Azure Cosmos DB 분석 저장소란?
적용 대상: ![]() NoSQL
NoSQL ![]() MongoDB
MongoDB ![]() Gremlin
Gremlin
Microsoft Azure Cosmos DB 분석 저장소는 트랜잭션 워크로드에 영향을 주지 않고 Microsoft Azure Cosmos DB의 작동 데이터에 대한 대규모 분석을 사용할 수 있게 하는 완전히 격리된 열 저장소입니다.
Microsoft Azure Cosmos DB 트랜잭션 저장소는 스키마에 구애받지 않으며 스키마나 인덱스 관리를 처리할 필요 없이 트랜잭션 애플리케이션을 반복할 수 있습니다. 이와 달리 Microsoft Azure Cosmos DB 분석 저장소는 분석 쿼리 성능을 최적화하도록 스키마화됩니다. 이 문서에서는 분석 스토리지에 대해 자세히 설명합니다.
작동 데이터의 대규모 분석 문제
Microsoft Azure Cosmos DB 컨테이너의 다중 모델 작동 데이터는 인덱싱된 행 기반 "트랜잭션 저장소"에 내부적으로 저장됩니다. 행 저장소 형식은 밀리초 단위의 응답 시간과 운영 쿼리를 통해 빠른 트랜잭션 읽기 및 쓰기를 지원하도록 설계되었습니다. 데이터 세트가 커지면 이 형식으로 저장된 데이터에 대한 프로비저닝된 처리량 측면에서 복잡한 분석 쿼리에 많은 비용이 들 수 있습니다. 프로비저닝된 처리량의 소비량이 많으면 실시간 애플리케이션과 서비스에서 사용하는 트랜잭션 워크로드의 성능에 영향이 있습니다.
일반적으로 많은 양의 데이터를 분석하기 위해 Microsoft Azure Cosmos DB의 트랜잭션 저장소에서 작동 데이터가 추출되어 별도의 데이터 계층에 저장됩니다. 예를 들어, 데이터는 데이터 웨어하우스나 데이터 레이크에 적절한 형식으로 저장됩니다. 이 데이터는 나중에 대규모 분석에 사용되며 Apache Spark 클러스터와 같은 컴퓨팅 엔진을 사용하여 분석됩니다. 분석을 운영 데이터와 분리하면 최신 데이터를 사용하려는 분석가의 작업이 지연됩니다.
또한 새로 수집된 작동 데이터만 처리할 때보다 작동 데이터의 업데이트를 처리할 때 ETL 파이프라인이 복잡해집니다.
열 기반 분석 저장소
Microsoft Azure Cosmos DB 분석 저장소는 기존의 ETL 파이프라인에서 발생하는 복잡성과 대기 시간 문제를 해결합니다. Microsoft Azure Cosmos DB 분석 저장소는 작동 데이터를 별도의 열 저장소로 자동 동기화할 수 있습니다. 열 저장소 형식은 대규모 분석 쿼리를 최적화된 방식으로 수행하는 데 적합합니다. 따라서 열 저장소 형식을 사용하면 대규모 분석 쿼리의 대기 시간이 향상됩니다.
이제 Azure Synapse Link로 Azure Synapse Analytics에서 Microsoft Azure Cosmos DB 분석 저장소에 직접 연결하여 비 ETL HTAP 솔루션을 구축할 수 있습니다. 이를 통해 작동 데이터에 대해 거의 실시간으로 대규모 분석을 실행할 수 있습니다.
분석 저장소의 기능
Microsoft Azure Cosmos DB 컨테이너에서 분석 저장소를 사용하도록 설정하면 컨테이너의 작동 데이터를 기반으로 새 열 저장소가 내부적으로 만들어집니다. 이 열 저장소는 해당 컨테이너에 대한 행 지향 트랜잭션 저장소와 별도로 내부 구독의 Azure Cosmos DB에서 모든 것을 관리하는 완전 관리형 스토리지 계정에 유지됩니다. 고객은 스토리지 관리에 시간을 쓸 필요가 없습니다. 작동 데이터의 삽입, 업데이트 및 삭제는 분석 저장소에 자동으로 동기화됩니다. 데이터를 동기화하는 데 변경 피드 또는 ETL이 필요하지 않습니다.
작동 데이터에 대한 분석 워크로드의 열 저장소
분석 워크로드에는 일반적으로 선택된 필드의 집계와 순차 검사가 포함됩니다. 데이터를 열 우선 순서로 저장하면 분석 저장소에서 각 필드의 값 그룹을 함께 직렬화할 수 있습니다. 이 형식은 특정 필드에 대한 통계를 검사하거나 계산하는 데 필요한 IOPS를 줄입니다. 이를 통해 큰 데이터 세트 검사를 위한 쿼리 응답 시간이 크게 향상됩니다.
예를 들어, 운영 테이블이 다음과 같은 형식입니다.
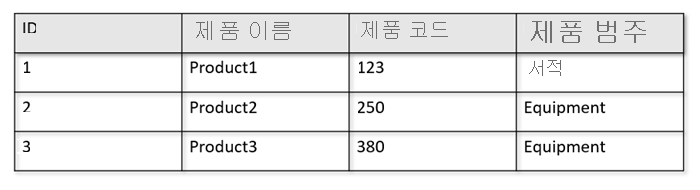
행 저장소는 디스크에 행별로 직렬화된 형식으로 위의 데이터를 저장합니다. 이 형식을 사용하면 트랜잭션 읽기와 쓰기 속도는 물론 "Product1에 대한 정보 반환"과 같은 운영 쿼리 속도를 높일 수 있습니다. 그러나 데이터 세트가 커지고 데이터에 대해 복잡한 분석 쿼리를 실행하려는 경우 비용이 많이 들 수 있습니다. 예를 들어 "여러 사업부와 월에 걸쳐 '장비'라는 범주의 제품에 대한 판매 추세"를 얻으려면 복잡한 쿼리를 실행해야 합니다. 이 데이터 세트에 대한 대규모 검사는 프로비저닝된 처리량 측면에서 비용이 많이 들 수 있으며 실시간 애플리케이션 및 서비스를 지원하는 트랜잭션 워크로드의 성능에 영향을 줄 수도 있습니다.
열 저장소인 분석 저장소가 유사한 데이터 필드를 함께 직렬화하고 디스크 IOPS를 줄이므로 이러한 쿼리에 더 적합합니다.
다음 이미지에서는 Microsoft Azure Cosmos DB의 트랜잭션 행 저장소와 분석 열 저장소를 비교하여 보여줍니다.
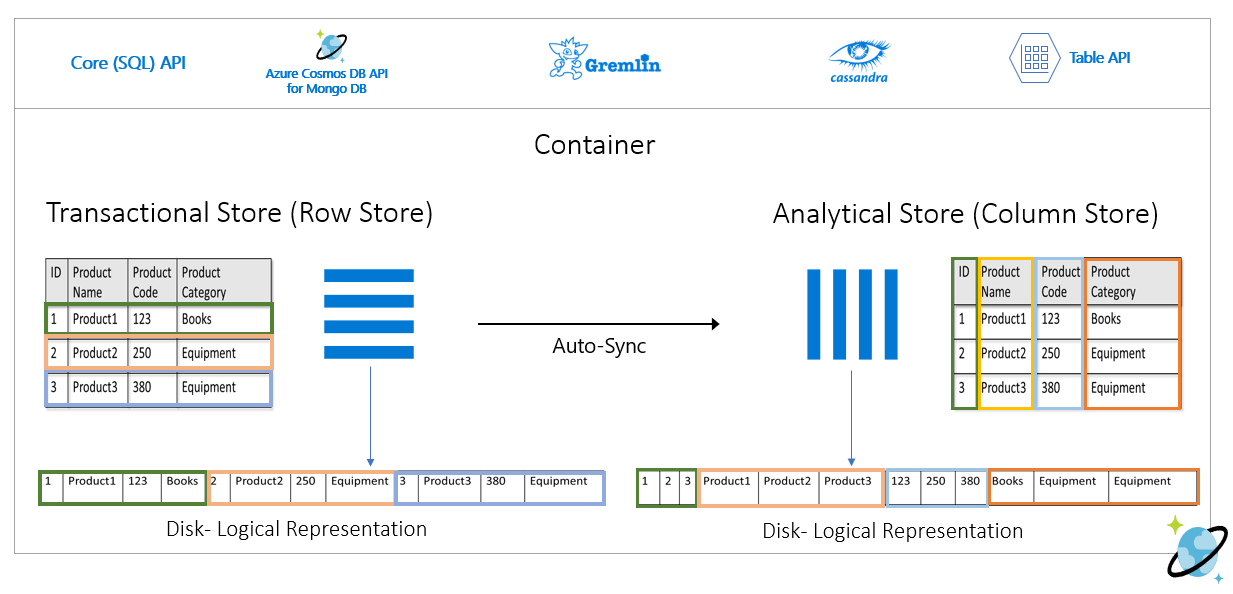
분석 워크로드를 위한 분리된 성능
분석 저장소는 트랜잭션 저장소와 별개이므로 분석 쿼리가 트랜잭션 워크로드의 성능에 영향을 주지 않습니다. 분석 저장소에는 별도의 RU(요청 단위)를 할당할 필요가 없습니다.
자동 동기화
자동 동기화는 작동 데이터의 삽입, 업데이트 및 삭제가 거의 실시간으로 트랜잭션 저장소에서 분석 저장소로 자동 동기화되는 Microsoft Azure Cosmos DB의 완전 관리형 기능입니다. 자동 동기화 대기 시간은 일반적으로 2분 이내입니다. 컨테이너가 많은 공유 처리량 데이터베이스의 경우 개별 컨테이너의 자동 동기화 대기 시간이 더 길어질 수 있으며 최대 5분이 걸릴 수 있습니다.
자동 동기화 프로세스 실행이 끝날 때마다 Azure Synapse Analytics 런타임에서 트랜잭션 데이터를 즉시 사용할 수 있습니다.
Azure Synapse Analytics Spark 풀은 항상 데이터의 마지막 상태를 읽는
spark.read명령을 통해 또는 자동으로 업데이트되는 Spark 테이블을 사용하여 최근 업데이트를 비롯한 모든 데이터를 읽을 수 있습니다.Azure Synapse Analytics SQL 서버리스 풀은 항상 데이터의 최신 상태를 읽는
SELECT및OPENROWSET명령을 통해 또는 자동으로 업데이트되는 뷰를 사용하여 최근 업데이트를 비롯한 모든 데이터를 읽을 수 있습니다.
참고 항목
트랜잭션 TTL(time-to-live)이 2분 미만인 경우에도 트랜잭션 데이터는 분석 저장소에 동기화됩니다.
참고 항목
컨테이너를 삭제하면 분석 저장소도 삭제됩니다.
확장성 및 탄력성
Microsoft Azure Cosmos DB 트랜잭션 저장소는 행 분할을 사용하여 가동 중지 시간 없이 스토리지와 처리량을 탄력적으로 스케일링할 수 있습니다. 트랜잭션 저장소의 행 분할은 자동 동기화의 확장성과 탄력성을 제공하여 데이터가 분석 저장소에 거의 실시간으로 동기화되도록 합니다. 데이터 동기화는 트랜잭션 트래픽 처리량이 초당 1,000개 작업인지 아니면 초당 100만개 작업인지와 관계없이 수행되며, 트랜잭션 저장소의 프로비전된 처리량에 영향을 주지 않습니다.
스키마 업데이트 자동 처리
Microsoft Azure Cosmos DB 트랜잭션 저장소는 스키마에 구애받지 않으며 스키마나 인덱스 관리를 처리할 필요 없이 트랜잭션 애플리케이션을 반복할 수 있습니다. 이와 달리 Microsoft Azure Cosmos DB 분석 저장소는 분석 쿼리 성능을 최적화하도록 스키마화됩니다. 자동 동기화 기능을 통해 Azure Cosmos DB는 트랜잭션 저장소의 최신 업데이트에 대한 스키마 유추를 관리합니다. 또한 중첩된 데이터 형식 처리를 포함하여 기본적으로 분석 저장소에서 스키마 표현을 관리합니다.
스키마가 진화하고 시간이 지남에 따라 새 속성이 추가되면 분석 저장소는 트랜잭션 저장소의 모든 기록 스키마에서 통합된 스키마를 자동으로 표시합니다.
참고 항목
분석 저장소 컨텍스트에서는 다음 구조를 속성으로 간주합니다.
- JSON “요소” 또는 “
:으로 구분된 문자열-값 쌍” {및}로 구분된 JSON 개체[및]로 구분된 JSON 배열
스키마 제약 조건
다음 제약 조건은 분석 저장소가 스키마를 자동으로 유추하고 올바르게 표현하도록 설정할 때 Azure Cosmos DB의 작동 데이터에 적용됩니다.
문서 스키마의 모든 중첩 수준에서 최대 1,000개의 속성을 사용할 수 있으며 최대 중첩 깊이는 127입니다.
- 처음 1000개의 속성만 분석 저장소에 표시됩니다.
- 처음 127개의 중첩된 수준만 분석 저장소에 표시됩니다.
- JSON 문서의 첫 번째 수준은
/루트 수준입니다. - 문서의 첫 번째 수준에 있는 속성은 열로 표시됩니다.
샘플 시나리오:
- 문서의 첫 번째 수준에 2000개의 속성이 있는 경우 동기화 프로세스는 처음 1000개 속성을 나타냅니다.
- 문서에 5개 수준이 있고 각 수준에 각각 200개의 속성이 있는 경우 동기화 프로세스는 모든 속성을 나타냅니다.
- 문서에 10개 수준이 있고 각 수준에 각각 400개의 속성이 있는 경우 동기화 프로세스는 처음 2개 수준과 세 번째 수준의 절반만 완전히 표시합니다.
아래의 가상 문서에는 4개의 속성과 3개의 수준이 있습니다.
- 수준은
root,myArray,myArray내의 중첩 구조입니다. - 속성은
id,myArray,myArray.nested1및myArray.nested2입니다. - 분석 저장소 표현에는
id와myArray라는 2개의 열이 있습니다. Spark 또는 T-SQL 함수를 사용하여 중첩 구조를 열로 노출할 수도 있습니다.
- 수준은
{
"id": "1",
"myArray": [
"string1",
"string2",
{
"nested1": "abc",
"nested2": "cde"
}
]
}
JSON 문서(및 Azure Cosmos DB 컬렉션/컨테이너)는 고유성 관점에서 대/소문자를 구분하지만, 분석 저장소는 그렇지 않습니다.
- 동일한 문서에서: 동일한 수준의 속성 이름은 대/소문자를 구분하지 않고 비교할 때 고유해야 합니다. 예를 들어 다음 JSON 문서는 동일한 수준에 "Name"과 "name"이 있습니다. 유효한 JSON 문서이지만 고유성 제약 조건을 충족하지 않으므로 분석 저장소에 완전히 표시되지 않습니다. 이 예에서 "Name"과 "name"은 대/소문자를 구분하지 않고 비교할 때 동일합니다.
"Name": "fred"가 첫 번째 발생 항목이므로 이 항목만 분석 저장소에 표시됩니다. 그리고"name": "john"은 전혀 표시되지 않습니다.
{"id": 1, "Name": "fred", "name": "john"}- 다른 문서에서: 동일한 수준에 있고 이름은 같지만 대/소문자가 다른 속성은 첫 번째 발생 항목의 이름 형식을 사용하여 동일한 열에 표시됩니다. 예를 들어 다음 JSON 문서는 동일한 수준에
"Name"및"name"이 있습니다. 첫 번째 문서 형식은"Name"이므로 분석 저장소에서 이 속성 이름을 나타내는 데 사용됩니다. 즉, 분석 저장소의 열 이름은"Name"입니다."fred"및"john"모두"Name"열에 표시됩니다.
{"id": 1, "Name": "fred"} {"id": 2, "name": "john"}- 동일한 문서에서: 동일한 수준의 속성 이름은 대/소문자를 구분하지 않고 비교할 때 고유해야 합니다. 예를 들어 다음 JSON 문서는 동일한 수준에 "Name"과 "name"이 있습니다. 유효한 JSON 문서이지만 고유성 제약 조건을 충족하지 않으므로 분석 저장소에 완전히 표시되지 않습니다. 이 예에서 "Name"과 "name"은 대/소문자를 구분하지 않고 비교할 때 동일합니다.
컬렉션의 첫 번째 문서는 초기 분석 저장소 스키마를 정의합니다.
- 초기 스키마보다 속성이 더 많은 문서는 분석 저장소에 새 열을 생성합니다.
- 열은 제거할 수 없습니다.
- 컬렉션의 모든 문서를 삭제해도 분석 저장소 스키마가 다시 설정되지는 않습니다.
- 스키마 버전 관리가 없습니다. 트랜잭션 저장소에서 유추된 마지막 버전이 분석 저장소에 표시되는 것입니다.
현재 Azure Synapse Spark는 아래에 나열된 일부 특수 문자가 이름에 포함된 속성을 읽을 수 없습니다. Azure Synapse SQL 서버리스는 영향을 받지 않습니다.
- :
- `
- ,
- ;
- {}
- ()
- \n
- \t
- =
- "
참고 항목
이 제한에 도달하면 반환되는 Spark 오류 메시지에도 공백이 나열됩니다. 그러나 공백에 대한 특별한 처리가 추가되었습니다. 자세한 내용은 아래 항목을 확인하세요.
- 위에 나열된 문자를 사용하는 속성 이름이 있는 경우 대안은 다음과 같습니다.
- 이러한 문자를 방지하려면 데이터 모델을 미리 변경합니다.
- 현재 스키마 재설정을 지원하지 않으므로 이러한 문자를 사용하지 않고 유사한 이름을 사용하는 중복 속성을 추가하도록 애플리케이션을 변경할 수 있습니다.
- 변경 피드를 사용하여 속성 이름에 이러한 문자가 없는 컨테이너의 구체화된 보기를 만듭니다.
dropColumnSpark 옵션을 사용하여 영향을 받는 열을 무시하고 다른 모든 열을 DataFrame에 로드합니다. 구문은 다음과 같습니다.
# Removing one column:
df = spark.read\
.format("cosmos.olap")\
.option("spark.synapse.linkedService","<your-linked-service-name>")\
.option("spark.synapse.container","<your-container-name>")\
.option("spark.cosmos.dropColumn","FirstName,LastName")\
.load()
# Removing multiple columns:
df = spark.read\
.format("cosmos.olap")\
.option("spark.synapse.linkedService","<your-linked-service-name>")\
.option("spark.synapse.container","<your-container-name>")\
.option("spark.cosmos.dropColumn","FirstName,LastName;StreetName,StreetNumber")\
.option("spark.cosmos.dropMultiColumnSeparator", ";")\
.load()
- Azure Synapse Spark는 이제 이름에 공백이 있는 속성을 지원합니다. 이를 위해
allowWhiteSpaceInFieldNamesSpark 옵션을 사용하여 영향을 받는 열을 DataFrame에 로드하고 원래 이름을 유지해야 합니다. 구문은 다음과 같습니다.
df = spark.read\
.format("cosmos.olap")\
.option("spark.synapse.linkedService","<your-linked-service-name>")\
.option("spark.synapse.container","<your-container-name>")\
.option("spark.cosmos.allowWhiteSpaceInFieldNames", "true")\
.load()
다음 BSON 데이터 형식은 지원되지 않으며 분석 저장소에 표시되지 않습니다.
- Decimal128
- 정규식
- DB 포인터
- JavaScript
- 기호
- MinKey/MaxKey
ISO 8601 UTC 표준을 따르는 DateTime 문자열을 사용하는 경우 다음 동작이 필요합니다.
- Azure Synapse의 Spark 풀은 이러한 열을
string으로 표현합니다. - Azure Synapse의 SQL 서버리스 풀은 이러한 열을
varchar(8000)로 표현합니다.
- Azure Synapse의 Spark 풀은 이러한 열을
UNIQUEIDENTIFIER (guid)형식의 속성은 분석 저장소에서string으로 표시되며 올바른 시각화를 위해 SQL의VARCHAR또는 Spark의string으로 변환되어야 합니다.Azure Synapse의 SQL 서버리스 풀은 최대 1,000개의 열이 있는 결과 집합을 지원하며, 중첩된 열의 공개도 해당 제한에 계산됩니다. 트랜잭션 데이터 아키텍처 및 모델링에서 이 정보를 감안하는 것이 좋습니다.
속성 이름을 바꾸는 경우 하나 이상의 문서에서 새 열로 간주됩니다. 컬렉션의 모든 문서에서 동일한 이름 바꾸기를 실행하면 모든 데이터가 새 열로 마이그레이션되고 이전 열은
NULL값으로 표시됩니다.
스키마 표현
분석 저장소에는 데이터베이스 계정의 모든 컨테이너에 유효한 두 가지 스키마 표현 방법이 있습니다. 이러한 두 가지 방법은 쿼리 환경의 단순성과 다형성 스키마의 열 표현 포괄성 간에 장단점이 있습니다.
- 잘 정의된 스키마 표현(API for NoSQL 및 API for Gremlin 계정의 기본 옵션)
- 전체 충실도 스키마 표현(API for MongoDB 계정의 기본 옵션)
올바르게 정의된 스키마 표시
잘 정의된 스키마 표시는 트랜잭션 저장소에서 스키마와 관계없는 데이터의 간단한 테이블 형식 표시를 만듭니다. 잘 정의된 스키마 표시의 고려 사항은 다음과 같습니다.
- 첫 번째 문서는 기본 스키마를 정의하며, 속성은 항상 모든 문서에서 동일한 형식이어야 합니다. 유일한 예외는 다음과 같습니다.
NULL에서 다른 데이터 형식으로 변경. 첫 번째 null이 아닌 발생 항목은 열 데이터 형식을 정의합니다. 첫 번째 null이 아닌 데이터 형식을 따르지 않는 문서는 분석 저장소에 표시되지 않습니다.float~integer입니다. 모든 문서는 분석 저장소에 표시됩니다.integer~float입니다. 모든 문서는 분석 저장소에 표시됩니다. 그러나 Azure Synapse SQL 서버리스 풀에서 이 데이터를 읽으려면 WITH 절을 사용하여 열을varchar로 변환해야 합니다. 그리고 이 초기 변환 후에 다시 숫자로 변환할 수 있습니다. num 초기 값이 정수이고 두 번째 값이 float인 아래 예제를 확인하세요.
SELECT CAST (num as float) as num
FROM OPENROWSET(PROVIDER = 'CosmosDB',
CONNECTION = '<your-connection',
OBJECT = 'IntToFloat',
SERVER_CREDENTIAL = 'your-credential'
)
WITH (num varchar(100)) AS [IntToFloat]
기본 스키마 데이터 형식을 따르지 않는 속성은 분석 저장소에 표시되지 않습니다. 예를 들어 아래의 두 문서를 고려해 보세요. 첫 번째 문서는 분석 저장소 기본 스키마를 정의합니다.
id가"2"인 두 번째 문서에는"code"속성이 문자열이고 첫 번째 문서에"code"가 숫자로 있으므로 잘 정의된 스키마가 없습니다. 이 경우 분석 저장소는 컨테이너 수명 동안"code"의 데이터 형식을integer로 등록합니다. 두 번째 문서는 분석 저장소에 계속 포함되지만 해당"code"속성은 포함되지 않습니다.{"id": "1", "code":123}{"id": "2", "code": "123"}
참고 항목
위의 조건은 NULL 속성에 적용되지 않습니다. 예를 들어, {"a":123} and {"a":NULL}은 여전히 잘 정의되어 있습니다.
참고 항목
"1" 문서의 "code"를 트랜잭션 저장소의 문자열로 업데이트하는 경우 위의 조건은 변경되지 않습니다. 현재 스키마 재설정을 지원하지 않으므로 분석 저장소에서 "code"는 integer로 유지됩니다.
- 배열 형식에는 단일 형식이 반복되어 포함되어야 합니다. 예를 들어 배열에 정수 형식과 문자열 형식이 혼합되어 있으므로
{"a": ["str",12]}는 잘 정의된 스키마가 아닙니다.
참고 항목
Azure Cosmos DB 분석 저장소에서 잘 정의된 스키마 표현을 따르고 특정 항목이 위의 사양을 위반하는 경우 해당 항목은 분석 저장소에 포함되지 않습니다.
잘 정의된 스키마의 다른 유형과 관련하여 다른 동작이 필요합니다.
- Azure Synapse의 Spark 풀은 이러한 값을
undefined로 표현합니다. - Azure Synapse의 SQL 서버리스 풀은 이러한 값을
NULL로 표현합니다.
- Azure Synapse의 Spark 풀은 이러한 값을
명시적
NULL값과 관련하여 다른 동작이 발생합니다.- Azure Synapse의 Spark 풀은 이러한 값을
0(0)으로 읽고, 열에 null이 아닌 값이 있는 즉시undefined로 읽습니다. - Azure Synapse의 SQL 서버리스 풀은 이러한 값을
NULL로 읽습니다.
- Azure Synapse의 Spark 풀은 이러한 값을
누락된 열과 관련하여 다른 동작이 발생합니다.
- Azure Synapse의 Spark 풀은 이러한 열을
undefined으로 표현합니다. - Azure Synapse의 SQL 서버리스 풀은 이러한 열을
NULL로 표현합니다.
- Azure Synapse의 Spark 풀은 이러한 열을
표현 과제 해결 방법
스키마가 잘못된 이전 문서가 컨테이너의 분석 저장소 기본 스키마를 만드는 데 사용되었을 수 있습니다. 위에 설명된 모든 규칙에 따라 Azure Synapse Link를 사용하여 분석 저장소를 쿼리할 때 특정 속성에 대해 NULL을 수신할 수도 있습니다. 기본 스키마 초기화는 현재 지원되지 않으므로 문제가 있는 문서를 삭제하거나 업데이트하는 것은 도움이 되지 않습니다. 가능한 해결 방법은 다음과 같습니다.
- 데이터를 새 컨테이너로 마이그레이션하고, 모든 문서의 스키마가 올바른지 확인합니다.
- 스키마가 잘못된 속성을 포기하고, 모든 문서에서 스키마가 올바른 새 속성을 다른 이름으로 추가합니다. 예: Orders 컨테이너에 status 속성이 문자열인 문서가 수십억 개 있습니다. 그러나 이 컨테이너의 첫 번째 문서는 status가 정수로 정의되어 있습니다. 따라서 한 문서는 status가 올바르게 표현되고 나머지 문서는
NULL값을 갖게 됩니다. 모든 문서에 status2 속성을 추가하고, 원래 속성 대신 이 속성을 사용할 수 있습니다.
전체 충실도 스키마 표시
전체 충실도 스키마 표시는 스키마와 관계없는 작동 데이터에서 전체 다형성 스키마를 처리하도록 설계되었습니다. 이 스키마 표시에서는 잘 정의된 스키마 제약 조건(혼합 데이터 형식 필드도 혼합 데이터 형식 배열도 아님)을 위반하더라도 분석 저장소에서 항목이 삭제되지 않습니다.
이 작업은 운영 데이터의 리프 속성을 분석 저장소에 JSON key-value 쌍으로 변환하여 수행됩니다. 여기서 데이터 형식은 key이고 속성 콘텐츠는 value입니다. 이 JSON 개체 표현은 모호하지 않은 쿼리를 허용하며, 각 데이터 형식을 개별적으로 분석할 수 있습니다.
다시 말해서, 전체 충실도 스키마 표현에서 각 문서의 각 속성의 각 데이터 형식은 해당 속성에 대한 JSON 개체에 key-value 쌍을 생성합니다. 각 속성은 최대 속성 수 제한인 1,000개 중 하나로 계산됩니다.
예를 들어 트랜잭션 저장소에 있는 다음 샘플 문서를 살펴보겠습니다.
{
name: "John Doe",
age: 32,
profession: "Doctor",
address: {
streetNo: 15850,
streetName: "NE 40th St.",
zip: 98052
},
salary: 1000000
}
중첩된 개체 address는 문서 루트 수준의 속성이며 열로 표현됩니다. address 개체의 각 리프 속성은 JSON 개체 {"object":{"streetNo":{"int32":15850},"streetName":{"string":"NE 40th St."},"zip":{"int32":98052}}}로 표현됩니다.
잘 정의된 스키마 표현과 달리 전체 충실도 메서드는 데이터 형식의 변형을 허용합니다. 위 예제 컬렉션의 다음 문서에서 streetNo가 문자열로 있으면 분석 저장소에 "streetNo":{"string":15850}으로 표현됩니다. 잘 정의된 스키마 메서드에서는 표현되지 않습니다.
전체 충실도 스키마의 데이터 형식 맵
다음은 분석 저장소에 있는 MongoDB 데이터 형식 및 해당 표현의 맵을 전체 충실도 스키마 표현으로 나타낸 것입니다. 아래 맵은 NoSQL API 계정에는 유효하지 않습니다.
| 원래 데이터 형식 | 접미사 | 예제 |
|---|---|---|
| Double | ".float64" | 24.99 |
| Array | ".array" | ["a", "b"] |
| 이진 | ".binary" | 0 |
| 부울 | ".bool" | True |
| Int32 | ".int32" | 123 |
| Int64 | ".int64" | 255486129307 |
| NULL | ".NULL" | NULL |
| 문자열 | ".string" | "ABC" |
| 타임스탬프 | ".timestamp" | Timestamp(0, 0) |
| ObjectId | ".objectId" | ObjectId("5f3f7b59330ec25c132623a2") |
| 문서 | ".object" | {"a": "a"} |
명시적
NULL값과 관련하여 다른 동작이 발생합니다.- Azure Synapse의 Spark 풀은 이러한 값을
0(영)으로 읽습니다. - Azure Synapse의 SQL 서버리스 풀은 해당 값을
NULL로 읽습니다.
- Azure Synapse의 Spark 풀은 이러한 값을
누락된 열과 관련하여 다른 동작이 발생합니다.
- Azure Synapse의 Spark 풀은 이러한 열을
undefined로 나타냅니다. - Azure Synapse의 SQL 서버리스 풀은 이러한 열을
NULL로 나타냅니다.
- Azure Synapse의 Spark 풀은 이러한 열을
timestamp값과 관련하여 다른 동작이 발생합니다.- Azure Synapse의 Spark 풀은 이러한 값을
TimestampType,DateType또는Float로 읽습니다. 범위와 타임스탬프가 생성된 방식에 따라 읽는 방법이 달라집니다. - Azure Synapse의 SQL 서버리스 풀은 이러한 값을
DATETIME2로 읽으며, 범위는0001-01-01에서9999-12-31까지입니다. 이 범위를 벗어나는 값은 지원되지 않으며 쿼리 실행 오류를 유발합니다. 이 경우 다음과 같은 조치를 취할 수 있습니다.- 쿼리의 열을 제거합니다. 표현을 유지하려면 지원되는 범위 내에서 해당 열을 미러링하는 새 속성을 만들면 됩니다. 그리고 해당 속성을 쿼리에 사용합니다.
- RU 비용 없이 분석 저장소에서 변경 데이터 캡처를 사용하여 지원되는 싱크 중 하나에서 데이터를 새 형식으로 변환하고 로드합니다.
- Azure Synapse의 Spark 풀은 이러한 값을
Spark에서 전체 충실도 스키마 사용
Spark는 DataFrame에 로드할 때 각 데이터 형식을 열로 관리합니다. 아래 문서가 있는 컬렉션이 하나 있다고 가정하겠습니다.
{
"_id" : "1" ,
"item" : "Pizza",
"price" : 3.49,
"rating" : 3,
"timestamp" : 1604021952.6790195
},
{
"_id" : "2" ,
"item" : "Ice Cream",
"price" : 1.59,
"rating" : "4" ,
"timestamp" : "2022-11-11 10:00 AM"
}
첫 번째 문서에서는 rating이 숫자, timestamp가 utc 형식이지만 두 번째 문서에서는 rating과 timestamp가 문자열입니다. 이 컬렉션이 데이터 변환 없이 DataFrame에 로드될 경우 df.printSchema()의 출력은 다음과 같습니다.
root
|-- _rid: string (nullable = true)
|-- _ts: long (nullable = true)
|-- id: string (nullable = true)
|-- _etag: string (nullable = true)
|-- _id: struct (nullable = true)
| |-- objectId: string (nullable = true)
|-- item: struct (nullable = true)
| |-- string: string (nullable = true)
|-- price: struct (nullable = true)
| |-- float64: double (nullable = true)
|-- rating: struct (nullable = true)
| |-- int32: integer (nullable = true)
| |-- string: string (nullable = true)
|-- timestamp: struct (nullable = true)
| |-- float64: double (nullable = true)
| |-- string: string (nullable = true)
|-- _partitionKey: struct (nullable = true)
| |-- string: string (nullable = true)
잘 정의된 스키마 표현에서는 두 번째 문서의 rating과 timestamp 둘 다 표현되지 않습니다. 전체 충실도 스키마에서는 다음 예제를 사용하여 각 데이터 형식의 각 값에 개별적으로 액세스할 수 있습니다.
아래 예제에서는 PySpark를 사용하여 집계를 실행할 수 있습니다.
df.groupBy(df.item.string).sum().show()
아래 예제에서는 PySQL을 사용하여 또 다른 집계를 실행할 수 있습니다.
df.createOrReplaceTempView("Pizza")
sql_results = spark.sql("SELECT sum(price.float64),count(*) FROM Pizza where timestamp.string is not null and item.string = 'Pizza'")
sql_results.show()
SQL에서 전체 충실도 스키마 사용
위 예제와 동일한 Spark 문서라고 가정할 때, 고객은 다음 구문 예제를 사용할 수 있습니다.
SELECT rating,timestamp_string,timestamp_utc
FROM OPENROWSET(PROVIDER = 'CosmosDB',
CONNECTION = 'Account=<your-database-account-name';Database=<your-database-name>',
OBJECT = '<your-collection-name>',
SERVER_CREDENTIAL = '<your-synapse-sql-server-credential-name>')
WITH (
rating integer '$.rating.int32',
timestamp varchar(50) '$.timestamp.string',
timestamp_utc float '$.timestamp.float64'
) as HTAP
WHERE timestamp is not null or timestamp_utc is not null
위의 쿼리부터 고객은 cast, convert 또는 다른 T-SQL 함수로 변환을 구현하여 데이터를 조작할 수 있습니다. 또한 고객은 보기를 사용하여 복잡한 데이터 형식 구조를 숨길 수 있습니다.
create view MyView as
SELECT MyRating=rating,MyTimestamp = convert(varchar(50),timestamp_utc)
FROM OPENROWSET(PROVIDER = 'CosmosDB',
CONNECTION = 'Account=<your-database-account-name';Database=<your-database-name>',
OBJECT = '<your-collection-name>',
SERVER_CREDENTIAL = '<your-synapse-sql-server-credential-name>')
WITH (
rating integer '$.rating.int32',
timestamp_utc float '$.timestamp.float64'
) as HTAP
WHERE timestamp_utc is not null
union all
SELECT MyRating=convert(integer,rating_string),MyTimestamp = timestamp_string
FROM OPENROWSET(PROVIDER = 'CosmosDB',
CONNECTION = 'Account=<your-database-account-name';Database=<your-database-name>',
OBJECT = '<your-collection-name>',
SERVER_CREDENTIAL = '<your-synapse-sql-server-credential-name>')
WITH (
rating_string varchar(50) '$.rating.string',
timestamp_string varchar(50) '$.timestamp.string'
) as HTAP
WHERE timestamp_string is not null
MongoDB _id 필드 작업
MongoDB _id 필드는 MongoDB의 모든 컬렉션에 기본이며 원래 16진수 표현을 사용합니다. 위의 표에서 볼 수 있듯이, 전체 충실도 스키마는 특징을 유지하므로 Azure Synapse Analytics에서 시각화하려면 해결할 부분이 있습니다. 올바른 시각화를 위해 다음과 같이 _id 데이터 형식을 변환해야 합니다.
Spark에서 MongoDB _id 필드 작업
아래 예제는 Spark 2.x 및 3.x 버전에서 작동합니다.
val df = spark.read.format("cosmos.olap").option("spark.synapse.linkedService", "xxxx").option("spark.cosmos.container", "xxxx").load()
val convertObjectId = udf((bytes: Array[Byte]) => {
val builder = new StringBuilder
for (b <- bytes) {
builder.append(String.format("%02x", Byte.box(b)))
}
builder.toString
}
)
val dfConverted = df.withColumn("objectId", col("_id.objectId")).withColumn("convertedObjectId", convertObjectId(col("_id.objectId"))).select("id", "objectId", "convertedObjectId")
display(dfConverted)
SQL에서 MongoDB _id 필드 작업
SELECT TOP 100 id=CAST(_id as VARBINARY(1000))
FROM OPENROWSET('CosmosDB',
'Your-account;Database=your-database;Key=your-key',
HTAP) WITH (_id VARCHAR(1000)) as HTAP
API for NoSQL 또는 API for Gremlin 계정의 전체 충실도 스키마
Azure Cosmos DB 계정에서 처음으로 Synapse Link를 사용하도록 설정할 때 스키마 유형을 설정하면 기본 옵션 대신 전체 충실도 스키마를 API for NoSQL 계정에 사용할 수 있습니다. 기본 스키마 표현 형식 변경에 대한 고려 사항은 다음과 같습니다.
- 현재 Azure Portal을 사용하여 NoSQL API 계정에서 Synapse Link를 사용하도록 설정하면 Synapse Link는 잘 정의된 스키마로 사용하도록 설정됩니다.
- 현재 NoSQL 또는 Gremlin API 계정에서 전체 충실도 스키마를 사용하려면 계정 수준에서 Synapse Link를 사용하도록 설정하는 동일한 CLI 또는 PowerShell 명령을 통해 설정해야 합니다.
- 현재 Azure Cosmos DB for MongoDB는 스키마 표현을 변경하는 이 방법을 지원하지 않습니다. 모든 MongoDB 계정에는 전체 충실도 스키마 표현 형식이 있습니다.
- 위에서 언급한 전체 충실도 스키마 데이터 형식 맵은 JSON 데이터 형식을 사용하는 NoSQL API 계정에는 유효하지 않습니다. 예를 들어
float및integer값은 분석 저장소에서num으로 표현됩니다. - 스키마 표현 형식을 잘 정의된 스키마에서 전체 충실도 스키마로 또는 그 반대로 다시 설정할 수 없습니다.
- 현재 분석 저장소의 컨테이너 스키마는 컨테이너를 만들 때 정의되며, 데이터베이스 계정에서 Synapse Link를 사용하도록 설정하지 않은 경우에도 마찬가지입니다.
- 계정 수준에서 전체 충실도 스키마를 사용하여 Synapse Link를 사용하도록 설정하기 전에 만든 컨테이너 또는 그래프는 잘 정의된 스키마를 사용하게 됩니다.
- 계정 수준에서 전체 충실도 스키마를 사용하여 Synapse Link를 사용하도록 설정한 이후에 만든 컨테이너 또는 그래프는 전체 충실도 스키마를 사용하게 됩니다.
Azure CLI 또는 PowerShell을 사용하여 계정에서 Synapse Link를 사용하도록 설정하는 동시에 스키마 표현 형식을 결정해야 합니다.
Azure CLI 사용:
az cosmosdb create --name MyCosmosDBDatabaseAccount --resource-group MyResourceGroup --subscription MySubscription --analytical-storage-schema-type "FullFidelity" --enable-analytical-storage true
참고 항목
위의 명령에서 기존 계정에 대해 create를 update로 바꿉니다.
PowerShell 사용:
New-AzCosmosDBAccount -ResourceGroupName MyResourceGroup -Name MyCosmosDBDatabaseAccount -EnableAnalyticalStorage true -AnalyticalStorageSchemaType "FullFidelity"
참고 항목
위의 명령에서 기존 계정에 대해 New-AzCosmosDBAccount를 Update-AzCosmosDBAccount로 바꿉니다.
분석 TTL(Time-to-Live)
ATTL(분석 TTL)은 컨테이너에 대해 데이터를 분석 저장소에 보존해야 하는 기간을 나타냅니다.
ATTL이 NULL 및 0 이외의 값으로 설정되면 분석 저장소가 사용하도록 설정됩니다. 사용하도록 설정되면 TTTL(트랜잭션 TTL) 구성과 관계없이 작동 데이터에 대한 삽입, 업데이트, 삭제가 트랜잭션 저장소에서 분석 저장소로 자동으로 동기화됩니다. 분석 저장소에서 이 트랜잭션 데이터를 보존하는 것은 AnalyticalStoreTimeToLiveInSeconds 속성을 통해 컨테이너 수준에서 제어할 수 있습니다.
가능한 ATTL 구성은 다음과 같습니다.
값이
0로 설정되거나NULL로 설정되면 분석 저장소가 사용하지 않도록 설정되고 데이터가 트랜잭션 저장소에서 분석 저장소로 복제되지 않습니다.값이
-1로 설정되면 트랜잭션 저장소의 데이터 보존과 관계없이 분석 저장소에서 모든 기록 데이터가 보존됩니다. 이 설정은 분석 저장소에 작동 데이터가 무기한으로 보존됨을 나타냅니다.값이 양의 정수
n으로 설정되면 항목이 트랜잭션 저장소에서 마지막으로 수정된 시간n초 후에 분석 저장소에서 만료됩니다. 트랜잭션 저장소의 데이터 보존과 관계없이 제한된 기간 동안 분석 저장소에 작동 데이터를 보존하려는 경우에 이 설정을 활용할 수 있습니다.
몇 가지 고려할 점은 다음과 같습니다.
- ATTL 값을 사용하여 분석 저장소가 사용하도록 설정되면 나중에 다른 유효한 값을 사용하여 업데이트할 수 있습니다.
- TTTL은 컨테이너 또는 항목 수준에서 설정할 수 있지만 ATTL은 현재 컨테이너 수준에서만 설정할 수 있습니다.
- 컨테이너 수준에서 ATTL >= TTTL을 설정하여 분석 저장소에서 작동 데이터를 더 오래 보존할 수 있습니다.
- ATTL = TTTL을 설정하여 트랜잭션 저장소를 미러링하도록 분석 저장소를 만들 수 있습니다.
- TTTL보다 큰 ATTL이 있는 경우 특정 시점에서 분석 저장소에만 있는 데이터를 갖게 됩니다. 이 데이터는 읽기 전용입니다.
- 현재 Microsoft는 분석 저장소의 데이터를 삭제하지 않습니다. ATTL을 양의 정수로 설정하면 데이터가 쿼리에 포함되지 않으므로 요금이 청구되지 않습니다. 하지만 ATTL을 다시
-1로 변경하면 모든 데이터가 다시 표시되고, 모든 데이터 볼륨에 대한 요금이 청구되기 시작합니다.
컨테이너에서 분석 저장소를 사용하도록 설정하는 방법은 다음과 같습니다.
Azure Portal에서 ATTL 옵션을 켜져 있으면 기본값인 -1로 설정됩니다. Data Explorer 아래의 컨테이너 설정으로 이동하여 이 값을 'n'초로 변경할 수 있습니다.
Azure Management SDK, Azure Cosmos DB SDK, PowerShell 또는 Azure CLI에서 ATTL 옵션을 -1 또는 'n'초로 설정하여 이 옵션을 사용하도록 설정할 수 있습니다.
자세한 내용은 컨테이너에 분석 TTL을 구성하는 방법을 참조하세요
기록 데이터에 대한 비용 효율적인 분석
데이터 계층화는 서로 다른 시나리오에 최적화된 스토리지 인프라 간에 데이터를 분리하는 것을 말합니다. 그러면 엔드투엔드 데이터 스택의 전반적인 성능과 비용 효율성이 향상됩니다. Microsoft Azure Cosmos DB는 이제 분석 저장소를 사용하여 다른 데이터 레이아웃을 가진 트랜잭션 저장소에서 분석 저장소로의 데이터 자동 계층화를 지원합니다. 트랜잭션 저장소와 비교하여 스토리지 비용 측면에서 최적화된 분석 저장소를 사용하면 기록 분석을 위해 훨씬 더 긴 기간의 작동 데이터를 보존할 수 있습니다.
분석 저장소가 사용하도록 설정된 후 트랜잭션 워크로드의 데이터 보존 요구 사항에 따라 특정 기간 후에 트랜잭션 저장소에서 레코드가 자동으로 삭제되도록 transactional TTL 속성을 구성할 수 있습니다. 마찬가지로 analytical TTL을 사용하면 트랜잭션 저장소와 별개로 분석 저장소에 보존된 데이터의 수명 주기를 관리할 수 있습니다. 분석 저장소를 사용하도록 설정하고 트랜잭션 및 분석 TTL 속성을 구성하여 두 저장소의 데이터 보존 기간을 원활하게 계층화하고 정의할 수 있습니다.
참고 항목
analytical TTL이 transactional TTL보다 크면 컨테이너에는 분석 저장소에만 존재하는 데이터가 있습니다. 이 데이터는 읽기 전용이며 현재 분석 저장소에서 문서 수준 TTL을 지원하지 않습니다. 컨테이너 데이터가 향후의 특정 시점에서 업데이트 또는 삭제가 필요할 수 있는 경우 transactional TTL보다 큰 analytical TTL을 사용하지 마세요. 이 기능은 향후 업데이트나 삭제가 필요하지 않은 데이터에 권장됩니다.
참고 항목
시나리오에서 실제 삭제를 요구하지 않는 경우 논리적 삭제/업데이트 방법을 채택할 수 있습니다. 분석 저장소에만 존재하지만 논리적 삭제/업데이트가 필요한 동일한 문서의 다른 버전을 트랜잭션 저장소에 삽입합니다. 만료된 문서의 삭제 또는 업데이트임을 나타내는 플래그가 있을 수 있습니다. 동일한 문서의 두 버전이 모두 분석 저장소에 공존하며 애플리케이션은 마지막 버전만 고려해야 합니다.
복원력
분석 스토리지는 Azure Storage에 의존하며 실제 오류에 대해 다음과 같은 보호 기능을 제공합니다.
- 기본적으로 Azure Cosmos DB 데이터베이스 계정은 분석 저장소를 LRS(로컬 중복 스토리지) 계정에 할당합니다. LRS는 지정된 1년 동안 개체에 99.999999999%(11개의 9) 이상의 내구성을 제공합니다.
- 데이터베이스 계정의 지리적 지역이 영역 중복성을 위해 구성된 경우 해당 지리적 지역은 ZRS(영역 중복 스토리지) 계정에 할당됩니다. 고객은 Azure Cosmos DB 데이터베이스 계정의 지역에서 가용성 영역을 사용하도록 설정하여 해당 지역의 분석 데이터를 영역 중복 스토리지에 저장해야 합니다. ZRS는 지정된 연도 동안 스토리지 리소스에 대한 99.9999999999%(12개의 9) 이상의 내구성을 제공합니다.
Azure Storage 내구성에 대한 자세한 내용을 보려면 여기를 클릭하세요.
Backup
분석 저장소에는 실제 오류에 대한 기본 제공 보호 기능이 있지만 트랜잭션 저장소에서 실수로 삭제하거나 업데이트하는 경우 백업이 필요할 수 있습니다. 이러한 경우 컨테이너를 복원하고 복원된 컨테이너를 사용하여 원래 컨테이너의 데이터를 백필하거나 필요한 경우 분석 저장소를 완전히 다시 빌드할 수 있습니다.
참고 항목
현재 분석 저장소는 백업되지 않으므로 복원할 수 없습니다. 분석 저장소를 사용하여 백업 정책을 계획할 수 없습니다.
결과적으로 Synapse Link 및 분석 저장소는 Azure Cosmos DB 백업 모드와의 호환성 수준이 다릅니다.
- 주기적인 백업 모드는 Synapse Link와 완벽하게 호환되며 이 두 가지 기능은 동일한 데이터베이스 계정에서 사용할 수 있습니다.
- 지속적인 백업 모드와 Synapse Link는 동일한 데이터베이스 계정에서 지원됩니다. 현재 컨테이너에서 Synapse Link를 사용하지 않도록 설정한 고객은 지속적인 백업으로 마이그레이션할 수 없습니다.
Backup 정책
두 가지 가능한 백업 정책이 있으며, 백업 정책 사용 방법을 이해하려면 Azure Cosmos DB 백업에 대한 다음 세부 정보가 매우 중요합니다.
- 원본 컨테이너는 두 백업 모드 모두에서 분석 저장소 없이 복원됩니다.
- Azure Cosmos DB는 복원에서 컨테이너 덮어쓰기를 지원하지 않습니다.
이제 분석 저장소 관점에서 백업 및 복원을 사용하는 방법을 살펴보겠습니다.
TTTL >= ATTL로 컨테이너 복원
transactional TTL이 analytical TTL보다 크거나 같으면 분석 저장소의 모든 데이터가 여전히 트랜잭션 저장소에 존재합니다. 복원의 경우 다음 두 가지 상황이 발생할 수 있습니다.
- 복원된 컨테이너를 원래 컨테이너의 대체품으로 사용합니다. 분석 저장소를 다시 빌드하려면 계정 수준 및 컨테이너 수준에서 Synapse Link를 사용하도록 설정하기만 하면 됩니다.
- 복원된 컨테이너를 데이터 원본으로 사용하여 원래 컨테이너의 데이터를 백필하거나 업데이트합니다. 이 경우 분석 저장소는 데이터 작업을 자동으로 반영합니다.
TTTL < ATTL로 컨테이너 복원
transactional TTL이 analytical TTL보다 작은 경우 일부 데이터는 분석 저장소에만 존재하며 복원된 컨테이너에는 포함되지 않습니다. 다시 말씀드리지만, 두 가지 가능한 상황이 있습니다.
- 복원된 컨테이너를 원래 컨테이너의 대체품으로 사용합니다. 이 경우 컨테이너 수준에서 Synapse Link를 사용하도록 설정하면 트랜잭션 저장소에 있던 데이터만 새 분석 저장소에 포함됩니다. 그러나 원래 컨테이너가 존재하는 한 원래 컨테이너의 분석 저장소는 쿼리에 계속 사용할 수 있습니다. 둘 다 쿼리하도록 애플리케이션을 변경할 수 있습니다.
- 복원된 컨테이너를 데이터 원본으로 사용하여 원래 컨테이너의 데이터를 백필하거나 업데이트하려면:
- 분석 저장소는 트랜잭션 저장소에 있는 데이터에 대한 데이터 작업을 자동으로 반영합니다.
- 이전에
transactional TTL로 인해 트랜잭션 저장소에서 제거된 데이터를 다시 삽입하면 이 데이터가 분석 저장소에 복제됩니다.
예시:
OnlineOrders컨테이너에는 TTTL이 1개월로, ATTL이 1년으로 설정되어 있습니다.- 이를
OnlineOrdersNew로 복원하고 분석 저장소를 켜서 다시 빌드하면 1개월의 데이터만 트랜잭션 및 분석 저장소 모두에 있게 됩니다. - 원래의
OnlineOrders컨테이너는 삭제되지 않고 해당 분석 저장소를 계속 사용할 수 있습니다. - 새 데이터는
OnlineOrdersNew로만 수집됩니다. - 분석 쿼리는 원래 데이터가 여전히 관련이 있는 동안 분석 저장소에서 UNION ALL을 수행합니다.
원래 컨테이너를 삭제하지만 분석 저장소 데이터를 잃지 않으려면 원래 컨테이너의 분석 저장소를 다른 Azure 데이터 서비스에 유지하면 됩니다. Synapse Analytics에는 서로 다른 위치에 저장된 데이터 간에 조인을 수행할 수 있는 기능이 있습니다. 예를 들어 Synapse Analytics 쿼리는 분석 저장소 데이터를 Azure Blob Storage, Azure Data Lake Store 등에 있는 외부 테이블과 조인합니다.
분석 저장소의 데이터에는 트랜잭션 저장소에 있는 것과 다른 스키마가 있다는 점에 유의해야 합니다. RU 비용 없이 분석 저장소 데이터의 스냅샷을 생성하고 이를 Azure Data 서비스로 내보낼 수 있지만 이 스냅샷을 사용하여 트랜잭션 저장소를 다시 공급하는 것은 보장할 수 없습니다. 이 프로세스는 지원되지 않습니다.
글로벌 분포
전역적으로 분산된 Microsoft Azure Cosmos DB 계정이 있는 경우 컨테이너에 분석 저장소를 사용하도록 설정하면 해당 계정의 모든 지역에서 이 계정을 사용할 수 있습니다. 작동 데이터의 변경 내용은 모든 지역에서 전역적으로 복제됩니다. Microsoft Azure Cosmos DB에서 데이터의 가장 가까운 지역 복사본을 대상으로 분석 쿼리를 효과적으로 실행할 수 있습니다.
분할
분석 저장소 분할은 트랜잭션 저장소 분할과 전혀 관련이 없습니다. 기본적으로 분석 저장소의 데이터는 분할되지 않습니다. 분석 쿼리에 자주 사용되는 필터가 있는 경우 더 나은 쿼리 성능을 위해 이러한 필드를 기반으로 분할하는 옵션이 있습니다. 자세한 내용은 사용자 지정 분할 소개 및 사용자 지정 분할 구성 방법을 참조하세요.
보안
분석 저장소를 사용한 인증은 지정된 데이터베이스의 트랜잭션 저장소와 동일합니다. 기본, 보조 또는 읽기 전용 키는 인증에 사용할 수 있습니다. Synapse Studio에서 연결된 서비스를 활용하여 Spark 노트북에 Microsoft Azure Cosmos DB 키 붙여넣기를 방지할 수 있습니다. Azure Synapse SQL 서버리스의 경우 SQL 자격 증명을 사용하여 Azure Cosmos DB 키를 SQL Notebook에 붙여넣지 않도록 방지할 수도 있습니다. 이러한 연결된 서비스 또는 이러한 SQL 자격 증명에 대한 액세스는 작업 영역에 대한 액세스 권한이 있는 모든 사용자가 사용할 수 있습니다. Azure Cosmos DB 읽기 전용 키를 사용할 수도 있습니다.
프라이빗 엔드포인트를 사용한 네트워크 격리 - 트랜잭션 및 분석 저장소에 있는 데이터에 대한 네트워크 액세스를 독립적으로 제어할 수 있습니다. 네트워크 격리는 Azure Synapse 작업 영역의 관리형 가상 네트워크 내에서 각 저장소마다 별도의 관리형 프라이빗 엔드포인트를 사용하여 수행됩니다. 자세히 알아보려면 분석 저장소에 대한 프라이빗 엔드포인트 구성 방법에 대한 문서를 참조하세요.
미사용 데이터 암호화 - 분석 저장소 암호화는 기본적으로 사용하도록 설정됩니다.
고객 관리형 키를 통한 데이터 암호화 - 자동화되고 투명한 방식으로 동일한 고객 관리형 키를 사용하여 트랜잭션 및 분석 저장소에서 데이터를 원활하게 암호화할 수 있습니다. Azure Synapse Link는 Azure Cosmos DB 계정의 관리 ID를 사용하여 고객 관리형 키 구성만 지원합니다. 계정에서 Azure Synapse Link를 사용하도록 설정하기 전에 Azure Key Vault 액세스 정책에서 계정의 관리 ID를 구성해야 합니다. 자세한 내용은 Azure Cosmos DB 계정의 관리 ID를 사용하여 고객 관리형 키 구성 문서를 참조하세요.
참고 항목
데이터베이스 계정을 자사 ID에서 시스템 또는 사용자가 할당한 ID로 변경하고 데이터베이스 계정에서 Azure Synapse Link를 사용하도록 설정하면 데이터베이스 계정에서 Synapse Link를 사용하지 않도록 설정할 수 없으므로 자사 ID로 돌아갈 수 없습니다.
여러 Azure Synapse Analytics 런타임 지원
분석 저장소는 컴퓨팅 실행 시간에 종속되지 않고 분석 워크로드에 확장성, 탄력성 및 성능을 제공하도록 최적화되었습니다. 스토리지 기술은 수동 작업 없이 분석 워크로드를 최적화하기 위해 자체 관리됩니다.
분석 컴퓨팅 시스템에서 분석 스토리지 시스템을 분리하면 Azure Synapse Analytics에서 지원하는 여러 분석 런타임에서 Microsoft Azure Cosmos DB 분석 저장소의 데이터를 동시에 쿼리할 수 있습니다. 현재 Azure Synapse Analytics는 Azure Cosmos DB 분석 저장소를 통해 Apache Spark와 서버리스 SQL 풀을 지원합니다.
참고 항목
Azure Synapse Analytics 런타임을 사용하여 분석 저장소에서 읽기만 가능합니다. 반대의 경우도 마찬가지입니다. Azure Synapse Analytics 런타임은 분석 저장소에서 읽기만 가능합니다. 자동 동기화 프로세스만 분석 저장소의 데이터를 변경할 수 있습니다. 기본 제공 Azure Cosmos DB OLTP SDK를 통해 Azure Synapse Analytics Spark 풀을 사용하여 Azure Cosmos DB 트랜잭션 저장소에 데이터를 쓰기 저장할 수 있습니다.
가격 책정
분석 저장소는 다음 항목에 대한 요금이 청구되는 사용량 기반 가격 책정 모델을 따릅니다.
스토리지: 분석 TTL에서 정의한 기록 데이터를 포함하여 매월 분석 저장소에 보존되는 데이터의 양입니다.
분석 쓰기 작업: 트랜잭션 저장소에서 분석 저장소로 작동 데이터 업데이트의 완전 관리형 동기화(자동 동기화)
분석 읽기 작업: Azure Synapse Analytics Spark 풀 및 서버리스 SQL 풀 런타임에서 분석 저장소에 대해 수행되는 읽기 작업입니다.
분석 저장소 가격은 트랜잭션 저장소 가격 책정 모델과는 별개입니다. 분석 저장소에는 프로비전된 RU의 개념이 없습니다. 분석 저장소의 가격 책정 모델에 대한 자세한 내용은 Azure Cosmos DB 가격 페이지를 참조하세요.
분석 저장소의 데이터는 Azure Synapse Analytics 런타임(Azure Synapse Apache Spark 풀 및 Azure Synapse 서버리스 SQL 풀)에서 수행되는 Azure Synapse Link를 통해서만 액세스할 수 있습니다. 분석 저장소의 데이터에 액세스할 수 있는 가격 책정 모델에 대한 자세한 내용은 Azure Synapse Analytics 가격 페이지를 참조하세요.
Azure Cosmos DB 컨테이너에서 분석 저장소를 사용하도록 설정하기 위한 개략적인 비용을 예측하려면 분석 저장소 관점에서 Azure Cosmos DB Capacity Planner를 사용하여 분석 스토리지와 쓰기 작업 비용을 예측할 수 있습니다.
분석 저장소 읽기 작업 수 예측은 분석 워크로드의 함수이므로 Azure Cosmos DB 비용 계산기에 포함되지 않습니다. 하지만 대략적으로 어림하여 분석 저장소에서 1TB의 데이터를 검사할 경우 대개 130,000개의 분석 읽기 작업이 수행되고 결과적으로 $0.065의 비용이 발생합니다. 예를 들어 Azure Synapse 서버리스 SQL 풀을 사용하여 1TB의 데이터를 검사하면 Azure Synapse Analytics 가격 책정 페이지에 따라 $5.00의 비용이 발생합니다. 데이터 1TB 검사에 드는 최종 총 비용은 $5.065입니다.
위의 추정치는 분석 저장소에서 1TB의 데이터를 검사하는 경우에 대한 것이지만 필터를 적용하면 검사되는 데이터 볼륨이 감소합니다. 이 값은 사용량에 따른 가격 책정 모델에서 정확한 분석 읽기 작업 수를 결정합니다. 분석 워크로드의 개념 증명은 분석 읽기 작업에 대한 보다 정밀한 추정치를 제공합니다. 이 예측에는 Azure Synapse Analytics 비용이 포함되지 않습니다.
다음 단계
자세히 알아보려면 다음 문서를 참조하세요