Azure Blob Storage 또는 Azure Data Lake Storage에서 Azure Event Hubs를 통해 이벤트 캡처
Azure Event Hubs를 사용하면 시간 또는 크기 간격을 유연하게 지정하여 Event Hubs의 스트리밍 데이터를 선택한 Azure Blob 스토리지 또는 Azure Data Lake Storage Gen 1 또는 Gen 2 계정에 자동으로 캡처할 수 있습니다. 캡처 설정은 빠르고, 관리 비용이 없으며 표준 계층의 Event Hubs 처리량 단위 또는 프리미엄 계층 처리 단위를 사용하여 자동으로 크기를 조정합니다. Event Hubs 캡처는 스트리밍 데이터를 Azure에 로드하는 가장 쉬운 방법이며 데이터 캡처보다 데이터 처리에 집중할 수 있게 해줍니다.
참고 항목
Azure Data Lake Storage Gen 2를 사용하도록 Event Hubs 캡처를 구성하는 것은 Azure Blob Storage를 사용하도록 구성하는 것과 같습니다. 자세한 내용은 Event Hubs 캡처 구성을 참조하세요.
Event Hubs 캡처를 사용하면 동일한 스트림에서 실시간 및 일괄 처리 기반 파이프라인을 처리할 수 있습니다. 즉, 시간이 지나면서 요구에 따라 확장되는 솔루션을 빌드할 수 있습니다. 향후 실시간 처리를 염두에 두고 현재 일괄 처리 기반 시스템을 빌드 중이든, 기존의 실시간 솔루션에 효율적인 콜드 경로를 추가하려는 경우든 간에 Event Hubs 캡처를 통해 스트리밍 데이터 작업이 더 쉬워집니다.
Important
- 인증에 관리 ID를 사용하지 않는 경우 대상 스토리지(Azure Storage 또는 Azure Data Lake Storage) 계정은 이벤트 허브와 동일한 구독에 있어야 합니다.
- Event Hubs는 프리미엄 스토리지 계정에서 이벤트 캡처를 지원하지 않습니다.
- Event Hubs 캡처는 블록 Blob을 지원하는 비프리미엄이 Azure Storage 계정을 지원합니다.
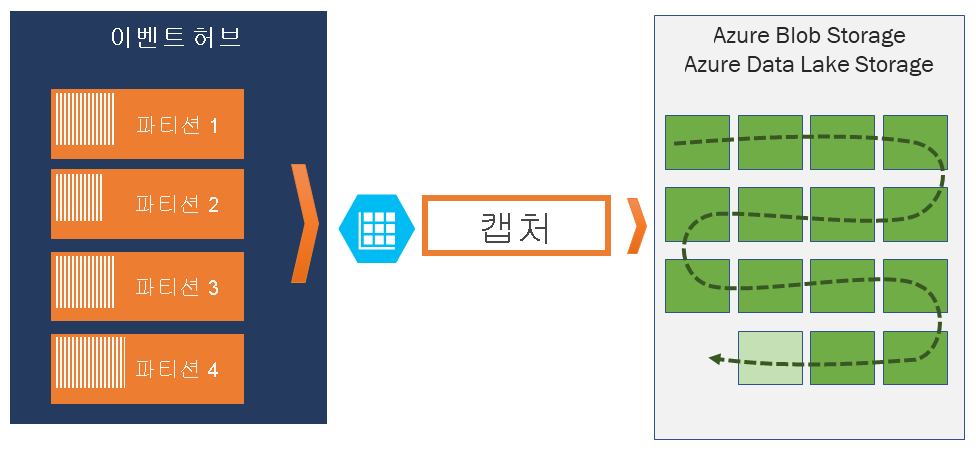
Event Hubs 캡처의 작동 방식
Event Hubs는 원격 분석 수신에 대한 시간 보존 지속형 버퍼이며 분산된 로그와 비슷합니다. Event Hubs 크기 조정의 핵심은 분할된 소비자 모델입니다. 각 파티션은 데이터의 독립적인 세그먼트이며 독립적으로 사용됩니다. 시간이 지나면서 이 데이터는 구성 가능한 보존 기간에 따라 에이징됩니다. 결과적으로 지정된 이벤트 허브는 "꽉 참" 상태가 되지 않습니다.
Event Hubs 캡처를 사용하면 캡처된 데이터를 저장하는 데 사용되는 고유한 Azure Blob Storage 계정 및 컨테이너 또는 Azure Data Lake Storage 계정을 지정할 수 있습니다. 이러한 계정은 이벤트 허브와 동일한 지역에 있을 수도 있고 다른 지역에 있을 수도 있으므로 Event Hubs 캡처 기능의 유연성이 향상됩니다.
캡처된 데이터는 Apache Avro 형식으로 작성되는데, 이는 인라인 스키마가 있는 풍부한 데이터 구조를 제공하는 간단하고 빠른 이진 형식입니다. 이 형식은 Hadoop 에코시스템, Stream Analytics 및 Azure Data Factory에서 널리 사용됩니다. Avro 작업에 대한 자세한 내용은 이 문서의 뒷부분을 참조하세요.
참고 항목
Azure Portal에서 코드 편집기를 사용하지 않는 경우 Parquet 형식으로 Azure Data Lake Storage Gen2 계정의 Event Hubs에서 스트리밍 데이터를 캡처할 수 있습니다. 자세한 내용은 방법: Event Hubs에서 데이터를 Parquet 형식으로 캡처 및 자습서: Event Hubs 데이터를 Parquet 형식으로 캡처하고 Azure Synapse Analytics로 분석을 참조하세요.
캡처 기간 이동
Event Hubs 캡처를 사용하면 기간을 설정하여 캡처를 제어할 수 있습니다. 이 기간은 발견된 첫 번째 트리거에서 캡처 작업이 발생하도록 하는 "첫 번째 우선 정책"이 포함된 최소 크기 및 시간 구성입니다. 15분/100MB 캡처 기간을 사용하고 초당 1MB로 전송할 경우 크기 기간이 시간 기간보다 먼저 트리거됩니다. 각 파티션이 독립적으로 캡처하며, 캡처 시점에 완료된 블록 Blob을 작성하고 캡처 간격이 발생한 시간을 따라 명명합니다. 스토리지 명명 규칙은 다음과 같습니다.
{Namespace}/{EventHub}/{PartitionId}/{Year}/{Month}/{Day}/{Hour}/{Minute}/{Second}
날짜 값은 0으로 채워집니다. 파일 이름의 예는 다음과 같습니다.
https://mystorageaccount.blob.core.windows.net/mycontainer/mynamespace/myeventhub/0/2017/12/08/03/03/17.avro
Azure Storage BLOB을 일시적으로 사용할 수 없는 경우 Event Hubs 캡처가 이벤트 허브에 구성된 데이터 보존 기간 동안 데이터를 보존하고 스토리지 계정을 다시 사용할 수 있게 되면 데이터를 다시 채웁니다.
처리량 단위 또는 처리 단위 크기 조정
Event Hubs의 표준 계층에서 트래픽은 처리량 단위로 제어되고 프리미엄 계층 Event Hubs에서는 처리 단위로 제어됩니다. Event Hubs 캡처는 내부 Event Hubs 스토리지에서 데이터를 직접 복사하여 처리량 단위 또는 처리 단위 송신 할당량을 우회하고 Stream Analytics, Spark 등의 다른 처리 리더를 위해 송신 내용을 저장합니다.
Event Hubs 캡처가 구성되면 첫 번째 이벤트를 전송하는 즉시 자동으로 실행되어 계속 실행됩니다. 다운스트림 처리 시 프로세스가 제대로 작동하는지 쉽게 알 수 있도록 Event Hubs는 데이터가 없을 경우 빈 파일을 작성합니다. 이 프로세스는 일괄 처리 프로세서에 제공할 수 있는 예측 가능한 주기와 표식을 제공합니다.
Event Hubs 캡처 설정
이벤트 허브 생성 시 Azure Portal 또는 Azure Resource Manager 템플릿을 사용하여 캡처를 구성할 수 있습니다. 자세한 내용은 다음 문서를 참조하세요.
- Azure Portal을 사용하여 Event Hubs 캡처를 사용하도록 설정
- Azure Resource Manager 템플릿을 사용하여 하나의 이벤트 허브가 있는 Event Hubs 네임스페이스를 만들고 캡처를 사용하도록 설정
참고 항목
기존 이벤트 허브에 캡처 기능을 사용하도록 설정하면, 해당 기능이 설정된 후 이벤트 허브에 도착하는 이벤트를 캡처합니다. 해당 기능이 설정되기 전에 이벤트 허브에 있던 이벤트는 캡처하지 않습니다.
Event Hubs 캡처의 요금 부과 방식
캡처 기능은 프리미엄 계층에 포함되므로 해당 계층에 대한 추가 요금이 부과되지 않습니다. 표준 계층의 경우 기능은 매월 청구되며 요금은 네임스페이스에 대해 구매한 처리량 단위 또는 처리 단위 수에 직접 비례합니다. 처리량 단위 또는 처리 단위가 증가 및 감소함에 따라 성능이 일치하도록 Event Hubs 캡처도 증가 및 감소합니다. 측정은 동시에 발생합니다. 가격 정보는 Event Hubs 가격 책정을 참조하세요.
캡처는 별도로 청구되므로 송신 할당량을 사용하지 않습니다.
Event Grid와 통합
원본으로 Event Hubs 네임스페이스를 사용하여 Azure Event Grid 구독을 만들 수 있습니다. Event Grid 및 Azure Functions를 사용하여 캡처된 Event Hubs 데이터를 Azure Synapse Analytics로 처리 및 마이그레이션 자습서에서는 이벤트 허브를 원본으로, Azure Functions 앱을 싱크로 사용하여 Event Grid 구독을 만드는 방법을 보여 줍니다.
캡처된 파일 탐색
캡처된 Avro 파일을 탐색하는 방법을 알아보려면 캡처된 Avro 파일 탐색을 참조하세요.
대상인 Azure Storage 계정
Azure Storage를 캡처 대상으로 사용하여 이벤트 허브에서 캡처를 사용하도록 설정하거나 Azure Storage를 캡처 대상으로 사용하여 이벤트 허브의 속성을 업데이트하려면 사용자 또는 서비스 주체가 스토리지 계정 범위에 할당된 다음 권한이 있는 RBAC 역할이 있어야 합니다.
Microsoft.Storage/storageAccounts/blobServices/containers/write
Microsoft.Storage/storageAccounts/blobServices/containers/blobs/write
위의 권한이 없으면 아래 오류가 표시됩니다.
Generic: Linked access check failed for capture storage destination <StorageAccount Arm Id>.
User or the application with object id <Object Id> making the request doesn't have the required data plane write permissions.
Please enable Microsoft.Storage/storageAccounts/blobServices/containers/write, Microsoft.Storage/storageAccounts/blobServices/containers/blobs/write permission(s) on above resource for the user or the application and retry.
TrackingId:<ID>, SystemTracker:mynamespace.servicebus.windows.net:myhub, Timestamp:<TimeStamp>
Storage Blob 데이터 소유자는 위의 권한이 있는 기본 제공 역할이므로 사용자 계정 또는 서비스 주체를 이 역할에 추가합니다.
다음 단계
Event Hubs 캡처는 데이터를 Azure로 가져오는 가장 쉬운 방법입니다. Azure Data Lake, Azure Data Factory 및 Azure HDInsight를 통해 규모에 관계없이 선택한 도구 및 플랫폼을 사용하여 선택한 일괄 처리 및 기타 분석을 수행할 수 있습니다.
Azure Portal 및 Azure Resource Manager 템플릿을 사용하여 이 기능을 사용하도록 설정하는 방법을 알아봅니다.