다른 Notebook에서 Databricks Notebook 실행
Important
Notebook 오케스트레이션의 경우 Databricks 작업을 사용합니다. 코드 모듈화 시나리오의 경우 작업 영역 파일을 사용합니다. 동적 매개 변수 집합을 통해 Notebook을 반복하거나 작업 영역 파일에 액세스할 수 없는 경우와 같이 Databricks 작업을 사용하여 사용 사례를 구현할 수 없는 경우에만 이 문서에 설명된 기술을 사용해야 합니다. 자세한 내용은 Databricks 작업 및 공유 코드를 참조하세요.
%run와 dbutils.notebook.run()의 비교
이 %run 명령을 사용하면 전자 필기장 내에 다른 전자 필기장을 포함할 수 있습니다. 예를 들어 %run을 사용해 지원 함수를 별도의 Notebook에 배치하여 코드를 모듈화할 수 있습니다. 이를 통해 분석의 단계를 구현하는 Notebook을 연결할 수도 있습니다. %run을 사용하면 호출된 Notebook이 즉시 실행되고 그 안에 정의된 함수와 변수를 호출 Notebook에서 사용할 수 있게 됩니다.
dbutils.notebook API는 Notebook에서 매개 변수를 %run 전달하고 값을 반환할 수 있기 때문에 보완합니다. 이렇게 하면 종속성이 있는 복잡한 워크플로 및 파이프라인을 빌드할 수 있습니다. 예를 들어 디렉터리에 있는 파일 목록을 가져와서 다른 Notebook에 이름을 전달할 수 있습니다. 이 경우에는 %run을 사용할 수 없습니다. 반환 값을 기반으로 if-then-else 워크플로를 만들거나 상대 경로를 사용하여 다른 Notebook을 호출할 수도 있습니다.
%run과 달리 dbutils.notebook.run() 메서드는 Notebook을 실행하는 새 작업을 시작합니다.
이러한 메서드는 모든 dbutils API와 마찬가지로 Python 및 Scala에서만 사용할 수 있습니다. 그러나 dbutils.notebook.run()을 사용하여 R Notebook을 호출할 수 있습니다.
%run을 사용하여 Notebook 가져오기
이 예제에서 첫 번째 Notebook은 매직을 사용하여 실행shared-code-notebook한 후 두 번째 Notebook에서 사용할 수 있는 함수reverse를 %run 정의합니다.


이러한 두 Notebook은 모두 작업 영역의 동일한 디렉터리에 있으므로 ./shared-code-notebook에서 ./ 접두사를 사용하여 현재 실행 중인 Notebook을 기준으로 하는 경로를 확인해야 함을 나타냅니다. Notebook을 디렉터리(예: %run ./dir/notebook)로 구성하거나 절대 경로(예: %run /Users/username@organization.com/directory/notebook)를 사용할 수 있습니다.
참고 항목
%run는 전체 Notebook을 인라인으로 실행하기 때문에 셀 자체에 있어야 합니다.- Python 파일 및
import해당 파일에 정의된 엔터티를 Notebook에 실행하는 데 사용할%run수 없습니다. Python 파일에서 가져오려면 파일을 사용하여 코드 모듈화를 참조하세요. 또는 파일을 Python 라이브러리에 패키지하고, 해당 Python 라이브러리에서 Azure Databricks 라이브러리를 만든 다음, Notebook을 실행하는 데 사용하는 클러스터에 라이브러리를 설치합니다. %run을 사용하여 위젯이 포함된 Notebook을 실행하는 경우 기본적으로 지정된 Notebook이 위젯의 기본값을 사용하여 실행됩니다. 값을 위젯에 전달할 수도 있습니다. %run을 통해 Databricks 위젯 사용을 참조하세요.
dbutils.notebook API
API에서 사용할 수 있는 dbutils.notebook 메서드는 다음과 같습니다 runexit. 매개 변수와 반환 값은 모두 문자열이어야 합니다.
run(path: String, timeout_seconds: int, arguments: Map): String
Notebook을 실행하고 해당 종료 값을 반환합니다. 메서드는 즉시 실행되는 임시 작업을 시작합니다.
timeout_seconds 매개 변수는 실행의 시간 제한을 제어합니다(0은 시간 초과 없음을 의미). run에 대한 호출은 지정된 시간 내에 완료되지 않으면 예외를 throw입니다. Azure Databricks가 10분을 초과하여 다운된 경우 Notebook 실행은 timeout_seconds에 관계없이 실패합니다.
arguments 매개 변수는 대상 Notebook의 위젯 값을 설정합니다. 특히, 실행 중인 Notebook에 A라는 위젯이 있고 run() 호출에 대한 인수 매개 변수의 일부로 키-값 쌍 ("A": "B")를 전달하는 경우 위젯 A의 값을 검색하면 "B"가 반환됩니다. Databricks 위젯 문서에서 위젯을 만들고 작업하기 위한 지침을 찾을 수 있습니다.
참고 항목
arguments매개 변수는 라틴 문자(ASCII 문자 집합)만 허용합니다. ASCII가 아닌 문자를 사용하면 오류가 반환됩니다.- API를
dbutils.notebook사용하여 만든 작업은 30일 이내에 완료되어야 합니다.
run 사용 방법
Python
dbutils.notebook.run("notebook-name", 60, {"argument": "data", "argument2": "data2", ...})
Scala
dbutils.notebook.run("notebook-name", 60, Map("argument" -> "data", "argument2" -> "data2", ...))
run 예
위젯의 값을 인쇄하는 foo라는 위젯이 있는 workflows라는 Notebook이 있다고 가정합니다.
dbutils.widgets.text("foo", "fooDefault", "fooEmptyLabel")
print(dbutils.widgets.get("foo"))
dbutils.notebook.run("workflows", 60, {"foo": "bar"})를 실행하면 다음 결과가 생성됩니다.
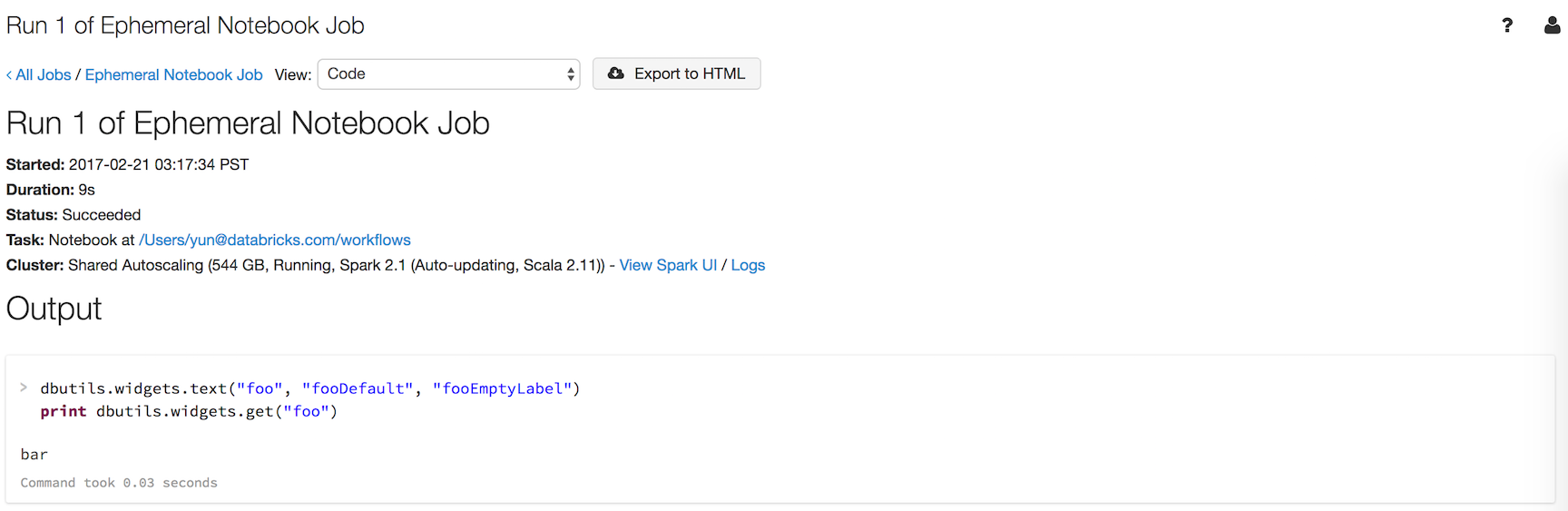
위젯에는 기본값이 아닌 사용 "bar"하 여 dbutils.notebook.run()전달 된 값이 있습니다.
exit(value: String): void 값이 있는 Notebook을 종료합니다. run 메서드를 사용하여 Notebook을 호출하는 경우 반환되는 값입니다.
dbutils.notebook.exit("returnValue")
작업에서 dbutils.notebook.exit를 호출하면 Notebook이 성공적으로 완료됩니다. 작업이 실패하도록 하려면 예외를 throw합니다.
예제
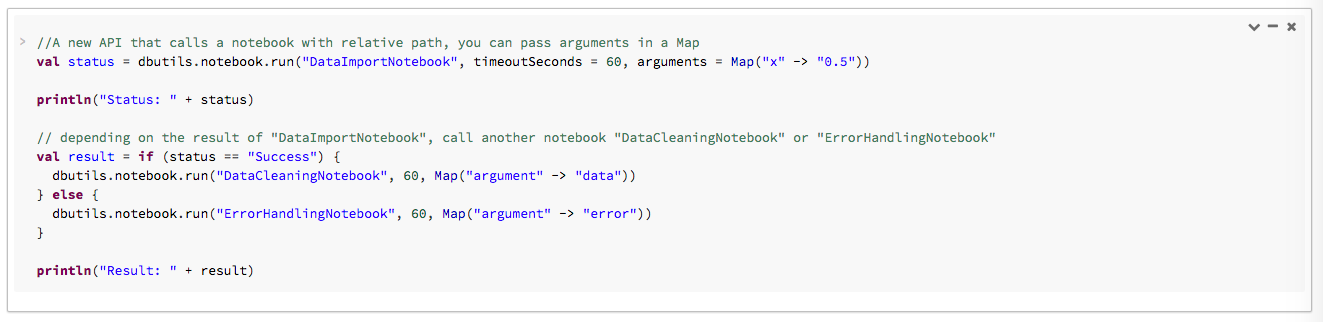
다음 예제에서는 DataImportNotebook에 인수를 전달하고 DataImportNotebook의 결과에 따라 다른 Notebook(DataCleaningNotebook 또는 ErrorHandlingNotebook)을 실행합니다.
코드가 실행되면 실행 중인 Notebook에 대한 링크가 표시됩니다.

실행 세부 정보를 보려면 Notebook 링크 Notebook 작업 #xxxx 클릭합니다.
구조화된 데이터 전달
이 섹션에서는 Notebook 간에 구조화된 데이터를 전달하는 방법을 보여 줍니다.
Python
# Example 1 - returning data through temporary views.
# You can only return one string using dbutils.notebook.exit(), but since called notebooks reside in the same JVM, you can
# return a name referencing data stored in a temporary view.
## In callee notebook
spark.range(5).toDF("value").createOrReplaceGlobalTempView("my_data")
dbutils.notebook.exit("my_data")
## In caller notebook
returned_table = dbutils.notebook.run("LOCATION_OF_CALLEE_NOTEBOOK", 60)
global_temp_db = spark.conf.get("spark.sql.globalTempDatabase")
display(table(global_temp_db + "." + returned_table))
# Example 2 - returning data through DBFS.
# For larger datasets, you can write the results to DBFS and then return the DBFS path of the stored data.
## In callee notebook
dbutils.fs.rm("/tmp/results/my_data", recurse=True)
spark.range(5).toDF("value").write.format("parquet").save("dbfs:/tmp/results/my_data")
dbutils.notebook.exit("dbfs:/tmp/results/my_data")
## In caller notebook
returned_table = dbutils.notebook.run("LOCATION_OF_CALLEE_NOTEBOOK", 60)
display(spark.read.format("parquet").load(returned_table))
# Example 3 - returning JSON data.
# To return multiple values, you can use standard JSON libraries to serialize and deserialize results.
## In callee notebook
import json
dbutils.notebook.exit(json.dumps({
"status": "OK",
"table": "my_data"
}))
## In caller notebook
import json
result = dbutils.notebook.run("LOCATION_OF_CALLEE_NOTEBOOK", 60)
print(json.loads(result))
Scala
// Example 1 - returning data through temporary views.
// You can only return one string using dbutils.notebook.exit(), but since called notebooks reside in the same JVM, you can
// return a name referencing data stored in a temporary view.
/** In callee notebook */
sc.parallelize(1 to 5).toDF().createOrReplaceGlobalTempView("my_data")
dbutils.notebook.exit("my_data")
/** In caller notebook */
val returned_table = dbutils.notebook.run("LOCATION_OF_CALLEE_NOTEBOOK", 60)
val global_temp_db = spark.conf.get("spark.sql.globalTempDatabase")
display(table(global_temp_db + "." + returned_table))
// Example 2 - returning data through DBFS.
// For larger datasets, you can write the results to DBFS and then return the DBFS path of the stored data.
/** In callee notebook */
dbutils.fs.rm("/tmp/results/my_data", recurse=true)
sc.parallelize(1 to 5).toDF().write.format("parquet").save("dbfs:/tmp/results/my_data")
dbutils.notebook.exit("dbfs:/tmp/results/my_data")
/** In caller notebook */
val returned_table = dbutils.notebook.run("LOCATION_OF_CALLEE_NOTEBOOK", 60)
display(sqlContext.read.format("parquet").load(returned_table))
// Example 3 - returning JSON data.
// To return multiple values, you can use standard JSON libraries to serialize and deserialize results.
/** In callee notebook */
// Import jackson json libraries
import com.fasterxml.jackson.module.scala.DefaultScalaModule
import com.fasterxml.jackson.module.scala.experimental.ScalaObjectMapper
import com.fasterxml.jackson.databind.ObjectMapper
// Create a json serializer
val jsonMapper = new ObjectMapper with ScalaObjectMapper
jsonMapper.registerModule(DefaultScalaModule)
// Exit with json
dbutils.notebook.exit(jsonMapper.writeValueAsString(Map("status" -> "OK", "table" -> "my_data")))
/** In caller notebook */
// Import jackson json libraries
import com.fasterxml.jackson.module.scala.DefaultScalaModule
import com.fasterxml.jackson.module.scala.experimental.ScalaObjectMapper
import com.fasterxml.jackson.databind.ObjectMapper
// Create a json serializer
val jsonMapper = new ObjectMapper with ScalaObjectMapper
jsonMapper.registerModule(DefaultScalaModule)
val result = dbutils.notebook.run("LOCATION_OF_CALLEE_NOTEBOOK", 60)
println(jsonMapper.readValue[Map[String, String]](result))
오류 처리
이 섹션에서는 오류를 처리하는 방법을 보여 줍니다.
Python
# Errors throw a WorkflowException.
def run_with_retry(notebook, timeout, args = {}, max_retries = 3):
num_retries = 0
while True:
try:
return dbutils.notebook.run(notebook, timeout, args)
except Exception as e:
if num_retries > max_retries:
raise e
else:
print("Retrying error", e)
num_retries += 1
run_with_retry("LOCATION_OF_CALLEE_NOTEBOOK", 60, max_retries = 5)
Scala
// Errors throw a WorkflowException.
import com.databricks.WorkflowException
// Since dbutils.notebook.run() is just a function call, you can retry failures using standard Scala try-catch
// control flow. Here we show an example of retrying a notebook a number of times.
def runRetry(notebook: String, timeout: Int, args: Map[String, String] = Map.empty, maxTries: Int = 3): String = {
var numTries = 0
while (true) {
try {
return dbutils.notebook.run(notebook, timeout, args)
} catch {
case e: WorkflowException if numTries < maxTries =>
println("Error, retrying: " + e)
}
numTries += 1
}
"" // not reached
}
runRetry("LOCATION_OF_CALLEE_NOTEBOOK", timeout = 60, maxTries = 5)
여러 Notebook을 동시에 실행
스레드(Scala, Python) 및 Futures(Scala, Python)와 같은 표준 Scala 및 Python 구문을 사용하여 동시에 여러 Notebook을 실행할 수 있습니다. 예제 Notebook에서는 이러한 구문을 사용하는 방법을 보여 줍니다.
- 다음 4개의 전자 필기장을 다운로드합니다. Notebook은 Scala로 작성됩니다.
- 전자 필기장을 작업 영역의 단일 폴더로 가져옵니다.
- 동시에 실행 Notebook을 실행합니다.
동시에 Notebook 실행
병렬 Notebook에서 실행
Notebook 테스트
Testing-2 Notebook
피드백
출시 예정: 2024년 내내 콘텐츠에 대한 피드백 메커니즘으로 GitHub 문제를 단계적으로 폐지하고 이를 새로운 피드백 시스템으로 바꿀 예정입니다. 자세한 내용은 다음을 참조하세요. https://aka.ms/ContentUserFeedback
다음에 대한 사용자 의견 제출 및 보기