HDInsight 클러스터의 용량 계획
HDInsight 클러스터를 배포하기 전에 원하는 성능 및 크기를 확인하여 원하는 클러스터 용량을 계획합니다. 이러한 계획은 유용성 및 비용을 둘 다 최적화합니다. 일부 클러스터 용량 결정은 배포 후에 변경할 수 없습니다. 성능 매개 변수가 변경되면 저장된 데이터를 손실하지 않으면서 클러스터를 분해한 후 다시 만들 수 있습니다.
용량 계획을 위해 확인할 핵심 질문은 다음과 같습니다.
- 클러스터를 어떤 지리적 지역에 배포하려고 하나요?
- 스토리지 공간은 얼마나 필요한가요?
- 어떤 클러스터 유형을 배포해야 하나요?
- 클러스터 노드는 어떤 크기 및 유형의 VM(가상 머신)을 사용해야 하나요?
- 클러스터는 몇 개의 작업자 노드가 있어야 하나요?
Azure 지역 선택
Azure 지역은 클러스터가 물리적으로 프로비전되는 위치를 결정합니다. 읽기 및 쓰기 대기 시간을 최소화하려면 클러스터가 데이터 근처에 있어야 합니다.
HDInsight는 여러 Azure 지역에서 사용할 수 있습니다. 가장 가까운 지역을 찾으려면 지역별 사용 가능한 제품을 참조하세요.
스토리지 위치 및 크기 선택
기본 스토리지의 위치
Azure Storage 계정 또는 Azure Data Lake Storage에 해당하는 기본 스토리지는 클러스터와 동일한 위치에 있어야 합니다. Azure Storage는 모든 위치에서 사용할 수 있습니다. Data Lake Storage는 일부 지역에서 사용할 수 있습니다. 최신 Data Lake Storage 가용성을 참조하세요.
기존 데이터의 위치
기존 스토리지 계정이나 Data Lake Storage를 클러스터의 기본 스토리지로 사용하려는 경우 동일한 위치에 클러스터를 배포해야 합니다.
스토리지 크기
배포된 클러스터에서 다른 Azure Storage 계정을 연결하거나 다른 Data Lake Storage에 액세스할 수 있습니다. 모든 스토리지 계정은 클러스터와 동일한 위치에 있어야 합니다. Data Lake Storage는 다른 위치에 있을 수 있으며 이 경우 어느 정도의 대기 시간이 발생할 수 있습니다.
Azure Storage에는 몇 가지 용량 제한이 있는 반면 Data Lake Storage는 거의 무제한입니다. 클러스터는 다른 스토리지 계정 조합에 액세스할 수 있습니다. 일반적인 예는 다음과 같습니다.
- 데이터 양이 단일 Blob Storage 컨테이너의 스토리지 용량을 초과하기 쉬운 경우
- Blob 컨테이너에 대한 액세스 속도가 임계값을 초과하여 제한이 발생하는 경우
- 데이터를 만들려고 하는 데 이미 클러스터에서 사용할 수 있는 Blob 컨테이너를 업로드한 경우
- 보안상의 이유나 관리 간소화를 위해 스토리지의 다른 부분을 격리하려고 하는 경우
성능 향상을 위해서는 스토리지 계정당 하나의 컨테이너만 사용합니다.
클러스터 유형 선택
클러스터 유형은 HDInsight 클러스터가 실행하도록 구성되는 워크로드를 결정합니다. 형식에는 Apache Hadoop, Apache Kafka 또는 Apache Spark가 포함됩니다. 사용 가능한 클러스터 형식의 대한 자세한 설명은 Azure HDInsight 소개를 참조하세요. 각 클러스터 유형은 필요한 노드 크기 및 개수를 포함하는 배포 토폴로지를 갖습니다.
VM 크기 및 유형 선택
클러스터 유형마다 노드 유형 집합이 있으며 각 노드 유형은 VM 크기 및 유형에 대한 특정 옵션을 제공합니다.
사용하는 애플리케이션에 대해 최적의 클러스터 크기를 결정하려면 클러스터 용량을 벤치마킹하고 지정된 대로 크기를 늘릴 수 있습니다. 예를 들어 시뮬레이트한 워크로드 또는 카나리아 쿼리를 사용할 수 있습니다. 다른 크기의 클러스터에서 시뮬레이트한 워크로드를 실행합니다. 의도된 성능에 도달할 때까지 점차적으로 크기를 늘립니다. 카나리아 쿼리는 다른 프로덕션 쿼리 간에 주기적으로 삽입하여 클러스터에 충분한 리소스가 있는지 여부를 표시할 수 있습니다.
워크로드에 적합한 VM 제품군을 선택하는 방법에 대한 자세한 내용은 클러스터에 적합한 VM 크기 선택을 참조하세요.
클러스터 확장 선택
클러스터 확장은 VM 노드의 수량에 따라 결정됩니다. 모든 클러스터 유형에는 특정 크기를 갖는 노드 유형과 스케일 아웃을 지원하는 노드 유형이 있습니다. 예를 들어 클러스터에 정확히 3개의 Apache ZooKeeper 노드 또는 2개의 Head 노드가 필요할 수 있습니다. 분산 방식으로 데이터 처리를 수행하는 작업자 노드는 다른 작업자 노드의 이점을 얻습니다.
클러스터 유형에 따라 작업자 노드 수를 늘리면 더 많은 계산 용량(예: 더 많은 코어)이 추가됩니다. 노드가 많을수록 처리 중인 데이터의 메모리 내 저장을 지원하기 위해 전체 클러스터에 필요한 총 메모리가 늘어납니다. VM 크기 및 유형을 선택하는 경우처럼 올바른 클러스터 크기 선택은 보통 실험적으로 진행됩니다. 시뮬레이트한 워크로드 또는 카나리아 쿼리를 사용합니다.
최대 부하 요구를 충족하도록 클러스터를 확장할 수 있습니다. 그런 다음, 추가 노드가 더 이상 필요하지 않으면 다시 축소합니다. 자동 크기 조정 기능을 사용하면 미리 결정된 메트릭과 타이밍에 따라 클러스터의 크기를 자동으로 조정할 수 있습니다. 클러스터의 수동 확장에 대한 자세한 내용은 HDInsight 클러스터 크기 조정을 참조하세요.
클러스터 수명 주기
클러스터의 수명 주기 동안 요금이 청구됩니다. 특정 시간에만 클러스터가 필요한 경우 Azure Data Factory를 사용하여 주문형 클러스터를 만듭니다. 클러스터를 프로비전하고 삭제하는 PowerShell 스크립트를 만든 다음 Azure Automation을 사용하여 해당 스크립트를 예약할 수도 있습니다.
참고 항목
클러스터를 삭제하면 해당 기본 Hive 메타스토어도 삭제됩니다. 다음에 클러스터를 다시 만들 때를 대비해서 metastore를 보존하려면 Azure Database 또는 Apache Oozie와 같은 외부 메타데이터 저장소를 사용합니다.
클러스터 작업 오류 격리
경우에 따라 여러 맵의 병렬 실행으로 인해 오류가 발생하고, 다중 노드 클러스터의 구성 요소를 줄일 수 있습니다. 문제를 격리하려면 분산 테스트를 시도합니다. 단일 작업자 노드 클러스터에서 동시에 여러 작업을 실행합니다. 그런 다음, 이 방법을 확대하여 여러 노드가 포함된 클러스터에서 여러 작업을 동시에 실행합니다. Azure에서 단일 노드 HDInsight 클러스터를 만들려면 Custom(size, settings, apps) 옵션을 사용하고, 포털에서 새 클러스터를 프로비저닝할 때 클러스터 크기 섹션의 작업자 노드 수에 1 값을 사용합니다.
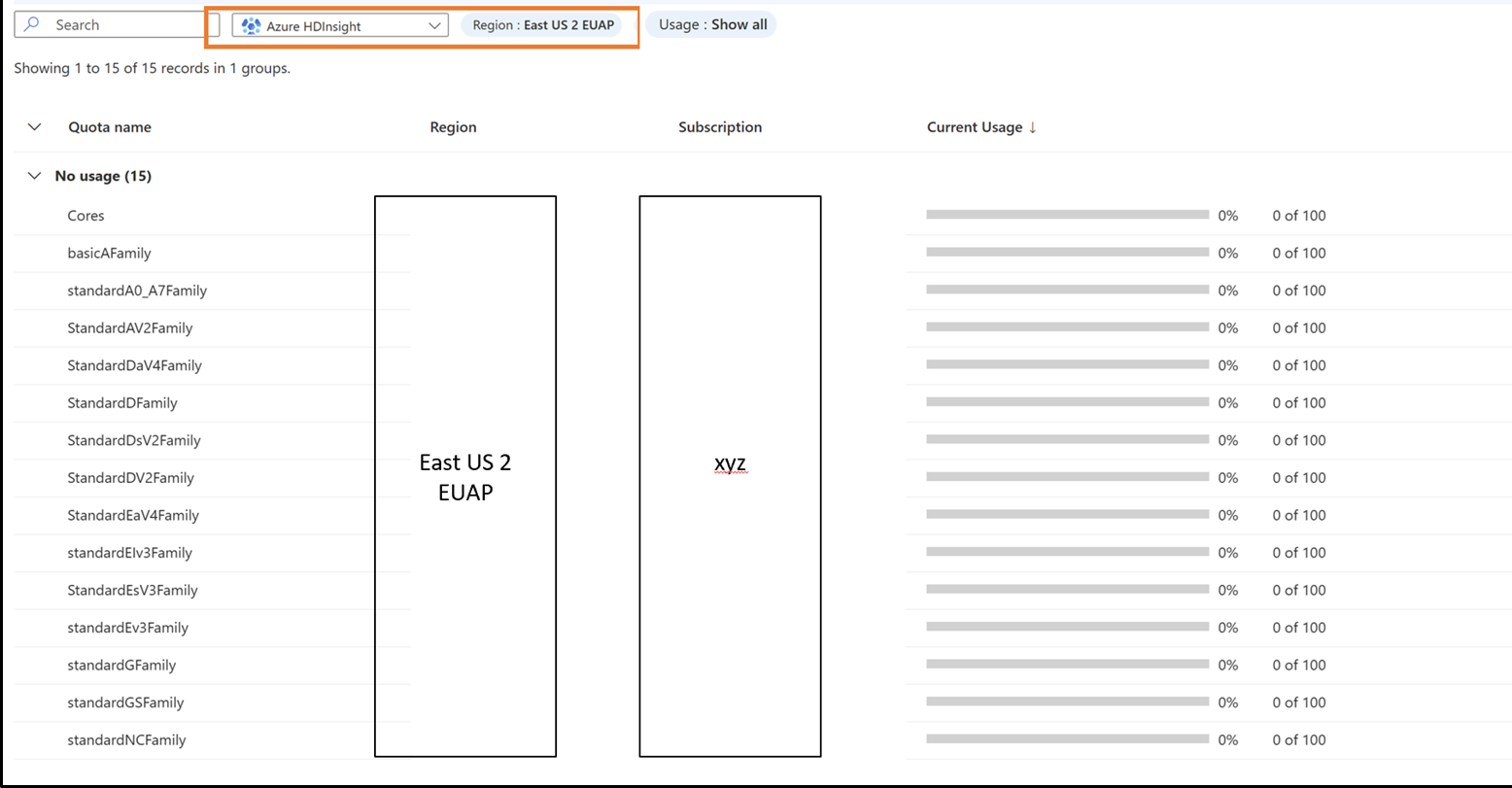
HDInsight에 대한 할당량 관리 보기
VM 제품군 수준에서 할당량의 세분화된 수준 및 분류를 봅니다. VM 제품군 수준에서 현재 할당량 및 지역에 남은 할당량을 확인합니다.
참고 항목
이 기능은 현재 미국 동부 EUAP 지역의 HDInsight 4.x 및 5.x에서 사용할 수 있습니다. 이후에 따라야 할 다른 지역입니다.
현재 할당량 보기:
현재 할당량 및 VM 제품군 수준에서 지역에 남은 할당량을 참조하세요.
Azure Portal 위쪽 검색 창에서 할당량을 검색하고 선택합니다.
할당량 페이지에서 Azure HDInsight를 선택합니다.

드롭다운 상자에서 구독 및 지역을 선택합니다.

VM 제품군 및 지역당 새 할당량 요청
- 할당량 세부 정보를 보려는 행을 클릭합니다.





할당량
구독 할당량 관리에 대한 자세한 내용은 할당량 증대 요청을 참조하세요.
다음 단계
- Apache Hadoop, Spark, Kafka 등을 사용하여 HDInsight에서 클러스터 설정: HDInsight에서 클러스터를 설정하고 구성하는 방법을 알아봅니다.
- 클러스터 성능 모니터링: 클러스터의 용량에 영향을 줄 수 있는 HDInsight 클러스터를 모니터링하는 주요 시나리오에 대해 알아봅니다.