Azure Data Factory를 사용하여 Azure Blob 스토리지에서 Azure SQL Database의 데이터베이스로 데이터 복사
적용 대상: Azure Data Factory Azure Synapse Analytics
Azure Data Factory Azure Synapse Analytics
팁
기업용 올인원 분석 솔루션인 Microsoft Fabric의 Data Factory를 사용해 보세요. Microsoft Fabric은 데이터 이동부터 데이터 과학, 실시간 분석, 비즈니스 인텔리전스 및 보고에 이르기까지 모든 것을 다룹니다. 무료로 새 평가판을 시작하는 방법을 알아봅니다!
이 자습서에서는 Azure Data Factory UI(사용자 인터페이스)를 사용하여 데이터 팩터리를 만듭니다. 데이터 팩터리의 파이프라인은 Azure Blob 스토리지에서 Azure SQL Database의 데이터베이스로 데이터를 복사합니다. 이 자습서의 구성 패턴은 파일 기반 데이터 저장소에서 관계형 데이터 저장소로 복사하는 데 적용됩니다. 원본 및 싱크로 지원되는 데이터 저장소의 목록은 지원되는 데이터 저장소 표를 참조하세요.
참고 항목
Data Factory를 처음 사용하는 경우 Azure Data Factory 소개를 참조하세요.
이 자습서에서는 다음 단계를 수행합니다.
- 데이터 팩터리를 만듭니다.
- 복사 활동이 있는 파이프라인 만들기
- 파이프라인 실행 테스트
- 수동으로 파이프라인 트리거
- 일정에 따라 파이프라인 트리거
- 파이프라인 및 작업 실행을 모니터링합니다.
필수 조건
- Azure 구독. Azure 구독이 아직 없는 경우 시작하기 전에 Azure 체험 계정을 만듭니다.
- Azure 스토리지 계정. Blob Storage를 원본 데이터 스토리지로 사용합니다. 스토리지 계정이 없는 경우 Azure Storage 계정 만들기를 참조하세요.
- Azure SQL Database. 데이터베이스를 싱크 데이터 저장소로 사용합니다. Azure SQL Database에 데이터베이스가 없는 경우 데이터베이스를 만드는 단계는 Azure SQL Database에서 데이터베이스 만들기를 참조하세요.
Blob 및 SQL 테이블 만들기
이제 다음 단계를 수행하여 자습서에서 사용할 Blob Storage 및 SQL 데이터베이스를 준비합니다.
원본 Blob 만들기
메모장을 시작합니다. 다음 텍스트를 복사하고 디스크에 emp.txt 파일로 저장합니다.
FirstName,LastName John,Doe Jane,DoeBlob Storage에 adftutorial이라는 컨테이너를 만듭니다. 이 컨테이너에 input이라는 폴더를 만듭니다. 그런 다음 emp.txt 파일을 input 폴더에 업로드합니다. 이러한 작업을 수행하려면 Azure Portal 또는 Azure Storage Explorer와 같은 도구를 사용합니다.
싱크 SQL 테이블 만들기
다음 SQL 스크립트를 사용하여 데이터베이스에 dbo.emp 테이블을 만듭니다.
CREATE TABLE dbo.emp ( ID int IDENTITY(1,1) NOT NULL, FirstName varchar(50), LastName varchar(50) ) GO CREATE CLUSTERED INDEX IX_emp_ID ON dbo.emp (ID);Azure 서비스에서 SQL Server에 액세스하도록 허용합니다. Data Factory에서 SQL Server에 데이터를 쓸 수 있도록 SQL Server에 대해 Azure 서비스 방문 허용이 켜기로 설정되어 있는지 확인합니다. 이 설정을 확인하고 켜려면 논리 SQL Server > 개요 > 서버 방화벽 설정>으로 이동하여 Azure 서비스에 대한 액세스 허용 옵션을 켜기로 설정합니다.
데이터 팩터리 만들기
이 단계에서는 데이터 팩터리를 만들고, Data Factory UI를 시작하여 파이프라인을 데이터 팩터리에 만듭니다.
Microsoft Edge 또는 Google Chrome을 엽니다. 현재 Data Factory UI는 Microsoft Edge 및 Google Chrome 웹 브라우저에서만 지원됩니다.
왼쪽 메뉴에서 리소스 만들기>통합>Data Factory를 선택합니다.
Data Factory 만들기 페이지의 기본 사항 탭에서 데이터 팩터리를 만들려는 위치에 Azure 구독을 선택합니다.
리소스 그룹에 대해 다음 단계 중 하나를 사용합니다.
a. 드롭다운 목록에서 기존 리소스 그룹을 선택합니다.
b. 새로 만들기를 선택하고 새 리소스 그룹의 이름을 입력합니다.
리소스 그룹에 대한 자세한 내용은 리소스 그룹을 사용하여 Azure 리소스 관리를 참조하세요.
지역에서 데이터 팩터리의 위치를 선택합니다. 지원되는 위치만 드롭다운 목록에 표시됩니다. 데이터 팩터리에서 사용되는 데이터 저장소(예: Azure Storage, SQL Database) 및 계산(예: Azure HDInsight)은 다른 지역에 있을 수 있습니다.
이름에 ADFTutorialDataFactory를 입력합니다.
Azure Data Factory의 이름은 전역적으로 고유해야 합니다. 이름 값에 대한 오류 메시지가 표시되면 데이터 팩터리에 대한 다른 이름을 입력합니다. (예: yournameADFTutorialDataFactory). Data Factory 아티팩트에 대한 명명 규칙은 Data Factory 명명 규칙을 참조하세요.
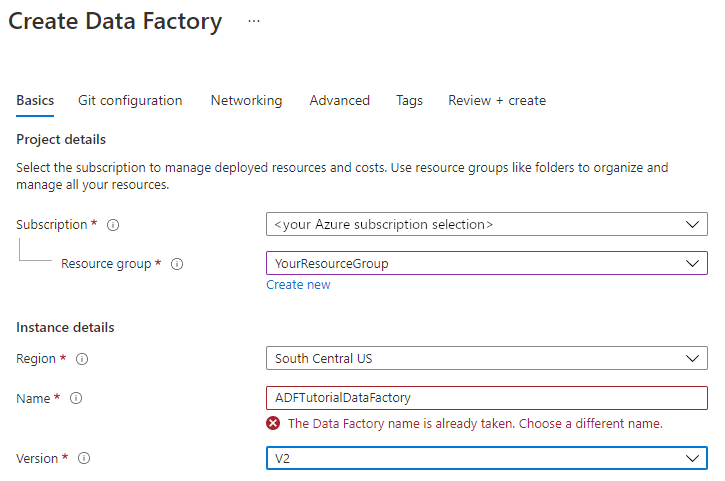
버전에서 V2를 선택합니다.
상단에 있는 Git 구성 탭을 선택하고 나중에 Git 구성 확인란을 선택합니다.
검토 + 만들기를 선택하고 유효성 검사를 통과한 후 만들기를 선택합니다.
만들기가 완료되면 알림 센터에 알림이 표시됩니다. 리소스로 이동을 선택하여 Data Factory 페이지로 이동합니다.
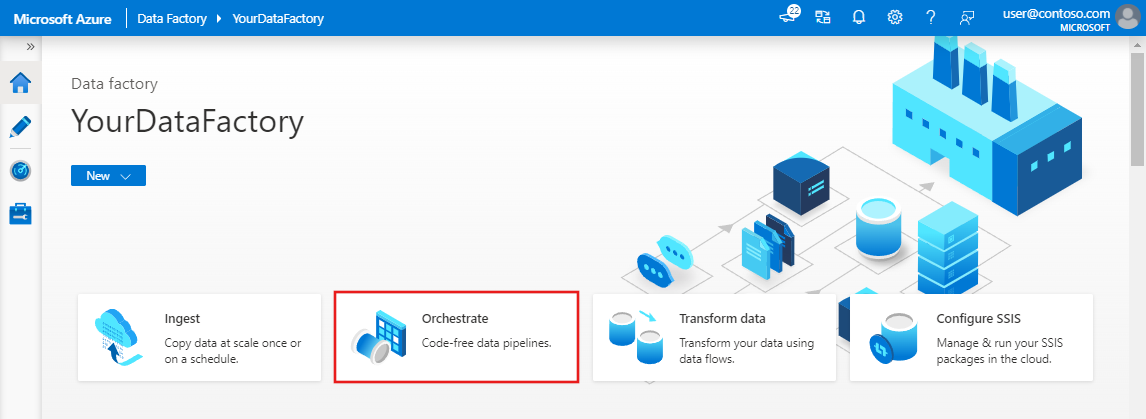
Azure Data Factory Studio 열기 타일에서 열기를 선택하여 별도의 탭에서 Azure Data Factory UI를 시작합니다.
파이프라인을 만듭니다.
이 단계에서는 복사 활동이 있는 파이프라인을 데이터 팩터리에 만듭니다. 복사 활동은 Blob Storage에서 SQL Database로 데이터를 복사합니다. 빠른 시작 자습서에서 다음 단계에 따라 파이프라인을 만들었습니다.
- 연결된 서비스를 만듭니다.
- 입력 및 출력 데이터 세트를 만듭니다.
- 파이프라인 만들기
이 자습서에서는 파이프라인을 만드는 것부터 시작합니다. 그런 다음, 파이프라인을 구성해야 할 때 연결된 서비스와 데이터 세트를 만듭니다.
홈페이지에서 오케스트레이션을 선택합니다.
속성 아래의 일반 패널에서 이름에 CopyPipeline을 지정합니다. 그런 다음, 오른쪽 위에 있는 속성 아이콘을 클릭하여 패널을 축소합니다.
활동 도구 상자에서 이동 및 변환 범주를 펼치고, 데이터 복사 활동을 도구 상자에서 파이프라인 디자이너 화면으로 끌어서 놓습니다. 이름에 대해 CopyFromBlobToSql을 지정합니다.

원본 구성
팁
이 자습서에서는 계정 키를 원본 데이터 저장소의 인증 형식으로 사용하지만 지원되는 다른 인증 방법을 선택할 수 있습니다. 필요한 경우 SAS URI, 서비스 주체 및 관리 ID를 선택합니다. 자세한 내용은 이 문서의 해당 섹션을 참조하세요. 데이터 저장소에 대한 비밀을 안전하게 저장하려면 Azure Key Vault를 사용하는 것도 좋습니다. 자세한 그림은 이 문서를 참조하세요.
원본 탭으로 이동합니다. + 새로 만들기를 선택하여 원본 데이터 세트를 만듭니다.
새 데이터 세트 대화 상자에서 Azure Blob Storage를 선택한 다음, 계속을 선택합니다. 원본 데이터는 Blob 스토리지에 있으므로 원본 데이터 세트으로 Azure Blob Storage를 선택합니다.
형식 선택 대화 상자에서 데이터의 형식 유형을 선택한 다음, 계속을 선택합니다.
속성 설정 대화 상자에서 이름에 SourceBlobDataset를 입력합니다. 헤더로 첫 번째 행의 확인란을 선택합니다. 연결된 서비스 텍스트 상자에서 + 새로 만들기를 선택합니다.
새로 연결된 서비스(Azure Blob Storage) 대화 상자에서 AzureStorageLinkedService를 이름으로 입력하고, 스토리지 계정 이름 목록에서 스토리지 계정을 선택합니다. 연결을 테스트하고 만들기를 선택하여 연결된 서비스를 배포합니다.
연결된 서비스가 생성된 후 속성 설정 페이지로 다시 이동합니다. 파일 경로 옆에 있는 찾아보기를 선택합니다.
adftutorial/input 폴더로 이동하여 emp.txt 파일을 선택한 다음, 확인을 선택합니다.
확인을 선택합니다. 자동으로 파이프라인 페이지로 이동합니다. 원본 탭에서 SourceBlobDataset가 선택되어 있는지 확인합니다. 이 페이지에서 데이터를 미리 보려면 데이터 미리 보기를 선택합니다.

싱크 구성
팁
이 자습서에서는 SQL 인증을 싱크 데이터 저장소의 인증 형식으로 사용하지만 지원되는 다른 인증 방법을 선택할 수 있습니다. 필요한 경우 서비스 주체 및 관리 ID를 선택합니다. 자세한 내용은 이 문서의 해당 섹션을 참조하세요. 데이터 저장소에 대한 비밀을 안전하게 저장하려면 Azure Key Vault를 사용하는 것도 좋습니다. 자세한 그림은 이 문서를 참조하세요.
싱크 탭으로 이동하고, + 새로 만들기를 선택하여 싱크 데이터 세트를 만듭니다.
새 데이터 세트 대화 상자에서 검색 상자에 “SQL”을 입력하여 커넥터를 필터링하고, Azure SQL Database를 선택한 다음, 마침을 선택합니다. 이 자습서에서는 데이터를 SQL 데이터베이스에 복사합니다.
속성 설정 대화 상자에서 이름에 OutputSqlDataset를 입력합니다. 연결된 서비스 드롭다운 목록에서 + 새로 만들기를 선택합니다. 데이터 세트는 연결된 서비스와 연결되어야 합니다. 연결된 서비스에는 런타임에 Data Factory에서 SQL Database에 연결하는 데 사용하는 연결 문자열 있습니다. 데이터 세트는 데이터가 복사될 컨테이너, 폴더 및 파일(선택 사항)을 지정합니다.
새로 연결된 서비스(Azure SQL Database) 대화 상자에서 다음 단계를 수행합니다.
a. 이름 아래에서 AzureSqlDatabaseLinkedService를 입력합니다.
b. 서버 이름 아래에서 SQL Server 인스턴스를 선택합니다.
c. 데이터베이스 이름 아래에서 데이터베이스를 선택합니다.
d. 사용자 이름 아래에서 사용자의 이름을 입력합니다.
e. 암호 아래에서 사용자의 암호를 입력합니다.
f. 연결 테스트를 선택하여 연결을 테스트합니다.
g. 만들기를 선택하여 연결된 서비스를 배포합니다.

자동으로 속성 설정 대화 상자로 이동합니다. 테이블에서 [dbo].[emp]를 선택합니다. 그런 다음 확인을 선택합니다.
파이프라인이 있는 탭으로 이동하고, 싱크 데이터 세트에서 OutputSqlDataset가 선택되어 있는지 확인합니다.

복사 작업의 스키마 매핑을 따라 선택적으로 원본 스키마를 대상의 해당 스키마에 매핑할 수 있습니다.
파이프라인 유효성 검사
파이프라인에 대한 유효성을 검사하려면 도구 모음에서 유효성 검사를 선택합니다.
오른쪽 위에서 코드를 클릭하면 파이프라인과 연결된 JSON 코드를 볼 수 있습니다.
파이프라인 디버그 및 게시
아티팩트(연결된 서비스, 데이터 세트 및 파이프라인)를 Data Factory 또는 고유한 Azure Repos Git 리포지토리에 게시하기 전에 파이프라인을 디버그할 수 있습니다.
파이프라인을 디버그하려면 도구 모음에서 디버그를 선택합니다. 창의 아래쪽에 있는 출력 탭에서 파이프라인 실행 상태가 표시됩니다.
파이프라인이 성공적으로 실행되면 위쪽 도구 모음에서 모두 게시를 선택합니다. 이 작업은 사용자가 생성된 엔터티(데이터 세트 및 파이프라인)를 Data Factory에 게시합니다.
게시됨 메시지가 표시될 때까지 기다립니다. 알림 메시지를 보려면 오른쪽 위에서 알림 표시(종 모양 단추)를 클릭합니다.
수동으로 파이프라인 트리거
이 단계에서는 이전 단계에서 게시한 파이프라인을 수동으로 트리거합니다.
도구 모음에서 트리거를 선택한 다음 지금 트리거를 선택합니다. 파이프라인 실행 페이지에서 확인을 선택합니다.
왼쪽의 모니터 탭으로 이동합니다. 수동 트리거로 트리거되는 파이프라인 실행이 표시됩니다. 파이프라인 이름 열 아래의 링크를 사용하여 활동 세부 정보를 보고 파이프라인을 다시 실행할 수 있습니다.

파이프라인 실행과 관련된 활동 실행을 보려면 파이프라인 이름 열에서 CopyPipeline 링크를 선택합니다. 이 예제에서는 활동이 하나뿐이므로 목록에 하나의 항목만 표시됩니다. 복사 작업에 대한 자세한 내용을 보려면 활동 이름 열에서 세부 정보 링크(안경 아이콘)를 선택합니다. 파이프라인 실행 보기로 돌아가려면 위쪽에 있는 모든 파이프라인 실행을 선택합니다. 보기를 새로 고치려면 새로 고침을 선택합니다.

데이터베이스의 emp 테이블에 둘 이상의 행이 추가되어 있는지 확인합니다.

일정에 따라 파이프라인 트리거
이 일정에서 파이프라인에 대한 스케줄러 트리거를 만듭니다. 트리거는 지정된 일정(예: 매시간, 매일)에 따라 파이프라인을 실행합니다. 여기에서는 지정된 종료 날짜/시간까지 매분마다 실행되도록 트리거를 설정합니다.
왼쪽의 모니터링 탭 위에서 작성 탭으로 이동합니다.
파이프라인으로 이동하고, 도구 모음에서 트리거를 클릭하고, 새로 만들기/편집을 선택합니다.
트리거 추가 대화 상자에서 트리거 선택 영역에 + 새로 만들기를 선택합니다.
새 트리거 창에서 다음 단계를 수행합니다.
a. 이름 아래에서 RunEveryMinute를 입력합니다.
b. 트리거의 시작 날짜를 업데이트합니다. 날짜가 현재 날짜/시간 이전인 경우 변경 내용이 게시되면 트리거가 적용되기 시작합니다.
c. 표준 시간대에서 드롭다운 목록을 선택합니다.
d. 되풀이를 1분마다로 설정합니다.
e. 종료일 지정 확인란을 선택하고 종료 날짜 부분을 현재 날짜/시간보다 몇 분 늦게 업데이트합니다. 트리거는 변경 내용을 게시한 후에만 활성화됩니다. 몇 분 이후로 설정하고 그때까지 게시하지 않으면 트리거 실행이 표시되지 않습니다.
f. 활성화됨 옵션에서 예를 선택합니다.
g. 확인을 선택합니다.
Important
비용은 각 파이프라인 실행과 연결되므로 종료 날짜를 적절하게 설정합니다.
트리거 편집 페이지에서 경고를 검토한 다음, 저장을 선택합니다. 다음 예의 파이프라인은 매개 변수를 사용하지 않습니다.
모두 게시를 클릭하여 변경 내용을 게시합니다.
왼쪽의 모니터 탭으로 이동하여 트리거된 파이프라인 실행을 확인합니다.

파이프라인 실행 보기에서 트리거 실행 보기로 전환하려면 창 왼쪽에서 트리거 실행을 선택합니다.
목록에서 트리거 실행이 표시됩니다.
지정된 종료 시간까지 각 파이프라인 실행에 대해 분당 두 행이 emp 테이블에 삽입되었는지 확인합니다.
관련 콘텐츠
이 샘플의 파이프라인이 Blob Storage의 위치 간에 데이터를 복사합니다. 다음 방법에 대해 알아보았습니다.
- 데이터 팩터리를 만듭니다.
- 복사 활동이 있는 파이프라인 만들기
- 파이프라인 실행 테스트
- 수동으로 파이프라인 트리거
- 일정에 따라 파이프라인 트리거
- 파이프라인 및 작업 실행을 모니터링합니다.
온-프레미스에서 클라우드로 데이터를 복사하는 방법을 알아보려면 다음 자습서로 계속 진행하세요.