전문 음성 모델 학습
이 문서에서는 Speech Studio 포털을 통해 사용자 지정 신경망 음성을 학습하는 방법을 알아봅니다.
Important
사용자 지정 신경망 음성 학습은 현재 일부 지역에서만 사용할 수 있습니다. 음성 모델이 지원되는 지역에서 학습되면 필요에 따라 다른 지역의 Speech 리소스에 복사할 수 있습니다. 자세한 내용은 Speech Service 표의 각주를 참조하세요.
학습 기간은 사용하는 데이터 양에 따라 달라집니다. 사용자 지정 신경망 음성을 학습하는 데 평균 40 컴퓨팅 시간이 소요됩니다. 표준 구독(S0) 사용자는 4개의 음성을 동시에 학습할 수 있습니다. 한도에 도달하면 하나 이상의 음성 모델에 대한 학습이 완료될 때까지 기다린 후 다시 시도하세요.
학습 방법 선택
데이터 파일의 유효성을 검사한 후 이를 사용하여 사용자 지정 신경망 음성 모델을 빌드합니다. 사용자 지정 신경망 음성을 만드는 경우 다음 방법 중 하나를 사용하여 학습하도록 선택할 수 있습니다.
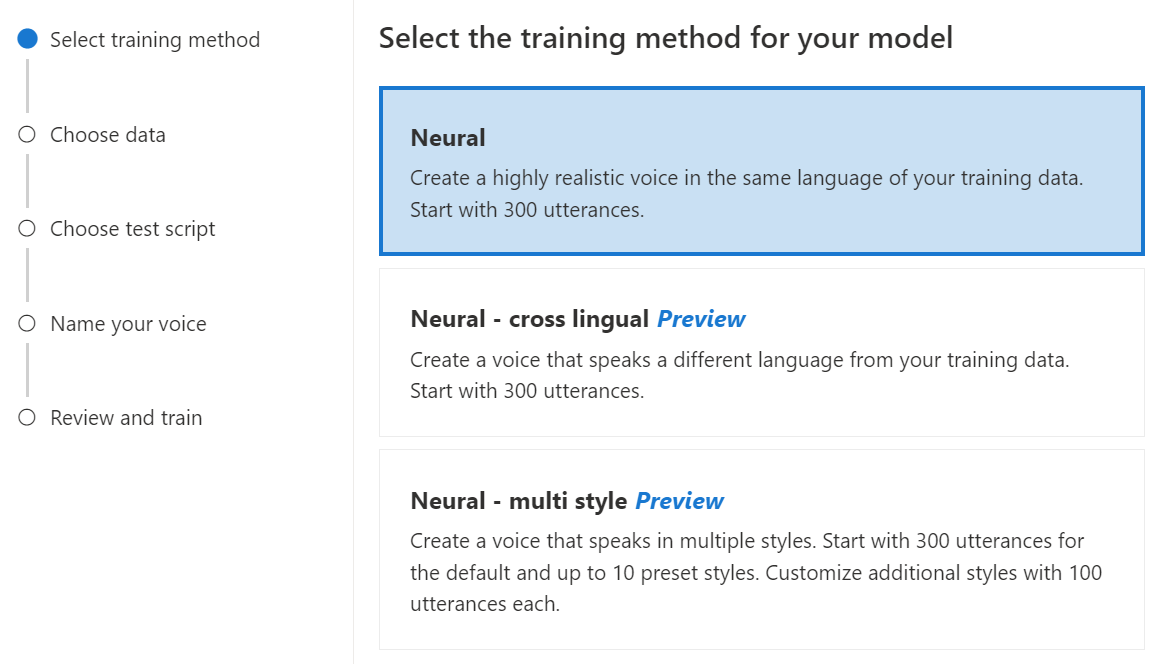
인공신경망: 음성을 학습 데이터와 동일한 언어로 만듭니다.
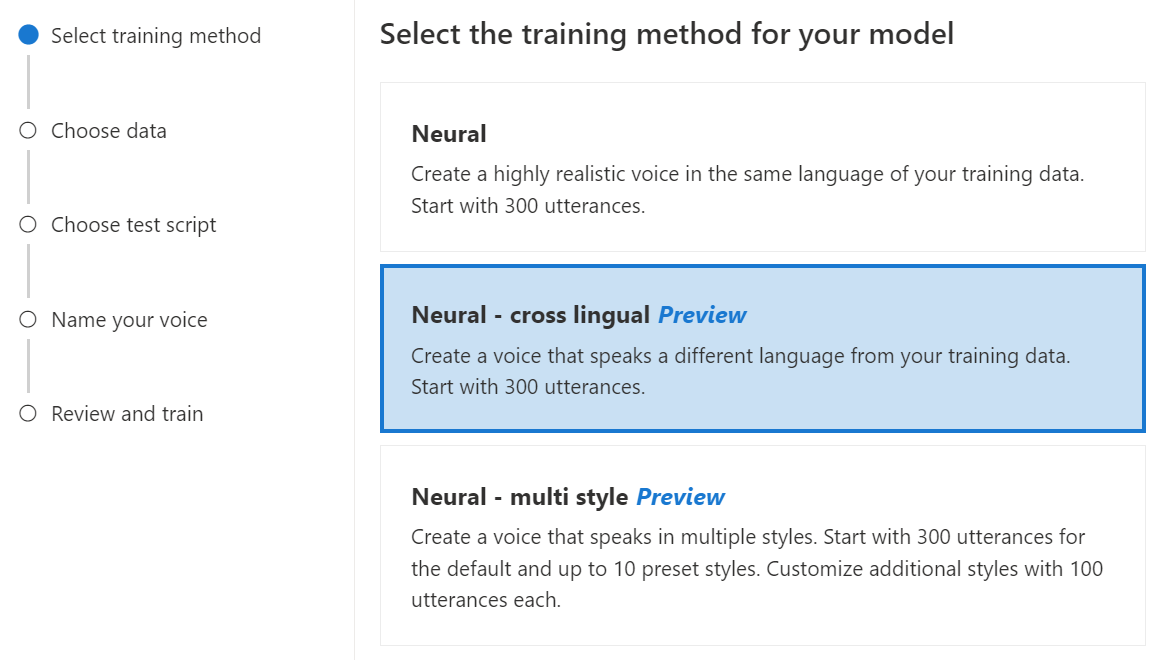
신경망 - 언어 간: 학습 데이터와 다른 언어를 사용하는 음성을 만듭니다. 예를 들어
zh-CN학습 데이터를 사용하면en-US를 말하는 음성을 만들 수 있습니다.학습 데이터의 언어와 대상 언어는 모두 언어 간 음성 학습에 지원되는 언어 중 하나여야 합니다. 학습 데이터를 대상 언어로 준비할 필요는 없지만 테스트 스크립트는 대상 언어로 되어 있어야 합니다.
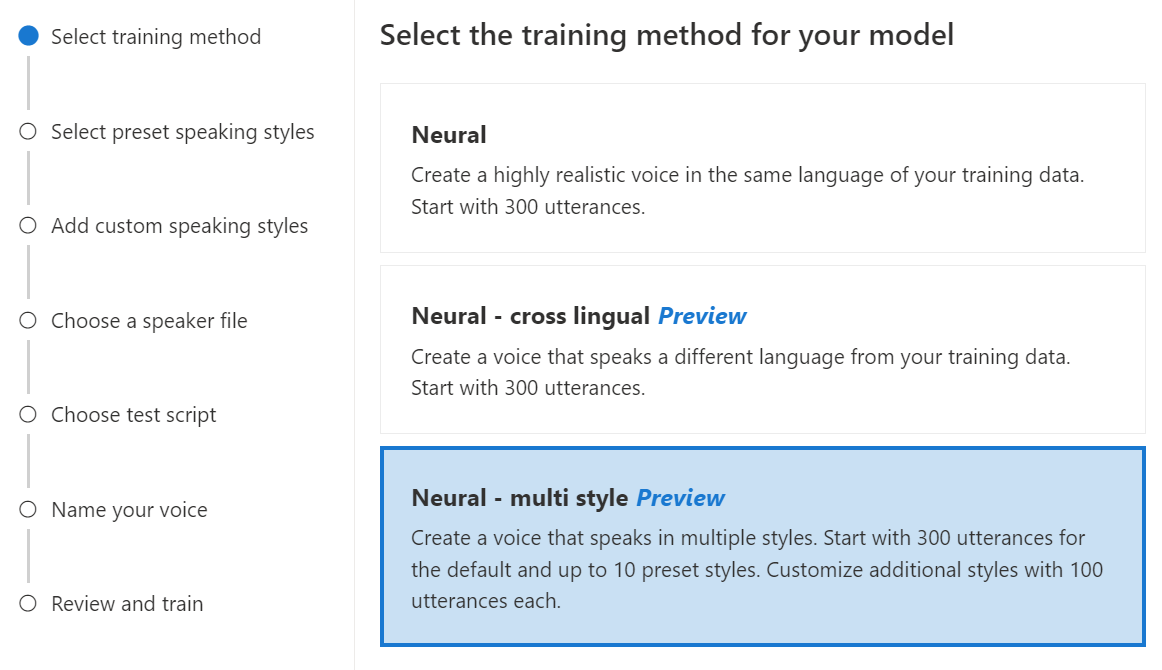
인공신경망 - 다중 스타일: 새 학습 데이터를 추가하지 않고 여러 스타일과 감정으로 말하는 사용자 지정 신경망 음성을 만듭니다. 다중 스타일 음성은 비디오 게임 캐릭터, 대화형 챗봇, 오디오 책, 콘텐츠 리더 등에 유용합니다.
여러 스타일 음성을 만들려면 300개 이상의 발화로 이루어진 일반 학습 데이터 세트를 준비해야 합니다. 미리 설정된 대상 말하기 스타일 중 하나 이상을 선택합니다. 또한 스타일 샘플을 동일한 음성에 대한 추가 학습 데이터로 제공하여(스타일당 최대 100개의 발화) 여러 사용자 지정 스타일을 만들 수 있습니다. 지원되는 사전 설정 스타일은 언어에 따라 다릅니다. 다양한 언어에서 사용 가능한 미리 설정된 스타일을 참조 하세요.
학습 데이터의 언어는 사용자 지정 인공신경망 음성, 언어 간 또는 다중 스타일 학습에 지원되는 언어 중 하나여야 합니다.
사용자 지정 신경망 음성 모델 학습
Speech Studio에서 사용자 지정 신경망 음성을 만들려면 다음 방법 중 하나에 대한 단계를 수행합니다.
Speech Studio에 로그인합니다.
사용자 지정 음성<>을 선택합니다. 프로젝트 이름>>학습 모델>새 모델 학습
모델에 대한 학습 방법으로 인공신경망을 선택하고, 다음을 선택합니다. 다른 학습 방법을 사용하려면 인공신경망 - 언어 간 또는 인공신경망 - 다중 스타일을 참조하세요.
모델에 대한 학습 레시피 버전을 선택합니다. 기본적으로 최신 버전이 선택됩니다. 지원되는 기능 및 학습 시간은 버전에 따라 다를 수 있습니다. 일반적으로 최신 버전을 사용하는 것이 좋습니다. 경우에 따라 이전 버전을 선택하여 학습 시간을 줄일 수 있습니다. 이중 언어 학습 및 로캘 간의 차이점에 대한 자세한 내용은 이중 언어 교육을 참조하세요.
학습에 사용하려는 데이터를 선택합니다. 중복된 오디오 이름은 학습에서 제거됩니다. 선택한 데이터에 여러 .zip 파일에 동일한 오디오 이름이 포함되지 않도록 합니다.
성공적으로 처리된 데이터 세트만 학습용으로 선택할 수 있습니다. 목록에 학습 집합이 표시되지 않으면 데이터 처리 상태를 확인합니다.
학습 데이터의 화자에 해당하는 성우 설명이 있는 화자 파일을 선택합니다.
다음을 선택합니다.
각 학습에서는 기본 스크립트를 사용하여 모델을 테스트하는 데 도움이 되는 100개의 샘플 오디오 파일을 자동으로 생성합니다.
원하는 경우 내 테스트 스크립트 추가를 선택하고 최대 100개의 발화가 포함된 자체 테스트 스크립트를 제공하여 추가 비용 없이 모델을 테스트할 수도 있습니다. 생성된 오디오 파일은 자동 테스트 스크립트와 사용자 지정 테스트 스크립트의 조합입니다. 자세한 내용은 테스트 스크립트 요구 사항을 참조하세요.
모델을 식별하는 데 도움이 되는 이름을 입력합니다. 신중하게 이름을 선택합니다. 모델 이름은 SDK 및 SSML 입력을 통해 음성 합성 요청에서 음성 이름으로 사용됩니다. 문자, 숫자 및 몇 가지 문장 부호 문자만 허용됩니다. 다른 신경망 음성 모델에 다른 이름을 사용합니다.
필요에 따라 모델을 식별하는 데 도움이 되는 설명을 입력합니다. 설명의 일반적인 용도는 모델을 만드는 데 사용한 데이터의 이름을 기록하는 것입니다.
다음을 선택합니다.
설정을 검토하고, 사용 약관에 동의하는 확인란을 선택합니다.
제출을 선택하여 모델 학습을 시작합니다.
이중 언어 교육
신경망 학습 유형을 선택하는 경우 여러 언어로 음성을 학습시킬 수 있습니다. 로캘과 zh-TW 로캘은 zh-CN 모두 음성에 대한 이중 언어 교육을 지원하여 중국어와 영어를 모두 구사합니다. 학습 데이터에 따라 합성된 음성은 영어 네이티브 악센트 또는 영어와 학습 데이터와 동일한 악센트로 영어를 말할 수 있습니다.
참고 항목
로캘의 zh-CN 음성이 샘플 데이터와 동일한 악센트로 영어를 사용할 수 있도록 하려면 프로젝트를 만들 때 선택 Chinese (Mandarin, Simplified), English bilingual 하거나 REST API를 통해 학습 집합 데이터에 대한 로캘을 지정 zh-CN (English bilingual) 해야 합니다.
다음 표에서는 두 로캘 간의 차이점을 보여 줍니다.
| Speech Studio 로캘 | REST API 로캘 | 이중 언어 지원 |
|---|---|---|
Chinese (Mandarin, Simplified) |
zh-CN |
샘플 데이터에 영어가 포함된 경우 합성된 음성은 영어 데이터의 양에 관계없이 샘플 데이터와 동일한 악센트 대신 영어 네이티브 악센트로 영어를 구사합니다. |
Chinese (Mandarin, Simplified), English bilingual |
zh-CN (English bilingual) |
합성된 음성이 샘플 데이터와 동일한 악센트로 영어를 구사하도록 하려면 학습 집합에 10% 이상의 영어 데이터를 포함하는 것이 좋습니다. 그렇지 않으면 영어 억양이 이상적이지 않을 수 있습니다. |
Chinese (Taiwanese Mandarin, Traditional) |
zh-TW |
샘플 데이터와 동일한 악센트로 영어를 말할 수 있는 합성된 음성을 학습하려면 학습 집합에 10% 이상의 영어 데이터를 제공해야 합니다. 그렇지 않으면 기본값은 영어 네이티브 악센트입니다. 10% 임계값은 업로드 전에 데이터가 아니라 성공적으로 업로드한 후에 허용되는 데이터를 기반으로 계산됩니다. 일부 업로드된 영어 데이터가 결함으로 인해 거부되고 10% 임계값을 충족하지 않는 경우 합성된 음성은 기본적으로 영어 네이티브 악센트로 설정됩니다. |
다양한 언어에서 사용 가능한 사전 설정 스타일
다음 표에는 다양한 언어에 따른 다양한 사전 설정 스타일이 요약되어 있습니다.
| 말하기 스타일 | 언어(로캘) |
|---|---|
| 화난 | 영어(미국)(en-US)일본어(일본) ( ja-JP) 1중국어(중국어, 간체) ( zh-CN) 1 |
| 차분한 | 중국어(중국어, 간체) (zh-CN) 1 |
| 채팅 | 중국어(중국어, 간체) (zh-CN) 1 |
| 쾌활한 | 영어(미국)(en-US)일본어(일본) ( ja-JP) 1중국어(중국어, 간체) ( zh-CN) 1 |
| 불만스러운 | 중국어(중국어, 간체) (zh-CN) 1 |
| 신남 | 영어(미국)(en-US) |
| 걱정하는 | 중국어(중국어, 간체) (zh-CN) 1 |
| 친숙한 | 영어(미국)(en-US) |
| 희망적인 | 영어(미국)(en-US) |
| 슬픈 | 영어(미국)(en-US)일본어(일본) ( ja-JP) 1중국어(중국어, 간체) ( zh-CN) 1 |
| 소리 지르는 | 영어(미국)(en-US) |
| 심각한 | 중국어(중국어, 간체) (zh-CN) 1 |
| 무서운 | 영어(미국)(en-US) |
| 쌀 쌀 | 영어(미국)(en-US) |
| 속삭이는 | 영어(미국)(en-US) |
1 신경망 음성 스타일은 공개 미리 보기에서 사용할 수 있습니다. 공개 미리 보기의 스타일은 미국 동부, 서유럽 및 동남 아시아의 서비스 지역에서만 사용할 수 있습니다.
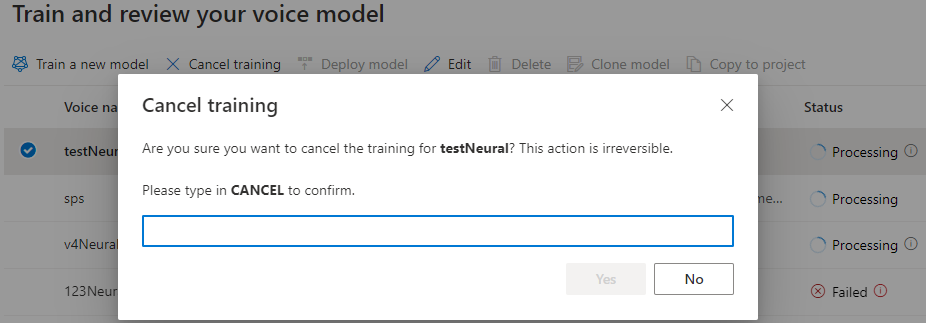
모델 학습 테이블에는 새로 만든 이 모델에 해당하는 새 항목이 표시됩니다. 상태는 다음 표에서 설명한 대로 데이터를 음성 모델로 변환하는 프로세스를 반영합니다.
| 시스템 상태 | 의미 |
|---|---|
| 처리 | 음성 모델이 만들어지고 있습니다. |
| 성공함 | 음성 모델이 만들어졌으며 배포할 수 있습니다. |
| 실패함 | 음성 모델이 학습에 실패했습니다. 실패의 원인은 예를 들어 표시되지 않는 데이터 문제 또는 네트워크 문제일 수 있습니다. |
| Canceled | 음성 모델에 대한 학습이 취소되었습니다. |
모델 상태가 처리 중인 동안 학습 취소를 선택하여 음성 모델을 취소할 수 있습니다. 취소된 학습에 대한 비용은 청구되지 않습니다.
모델 학습이 성공적으로 완료되면 모델 세부 정보를 검토하고 음성 모델을 테스트할 수 있습니다.
Speech Studio에서 오디오 콘텐츠 만들기 도구를 사용하여 오디오를 만들고 배포된 음성을 미세 조정할 수 있습니다. 사용자 음성에 적절한 경우 여러 스타일 중 하나를 선택할 수 있습니다.
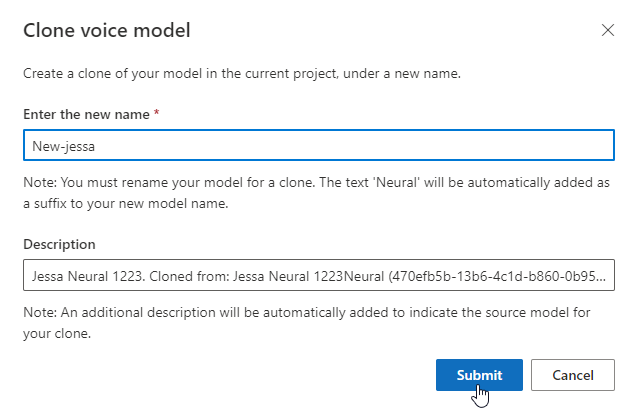
모델 이름 바꾸기
빌드한 모델의 이름을 바꾸려면 모델 복제를 선택하여 현재 프로젝트에서 새 이름으로 모델의 복제본을 만듭니다.

음성 모델 복제 창에서 새 이름을 입력한 다음, 제출을 클릭합니다. 텍스트 Neural이 새 모델 이름의 접미사로 자동 추가됩니다.
음성 모델 테스트
음성 모델이 성공적으로 빌드된 후에는 사용을 위해 배포하기 전에 생성된 샘플 오디오 파일을 테스트할 수 있습니다.
음성 품질은 다음과 같은 여러 요인에 따라 달라집니다.
- 학습 데이터의 크기
- 녹음 품질
- 음성 텍스트 파일의 정확도
- 학습 데이터의 녹음된 음성이 의도한 사용 사례에 대해 설계된 음성의 특성과 일치하는 수준
샘플 오디오 파일을 들으려면 테스트에서 DefaultTests를 선택합니다. 기본 테스트 샘플에는 모델 테스트에 도움이 되도록 학습 중에 자동으로 생성된 100개의 샘플 오디오 파일이 포함됩니다. 기본적으로 제공되는 이러한 100개의 오디오 파일 외에도 학습 중에 제공되는 자체 테스트 스크립트 발화도 DefaultTests 집합에 추가됩니다. 이 추가 내용은 최대 100개의 발화입니다. DefaultTests를 사용한 테스트 비용은 청구되지 않습니다.

자체 테스트 스크립트를 업로드하여 모델을 추가로 테스트하려면 테스트 스크립트 추가를 선택하여 자체 테스트 스크립트를 업로드합니다.
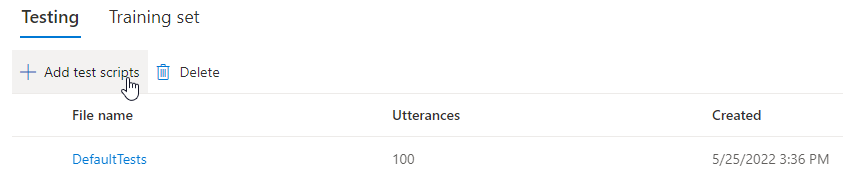
테스트 스크립트를 업로드하기 전에 테스트 스크립트 요구 사항을 확인합니다. 청구 가능한 문자 수를 기준으로 일괄 처리 합성을 통한 추가 테스트 비용이 청구됩니다. Azure AI 음성 가격 책정을 참조하세요.
테스트 스크립트 추가에서 파일 찾아보기를 선택하여 사용자 고유의 스크립트를 선택한 다음, 추가를 선택하여 업로드합니다.

테스트 스크립트 요구 사항
테스트 스크립트는 1MB 미만의 .txt 파일이어야 합니다. 지원되는 인코딩 형식으로 ANSI/ASCII, UTF-8, UTF-8-BOM, UTF-16-LE 또는 UTF-16-BE가 있습니다.
학습 대화 내용 기록 파일과 달리 테스트 스크립트는 발화 ID(각 발화의 파일 이름)를 제외해야 합니다. 그렇지 않으면 이러한 ID가 음성으로 발화됩니다.
한 .txt 파일에 있는 발화 세트의 예제는 다음과 같습니다.
This is the waistline, and it's falling.
We have trouble scoring.
It was Janet Maslin.
발화의 각 단락에서 별도의 오디오를 생성합니다. 모든 문장을 하나의 오디오로 결합하려면 이를 한 단락으로 만듭니다.
참고 항목
생성된 오디오 파일은 자동 테스트 스크립트와 사용자 지정 테스트 스크립트의 조합입니다.
음성 모델에 대한 엔진 버전 업데이트
Azure 텍스트 음성 변환 엔진은 언어의 발음을 정의하는 최신 언어 모델을 캡처하기 위해 수시로 업데이트됩니다. 음성이 학습되면 최신 엔진 버전으로 업데이트하여 음성을 새 언어 모델에 적용할 수 있습니다.
새 엔진을 사용할 수 있는 경우 신경망 음성 모델을 업데이트하라는 메시지가 표시됩니다.

모델 세부 정보 페이지로 이동하여 화면의 지침에 따라 최신 엔진을 설치합니다.

또는 나중에 최신 엔진 설치를 선택하여 모델을 최신 엔진 버전으로 업데이트합니다.
엔진 업데이트에 대한 요금이 청구되지 않습니다. 이전 버전은 계속 유지됩니다.
엔진 버전 목록에서 모델에 대한 모든 엔진 버전을 확인하거나, 더 이상 필요하지 않은 경우 해당 버전을 제거할 수 있습니다.
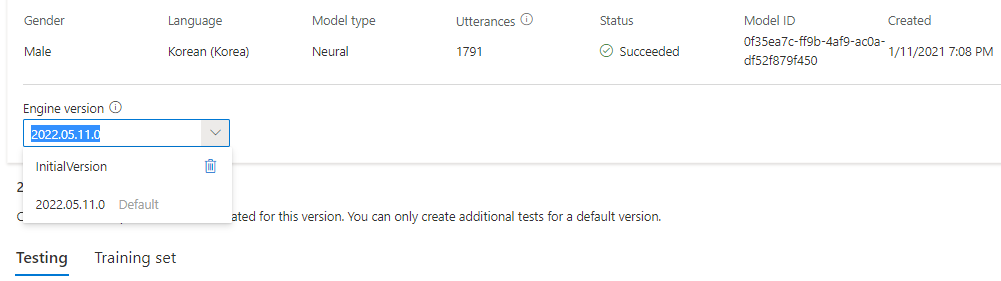
업데이트된 버전은 자동으로 기본값으로 설정됩니다. 그러나 기본 버전은 드롭다운 목록에서 버전을 선택하고 기본값으로 설정을 선택하여 변경할 수 있습니다.
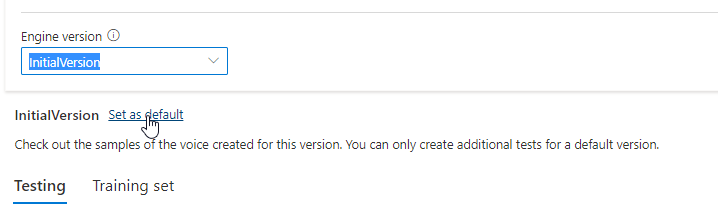

음성 모델의 각 엔진 버전을 테스트하려면 목록에서 버전을 선택한 다음, 테스트 아래에서 DefaultTests를 선택하여 샘플 오디오 파일을 들을 수 있습니다. 현재 엔진 버전을 추가로 테스트하기 위해 사용자 고유의 테스트 스크립트를 업로드하려면 먼저 버전이 기본값으로 설정되어 있는지 확인한 다음, 음성 모델 테스트의 단계를 수행합니다.
엔진을 업데이트하면 추가 비용 없이 모델의 새 버전이 생성됩니다. 음성 모델의 엔진 버전을 업데이트한 후 새 버전을 배포하여 새 엔드포인트를 만들어야 합니다. 기본 버전만 배포할 수 있습니다.
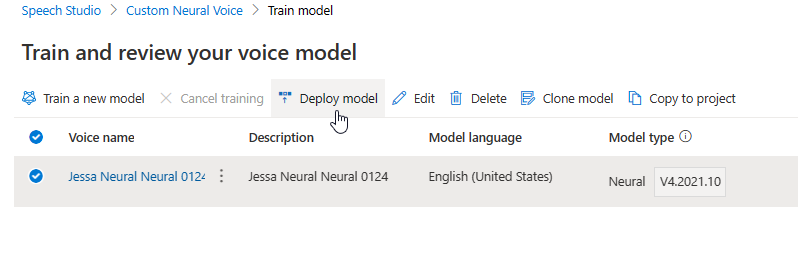
새 엔드포인트를 만든 후에는 제품의 새 엔드포인트로 트래픽을 전송해야 합니다.
이 기능의 기능 및 제한 사항 및 모델 품질을 개선하는 모범 사례에 대해 자세히 알아보려면 사용자 지정 신경망 음성 사용에 대한 특성 및 제한 사항을 참조하세요.
음성 모델을 다른 프로젝트에 복사
음성 모델은 동일한 지역 또는 다른 지역의 다른 프로젝트에 복사할 수 있습니다. 예를 들어 한 지역에서 학습된 신경망 음성 모델을 다른 지역의 프로젝트에 복사할 수 있습니다.
참고 항목
사용자 지정 신경망 음성 학습은 현재 일부 지역에서만 사용할 수 있습니다. 그러나 인공신경망 음성 모델을 이러한 지역에서 다른 지역으로 복사할 수 있습니다. 자세한 내용은 사용자 지정 신경망 음성 지역을 참조하세요.
사용자 지정 신경망 음성 모델을 다른 프로젝트에 복사하려면 다음을 수행합니다.
모델 학습 탭에서 복사하려는 음성 모델을 선택한 다음, 프로젝트에 복사를 선택합니다.

모델을 복사하려는 지역, 음성 리소스 및 프로젝트를 선택합니다. 음성 리소스와 프로젝트는 대상 지역에 있어야 합니다. 그렇지 않으면 먼저 만들어야 합니다.

제출을 선택하여 모델을 복사합니다.
복사 성공 알림 메시지 아래에서 모델 보기를 선택합니다.
모델을 복사한 프로젝트로 이동하여 모델 복사본을 배포합니다.
다음 단계
이 문서에서는 사용자 지정 음성 API를 통해 사용자 지정 신경망 음성을 학습하는 방법을 알아봅니다.
Important
사용자 지정 신경망 음성 학습은 현재 일부 지역에서만 사용할 수 있습니다. 음성 모델이 지원되는 지역에서 학습되면 필요에 따라 다른 지역의 Speech 리소스에 복사할 수 있습니다. 자세한 내용은 Speech Service 표의 각주를 참조하세요.
학습 기간은 사용하는 데이터 양에 따라 달라집니다. 사용자 지정 신경망 음성을 학습하는 데 평균 40 컴퓨팅 시간이 소요됩니다. 표준 구독(S0) 사용자는 4개의 음성을 동시에 학습할 수 있습니다. 한도에 도달하면 하나 이상의 음성 모델에 대한 학습이 완료될 때까지 기다린 후 다시 시도하세요.
학습 방법 선택
데이터 파일의 유효성을 검사한 후 이를 사용하여 사용자 지정 신경망 음성 모델을 빌드합니다. 사용자 지정 신경망 음성을 만드는 경우 다음 방법 중 하나를 사용하여 학습하도록 선택할 수 있습니다.
인공신경망: 음성을 학습 데이터와 동일한 언어로 만듭니다.
신경망 - 언어 간: 학습 데이터와 다른 언어를 사용하는 음성을 만듭니다. 예를 들어
fr-FR학습 데이터를 사용하면en-US를 말하는 음성을 만들 수 있습니다.학습 데이터의 언어와 대상 언어는 모두 언어 간 음성 학습에 지원되는 언어 중 하나여야 합니다. 학습 데이터를 대상 언어로 준비할 필요는 없지만 테스트 스크립트는 대상 언어로 되어 있어야 합니다.
인공신경망 - 다중 스타일: 새 학습 데이터를 추가하지 않고 여러 스타일과 감정으로 말하는 사용자 지정 신경망 음성을 만듭니다. 다중 스타일 음성은 비디오 게임 캐릭터, 대화형 챗봇, 오디오 책, 콘텐츠 리더 등에 유용합니다.
여러 스타일 음성을 만들려면 300개 이상의 발화로 이루어진 일반 학습 데이터 세트를 준비해야 합니다. 미리 설정된 대상 말하기 스타일 중 하나 이상을 선택합니다. 또한 스타일 샘플을 동일한 음성에 대한 추가 학습 데이터로 제공하여(스타일당 최대 100개의 발화) 여러 사용자 지정 스타일을 만들 수 있습니다. 지원되는 사전 설정 스타일은 언어에 따라 다릅니다. 다양한 언어에서 사용 가능한 미리 설정된 스타일을 참조 하세요.
학습 데이터의 언어는 사용자 지정 신경망 음성, 언어 간 또는 여러 스타일 학습에 지원되는 언어 중 하나여야 합니다.
음성 모델 만들기
신경망 음성을 만들려면 사용자 지정 음성 API의 Models_Create 작업을 사용합니다. 다음 지침에 따라 요청 본문을 생성합니다.
- 필수
projectId속성을 설정합니다. 프로젝트 만들기를 참조하세요. - 필수
consentId속성을 설정합니다. 성우 동의 추가를 참조하세요. - 필수
trainingSetId속성을 설정합니다. 학습 집합 만들기를 참조 하세요. - 신경망 음성 학습에
Default필요한 레시피kind속성을 설정합니다. 레시피 종류는 학습 방법을 나타내며 나중에 변경할 수 없습니다. 다른 학습 방법을 사용하려면 인공신경망 - 언어 간 또는 인공신경망 - 다중 스타일을 참조하세요. 이중 언어 학습 및 로캘 간의 차이점에 대한 자세한 내용은 이중 언어 교육을 참조하세요. - 필수
voiceName속성을 설정합니다. 음성 이름은 "신경망"으로 끝나야 하며 나중에 변경할 수 없습니다. 신중하게 이름을 선택합니다. 음성 이름은 SDK 및 SSML 입력에서 음성 합성 요청에 사용됩니다. 문자, 숫자 및 몇 가지 문장 부호 문자만 허용됩니다. 다른 신경망 음성 모델에 다른 이름을 사용합니다. - 필요에 따라 음성 설명의
description속성을 설정합니다. 음성 설명은 나중에 변경할 수 있습니다.
다음 Models_Create 예제와 같이 URI를 사용하여 HTTP PUT 요청을 만듭니다.
YourResourceKey를 Speech 리소스 키로 바꿉니다.- Speech 리소스 지역으로 대체
YourResourceRegion합니다. - 선택한 모델 ID로 대체
JessicaModelId합니다. 대/소문자 구분 ID는 모델의 URI에서 사용되며 나중에 변경할 수 없습니다.
curl -v -X PUT -H "Ocp-Apim-Subscription-Key: YourResourceKey" -H "Content-Type: application/json" -d '{
"voiceName": "JessicaNeural",
"description": "Jessica voice",
"recipe": {
"kind": "Default"
},
"projectId": "ProjectId",
"consentId": "JessicaConsentId",
"trainingSetId": "JessicaTrainingSetId"
} ' "https://YourResourceRegion.api.cognitive.microsoft.com/customvoice/models/JessicaModelId?api-version=2023-12-01-preview"
응답 본문은 다음 형식으로 표시되어야 합니다.
{
"id": "JessicaModelId",
"voiceName": "JessicaNeural",
"description": "Jessica voice",
"recipe": {
"kind": "Default",
"version": "V7.2023.03"
},
"projectId": "ProjectId",
"consentId": "JessicaConsentId",
"trainingSetId": "JessicaTrainingSetId",
"locale": "en-US",
"engineVersion": "2023.07.04.0",
"status": "NotStarted",
"createdDateTime": "2023-04-01T05:30:00.000Z",
"lastActionDateTime": "2023-04-02T10:15:30.000Z"
}
이중 언어 교육
신경망 학습 유형을 선택하는 경우 여러 언어로 음성을 학습시킬 수 있습니다. 로캘과 zh-TW 로캘은 zh-CN 모두 음성에 대한 이중 언어 교육을 지원하여 중국어와 영어를 모두 구사합니다. 학습 데이터에 따라 합성된 음성은 영어 네이티브 악센트 또는 영어와 학습 데이터와 동일한 악센트로 영어를 말할 수 있습니다.
참고 항목
로캘의 zh-CN 음성이 샘플 데이터와 동일한 악센트로 영어를 사용할 수 있도록 하려면 프로젝트를 만들 때 선택 Chinese (Mandarin, Simplified), English bilingual 하거나 REST API를 통해 학습 집합 데이터에 대한 로캘을 지정 zh-CN (English bilingual) 해야 합니다.
다음 표에서는 두 로캘 간의 차이점을 보여 줍니다.
| Speech Studio 로캘 | REST API 로캘 | 이중 언어 지원 |
|---|---|---|
Chinese (Mandarin, Simplified) |
zh-CN |
샘플 데이터에 영어가 포함된 경우 합성된 음성은 영어 데이터의 양에 관계없이 샘플 데이터와 동일한 악센트 대신 영어 네이티브 악센트로 영어를 구사합니다. |
Chinese (Mandarin, Simplified), English bilingual |
zh-CN (English bilingual) |
합성된 음성이 샘플 데이터와 동일한 악센트로 영어를 구사하도록 하려면 학습 집합에 10% 이상의 영어 데이터를 포함하는 것이 좋습니다. 그렇지 않으면 영어 억양이 이상적이지 않을 수 있습니다. |
Chinese (Taiwanese Mandarin, Traditional) |
zh-TW |
샘플 데이터와 동일한 악센트로 영어를 말할 수 있는 합성된 음성을 학습하려면 학습 집합에 10% 이상의 영어 데이터를 제공해야 합니다. 그렇지 않으면 기본값은 영어 네이티브 악센트입니다. 10% 임계값은 업로드 전에 데이터가 아니라 성공적으로 업로드한 후에 허용되는 데이터를 기반으로 계산됩니다. 일부 업로드된 영어 데이터가 결함으로 인해 거부되고 10% 임계값을 충족하지 않는 경우 합성된 음성은 기본적으로 영어 네이티브 악센트로 설정됩니다. |
다양한 언어에서 사용 가능한 사전 설정 스타일
다음 표에는 다양한 언어에 따른 다양한 사전 설정 스타일이 요약되어 있습니다.
| 말하기 스타일 | 언어(로캘) |
|---|---|
| 화난 | 영어(미국)(en-US)일본어(일본) ( ja-JP) 1중국어(중국어, 간체) ( zh-CN) 1 |
| 차분한 | 중국어(중국어, 간체) (zh-CN) 1 |
| 채팅 | 중국어(중국어, 간체) (zh-CN) 1 |
| 쾌활한 | 영어(미국)(en-US)일본어(일본) ( ja-JP) 1중국어(중국어, 간체) ( zh-CN) 1 |
| 불만스러운 | 중국어(중국어, 간체) (zh-CN) 1 |
| 신남 | 영어(미국)(en-US) |
| 걱정하는 | 중국어(중국어, 간체) (zh-CN) 1 |
| 친숙한 | 영어(미국)(en-US) |
| 희망적인 | 영어(미국)(en-US) |
| 슬픈 | 영어(미국)(en-US)일본어(일본) ( ja-JP) 1중국어(중국어, 간체) ( zh-CN) 1 |
| 소리 지르는 | 영어(미국)(en-US) |
| 심각한 | 중국어(중국어, 간체) (zh-CN) 1 |
| 무서운 | 영어(미국)(en-US) |
| 쌀 쌀 | 영어(미국)(en-US) |
| 속삭이는 | 영어(미국)(en-US) |
1 신경망 음성 스타일은 공개 미리 보기에서 사용할 수 있습니다. 공개 미리 보기의 스타일은 미국 동부, 서유럽 및 동남 아시아의 서비스 지역에서만 사용할 수 있습니다.
학습 상태 가져오기
음성 모델의 학습 상태 얻으려면 사용자 지정 음성 API의 Models_Get 작업을 사용합니다. 다음 지침에 따라 요청 URI를 생성합니다.
다음 Models_Get 예제와 같이 URI를 사용하여 HTTP GET 요청을 만듭니다.
YourResourceKey를 Speech 리소스 키로 바꿉니다.- Speech 리소스 지역으로 대체
YourResourceRegion합니다. - 이전 단계에서 다른 모델 ID를 지정한 경우 바꿉
JessicaModelId니다.
curl -v -X GET "https://YourResourceRegion.api.cognitive.microsoft.com/customvoice/models/JessicaModelId?api-version=2023-12-01-preview" -H "Ocp-Apim-Subscription-Key: YourResourceKey"
다음 형식의 응답 본문을 받아야 합니다.
참고 항목
레시피 kind 및 기타 속성은 음성을 학습하는 방법에 따라 달라집니다. 이 예제에서 레시피 종류는 Default 신경망 음성 학습을 위한 것입니다.
{
"id": "JessicaModelId",
"voiceName": "JessicaNeural",
"description": "Jessica voice",
"recipe": {
"kind": "Default",
"version": "V7.2023.03"
},
"projectId": "ProjectId",
"consentId": "JessicaConsentId",
"trainingSetId": "JessicaTrainingSetId",
"locale": "en-US",
"engineVersion": "2023.07.04.0",
"status": "Succeeded",
"createdDateTime": "2023-04-01T05:30:00.000Z",
"lastActionDateTime": "2023-04-02T10:15:30.000Z"
}
학습이 완료되기 전에 몇 분 동안 기다려야 할 수 있습니다. 결국 상태 중 하나 Succeeded 또는 Failed.로 변경됩니다.