Azure Databricks 작업으로 첫 번째 워크플로 만들기
이 문서에서는 샘플 데이터 세트를 읽고 처리하도록 작업을 오케스트레이션하는 Azure Databricks 작업을 보여 줍니다. 이 빠른 시작에서 관련 정보는 다음과 같습니다.
- 새 Notebook을 만들고 코드를 추가하여 매년 인기 있는 아기 이름이 포함된 샘플 데이터 세트를 검색합니다.
- 샘플 데이터 세트를 Unity 카탈로그에 저장합니다.
- 새 Notebook을 만들고 코드를 추가하여 Unity 카탈로그에서 데이터 세트를 읽고, 연도별로 필터링하고, 결과를 표시합니다.
- 새 작업을 만들고 Notebook을 사용하여 두 작업을 구성합니다.
- 작업을 실행하고 결과를 봅니다.
요구 사항
작업 영역이 Unity 카탈로그 사용이고 서버리스 워크플로 가 사용하도록 설정된 경우 기본적으로 작업은 서버리스 컴퓨팅에서 실행됩니다. 서버리스 컴퓨팅을 사용하여 작업을 실행하려면 클러스터 만들기 권한이 필요하지 않습니다.
그렇지 않으면 작업 컴퓨팅을 만들거나 다목적 컴퓨팅 리소스에 대한 권한을 만들 수 있는 클러스터 만들기 권한이 있어야 합니다.
Unity 카탈로그에 볼륨이 있어야 합니다. 이 문서에서는 이름이 main지정된 카탈로그 내에 이름이 지정된 스키마에 이름이 지정된 my-volumedefault 볼륨을 사용합니다. 또한 Unity 카탈로그에는 다음 권한이 있어야 합니다.
READ VOLUME및WRITE VOLUME, 또는ALL PRIVILEGES볼륨의 경우my-volumeUSE SCHEMA또는ALL PRIVILEGES스키마의 경우defaultUSE CATALOG또는ALL PRIVILEGES카탈로그의 경우main
이러한 권한을 설정하려면 Databricks 관리자 또는 Unity 카탈로그 권한 및 보안 개체를 참조하세요.
Notebook 만들기
데이터 검색 및 저장
샘플 데이터 세트를 검색하고 Unity 카탈로그에 저장하는 Notebook을 만들려면 다음을 수행합니다.
Azure Databricks 방문 페이지로 이동하여 사이드바에서 새로 만들기를 클릭하고
 Notebook을 선택합니다. Databricks는 기본 폴더에 비어 있는 새 전자 필기장을 만들고 엽니다. 기본 언어는 가장 최근에 사용한 언어이며 Notebook은 가장 최근에 사용한 컴퓨팅 리소스에 자동으로 연결됩니다.
Notebook을 선택합니다. Databricks는 기본 폴더에 비어 있는 새 전자 필기장을 만들고 엽니다. 기본 언어는 가장 최근에 사용한 언어이며 Notebook은 가장 최근에 사용한 컴퓨팅 리소스에 자동으로 연결됩니다.필요한 경우 기본 언어를 Python으로 변경합니다.
다음 Python 코드를 복사하여 Notebook의 첫 번째 셀에 붙여넣습니다.
import requests response = requests.get('https://health.data.ny.gov/api/views/jxy9-yhdk/rows.csv') csvfile = response.content.decode('utf-8') dbutils.fs.put("/Volumes/main/default/my-volume/babynames.csv", csvfile, True)
필터링된 데이터 읽기 및 표시
필터링할 데이터를 읽고 표시하는 Notebook을 만들려면 다음을 수행합니다.
Azure Databricks 방문 페이지로 이동하여 사이드바에서 새로 만들기를 클릭하고
Notebook을 선택합니다. Databricks는 기본 폴더에 비어 있는 새 전자 필기장을 만들고 엽니다. 기본 언어는 가장 최근에 사용한 언어이며 Notebook은 가장 최근에 사용한 컴퓨팅 리소스에 자동으로 연결됩니다.필요한 경우 기본 언어를 Python으로 변경합니다.
다음 Python 코드를 복사하여 Notebook의 첫 번째 셀에 붙여넣습니다.
babynames = spark.read.format("csv").option("header", "true").option("inferSchema", "true").load("/Volumes/main/default/my-volume/babynames.csv") babynames.createOrReplaceTempView("babynames_table") years = spark.sql("select distinct(Year) from babynames_table").toPandas()['Year'].tolist() years.sort() dbutils.widgets.dropdown("year", "2014", [str(x) for x in years]) display(babynames.filter(babynames.Year == dbutils.widgets.get("year")))
작업 만들기
사이드바에서 워크플로를 클릭합니다
 .
. 을 클릭합니다.
을 클릭합니다.작업 탭에 작업 만들기 대화 상자가 표시됩니다.

작업 이름 추가...를 작업 이름으로 바꿉니다.
작업 이름 필드에 작업 이름(예: retrieve-baby-names)을 입력합니다.
형식 드롭다운 메뉴에서 전자 필기장을 선택합니다.
파일 브라우저를 사용하여 만든 첫 번째 Notebook을 찾고 Notebook 이름을 클릭한 다음 확인을 클릭합니다.
작업 만들기를 클릭합니다.
방금 만든 작업 아래를 클릭하여
 다른 작업을 추가합니다.
다른 작업을 추가합니다.작업 이름 필드에 작업 이름(예: filter-baby-names)을 입력합니다.
형식 드롭다운 메뉴에서 전자 필기장을 선택합니다.
파일 브라우저를 사용하여 만든 두 번째 Notebook을 찾고 Notebook 이름을 클릭한 다음 확인을 클릭합니다.
매개 변수 아래에서 추가를 클릭합니다. 키 필드에
year을(를) 입력합니다. 값 필드에2014를 입력합니다.작업 만들기를 클릭합니다.
작업 실행
작업을 즉시 실행하려면 오른쪽 위 모서리를 클릭합니다  . 실행 탭을 클릭하고 활성 실행 테이블에서 지금 실행을 클릭하여 작업을 실행할 수도 있습니다.
. 실행 탭을 클릭하고 활성 실행 테이블에서 지금 실행을 클릭하여 작업을 실행할 수도 있습니다.
실행 세부 정보 보기
실행 탭을 클릭하고 활성 실행 테이블 또는 완료된 실행(지난 60일) 테이블에서 해당 실행에 대한 링크를 클릭합니다.
출력 및 세부 정보를 보려면 두 작업을 클릭합니다. 예를 들어 필터-아기 이름 작업을 클릭하여 출력을 보고 필터 작업에 대한 세부 정보를 실행합니다.
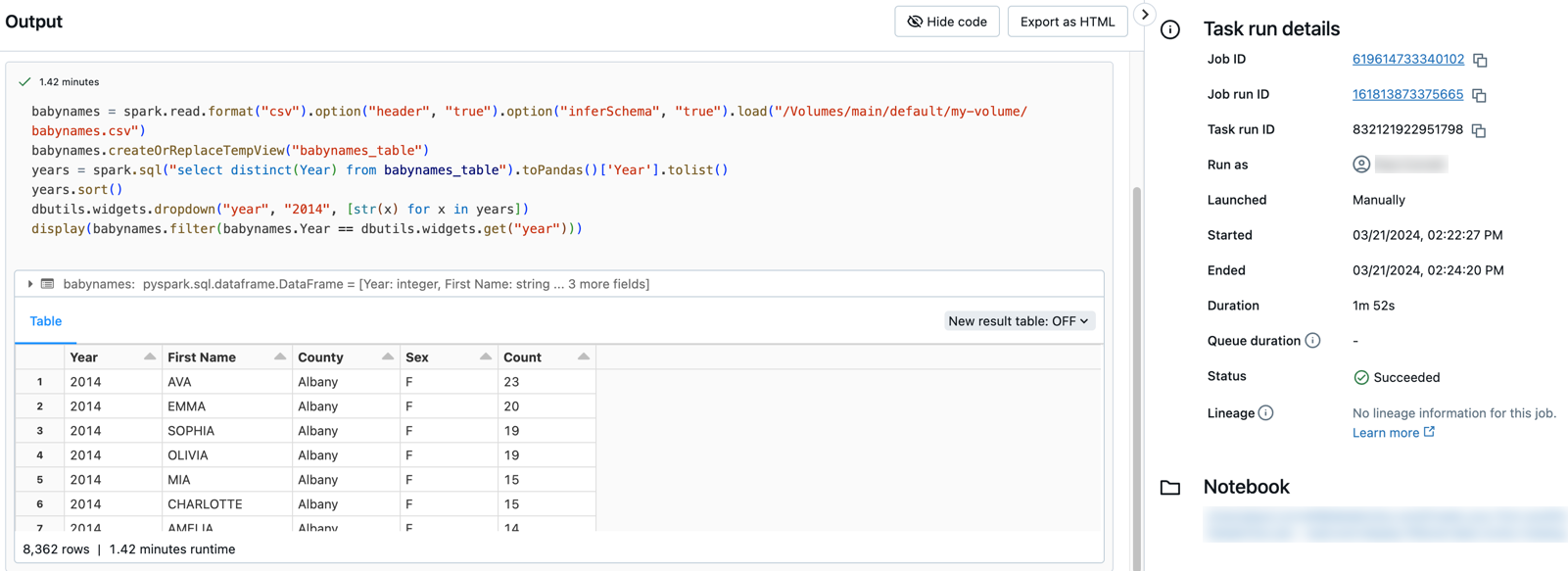
다른 매개 변수를 사용하여 실행
작업을 다시 실행하고 다른 연도의 아기 이름을 필터링하려면 다음을 수행합니다.
- 지금 실행 옆을 클릭하고
 다른 매개 변수를 사용하여 지금 실행을 선택하거나 활성 실행 테이블에서 다른 매개 변수 를 사용하여 지금 실행을 클릭합니다.
다른 매개 변수를 사용하여 지금 실행을 선택하거나 활성 실행 테이블에서 다른 매개 변수 를 사용하여 지금 실행을 클릭합니다. - 값 필드에
2015를 입력합니다. - 실행을 클릭합니다.
피드백
출시 예정: 2024년 내내 콘텐츠에 대한 피드백 메커니즘으로 GitHub 문제를 단계적으로 폐지하고 이를 새로운 피드백 시스템으로 바꿀 예정입니다. 자세한 내용은 다음을 참조하세요. https://aka.ms/ContentUserFeedback
다음에 대한 사용자 의견 제출 및 보기