자습서: Python API를 사용하여 Azure Batch에서 병렬 워크로드 실행
클라우드에서 Azure Batch를 사용하여 대규모 병렬 및 HPC(고성능 컴퓨팅) 일괄 작업을 Azure에서 효율적으로 실행합니다. 이 자습서는 Batch를 사용하여 병렬 워크로드를 실행하는 Python의 예제를 안내합니다. 일반적인 Batch 애플리케이션 워크플로, 그리고 Batch 및 Storage 리소스와 프로그래밍 방식으로 상호 작용하는 방법을 알아봅니다.
- Batch 및 Storage 계정을 인증합니다.
- 입력 파일을 Storage에 업로드합니다.
- 컴퓨팅 노드 풀을 만들어 애플리케이션을 실행합니다.
- 작업 및 태스크를 만들어 입력 파일을 처리합니다.
- 태스크 실행을 모니터링합니다.
- 출력 파일을 검색합니다.
이 자습서에서는 ffmpeg 오픈 소스 도구를 사용하여 MP4 미디어 파일을 MP3 형식으로 병렬로 변환합니다.
Azure를 구독하고 있지 않다면 시작하기 전에 Azure 체험 계정을 만듭니다.
필수 조건
pip 패키지 관리자
Azure Batch 계정 및 연결된 Azure Storage 계정. 이러한 계정을 만들려면 Azure Portal 또는 Azure CLI에 대한 Batch 빠른 시작 가이드를 참조하세요.
Azure에 로그인
Azure Portal에 로그인합니다.
계정 자격 증명 가져오기
이 예제에서는 배치 계정과 스토리지 계정에 대한 자격 증명을 제공해야 합니다. 필요한 자격 증명을 가져오는 간단한 방법은 Azure Portal에 있습니다. (Azure API 또는 명령줄 도구를 사용하여 이러한 자격 증명을 가져올 수도 있습니다.)
모든 서비스>배치 계정을 차례로 선택한 다음, 배치 계정의 이름을 선택합니다.
Batch 자격 증명을 보려면 키를 선택합니다. 배치 계정, URL 및 기본 액세스 키의 값을 텍스트 편집기에 복사합니다.
스토리지 계정 이름 및 키를 보려면 스토리지 계정을 선택합니다. 스토리지 계정 이름 및 Key1의 값을 텍스트 편집기에 복사합니다.
샘플 앱 다운로드 및 실행
샘플 앱 다운로드
GitHub에서 샘플 앱을 다운로드 또는 복제합니다. Git 클라이언트를 사용하여 샘플 앱 리포지토리를 복제하려면 다음 명령을 사용합니다.
git clone https://github.com/Azure-Samples/batch-python-ffmpeg-tutorial.git
batch_python_tutorial_ffmpeg.py 파일이 포함된 디렉터리로 이동합니다.
Python 환경에서 pip를 사용하는 데 필요한 패키지를 설치합니다.
pip install -r requirements.txt
코드 편집기를 사용하여 config.py 파일을 엽니다. Batch 및 Storage 계정 자격 증명 문자열을 계정에 고유한 값으로 업데이트합니다. 예시:
_BATCH_ACCOUNT_NAME = 'yourbatchaccount'
_BATCH_ACCOUNT_KEY = 'xxxxxxxxxxxxxxxxE+yXrRvJAqT9BlXwwo1CwF+SwAYOxxxxxxxxxxxxxxxx43pXi/gdiATkvbpLRl3x14pcEQ=='
_BATCH_ACCOUNT_URL = 'https://yourbatchaccount.yourbatchregion.batch.azure.com'
_STORAGE_ACCOUNT_NAME = 'mystorageaccount'
_STORAGE_ACCOUNT_KEY = 'xxxxxxxxxxxxxxxxy4/xxxxxxxxxxxxxxxxfwpbIC5aAWA8wDu+AFXZB827Mt9lybZB1nUcQbQiUrkPtilK5BQ=='
앱 실행
스크립트를 실행하려면
python batch_python_tutorial_ffmpeg.py
샘플 애플리케이션을 실행하는 경우 콘솔 출력은 다음과 비슷합니다. 실행 중에 풀의 컴퓨팅 노드가 시작되는 동안 Monitoring all tasks for 'Completed' state, timeout in 00:30:00...에서 일시 중지가 발생합니다.
Sample start: 11/28/2018 3:20:21 PM
Container [input] created.
Container [output] created.
Uploading file LowPriVMs-1.mp4 to container [input]...
Uploading file LowPriVMs-2.mp4 to container [input]...
Uploading file LowPriVMs-3.mp4 to container [input]...
Uploading file LowPriVMs-4.mp4 to container [input]...
Uploading file LowPriVMs-5.mp4 to container [input]...
Creating pool [LinuxFFmpegPool]...
Creating job [LinuxFFmpegJob]...
Adding 5 tasks to job [LinuxFFmpegJob]...
Monitoring all tasks for 'Completed' state, timeout in 00:30:00...
Success! All tasks completed successfully within the specified timeout period.
Deleting container [input]....
Sample end: 11/28/2018 3:29:36 PM
Elapsed time: 00:09:14.3418742
Azure Portal에서 Batch 계정으로 이동하여 풀, 컴퓨팅 노드, 작업 및 태스크를 모니터링합니다. 예를 들어, 풀에 있는 컴퓨팅 노드의 열 지도를 보려면 풀>LinuxFFmpegPool을 선택합니다.
태스크가 실행 중일 때 열 지도는 다음과 유사합니다.
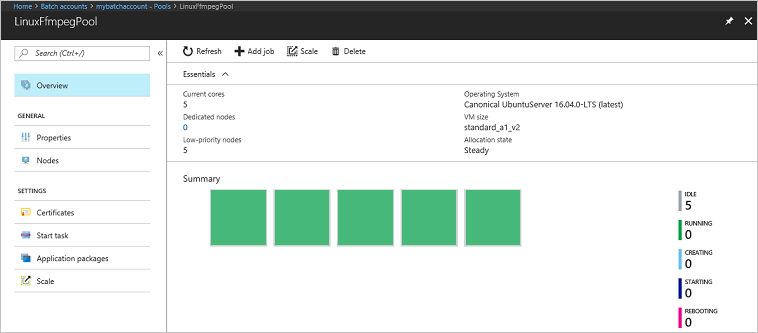
기본 구성에서 애플리케이션을 실행하는 경우 일반적인 실행 시간은 약 5분입니다. 풀을 만드는 데 가장 많은 시간이 걸립니다.
출력 파일 검색
Azure Portal을 사용하여 ffmpeg 작업에서 생성된 출력 MP3 파일을 다운로드할 수 있습니다.
- 모든 서비스>스토리지 계정을 차례로 클릭한 다음, 스토리지 계정의 이름을 클릭합니다.
- Blob>출력을 차례로 클릭합니다.
- 출력 MP3 파일 중 하나를 마우스 오른쪽 단추로 클릭한 다음, 다운로드를 클릭합니다. 브라우저의 지시에 따라 파일을 열거나 저장합니다.
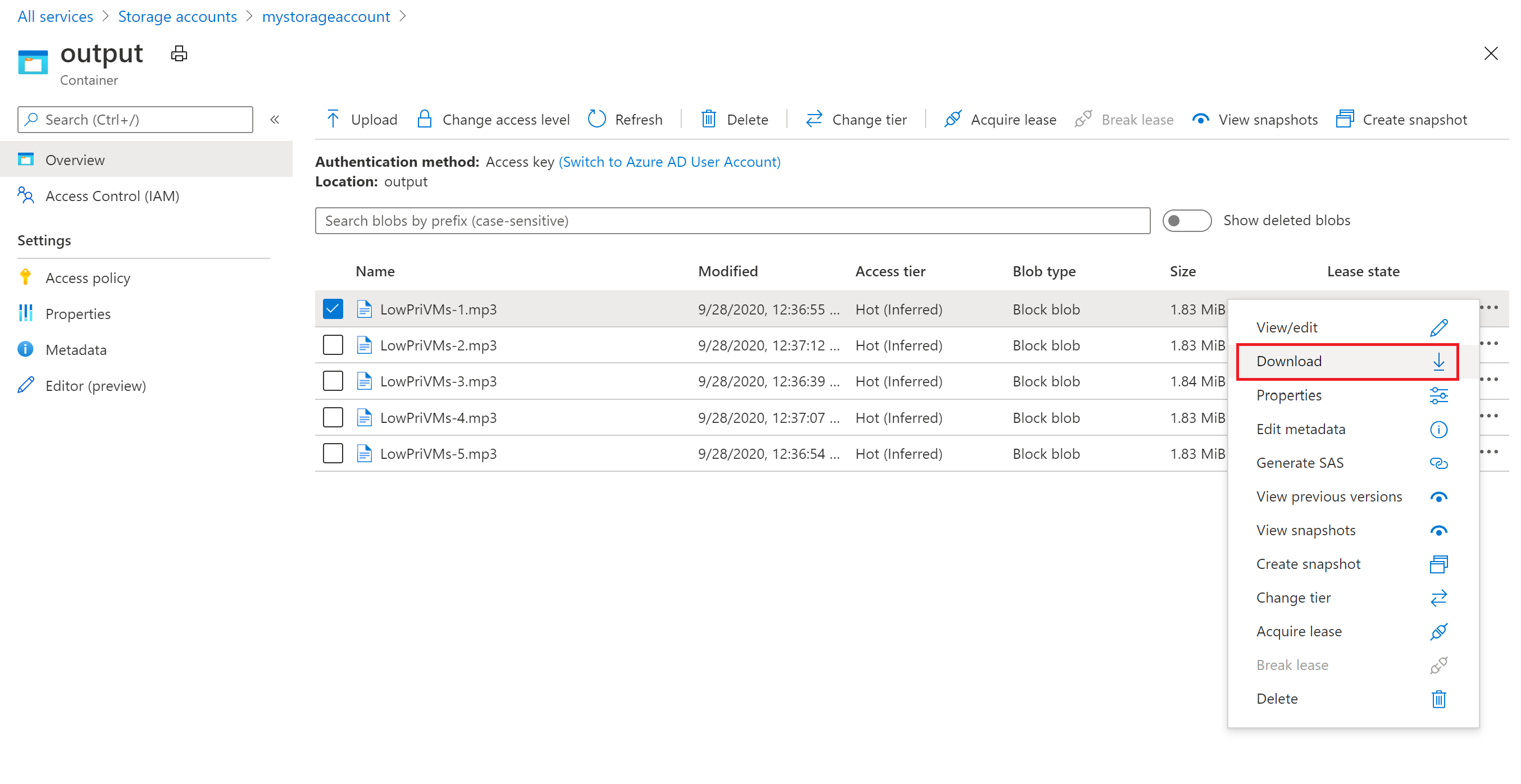
이 샘플에서는 표시되지 않지만, 컴퓨팅 노드 또는 스토리지 컨테이너에서 프로그래밍 방식으로 파일을 다운로드할 수도 있습니다.
코드 검토
다음 섹션에서는 샘플 애플리케이션을 Batch 서비스에서 워크로드를 처리하기 위해 수행하는 단계로 세분화합니다. 샘플에 있는 코드의 모든 줄이 설명되어 있지 않으므로 이 문서의 나머지 부분을 읽을 때 Python 코드를 참조하세요.
Blob 및 Batch 클라이언트 인증
스토리지 계정과 상호 작용하기 위해 앱에서 azure-storage-blob 패키지를 사용하여 BlockBlobService 개체를 만듭니다.
blob_client = azureblob.BlockBlobService(
account_name=_STORAGE_ACCOUNT_NAME,
account_key=_STORAGE_ACCOUNT_KEY)
이 앱은 Batch 서비스에서 풀, 작업 및 태스크를 만들고 관리하는 BatchServiceClient 개체를 만듭니다. 샘플의 Batch 클라이언트는 공유 키 인증을 사용합니다. Batch는 또한 Microsoft Entra ID를 통한 인증을 지원하여 개별 사용자 또는 무인 애플리케이션을 인증합니다.
credentials = batchauth.SharedKeyCredentials(_BATCH_ACCOUNT_NAME,
_BATCH_ACCOUNT_KEY)
batch_client = batch.BatchServiceClient(
credentials,
base_url=_BATCH_ACCOUNT_URL)
입력 파일 업로드
이 앱은 blob_client 참조를 사용하여 입력된 MP4 파일을 위한 스토리지 컨테이너와 태스크 출력을 위한 컨테이너를 만듭니다. 그런 다음 upload_file_to_container 함수를 호출하여 로컬 InputFiles 디렉터리에 있는 MP4 파일을 컨테이너에 업로드합니다. 스토리지의 파일은 Batch가 나중에 컴퓨팅 노드에 다운로드할 수 있는 Batch ResourceFile 개체로 정의됩니다.
blob_client.create_container(input_container_name, fail_on_exist=False)
blob_client.create_container(output_container_name, fail_on_exist=False)
input_file_paths = []
for folder, subs, files in os.walk(os.path.join(sys.path[0], './InputFiles/')):
for filename in files:
if filename.endswith(".mp4"):
input_file_paths.append(os.path.abspath(
os.path.join(folder, filename)))
# Upload the input files. This is the collection of files that are to be processed by the tasks.
input_files = [
upload_file_to_container(blob_client, input_container_name, file_path)
for file_path in input_file_paths]
컴퓨팅 노드 풀 만들기
다음으로, 샘플이 create_pool에 대한 호출을 통해 Batch 계정에 컴퓨팅 노드의 풀을 만듭니다. 이 정의된 함수는 Batch PoolAddParameter 클래스를 사용하여 노드 수, VM 크기 및 풀 구성을 설정합니다. 여기서 VirtualMachineConfiguration 개체는 Azure Marketplace에 게시된 Ubuntu Server 20.04 LTS 이미지에 대한 ImageReference를 지정합니다. Batch는 Azure Marketplace의 광범위한 VM 이미지뿐만 아니라 사용자 지정 VM 이미지도 지원합니다.
노드 수 및 VM 크기는 정의된 상수를 사용하여 설정됩니다. Batch는 전용 노드와 스폿 노드를 지원하며, 풀에서 하나 또는 둘 다 사용할 수 있습니다. 전용 노드는 풀에 예약되어 있습니다. 스폿 노드는 Azure의 잔여 VM 용량에서 할인된 가격으로 제공됩니다. Azure에 용량이 충분하지 않으면 스폿 노드를 사용할 수 없게 됩니다. 이 샘플은 기본적으로 Standard_A1_v2 크기의 스폿 노드 5개만 포함된 풀을 만듭니다.
이 풀 구성에는 실제 노드 속성 외에 StartTask 개체가 포함되어 있습니다. StartTask는 해당 노드가 풀을 연결할 때 각 노드에서 실행하고 이 때마다 노드가 다시 시작됩니다. 이 예에서 StartTask는 Bash 셸 명령을 실행하여 노드에 ffmpeg 패키지와 종속성을 설치합니다.
pool.add 메서드는 풀을 Batch 서비스에 제출합니다.
new_pool = batch.models.PoolAddParameter(
id=pool_id,
virtual_machine_configuration=batchmodels.VirtualMachineConfiguration(
image_reference=batchmodels.ImageReference(
publisher="Canonical",
offer="UbuntuServer",
sku="20.04-LTS",
version="latest"
),
node_agent_sku_id="batch.node.ubuntu 20.04"),
vm_size=_POOL_VM_SIZE,
target_dedicated_nodes=_DEDICATED_POOL_NODE_COUNT,
target_low_priority_nodes=_LOW_PRIORITY_POOL_NODE_COUNT,
start_task=batchmodels.StartTask(
command_line="/bin/bash -c \"apt-get update && apt-get install -y ffmpeg\"",
wait_for_success=True,
user_identity=batchmodels.UserIdentity(
auto_user=batchmodels.AutoUserSpecification(
scope=batchmodels.AutoUserScope.pool,
elevation_level=batchmodels.ElevationLevel.admin)),
)
)
batch_service_client.pool.add(new_pool)
작업 만들기
Batch 작업은 태스크를 실행할 풀과 우선 순위 및 작업 일정과 같은 선택적 설정을 지정합니다. 이 샘플은 create_job를 호출하여 작업을 만듭니다. 이 정의된 함수는 JobAddParameter 클래스를 사용하여 풀에 작업을 만듭니다. job.add 메서드는 풀을 Batch 서비스에 제출합니다. 처음에는 작업에 태스크가 없습니다.
job = batch.models.JobAddParameter(
id=job_id,
pool_info=batch.models.PoolInformation(pool_id=pool_id))
batch_service_client.job.add(job)
작업 만들기
이 앱은 add_tasks를 호출하여 작업에 태스크를 만듭니다. 이 정의된 함수는 TaskAddParameter 클래스를 사용하여 태스크 개체 목록을 만듭니다. 각 태스크는 command_line 매개 변수를 사용하여 입력된 resource_files 개체를 처리하는 ffmpeg를 실행합니다. ffmpeg는 이전에 풀이 생성될 때 각 노드에 설치되었습니다. 여기서 명령줄은 fmpeg를 실행하여 입력된 각 MP4(비디오) 파일을 MP3(오디오) 파일로 변환합니다.
이 샘플에서는 명령줄을 실행한 후 MP3 파일에 대한 OutputFile 개체를 만듭니다. 각 태스크의 출력 파일(이 경우에는 하나)은 태스크의 output_files 속성을 사용하여 연결된 스토리지 계정의 컨테이너에 업로드됩니다.
그런 다음, 이 앱은 task.add_collection 메서드를 사용하여 작업에 태스크를 추가하고, 컴퓨팅 노드 실행 대기열에 추가합니다.
tasks = list()
for idx, input_file in enumerate(input_files):
input_file_path = input_file.file_path
output_file_path = "".join((input_file_path).split('.')[:-1]) + '.mp3'
command = "/bin/bash -c \"ffmpeg -i {} {} \"".format(
input_file_path, output_file_path)
tasks.append(batch.models.TaskAddParameter(
id='Task{}'.format(idx),
command_line=command,
resource_files=[input_file],
output_files=[batchmodels.OutputFile(
file_pattern=output_file_path,
destination=batchmodels.OutputFileDestination(
container=batchmodels.OutputFileBlobContainerDestination(
container_url=output_container_sas_url)),
upload_options=batchmodels.OutputFileUploadOptions(
upload_condition=batchmodels.OutputFileUploadCondition.task_success))]
)
)
batch_service_client.task.add_collection(job_id, tasks)
태스크 모니터링
태스크가 작업에 추가되면 Batch에서 서비스가 연결된 풀의 컴퓨팅 노드 실행 대기열에 자동으로 추가하고 예약합니다. 지정한 설정에 따라 Batch는 대기, 예약, 다시 시도하는 모든 작업 및 기타 담당 작업 관리 업무를 처리합니다.
태스크 실행을 모니터링하는 방법은 여러 가지가 있습니다. 이 예에서 wait_for_tasks_to_complete 함수는 TaskState 개체를 사용하여 제한된 시간 동안 태스크의 특정 상태(이 경우에는 완료된 상태)를 모니터링합니다.
while datetime.datetime.now() < timeout_expiration:
print('.', end='')
sys.stdout.flush()
tasks = batch_service_client.task.list(job_id)
incomplete_tasks = [task for task in tasks if
task.state != batchmodels.TaskState.completed]
if not incomplete_tasks:
print()
return True
else:
time.sleep(1)
...
리소스 정리
앱은 태스크를 실행한 후 생성된 입력 스토리지 컨테이너를 자동으로 삭제하고 사용자에게 Batch 풀 및 작업을 삭제하는 옵션을 제공합니다. BatchClient의 JobOperations 및 PoolOperations 클래스에는 삭제 메서드가 있고 이는 삭제를 확인하는 경우 호출됩니다. 작업 및 태스크 자체에 대한 요금이 부과되지 않지만 컴퓨팅 노드에 대한 요금이 청구됩니다. 따라서 풀을 필요할 때만 할당하는 것이 좋습니다. 풀을 삭제하면 노드의 모든 태스크 출력이 삭제됩니다. 그러나 입력 및 출력 파일은 스토리지 계정에 남아 있습니다.
더 이상 필요하지 않으면 리소스 그룹, 배치 계정 및 스토리지 계정을 삭제합니다. Azure Portal에서 이렇게 하려면 배치 계정에 대한 리소스 그룹을 선택하고 리소스 그룹 삭제를 선택합니다.
다음 단계
이 자습서에서는 다음 작업 방법을 알아보았습니다.
- Batch 및 Storage 계정을 인증합니다.
- 입력 파일을 Storage에 업로드합니다.
- 컴퓨팅 노드 풀을 만들어 애플리케이션을 실행합니다.
- 작업 및 태스크를 만들어 입력 파일을 처리합니다.
- 태스크 실행을 모니터링합니다.
- 출력 파일을 검색합니다.
Python API를 사용하여 Batch 워크로드를 예약하고 처리하는 방법에 대한 추가 예는 GitHub의 Batch Python 샘플을 참조하세요.