Azure SQL Managed Instance를 사용한 비즈니스 연속성 개요
적용 대상:![]() Azure SQL Managed Instance
Azure SQL Managed Instance
이 문서에서는 Azure SQL Managed Instance의 비즈니스 연속성 및 재해 복구 기능에 대한 개요를 제공하며, 데이터가 손실되거나 인스턴스 및 애플리케이션을 사용할 수 없게 되는 중단 이벤트로부터 복구하기 위한 옵션 및 권장 사항을 설명합니다. 사용자 또는 애플리케이션 오류가 데이터 무결성에 영향을 주거나, Azure 가용성 영역 또는 지역에 가동 중단이 발생하거나, 애플리케이션에 유지 관리가 필요할 때 수행할 작업을 알아봅니다.
개요
Azure SQL Managed Instance에서 비즈니스 연속성은 가용성, 고가용성 및 재해 복구를 제공함으로써 중단 시 비즈니스를 계속 운영할 수 있도록 하는 메커니즘, 정책 및 절차를 나타냅니다.
대부분의 경우 SQL Managed Instance는 클라우드 환경에서 발생할 수 있는 중단 이벤트에 대처하고 애플리케이션 및 비즈니스 프로세스를 계속 실행합니다. 그러나 다음과 같이 완화에 다소 시간이 걸릴 수 있는 몇 가지 중단 이벤트가 있습니다.
- 사용자가 실수로 테이블 행을 삭제하거나 업데이트했습니다.
- 악의적인 공격자가 데이터를 삭제하거나 데이터베이스를 삭제하는 데 성공합니다.
- 치명적인 자연 재해 이벤트는 데이터 센터, 가용성 영역 또는 지역에서 가동 중단을 유발합니다.
- 구성 변경, 소프트웨어 버그 또는 하드웨어 구성 요소 장애로 인한 드문 데이터 센터, 가용성 영역 또는 지역 전체 가동 중단.
가용성
Azure SQL Managed Instance는 소프트웨어 또는 하드웨어 오류로부터 보호하는 핵심 복원력 및 안정성을 약속합니다. 데이터베이스 백업은 데이터가 손상되거나 실수로 삭제되지 않도록 데이터를 보호하기 위해 자동화됩니다. PaaS(Platform-as-a-Service)인 Azure SQL Managed Instance 서비스는 업계 최고의 99.99% 가용성 SLA를 지원하며 상용 기능으로 가용성을 제공합니다.
고가용성
Azure 클라우드 환경에서 고가용성을 지원하려면 영역 중복을 사용하도록 설정합니다. 그러면 인스턴스가 가용성 영역을 사용하여 영역 장애에 대한 복원력을 보장합니다. 많은 Azure 지역이 독립적인 전력, 냉각 및 네트워킹 인프라를 보유한 지역 내 분리된 데이터 센터 그룹에 해당하는 가용성 영역을 제공합니다. 가용성 영역은 한 영역에서 가동 중단이 발생하는 경우 나머지 영역에서 지역 서비스, 용량 및 고가용성을 제공하도록 설계되었습니다. 영역 중복을 사용하도록 설정하면 인스턴스가 영역 하드웨어 및 소프트웨어 장애에 복원력을 갖고 애플리케이션에 복구가 투명하게 이루어집니다. 고가용성을 사용하도록 설정하면 Azure SQL Managed Instance 서비스는 99.995%의 고가용성 SLA를 제공할 수 있습니다.
재해 복구
지역 간 가용성 및 중복성을 높이기 위해 재해 복구 기능을 사용하여 치명적인 지역 장애로부터 인스턴스를 신속하게 복구할 수 있습니다. 다음은 Azure SQL Managed Instance에서 재해 복구 옵션입니다.
- 장애 조치(failover) 그룹은 주 인스턴스와 보조 인스턴스 간 연속 동기화를 사용합니다. 장애 조치(failover) 그룹은 변경되지 않고 유지되는 읽기 전용 리스너 엔드포인트 및 읽기-쓰기 수신기 엔드포인트를 제공합니다. 따라서 장애 조치(failover) 후 애플리케이션 연결 문자열 업데이트할 필요가 없습니다.
- 지역 복원을 사용하면 Azure 지역의 기존 인스턴스에 새 데이터베이스를 생성하여 주 지역의 데이터베이스에 액세스할 수 없는 경우 지역 복제된 백업에서 복원함으로써 지역 자동 중단에서 복구할 수 있습니다.
비즈니스 연속성을 지원하는 기능
예를 들어 네 가지 주요 중단 시나리오가 있습니다. 다음 테이블에는 잠재적인 비즈니스 중단 시나리오를 완화하는 데 사용할 수 있는 SQL Managed Instance 비즈니스 연속성이 나와 있습니다.
| 비즈니스 중단 시나리오 | 비즈니스 연속성 기능 |
|---|---|
| 데이터베이스 노드에 영향을 주는 로컬 하드웨어 또는 소프트웨어 오류. | 로컬 하드웨어 및 소프트웨어 장애를 완화하기 위해 SQL Managed Instance는 최대 99.99%의 가용성 SLA로 이러한 장애로부터 자동 복구를 보장하는 가용성 아키텍처를 포함합니다. |
| 데이터 손상 또는 삭제 - 일반적으로 애플리케이션 버그 또는 사람의 실수로 인해 발생합니다. 이러한 오류는 애플리케이션에서 개별적으로 발생하며 일반적으로 서비스에서 검색할 수 없습니다. | 데이터 손실로부터 비즈니스를 보호하기 위해 SQL Managed Instance는 매주 전체 데이터베이스 백업, 12시간 또는 24시간마다 차등 데이터베이스 백업 및 5~10분마다 트랜잭션 로그 백업을 자동으로 생성합니다. 기본값으로 백업은 7일 동안 지역 중복 스토리지에 저장되며, 최대 35일의 특정 시점 복원을 위해 구성 가능한 백업 보존 기간을 지원합니다. 인스턴스가 삭제되지 않은 경우 또는 장기 보존을 구성한 경우 삭제된 시점으로 삭제된 데이터베이스를 복원할 수 있습니다. |
| 자연 재해, 구성 변경, 소프트웨어 버그 또는 하드웨어 구성 요소 장애로 인한 드문 데이터 센터 또는 가용성 영역 가동 중단. | 데이터 센터 또는 가용성 영역 수준 가동 중단을 완화하려면 Azure 가용성 영역을 사용하도록 SQL Managed Instance에서 영역 중복을 사용하도록 설정하고 Azure 지역 내 여러 물리적 영역에 중복성을 제공합니다. 영역 중복을 사용하도록 설정하면 관리형 인스턴스가 최대 99.995%의 고가용성 SLA를 지원하며 영역 장애에 대한 복원력을 보장합니다. |
| 치명적인 자연 재해 이벤트로 인해 발생할 수 있는 모든 가용성 영역 및 이를 구성하는 데이터 센터에 영향을 주는 드문 지역 가동 중단. | 지역 전체 가동 중단을 완화하려면 다음 옵션 중 하나를 사용하여 재해 복구를 사용하도록 설정합니다. - 장애 조치(failover)에 사용되는 보조 지역의 복제본(replica)으로 장애 조치(failover) 그룹의 연속 데이터 동기화. - 백업 스토리지 중복을 지역 중복 백업 스토리지로 설정하여 지역 복원을 사용합니다. |
RTO 및 RPO
비즈니스 연속성 계획을 개발할 때는 중단 이벤트가 발생한 후 애플리케이션이 완전히 복구되기까지 허용되는 최대 시간을 파악합니다. 애플리케이션을 완전히 복구하는 데 필요한 시간을 RTO(복구 시간 목표)라고 합니다. 또한 우발적인 중단 이벤트가 발생한 후 복구될 때 애플리케이션에서 손실을 허용할 수 있는 최근 데이터 업데이트의 최대 기간(시간 간격)도 감안합니다. 잠재적인 데이터 손실을 RPO(복구 지점 목표)라고 합니다.
다음 테이블에서는 각 비즈니스 연속성 옵션의 RPO 및 RTO를 비교합니다.
| 비즈니스 연속성 옵션 | RTO(가동 중지 시간) | RPO(데이터 손실) |
|---|---|---|
| 고가용성 (영역 중복 사용) |
일반적으로 30초 미만입니다. | 0 |
| 재해 복구 (장애 조치(failover) 그룹 사용) |
1시간 | 5초 (중단 이벤트 전에 복제되지 않은 데이터 변경 내용에 따라 다름) |
| 재해 복구 (지역 복원 사용) |
12시간 | 1시간 |
동일한 Azure 지역 내에서 데이터베이스 복구
자동 데이터베이스 백업을 사용하여 과거의 시점으로 데이터베이스를 복원할 수 있습니다. 이러한 방식으로 인력 오류로 인한 데이터 손상으로부터 복구할 수 있습니다. PITR(특정 시점 복원)을 사용하면 손상된 이벤트 이전의 데이터 상태를 나타내는 다른 인스턴스나 동일한 인스턴스로 새 데이터베이스를 생성할 수 있습니다. 복원 작업은 대상 인스턴스의 현재 워크로드에 따라서도 달라지는 데이터 작업의 크기입니다. 매우 크거나 매우 활성화된 상태인 데이터베이스를 복구하는 데는 시간이 더 오래 걸릴 수 있습니다. 복구 시간에 대한 자세한 내용은 데이터베이스 복구 시간을 참조하세요.
지원되는 최대 PITR(특정 시점 복원) 보존 기간이 애플리케이션에 충분하지 않을 경우 데이터베이스에 대한 LTR(장기 보존) 정책을 구성하여 확장할 수 있습니다. 자세한 내용은 장기 백업 보존을 참조하세요.
기존 인스턴스로 데이터베이스 복구
드물긴 하지만 Azure 데이터 센터가 가동 중단될 수도 있습니다. 가동 중단이 발생하면 몇 분 내지 몇 시간 동안 지속될 수 있는 업무 중단이 발생합니다.
- 한 가지 옵션은 데이터 센터 중단이 끝날 때 인스턴스가 온라인 상태가 되기까지 기다리는 것입니다. 이러한 방법은 데이터베이스의 오프라인 유지가 가능한 애플리케이션에 적합합니다. 예를 들어 지속적으로 작업할 필요가 없는 개발 프로젝트 또는 무료 평가판이 있습니다. 데이터 센터가 가동 중단되면 중단이 얼마나 지속될지 알 수 없으므로 이 옵션은 잠시 데이터베이스가 필요 없어도 되는 경우에만 적합합니다.
- GRS(지역 중복) 또는 GZRS(지역 영역 중복) 스토리지를 사용하는 경우 또 다른 옵션은 지역 중복 데이터베이스 백업(지역 복원)을 사용하여 Azure 지역의 모든 SQL Managed Instance로 데이터베이스를 복원하는 것입니다. 지역 복원은 지역 중복 백업을 해당 원본으로 사용하고 가동 중단으로 인해 데이터베이스 또는 데이터 센터에 액세스할 수 없는 경우에도 데이터베이스를 마지막으로 사용 가능한 지점으로 복구하는 데 사용될 수 있습니다. 사용 가능한 백업은 쌍을 이루는 지역에서 찾을 수 있습니다.
- 마지막으로, 고객(권장) 또는 Microsoft 관리 장애 조치(failover)를 사용하여 인스턴스에 대한 장애 조치(failover) 그룹을 사용하여 지역 보조를 구성한 경우 가동 중단에서 신속하게 복구할 수 있습니다. 장애 조치(failover) 자체는 몇 초밖에 걸리지 않지만, 구성된 경우 서비스에서 Microsoft 관리 지역 장애 조치(failover)를 활성화하는 데 1시간 이상 걸립니다. 가동 중단 규모가 장애 조치(failover)를 수행하기에 적합한지를 확인해야 하기 때문입니다. 또한 장애 조치(failover) 시 쌍을 이루는 지역 간 비동기 복제 특성으로 인해 최근에 변경된 데이터가 손실될 수 있습니다.
비즈니스 연속성 계획을 개발할 때는 중단 이벤트가 발생한 후 애플리케이션이 완전히 복구되기까지 허용되는 최대 시간을 이해해야 합니다. 애플리케이션을 완전히 복구하는 데 필요한 시간을 복구 시간 목표(RTO)라고 합니다. 또한 우발적인 중단 이벤트가 발생한 후 복구될 때 응용 프로그램에서 손실을 허용할 수 있는 최근 데이터 업데이트의 최대 기간(시간 간격)도 감안해야 합니다. 잠재적인 데이터 손실을 RPO(복구 지점 목표)라고 합니다.
복구 방법마다 다른 수준의 RPO 및 RTO를 제공합니다. 특정 복구 방법을 선택하거나 방법을 조합하여 전체 응용 프로그램을 복구할 수 있습니다.
애플리케이션이 다음 조건에 맞는 경우 장애 조치(failover) 그룹을 사용합니다.
- 중요 업무용입니다.
- 12시간 이상의 가동 중지 시간을 허용하지 않는 SLA(서비스 수준 약정)가 있습니다.
- 가동 중지 시간으로 인해 재무적 책임이 유발될 수 있습니다.
- 데이터 변경률이 높고 1시간에 해당하는 데이터 손실은 허용할 수 없는 수준입니다.
- 활성 지역 복제를 사용할 때 발생하는 추가적인 비용이 잠재적인 재무적 책임과 연계된 비즈니스 손실보다 낮습니다.
애플리케이션 요구 사항에 따라 데이터베이스 백업 및 장애 조치(failover) 그룹을 조합하여 사용하도록 선택할 수 있습니다.
다음 섹션에서는 데이터베이스 백업 또는 장애 조치(failover) 그룹을 사용하는 복구 단계 개요를 제공합니다.
가동 중단에 대비
어떤 비즈니스 연속성 기능을 사용하든 관계없이 다음 작업을 수행해야 합니다.
- 네트워크 IP 방화벽 규칙, 로그인 및
master데이터베이스 수준 권한을 포함하여 대상 서버를 식별하고 준비합니다. - 클라이언트 및 클라이언트 애플리케이션을 새 인스턴스로 리디렉션하는 방법 결정
- 감사 설정 및 경고와 같은 다른 종속성을 문서화합니다.
적절한 준비 없이 장애 조치나 데이터베이스 복구 이후에 애플리케이션을 온라인 상태로 전환하면 추가 시간이 소요되고, 바쁜 업무 중 문제 해결이 필요할 수도 있어 비효율적입니다.
지역 복제된 보조 데이터베이스로 장애 조치
장애 조치(failover) 그룹을 복구 메커니즘으로 사용하는 경우 자동 장애 조치(failover) 정책을 구성할 수 있습니다. 일단 장애 조치가 시작되면 보조 인스턴스는 새로운 주 인스턴스로 승격되며, 새 트랜잭션을 기록하고 쿼리에 응답할 준비를 갖춥니다. 이때 최소한의 데이터 손실이 있을 수 있으나 아직 복제되지 않습니다.
참고 항목
데이터 센터가 다시 온라인 상태가 되면 이전 주 인스턴스는 새 주 인스턴스에 자동으로 다시 연결되고 보조 인스턴스가 됩니다. 주 데이터베이스를 다시 원래 지역으로 재배치해야 할 경우 계획된 장애 조치를 수동으로 시작할 수 있습니다(장애 복구).
지역 복원 수행
지역 중복 스토리지(인스턴스를 생성할 때 기본 스토리지 옵션)와 함께 자동화된 백업을 사용하는 경우 지역 복원을 사용하여 데이터베이스를 복구할 수 있습니다. 일반적으로 복구는 12시간 이내에 수행됩니다. 이때 마지막 로그 백업의 실행 및 복제를 기준으로 최대 1시간의 데이터 손실이 있을 수 있습니다. 복구가 완료될 때까지 데이터베이스는 어떤 트랜잭션도 기록할 수 없으며 쿼리에 응답할 수 없습니다. 지역 복원은 데이터베이스를 마지막으로 사용할 수 있는 시점으로만 복원합니다.
참고
응용 프로그램이 복구된 데이터베이스로 전환하기 전에 데이터 센터가 다시 온라인 상태가 되면 복구를 취소할 수 있습니다.
사후 장애 조치(failover)/복구 작업 수행
복구 메커니즘에서 복구한 후에는 사용자 및 애플리케이션이 다시 실행되기 전에 다음과 같은 추가 작업을 수행해야 합니다.
- 클라이언트 및 클라이언트 애플리케이션을 새 인스턴스 및 복원된 데이터베이스로 리디렉션합니다.
- 사용자가 연결할 수 있도록 적합한 네트워크 IP 방화벽 규칙이 설정되었는지 확인합니다.
- 적절한 로그인 및
master데이터베이스 수준 권한이 설정되었는지 확인합니다(또는 포함된 사용자를 사용함). - 필요에 따라 감사를 구성합니다.
- 필요에 따라 경고를 구성합니다.
참고 항목
장애 조치(failover) 그룹을 사용 중이며 읽기-쓰기 수신기를 사용하여 인스턴스에 연결하는 경우에는 장애 조치(failover) 후의 리디렉션이 애플리케이션에 투명하게 자동으로 수행됩니다.
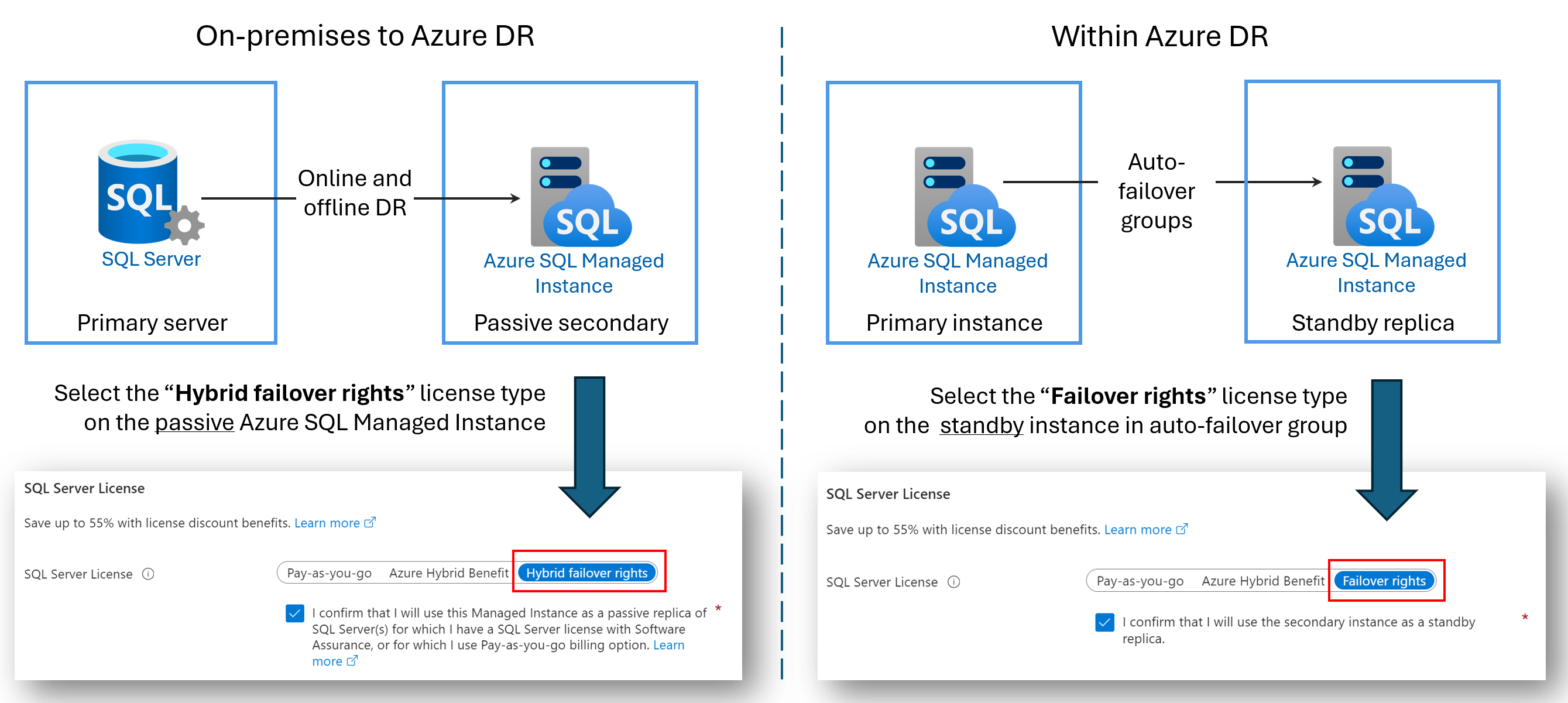
라이선스가 필요 없는 DR 복제본(replica)
DR(재해 복구)에 대해서만 보조 Azure SQL Managed Instance를 구성하여 라이선스 비용을 절감할 수 있습니다. 이 혜택은 두 SQL Managed Instance 간에 장애 조치(failover) 그룹을 사용하거나 SQL Server와 Azure SQL Managed Instance 간에 하이브리드 링크를 구성한 경우에 사용할 수 있습니다. 보조 인스턴스에 읽기 또는 쓰기 워크로드가 없고 수동 DR 대기인 경우 보조 인스턴스에서 사용하는 vCore 라이선스 비용이 청구되지 않습니다.
보조 인스턴스가 재해 복구용으로만 지정되고 인스턴스에서 실행 중인 읽기 또는 쓰기 워크로드가 없는 경우 Microsoft는 장애 조치(failover) 권한 혜택에 따라 추가 요금 없이 주 인스턴스에 라이선스가 부여된 vCore 수를 제공합니다. 보조 인스턴스에서 사용하는 컴퓨팅 및 스토리지에 대한 요금은 계속 청구됩니다. 하이브리드 장애 조치(failover) 권한 혜택의 정확한 계약조건은 "SQL Server – 장애 조치(failover) 권한" 섹션에서 온라인 SQL Server 라이선스 조건을 참조하세요.
혜택의 이름은 시나리오에 따라 달라집니다.
- 수동 복제본(replica)에 대한 하이브리드 장애 조치(failover) 권한: SQL Server와 Azure SQL Managed Instance 간의 링크를 구성할 때 하이브리드 장애 조치(failover) 권한 혜택을 사용하여 수동 보조 복제본에 대한 vCore 라이선스 비용을 절감할 수 있습니다.
- 대기 복제본(replica)에 대한 장애 조치(failover) 권한: 두 관리형 인스턴스 사이에서 장애 조치(failover) 그룹을 구성하는 경우 장애 조치(failover) 권한 혜택을 사용하여 대기 보조 복제본에 대한 vCore 라이선스 비용을 절감할 수 있습니다.
다음 다이어그램은 각 시나리오의 혜택을 보여줍니다.
다음 단계
비즈니스 연속성 기능에 대한 자세한 내용은 자동화된 백업 및 장애 조치(failover) 그룹을 참조하세요. 재해 발생 시 데이터베이스 복구를 참조하세요.
피드백
출시 예정: 2024년 내내 콘텐츠에 대한 피드백 메커니즘으로 GitHub 문제를 단계적으로 폐지하고 이를 새로운 피드백 시스템으로 바꿀 예정입니다. 자세한 내용은 다음을 참조하세요. https://aka.ms/ContentUserFeedback
다음에 대한 사용자 의견 제출 및 보기