기능 저장소란?
이 페이지에서는 기능 저장소의 특징과 기능 저장소의 이점 및 Databricks 기능 저장소의 특정 이점에 대해 설명합니다.
기능 저장소는 데이터 과학자가 기능을 찾고 공유할 수 있도록 하는 중앙 집중식 리포지토리이며, 기능 값을 계산하는 데 사용되는 동일한 코드가 모델 학습 및 유추에 사용되도록 합니다.
기계 학습은 기존 데이터를 사용하여 향후 결과를 예측하는 모델을 빌드합니다. 거의 모든 경우에 원시 데이터는 모델을 빌드하는 데 사용되기 전에 전처리 및 변환이 필요합니다. 이 프로세스를 기능 엔지니어링이라고 하며, 이 프로세스의 출력을 모델의 구성 요소인 기능이라고 합니다.
기능 개발은 복잡하고 시간이 많이 걸립니다. 기계 학습의 경우 모델 학습을 위한 기능 계산을 수행한 다음, 모델을 사용하여 예측을 수행할 때 다시 계산해야 한다는 복잡함이 있습니다. 이러한 구현은 동일한 팀에서 수행하거나 동일한 코드 환경을 사용하지 않을 수 있으며, 이로 인해 지연 및 오류가 발생할 수 있습니다. 또한 조직의 여러 팀이 비슷한 기능을 필요로 하지만 다른 팀이 수행한 작업을 인식하지 못할 수도 있습니다. 기능 저장소는 이러한 문제를 해결하도록 설계되었습니다.
Databricks 기능 저장소를 사용하는 이유는 무엇인가요?
Databricks 기능 저장소는 Azure Databricks의 다른 구성 요소와 완전히 통합됩니다.
- 검색 기능. Databricks 작업 영역에서 액세스할 수 있는 기능 저장소 UI를 사용하면 기존 기능을 찾아보고 검색할 수 있습니다.
- 계보. Azure Databricks에서 기능 테이블을 만들 때 기능 테이블을 만드는 데 사용되는 데이터 원본이 저장되고 액세스할 수 있습니다. 기능 테이블의 각 기능에 대해 해당 기능을 사용하는 모델, Notebook, 작업 및 엔드포인트에 액세스할 수도 있습니다.
- 모델 점수 매기기 및 서비스와의 통합. 기능 저장소의 기능을 사용하여 모델을 학습하는 경우 모델은 기능 메타데이터로 패키지됩니다. 일괄 처리 채점 또는 온라인 유추에 모델을 사용하면 기능 저장소에서 기능이 자동으로 검색됩니다. 호출자는 해당 기능에 대해 알 필요가 없으며, 기능을 조회하거나 조인하여 새 데이터의 점수를 매기는 논리를 포함할 필요가 없습니다. 이렇게 하면 모델 배포 및 업데이트가 훨씬 쉬워집니다.
- 특정 시점 조회. 기능 저장소는 특정 시점의 정확성이 필요한 시계열 및 이벤트 기반 사용 사례를 지원합니다.
Unity 카탈로그의 기능 엔지니어링
Databricks Runtime 13.3 LTS 이상을 사용하는 경우 Unity 카탈로그에 작업 영역을 사용하도록 설정하면 Unity 카탈로그가 기능 저장소가 됩니다. 모델 학습 또는 유추를 위한 기능 테이블로 기본 키를 사용하여 Unity 카탈로그의 델타 테이블 또는 델타 라이브 테이블을 사용할 수 있습니다. Unity 카탈로그는 기능 검색, 거버넌스, 계보 및 작업 영역 간 액세스를 제공합니다.
Databricks 기능 저장소는 어떻게 작동하나요?
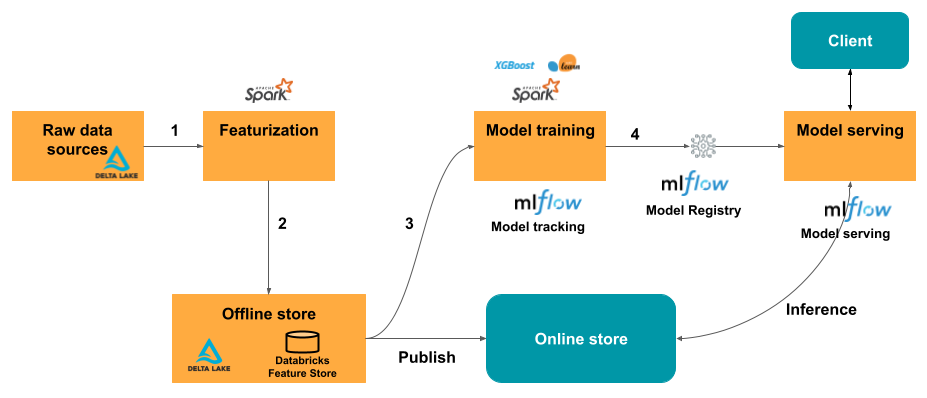
기능 저장소를 사용하는 일반적인 기계 학습 워크플로는 다음 경로를 따릅니다.
- 원시 데이터를 기능으로 변환하고 원하는 기능이 포함된 Spark DataFrame을 만드는 코드를 씁니다.
- Unity 카탈로그에 사용하도록 설정된 작업 영역의 경우 DataFrame을 Unity 카탈로그의 기능 테이블로 작성합니다. Unity 카탈로그 에 대해 작업 영역을 사용하도록 설정하지 않은 경우 작업 영역 기능 저장소에 DataFrame을 기능 테이블로 작성합니다.
- 기능 저장소의 기능을 사용하여 모델을 학습합니다. 이렇게 하면 모델은 학습에 사용되는 기능의 사양을 저장합니다. 모델이 유추에 사용되는 경우 해당 기능 테이블의 기능을 자동으로 조인합니다.
- 모델 레지스트리에 모델을 등록합니다.
이제 모델을 사용하여 새 데이터에서 예측을 수행할 수 있습니다.
일괄 처리 사용 사례의 경우 모델은 기능 저장소에서 필요한 기능을 자동으로 검색합니다.

실시간 서비스 사용 사례의 경우 온라인 스토어에 기능을 게시하거나 온라인 테이블을 사용합니다.
유추 시 모델은 온라인 저장소에서 미리 계산된 기능을 읽고 클라이언트 요청에 제공된 데이터와 엔드포인트를 제공하는 모델에 조인합니다.
기능 저장소 사용 시작
기능 저장소를 시작하려면 다음 문서를 참조하세요.
- 기능 저장소 기능을 보여 주는 예제 Notebook 중 하나를 사용해 보세요.
- 기능 저장소 Python API에 대한 참조 자료를 확인하세요.
- 기능 저장소를 사용하는 학습 모델에 대해 알아봅니다.
- Unity 카탈로그의 기능 엔지니어링에 대해 알아봅니다.
- 작업 영역 기능 저장소에 대해 알아봅니다.
- 시계열 기능 테이블 및 특정 시점 조회를 사용하여 모델 학습 또는 채점을 위해 특정 시간을 기준으로 최신 기능 값을 검색합니다.
- 실시간 서비스 및 자동 기능 조회를 위해 온라인 상점 또는 온라인 테이블에 기능을 게시하는 방법에 대해 알아봅니다.
- Databricks 플랫폼의 기능을 Databricks 외부에 배포된 모델 또는 애플리케이션에 대한 짧은 대기 시간으로 사용할 수 있도록 하는 기능 제공에 대해 알아봅니다.
Unity 카탈로그에서 기능 엔지니어링을 사용하는 경우 Unity 카탈로그는 작업 영역 간에 기능 테이블을 공유하고 Unity 카탈로그 권한을 사용하여 기능 테이블에 대한 액세스를 제어합니다 . 다음 링크는 작업 영역 기능 저장소에만 해당합니다.
지원되는 데이터 유형
Unity 카탈로그 및 작업 영역 기능 저장소의 기능 엔지니어링은 다음 PySpark 데이터 형식을 지원합니다.
IntegerTypeFloatTypeBooleanTypeStringTypeDoubleTypeLongTypeTimestampTypeDateTypeShortTypeArrayTypeBinaryType[1]DecimalType[1]MapType[1]
[1] BinaryType및 DecimalTypeUnity 카탈로그의 MapType 모든 기능 엔지니어링 버전 및 작업 영역 기능 저장소 v0.3.5 이상에서 지원됩니다.
위에 나열된 데이터 형식은 기계 학습 애플리케이션에서 일반적인 기능 유형을 지원합니다. 예시:
- 조밀한 벡터, 텐서 및 포함을
ArrayType으로 저장할 수 있습니다. - 희박한 벡터, 텐서 및 포함을
MapType으로 저장할 수 있습니다. - 텍스트를
StringType으로 저장할 수 있습니다.
온라인 저장소에 게시되면 ArrayType 및 MapType 기능이 JSON 형식으로 저장됩니다.
기능 저장소 UI는 기능 데이터 형식의 메타데이터를 표시합니다.

자세한 정보
기능 저장소 사용에 대한 모범 사례를 보려면 포괄적인 기능 저장소 가이드를 다운로드하세요.