Azure Databricks AutoML UI를 사용하여 ML 모델 학습
이 문서에서는 AutoML 및 Databricks Machine Learning UI를 사용하여 기계 학습 모델을 학습하는 방법을 보여 줍니다. AutoML UI는 데이터 세트에서 분류, 회귀 또는 예측 모델을 학습하는 프로세스를 단계별로 안내합니다.
UI에 액세스하려면:
사이드바에서 새 > AutoML 실험을 선택합니다.
실험 페이지에서 새 AutoML 실험을 만들 수도 있습니다.
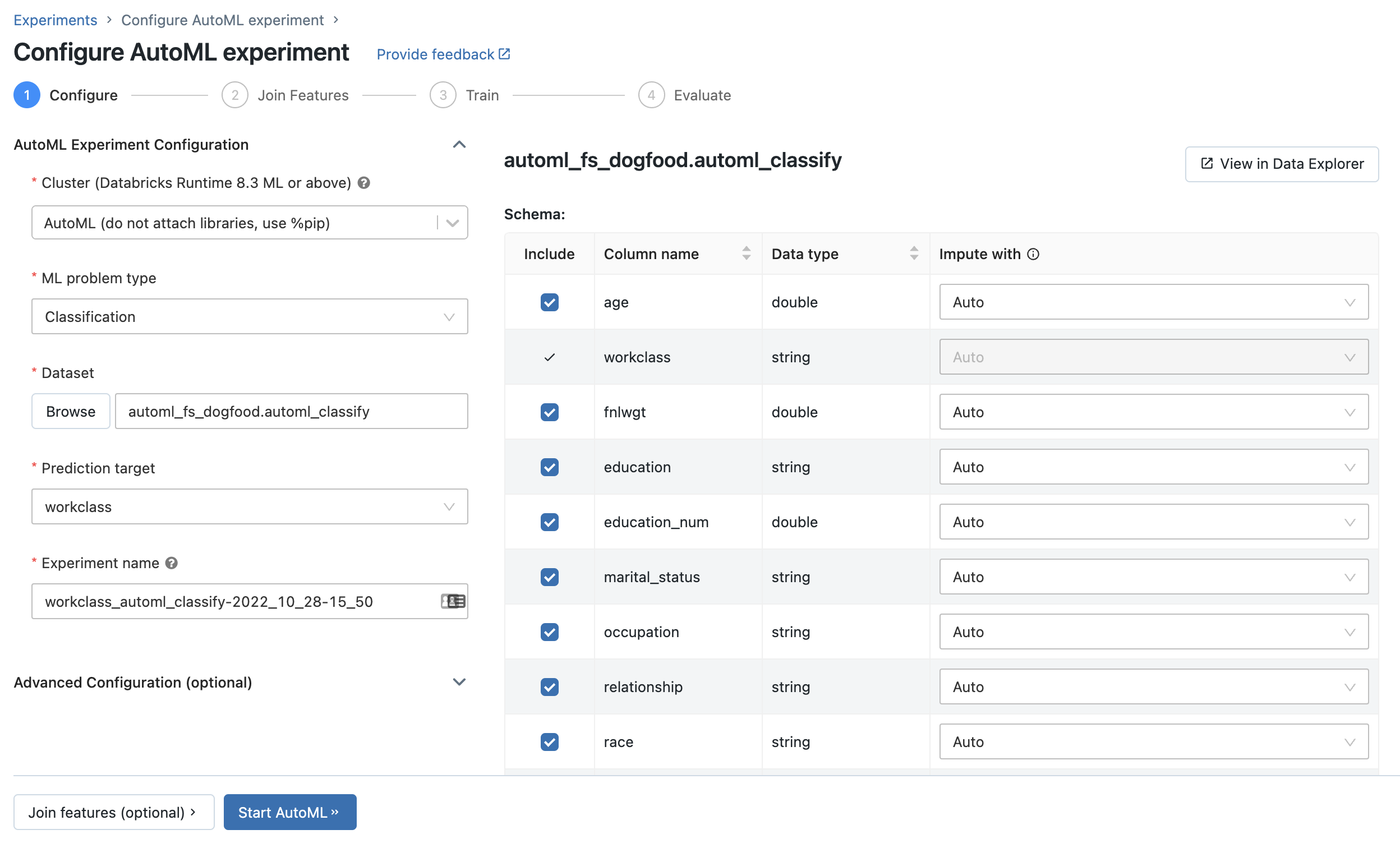
AutoML 실험 구성 페이지가 표시됩니다. 이 페이지에서는 데이터 세트, 문제 유형, 예측할 대상 또는 레이블 열, 실험 실행을 평가하고 점수를 매기는 데 사용할 메트릭, 중지 조건을 지정하여 AutoML 프로세스를 구성합니다.
요구 사항
AutoML 실험에 대한 요구 사항을 참조하세요.
분류 또는 회귀 문제 설정
다음 단계에 따라 AutoML UI를 사용하여 분류 또는 회귀 문제를 설정할 수 있습니다.
컴퓨팅 필드에서 Databricks Runtime ML을 실행하는 클러스터를 선택합니다.
ML 문제 유형 드롭다운 메뉴에서 회귀 또는 분류를 선택합니다. 연간 소득과 같은 각 관측치에 대한 연속 숫자 값을 예측하려는 경우 회귀를 선택합니다. 좋은 신용 위험이나 나쁜 신용 위험과 같은 개별 클래스 집합 중 하나에 각 관찰을 할당하려는 경우 분류를 선택합니다.
데이터 세트에서 찾아보기를 선택합니다.
사용하려는 표로 이동하여 선택을 클릭합니다. 테이블 스키마가 나타납니다.
분류 및 회귀 문제의 경우에만 학습에 포함할 열을 지정하고 사용자 지정 대치 메서드를 선택할 수 있습니다.
예측 대상 필드를 클릭합니다. 스키마에 표시된 열을 나열하는 드롭다운이 나타납니다. 모델에서 예측할 열을 선택합니다.
실험 이름 필드에는 기본 이름이 표시됩니다. 변경하려면 필드에 새 이름을 입력합니다.
다음도 가능합니다.
- 추가 구성 옵션을 지정 합니다.
- 기능 저장소의 기존 기능 테이블을 사용하여 원래 입력 데이터 세트를 보강합니다.
예측 문제 설정
다음 단계에 따라 AutoML UI를 사용하여 예측 문제를 설정할 수 있습니다.
- 컴퓨팅 필드에서 Databricks Runtime 10.0 ML 이상을 실행하는 클러스터를 선택합니다.
- ML 문제 유형 드롭다운 메뉴에서 예측을 선택합니다.
- 데이터 세트에서 찾아보기를 클릭합니다. 사용하려는 표로 이동하여 선택을 클릭합니다. 테이블 스키마가 나타납니다.
- 예측 대상 필드를 클릭합니다. 스키마에 표시된 열을 나열하는 드롭다운 메뉴가 나타납니다. 모델에서 예측할 열을 선택합니다.
- 시간 열 필드를 클릭합니다.
timestamp또는date유형의 데이터 세트 열을 보여 주는 드롭다운이 나타납니다. 시계열의 기간이 포함된 열을 선택합니다. - 다중 시리즈 예측의 경우 시계열 식별자 드롭다운에서 개별 시계열을 식별하는 열을 선택합니다. AutoML은 이러한 열을 기준으로 데이터를 다른 시계열로 그룹화하고 각 시리즈에 대한 모델을 독립적으로 학습시킵니다. 이 필드를 비워두면 AutoML은 데이터 세트에 단일 시계열이 포함되어 있다고 가정합니다.
- 예측 기간 및 빈도 필드에서 AutoML이 예측 값을 계산해야 하는 향후의 기간 수를 지정합니다. 왼쪽 상자에 예측할 기간의 정수를 입력합니다. 오른쪽 상자에서 단위를 선택합니다. .. 참고 :: Auto-ARIMA를 사용하려면 시계열이 규칙적인 빈도를 가져야 합니다(즉, 두 지점 사이의 간격이 시계열 전체에서 동일해야 함). 빈도는 API 호출 또는 AutoML UI에 지정된 빈도 단위와 일치해야 합니다. AutoML은 해당 값을 이전 값으로 채워 누락된 시간 단계를 처리합니다.
- Databricks Runtime 11.3 LTS ML 이상에서는 예측 결과를 저장할 수 있습니다. 이렇게 하려면 출력 데이터베이스 필드에 데이터베이스를 지정합니다. 찾아보기를 클릭하고 대화 상자에서 데이터베이스를 선택합니다. AutoML은 예측 결과를 이 데이터베이스의 테이블에 씁니다.
- 실험 이름 필드에는 기본 이름이 표시됩니다. 변경하려면 필드에 새 이름을 입력합니다.
다음도 가능합니다.
- 추가 구성 옵션을 지정 합니다.
- 기능 저장소의 기존 기능 테이블을 사용하여 원래 입력 데이터 세트를 보강합니다.
Databricks 기능 저장소에서 기존 기능 테이블 사용
Databricks Runtime 11.3 LTS ML 이상에서는 Databricks 기능 저장소의 기능 테이블을 사용하여 분류 및 회귀 문제에 대한 입력 학습 데이터 세트를 확장할 수 있습니다.
Databricks Runtime 12.2 LTS ML 이상에서는 Databricks 기능 저장소의 기능 테이블을 사용하여 분류, 회귀 및 예측과 같은 모든 AutoML 문제에 대한 입력 학습 데이터 세트를 확장할 수 있습니다.
기능 테이블을 만들려면 Unity 카탈로그에서 기능 테이블 만들기 또는 Databricks 기능 저장소에서 기능 테이블 만들기를 참조하세요.
AutoML 실험 구성을 완료한 후 다음 단계에 따라 기능 테이블을 선택할 수 있습니다.
기능 조인(선택 사항)을 클릭합니다.
추가 기능 조인 페이지의 기능 테이블 필드에서 기능 테이블을 선택합니다.
각 기능 테이블 기본 키에 대해 해당 조회 키를 선택합니다. 조회 키는 AutoML 실험을 위해 제공한 학습 데이터 세트의 열이어야 합니다.
시계열 기능 테이블의 경우 해당 타임스탬프 조회 키를 선택합니다. 마찬가지로 타임스탬프 조회 키는 AutoML 실험을 위해 제공한 학습 데이터 세트의 열이어야 합니다.

기능 테이블을 더 추가하려면 다른 테이블 추가를 클릭하고 위의 단계를 반복합니다.
고급 구성
이러한 매개 변수에 액세스하려면 고급 구성(선택 사항) 섹션을 엽니다.
- 평가 메트릭은 실행 점수를 매기는 데 사용되는 기본 메트릭입니다.
- Databricks Runtime 10.4 LTS ML 이상에서는 학습 프레임워크를 고려 사항에서 제외할 수 있습니다. 기본적으로 AutoML은 AutoML 알고리즘에 나열된 프레임워크를 사용하여 모델을 학습시킵니다.
- 정지 조건을 편집할 수 있습니다. 기본 중지 조건은 다음과 같습니다.
- 예측 실험의 경우 120분 후에 중지합니다.
- Databricks Runtime 10.4 LTS ML 이하에서 분류 및 회귀 실험의 경우 60분 후에 또는 200개의 평가판을 완료한 후 먼저 중지합니다. Databricks Runtime 11.0 ML 이상의 경우 시도 횟수는 중지 조건으로 사용되지 않습니다.
- Databricks Runtime 10.4 LTS ML 이상에서 분류 및 회귀 실험의 경우 AutoML은 조기 중지를 통합합니다. 유효성 검사 메트릭이 더 이상 개선되지 않는 경우 모델 학습 및 튜닝을 중지합니다.
- Databricks Runtime 10.4 LTS ML 이상에서 시간 열을 선택하여 학습, 유효성 검사 및 테스트를 위한 데이터를 시간순으로 분할할 수 있습니다(분류 및 회귀에만 적용됨).
- Databricks는 데이터 디렉터리 필드를 채웁니다. 이렇게 하면 데이터 세트를 MLflow 아티팩트로 안전하게 저장하는 기본 동작이 트리거됩니다. DBFS 경로를 지정할 수 있지만 이 경우 데이터 세트는 AutoML 실험의 액세스 권한을 상속하지 않습니다.
열 선택
참고 항목
이 기능은 분류 및 회귀 문제에만 사용할 수 있습니다.
Databricks Runtime 10.3 ML 이상에서는 AutoML이 학습에 사용해야 하는 열을 지정할 수 있습니다. 열을 제외하려면 포함 열에서 선택을 취소합니다.
데이터를 분할하기 위해 예측 대상 또는 시간 열로 선택한 열을 삭제할 수 없습니다.
기본적으로 모든 열이 포함됩니다.
누락된 값의 대체
Databricks Runtime 10.4 LTS ML 이상에서는 null 값을 대치하는 방법을 지정할 수 있습니다. UI에서 테이블 스키마의 다음으로 대체 열에 있는 드롭다운에서 메서드를 선택합니다.
기본적으로 AutoML은 열 유형 및 콘텐츠를 기반으로 대치 메서드를 선택합니다.
참고 항목
기본값이 아닌 대치 메서드를 지정하면 AutoML이 의미 체계 유형 검색을 수행하지 않습니다.
실험 실행 및 결과 모니터링
AutoML 실험을 시작하려면 AutoML 시작을 클릭합니다. 실험이 실행되기 시작하고 AutoML 학습 페이지가 나타납니다. 실행 테이블을 새로 고치려면 을 클릭합니다  .
.
이 페이지에서 다음을 수행할 수 있습니다.
- 언제든지 실험을 중지합니다.
- 데이터 탐색 Notebook을 엽니다.
- 실행을 모니터링합니다.
- 실행에 대한 실행 페이지로 이동합니다.
Databricks Runtime 10.1 ML 이상에서 AutoML은 지원되지 않는 열 유형 또는 높은 카디널리티 열과 같은 데이터 세트의 잠재적인 문제에 대한 경고를 표시합니다.
참고 항목
Databricks는 잠재적인 오류나 문제를 나타내기 위해 최선을 다합니다. 그러나 이는 포괄적이지 않을 수 있으며 검색할 수 있는 문제나 오류를 포착하지 못할 수 있습니다. 여러분도 여러분 나름대로의 검토를 해 보시기 바랍니다.
데이터 세트에 대한 경고를 보려면 학습 페이지 또는 실험이 완료된 후 실험 페이지에서 경고 탭을 클릭합니다.

실험이 완료되면 다음을 수행할 수 있습니다.
- MLflow로 모델 중 하나를 등록 및 배포합니다.
- 최상의 모델용 Notebook 보기를 선택하여 최상의 모델을 만든 Notebook을 검토하고 편집합니다.
- 데이터 탐색 Notebook 보기를 선택하여 데이터 탐색 Notebook을 엽니다.
- 런 테이블에서 런을 검색, 필터링 및 정렬합니다.
- 모든 실행에 대한 세부 정보를 참조하세요.
- 평가판 실행에 대한 소스 코드가 포함된 생성된 Notebook은 MLflow 실행을 클릭하여 찾을 수 있습니다. Notebook은 실행 페이지의 아티팩트 섹션에 저장 됩니다 . 작업 영역 관리자가 아티팩트 다운로드를 사용하도록 설정한 경우 이 Notebook을 다운로드하고 작업 영역으로 가져올 수 있습니다.
- 실행 결과를 보려면 모델 열 또는 시작 시간 열을 클릭합니다. 모델을 포함하여 실행에 의해 만들어진 아티팩트 및 매개 변수, 메트릭 및 태그와 같은 시험 실행에 대한 정보를 보여 주는 실행 페이지가 나타납니다. 이 페이지에는 모델로 예측하는 데 사용할 수 있는 코드 조각도 포함되어 있습니다.
나중에 이 AutoML 실험으로 돌아가려면 실험 페이지의 표에서 찾습니다. 데이터 탐색 및 학습 Notebook을 포함한 각 AutoML 실험의 결과는 실험을 실행한 사용자의 홈 폴더에 있는 databricks_automl 폴더에 저장됩니다.
모델 등록 및 배포
AutoML UI를 사용하여 모델을 등록하고 배포할 수 있습니다.
- 등록할 모델의 모델 열에 있는 링크를 선택합니다. 실행이 완료되면 기본 메트릭을 기반으로 가장 적합한 모델이 맨 위 행입니다.
- 모델 레지스트리에 모델을 등록하려면 선택합니다
 .
. - 사이드바에서 모델을 선택하여
 모델 레지스트리로 이동합니다.
모델 레지스트리로 이동합니다. - 모델 테이블에서 모델 이름을 선택합니다.
- 등록된 모델 페이지에서 모델 서비스로 모델을 제공할 수 있습니다.
'pandas.core.indexes.numeric'이라는 모듈이 없습니다.
모델 제공과 함께 AutoML을 사용하여 빌드된 모델을 제공하는 경우 다음과 같은 오류가 발생할 No module named 'pandas.core.indexes.numeric수 있습니다.
이는 AutoML과 엔드포인트 환경을 제공하는 모델 간의 호환되지 않는 pandas 버전 때문입니다. add-pandas-dependency.py 스크립트를 실행하여 이 오류를 해결할 수 있습니다. 스크립트는 적절한 pandas 종속성 버전을 포함하도록 기록된 모델을 편집 requirements.txt 합니다conda.yaml.pandas==1.5.3
- 모델이 기록된 MLflow 실행을 포함
run_id하도록 스크립트를 수정합니다. - MLflow 모델 레지스트리에 모델을 다시 등록합니다.
- 새 버전의 MLflow 모델을 제공해 보세요.