Azure Storage에서 데이터 가져오기
데이터 수집은 하나 이상의 원본에서 Azure Data Explorer 테이블로 데이터를 로드하는 데 사용되는 프로세스입니다. 수집한 후에는 데이터를 쿼리에 사용할 수 있게 됩니다. 이 문서에서는 Azure Storage(ADLS Gen2 컨테이너, Blob 컨테이너 또는 개별 Blob)에서 새 테이블 또는 기존 테이블로 데이터를 가져오는 방법을 알아봅니다.
수집은 일회성 작업 또는 연속 메서드로 수행할 수 있습니다. 지속적인 수집은 포털을 통해서만 구성할 수 있습니다.
데이터 수집에 대한 일반적인 내용은 Azure Data Explorer 데이터 수집 개요를 참조하세요.
사전 요구 사항
- Microsoft 계정 또는 Microsoft Entra 사용자 ID. Azure 구독이 필요하지 않습니다.
- Azure Data Explorer 웹 UI에 로그인합니다.
- Azure Data Explorer 클러스터 및 데이터베이스. 클러스터 및 데이터베이스를 만듭니다.
- 스토리지 계정.
데이터 가져오기
왼쪽 메뉴에서 쿼리를 선택합니다.
데이터를 수집할 데이터베이스를 마우스 오른쪽 단추로 클릭합니다. 데이터 가져오기를 선택합니다.


Source
데이터 가져오기 창에서 원본 탭이 선택됩니다.
사용 가능한 목록에서 데이터 원본을 선택합니다. 이 예제에서는 Azure Storage에서 데이터를 수집합니다.

구성
대상 데이터베이스 및 테이블을 선택합니다. 새 테이블에 데이터를 수집하려면 + 새 테이블을 선택하고 테이블 이름을 입력합니다.
참고
테이블 이름은 공백, 영숫자, 하이픈 및 밑줄을 포함하여 최대 1024자까지 가능합니다. 특수 문자는 지원되지 않습니다.
원본을 추가하려면 컨테이너 선택 또는 URI 추가를 선택합니다.
컨테이너 선택을 선택한 경우 다음 필드를 입력합니다.

설정 필드 설명 Subscription 스토리지 계정이 있는 구독 ID입니다. 스토리지 계정 스토리지 계정을 식별하는 이름입니다. 컨테이너 수집하려는 스토리지 컨테이너입니다. 파일 필터(선택 사항) 폴더 경로 특정 폴더 경로를 사용하여 파일을 수집하도록 데이터를 필터링합니다. 파일 확장명 특정 파일 확장명만 사용하여 파일을 수집하도록 데이터를 필터링합니다. URI 추가를 선택한 경우 URI 필드에 Blob 컨테이너 또는 개별 파일에 대한 스토리지 연결 문자열 붙여넣은 다음 을 선택합니다+.
참고
- 최대 10개의 개별 Blob을 추가할 수 있습니다. 각 Blob은 최대 1GB의 압축되지 않을 수 있습니다.
- 단일 컨테이너에서 최대 5,000개의 Blob을 수집할 수 있습니다.

다음을 선택합니다.


검사
검사 탭이 열리고 데이터의 미리 보기가 열립니다.
수집 프로세스를 완료하려면 마침을 선택합니다.

필요에 따라 다음을 수행합니다.
- 명령 뷰어를 선택하여 입력에서 생성된 자동 명령을 보고 복사합니다.
- 스키마 정의 파일 드롭다운을 사용하여 스키마가 유추되는 파일을 변경합니다.
- 드롭다운에서 원하는 형식을 선택하여 자동으로 유추된 데이터 형식을 변경합니다. 수집은 Azure Data Explorer 지원하는 데이터 형식을 참조하세요.
- 열을 편집합니다.
- 데이터 형식에 따라 고급 옵션을 탐색합니다.
열 편집
참고
- 테이블 형식(CSV, TSV, PSV)의 경우 열을 두 번 매핑할 수 없습니다. 기존 열에 매핑하려면 먼저 새 열을 삭제합니다.
- 기존 열 유형은 변경할 수 없습니다. 다른 형식의 열에 매핑하려고 하면 빈 열이 생길 수 있습니다.
테이블에서 변경할 수 있는 사항은 다음 매개 변수에 따라 다릅니다.
- 테이블 유형은 신규 또는 기존입니다.
- 매핑 유형은 신규 또는 기존입니다.
| 테이블 유형 | 매핑 유형 | 사용 가능한 조정 |
|---|---|---|
| 새 테이블 | 새 매핑 | 열 이름 바꾸기, 데이터 형식 변경, 데이터 원본 변경, 매핑 변환, 열 추가, 열 삭제 |
| 기존 테이블 | 새 매핑 | 열 추가(데이터 형식 변경, 이름 바꾸기 및 업데이트 가능) |
| 기존 테이블 | 기존 매핑 | 없음 |

매핑 변환
일부 데이터 형식 매핑(Parquet, JSON 및 Avro)은 간단한 수집 시간 변환을 지원합니다. 매핑 변환을 적용하려면 열 편집 창에서 열을 만들거나 업데이트 합니다 .
매핑 변환은 데이터 형식이 int 또는 long인 원본을 사용하여 문자열 또는 datetime 형식의 열에서 수행할 수 있습니다. 지원되는 매핑 변환은 다음과 같습니다.
- DateTimeFromUnixSeconds
- DateTimeFromUnixMilliseconds
- DateTimeFromUnixMicroseconds
- DateTimeFromUnixNanoseconds
데이터 형식을 기반으로 하는 고급 옵션
테이블 형식(CSV, TSV, PSV):
기존 테이블에서 테이블 형식을 수집하는 경우 고급>현재 테이블 스키마 유지를 선택할 수 있습니다. 테이블 형식 데이터에는 원본 데이터를 기존 열에 매핑하는 데 사용되는 열 이름이 반드시 포함되지는 않습니다. 이 옵션을 선택하면 매핑이 순서대로 수행되고 테이블 스키마는 동일하게 유지됩니다. 이 옵션을 선택 취소하면 데이터 구조에 관계없이 들어오는 데이터에 대한 새 열이 만들어집니다.
첫 번째 행을 열 이름으로 사용하려면 고급>첫 번째 행이 열 머리글임을 선택합니다.

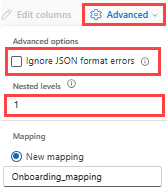
JSON:
JSON 데이터의 열 나누기를 확인하려면 1에서 100까지 의 고급>중첩 수준을 선택합니다.
고급>데이터 형식 오류 무시를 선택하면 데이터가 JSON 형식으로 수집됩니다. 이 확인란을 선택하지 않은 상태로 두면 데이터가 multijson 형식으로 수집됩니다.
요약
데이터 준비 창에서 데이터 수집이 성공적으로 완료되면 세 단계 모두 녹색 검사 표시로 표시됩니다. 각 단계에 사용된 명령을 보거나 수집된 데이터를 쿼리, 시각화 또는 삭제할 카드 선택할 수 있습니다.

관련 콘텐츠
피드백
출시 예정: 2024년 내내 콘텐츠에 대한 피드백 메커니즘으로 GitHub 문제를 단계적으로 폐지하고 이를 새로운 피드백 시스템으로 바꿀 예정입니다. 자세한 내용은 다음을 참조하세요. https://aka.ms/ContentUserFeedback
다음에 대한 사용자 의견 제출 및 보기