데이터 파이프라인을 사용하는 이유
Azure DevOps Services
데이터 파이프라인을 사용하여 다음을 수행할 수 있습니다.
- 다양한 데이터 원본에서 데이터 수집
- 데이터 처리 및 변환
- 처리된 데이터를 다른 사용자가 사용할 준비 위치에 저장
엔터프라이즈의 데이터 파이프라인은 여러 원본 시스템을 사용하여 더 복잡한 시나리오로 발전하고 다양한 다운스트림 애플리케이션을 지원할 수 있습니다.
데이터 파이프라인은 다음을 제공합니다.
- 일관성: 데이터 파이프라인은 사용자가 사용할 수 있는 일관된 형식으로 데이터를 변환합니다.
- 오류 감소: 자동화된 데이터 파이프라인은 데이터를 조작할 때 사람의 오류를 제거합니다.
- 효율성: 데이터 전문가는 데이터 처리 변환에 소요된 시간을 절약합니다. 시간을 절약하면 데이터에서 인사이트를 얻고 비즈니스가 더 나은 결정을 내릴 수 있도록 돕는 핵심 작업 기능에 집중할 수 있습니다.
CI/CD란?
CI/CD(지속적인 통합 및 지속적인 업데이트)는 모든 개발자가 코드의 공유 리포지토리에서 함께 작업하는 소프트웨어 개발 접근 방식이며, 변경 내용이 적용되면 코드 문제를 검색하기 위한 자동화된 빌드 프로세스가 있습니다. 결과는 개발 수명 주기가 빨라지고 오류율이 낮습니다.
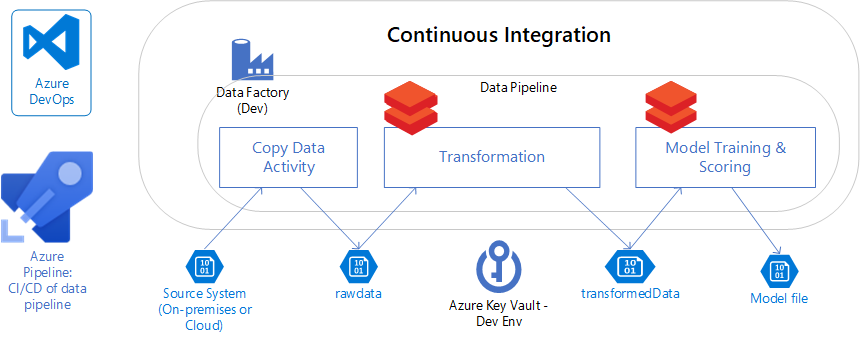
CI/CD 데이터 파이프라인이란 무엇이며 데이터 과학에 중요한 이유는 무엇인가요?
기계 학습 모델의 빌드는 데이터 과학자가 기계 학습 모델을 학습하고 점수를 매기기 위해 코드를 작성해야 한다는 점에서 기존 소프트웨어 개발과 유사합니다.
제품이 코드를 기반으로 하는 기존 소프트웨어 개발과 달리 데이터 과학 기계 학습 모델은 코드(알고리즘, 하이퍼 매개 변수)와 모델 학습에 사용되는 데이터를 모두 기반으로 합니다. 따라서 대부분의 데이터 과학자들은 데이터 준비, 정리 및 기능 엔지니어링을 수행하는 데 80%의 시간을 소비한다고 말합니다.
이 문제를 더욱 복잡하게 만들기 위해 기계 학습 모델의 품질을 보장하기 위해 A/B 테스트와 같은 기술이 사용됩니다. A/B 테스트를 사용하면 여러 기계 학습 모델이 동시에 사용될 수 있습니다. 일반적으로 비교를 위한 컨트롤 모델과 하나 이상의 처리 모델이 있으므로 모델 성능을 비교하고 유지 관리할 수 있습니다. 여러 모델이 있으면 기계 학습 모델의 CI/CD에 대한 또 다른 복잡성 계층이 추가됩니다.
CI/CD 데이터 파이프라인을 갖는 것은 데이터 과학 팀이 기계 학습 모델을 시기적절하고 양질의 방식으로 비즈니스에 제공하는 데 매우 중요합니다.
다음 단계
피드백
출시 예정: 2024년 내내 콘텐츠에 대한 피드백 메커니즘으로 GitHub 문제를 단계적으로 폐지하고 이를 새로운 피드백 시스템으로 바꿀 예정입니다. 자세한 내용은 다음을 참조하세요. https://aka.ms/ContentUserFeedback
다음에 대한 사용자 의견 제출 및 보기