엔터프라이즈 보안을 위한 Azure Machine Learning 모범 사례
이 문서에서는 보안 Azure Machine Learning 배포를 계획하거나 관리하기 위한 보안 모범 사례를 설명합니다. 모범 사례는 Azure Machine Learning을 통한 고객 경험 및 Microsoft에서 제공됩니다. 각 지침은 사례와 그 근거를 설명합니다. 이 문서에는 방법 및 참조 설명서에 대한 링크도 제공됩니다.
권장되는 네트워크 보안 아키텍처(관리되는 네트워크)
권장되는 기계 학습 네트워크 보안 아키텍처는 관리형 가상 네트워크입니다. Azure Machine Learning 관리형 가상 네트워크는 작업 영역, 연결된 Azure 리소스 및 모든 관리형 컴퓨팅 리소스를 보호합니다. 필요한 출력을 미리 구성하고 네트워크 내에서 관리되는 리소스를 자동으로 만들어 네트워크 보안의 구성 및 관리를 간소화합니다. 프라이빗 엔드포인트를 사용하여 Azure 서비스가 네트워크에 액세스할 수 있도록 허용하고 필요에 따라 아웃바운드 규칙을 정의하여 네트워크가 인터넷에 액세스할 수 있도록 할 수 있습니다.
관리되는 가상 네트워크에는 다음을 위해 구성할 수 있는 두 가지 모드가 있습니다.
인터넷 아웃바운드 허용 - 이 모드는 공용 PyPi 또는 Anaconda 패키지 리포지토리와 같은 인터넷에 있는 리소스와의 아웃바운드 통신을 허용합니다.

승인된 아웃바운드 만 허용 - 이 모드에서는 작업 영역이 작동하는 데 필요한 최소 아웃바운드 통신만 허용합니다. 이 모드는 인터넷에서 격리해야 하는 작업 영역에 권장됩니다. 또는 서비스 엔드포인트, 서비스 태그 또는 정규화된 do기본 이름을 통해서만 특정 리소스에 대한 아웃바운드 액세스가 허용되는 경우

자세한 내용은 관리형 가상 네트워크 격리를 참조하세요.
권장되는 네트워크 보안 아키텍처(Azure Virtual Network)
비즈니스 요구 사항으로 인해 관리형 가상 네트워크를 사용할 수 없는 경우 다음 서브넷에서 Azure 가상 네트워크를 사용할 수 있습니다.
- 학습 - 학습에 사용되는 컴퓨팅 리소스(예: 기계 학습 컴퓨팅 인스턴스 또는 컴퓨팅 클러스터)가 포함됩니다.
- 채점- AKS(Azure Kubernetes Service)와 같이 채점에 사용되는 컴퓨팅 리소스가 포함됩니다.
- 방화벽 - 공용 인터넷과 주고받는 트래픽을 허용하는 방화벽(예: Azure Firewall)이 포함됩니다.
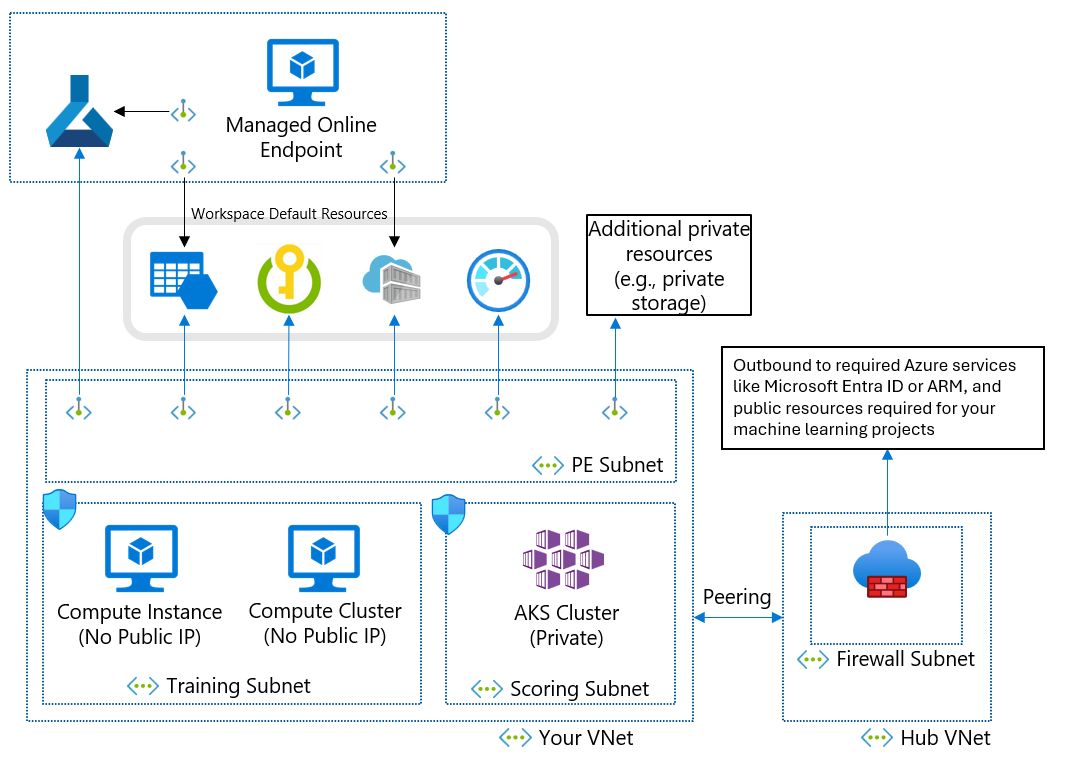
가상 네트워크에는 기계 학습 작업 영역 및 다음 종속 서비스에 대한 프라이빗 엔드포인트도 포함되어 있습니다.
- Azure Storage 계정
- Azure Key Vault
- Azure Container Registry
가상 네트워크의 아웃바운드 통신은 다음과 같은 Microsoft 서비스에 연결할 수 있어야 합니다.
- 기계 학습
- Microsoft Entra ID
- Azure Container Registry 및 Microsoft에서 유지 관리하는 특정 레지스트리
- Azure Front Door
- Azure Resource Manager
- Azure Storage
원격 클라이언트는 Azure ExpressRoute 또는 VPN(가상 사설망) 연결을 사용하여 가상 네트워크에 연결합니다.
가상 네트워크 및 프라이빗 엔드포인트 디자인
Azure Virtual Network, 서브넷 및 프라이빗 엔드포인트를 디자인할 때 다음 요구 사항을 고려합니다.
일반적으로 학습 및 채점을 위한 별도의 서브넷을 만들고 모든 프라이빗 엔드포인트에 대해 학습 서브넷을 사용합니다.
IP 주소 지정의 경우 컴퓨팅 인스턴스에는 각각 하나의 개인 IP가 필요합니다. 컴퓨팅 클러스터에는 노드당 하나의 개인 IP가 필요합니다. AKS 클러스터에는 AKS 클러스터에 대한 IP 주소 지정 계획에 설명된 대로 개인 IP 주소가 많이 필요합니다. 최소한 AKS에 대한 별도의 서브넷은 IP 주소 고갈을 방지하는 데 도움이 됩니다.
학습 및 채점 서브넷의 컴퓨팅 리소스는 스토리지 계정, 키 자격 증명 모음 및 컨테이너 레지스트리에 액세스해야 합니다. 스토리지 계정, 키 자격 증명 모음, 컨테이너 레지스트리에 대한 프라이빗 엔드포인트를 만듭니다.
기계 학습 작업 영역 기본 스토리지에는 두 개의 프라이빗 엔드포인트가 필요합니다. 하나는 Azure Blob Storage용이고 다른 하나는 Azure File Storage용입니다.
Azure Machine Learning 스튜디오 사용하는 경우 작업 영역 및 스토리지 프라이빗 엔드포인트는 동일한 가상 네트워크에 있어야 합니다.
여러 작업 영역이 있는 경우 각 작업 영역에 대해 가상 네트워크를 사용하여 작업 영역 간에 명시적 네트워크 경계를 만듭니다.
개인 IP 주소 사용
개인 IP 주소는 Azure 리소스가 인터넷에 노출되는 것을 최소화합니다. 기계 학습은 많은 Azure 리소스를 사용하며, 기계 학습 작업 영역 프라이빗 엔드포인트는 엔드투엔드 개인 IP에 충분하지 않습니다. 다음 표에서는 기계 학습에서 사용하는 주요 리소스와 리소스에 대한 개인 IP를 사용하도록 설정하는 방법을 보여 줍니다. 컴퓨팅 인스턴스 및 컴퓨팅 클러스터는 개인 IP 기능이 없는 유일한 리소스입니다.
| 리소스 | 개인 IP 솔루션 | 설명서 |
|---|---|---|
| 작업 영역 | 프라이빗 엔드포인트 | Azure Machine Learning 작업 영역용 프라이빗 엔드포인트 구성 |
| 등록 | 프라이빗 엔드포인트 | Azure Machine Learning 레지스트리를 사용하여 네트워크 격리 |
| 연결된 리소스 | ||
| 스토리지 | 프라이빗 엔드포인트 | 서비스 엔드포인트로 Azure Storage 계정 보호 |
| Key Vault | 프라이빗 엔드포인트 | Azure Key Vault 보안 |
| Container Registry | 프라이빗 엔드포인트 | Azure Container Registry 사용 |
| 학습 리소스 | ||
| 컴퓨팅 인스턴스 | 개인 IP(공용 IP 없음) | 학습 환경 보호 |
| 컴퓨팅 클러스터 | 개인 IP(공용 IP 없음) | 학습 환경 보호 |
| 호스팅 리소스 | ||
| 관리되는 온라인 엔드포인트 | 프라이빗 엔드포인트 | 관리되는 온라인 엔드포인트를 사용하여 네트워크 격리 |
| 온라인 엔드포인트(Kubernetes) | 프라이빗 엔드포인트 | Azure Kubernetes Service 온라인 엔드포인트 보호 |
| 배치 엔드포인트 | 개인 IP(컴퓨팅 클러스터에서 상속됨) | 일괄 처리 엔드포인트에서 네트워크 격리 |
가상 네트워크 인바운드 및 아웃바운드 트래픽 제어
방화벽 또는 Azure NSG(네트워크 보안 그룹)를 사용하여 가상 네트워크 인바운드 및 아웃바운드 트래픽을 제어합니다. 인바운드 및 아웃바운드 요구 사항에 대한 자세한 내용은 인바운드 및 아웃바운드 네트워크 트래픽 구성을 참조하세요. 구성 요소 간의 트래픽 흐름에 대한 자세한 내용은 보안 작업 영역의 네트워크 트래픽 흐름을 참조 하세요.
작업 영역에 대한 액세스 확인
프라이빗 엔드포인트가 기계 학습 작업 영역에 액세스할 수 있도록 하려면 다음 단계를 수행합니다.
Azure Bastion 액세스 권한이 있는 VPN 연결, ExpressRoute 또는 점프 박스 VM(가상 머신)을 사용하여 가상 네트워크에 액세스할 수 있는지 확인합니다. 공용 사용자는 프라이빗 엔드포인트를 사용하여 기계 학습 작업 영역에 액세스할 수 없습니다. 프라이빗 엔드포인트는 가상 네트워크에서만 액세스할 수 있기 때문입니다. 자세한 내용은 가상 네트워크로 작업 영역 보호를 참조하세요.
개인 IP 주소로 작업 영역 FQDN(정규화된 도메인 이름)을 확인할 수 있는지 확인합니다. 자체 DNS(Domain Name System) 서버 또는 중앙 집중식 DNS 인프라를 사용하는 경우 DNS 전달자를 구성해야 합니다. 자세한 내용은 사용자 지정 DNS 서버로 작업 영역을 사용하는 방법을 참조하세요.
작업 영역 액세스 관리
기계 학습 ID 및 액세스 관리 컨트롤을 정의할 때 데이터 자산에 대한 액세스를 관리하는 컨트롤과 Azure 리소스에 대한 액세스를 정의하는 컨트롤을 분리할 수 있습니다. 사용 사례에 따라 셀프 서비스, 데이터 중심, 프로젝트 중심 ID 및 액세스 관리 중에 무엇을 사용할지 고려합니다.
셀프 서비스 패턴
셀프 서비스 패턴에서 데이터 과학자는 작업 영역을 만들고 관리할 수 있습니다. 이 패턴은 다양한 구성을 유연하게 시도해야 하는 개념 증명 상황에 가장 적합합니다. 단점은 데이터 과학자가 Azure 리소스를 프로비전하기 위한 전문 지식이 필요하다는 것입니다. 엄격한 제어, 리소스 사용, 감사 추적 및 데이터 액세스가 필요한 경우 이 방법은 적합하지 않습니다.
리소스 프로비전 및 사용(예: 허용되는 클러스터 크기 및 VM 유형)에 대한 세이프가드를 설정하는 Azure 정책을 정의합니다.
작업 영역을 보유하기 위한 리소스 그룹을 만들고 데이터 과학자에게 리소스 그룹에서 기여자 역할을 부여합니다.
이제 데이터 과학자가 셀프 서비스 방식으로 작업 영역을 만들고 리소스 그룹의 리소스를 연결할 수 있습니다.
데이터 스토리지에 액세스하려면 사용자 할당 관리 ID를 만들고 스토리지에서 ID 읽기 액세스 역할을 부여합니다.
데이터 과학자가 컴퓨팅 리소스를 만들 때 컴퓨팅 인스턴스에 관리 ID를 할당하여 데이터 액세스 권한을 얻을 수 있습니다.
모범 사례는 클라우드 채택 분석을 위한 인증을 참조하세요.
데이터 중심 패턴
데이터 중심 패턴에서 작업 영역은 여러 프로젝트에서 작업할 수 있는 단일 데이터 과학자에 속합니다. 이 방식의 장점은 데이터 과학자가 코드 또는 학습 파이프라인을 여러 프로젝트에서 다시 사용할 수 있다는 것입니다. 작업 영역이 단일 사용자로 제한되는 한 스토리지 로그를 감사할 때 데이터 액세스를 해당 사용자로 역추적할 수 있습니다.
단점은 데이터 액세스가 프로젝트별로 구획화되거나 제한되지 않으며 작업 영역에 추가된 모든 사용자가 동일한 자산에 액세스할 수 있다는 것입니다.
작업 영역을 만듭니다.
시스템 할당 관리 ID를 사용하도록 설정된 컴퓨팅 리소스를 만듭니다.
데이터 과학자가 지정된 프로젝트의 데이터에 액세스해야 하는 경우 컴퓨팅 관리 ID에 데이터에 대한 읽기 권한을 부여합니다.
학습을 위해 사용자 지정 Docker 이미지가 있는 컨테이너 레지스트리와 같은 다른 필수 리소스에 대한 컴퓨팅 관리 ID 액세스 권한을 부여합니다.
또한 데이터 미리 보기를 사용하도록 데이터에 대한 작업 영역의 관리 ID 읽기 액세스 역할을 부여합니다.
데이터 과학자에게 작업 영역에 대한 액세스 권한을 부여합니다.
이제 데이터 과학자는 프로젝트에 필요한 데이터에 액세스하고 데이터를 사용하는 학습 실행을 제출하는 데이터 저장소를 만들 수 있습니다.
필요에 따라 Microsoft Entra 보안 그룹을 만들고 데이터에 대한 읽기 액세스 권한을 부여한 다음, 보안 그룹에 관리 ID를 추가합니다. 이 방식을 사용하면 리소스에 대한 직접 역할 할당 수가 줄어서 역할 할당에 대한 구독 제한에 도달하는 것을 피할 수 있습니다.
프로젝트 중심 패턴
프로젝트 중심 패턴은 특정 프로젝트에 대한 기계 학습 작업 영역을 만들고, 많은 데이터 과학자가 동일한 작업 영역 내에서 협업합니다. 데이터 액세스가 특정 프로젝트로 제한되므로 중요한 데이터 작업에 적합한 방식입니다. 또한 프로젝트에서 데이터 과학자를 추가하거나 제거하는 것도 간단합니다.
이 방식의 단점은 프로젝트 간에 자산을 공유하기 어려울 수 있다는 것입니다. 또한 감사하는 동안 특정 사용자에 대한 데이터 액세스를 추적하기가 어렵습니다.
작업 영역 만들기
프로젝트에 필요한 데이터 스토리지 인스턴스를 식별하고, 사용자 할당 관리 ID를 만들고, 이 ID에 스토리지에 대한 읽기 권한을 부여합니다.
필요에 따라 데이터 미리 보기를 허용하도록 작업 영역의 관리 ID에 데이터 스토리지에 대한 액세스 권한을 부여합니다. 미리 보기에 적합하지 않은 중요한 데이터에 대해서는 이 액세스를 생략할 수 있습니다.
스토리지 리소스에 대한 자격 증명 없는 데이터 저장소를 만듭니다.
작업 영역 내에서 컴퓨팅 리소스를 만들고 컴퓨팅 리소스에 관리 ID를 할당합니다.
학습을 위해 사용자 지정 Docker 이미지가 있는 컨테이너 레지스트리와 같은 다른 필수 리소스에 대한 컴퓨팅 관리 ID 액세스 권한을 부여합니다.
프로젝트에서 작업하는 데이터 과학자에게 작업 영역에서 역할을 부여합니다.
Azure RBAC(역할 기반 액세스 제어)를 사용하면 데이터 과학자가 다른 관리 ID를 사용하여 새 데이터 저장소 또는 새 컴퓨팅 리소스를 만들지 못하도록 제한할 수 있습니다. 이렇게 하면 프로젝트와 관련이 없는 데이터에 액세스할 수 없습니다.
필요에 따라 프로젝트 멤버 자격 관리를 간소화하기 위해 프로젝트 멤버에 대한 Microsoft Entra 보안 그룹을 만들고 그룹에게 작업 영역에 대한 액세스 권한을 부여할 수 있습니다.
자격 증명 통과를 사용하는 Azure Data Lake Storage
Machine Learning Studio에서 대화형 스토리지 액세스에 Microsoft Entra 사용자 ID를 사용할 수 있습니다. 계층 구조 네임스페이스를 사용하도록 설정된 Data Lake Storage를 사용하면 스토리지 및 협업을 위해 데이터 자산의 구성을 향상시킬 수 있습니다. Data Lake Storage 계층 구조 네임스페이스를 사용하면 다른 사용자에게 다른 폴더 및 파일에 대한 ACL(액세스 제어 목록) 기반 액세스를 제공하여 데이터 액세스를 구분할 수 있습니다. 예를 들어 일부 사용자에게만 기밀 데이터에 대한 액세스 권한을 부여할 수 있습니다.
RBAC 및 사용자 지정 역할
Azure RBAC를 사용하면 기계 학습 리소스에 액세스할 수 있는 사용자를 관리하고 작업을 수행할 수 있는 사용자를 구성할 수 있습니다. 예를 들어 컴퓨팅 리소스를 관리할 수 있는 작업 영역 관리자 역할을 특정 사용자에게만 부여할 수 있습니다.
액세스 범위는 환경마다 다를 수 있습니다. 프로덕션 환경에서 추론 엔드포인트를 업데이트할 수 있는 사용자의 자격을 제한할 수 있습니다. 대신 이 권한을 승인된 서비스 주체에게 부여할 수 있습니다.
기계 학습에는 소유자, 기여자, 읽기 권한자, 데이터 과학자 등 몇 가지 기본 역할이 있습니다. 예를 들어, 조직 구조를 반영하는 권한을 만드는 자체적인 사용자 지정 역할을 만들 수도 있습니다. 자세한 내용은 Azure Machine Learning 작업 영역 액세스 관리를 참조하세요.
시간이 지나면서 팀의 구성이 변화할 수 있습니다. 각 팀 역할 및 작업 영역에 대한 Microsoft Entra 그룹을 만드는 경우 Microsoft Entra 그룹에 Azure RBAC 역할을 할당하고 리소스 액세스 및 사용자 그룹을 별도로 관리할 수 있습니다.
사용자 주체 및 서비스 주체는 동일한 Microsoft Entra 그룹에 속할 수 있습니다. 예를 들어 Azure Data Factory가 기계 학습 파이프라인을 트리거하는 데 사용하는 사용자 할당 관리 ID를 만들 때 ML 파이프라인 실행기 Microsoft Entra 그룹에 관리 ID를 포함할 수 있습니다.
중앙 Docker 이미지 관리
Azure Machine Learning은 학습 및 배포에 사용할 수 있는 큐레이팅된 Docker 이미지를 제공합니다. 그러나 엔터프라이즈 규정 준수 요구 사항에 따라 회사에서 관리하는 프라이빗 리포지토리의 이미지를 사용해야 할 수 있습니다. 기계 학습에 중앙 리포지토리를 사용하는 방법은 두 가지입니다.
중앙 리포지토리의 이미지를 기본 이미지로 사용합니다. 기계 학습 환경 관리는 패키지를 설치하고 학습 또는 추론 코드가 실행되는 Python 환경을 만듭니다. 이 방법을 사용하면 기본 이미지를 수정하지 않고도 패키지 종속성을 쉽게 업데이트할 수 있습니다.
기계 학습 환경 관리를 사용하지 않고 이미지를 있는 그대로 사용합니다. 이 방법은 더 높은 수준의 제어를 제공하지만 이미지의 일부로 Python 환경을 신중하게 구성해야 합니다. 코드를 실행하는 데 필요한 모든 종속성을 충족해야 하며, 새 종속성을 사용하려면 이미지를 다시 빌드해야 합니다.
자세한 내용은 환경 관리를 참조 하세요.
데이터 암호화
기계 학습 미사용 데이터에는 다음 두 가지 데이터 원본이 있습니다.
스토리지에는 메타데이터를 제외한 학습 및 학습된 모델 데이터를 포함한 모든 데이터가 있습니다. 스토리지 암호화는 사용자의 책임입니다.
Azure Cosmos DB에는 실험 이름, 실험 제출 날짜 및 시간과 같은 실행 기록 정보를 비롯한 메타데이터가 포함됩니다. 대부분의 작업 영역에서 Azure Cosmos DB는 Microsoft 구독에 있으며 Microsoft 관리형 키로 암호화됩니다.
사용자 고유의 키를 사용하여 메타데이터를 암호화하려는 경우 고객 관리형 키 작업 영역을 사용할 수 있습니다. 단점은 구독에 Azure Cosmos DB가 있어야 하고 그 비용을 지불해야 한다는 것입니다. 자세한 내용은 Azure Machine Learning과 데이터 통합을 참조하세요.
Azure Machine Learning이 전송 중 데이터를 암호화하는 방법에 대한 자세한 내용은 전송 중 암호화를 참조하세요.
모니터링
기계 학습 리소스를 배포할 때 가시성을 위해 로깅 및 감사 컨트롤을 설정합니다. 데이터를 관찰하는 동기는 데이터를 보는 사람에 따라 다를 수 있습니다. 다음과 같은 시나리오가 있습니다.
기계 학습 실무자 또는 운영 팀이 기계 학습 파이프라인 상태를 모니터링하려고 합니다. 이러한 관찰자는 예약된 실행의 문제 또는 데이터 품질 또는 예상 학습 성능 문제를 이해해야 합니다. Azure Machine Learning 데이터를 모니터링하는 Azure 대시보드를 빌드하거나 이벤트 기반 워크플로를 만들 수 있습니다.
용량 관리자, 기계 학습 실무자 또는 운영 팀은 컴퓨팅 및 할당량 사용률을 관찰하기 위해 대시보드를 생성할 수 있습니다. 여러 Azure Machine Learning 작업 영역으로 배포를 관리하려면 할당량 사용률을 파악하기 위한 중앙 대시보드를 만드는 것이 좋습니다. 할당량은 구독 수준에서 관리되므로 최적화를 추진하려면 전체 환경 보기가 중요합니다.
IT 및 운영 팀은 작업 영역에서 리소스 액세스 및 변경 이벤트를 감사하기 위한 진단 로깅을 설정할 수 있습니다.
스토리지와 같은 종속 리소스 및 기계 학습에 대한 전반적인 인프라 상태를 모니터링하는 대시보드를 만드는 것이 좋습니다. 예를 들어 Azure Storage 메트릭을 파이프라인 실행 데이터와 결합하면 인프라를 최적화하여 성능을 향상하거나 문제의 근본 원인을 검색할 수 있습니다.
Azure는 플랫폼 메트릭 및 활동 로그를 자동으로 수집하고 저장합니다. 진단 설정을 사용하여 데이터를 다른 위치로 라우팅할 수 있습니다. 여러 작업 영역 인스턴스에서 가시성을 위해 중앙 집중식 Log Analytics 작업 영역에 진단 로깅을 설정합니다. Azure Policy를 사용하여 새 기계 학습 작업 영역에 대한 로깅을 중앙 Log Analytics 작업 영역에 자동으로 설정합니다.
Azure Policy
Azure Policy를 통해 작업 영역에서 보안 기능 사용법을 적용하고 감사할 수 있습니다. 권장 사항은 다음과 같습니다.
- 사용자 지정 관리형 키 암호화를 적용합니다.
- Azure Private Link 및 프라이빗 엔드포인트를 적용합니다.
- 프라이빗 DNS 영역을 적용합니다.
- SSH(Secure Shell)와 같은 비 Azure AD 인증을 사용하지 않도록 설정합니다.
자세한 내용은 Azure Machine Learning을 위한 기본 제공 정책 정의를 참조하세요.
사용자 지정 정책 정의를 사용하여 유연한 방식으로 작업 영역 보안을 제어할 수도 있습니다.
컴퓨팅 클러스터 및 인스턴스
다음 고려 사항 및 권장 사항은 기계 학습 컴퓨팅 클러스터 및 인스턴스에 적용됩니다.
디스크 암호화
컴퓨팅 인스턴스 또는 컴퓨팅 클러스터 노드에 대한 운영 체제(OS) 디스크는 Azure Storage에 저장되고 Microsoft 관리형 키로 암호화됩니다. 각 노드에는 로컬 임시 디스크도 있습니다. 또한 매개 변수를 사용하여 작업 영역을 만든 경우 임시 디스크는 Microsoft 관리형 키로 hbi_workspace = True 암호화됩니다. 자세한 내용은 Azure Machine Learning과 데이터 통합을 참조하세요.
관리 ID
컴퓨팅 클러스터는 관리 ID를 사용하여 Azure 리소스에 인증할 수 있도록 지원합니다. 클러스터에 관리 ID를 사용하면 코드에서 자격 증명을 노출하지 않고 리소스에 대한 인증이 가능합니다. 자세한 내용은 Azure Machine Learning 컴퓨팅 클러스터 만들기를 참조 하세요.
설치 스크립트
설치 스크립트를 사용하여 생성 시 컴퓨팅 인스턴스의 사용자 지정 및 구성을 자동화할 수 있습니다. 관리자는 작업 영역에서 모든 컴퓨팅 인스턴스를 만들 때 사용할 사용자 지정 스크립트를 작성할 수 있습니다. Azure Policy를 사용하여 설정 스크립트를 적용하여 모든 컴퓨팅 인스턴스를 만들 수 있습니다. 자세한 내용은 Azure Machine Learning 컴퓨팅 인스턴스 만들기 및 관리를 참조하세요.
대신 만들기
데이터 과학자가 컴퓨팅 리소스를 프로비전하지 않으려면 컴퓨팅 인스턴스를 대신 만들어 데이터 과학자에게 할당할 수 있습니다. 자세한 내용은 Azure Machine Learning 컴퓨팅 인스턴스 만들기 및 관리를 참조하세요.
프라이빗 엔드포인트 사용 작업 영역
프라이빗 엔드포인트 사용 작업 영역에서 컴퓨팅 인스턴스를 사용합니다. 컴퓨팅 인스턴스는 가상 네트워크 외부의 공용 액세스를 모두 거부합니다. 이런 구성은 패킷 필터링도 방지합니다.
Azure Policy 지원
Azure 가상 네트워크를 사용하는 경우 Azure Policy를 사용하여 모든 컴퓨팅 클러스터 또는 인스턴스가 가상 네트워크에 생성되도록 하고 기본 가상 네트워크 및 서브넷을 지정할 수 있습니다. 관리되는 가상 네트워크에서 컴퓨팅 리소스가 자동으로 생성되기 때문에 관리형 가상 네트워크를 사용할 때는 정책이 필요하지 않습니다.
정책을 사용하여 SSH와 같은 비 Azure AD 인증을 사용하지 않도록 설정할 수도 있습니다.
다음 단계
기계 학습 보안 구성에 대해 자세히 알아보기:
기계 학습 템플릿 기반 배포 시작:
기계 학습을 배포하기 위한 아키텍처 고려 사항에 대한 문서 읽어보기:
팀 구조, 환경 또는 지역 제약 조건이 작업 영역 설정에 어떻게 영향을 미치는지 알아봅니다.
팀과 사용자 전반에 걸쳐 컴퓨팅 비용과 예산을 관리하는 방법을 알아보세요.
사람, 프로세스 및 기술의 조합을 사용하여 강력하고 안정적이며 자동화된 Machine Learning 솔루션을 제공하는 MLOps(Machine learning DevOps)에 대해 알아봅니다.
피드백
출시 예정: 2024년 내내 콘텐츠에 대한 피드백 메커니즘으로 GitHub 문제를 단계적으로 폐지하고 이를 새로운 피드백 시스템으로 바꿀 예정입니다. 자세한 내용은 다음을 참조하세요. https://aka.ms/ContentUserFeedback
다음에 대한 사용자 의견 제출 및 보기