Azure Data Factory에서 Databricks Notebook 작업으로 Databricks Notebook 실행
적용 대상: Azure Data Factory Azure Synapse Analytics
Azure Data Factory Azure Synapse Analytics
팁
기업용 올인원 분석 솔루션인 Microsoft Fabric의 Data Factory를 사용해 보세요. Microsoft Fabric은 데이터 이동부터 데이터 과학, 실시간 분석, 비즈니스 인텔리전스 및 보고에 이르기까지 모든 것을 다룹니다. 무료로 새 평가판을 시작하는 방법을 알아봅니다!
이 자습서에서는 Azure Portal을 사용하여 databricks 작업 클러스터에 대해 Databricks Notebook을 실행하는 Azure Data Factory 파이프라인을 만듭니다. 또한 실행 중에 Azure Data Factory 매개 변수를 Databricks Notebook에 전달합니다.
이 자습서에서 수행하는 단계는 다음과 같습니다.
데이터 팩터리를 만듭니다.
Databricks Notebook 작업을 사용하는 파이프라인을 만듭니다.
파이프라인 실행 트리거
파이프라인 실행을 모니터링합니다.
Azure 구독이 없는 경우 시작하기 전에 체험 계정을 만듭니다.
11분 동안 이 기능의 소개 및 데모에 대한 다음 비디오를 시청하세요.
필수 조건
- Azure Databricks 작업 영역. databricks 작업 영역을 만들거나 기존 작업 영역을 사용합니다. Azure Databricks 작업 영역에 Python Notebook을 만듭니다. 그런 다음, Azure Data Factory를 사용하여 Notebook을 실행하고 매개 변수를 전달합니다.
데이터 팩터리 만들기
Microsoft Edge 또는 Google Chrome 웹 브라우저를 시작합니다. 현재 Data Factory UI는 Microsoft Edge 및 Google Chrome 웹 브라우저에서만 지원됩니다.
Azure Portal 메뉴에서 리소스 만들기, 통합, 데이터 팩터리를 차례로 선택합니다.
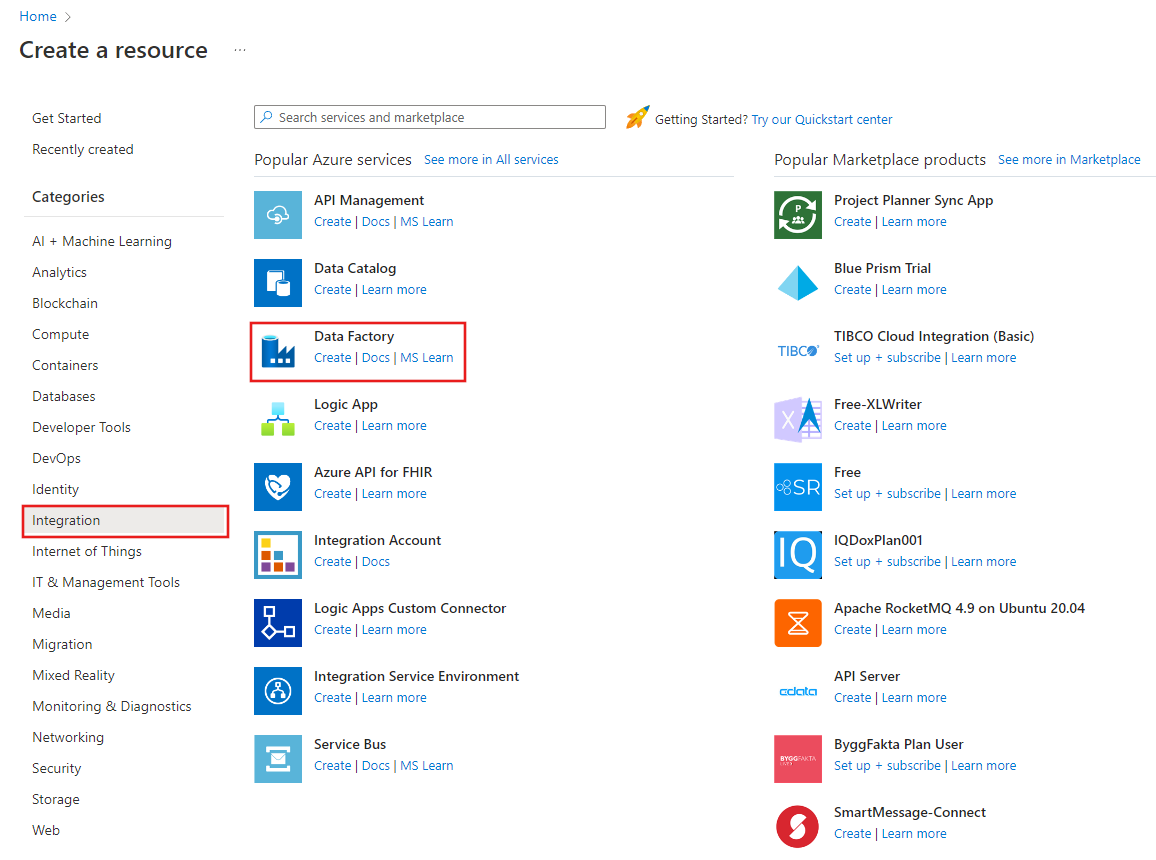
Data Factory 만들기 페이지의 기본 사항 탭에서 데이터 팩터리를 만들려는 위치에 Azure 구독을 선택합니다.
리소스 그룹에 대해 다음 단계 중 하나를 사용합니다.
드롭다운 목록에서 기존 리소스 그룹을 선택합니다.
새로 만들기를 선택하고 새 리소스 그룹의 이름을 입력합니다.
리소스 그룹에 대한 자세한 내용은 리소스 그룹을 사용하여 Azure 리소스 관리를 참조하세요.
지역의 경우 데이터 팩터리의 위치를 선택합니다.
이 목록은 데이터 팩터리가 지원하는 위치 및 Azure Data Factory 메타데이터가 저장될 위치만 표시합니다. Data Factory에서 사용하는 연결된 데이터 저장소(Azure Storage 및 Azure SQL Database 등) 및 컴퓨팅(Azure HDInsight 등)은 다른 하위 지역에서 실행할 수 있습니다.
이름에 ADFTutorialDataFactory를 입력합니다.
Azure Data Factory의 이름은 전역적으로 고유해야 합니다. 다음 오류가 표시되는 경우 데이터 팩터리 이름을 변경합니다(예: <yourname>ADFTutorialDataFactory 사용). 데이터 팩터리 아티팩트에 대한 명명 규칙은 데이터 팩터리 - 명명 규칙 문서를 참조하세요.
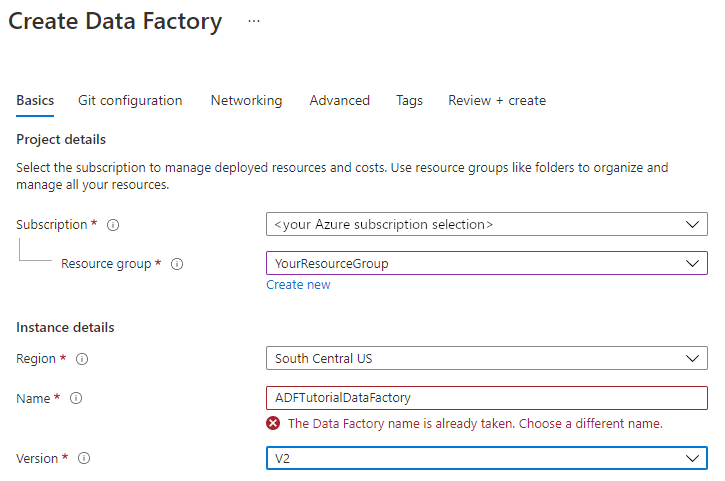
버전에서 V2를 선택합니다.
완료되면 다음: Git 구성을 선택한 다음, 나중에 Git 구성 확인란을 선택합니다.
검토 + 만들기를 선택하고 유효성 검사를 통과한 후 만들기를 선택합니다.
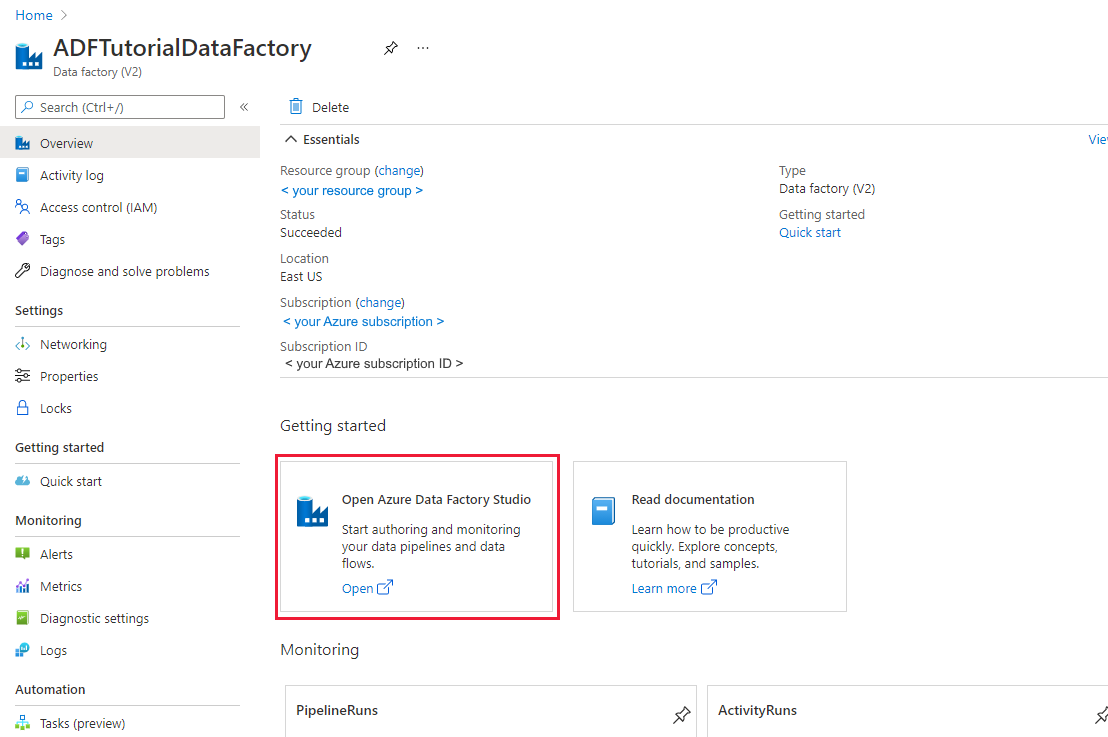
만들기가 완료되면 리소스로 이동을 선택하여 Data Factory 페이지로 이동합니다. Azure Data Factory 스튜디오 열기 타일을 선택하여 별도의 브라우저 탭에서 Azure Data Factory UI(사용자 인터페이스) 애플리케이션을 시작합니다.
연결된 서비스 생성
이 섹션에서는 Databricks 연결된 서비스를 작성합니다. 이 연결된 서비스에는 Databricks 클러스터에 대한 연결 정보가 포함됩니다.
Azure Databricks 연결된 서비스 만들기
홈페이지에서 왼쪽 패널의 관리 탭으로 전환합니다.
연결 아래에서 연결된 서비스를 선택한 다음, + 새로 만들기를 선택합니다.
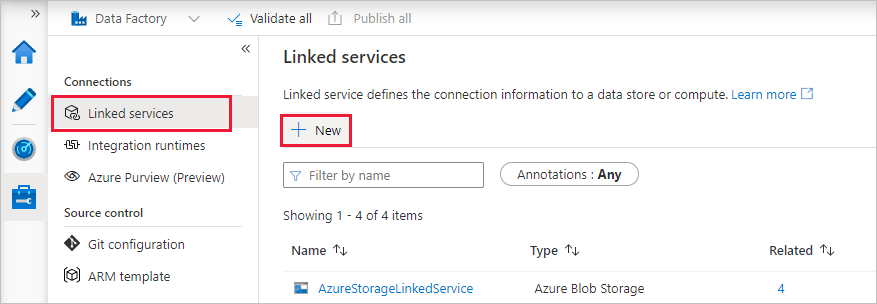
새 연결된 서비스 창에서 컴퓨팅>Azure Databricks를 차례로 선택한 다음, 계속을 선택합니다.

새 연결된 서비스 창에서 다음 단계를 완료합니다.
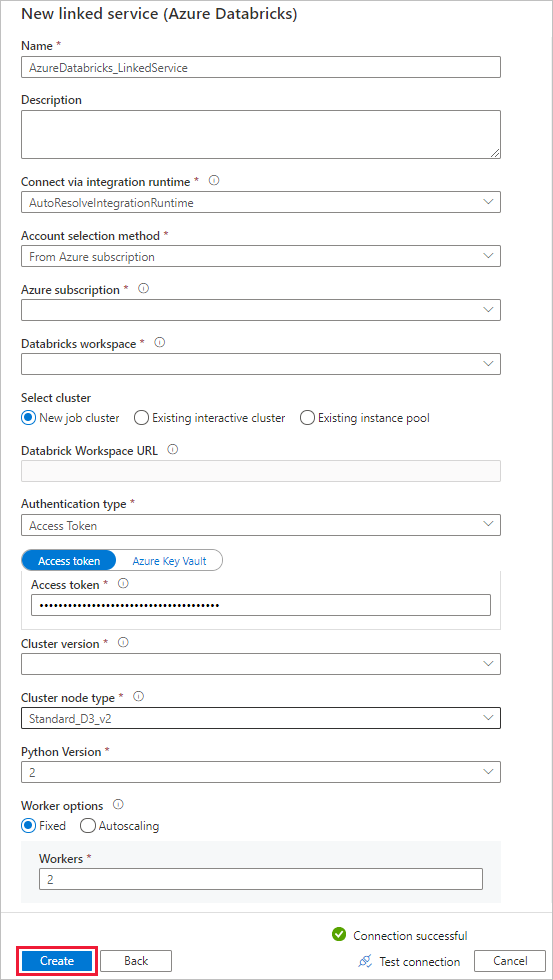
이름에 대해 AzureDatabricks_LinkedService를 입력합니다.
Notebook을 실행하는 데 적절한 Databricks 작업 영역을 선택합니다.
클러스터 선택에 대해 새 작업 클러스터를 선택합니다.
Databrick 작업 영역 URL의 경우 해당 정보가 자동으로 채워집니다.
인증 유형의 경우 액세스 토큰을 선택하면 Azure Databricks 작업 영역에서 생성합니다. 단계는 여기서 찾을 수 있습니다. 관리되는 서비스 ID 및 사용자 할당 관리 ID의 경우 Azure Databricks 리소스의 액세스 제어 메뉴에서 두 ID 모두에 기여자 역할을 부여합니다.
클러스터 버전에 사용할 버전을 선택합니다.
클러스터 노드 유형에 대해 이 자습서의 범용(HDD) 범주 아래에서 Standard_D3_v2를 선택합니다.
근로자에 대해 2를 입력합니다.
만들기를 실행합니다.
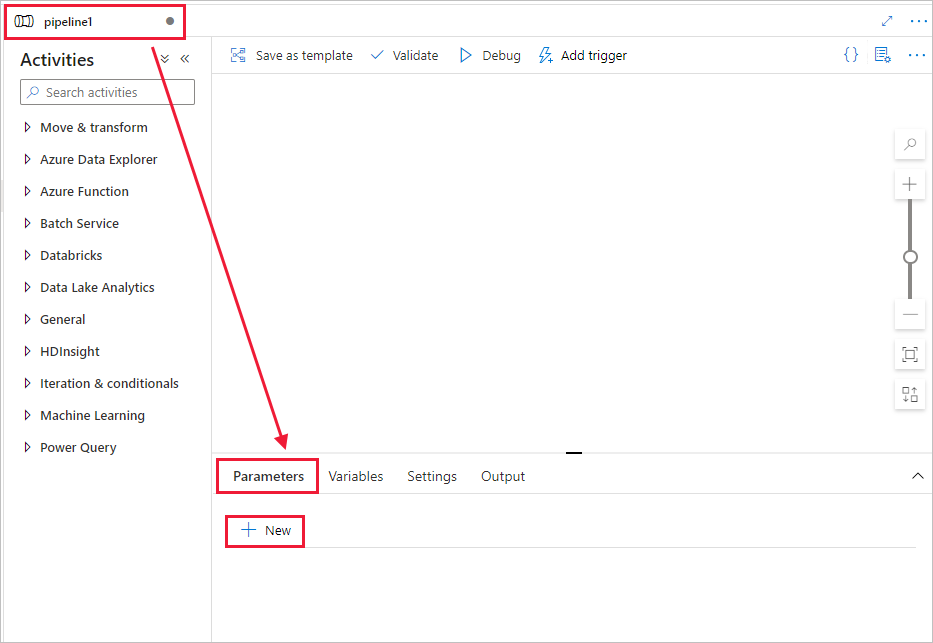
파이프라인을 만듭니다.
+(더하기) 단추를 선택한 다음 메뉴에서 파이프라인을 선택합니다.

파이프라인에서 사용할 매개 변수를 만듭니다. 나중에 이 매개 변수를 Databricks Notebook 작업에 전달합니다. 빈 파이프라인에서 매개 변수 탭, 새로 만들기를 차례로 선택하고, 이름으로 'name'을 지정합니다.
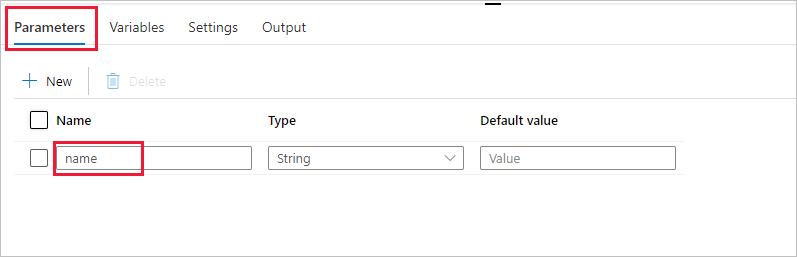
활동 도구 상자에서 Databricks를 펼칩니다. 활동 도구 상자에서 Notebook 활동을 파이프라인 디자이너 화면으로 끌어서 놓습니다.
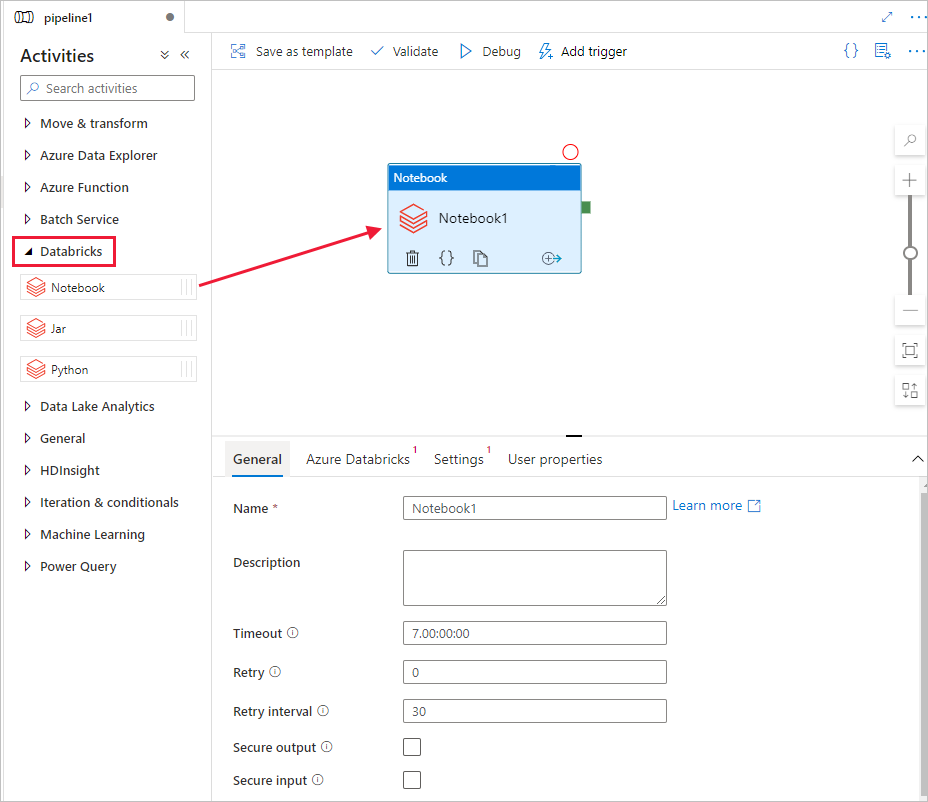
아래쪽의 DatabricksNotebook 활동 창에 대한 속성에서 다음 단계를 완료합니다.
Azure Databricks 탭으로 전환합니다.
이전 절차에서 만든 AzureDatabricks_LinkedService를 선택합니다.
설정 탭으로 전환합니다.
Databricks Notebook 경로를 찾아봅니다. 여기서는 노트북을 만들고 경로를 지정해 보겠습니다. 다음 몇 단계를 따라 Notebook 경로를 가져옵니다.
Azure Databricks 작업 영역을 시작합니다.
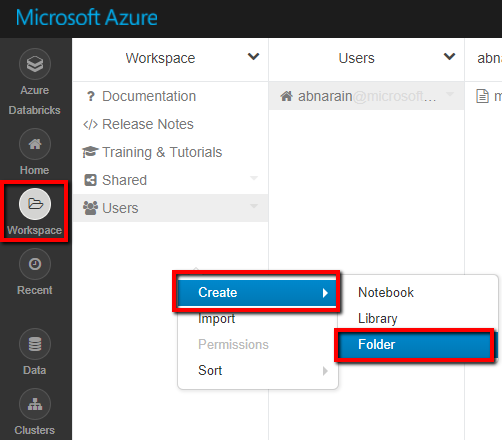
작업 공간에서 새 폴더를 만들고 adftutorial로 호출합니다.
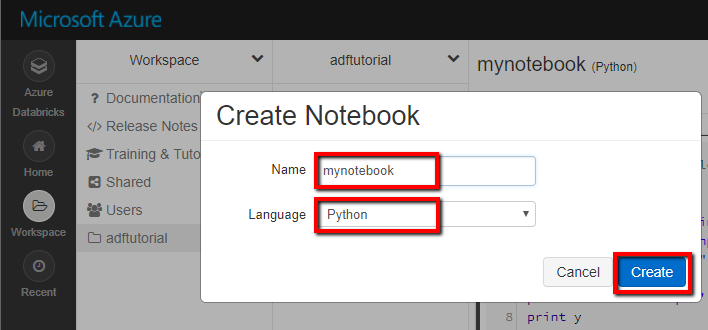
새 Notebook을 만드는 방법을 보여 주는 스크린샷 (Python) adftutorial 폴더 아래에서 mynotebook이라고 하고 만들기를 클릭해 보겠습니다.

새로 생성된 "mynotebook" Notebook에서 다음 코드를 추가합니다.
# Creating widgets for leveraging parameters, and printing the parameters dbutils.widgets.text("input", "","") y = dbutils.widgets.get("input") print ("Param -\'input':") print (y)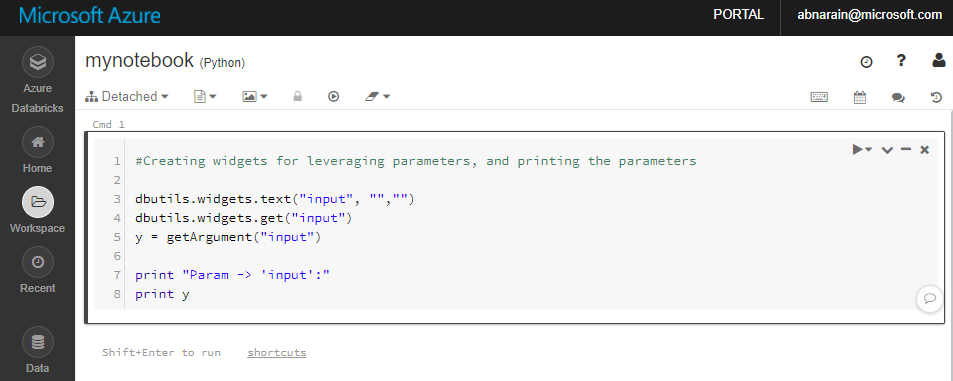
이 경우 Notebook 경로는 /adftutorial/mynotebook입니다.
Data Factory UI 제작 도구로 다시 전환합니다. Notebook1 작업 아래의 설정 탭으로 이동합니다.
a. 매개 변수를 Notebook 작업에 추가합니다. 이전에 파이프라인에 추가한 것과 동일한 매개 변수를 사용합니다.
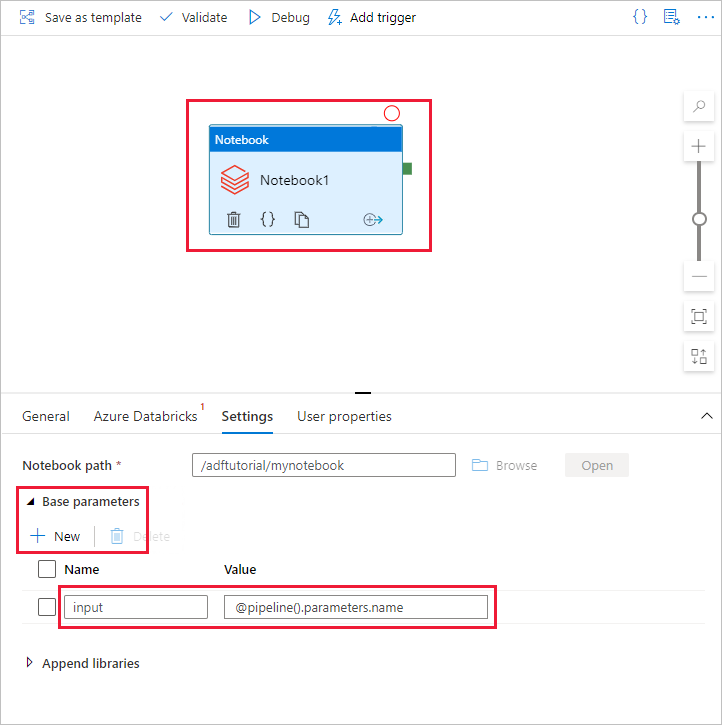
b. 매개 변수의 이름을 input으로 지정하고 값을 @pipeline().parameters.name 식으로 제공합니다.
파이프라인에 대한 유효성을 검사하려면 도구 모음에서 유효성 검사 단추를 선택합니다. 유효성 검사 창을 닫으려면 닫기 단추를 선택합니다.
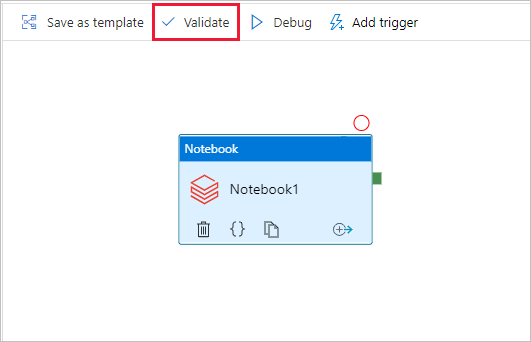
모두 게시를 선택합니다. Data Factory UI는 엔터티(연결된 서비스 및 파이프라인)를 Azure Data Factory 서비스에 게시합니다.

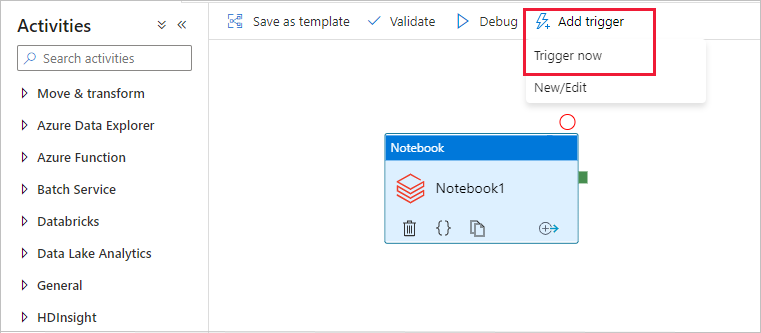
파이프라인 실행 트리거
도구 모음에서 트리거 추가를 선택한 다음, 지금 트리거를 선택합니다.
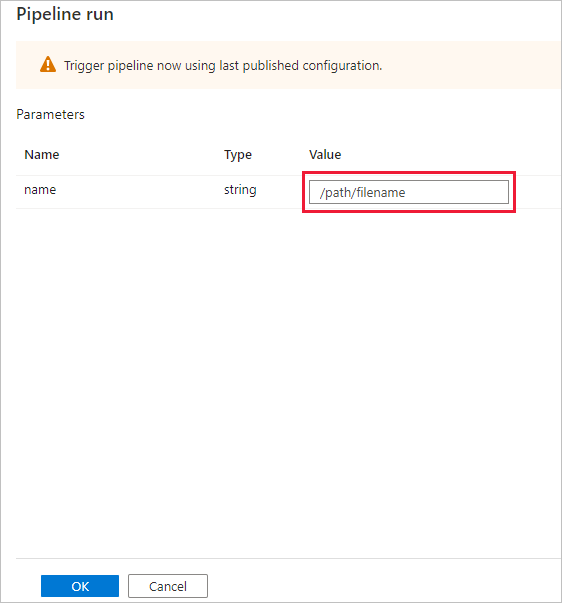
파이프라인 실행 대화 상자에서 name 매개 변수를 요청합니다. 여기서는 /path/filename을 매개 변수로 사용합니다. 확인을 선택합니다.
파이프라인 실행 모니터링
모니터 탭으로 전환합니다. 파이프라인 실행이 표시되는지 확인합니다. 노트북이 실행되는 Databricks 작업 클러스터를 만드는 데 약 5~8분이 걸립니다.
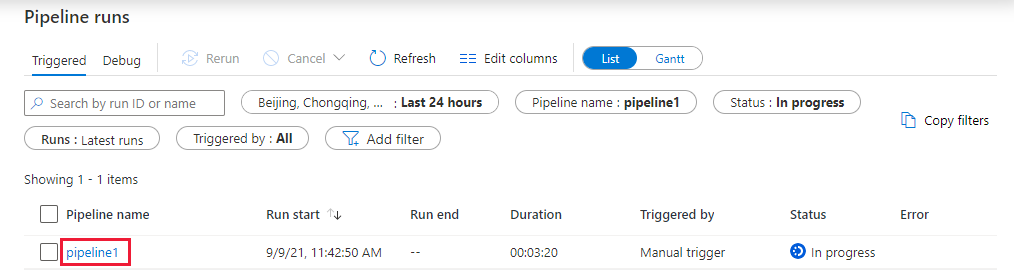
주기적으로 새로 고침을 선택하여 파이프라인 실행 상태를 확인합니다.
파이프라인 실행과 관련된 활동 실행을 보려면 파이프라인 이름 열에서 pipeline1 링크를 선택합니다.
활동 실행 페이지의 활동 이름 열에서 출력을 선택하여 각 활동 출력을 봅니다. Spark 로그에 대한 자세한 내용은 출력 창의 Databricks 로그의 링크를 참조하세요.
맨 위에 있는 이동 경로 메뉴의 모든 파이프라인 실행 링크를 선택하면 파이프라인 실행 보기로 다시 전환할 수 있습니다.
출력 확인
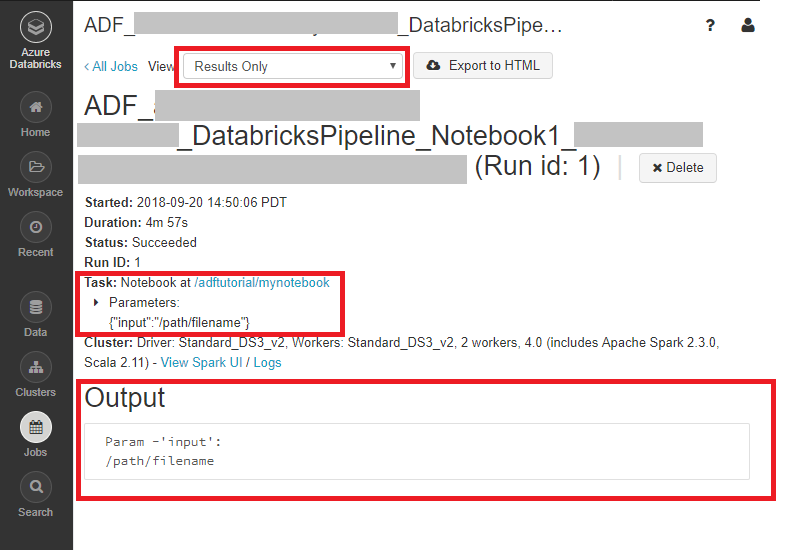
Azure Databricks 작업 영역에 로그온하고 클러스터로 이동할 수 있으며, 작업 상태가 실행 보류 중, 실행 중 또는 종료됨으로 표시됩니다.

작업 이름을 클릭하여 세부 정보를 탐색할 수 있습니다. 성공적으로 실행되면 전달된 매개 변수와 Python 노트북의 출력의 유효성을 검사할 수 있습니다.
관련 콘텐츠
이 샘플의 파이프라인에서 Databricks Notebook 활동을 트리거하고 여기에 매개 변수를 전달합니다. 다음 방법에 대해 알아보았습니다.
데이터 팩터리를 만듭니다.
Databricks Notebook 활동을 사용하는 파이프라인을 만듭니다.
파이프라인 실행 트리거
파이프라인 실행을 모니터링합니다.