Azure Databricks 작업 만들기 및 실행
이 문서에서는 작업 UI를 사용하여 Azure Databricks 작업을 만들고 실행하는 방법을 자세히 설명합니다.
작업에 대한 구성 옵션 및 기존 작업을 편집하는 방법에 대한 자세한 내용은 Azure Databricks 작업에 대한 설정 구성을 참조하세요.
작업 실행을 관리하고 모니터링하는 방법을 알아보려면 작업 실행 보기 및 관리를 참조하세요.
Azure Databricks 작업을 사용하여 첫 번째 워크플로를 만들려면 빠른 시작을 참조하세요.
Important
- 작업 영역은 1000개의 동시 작업 실행으로 제한됩니다. 즉시 시작할 수 없는 실행을 요청하면
429 Too Many Requests응답이 반환됩니다. - 작업 영역에서 한 시간 내에 만들 수 있는 작업 수는 10000개로 제한됩니다("실행 제출" 포함). 이 제한은 REST API 및 Notebook 워크플로에 의해 만들어진 작업에도 영향을 줍니다.
CLI, API 또는 Notebook을 사용하여 작업 만들기 및 실행
- Databricks CLI를 사용하여 작업을 만들고 실행하는 방법에 대한 자세한 내용은 Databricks CLI란?을 참조하세요.
- 작업 API를 사용하여 작업을 만들고 실행하는 방법에 대한 자세한 내용은 REST API 참조의 작업을 참조하세요.
- Databricks Notebook에서 직접 작업을 실행하고 예약하는 방법을 알아보려면 예약된 Notebook 작업 만들기 및 관리를 참조 하세요.
작업 만들기
다음 중 하나를 수행합니다.
- 사이드바에서 워크플로를 클릭하고 을 클릭합니다
 .
.
- 사이드바에서 새로 만들기를 클릭하고
 작업을 선택합니다.
작업을 선택합니다.
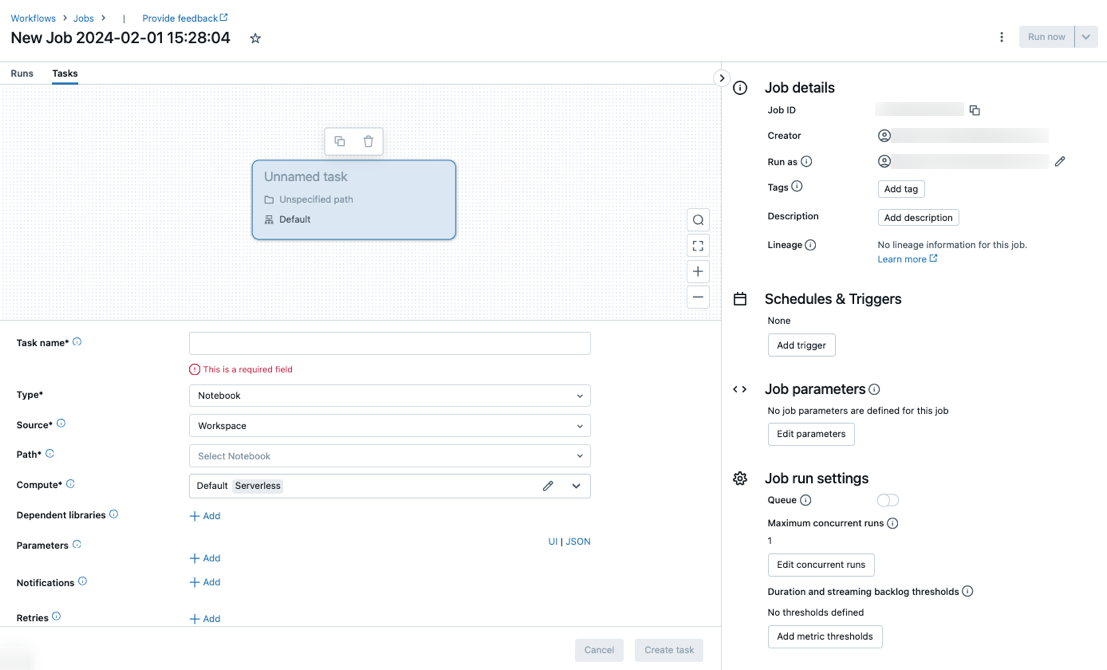
작업 탭은 작업 수준 설정을 포함하는 작업 세부 정보 측면 패널과 함께 작업 만들기 대화 상자와 함께 나타납니다.
- 사이드바에서 워크플로를 클릭하고 을 클릭합니다
새 작업을 작업 이름으로 대체합니다.
태스크 이름 필드에 태스크의 이름을 입력합니다.
태스크가 실행되는 클러스터를 구성합니다. 기본적으로 작업 영역이 Unity 카탈로그 사용 작업 영역에 있고 워크플로에 대해 서버리스 컴퓨팅에서 지원하는 작업을 선택한 경우 서버리스 컴퓨팅이 선택됩니다. 워크플로에 대한 서버리스 컴퓨팅을 사용하여 Azure Databricks 작업 실행을 참조 하세요. 서버리스 컴퓨팅을 사용할 수 없거나 다른 컴퓨팅 유형을 사용하려는 경우 컴퓨팅 드롭다운 메뉴에서 새 작업 클러스터 또는 기존 다목적 클러스터를 선택할 수 있습니다.
- 새 작업 클러스터: 클러스터 드롭다운 메뉴에서 편집 을 클릭하고 클러스터 구성을 완료합니다.
- 기존 다목적 클러스터: 클러스터 드롭다운 메뉴에서 기존 클러스터를 선택합니다. 새 페이지에서 클러스터를 열려면 클러스터 이름 및 설명의 오른쪽에 있는 아이콘을 클릭합니다
 .
.
작업을 실행하도록 클러스터를 선택하고 구성하는 방법에 대한 자세한 내용은 작업과 함께 Azure Databricks 컴퓨팅 사용을 참조하세요.
종속 라이브러리를 추가하려면 + 종속 라이브러리 옆에 추가를 클릭합니다. 종속 라이브러리 구성을 참조하세요.
태스크에 대한 매개 변수를 전달할 수 있습니다. 매개 변수 서식 지정 및 전달 요구 사항에 대한 자세한 내용은 Azure Databricks 작업 태스크에 매개 변수 전달을 참조 하세요.
필요에 따라 작업 시작, 성공 또는 실패에 대한 알림을 받으려면 + 전자 메일 옆에 추가를 클릭합니다. 오류 알림은 초기 작업 실패 및 후속 다시 시도 시 전송됩니다. 알림을 필터링하고 전송된 전자 메일 수를 줄이려면 건너뛴 실행에 대한 알림 음소거, 취소된 실행에 대한 알림 음소거 또는 마지막 다시 시도까지 알림 음소거를 검사.
필요에 따라 작업에 대한 재시도 정책을 구성하려면 다시 시도 옆에 있는 + 추가를 클릭합니다. 작업에 대한 재시도 정책 구성을 참조하세요.
필요에 따라 작업의 예상 기간 또는 시간 제한을 구성하려면 기간 임계값 옆에 있는 + 추가를 클릭합니다. 예상 완료 시간 또는 작업에 대한 시간 제한 구성을 참조하세요.
만들기를 클릭합니다.
첫 번째 작업을 만든 후 알림, 작업 트리거 및 권한과 같은 작업 수준 설정을 구성할 수 있습니다. 작업 편집을 참조하세요.
다른 작업을 추가하려면 DAG 보기를 클릭합니다  . 이전 작업에 대해 서버리스 컴퓨팅을 선택하거나 새 작업 클러스터를 구성한 경우 공유 클러스터 옵션이 제공됩니다. 태스크를 만들거나 편집할 때 각 태스크에 대해 클러스터를 구성할 수도 있습니다. 작업을 실행하도록 클러스터를 선택하고 구성하는 방법에 대한 자세한 내용은 작업과 함께 Azure Databricks 컴퓨팅 사용을 참조하세요.
. 이전 작업에 대해 서버리스 컴퓨팅을 선택하거나 새 작업 클러스터를 구성한 경우 공유 클러스터 옵션이 제공됩니다. 태스크를 만들거나 편집할 때 각 태스크에 대해 클러스터를 구성할 수도 있습니다. 작업을 실행하도록 클러스터를 선택하고 구성하는 방법에 대한 자세한 내용은 작업과 함께 Azure Databricks 컴퓨팅 사용을 참조하세요.
필요에 따라 알림, 작업 트리거 및 권한과 같은 작업 수준 설정을 구성할 수 있습니다. 작업 편집을 참조하세요. 작업 태스크와 공유되는 작업 수준 매개 변수를 구성할 수도 있습니다. 모든 작업 작업에 대한 매개 변수 추가를 참조 하세요.
작업 유형 옵션
다음은 Azure Databricks 작업에 추가할 수 있는 작업 유형과 다양한 작업 유형에 사용할 수 있는 옵션입니다.
Notebook: 원본 드롭다운 메뉴에서 작업 영역을 선택하여 Azure Databricks 작업 영역 폴더에 있는 Notebook 또는 원격 Git 리포지토리에 있는 Notebook에 대한 Git 공급자 를 사용합니다.
작업 영역: 파일 브라우저를 사용하여 Notebook을 찾아 Notebook 이름을 클릭한 다음, 확인을 클릭합니다.
Git 공급자: Git 참조 편집 또는 추가를 클릭하고 Git 리포지토리 정보를 입력합니다. 원격 Git 리포지토리에서 Notebook 사용을 참조 하세요.
참고 항목
총 Notebook 셀 출력(모든 Notebook 셀의 결합된 출력)에는 20MB 크기 제한이 적용됩니다. 또한 개별 셀 출력에는 8MB 크기 제한이 적용됩니다. 총 셀 출력 크기가 20MB를 초과하거나 개별 셀의 출력이 8MB보다 크면 실행이 취소되고 '실패'로 표시됩니다.
제한에 가깝거나 이를 초과하는 셀을 찾는 데 도움이 필요한 경우 다목적 클러스터에 대해 Notebook을 실행하고 이 Notebook 자동 저장 기술을 사용합니다.
JAR: 주 클래스를 지정합니다. main 메서드를 포함하는 클래스의 정규화된 이름(예:
org.apache.spark.examples.SparkPi)을 사용합니다. 그런 다음, 종속 라이브러리 아래에서 추가를 클릭하여 태스크를 실행하는 데 필요한 라이브러리를 추가합니다. 이러한 라이브러리 중 하나는 주 클래스를 포함해야 합니다.JAR 작업에 대한 자세한 내용은 Azure Databricks 작업에서 JAR 사용을 참조 하세요.
Spark 제출: 매개 변수 텍스트 상자에서 문자열의 JSON 배열 형식으로 지정된 주 클래스, 라이브러리 JAR 경로 및 모든 인수를 지정합니다. 다음 예제에서는 Apache Spark 예제에서
DFSReadWriteTest를 실행하도록 spark-submit 태스크를 구성합니다.["--class","org.apache.spark.examples.DFSReadWriteTest","dbfs:/FileStore/libraries/spark_examples_2_12_3_1_1.jar","/discover/databricks-datasets/README.md","/FileStore/examples/output/"]Important
spark-submit 태스크에는 몇 가지 제한 사항이 있습니다.
- spark-submit 태스크는 새 클러스터에서만 실행할 수 있습니다.
- spark-submit은 클러스터 자동 크기 조정을 지원하지 않습니다. 자동 크기 조정에 대한 자세한 내용은 클러스터 자동 크기 조정을 참조하세요.
- Spark-submit은 Databricks 유틸리티(dbutils) 참조를 지원하지 않습니다. Databricks 유틸리티를 사용하려면 JAR 태스크를 대신 사용합니다.
- Unity 카탈로그 사용 클러스터를 사용하는 경우 클러스터에서 할당 된 액세스 모드를 사용하는 경우에만 spark-submit이 지원됩니다. 공유 액세스 모드는 지원되지 않습니다.
- Spark 스트리밍 작업은 최대 동시 실행 수를 1보다 크게 설정할 수 없습니다. 스트리밍 작업은
"* * * * * ?"cron 식(매분)을 사용하여 실행되도록 설정해야 합니다. 스트리밍 작업은 지속적으로 실행되므로 항상 작업의 최종 작업이어야 합니다.
Python 스크립트: 원본 드롭다운 메뉴에서 Python 스크립트의 위치, 로컬 작업 영역의 스크립트에 대한 작업 영역, DBFS에 있는 스크립트의 DBFS 또는 Git 리포지토리에 있는 스크립트의 Git 공급자를 선택합니다. 경로 텍스트 상자에 Python 스크립트의 경로를 입력합니다.
작업 영역: Python 파일 선택 대화 상자에서 Python 스크립트를 찾아 확인을 클릭합니다.
DBFS: DBFS 또는 클라우드 스토리지에 있는 Python 스크립트의 URI를 입력합니다. 예:
dbfs:/FileStore/myscript.py.Git 공급자: 편집을 클릭하고 Git 리포지토리 정보를 입력합니다. 원격 Git 리포지토리에서 Python 코드 사용을 참조 하세요.
델타 라이브 테이블 파이프라인: 파이프라인 드롭다운 메뉴에서 기존 Delta Live Tables 파이프라인을 선택합니다.
Important
파이프라인 작업에는 트리거된 파이프라인만 사용할 수 있습니다. 연속 파이프라인은 작업으로 지원되지 않습니다. 트리거된 파이프라인 및 연속 파이프라인에 대한 자세한 내용은 연속 및 트리거된 파이프라인 실행을 참조하세요.
Python 휠: 패키지 이름 텍스트 상자에서 가져올 패키지를 입력합니다(예:
myWheel-1.0-py2.py3-none-any.whl). 진입점 텍스트 상자에 Python 휠 파일을 시작할 때 호출할 함수를 입력합니다. 종속 라이브러리 아래에서 추가를 클릭하여 태스크를 실행하는 데 필요한 라이브러리를 추가합니다.SQL: SQL 작업 드롭다운 메뉴에서 쿼리, 레거시 대시보드, 경고 또는 파일을 선택합니다.
참고 항목
- SQL 작업에는 Databricks SQL과 서버리스 또는 Pro SQL 웨어하우스가 필요합니다.
쿼리: SQL 쿼리 드롭다운 메뉴에서 태스크가 실행되면 실행할 쿼리를 선택합니다.
레거시 대시보드: SQL 대시보드 드롭다운 메뉴에서 작업이 실행될 때 업데이트할 대시보드를 선택합니다.
경고: SQL 경고 드롭다운 메뉴에서 평가를 위해 트리거할 경고를 선택합니다.
파일: Azure Databricks 작업 영역 폴더에 있는 SQL 파일을 사용하려면 원본 드롭다운 메뉴에서 작업 영역을 선택하고 파일 브라우저를 사용하여 SQL 파일을 찾고 파일 이름을 클릭한 다음 확인을 클릭합니다. 원격 Git 리포지토리에 있는 SQL 파일을 사용하려면 Git 공급자를 선택하고 Git 참조 편집 또는 추가를 클릭하고 Git 리포지토리에 대한 세부 정보를 입력합니다. 원격 Git 리포지토리에서 SQL 쿼리 사용을 참조 하세요.
SQL 웨어하우스 드롭다운 메뉴에서 서버를 사용하지 않는 SQL 웨어하우스 또는 PRO SQL 웨어하우스를 선택하여 작업을 실행합니다.
dbt: dbt 태스크를 구성하는 자세한 예제는 Azure Databricks 작업에서 dbt 변환 사용을 참조하세요.
작업 실행: 작업 드롭다운 메뉴에서 태스크에서 실행할 작업을 선택합니다. 실행할 작업을 검색하려면 작업 메뉴에 작업 이름을 입력하기 시작합니다.
Important
세
Run Job개 이상의 작업을 중첩하는 작업 또는 작업을 사용할Run Job때 순환 종속성이 있는 작업을 만들면 안 됩니다. 순환 종속성은Run Job직접 또는 간접적으로 서로를 트리거하는 작업입니다. 예를 들어 작업 A는 작업 B를 트리거하고 작업 B는 작업 A를 트리거합니다. Databricks는 순환 종속성이 있는 작업을 지원하지 않거나 세Run Job개 이상의 태스크를 중첩하여 향후 릴리스에서 이러한 작업을 실행하지 못할 수 있습니다.If/else: 작업을 사용하는
If/else condition방법을 알아보려면 If/else 조건 태스크를 사용하여 작업에 분기 논리 추가를 참조하세요.
Azure Databricks 작업 태스크에 매개 변수 전달
많은 작업 작업 유형에 매개 변수를 전달할 수 있습니다. 각 태스크 종류에는 매개 변수의 형식 지정 및 전달에 대한 별도의 요구 사항이 있습니다.
작업 이름과 같은 현재 작업에 대한 정보에 액세스하거나 작업 시작 시간 또는 현재 작업 실행의 식별자와 같은 작업 작업 간에 현재 실행에 대한 컨텍스트를 전달하려면 동적 값 참조를 사용합니다. 사용 가능한 동적 값 참조 목록을 보려면 동적 값 찾아보기를 클릭합니다.
작업이 속한 작업에 작업 매개 변수가 구성된 경우 작업 매개 변수를 추가할 때 해당 매개 변수가 표시됩니다. 작업 및 작업 매개 변수가 키를 공유하는 경우 작업 매개 변수가 우선합니다. 작업 매개 변수와 동일한 키를 사용하여 작업 매개 변수를 추가하려고 하면 UI에 경고가 표시됩니다. 작업 매개 변수를 키-값 매개 변수(Spark Submit예: 태스크)로 JAR 구성되지 않은 작업에 전달하려면 인수 형식을 매개 변수를 식별하는 인수로 {{job.parameters.[name]}}key 바꿉 [name] 니다.
Notebook: 추가를 클릭하고, 태스크에 전달할 각 매개 변수의 키와 값을 지정합니다. 다른 매개 변수를 사용하여 작업 실행 옵션을 사용하여 태스크를 수동으로 실행할 때 추가 매개 변수를 재정의하거나 추가할 수 있습니다. 매개 변수는 매개 변수의 키로 지정된 Notebook 위젯의 값을 설정합니다.
JAR: JSON 형식의 문자열 배열을 사용하여 매개 변수를 지정합니다. 이러한 문자열은 인수로 주 클래스의 main 메서드에 전달됩니다. JAR 작업 매개 변수 구성을 참조하세요.
Spark Submit: 매개 변수는 JSON 형식의 문자열 배열로 지정됩니다. Apache Spark spark-submit 규칙에 따라 JAR 경로 뒤의 매개 변수가 주 클래스의 main 메서드로 전달됩니다.
Python 휠: 매개 변수 드롭다운 메뉴에서 위치 인수를 선택하여 JSON 형식 문자열 배열로 매개 변수를 입력하거나 키워드 인수 > 추가를 선택하여 각 매개 변수의 키와 값을 입력합니다. 위치 및 키워드 인수는 모두 명령줄 인수로 Python 휠 작업에 전달됩니다. Python 휠 파일에 패키지된 Python 스크립트에서 인수를 읽는 예제를 보려면 Azure Databricks 작업에서 Python 휠 파일 사용을 참조하세요.
작업 실행: 작업에 전달할 각 작업 매개 변수의 키와 값을 입력합니다.
Python 스크립트: JSON 형식의 문자열 배열을 사용하여 매개 변수를 지정합니다. 이러한 문자열은 인수로 전달되며 위치 인수로 읽거나 Python의 argparse 모듈을 사용하여 구문 분석할 수 있습니다. Python 스크립트에서 위치 인수를 읽는 예제를 보려면 2단계: GitHub 데이터를 가져오는 스크립트 만들기를 참조하세요.
SQL: 태스크에서 매개 변수가 있는 쿼리 또는 매개 변수가 있는 대시보드를 실행하는 경우 제공된 텍스트 상자에 매개 변수 값을 입력합니다.
태스크 경로 복사
특정 작업 유형(예: Notebook 작업)을 사용하면 태스크 소스 코드에 대한 경로를 복사할 수 있습니다.
- 작업 탭을 클릭합니다.
- 복사할 경로가 포함된 태스크를 선택합니다.
- 작업 경로 옆을 클릭하여
 클립보드에 경로를 복사합니다.
클립보드에 경로를 복사합니다.
기존 작업에서 작업 만들기
기존 작업을 복제하여 새 작업을 빠르게 만들 수 있습니다. 작업을 복제하면 작업 ID를 제외하고 동일한 작업 복사본이 만들어집니다. 작업 페이지에서 작업 이름 옆에 있는 자세히 ...를 클릭하고, 드롭다운 메뉴에서 복제를 선택합니다.
기존 작업에서 작업 만들기
기존 태스크를 복제하여 새 태스크를 빠르게 만들 수 있습니다.
- 작업 페이지에서 태스크 탭을 클릭합니다.
- 복제할 태스크를 선택합니다.
- 작업을
 클릭하고 복제를 선택합니다.
클릭하고 복제를 선택합니다.
작업 삭제
작업을 삭제하려면 작업 페이지에서 작업 이름 옆에 있는 자세히 ...를 클릭하고, 드롭다운 메뉴에서 삭제를 선택합니다.
태스크 삭제
태스크 삭제하려면 다음을 수행합니다.
- 작업 탭을 클릭합니다.
- 삭제할 태스크를 선택합니다.
- 작업 제거를 클릭하고 선택합니다.
작업 실행
- 사이드바에서 워크플로를 클릭합니다.
- 작업을 선택하고, 실행 탭을 클릭합니다. 작업을 즉시 실행하거나 나중에 실행하도록 작업을 예약할 수 있습니다.
여러 태스크가 있는 작업에서 하나 이상의 작업이 실패하면 실패한 작업의 하위 집합을 다시 실행할 수 있습니다. 실패한 작업 및 건너뛴 작업 다시 실행을 참조 하세요.
즉시 작업 실행
작업을 즉시 실행하려면 을 클릭합니다  .
.
팁
지금 실행을 클릭하여 Notebook 태스크를 통해 작업의 테스트 실행을 수행할 수 있습니다. Notebook을 변경해야 하는 경우 Notebook을 편집한 후에 지금 실행을 다시 클릭하면 새 버전의 Notebook이 자동으로 실행됩니다.
다른 매개 변수를 사용하여 작업 실행
다른 매개 변수를 사용하여 지금 실행을 사용하여 기존 매개 변수에 대한 다른 매개 변수 또는 다른 값으로 작업을 다시 실행할 수 있습니다.
참고 항목
작업 매개 변수가 도입되기 전에 실행된 작업이 동일한 키를 사용하여 작업 매개 변수를 오버로드한 경우 작업 매개 변수를 재정의할 수 없습니다.
- 지금 실행 옆을 클릭하고
 다른 매개 변수를 사용하여 지금 실행을 선택하거나 활성 실행 테이블에서 다른 매개 변수를 사용하여 지금 실행을 클릭합니다. 태스크 종류에 따라 새 매개 변수를 입력합니다. Azure Databricks 작업 태스크에 매개 변수 전달을 참조 하세요.
다른 매개 변수를 사용하여 지금 실행을 선택하거나 활성 실행 테이블에서 다른 매개 변수를 사용하여 지금 실행을 클릭합니다. 태스크 종류에 따라 새 매개 변수를 입력합니다. Azure Databricks 작업 태스크에 매개 변수 전달을 참조 하세요. - 실행을 클릭합니다.
서비스 주체로 작업 실행
참고 항목
작업이 SQL 태스크를 사용하여 SQL 쿼리를 실행하는 경우 쿼리를 실행하는 데 사용되는 ID는 작업이 서비스 주체로 실행되는 경우에도 각 쿼리의 공유 설정에 따라 결정됩니다. 쿼리가 구성된 Run as owner경우 쿼리는 항상 서비스 주체의 ID가 아닌 소유자의 ID를 사용하여 실행됩니다. 쿼리가 구성 Run as viewer되면 서비스 주체의 ID를 사용하여 쿼리가 실행됩니다. 쿼리 공유 설정에 대한 자세한 내용은 쿼리 권한 구성을 참조 하세요.
기본적으로 작업은 작업 소유자의 ID로 실행됩니다. 즉, 작업은 작업 소유자의 사용 권한을 가정합니다. 작업은 작업 소유자가 액세스할 수 있는 권한이 있는 데이터 및 Azure Databricks 개체에만 액세스할 수 있습니다. 작업이 실행 중인 ID를 서비스 주체로 변경할 수 있습니다. 그런 다음, 작업은 소유자 대신 해당 서비스 주체의 사용 권한을 가정합니다.
실행 설정을 변경하려면 작업에 대해 CAN MANAGE 또는 IS OWNER 권한이 있어야 합니다. 실행 설정을 자신 또는 서비스 주체 사용자 역할이 있는 작업 영역의 서비스 주체로 설정할 수 있습니다. 자세한 내용은 서비스 주체 관리에 대한 역할을 참조 하세요.
참고 항목
작업 영역의 RestrictWorkspaceAdmins 설정이 설정 ALLOW ALL되면 작업 영역 관리자는 실행 설정을 작업 영역의 모든 사용자로 변경할 수도 있습니다. 작업 영역 관리자가 실행 설정을 자체 또는 서비스 주체 사용자 역할이 있는 서비스 주체로만 변경하도록 제한하려면 작업 영역 관리자 제한(Restrict Workspace Admins)을 참조하세요.
실행 필드를 변경하려면 다음을 수행합니다.
- 사이드바에서 워크플로를 클릭합니다.
- 이름 열에서 작업 이름을 클릭합니다.
- 작업 세부 정보 측면 패널에서 실행 필드 옆에 있는 연필 아이콘을 클릭합니다.
- 서비스 주체를 검색하고 선택합니다.
- 저장을 클릭합니다.
작업 영역 서비스 주체 API 사용에 대한 사용자 역할이 있는 서비스 주체를 나열할 수도 있습니다. 자세한 내용은 사용할 수 있는 서비스 주체 목록을 참조하세요.
일정에 따라 작업 실행
일정을 사용하여 지정된 시간 및 기간에 Azure Databricks 작업을 자동으로 실행할 수 있습니다. 작업 일정 추가를 참조하세요.
연속 작업 실행
작업의 활성 실행이 항상 있는지 확인할 수 있습니다. 연속 작업 실행을 참조하세요.
새 파일이 도착하면 작업 실행
새 파일이 Unity 카탈로그 외부 위치 또는 볼륨에 도착할 때 작업 실행을 트리거하려면 파일 도착 트리거를 사용합니다.
Databricks 자산 번들로 만든 작업 보기 및 실행
Azure Databricks 작업 UI를 사용하여 Databricks 자산 번들에 의해 배포된 작업을 보고 실행할 수 있습니다. 기본적으로 이러한 작업은 작업 UI에서 읽기 전용입니다. 번들에 의해 배포된 작업을 편집하려면 번들 구성 파일을 변경하고 작업을 다시 배포합니다. 번들 구성에만 변경 내용을 적용하면 번들 원본 파일이 항상 현재 작업 구성을 캡처할 수 있습니다.
그러나 작업을 즉시 변경해야 하는 경우 번들 구성에서 작업의 연결을 끊어 UI에서 작업 설정을 편집할 수 있습니다. 작업의 연결을 끊려면 원본에서 연결을 끊습니다. 원본에서 연결 끊기 대화 상자에서 연결 끊기를 클릭하여 확인합니다.
UI에서 작업을 변경한 내용은 번들 구성에 적용되지 않습니다. UI에서 변경한 내용을 번들에 적용하려면 번들 구성을 수동으로 업데이트해야 합니다. 번들 구성에 작업을 다시 연결하려면 번들을 사용하여 작업을 다시 배포합니다.
동시성 제한으로 인해 작업을 실행할 수 없는 경우 어떻게 해야 할까요?
참고 항목
큐는 UI에서 작업을 만들 때 기본적으로 사용하도록 설정됩니다.
동시성 제한으로 인해 작업 실행을 건너뛰지 않도록 하려면 작업에 대한 큐를 사용하도록 설정할 수 있습니다. 큐를 사용하도록 설정하면 작업 실행에 리소스를 사용할 수 없는 경우 실행은 최대 48시간 동안 큐에 대기됩니다. 용량을 사용할 수 있으면 작업 실행이 큐에서 해제되고 실행됩니다. 큐에 대기 중인 실행은 작업의 실행 목록과 최근 작업 실행 목록에 표시됩니다.
다음 제한 중 하나에 도달하면 실행이 큐에 대기됩니다.
- 작업 영역에서 최대 동시 활성 실행입니다.
- 최대 동시
Run Job작업은 작업 영역에서 실행됩니다. - 작업의 최대 동시 실행입니다.
큐는 해당 작업에 대해서만 큐를 실행하는 작업 수준 속성입니다.
큐를 사용하거나 사용하지 않도록 설정하려면 고급 설정을 클릭하고 작업 세부 정보 측면 패널에서 큐 토글 단추를 클릭합니다.
피드백
출시 예정: 2024년 내내 콘텐츠에 대한 피드백 메커니즘으로 GitHub 문제를 단계적으로 폐지하고 이를 새로운 피드백 시스템으로 바꿀 예정입니다. 자세한 내용은 다음을 참조하세요. https://aka.ms/ContentUserFeedback
다음에 대한 사용자 의견 제출 및 보기