Azure Data Lake에서 Azure Data Explorer를 사용하여 데이터 쿼리
Azure Data Lake Storage는 빅 데이터 분석을 위한 확장성이 우수하고 비용 효과적인 데이터 레이크 솔루션입니다. 고성능 파일 시스템의 강력한 기능을 대규모 및 경제성과 결합하여 인사이트 획득 시간을 단축할 수 있습니다. Data Lake Storage Gen2는 Azure Blob Storage 기능을 확장하며 분석 워크로드에 최적화되어 있습니다.
Azure Data Explorer는 Azure Blob Storage 및 Azure Data Lake Storage(Gen1 및 Gen2)와 통합되어 외부 스토리지에 저장된 데이터에 대한 빠르고 캐시되고 인덱싱된 액세스를 제공합니다. 이전에 Azure Data Explorer에 수집해 둔 데이터가 없어도 데이터를 분석 및 쿼리할 수 있습니다. 수집된 외부 데이터와 수집되지 않은 외부 데이터를 동시에 쿼리할 수도 있습니다. 자세한 내용은 Azure Data Explorer 웹 UI 마법사를 사용하여 외부 테이블을 만드는 방법을 참조하세요. 간략한 개요는 외부 테이블을 참조하세요.
팁
최고의 쿼리 성능을 위해서는 Azure Data Explorer에 데이터를 수집해야 합니다. 이전에 수집한 데이터 없이 외부 데이터를 쿼리하는 기능은 기록 데이터 또는 거의 쿼리되지 않는 데이터에만 사용해야 합니다. 최상의 결과를 얻을 수 있도록 외부 데이터 쿼리 성능을 최적화하세요.
외부 테이블 만들기
웨어하우스에 저장된 제품에 대한 기록 정보가 들어 있는 수많은 CSV 파일이 있는데, 이러한 파일을 신속하게 분석하여 작년에 가장 인기가 많았던 5개 제품을 찾으려 한다고 가정해 보겠습니다. 이 예제에서 CSV 파일은 다음과 같습니다.
| 타임스탬프 | ProductId | ProductDescription |
|---|---|---|
| 2019-01-01 11:21:00 | TO6050 | 3.5인치 DS/HD 플로피 디스크 |
| 2019-01-01 11:30:55 | YDX1 | Yamaha DX1 신시사이저 |
| ... | ... | ... |
파일은 다음과 같이 archivedproducts 컨테이너의 Azure Blob 스토리지 mycompanystorage에 저장되며, 날짜별로 분할됩니다.
https://mycompanystorage.blob.core.windows.net/archivedproducts/2019/01/01/part-00000-7e967c99-cf2b-4dbb-8c53-ce388389470d.csv.gz
https://mycompanystorage.blob.core.windows.net/archivedproducts/2019/01/01/part-00001-ba356fa4-f85f-430a-8b5a-afd64f128ca4.csv.gz
https://mycompanystorage.blob.core.windows.net/archivedproducts/2019/01/01/part-00002-acb644dc-2fc6-467c-ab80-d1590b23fc31.csv.gz
https://mycompanystorage.blob.core.windows.net/archivedproducts/2019/01/01/part-00003-cd5fad16-a45e-4f8c-a2d0-5ea5de2f4e02.csv.gz
https://mycompanystorage.blob.core.windows.net/archivedproducts/2019/01/02/part-00000-ffc72d50-ff98-423c-913b-75482ba9ec86.csv.gz
...
이러한 CSV 파일에서 직접 KQL 쿼리를 실행하려면 .create external table 명령을 사용하여 Azure Data Explorer에서 외부 테이블을 정의합니다. 외부 테이블 만들기 명령 옵션에 대한 자세한 내용은 외부 테이블 명령을 참조하세요.
.create external table ArchivedProducts(Timestamp:datetime, ProductId:string, ProductDescription:string)
kind=blob
partition by (Date:datetime = bin(Timestamp, 1d))
dataformat=csv
(
h@'https://mycompanystorage.blob.core.windows.net/archivedproducts;StorageSecretKey'
)
이제 Azure Data Explorer 웹 UI의 왼쪽 창에 외부 테이블이 표시됩니다.
외부 테이블 사용 권한
- 데이터베이스 사용자는 외부 테이블을 만들 수 있습니다. 테이블 작성자는 자동으로 테이블 관리자가 됩니다.
- 클러스터, 데이터베이스 또는 테이블 관리자는 기존 테이블을 편집할 수 있습니다.
- 모든 데이터베이스 사용자 또는 읽기 권한자는 외부 테이블을 쿼리할 수 있습니다.
외부 테이블 쿼리
외부 테이블을 정의한 후에는 external_table() 함수를 사용하여 해당 외부 테이블을 참조할 수 있습니다. 쿼리의 나머지 부분은 표준 Kusto 쿼리 언어입니다.
external_table("ArchivedProducts")
| where Timestamp > ago(365d)
| summarize Count=count() by ProductId,
| top 5 by Count
외부 데이터와 수집 데이터를 함께 쿼리
동일한 쿼리 내에서 외부 테이블과 수집된 데이터 테이블을 모두 쿼리할 수 있습니다. 외부 테이블을 Azure Data Explorer, SQL 서버 또는 기타 원본의 다른 데이터와 join 또는 union할 수 있습니다. let( ) statement 명령을 사용하여 외부 테이블 참조에 약식 이름을 할당합니다.
아래 예제에서 Products는 수집된 데이터 테이블이고 ArchivedProducts는 이전에 정의한 외부 테이블입니다.
let T1 = external_table("ArchivedProducts") | where TimeStamp > ago(100d);
let T = Products; //T is an internal table
T1 | join T on ProductId | take 10
계층형 데이터 형식 쿼리
Azure Data Explorer는 JSON, Parquet, Avro, ORC 등과 같은 계층형 형식을 쿼리할 수 있습니다. 계층적 데이터 스키마를 외부 테이블 스키마에 매핑하려면(서로 다른 경우) 외부 테이블 매핑 명령을 사용합니다. 예를 들어 다음 형식으로 JSON 로그 파일을 쿼리하는 방법은 아래와 같습니다.
{
"timestamp": "2019-01-01 10:00:00.238521",
"data": {
"tenant": "e1ef54a6-c6f2-4389-836e-d289b37bcfe0",
"method": "RefreshTableMetadata"
}
}
{
"timestamp": "2019-01-01 10:00:01.845423",
"data": {
"tenant": "9b49d0d7-b3e6-4467-bb35-fa420a25d324",
"method": "GetFileList"
}
}
...
외부 테이블 정의는 다음과 같습니다.
.create external table ApiCalls(Timestamp: datetime, TenantId: guid, MethodName: string)
kind=blob
dataformat=multijson
(
h@'https://storageaccount.blob.core.windows.net/container1;StorageSecretKey'
)
데이터 필드를 외부 테이블 정의 필드에 매핑하는 JSON 매핑을 정의합니다.
.create external table ApiCalls json mapping 'MyMapping' '[{"Column":"Timestamp","Properties":{"Path":"$.timestamp"}},{"Column":"TenantId","Properties":{"Path":"$.data.tenant"}},{"Column":"MethodName","Properties":{"Path":"$.data.method"}}]'
다음과 같이 외부 테이블을 쿼리하면 매핑이 호출되고, 관련 데이터가 외부 테이블 열에 매핑됩니다.
external_table('ApiCalls') | take 10
매핑 구문에 대한 자세한 내용은 데이터 매핑을 참조하세요.
help 클러스터에서 외부 테이블 TaxiRides 쿼리
help라는 테스트 클러스터를 사용하여 다른 Azure Data Explorer 기능을 사용해 보세요. help 클러스터에는 수십억 건의 택시 승차 기록이 들어 있는 뉴욕시 택시 데이터 세트에 대한 외부 테이블 정의가 포함되어 있습니다.
외부 테이블 TaxiRides 만들기
이 섹션에서는 help 클러스터에 TaxiRides 외부 테이블을 만드는 데 사용되는 쿼리를 보여줍니다. 이 테이블은 이미 생성되었으므로 이 섹션을 건너뛰고 query TaxiRides 외부 테이블 데이터로 바로 이동하면 됩니다.
.create external table TaxiRides
(
trip_id: long,
vendor_id: string,
pickup_datetime: datetime,
dropoff_datetime: datetime,
store_and_fwd_flag: string,
rate_code_id: int,
pickup_longitude: real,
pickup_latitude: real,
dropoff_longitude: real,
dropoff_latitude: real,
passenger_count: int,
trip_distance: real,
fare_amount: real,
extra: real,
mta_tax: real,
tip_amount: real,
tolls_amount: real,
ehail_fee: real,
improvement_surcharge: real,
total_amount: real,
payment_type: string,
trip_type: int,
pickup: string,
dropoff: string,
cab_type: string,
precipitation: int,
snow_depth: int,
snowfall: int,
max_temperature: int,
min_temperature: int,
average_wind_speed: int,
pickup_nyct2010_gid: int,
pickup_ctlabel: string,
pickup_borocode: int,
pickup_boroname: string,
pickup_ct2010: string,
pickup_boroct2010: string,
pickup_cdeligibil: string,
pickup_ntacode: string,
pickup_ntaname: string,
pickup_puma: string,
dropoff_nyct2010_gid: int,
dropoff_ctlabel: string,
dropoff_borocode: int,
dropoff_boroname: string,
dropoff_ct2010: string,
dropoff_boroct2010: string,
dropoff_cdeligibil: string,
dropoff_ntacode: string,
dropoff_ntaname: string,
dropoff_puma: string
)
kind=blob
partition by (Date:datetime = bin(pickup_datetime, 1d))
dataformat=csv
(
h@'https://storageaccount.blob.core.windows.net/container1;secretKey'
)
Azure Data Explorer 웹 UI의 왼쪽 창을 살펴보면 다음과 같이 TaxiRides 테이블이 생성된 것을 볼 수 있습니다.
TaxiRides 외부 테이블 데이터 쿼리
[https://manage.visualstudio.com](https://dataexplorer.azure.com/clusters/help/databases/Samples ) 에 로그인합니다.
분할하지 않고 TaxiRides 외부 테이블 쿼리
외부 테이블 TaxiRides에서 이 쿼리를 실행하여 전체 데이터 세트에서 요일마다 놀이기구를 표시합니다.
external_table("TaxiRides")
| summarize count() by dayofweek(pickup_datetime)
| render columnchart
이 쿼리는 가장 바쁜 요일을 보여줍니다. 데이터가 분할되지 않으므로 쿼리 결과가 반환될 때까지 최대 몇 분 정도 걸릴 수 있습니다.

분할하지 않고 TaxiRides 외부 테이블 쿼리
외부 테이블 TaxiRides에서 이 쿼리를 실행하여 2017년 1월에 사용된 택시 형식(노란색 또는 녹색)을 표시합니다.
external_table("TaxiRides")
| where pickup_datetime between (datetime(2017-01-01) .. datetime(2017-02-01))
| summarize count() by cab_type
| render piechart
이 쿼리에서는 분할을 사용합니다. 그러면 쿼리 시간과 성능이 최적화됩니다. 쿼리는 분할된 열(pickup_datetime)을 필터링하고 몇 초 내에 결과를 반환합니다.
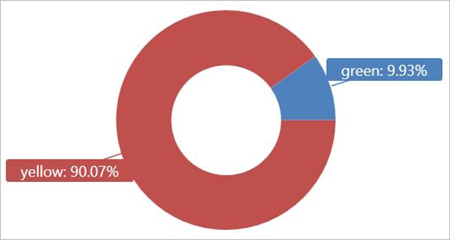
외부 테이블 TaxiRides에서 실행할 다른 쿼리를 작성하고 데이터에 대해 자세히 알아볼 수 있습니다.
쿼리 성능 최적화
외부 데이터 쿼리에 대한 다음 모범 사례를 사용하여 레이크의 쿼리 성능을 최적화하세요.
데이터 형식
- 다음과 같은 이유로 분석 쿼리에는 열 형식을 사용합니다.
- 쿼리와 관련된 열만 읽을 수 있습니다.
- 열 인코딩 기술을 통해 데이터 크기를 대폭 줄일 수 있습니다.
- Azure Data Explorer는 Parquet 및 ORC 열 형식을 지원합니다. 구현이 최적화된 Parquet 형식을 권장합니다.
Azure 지역
외부 데이터가 Azure Data Explorer 클러스터와 동일한 Azure 지역에 있는지 확인합니다. 이렇게 설정하면 비용과 데이터를 가져오는 시간이 단축됩니다.
파일 크기
최적의 파일 크기는 파일당 수백 Mb(최대 1GB)입니다. 느린 파일 열거형 프로세스와 제한된 열 형식 사용과 같이 불필요한 오버헤드가 발생하는 작은 파일을 많이 사용하지 마세요. 파일 수는 Azure Data Explorer 클러스터의 CPU 코어 수보다 많아야 합니다.
압축
압축을 사용하여 원격 스토리지에서 가져오는 데이터의 양을 줄이세요. Parquet 형식의 경우 열 그룹을 별도로 압축하는 내부 Parquet 압축 메커니즘을 사용하면 열 그룹을 별도로 읽을 수 있습니다. 압축 메커니즘 사용의 유효성을 검사하려면 파일 이름이 <filename>.parquet.gz가 아닌 <filename>.gz.parquet 또는 <filename>.snappy.parquet인지 확인합니다.
분할
쿼리에서 관련 없는 경로를 건너뛸 수 있는 "폴더" 파티션을 사용하여 데이터를 구성합니다. 분할을 계획할 때 타임스탬프 또는 테넌트 ID와 같은 쿼리의 파일 크기 및 일반 필터를 고려합니다.
VM 크기
더 많은 코어와 더 높은 네트워크 처리량을 제공하는 VM SKU를 선택합니다(메모리는 덜 중요). 자세한 내용은 Azure Data Explorer 클러스터에 적합한 VM SKU 선택을 참조하세요.
관련 콘텐츠
피드백
출시 예정: 2024년 내내 콘텐츠에 대한 피드백 메커니즘으로 GitHub 문제를 단계적으로 폐지하고 이를 새로운 피드백 시스템으로 바꿀 예정입니다. 자세한 내용은 다음을 참조하세요. https://aka.ms/ContentUserFeedback
다음에 대한 사용자 의견 제출 및 보기