확인하세요.
중요
위의 DTU에서 vCore 크기 조정 지침은 대상 데이터베이스 서비스 목표를 초기 예측하는 데 도움이 됩니다.
대상 데이터베이스에 대한 최적의 구성은 워크로드에 따라 달라집니다. 따라서 마이그레이션 후 최적의 가격/성능 비율을 달성하려면 vCore 모델의 유연성을 활용하여 vCore 수, 하드웨어 구성, 서비스 및 컴퓨팅 계층을 조정해야 할 수 있습니다. 또한 최대 병렬 처리 수준과 같은 데이터베이스 구성 매개 변수를 조정하거나 데이터베이스 엔진의 최근 개선 사항을 사용하도록 데이터베이스 호환성 수준을 변경해야 할 수도 있습니다.
DTU에서 vCore로의 마이그레이션 예제
참고
아래 예제에 표시된 값은 설명 목적으로 제시되었습니다. 시나리오 설명에서 반환되는 실제 값은 다를 수 있습니다.
표준 S9 데이터베이스 마이그레이션
매핑 쿼리는 다음 결과를 반환합니다(편의상 일부 열 생략).
| dtu_logical_cpus | dtu_memory_per_core_gb | standard_series_vcores | standard_series_memory_per_core_gb |
|---|---|---|---|
| 24.00 | 5.40 | 24.000 | 5.05 |
DTU 표준 데이터베이스에는 vCore당 5.4GB의 메모리를 포함하는 24개의 논리 CPU(vCore)가 있습니다. 해당 데이터베이스에 직접적으로 일치하는 것은 표준 시리즈(Gen5) 하드웨어의 범용 2 vCore 데이터베이스인 GP_Gen5_24 vCore 서비스 목표입니다.
표준 S0 데이터베이스 마이그레이션
매핑 쿼리는 다음 결과를 반환합니다(편의상 일부 열 생략).
| dtu_logical_cpus | dtu_memory_per_core_gb | standard_series_vcores | standard_series_memory_per_core_gb |
|---|---|---|---|
| 0.25 | 1.3 | 0.500 | 5.05 |
DTU 데이터베이스에는 vCore당 1.3GB의 메모리를 포함하는 0.25개의 논리 CPU(vCore)가 있습니다. 표준 시리즈(Gen5) 하드웨어 구성인 GP_Gen5_2에서 가장 작은 vCore 서비스 목표는 표준 S0 데이터베이스보다 많은 컴퓨팅 리소스를 제공하므로 직접적으로 일치하는 항목을 찾을 수 없습니다. GP_Gen5_2 옵션이 선호됩니다. 또한 워크로드가 서버리스 컴퓨팅 계층에 적합한 경우 GP_S_Gen5_1가 더욱 적합합니다.
프리미엄 P15 데이터베이스 마이그레이션
매핑 쿼리는 다음 결과를 반환합니다(편의상 일부 열 생략).
| dtu_logical_cpus | dtu_memory_per_core_gb | standard_series_vcores | standard_series_memory_per_core_gb |
|---|---|---|---|
| 42.00 | 4.86 | 42.000 | 5.05 |
DTU 데이터베이스에는 vCore당 4.86GB의 메모리를 포함하는 42개의 논리 CPU(vCore)가 있습니다. 42개 코어를 사용하는 vCore 서비스 목표는 없지만, BC_Gen5_40 서비스 목표는 CPU와 메모리 용량 면에서 거의 동일하며 매우 적합합니다.
기본 200 eDTU 탄력적 풀 마이그레이션
매핑 쿼리는 다음 결과를 반환합니다(편의상 일부 열 생략).
| dtu_logical_cpus | dtu_memory_per_core_gb | standard_series_vcores | standard_series_memory_per_core_gb |
|---|---|---|---|
| 4.00 | 5.40 | 4.000 | 5.05 |
DTU 탄력적 풀에는 vCore당 5.4GB의 메모리를 포함하는 4개의 논리 CPU(vCore)가 있습니다. 표준 시리즈 하드웨어는 4개의 vCore를 요구하지만, 서비스 목표는 풀 당 최대 200개의 데이터베이스를 지원하는 반면, 기본 200 eDTU 탄력적 풀은 최대 500개의 데이터베이스를 지원합니다. 마이그레이션할 탄력적 풀에 200개 이상의 데이터베이스가 있는 경우, 일치하는 vCore 서비스 목표는 GP_Gen5_6이며, 이는 최대 500개의 데이터베이스를 지원합니다.
지역 복제된 데이터베이스 마이그레이션
DTU 기반 모델에서 vCore 기반 모델로 마이그레이션하는 것은 표준 및 프리미엄 데이터베이스 간의 지역 복제 관계를 업그레이드하거나 다운그레이드하는 것과 유사합니다. 마이그레이션 중에 지역 복제를 중지할 필요는 없지만, 다음 시퀀싱 규칙을 따라야 합니다.
- 업그레이드하는 경우 보조 데이터베이스를 먼저 업그레이드한 다음, 주 데이터베이스를 업그레이드해야 합니다.
- 다운그레이드하는 경우 반대 순서로 주 데이터베이스를 먼저 다운그레이드한 다음, 보조 데이터베이스를 다운그레이드해야 합니다.
두 탄력적 풀 간에 지역 복제를 사용하는 경우, 하나의 풀을 주 데이터베이스로 지정하고 다른 풀을 보조 데이터베이스로 지정하는 것이 좋습니다. 해당 경우, 탄력적 풀의 마이그레이션 시 동일한 시퀀싱 참고자료를 사용해야 합니다. 그러나 주 데이터베이스와 보조 데이터베이스를 모두 포함하는 탄력적 풀을 사용하는 경우 사용률이 높은 풀을 주 데이터베이스로 처리하고 해당하는 시퀀싱 규칙을 따릅니다.
다음 테이블에서는 특정 마이그레이션 시나리오에 대한 참고 자료를 제공합니다.
| 현재 서비스 계층 | 대상 서비스 계층 | 마이그레이션 유형 | 사용자 작업 |
|---|---|---|---|
| Standard | 범용 | 수평 | 순서에 관계없이 마이그레이션할 수 있지만, 위의 설명과 같이 적절한 vCore 크기 조정을 보장해야 합니다. |
| Premium | 중요 비즈니스용 | 수평 | 순서에 관계없이 마이그레이션할 수 있지만, 위의 설명과 같이 적절한 vCore 크기 조정을 보장해야 합니다. |
| Standard | 중요 비즈니스용 | 업그레이드 | 먼저 보조 데이터베이스를 마이그레이션해야 합니다. |
| 중요 비즈니스용 | Standard | 다운그레이드 | 먼저 주 데이터베이스를 마이그레이션해야 합니다. |
| Premium | 범용 | 다운그레이드 | 먼저 주 데이터베이스를 마이그레이션해야 합니다. |
| 범용 | Premium | 업그레이드 | 먼저 보조 데이터베이스를 마이그레이션해야 합니다. |
| 중요 비즈니스용 | 범용 | 다운그레이드 | 먼저 주 데이터베이스를 마이그레이션해야 합니다. |
| 범용 | 중요 비즈니스용 | 업그레이드 | 먼저 보조 데이터베이스를 마이그레이션해야 합니다. |
장애 조치(failover) 그룹 마이그레이션
여러 데이터베이스가 있는 장애 조치 그룹을 마이그레이션하려면 주 데이터베이스와 보조 데이터베이스를 개별적으로 마이그레이션해야 합니다. 이 과정에서 동일한 고려 사항과 순서 지정 규칙이 적용됩니다. 데이터베이스가 vCore 기반 모델로 변환된 후에는 장애 조치 그룹이 동일한 정책 설정으로 계속 적용됩니다.
지역 복제 보조 데이터베이스 만들기
주 데이터베이스에 사용한 것과 동일한 서비스 계층을 사용하여 지역 복제 보조 데이터베이스(지역 보조 데이터베이스)를 만들 수 있습니다. 로그 생성 비율이 높은 데이터베이스의 경우 주 데이터베이스와 동일한 컴퓨팅 크기로 지역 보조 데이터베이스를 만드는 것이 좋습니다.
단일 주 데이터베이스에 대한 탄력적 풀에서 지역 보조 데이터베이스를 만드는 경우 maxVCore풀에 대한 설정이 주 데이터베이스의 컴퓨팅 크기와 일치하는지 확인합니다. 다른 탄력적 풀에 있는 주 데이터베이스에 지역 보조 데이터베이스를 만드는 경우, 풀의 maxVCore설정이 동일해야 합니다.
데이터베이스 복사본을 사용하여 DTU에서 vCore로 마이그레이션
데이터베이스 복사는 복사 작업이 시작된 후 특정 시점에 트랜잭션 측면에서 일관된 데이터 스냅샷을 생성합니다. 해당 시점 이후에는 원본과 대상 간에 데이터를 동기화하지 않습니다.
대상 컴퓨팅 크기가 원본 데이터베이스의 최대 데이터베이스 크기를 지원하는 경우 제한 또는 특별한 순서 지정 없이 PowerShell, Azure CLI 또는 Transact-SQL을 사용하여 DTU 기반 컴퓨팅 크기의 데이터베이스를 vCore 기반 컴퓨팅 크기의 데이터베이스에 복사할 수 있습니다. 다른 서비스 계층에 데이터베이스를 복사하는 것은 Azure Portal에서 지원되지 않습니다.
다음 단계
- 단일 데이터베이스에 사용할 수 있는 특정 컴퓨팅 크기 및 스토리지 크기 선택 방법에 대한 자세한 내용은 단일 데이터베이스에 대한 SQL Database vCore 기반 리소스 제한을 참조하세요.
- 탄력적 풀에 사용할 수 있는 특정 컴퓨팅 크기 및 스토리지 크기 옵션에 대한 자세한 내용은 탄력적 풀에 대한 SQL Database vCore 기반 리소스 제한을 참조하세요.
피드백
출시 예정: 2024년 내내 콘텐츠에 대한 피드백 메커니즘으로 GitHub 문제를 단계적으로 폐지하고 이를 새로운 피드백 시스템으로 바꿀 예정입니다. 자세한 내용은 다음을 참조하세요. https://aka.ms/ContentUserFeedback
다음에 대한 사용자 의견 제출 및 보기