Apache Kafka 및 Azure Databricks를 사용하여 스트림 처리
이 문서에서는 Azure Databricks에서 구조적 스트리밍 워크로드를 실행할 때 Apache Kafka를 원본 또는 싱크로 사용하는 방법을 설명합니다.
Kafka에 대한 자세한 내용은 Kafka 설명서를 참조 하세요.
Kafka에서 데이터 읽기
다음은 Kafka에서 읽은 스트리밍의 예입니다.
df = (spark.readStream
.format("kafka")
.option("kafka.bootstrap.servers", "<server:ip>")
.option("subscribe", "<topic>")
.option("startingOffsets", "latest")
.load()
)
또한 Azure Databricks는 다음 예제와 같이 Kafka 데이터 원본에 대한 일괄 읽기 의미 체계를 지원합니다.
df = (spark
.read
.format("kafka")
.option("kafka.bootstrap.servers", "<server:ip>")
.option("subscribe", "<topic>")
.option("startingOffsets", "earliest")
.option("endingOffsets", "latest")
.load()
)
증분 일괄 로드의 경우 Databricks는 Kafka와 함께 Trigger.AvailableNow사용하는 것이 좋습니다. 증분 일괄 처리 구성을 참조하세요.
Databricks Runtime 13.3 LTS 이상에서 Azure Databricks는 Kafka 데이터를 읽기 위한 SQL 함수를 제공합니다. SQL을 사용한 스트리밍은 Delta Live Tables 또는 Databricks SQL의 스트리밍 테이블에서만 지원됩니다. 테이블 반환 함수 read_kafka 참조하세요.
Kafka 구조적 스트리밍 판독기 구성
Azure Databricks는 Kafka 0.10 이상에 대한 연결을 구성하는 데이터 형식으로 키워드(keyword) 제공합니다 kafka .
다음은 Kafka에 대한 가장 일반적인 구성입니다.
구독할 토픽을 지정하는 방법에는 여러 가지가 있습니다. 다음 매개 변수 중 하나만 제공해야 합니다.
| 옵션 | 값 | 설명 |
|---|---|---|
| 구독 | 쉼표로 구분된 토픽 목록입니다. | 구독할 토픽 목록입니다. |
| subscribePattern | Java regex 문자열입니다. | 토픽을 구독하는 데 사용되는 패턴입니다. |
| 할당 | JSON 문자열 {"topicA":[0,1],"topic":[2,4]}입니다. |
사용할 특정 topicPartitions입니다. |
기타 주목할 만한 구성:
| 옵션 | 값 | 기본값 | 설명 |
|---|---|---|---|
| kafka.bootstrap.servers | 쉼표로 구분된 호스트:포트 목록입니다. | empty | [필수] Kafka bootstrap.servers 구성입니다. Kafka의 데이터가 없는 경우 먼저 브로커 주소 목록을 확인합니다. 브로커 주소 목록이 잘못된 경우 오류가 없을 수도 있습니다. Kafka 클라이언트는 결국 브로커가 사용 가능해지고, 네트워크 오류가 발생할 경우 영구적으로 다시 시도한다고 가정하기 때문입니다. |
| failOnDataLoss | true 또는 false. |
true |
[선택 사항] 데이터가 손실되었을 수 있는 경우 쿼리에 실패할지 여부입니다. 삭제된 토픽, 처리 전 토픽 잘림 등의 많은 시나리오로 인해 쿼리가 Kafka에서 데이터를 영구적으로 읽지 못할 수 있습니다. 데이터가 손실되었을 수 있는지 여부를 보수적으로 추정하려고 합니다. 이로 인해 거짓 경보가 발생하는 경우도 있습니다. 예상대로 작동하지 않거나 데이터 손실에 관계없이 쿼리를 계속 처리하려는 경우 이 옵션을 false로 설정합니다. |
| minPartitions | 정수 >= 0, 0 = 사용 안 함 | 0(사용 안 함) | [선택 사항] Kafka에서 읽을 최소 파티션 수입니다. 옵션을 사용하여 Kafka에서 읽을 임의의 최소 파티션을 사용하도록 Spark를 minPartitions 구성할 수 있습니다. 일반적으로 Spark는 Kafka에서 사용하는 Spark 파티션과 Kafka topicPartitions를 일대일로 매핑합니다. minPartitions 옵션을 Kafka topicPartitions보다 큰 값으로 설정하는 경우 Spark는 큰 Kafka 파티션을 더 작은 부분으로 분할합니다. 최대 부하, 데이터 기울이기, 스트림 지연 시 이 옵션을 설정하여 처리 속도를 높일 수 있습니다. 대신, 각 트리거에서 Kafka 소비자를 초기화해야 하므로 Kafka에 연결할 때 SSL을 사용하는 경우 성능에 영향을 미칠 수 있습니다. |
| kafka.group.id | Kafka 소비자 그룹 ID입니다. | 미설정 | [선택 사항] Kafka에서 읽는 동안 사용할 그룹 ID입니다. 사용 시 주의해야 합니다. 기본적으로 각 쿼리는 데이터를 읽기 위해 고유한 그룹 ID를 생성합니다. 따라서 각 쿼리에 다른 소비자의 간섭을 받지 않는 자체 소비자 그룹이 있으므로 구독된 토픽의 모든 파티션을 읽을 수 있습니다. 일부 시나리오(예: Kafka 그룹 기반 권한 부여)에서는 권한 있는 특정 그룹 ID를 사용하여 데이터를 읽는 것이 좋습니다. 필요에 따라 그룹 ID를 설정할 수 있습니다. 그러나 예기치 않은 동작이 발생할 수 있으므로 작업 시 주의해야 합니다. * 동일한 그룹 ID로 쿼리(일괄 처리 및 스트리밍)를 동시에 실행할 경우 서로 간섭하여 각 쿼리가 데이터의 일부만 읽게 될 수 있습니다. * 이 문제는 빠르게 연속해서 쿼리를 시작/다시 시작하는 경우에도 발생할 수 있습니다. 해당 이슈를 최소화하려면 Kafka 소비자 구성 session.timeout.ms를 매우 작게 설정합니다. |
| startingOffsets | earliest , latest | latest | [선택 사항] 쿼리가 시작될 때의 시작점, 가장 이른 오프셋의 "earliest"이거나 각 TopicPartition에 대한 시작 오프셋을 지정하는 json 문자열입니다. json에서 오프셋으로 -2를 사용하면 earliest를, -1을 사용하면 latest를 참조할 수 있습니다. 참고: 일괄 처리 쿼리의 경우 latest(묵시적으로 또는 json에서 -1 사용)은 허용되지 않습니다. 스트리밍 쿼리의 경우 이는 새 쿼리가 시작될 때만 적용되며, 항상 쿼리가 중단된 위치에서 다시 시작됩니다. 쿼리 중에 새로 검색된 파티션은 가장 일찍 시작됩니다. |
다른 선택적 구성은 구조적 스트리밍 Kafka 통합 가이드를 참조하세요.
Kafka 레코드에 대한 스키마
Kafka 레코드의 스키마는 다음과 같습니다.
| Column | 형식 |
|---|---|
| key | binary |
| value | binary |
| 토픽 | string |
| 파티션 | int |
| offset | long |
| timestamp | long |
| timestampType | int |
key와 value는 항상 ByteArrayDeserializer를 사용하여 바이트 배열로 역직렬화됩니다. 데이터 프레임 작업(예: cast("string"))을 사용하여 키와 값을 명시적으로 역직렬화합니다.
Kafka에 데이터 쓰기
다음은 Kafka에 대한 스트리밍 쓰기의 예입니다.
(df
.writeStream
.format("kafka")
.option("kafka.bootstrap.servers", "<server:ip>")
.option("topic", "<topic>")
.start()
)
또한 Azure Databricks는 다음 예제와 같이 Kafka 데이터 싱크에 대한 일괄 쓰기 의미 체계를 지원합니다.
(df
.write
.format("kafka")
.option("kafka.bootstrap.servers", "<server:ip>")
.option("topic", "<topic>")
.save()
)
Kafka 구조적 스트리밍 기록기 구성
Important
Databricks Runtime 13.3 LTS 이상에는 기본적으로 idempotent 쓰기를 사용하도록 설정하는 최신 버전의 kafka-clients 라이브러리가 포함되어 있습니다. Kafka 싱크에서 ACL이 구성된 버전 2.8.0 이하를 사용하지만 사용하도록 설정하지 않으면 IDEMPOTENT_WRITE 오류 메시지 org.apache.kafka.common.KafkaException:Cannot execute transactional method because we are in an error state와 함께 쓰기가 실패합니다.
Kafka 버전 2.8.0 이상으로 업그레이드하거나 구조적 스트리밍 기록기를 구성하는 동안 설정 .option(“kafka.enable.idempotence”, “false”) 하여 이 오류를 해결합니다.
DataStreamWriter에 제공된 스키마는 Kafka 싱크와 상호 작용합니다. 다음 필드를 사용할 수 있습니다.
| 열 이름 | 필수 또는 선택 사항 | Type |
|---|---|---|
key |
{b>선택 사항STRING 또는 BINARY | |
value |
필수 | STRING 또는 BINARY |
headers |
{b>선택 사항ARRAY | |
topic |
선택 사항(기록기 옵션으로 설정된 경우 topic 무시됨) |
STRING |
partition |
{b>선택 사항INT |
다음은 Kafka에 쓰는 동안 설정된 일반적인 옵션입니다.
| 옵션 | 값 | 기본값 | 설명 |
|---|---|---|---|
kafka.boostrap.servers |
쉼표로 구분된 목록 <host:port> |
없음 | [필수] Kafka bootstrap.servers 구성입니다. |
topic |
STRING |
미설정 | [선택 사항] 작성할 모든 행에 대한 토픽을 설정합니다. 이 옵션은 데이터에 있는 모든 토픽 열을 재정의합니다. |
includeHeaders |
BOOLEAN |
false |
[선택 사항] 행에 Kafka 헤더를 포함할지 여부입니다. |
다른 선택적 구성은 구조적 스트리밍 Kafka 통합 가이드를 참조하세요.
Kafka 메트릭 검색
avgOffsetsBehindLatest, maxOffsetsBehindLatest, minOffsetsBehindLatest 메트릭을 사용하여 스트리밍 쿼리가 구독된 모든 토픽에서 사용 가능한 최신 오프셋보다 지연된 오프셋 수의 평균, 최솟값, 최댓값을 가져올 수 있습니다. 대화형으로 메트릭 읽기를 참조하세요.
참고 항목
Databricks Runtime 9.1 이상에서 사용 가능합니다.
estimatedTotalBytesBehindLatest 값을 검사하여 구독된 토픽에서 쿼리 프로세스가 사용하지 않은 예상 총 바이트 수를 가져옵니다. 이 추정치는 지난 300초 동안 처리된 일괄 처리를 기반으로 합니다. bytesEstimateWindowLength 옵션을 다른 값으로 설정하여 추정치의 기반이 되는 기간을 변경할 수 있습니다. 예를 들어 10분으로 설정하려면 다음을 수행합니다.
df = (spark.readStream
.format("kafka")
.option("bytesEstimateWindowLength", "10m") # m for minutes, you can also use "600s" for 600 seconds
)
Notebook에서 스트림을 실행하는 경우 스트리밍 쿼리 진행률 대시보드의 원시 데이터 탭 아래에서 이러한 메트릭을 볼 수 있습니다.
{
"sources" : [ {
"description" : "KafkaV2[Subscribe[topic]]",
"metrics" : {
"avgOffsetsBehindLatest" : "4.0",
"maxOffsetsBehindLatest" : "4",
"minOffsetsBehindLatest" : "4",
"estimatedTotalBytesBehindLatest" : "80.0"
},
} ]
}
SSL을 사용하여 Azure Databricks를 Kafka에 연결
Kafka에 대한 SSL 연결을 사용하도록 설정하려면 Confluent 설명서인 SSL을 사용한 암호화 및 인증의 지침을 따르세요. 해당 문서에서 설명하는, kafka. 접두사가 붙은 구성을 옵션으로 제공할 수 있습니다. 예를 들어 kafka.ssl.truststore.location 속성에 신뢰 저장소 위치를 지정합니다.
Databricks는 다음을 권장합니다.
- 인증서를 클라우드 개체 스토리지에 저장합니다. 인증서에 대한 액세스를 Kafka에 액세스할 수 있는 클러스터로만 제한할 수 있습니다. Unity 카탈로그를 사용하여 데이터 거버넌스를 참조 하세요.
- 인증서 암호를 비밀 범위에 비밀로 저장합니다.
다음 예제에서는 개체 스토리지 위치 및 Databricks 비밀을 사용하여 SSL 연결을 사용하도록 설정합니다.
df = (spark.readStream
.format("kafka")
.option("kafka.bootstrap.servers", ...)
.option("kafka.security.protocol", "SASL_SSL")
.option("kafka.ssl.truststore.location", <truststore-location>)
.option("kafka.ssl.keystore.location", <keystore-location>)
.option("kafka.ssl.keystore.password", dbutils.secrets.get(scope=<certificate-scope-name>,key=<keystore-password-key-name>))
.option("kafka.ssl.truststore.password", dbutils.secrets.get(scope=<certificate-scope-name>,key=<truststore-password-key-name>))
)
Azure Databricks에 HDInsight의 Kafka 연결
HDInsight Kafka 클러스터를 만듭니다.
관련 지침은 Azure Virtual Network를 통해 HDInsight의 Kafka에 연결을 참조하세요.
올바른 주소를 보급하도록 Kafka 브로커를 구성합니다.
IP 보급을 위해 Kafka 구성의 지침을 따르세요. Azure Virtual Machines에서 Kafka를 직접 관리하는 경우 브로커의
advertised.listeners구성이 호스트의 내부 IP로 설정되어 있는지 확인합니다.Azure Databricks 클러스터를 만듭니다.
Kafka 클러스터를 Azure Databricks 클러스터에 피어링합니다.
가상 네트워크 피어링의 지침을 따르세요.
Microsoft Entra ID(이전의 Azure Active Directory) 및 Azure Event Hubs를 사용한 서비스 주체 인증
Azure Databricks는 Event Hubs 서비스를 사용하여 Spark 작업의 인증을 지원합니다. 이 인증은 Microsoft Entra ID(이전의 Azure Active Directory)를 사용하여 OAuth를 통해 수행됩니다.
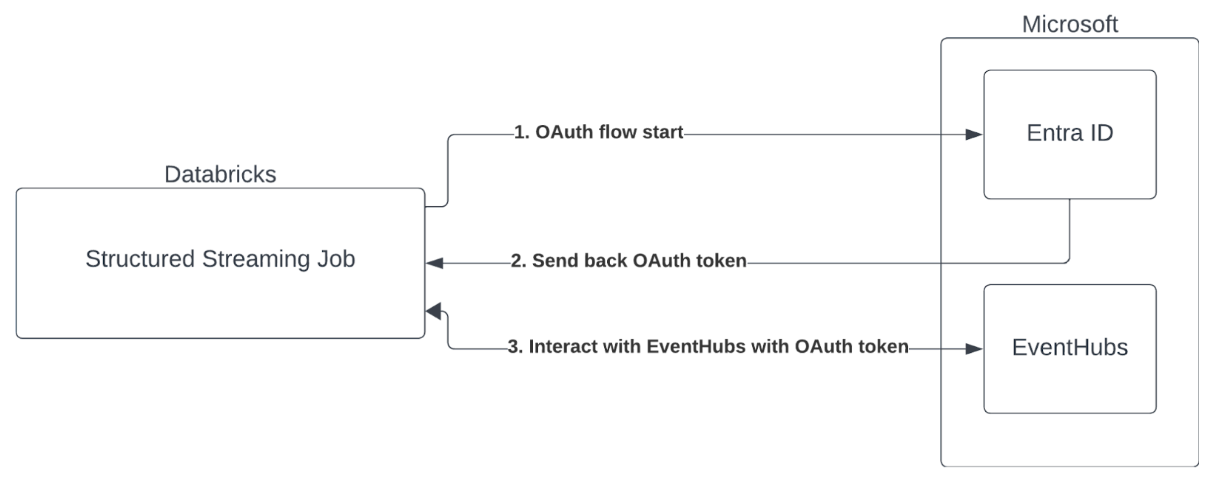
Azure Databricks는 다음 컴퓨팅 환경에서 클라이언트 ID 및 비밀을 사용하여 Microsoft Entra ID 인증을 지원합니다.
- 단일 사용자 액세스 모드로 구성된 컴퓨팅에서 Databricks Runtime 12.2 LTS 이상.
- 공유 액세스 모드로 구성된 컴퓨팅의 Databricks Runtime 14.3 LTS 이상.
- Unity 카탈로그 없이 구성된 Delta Live Tables 파이프라인입니다.
Azure Databricks는 모든 컴퓨팅 환경 또는 Unity 카탈로그로 구성된 Delta Live Tables 파이프라인에서 인증서를 사용하여 Microsoft Entra ID 인증을 지원하지 않습니다.
이 인증은 공유 클러스터 또는 Unity 카탈로그 델타 라이브 테이블에서 작동하지 않습니다.
구조적 스트리밍 Kafka 커넥트or 구성
Microsoft Entra ID로 인증을 수행하려면 다음 값이 필요합니다.
테넌트 ID입니다. Microsoft Entra ID 서비스 탭에서 찾을 수 있습니다.
clientID(애플리케이션 ID라고도 함)입니다.
클라이언트 암호입니다. 이 작업이 완료되면 Databricks 작업 영역에 비밀로 추가해야 합니다. 이 비밀을 추가하려면 비밀 관리를 참조하세요.
EventHubs 토픽입니다. 특정 Event Hubs 네임스페이스 페이지의 엔터티 섹션 아래에 있는 Event Hubs 섹션에서 항목 목록을 찾을 수 있습니다. 여러 항목을 사용하려면 Event Hubs 수준에서 IAM 역할을 설정할 수 있습니다.
EventHubs 서버입니다. 특정 Event Hubs 네임스페이스의 개요 페이지에서 찾을 수 있습니다.
또한 Entra ID를 사용하려면 Kafka에 OAuth SASL 메커니즘을 사용하도록 지시해야 합니다(SASL은 제네릭 프로토콜이며 OAuth는 SASL "메커니즘"의 한 유형임).
kafka.security.protocol이어야 합니다.SASL_SSLkafka.sasl.mechanism이어야 합니다.OAUTHBEARERkafka.sasl.login.callback.handler.class은 음영 처리된 Kafka 클래스의 로그인 콜백 처리기 값kafkashaded이 있는 Java 클래스의 정규화된 이름이어야 합니다. 정확한 클래스는 다음 예제를 참조하세요.
예시
다음으로 실행 중인 예제를 살펴보겠습니다.
Python
# This is the only section you need to modify for auth purposes!
# ------------------------------
tenant_id = "..."
client_id = "..."
client_secret = dbutils.secrets.get("your-scope", "your-secret-name")
event_hubs_server = "..."
event_hubs_topic = "..."
# -------------------------------
sasl_config = f'kafkashaded.org.apache.kafka.common.security.oauthbearer.OAuthBearerLoginModule required clientId="{client_id}" clientSecret="{client_secret}" scope="https://{event_hubs_server}/.default" ssl.protocol="SSL";'
kafka_options = {
# Port 9093 is the EventHubs Kafka port
"kafka.bootstrap.servers": f"{event_hubs_server}:9093",
"kafka.sasl.jaas.config": sasl_config,
"kafka.sasl.oauthbearer.token.endpoint.url": f"https://login.microsoft.com/{tenant_id}/oauth2/v2.0/token",
"subscribe": event_hubs_topic,
# You should not need to modify these
"kafka.security.protocol": "SASL_SSL",
"kafka.sasl.mechanism": "OAUTHBEARER",
"kafka.sasl.login.callback.handler.class": "kafkashaded.org.apache.kafka.common.security.oauthbearer.secured.OAuthBearerLoginCallbackHandler"
}
df = spark.readStream.format("kafka").options(**kafka_options)
display(df)
Scala
// This is the only section you need to modify for auth purposes!
// -------------------------------
val tenantId = "..."
val clientId = "..."
val clientSecret = dbutils.secrets.get("your-scope", "your-secret-name")
val eventHubsServer = "..."
val eventHubsTopic = "..."
// -------------------------------
val saslConfig = s"""kafkashaded.org.apache.kafka.common.security.oauthbearer.OAuthBearerLoginModule required clientId="$clientId" clientSecret="$clientSecret" scope="https://$eventHubsServer/.default" ssl.protocol="SSL";"""
val kafkaOptions = Map(
// Port 9093 is the EventHubs Kafka port
"kafka.bootstrap.servers" -> s"$eventHubsServer:9093",
"kafka.sasl.jaas.config" -> saslConfig,
"kafka.sasl.oauthbearer.token.endpoint.url" -> s"https://login.microsoft.com/$tenantId/oauth2/v2.0/token",
"subscribe" -> eventHubsTopic,
// You should not need to modify these
"kafka.security.protocol" -> "SASL_SSL",
"kafka.sasl.mechanism" -> "OAUTHBEARER",
"kafka.sasl.login.callback.handler.class" -> "kafkashaded.org.apache.kafka.common.security.oauthbearer.secured.OAuthBearerLoginCallbackHandler"
)
val scalaDF = spark.readStream
.format("kafka")
.options(kafkaOptions)
.load()
display(scalaDF)
잠재적 오류 처리
스트리밍 옵션은 지원되지 않습니다.
Unity 카탈로그로 구성된 Delta Live Tables 파이프라인에서 이 인증 메커니즘을 사용하려고 하면 다음 오류가 발생할 수 있습니다.
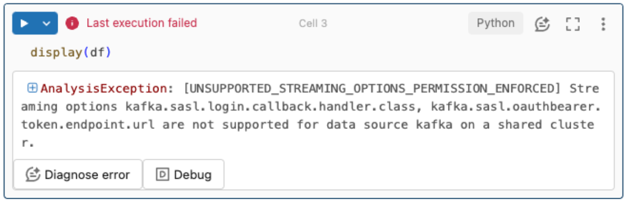
이 오류를 해결하려면 지원되는 컴퓨팅 구성을 사용합니다. Microsoft Entra ID(이전의 Azure Active Directory) 및 Azure Event Hubs를 사용하여 서비스 주체 인증을 참조 하세요.
새
KafkaAdminClient를 만들지 못했습니다.다음 인증 옵션이 올바르지 않으면 Kafka에서 throw하는 내부 오류입니다.
- 클라이언트 ID(애플리케이션 ID라고도 함)
- 테넌트 ID
- EventHubs 서버
오류를 해결하려면 이러한 옵션에 대한 값이 올바른지 확인합니다.
또한 예제에서 기본적으로 제공된 구성 옵션을 수정하는 경우(수정하지 말라는 요청을 받은 경우)
kafka.security.protocol이 오류가 표시될 수 있습니다.반환되는 레코드가 없습니다.
DataFrame을 표시하거나 처리하려고 하지만 결과가 표시되지 않는 경우 UI에 다음이 표시됩니다.
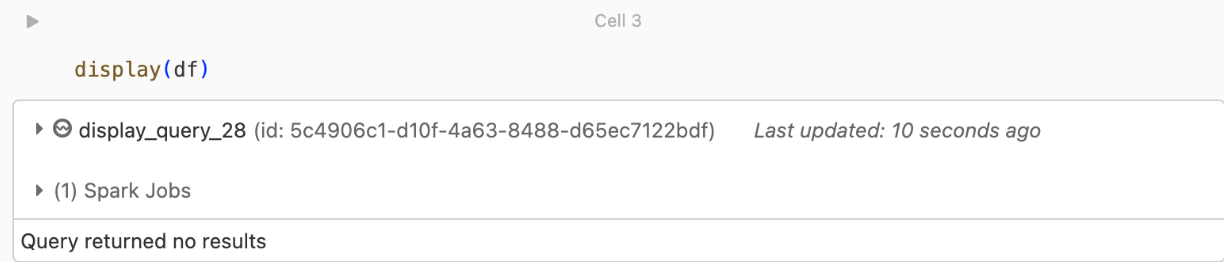
이 메시지는 인증에 성공했지만 EventHubs에서 데이터를 반환하지 않았음을 의미합니다. 가능한 몇 가지 이유는 다음과 같습니다(완전하지는 않지만).
- 잘못된 EventHubs 항목을 지정했습니다 .
- 기본 Kafka 구성 옵션은
startingOffsets이며, 현재 토픽을 통해 데이터를 받지 못하고 있습니다. Kafka의 초기 오프셋부터 데이터 읽기를 시작하도록 설정할startingOffsetstoearliest수 있습니다.